 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Source Tracing: Detecting Voice Spoofing
Dec 16, 2022
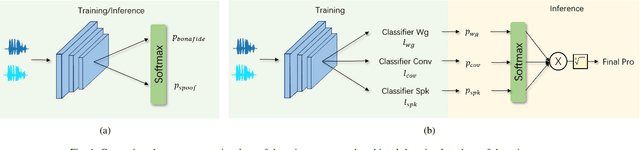
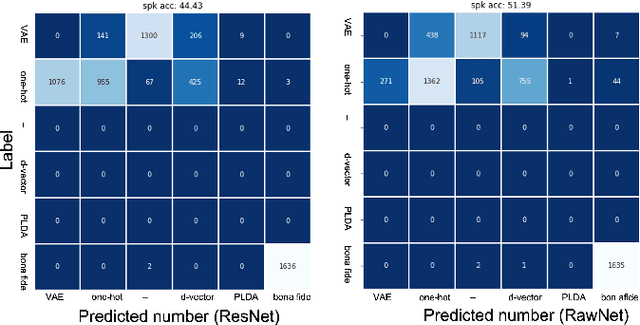
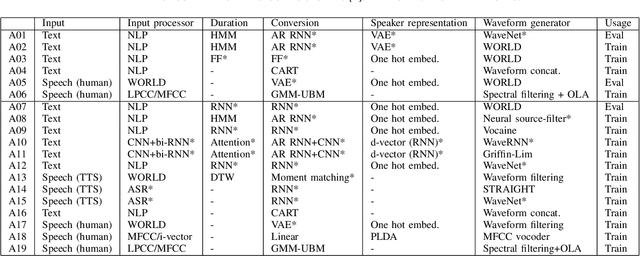
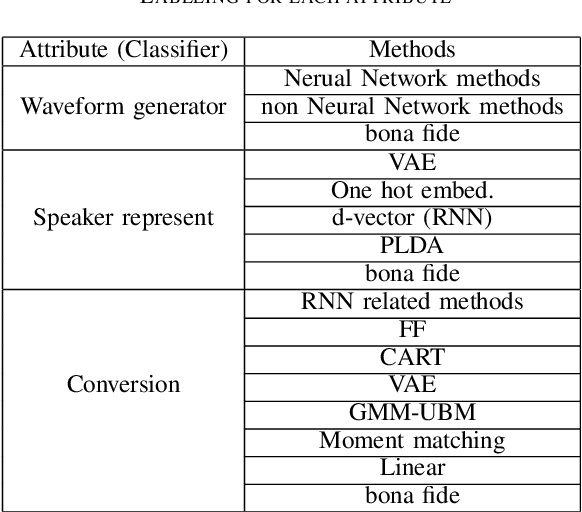
Recent anti-spoofing systems focus on spoofing detection, where the task is only to determine whether the test audio is fake. However, there are few studies putting attention to identifying the methods of generating fake speech. Common spoofing attack algorithms in the logical access (LA) scenario, such as voice conversion and speech synthesis, can be divided into several stages: input processing, conversion, waveform generation, etc. In this work, we propose a system for classifying different spoofing attributes, representing characteristics of different modules in the whole pipeline. Classifying attributes for the spoofing attack other than determining the whole spoofing pipeline can make the system more robust when encountering complex combinations of different modules at different stages. In addition, our system can also be used as an auxiliary system for anti-spoofing against unseen spoofing methods. The experiments are conducted on ASVspoof 2019 LA data set and the proposed method achieved a 20\% relative improvement against conventional binary spoof detection methods.
