 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Phase Continuity: Learning Derivatives of Phase Spectrum for Speech Enhancement
Feb 24, 2022
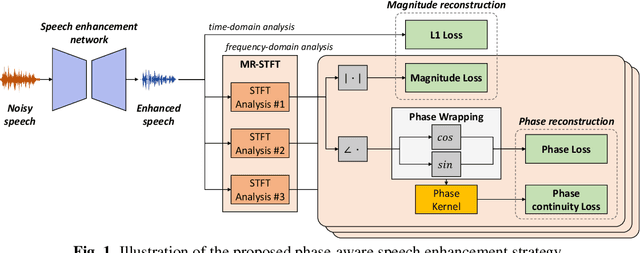
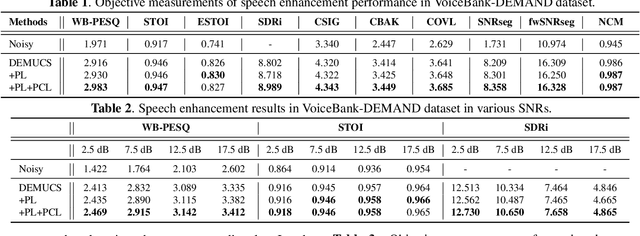
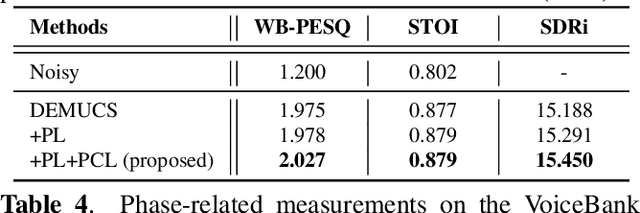
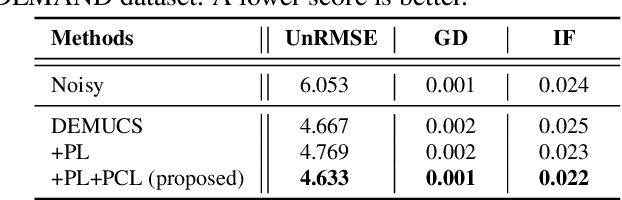
Modern neural speech enhancement models usually include various forms of phase information in their training loss terms, either explicitly or implicitly. However, these loss terms are typically designed to reduce the distortion of phase spectrum values at specific frequencies, which ensures they do not significantly affect the quality of the enhanced speech. In this paper, we propose an effective phase reconstruction strategy for neural speech enhancement that can operate in noisy environments. Specifically, we introduce a phase continuity loss that considers relative phase variations across the time and frequency axes. By including this phase continuity loss in a state-of-the-art neural speech enhancement system trained with reconstruction loss and a number of magnitude spectral losses, we show that our proposed method further improves the quality of enhanced speech signals over the baseline, especially when training is done jointly with a magnitude spectrum loss.
HateCheckHIn: Evaluating Hindi Hate Speech Detection Models
Apr 30, 2022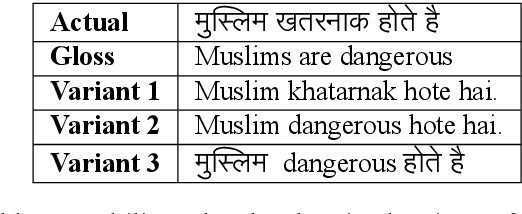
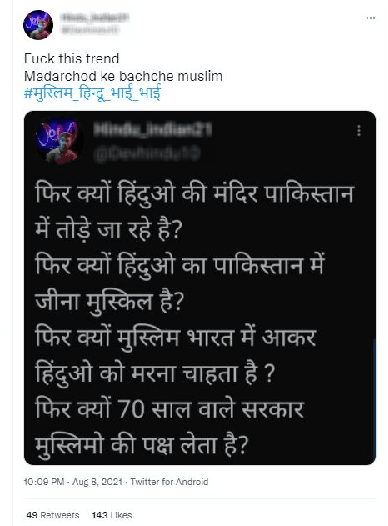

Due to the sheer volume of online hate, the AI and NLP communities have started building models to detect such hateful content. Recently, multilingual hate is a major emerging challenge for automated detection where code-mixing or more than one language have been used for conversation in social media. Typically, hate speech detection models are evaluated by measuring their performance on the held-out test data using metrics such as accuracy and F1-score. While these metrics are useful, it becomes difficult to identify using them where the model is failing, and how to resolve it. To enable more targeted diagnostic insights of such multilingual hate speech models, we introduce a set of functionalities for the purpose of evaluation. We have been inspired to design this kind of functionalities based on real-world conversation on social media. Considering Hindi as a base language, we craft test cases for each functionality. We name our evaluation dataset HateCheckHIn. To illustrate the utility of these functionalities , we test state-of-the-art transformer based m-BERT model and the Perspective API.
