 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Emotional Speech Synthesis for Companion Robot to Imitate Professional Caregiver Speech
Sep 27, 2021
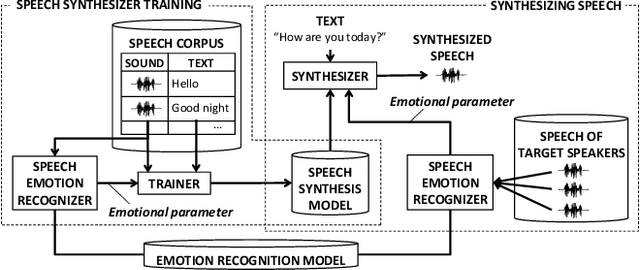
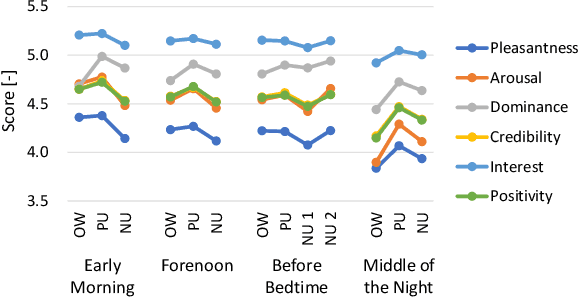


When people try to influence others to do something, they subconsciously adjust their speech to include appropriate emotional information. In order for a robot to influence people in the same way, the robot should be able to imitate the range of human emotions when speaking. To achieve this, we propose a speech synthesis method for imitating the emotional states in human speech. In contrast to previous methods, the advantage of our method is that it requires less manual effort to adjust the emotion of the synthesized speech. Our synthesizer receives an emotion vector to characterize the emotion of synthesized speech. The vector is automatically obtained from human utterances by using a speech emotion recognizer. We evaluated our method in a scenario when a robot tries to regulate an elderly person's circadian rhythm by speaking to the person using appropriate emotional states. For the target speech to imitate, we collected utterances from professional caregivers when they speak to elderly people at different times of the day. Then we conducted a subjective evaluation where the elderly participants listened to the speech samples generated by our method. The results showed that listening to the samples made the participants feel more active in the early morning and calmer in the middle of the night. This suggests that the robot may be able to adjust the participants' circadian rhythm and that the robot can potentially exert influence similarly to a person.
A single speaker is almost all you need for automatic speech recognition
Mar 29, 2022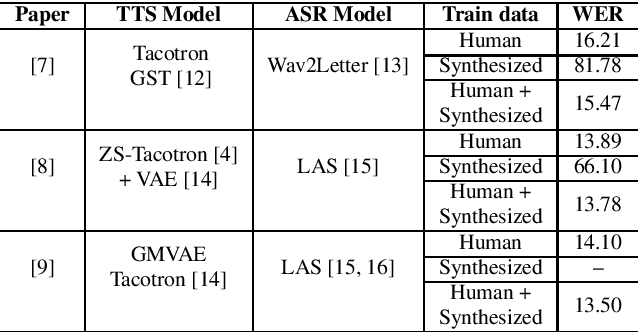
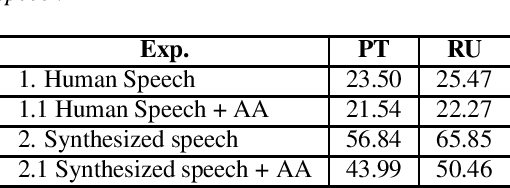

We explore the use of speech synthesis and voice conversion applied to augment datasets for automatic speech recognition (ASR) systems, in scenarios with only one speaker available for the target language. Through extensive experiments, we show that our approach achieves results compared to the state-of-the-art (SOTA) and requires only one speaker in the target language during speech synthesis/voice conversion model training. Finally, we show that it is possible to obtain promising results in the training of an ASR model with our data augmentation method and only a single real speaker in different target languages.