Emotional Prosody Control for Speech Generation
Nov 07, 2021
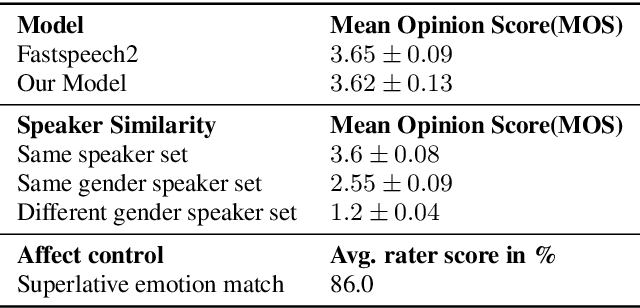
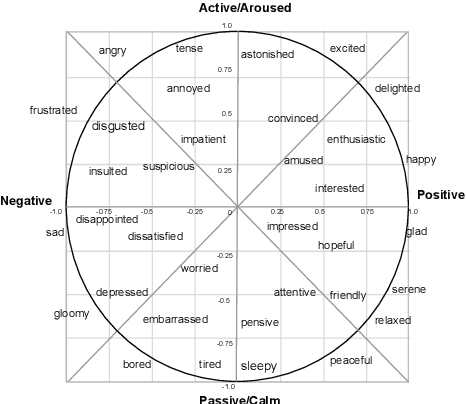
Machine-generated speech is characterized by its limited or unnatural emotional variation. Current text to speech systems generates speech with either a flat emotion, emotion selected from a predefined set, average variation learned from prosody sequences in training data or transferred from a source style. We propose a text to speech(TTS) system, where a user can choose the emotion of generated speech from a continuous and meaningful emotion space (Arousal-Valence space). The proposed TTS system can generate speech from the text in any speaker's style, with fine control of emotion. We show that the system works on emotion unseen during training and can scale to previously unseen speakers given his/her speech sample. Our work expands the horizon of the state-of-the-art FastSpeech2 backbone to a multi-speaker setting and gives it much-coveted continuous (and interpretable) affective control, without any observable degradation in the quality of the synthesized speech.
SAMO: Speaker Attractor Multi-Center One-Class Learning for Voice Anti-Spoofing
Nov 04, 2022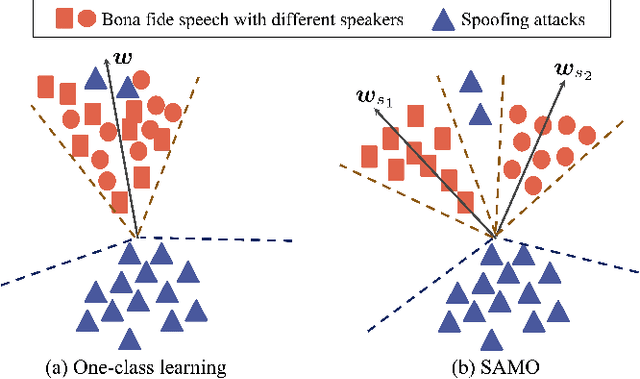
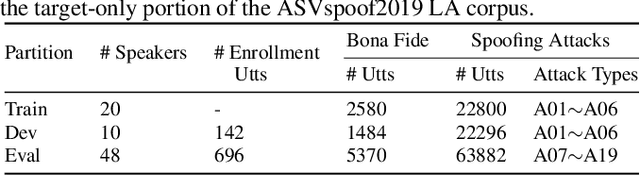
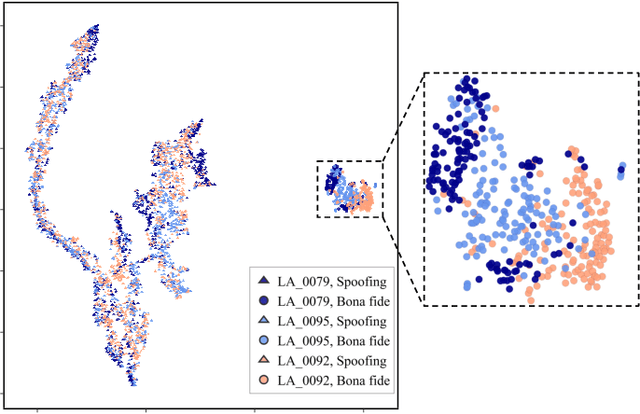
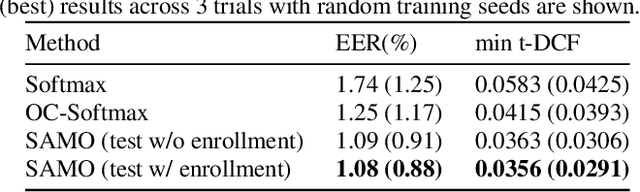
Voice anti-spoofing systems are crucial auxiliaries for automatic speaker verification (ASV) systems. A major challenge is caused by unseen attacks empowered by advanced speech synthesis technologies. Our previous research on one-class learning has improved the generalization ability to unseen attacks by compacting the bona fide speech in the embedding space. However, such compactness lacks consideration of the diversity of speakers. In this work, we propose speaker attractor multi-center one-class learning (SAMO), which clusters bona fide speech around a number of speaker attractors and pushes away spoofing attacks from all the attractors in a high-dimensional embedding space. For training, we propose an algorithm for the co-optimization of bona fide speech clustering and bona fide/spoof classification. For inference, we propose strategies to enable anti-spoofing for speakers without enrollment. Our proposed system outperforms existing state-of-the-art single systems with a relative improvement of 38% on equal error rate (EER) on the ASVspoof2019 LA evaluation set.