Learning Speech Emotion Representations in the Quaternion Domain
Apr 05, 2022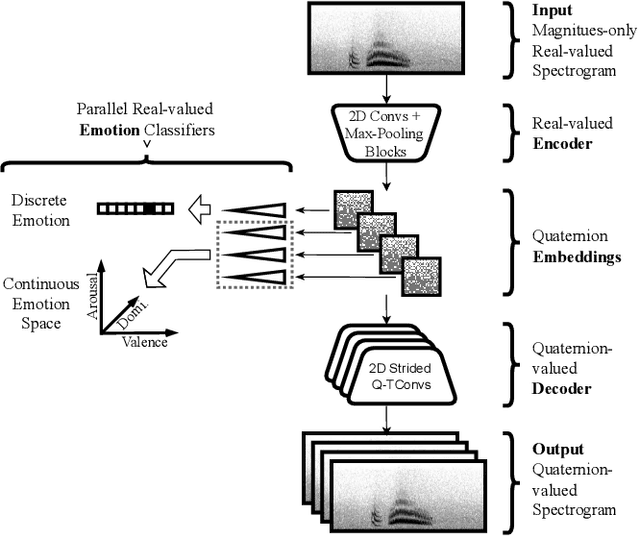
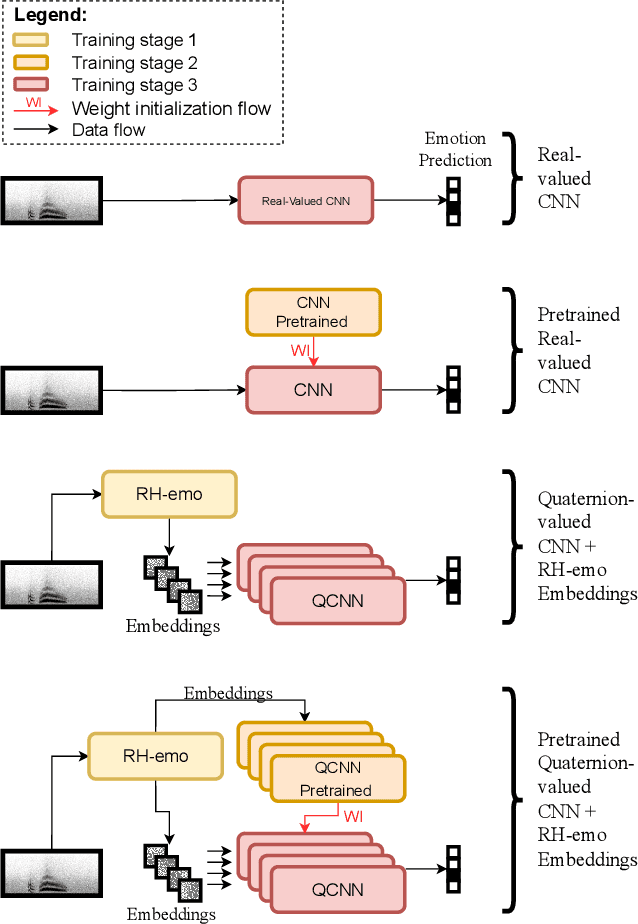
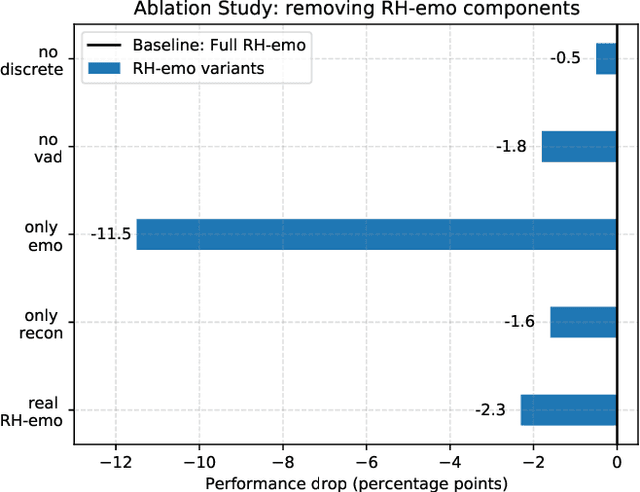
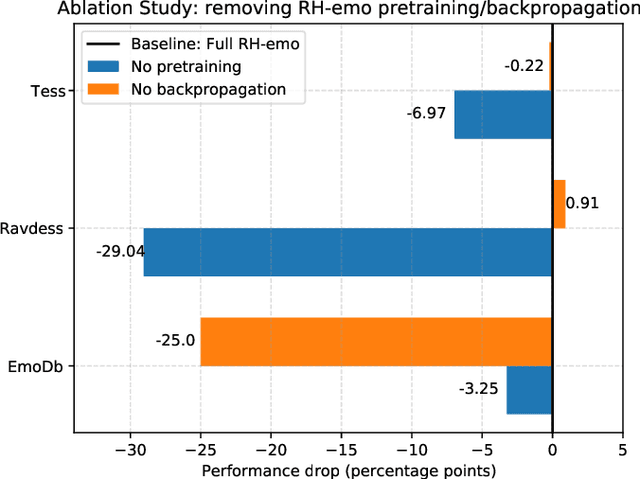
The modeling of human emotion expression in speech signals is an important, yet challenging task. The high resource demand of speech emotion recognition models, combined with the the general scarcity of emotion-labelled data are obstacles to the development and application of effective solutions in this field. In this paper, we present an approach to jointly circumvent these difficulties. Our method, named RH-emo, is a novel semi-supervised architecture aimed at extracting quaternion embeddings from real-valued monoaural spectrograms, enabling the use of quaternion-valued networks for speech emotion recognition tasks. RH-emo is a hybrid real/quaternion autoencoder network that consists of a real-valued encoder in parallel to a real-valued emotion classifier and a quaternion-valued decoder. On the one hand, the classifier permits to optimize each latent axis of the embeddings for the classification of a specific emotion-related characteristic: valence, arousal, dominance and overall emotion. On the other hand, the quaternion reconstruction enables the latent dimension to develop intra-channel correlations that are required for an effective representation as a quaternion entity. We test our approach on speech emotion recognition tasks using four popular datasets: Iemocap, Ravdess, EmoDb and Tess, comparing the performance of three well-established real-valued CNN architectures (AlexNet, ResNet-50, VGG) and their quaternion-valued equivalent fed with the embeddings created with RH-emo. We obtain a consistent improvement in the test accuracy for all datasets, while drastically reducing the resources' demand of models. Moreover, we performed additional experiments and ablation studies that confirm the effectiveness of our approach. The RH-emo repository is available at: https://github.com/ispamm/rhemo.
