 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Information Flow Routes: Automatically Interpreting Language Models at Scale
Feb 27, 2024
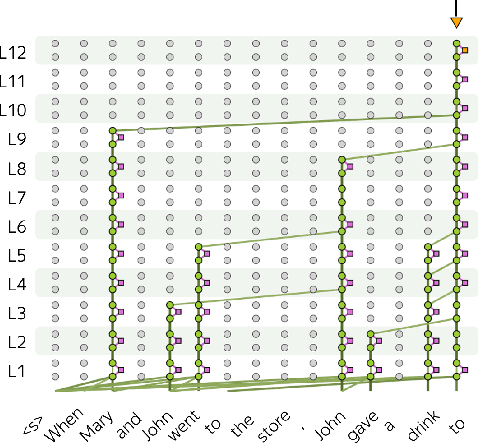
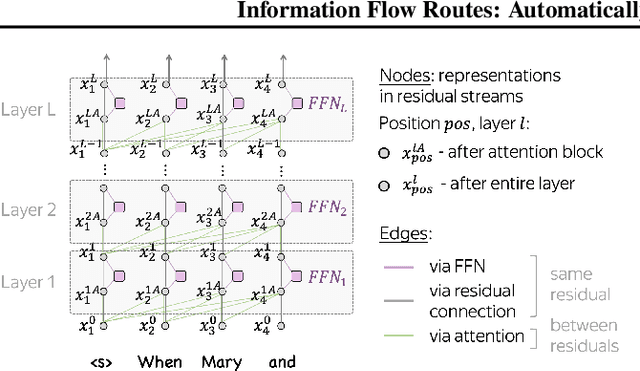
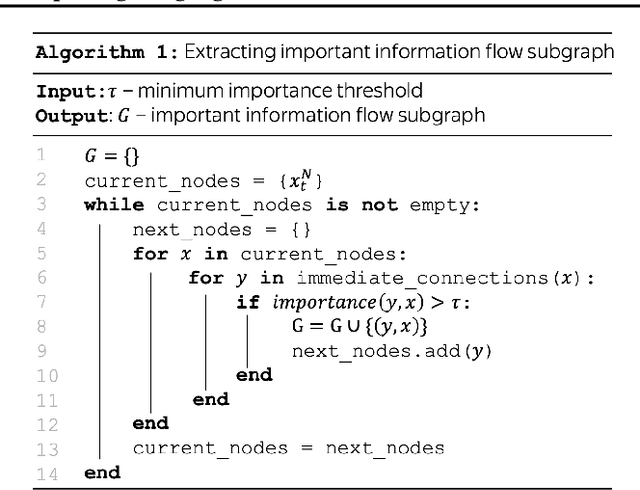
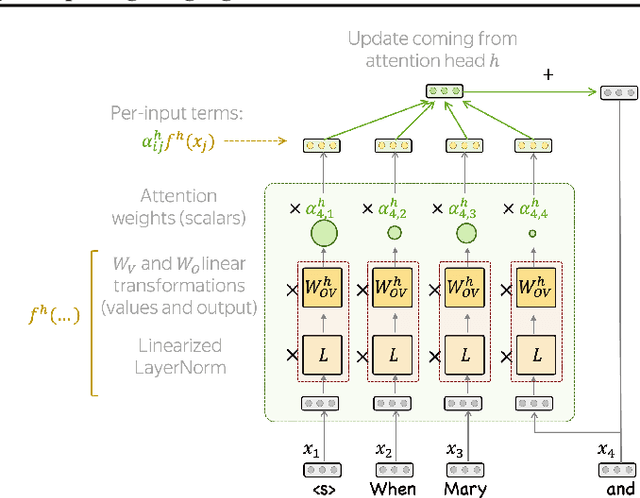
Information flows by routes inside the network via mechanisms implemented in the model. These routes can be represented as graphs where nodes correspond to token representations and edges to operations inside the network. We automatically build these graphs in a top-down manner, for each prediction leaving only the most important nodes and edges. In contrast to the existing workflows relying on activation patching, we do this through attribution: this allows us to efficiently uncover existing circuits with just a single forward pass. Additionally, the applicability of our method is far beyond patching: we do not need a human to carefully design prediction templates, and we can extract information flow routes for any prediction (not just the ones among the allowed templates). As a result, we can talk about model behavior in general, for specific types of predictions, or different domains. We experiment with Llama 2 and show that the role of some attention heads is overall important, e.g. previous token heads and subword merging heads. Next, we find similarities in Llama 2 behavior when handling tokens of the same part of speech. Finally, we show that some model components can be specialized on domains such as coding or multilingual texts.