Automatic Pronunciation Assessment using Self-Supervised Speech Representation Learning
Apr 08, 2022
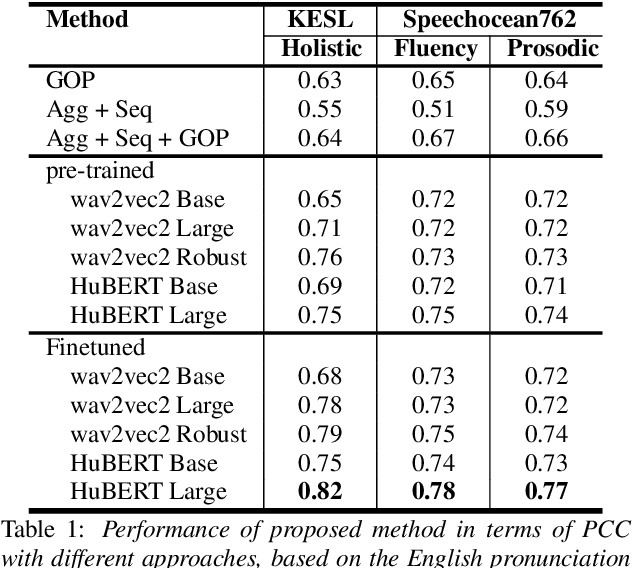

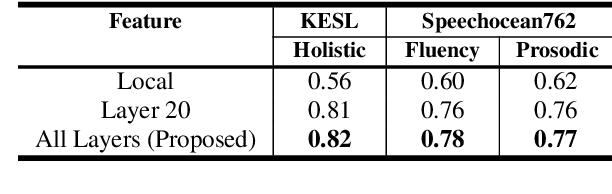
Self-supervised learning (SSL) approaches such as wav2vec 2.0 and HuBERT models have shown promising results in various downstream tasks in the speech community. In particular, speech representations learned by SSL models have been shown to be effective for encoding various speech-related characteristics. In this context, we propose a novel automatic pronunciation assessment method based on SSL models. First, the proposed method fine-tunes the pre-trained SSL models with connectionist temporal classification to adapt the English pronunciation of English-as-a-second-language (ESL) learners in a data environment. Then, the layer-wise contextual representations are extracted from all across the transformer layers of the SSL models. Finally, the automatic pronunciation score is estimated using bidirectional long short-term memory with the layer-wise contextual representations and the corresponding text. We show that the proposed SSL model-based methods outperform the baselines, in terms of the Pearson correlation coefficient, on datasets of Korean ESL learner children and Speechocean762. Furthermore, we analyze how different representations of transformer layers in the SSL model affect the performance of the pronunciation assessment task.