A two-step backward compatible fullband speech enhancement system
Jan 27, 2022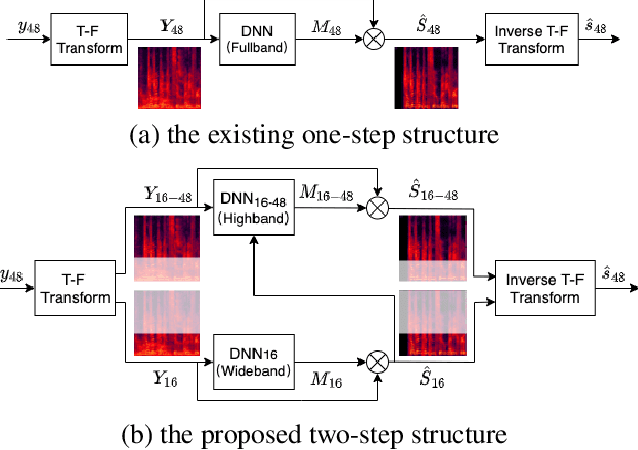
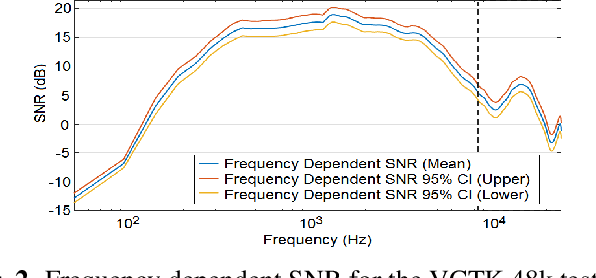
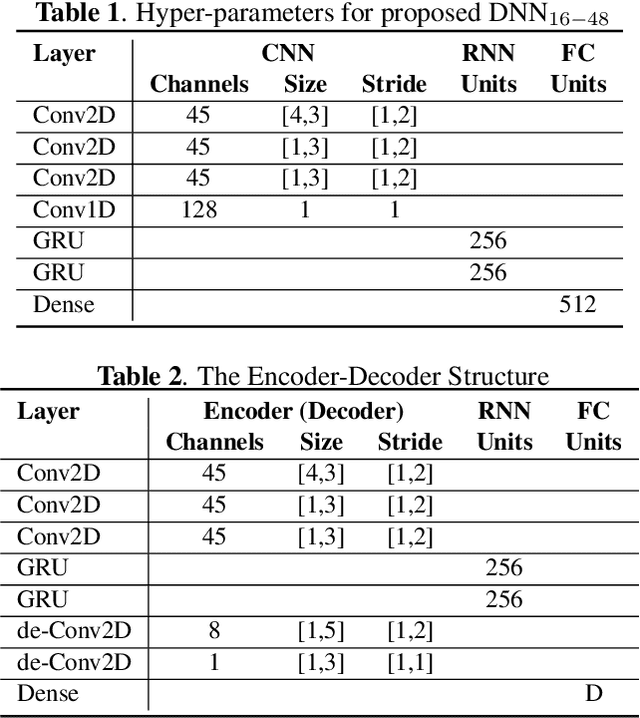
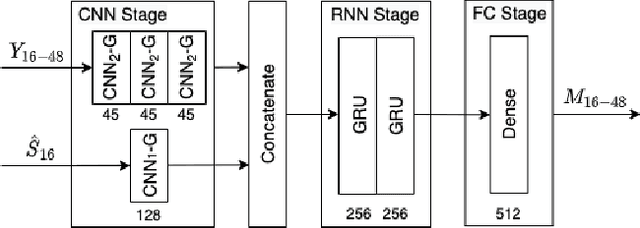
Speech enhancement methods based on deep learning have surpassed traditional methods. While many of these new approaches are operating on the wideband (16kHz) sample rate, a new fullband (48kHz) speech enhancement system is proposed in this paper. Compared to the existing fullband systems that utilizes perceptually motivated features to train the fullband speech enhancement using a single network structure, the proposed system is a two-step system ensuring good fullband speech enhancement quality while backward compatible to the existing wideband systems.