A Phoneme-Scale Assessment of Multichannel Speech Enhancement Algorithms
Jan 24, 2024In the intricate acoustic landscapes where speech intelligibility is challenged by noise and reverberation, multichannel speech enhancement emerges as a promising solution for individuals with hearing loss. Such algorithms are commonly evaluated at the utterance level. However, this approach overlooks the granular acoustic nuances revealed by phoneme-specific analysis, potentially obscuring key insights into their performance. This paper presents an in-depth phoneme-scale evaluation of 3 state-of-the-art multichannel speech enhancement algorithms. These algorithms -- FasNet, MVDR, and Tango -- are extensively evaluated across different noise conditions and spatial setups, employing realistic acoustic simulations with measured room impulse responses, and leveraging diversity offered by multiple microphones in a binaural hearing setup. The study emphasizes the fine-grained phoneme-level analysis, revealing that while some phonemes like plosives are heavily impacted by environmental acoustics and challenging to deal with by the algorithms, others like nasals and sibilants see substantial improvements after enhancement. These investigations demonstrate important improvements in phoneme clarity in noisy conditions, with insights that could drive the development of more personalized and phoneme-aware hearing aid technologies.
Revisiting speech segmentation and lexicon learning with better features
Jan 31, 2024We revisit a self-supervised method that segments unlabelled speech into word-like segments. We start from the two-stage duration-penalised dynamic programming method that performs zero-resource segmentation without learning an explicit lexicon. In the first acoustic unit discovery stage, we replace contrastive predictive coding features with HuBERT. After word segmentation in the second stage, we get an acoustic word embedding for each segment by averaging HuBERT features. These embeddings are clustered using K-means to get a lexicon. The result is good full-coverage segmentation with a lexicon that achieves state-of-the-art performance on the ZeroSpeech benchmarks.
An Embarrassingly Simple Approach for LLM with Strong ASR Capacity
Feb 13, 2024In this paper, we focus on solving one of the most important tasks in the field of speech processing, i.e., automatic speech recognition (ASR), with speech foundation encoders and large language models (LLM). Recent works have complex designs such as compressing the output temporally for the speech encoder, tackling modal alignment for the projector, and utilizing parameter-efficient fine-tuning for the LLM. We found that delicate designs are not necessary, while an embarrassingly simple composition of off-the-shelf speech encoder, LLM, and the only trainable linear projector is competent for the ASR task. To be more specific, we benchmark and explore various combinations of LLMs and speech encoders, leading to the optimal LLM-based ASR system, which we call SLAM-ASR. The proposed SLAM-ASR provides a clean setup and little task-specific design, where only the linear projector is trained. To the best of our knowledge, SLAM-ASR achieves the best performance on the Librispeech benchmark among LLM-based ASR models and even outperforms the latest LLM-based audio-universal model trained on massive pair data. Finally, we explore the capability emergence of LLM-based ASR in the process of modal alignment. We hope that our study can facilitate the research on extending LLM with cross-modality capacity and shed light on the LLM-based ASR community.
Bayesian Parameter-Efficient Fine-Tuning for Overcoming Catastrophic Forgetting
Feb 19, 2024Although motivated by the adaptation of text-to-speech synthesis models, we argue that more generic parameter-efficient fine-tuning (PEFT) is an appropriate framework to do such adaptation. However, catastrophic forgetting remains an issue with PEFT, damaging the pre-trained model's inherent capabilities. We demonstrate that existing Bayesian learning techniques can be applied to PEFT to prevent catastrophic forgetting as long as the parameter shift of the fine-tuned layers can be calculated differentiably. In a principled series of experiments on language modeling and speech synthesis tasks, we utilize established Laplace approximations, including diagonal and Kronecker factored approaches, to regularize PEFT with the low-rank adaptation (LoRA) and compare their performance in pre-training knowledge preservation. Our results demonstrate that catastrophic forgetting can be overcome by our methods without degrading the fine-tuning performance, and using the Kronecker factored approximations produces a better preservation of the pre-training knowledge than the diagonal ones.
SpecDiff-GAN: A Spectrally-Shaped Noise Diffusion GAN for Speech and Music Synthesis
Jan 30, 2024Generative adversarial network (GAN) models can synthesize highquality audio signals while ensuring fast sample generation. However, they are difficult to train and are prone to several issues including mode collapse and divergence. In this paper, we introduce SpecDiff-GAN, a neural vocoder based on HiFi-GAN, which was initially devised for speech synthesis from mel spectrogram. In our model, the training stability is enhanced by means of a forward diffusion process which consists in injecting noise from a Gaussian distribution to both real and fake samples before inputting them to the discriminator. We further improve the model by exploiting a spectrally-shaped noise distribution with the aim to make the discriminator's task more challenging. We then show the merits of our proposed model for speech and music synthesis on several datasets. Our experiments confirm that our model compares favorably in audio quality and efficiency compared to several baselines.