Revisiting Speech Content Privacy
Oct 13, 2021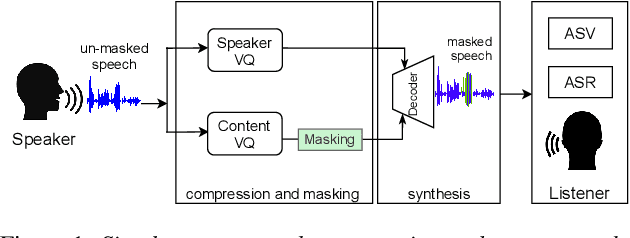
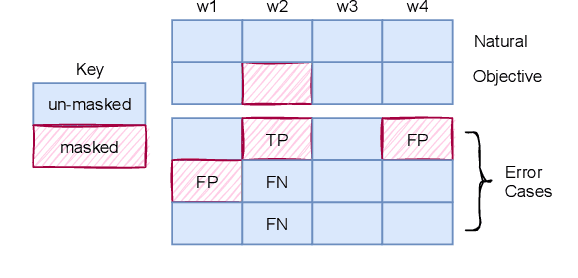
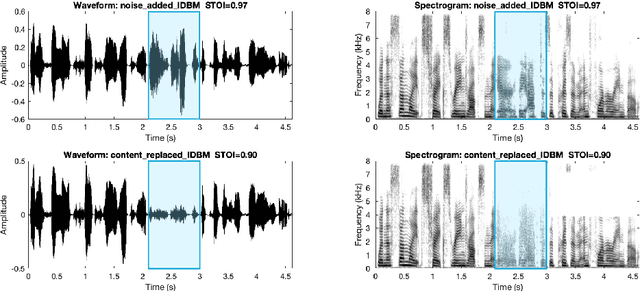
In this paper, we discuss an important aspect of speech privacy: protecting spoken content. New capabilities from the field of machine learning provide a unique and timely opportunity to revisit speech content protection. There are many different applications of content privacy, even though this area has been under-explored in speech technology research. This paper presents several scenarios that indicate a need for speech content privacy even as the specific techniques to achieve content privacy may necessarily vary. Our discussion includes several different types of content privacy including recoverable and non-recoverable content. Finally, we introduce evaluation strategies as well as describe some of the difficulties that may be encountered.
Non-Standard Vietnamese Word Detection and Normalization for Text-to-Speech
Sep 07, 2022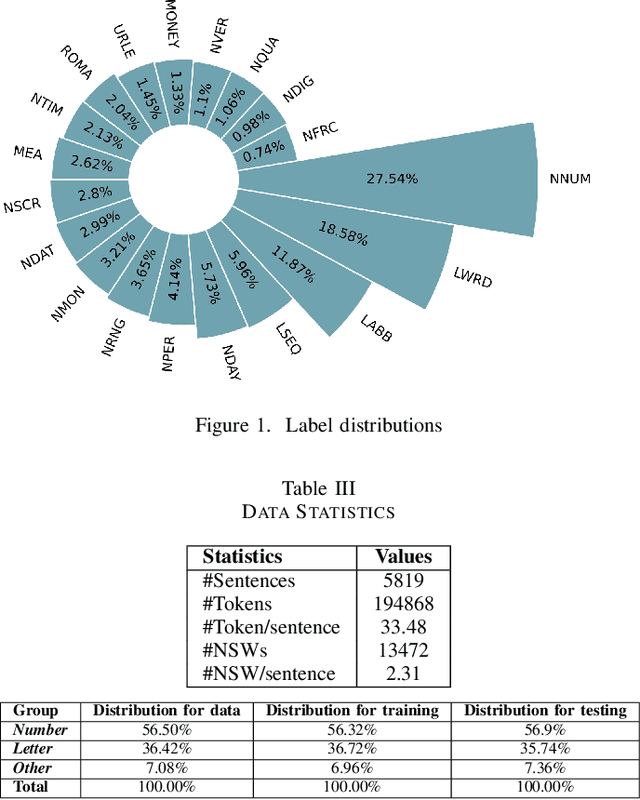
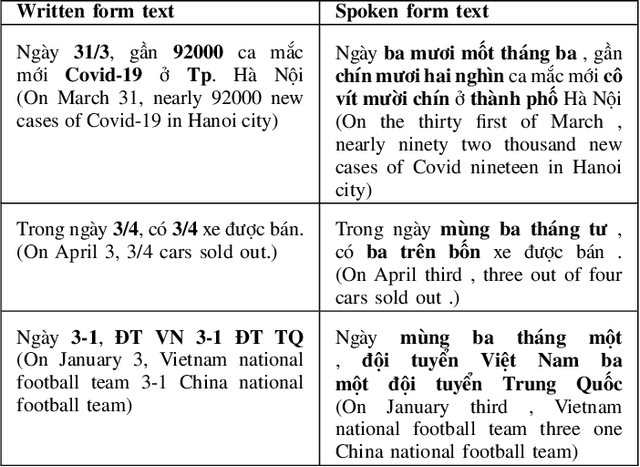

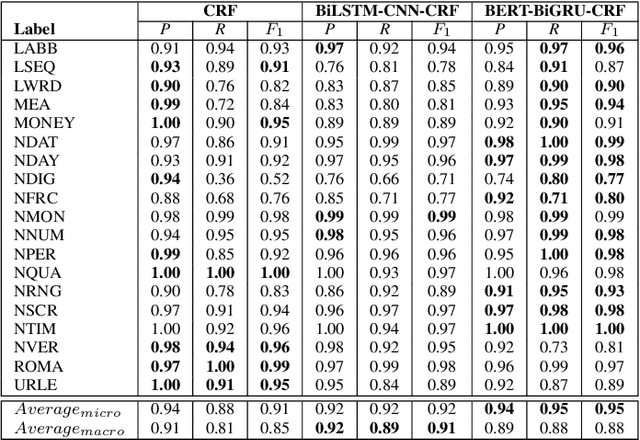
Converting written texts into their spoken forms is an essential problem in any text-to-speech (TTS) systems. However, building an effective text normalization solution for a real-world TTS system face two main challenges: (1) the semantic ambiguity of non-standard words (NSWs), e.g., numbers, dates, ranges, scores, abbreviations, and (2) transforming NSWs into pronounceable syllables, such as URL, email address, hashtag, and contact name. In this paper, we propose a new two-phase normalization approach to deal with these challenges. First, a model-based tagger is designed to detect NSWs. Then, depending on NSW types, a rule-based normalizer expands those NSWs into their final verbal forms. We conducted three empirical experiments for NSW detection using Conditional Random Fields (CRFs), BiLSTM-CNN-CRF, and BERT-BiGRU-CRF models on a manually annotated dataset including 5819 sentences extracted from Vietnamese news articles. In the second phase, we propose a forward lexicon-based maximum