Applying Automated Machine Translation to Educational Video Courses
Jan 09, 2023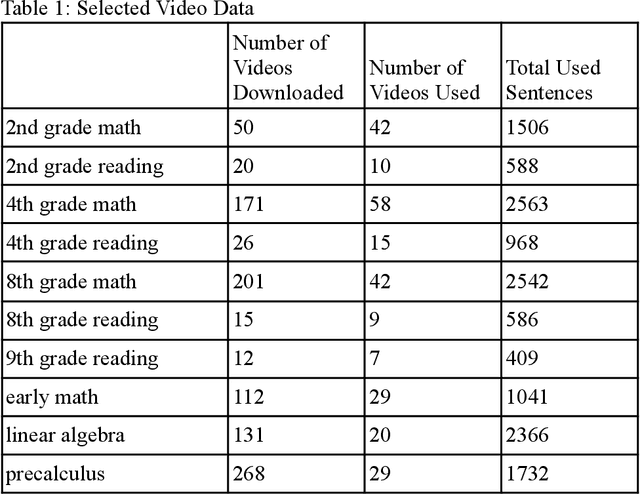
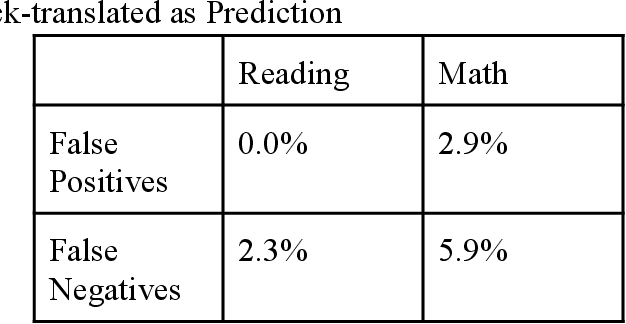
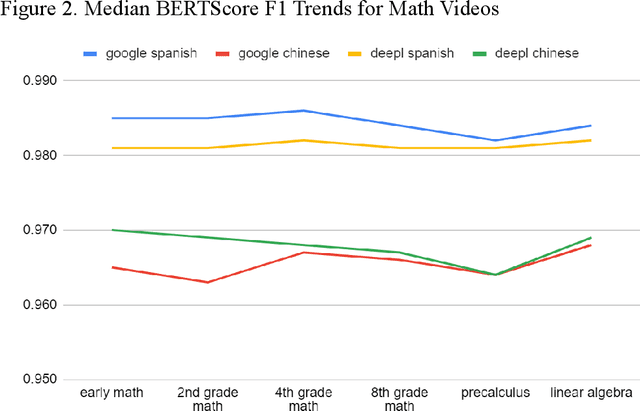
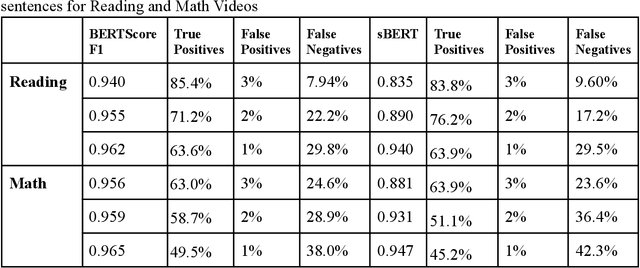
We studied the capability of automated machine translation in the online video education space by automatically translating Khan Academy videos with state of the art translation models and applying Text-to-Speech synthesis to build engaging videos in target languages. We also analyzed and established a reliable translation confidence estimator based on round-trip translations in order to efficiently manage translation quality and reduce human translation effort. Finally, we developed a deployable system to deliver translated videos to end users and collect user corrections for iterative improvement.