Subword Dictionary Learning and Segmentation Techniques for Automatic Speech Recognition in Tamil and Kannada
Jul 27, 2022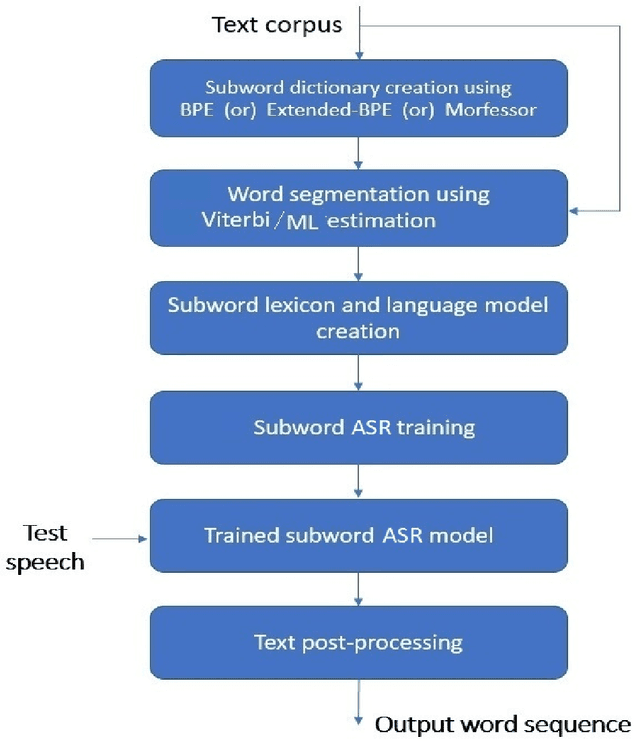
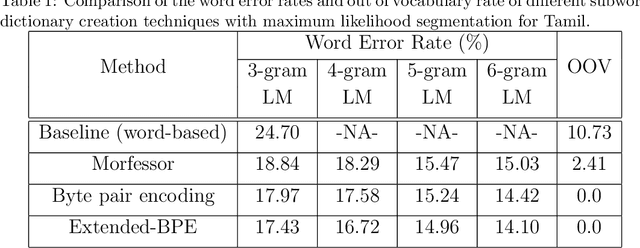
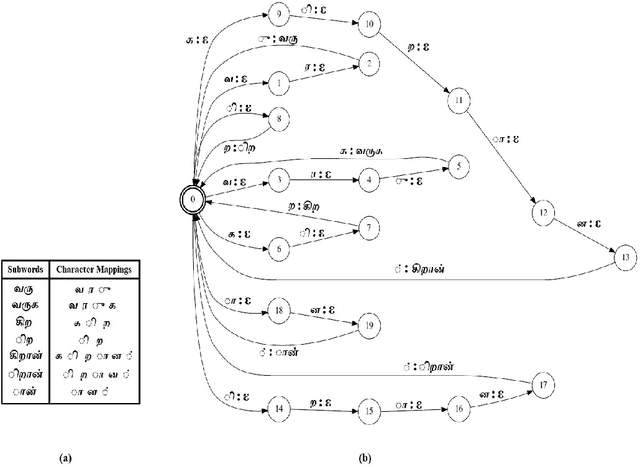
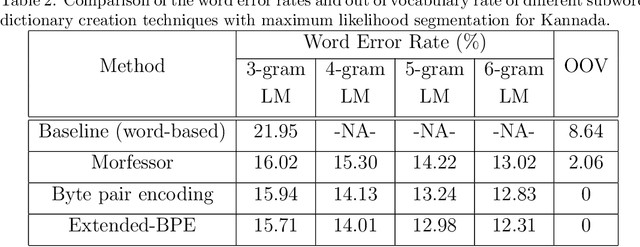
We present automatic speech recognition (ASR) systems for Tamil and Kannada based on subword modeling to effectively handle unlimited vocabulary due to the highly agglutinative nature of the languages. We explore byte pair encoding (BPE), and proposed a variant of this algorithm named extended-BPE, and Morfessor tool to segment each word as subwords. We have effectively incorporated maximum likelihood (ML) and Viterbi estimation techniques with weighted finite state transducers (WFST) framework in these algorithms to learn the subword dictionary from a large text corpus. Using the learnt subword dictionary, the words in training data transcriptions are segmented to subwords and we train deep neural network ASR systems which recognize subword sequence for any given test speech utterance. The output subword sequence is then post-processed using deterministic rules to get the final word sequence such that the actual number of words that can be recognized is much larger. For Tamil ASR, We use 152 hours of data for training and 65 hours for testing, whereas for Kannada ASR, we use 275 hours for training and 72 hours for testing. Upon experimenting with different combination of segmentation and estimation techniques, we find that the word error rate (WER) reduces drastically when compared to the baseline word-level ASR, achieving a maximum absolute WER reduction of 6.24% and 6.63% for Tamil and Kannada respectively.