matching algorithm to split down the hashtag, email, URL, and contact name. The experimental results of the tagging phase show that the average F1 scores of the BiLSTM-CNN-CRF and CRF models are above 90.00%, reaching the highest F1 of 95.00% with the BERT-BiGRU-CRF model. Overall, our approach has low sentence error rates, at 8.15% with CRF and 7.11% with BiLSTM-CNN-CRF taggers, and only 6.67% with BERT-BiGRU-CRF tagger.
Sneaky Spikes: Uncovering Stealthy Backdoor Attacks in Spiking Neural Networks with Neuromorphic Data
Feb 13, 2023


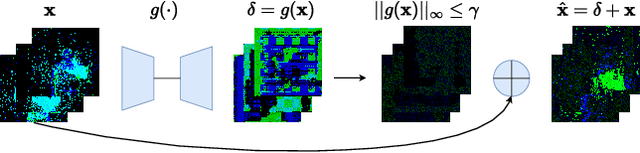
Deep neural networks (DNNs) have achieved excellent results in various tasks, including image and speech recognition. However, optimizing the performance of DNNs requires careful tuning of multiple hyperparameters and network parameters via training. High-performance DNNs utilize a large number of parameters, corresponding to high energy consumption during training. To address these limitations, researchers have developed spiking neural networks (SNNs), which are more energy-efficient and can process data in a biologically plausible manner, making them well-suited for tasks involving sensory data processing, i.e., neuromorphic data. Like DNNs, SNNs are vulnerable to various threats, such as adversarial examples and backdoor attacks. Yet, the attacks and countermeasures for SNNs have been almost fully unexplored. This paper investigates the application of backdoor attacks in SNNs using neuromorphic datasets and different triggers. More precisely, backdoor triggers in neuromorphic data can change their position and color, allowing a larger range of possibilities than common triggers in, e.g., the image domain. We propose different attacks achieving up to 100\% attack success rate without noticeable clean accuracy degradation. We also evaluate the stealthiness of the attacks via the structural similarity metric, showing our most powerful attacks being also stealthy. Finally, we adapt the state-of-the-art defenses from the image domain, demonstrating they are not necessarily effective for neuromorphic data resulting in inaccurate performance.