A Twitter BERT Approach for Offensive Language Detection in Marathi
Dec 20, 2022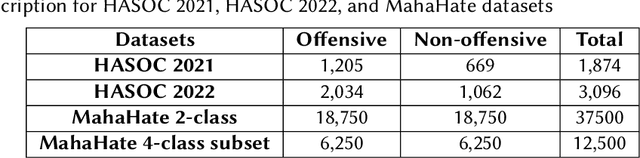
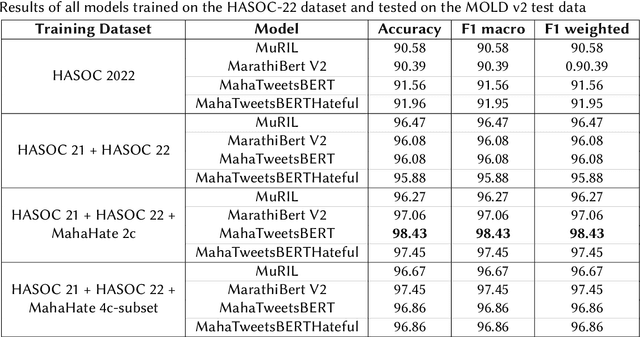
Automated offensive language detection is essential in combating the spread of hate speech, particularly in social media. This paper describes our work on Offensive Language Identification in low resource Indic language Marathi. The problem is formulated as a text classification task to identify a tweet as offensive or non-offensive. We evaluate different mono-lingual and multi-lingual BERT models on this classification task, focusing on BERT models pre-trained with social media datasets. We compare the performance of MuRIL, MahaTweetBERT, MahaTweetBERT-Hateful, and MahaBERT on the HASOC 2022 test set. We also explore external data augmentation from other existing Marathi hate speech corpus HASOC 2021 and L3Cube-MahaHate. The MahaTweetBERT, a BERT model, pre-trained on Marathi tweets when fine-tuned on the combined dataset (HASOC 2021 + HASOC 2022 + MahaHate), outperforms all models with an F1 score of 98.43 on the HASOC 2022 test set. With this, we also provide a new state-of-the-art result on HASOC 2022 / MOLD v2 test set.
Fast Blind Audio Copy-Move Detection and Localization Using Local Feature Tensors in Noise
Feb 15, 2023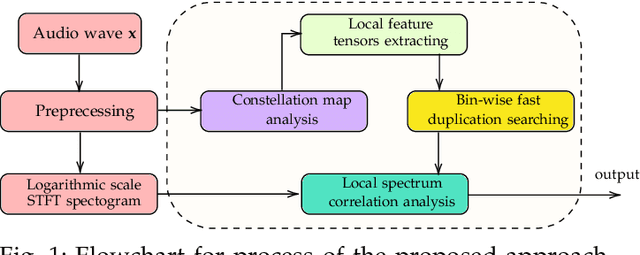
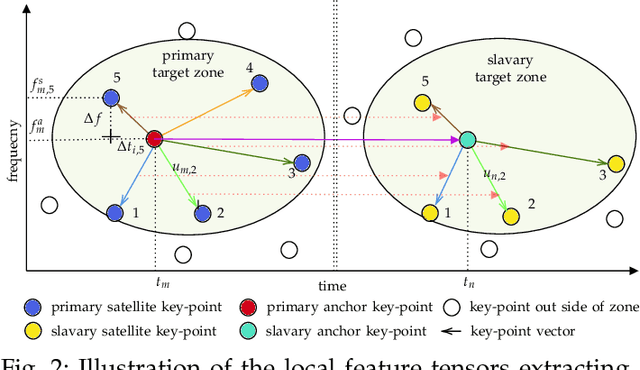
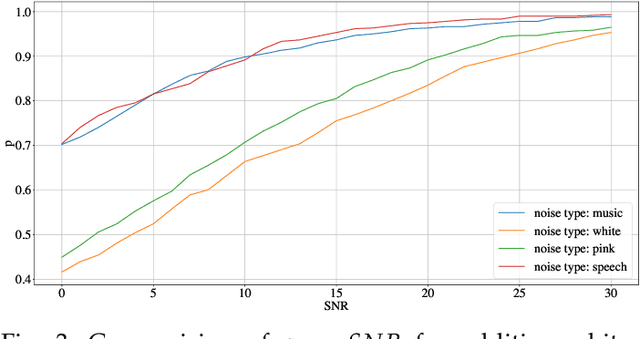
The increasing availability of audio editing software altering digital audios and their ease of use allows create forgeries at low cost. A copy-move forgery (CMF) is one of easiest and popular audio forgeries, which created by copying and pasting audio segments within the same audio, and potentially post-processing it. Three main