* Accepted at ICASSP 2024
A Multi-Aspect Framework for Counter Narrative Evaluation using Large Language Models
Feb 18, 2024Counter narratives - informed responses to hate speech contexts designed to refute hateful claims and de-escalate encounters - have emerged as an effective hate speech intervention strategy. While previous work has proposed automatic counter narrative generation methods to aid manual interventions, the evaluation of these approaches remains underdeveloped. Previous automatic metrics for counter narrative evaluation lack alignment with human judgment as they rely on superficial reference comparisons instead of incorporating key aspects of counter narrative quality as evaluation criteria. To address prior evaluation limitations, we propose a novel evaluation framework prompting LLMs to provide scores and feedback for generated counter narrative candidates using 5 defined aspects derived from guidelines from counter narrative specialized NGOs. We found that LLM evaluators achieve strong alignment to human-annotated scores and feedback and outperform alternative metrics, indicating their potential as multi-aspect, reference-free and interpretable evaluators for counter narrative evaluation.
Robust Dual-Modal Speech Keyword Spotting for XR Headsets
Jan 26, 2024While speech interaction finds widespread utility within the Extended Reality (XR) domain, conventional vocal speech keyword spotting systems continue to grapple with formidable challenges, including suboptimal performance in noisy environments, impracticality in situations requiring silence, and susceptibility to inadvertent activations when others speak nearby. These challenges, however, can potentially be surmounted through the cost-effective fusion of voice and lip movement information. Consequently, we propose a novel vocal-echoic dual-modal keyword spotting system designed for XR headsets. We devise two different modal fusion approches and conduct experiments to test the system's performance across diverse scenarios. The results show that our dual-modal system not only consistently outperforms its single-modal counterparts, demonstrating higher precision in both typical and noisy environments, but also excels in accurately identifying silent utterances. Furthermore, we have successfully applied the system in real-time demonstrations, achieving promising results. The code is available at https://github.com/caizhuojiang/VE-KWS.
GPT-HateCheck: Can LLMs Write Better Functional Tests for Hate Speech Detection?
Feb 23, 2024Online hate detection suffers from biases incurred in data sampling, annotation, and model pre-training. Therefore, measuring the averaged performance over all examples in held-out test data is inadequate. Instead, we must identify specific model weaknesses and be informed when it is more likely to fail. A recent proposal in this direction is HateCheck, a suite for testing fine-grained model functionalities on synthesized data generated using templates of the kind "You are just a [slur] to me." However, despite enabling more detailed diagnostic insights, the HateCheck test cases are often generic and have simplistic sentence structures that do not match the real-world data. To address this limitation, we propose GPT-HateCheck, a framework to generate more diverse and realistic functional tests from scratch by instructing large language models (LLMs). We employ an additional natural language inference (NLI) model to verify the generations. Crowd-sourced annotation demonstrates that the generated test cases are of high quality. Using the new functional tests, we can uncover model weaknesses that would be overlooked using the original HateCheck dataset.
Acoustic characterization of speech rhythm: going beyond metrics with recurrent neural networks
Jan 22, 2024Languages have long been described according to their perceived rhythmic attributes. The associated typologies are of interest in psycholinguistics as they partly predict newborns' abilities to discriminate between languages and provide insights into how adult listeners process non-native languages. Despite the relative success of rhythm metrics in supporting the existence of linguistic rhythmic classes, quantitative studies have yet to capture the full complexity of temporal regularities associated with speech rhythm. We argue that deep learning offers a powerful pattern-recognition approach to advance the characterization of the acoustic bases of speech rhythm. To explore this hypothesis, we trained a medium-sized recurrent neural network on a language identification task over a large database of speech recordings in 21 languages. The network had access to the amplitude envelopes and a variable identifying the voiced segments, assuming that this signal would poorly convey phonetic information but preserve prosodic features. The network was able to identify the language of 10-second recordings in 40% of the cases, and the language was in the top-3 guesses in two-thirds of the cases. Visualization methods show that representations built from the network activations are consistent with speech rhythm typologies, although the resulting maps are more complex than two separated clusters between stress and syllable-timed languages. We further analyzed the model by identifying correlations between network activations and known speech rhythm metrics. The findings illustrate the potential of deep learning tools to advance our understanding of speech rhythm through the identification and exploration of linguistically relevant acoustic feature spaces.