Dysfluencies Seldom Come Alone -- Detection as a Multi-Label Problem
Oct 28, 2022
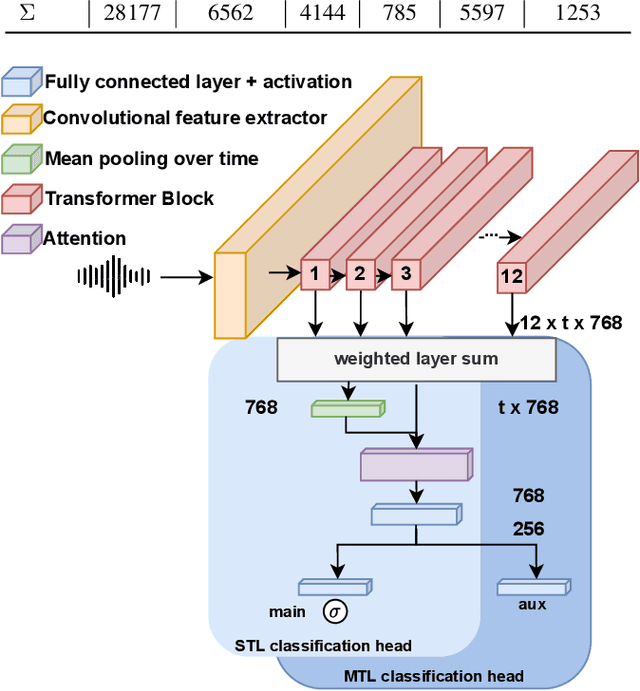
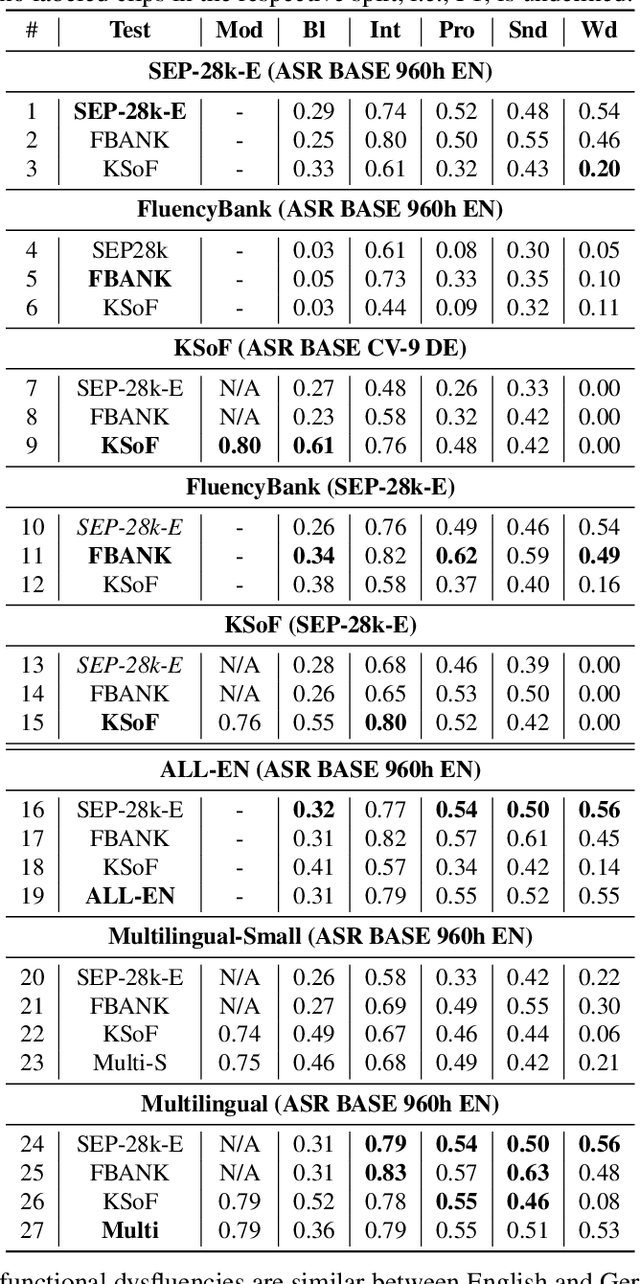
Specially adapted speech recognition models are necessary to handle stuttered speech. For these to be used in a targeted manner, stuttered speech must be reliably detected. Recent works have treated stuttering as a multi-class classification problem or viewed detecting each dysfluency type as an isolated task; that does not capture the nature of stuttering, where one dysfluency seldom comes alone, i.e., co-occurs with others. This work explores an approach based on a modified wav2vec 2.0 system for end-to-end stuttering detection and classification as a multi-label problem. The method is evaluated on combinations of three datasets containing English and German stuttered speech, yielding state-of-the-art results for stuttering detection on the SEP-28k-Extended dataset. Experimental results provide evidence for the transferability of features and the generalizability of the method across datasets and languages.