approaches to audio copy-move detection exist nowadays: samples/frames comparison, acoustic features coherence searching and dynamic time warping. But these approaches will suffer from computational complexity and/or sensitive to noise and post-processing. In this paper, we propose a new local feature tensors-based copy-move detection algorithm that can be applied to transformed duplicates detection and localization problem to a special locality sensitive hash like procedure. The experimental results with massive online real-time audios datasets reveal that the proposed technique effectively determines and locating copy-move forgeries even on a forged speech segment are as short as fractional second. This method is also computational efficient and robust against the audios processed with severe nonlinear transformation, such as resampling, filtering, jsittering, compression and cropping, even contaminated with background noise and music. Hence, the proposed technique provides an efficient and reliable way of copy-move forgery detection that increases the credibility of audio in practical forensics applications
Biologically inspired speech emotion recognition
Nov 15, 2021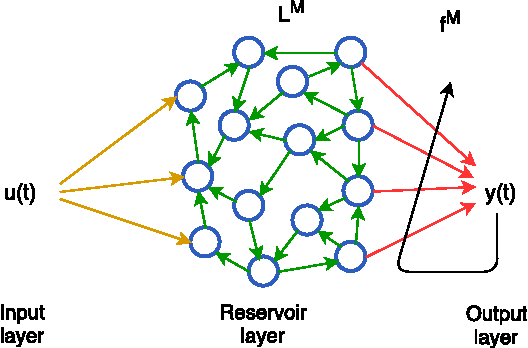
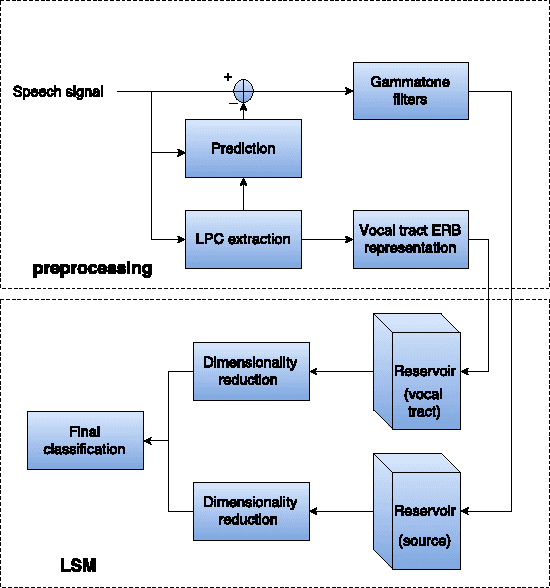
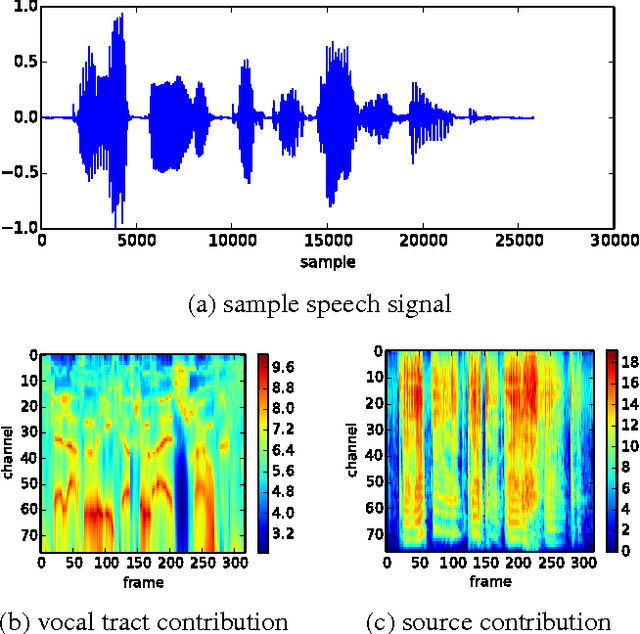
Conventional feature-based classification methods do not apply well to automatic recognition of speech emotions, mostly because the precise set of spectral and prosodic features that is required to identify the emotional state of a speaker has not been determined yet. This paper presents a method that operates directly on the speech signal, thus avoiding the problematic step of feature extraction. Furthermore, this method combines the strengths of the