An Exploration of Prompt Tuning on Generative Spoken Language Model for Speech Processing Tasks
Mar 31, 2022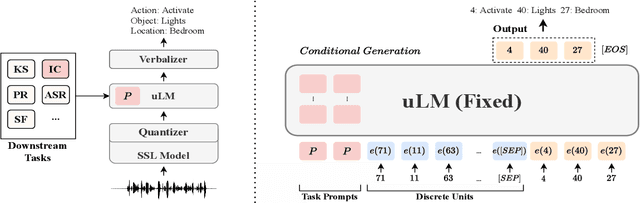
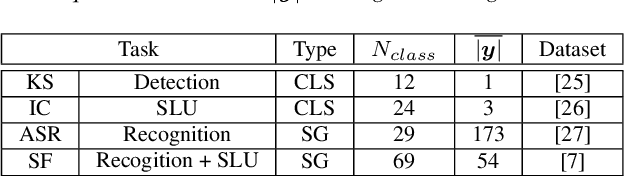
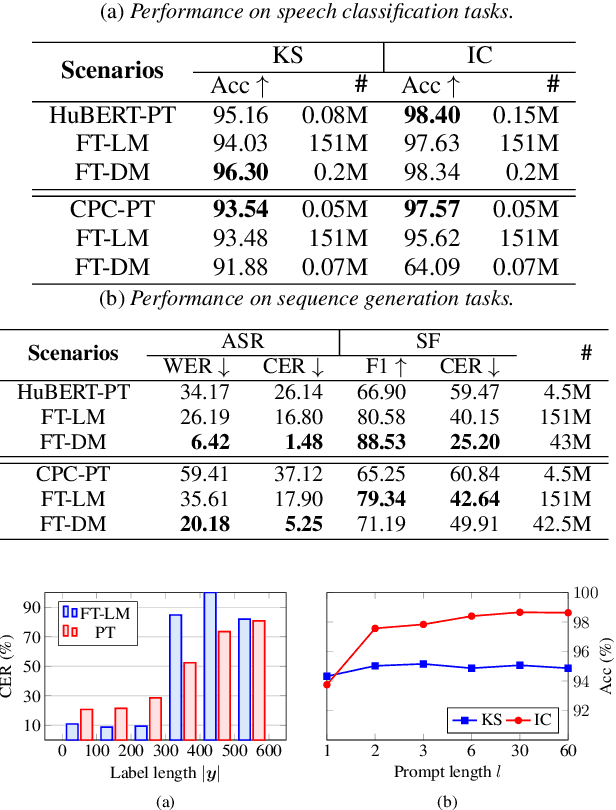
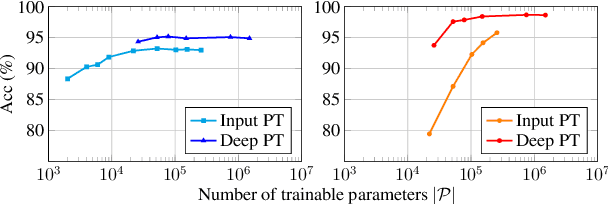
Speech representations learned from Self-supervised learning (SSL) models have been found beneficial for various speech processing tasks. However, utilizing SSL representations usually requires fine-tuning the pre-trained models or designing task-specific downstream models and loss functions, causing much memory usage and human labor. On the other hand, prompting in Natural Language Processing (NLP) is an efficient and widely used technique to leverage pre-trained language models (LMs). Nevertheless, such a paradigm is little studied in the speech community. We report in this paper the first exploration of the prompt tuning paradigm for speech processing tasks based on Generative Spoken Language Model (GSLM). Experiment results show that the prompt tuning technique achieves competitive performance in speech classification tasks with fewer trainable parameters than fine-tuning specialized downstream models. We further study the technique in challenging sequence generation tasks. Prompt tuning also demonstrates its potential, while the limitation and possible research directions are discussed in this paper.
Expressive-VC: Highly Expressive Voice Conversion with Attention Fusion of Bottleneck and Perturbation Features
Nov 09, 2022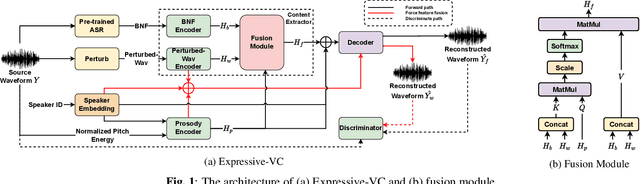
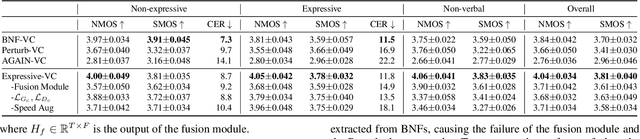


Voice conversion for highly expressive speech is challenging. Current approaches struggle with the balancing between speaker similarity, intelligibility and expressiveness. To address this problem, we propose Expressive-VC, a novel end-to-end voice conversion framework that leverages advantages from both neural bottleneck feature (BNF) approach and information perturbation approach. Specifically, we use a BNF encoder and a Perturbed-Wav encoder to form a content extractor to learn linguistic and para-linguistic features respectively, where BNFs come from a robust pre-trained ASR model and the perturbed wave becomes speaker-irrelevant after signal perturbation. We further fuse the linguistic and para-linguistic features through an attention mechanism, where speaker-dependent prosody features are adopted as the attention query, which result from a prosody encoder with target speaker embedding and normalized pitch and energy of source speech as input. Finally the decoder consumes the integrated features and the speaker-dependent prosody feature to generate the converted speech. Experiments demonstrate that Expressive-VC is superior to several state-of-the-art systems, achieving both high expressiveness captured from the source speech and high speaker similarity with the target speaker; meanwhile intelligibility is well maintained.
Speaker Adaptation Using Spectro-Temporal Deep Features for Dysarthric and Elderly Speech Recognition
Feb 21, 2022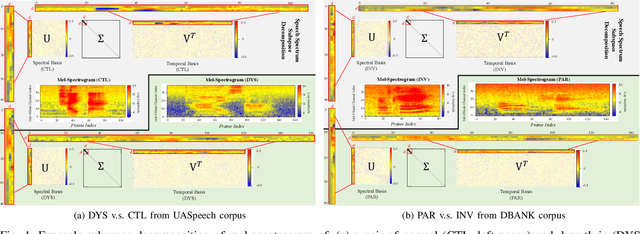
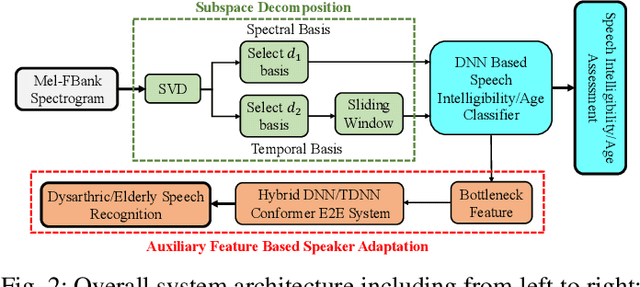
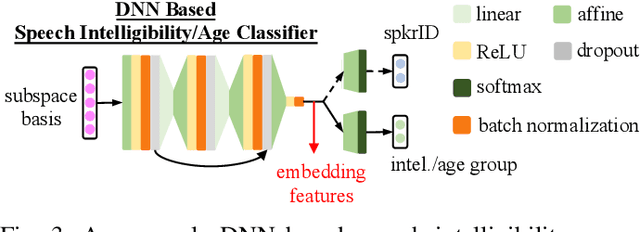
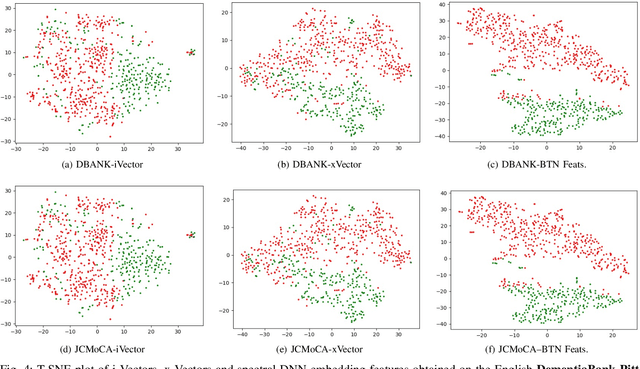
Despite the rapid progress of automatic speech recognition (ASR) technologies targeting normal speech in recent decades, accurate recognition of dysarthric and elderly speech remains highly challenging tasks to date. Sources of heterogeneity commonly found in normal speech including accent or gender, when further compounded with the variability over age and speech pathology severity level, create large diversity among speakers. To this end, speaker adaptation techniques play a key role in personalization of ASR systems for such users. Motivated by the spectro-temporal level differences between dysarthric, elderly and normal speech that systematically manifest in articulatory