classical source-filter model of human speech production with those of the recently introduced liquid state machine (LSM), a biologically-inspired spiking neural network (SNN). The source and vocal tract components of the speech signal are first separated and converted into perceptually relevant spectral representations. These representations are then processed separately by two reservoirs of neurons. The output of each reservoir is reduced in dimensionality and fed to a final classifier. This method is shown to provide very good classification performance on the Berlin Database of Emotional Speech (Emo-DB). This seems a very promising framework for solving efficiently many other problems in speech processing.
MBI-Net: A Non-Intrusive Multi-Branched Speech Intelligibility Prediction Model for Hearing Aids
Apr 07, 2022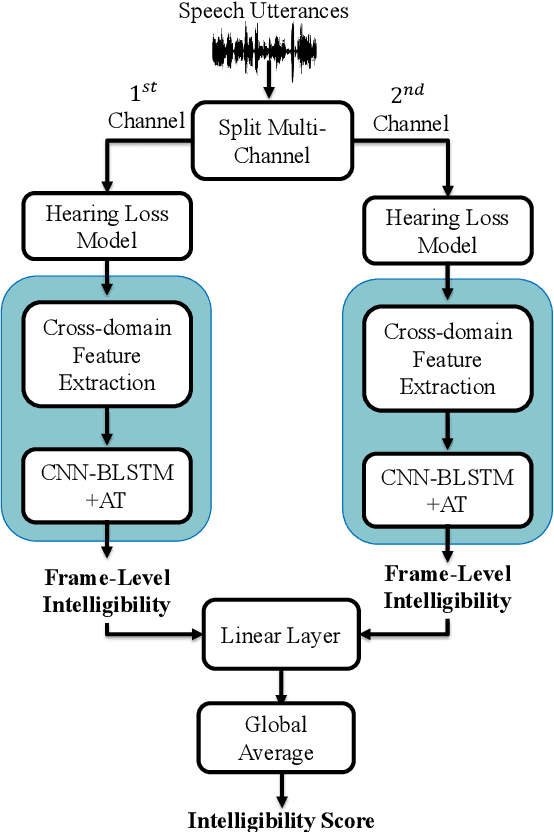
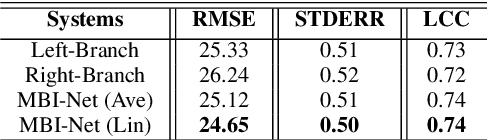
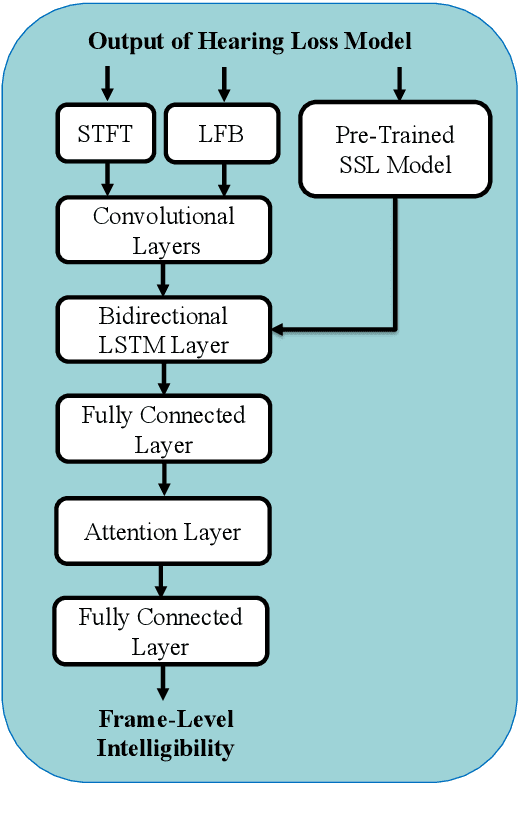
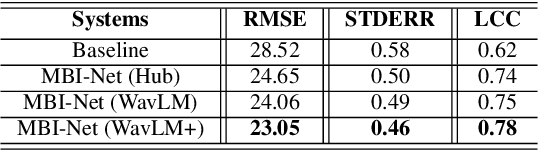
Improving the user's hearing ability to understand speech in noisy environments is critical to the development of hearing aid (HA) devices. For this, it is important to derive a metric that can fairly predict speech intelligibility for HA users. A straightforward approach is to conduct a subjective listening test and use the test results as an evaluation metric. However, conducting large-scale listening tests is time-consuming and expensive. Therefore, several evaluation metrics were derived as surrogates for subjective listening test results. In this study, we propose a multi-branched speech intelligibility prediction model (MBI-Net), for predicting the subjective intelligibility scores of HA users. MBI-Net consists of two branches of models, with each branch