imprecision, decreased volume and clarity, slower speaking rates and increased dysfluencies, novel spectrotemporal subspace basis deep embedding features derived using SVD speech spectrum decomposition are proposed in this paper to facilitate auxiliary feature based speaker adaptation of state-of-the-art hybrid DNN/TDNN and end-to-end Conformer speech recognition systems. Experiments were conducted on four tasks: the English UASpeech and TORGO dysarthric speech corpora; the English DementiaBank Pitt and Cantonese JCCOCC MoCA elderly speech datasets. The proposed spectro-temporal deep feature adapted systems outperformed baseline i-Vector and xVector adaptation by up to 2.63% absolute (8.63% relative) reduction in word error rate (WER). Consistent performance improvements were retained after model based speaker adaptation using learning hidden unit contributions (LHUC) was further applied. The best speaker adapted system using the proposed spectral basis embedding features produced the lowest published WER of 25.05% on the UASpeech test set of 16 dysarthric speakers.
Towards Error-Resilient Neural Speech Coding
Jul 03, 2022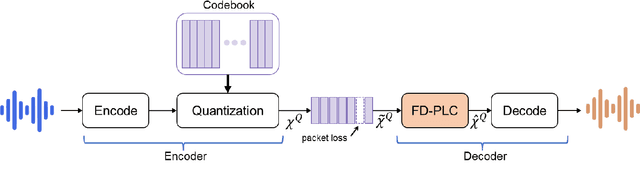
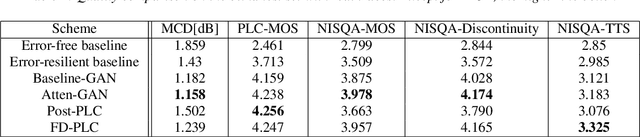

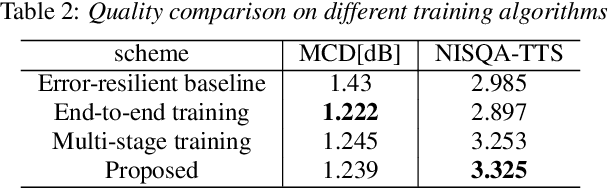
Neural audio coding has shown very promising results recently in the literature to largely outperform traditional codecs but limited attention has been paid on its error resilience. Neural codecs trained considering only source coding tend to be extremely sensitive to channel noises, especially in wireless channels with high error rate. In this paper, we investigate how to elevate the error resilience of neural audio codecs for packet losses that often occur during real-time communications. We propose a feature-domain packet loss concealment algorithm (FD-PLC) for real-time neural speech coding. Specifically, we introduce a self-attention-based module on the received latent features to recover lost frames in the feature domain before the decoder. A hybrid segment-level and frame-level frequency-domain discriminator is employed to guide the network to focus on both the generative quality of lost frames and the continuity with neighbouring frames. Experimental results on several error patterns show that the proposed scheme can achieve better robustness compared with the corresponding error-free and error-resilient baselines. We also show that feature-domain concealment is superior to waveform-domain counterpart as post-processing.