consisting of a hearing loss model, a cross-domain feature extraction module, and a speech intelligibility prediction model, to process speech signals from one channel. The outputs of the two branches are fused through a linear layer to obtain predicted speech intelligibility scores. Experimental results confirm the effectiveness of MBI-Net, which produces higher prediction scores than the baseline system in Track 1 and Track 2 on the Clarity Prediction Challenge 2022 dataset.
Improving Frame-Online Neural Speech Enhancement with Overlapped-Frame Prediction
Apr 15, 2022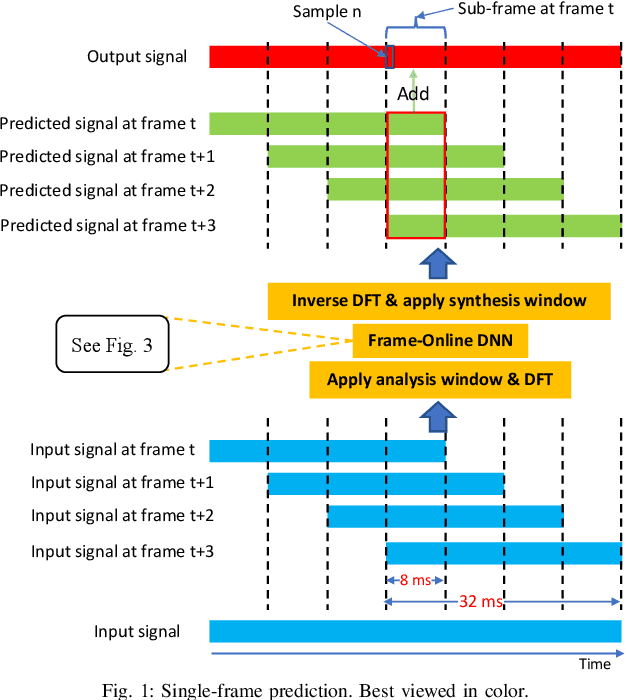
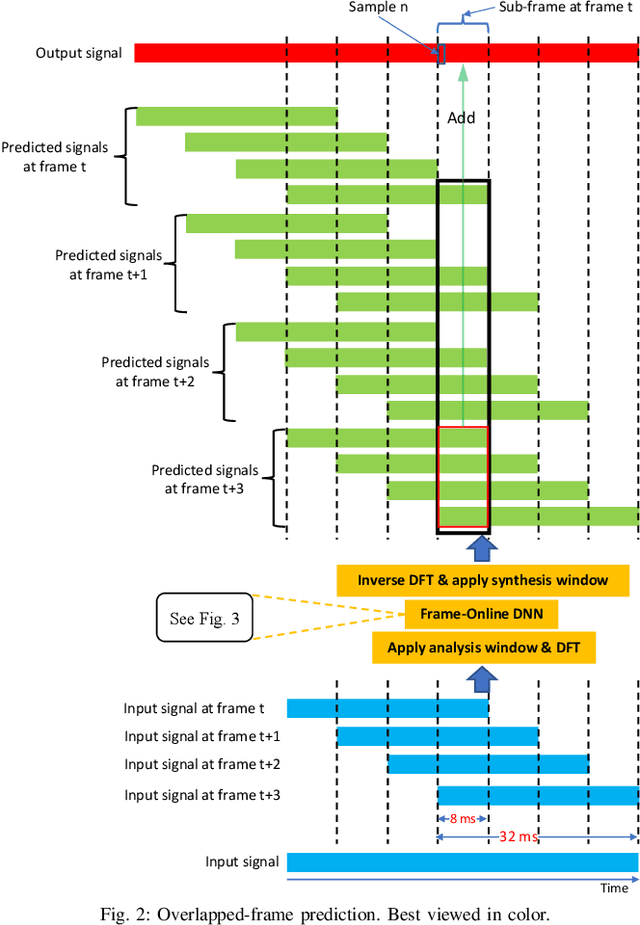
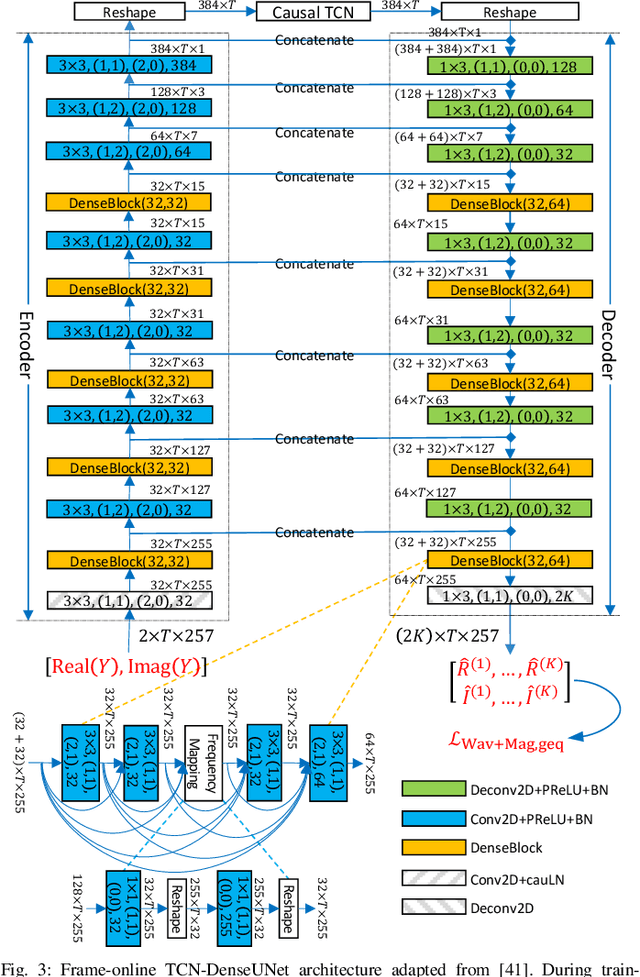
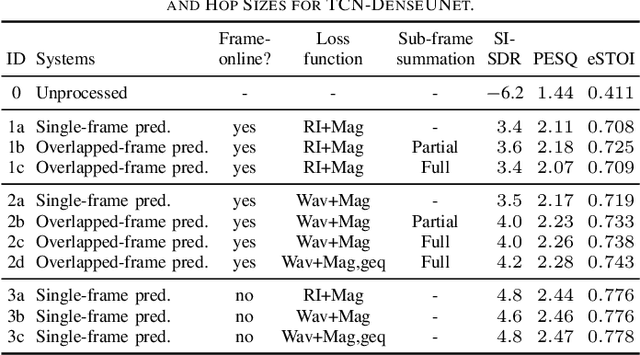
Frame-online speech enhancement systems in the short-time Fourier transform (STFT) domain usually have an algorithmic latency equal to the window size due to the use of the overlap-add algorithm in the inverse STFT (iSTFT). This algorithmic latency allows the enhancement models to leverage future contextual information up to a length equal to the window size. However, current frame-online systems only partially leverage this future information. To fully exploit this information, this study proposes an overlapped-frame prediction technique for deep learning based frame-online speech enhancement, where at each frame our deep neural network (DNN) predicts the current and several past frames that are necessary for overlap-add, instead of only predicting the current frame. In addition, we propose a novel loss function to account for the scale difference between predicted and oracle target signals. Evaluations results on a noisy-reverberant speech enhancement task show the effectiveness of the proposed algorithms.