Part-of-Speech Tagging of Odia Language Using statistical and Deep Learning-Based Approaches
Jul 07, 2022



Automatic Part-of-speech (POS) tagging is a preprocessing step of many natural language processing (NLP) tasks such as name entity recognition (NER), speech processing, information extraction, word sense disambiguation, and machine translation. It has already gained a promising result in English and European languages, but in Indian languages, particularly in Odia language, it is not yet well explored because of the lack of supporting tools, resources, and morphological richness of language. Unfortunately, we were unable to locate an open source POS tagger for Odia, and only a handful of attempts have been made to develop POS taggers for Odia language. The main contribution of this research work is to present a conditional random field (CRF) and deep learning-based approaches (CNN and Bidirectional Long Short-Term Memory) to develop Odia part-of-speech tagger. We used a publicly accessible corpus and the dataset is annotated with the Bureau of Indian Standards (BIS) tagset. However, most of the languages around the globe have used the dataset annotated with Universal Dependencies (UD) tagset. Hence, to maintain uniformity Odia dataset should use the same tagset. So we have constructed a simple mapping from BIS tagset to UD tagset. We experimented with various feature set inputs to the CRF model, observed the impact of constructed feature set. The deep learning-based model includes Bi-LSTM network, CNN network, CRF layer, character sequence information, and pre-trained word vector. Character sequence information was extracted by using convolutional neural network (CNN) and Bi-LSTM network. Six different combinations of neural sequence labelling models are implemented, and their performance measures are investigated. It has been observed that Bi-LSTM model with character sequence feature and pre-trained word vector achieved a significant state-of-the-art result.
AVATAR: Unconstrained Audiovisual Speech Recognition
Jun 15, 2022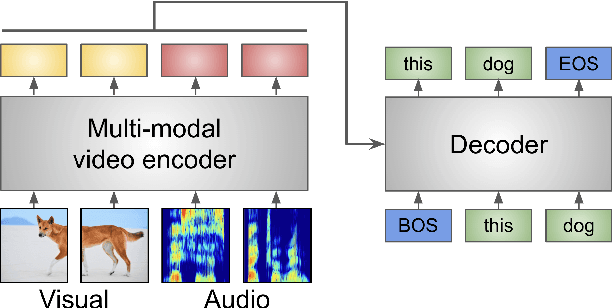
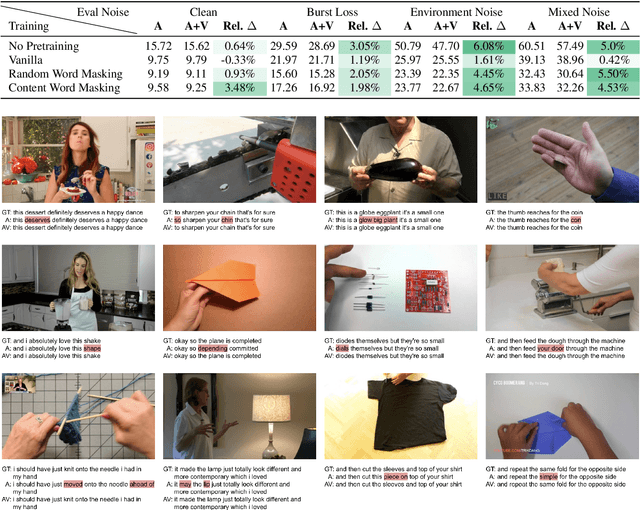
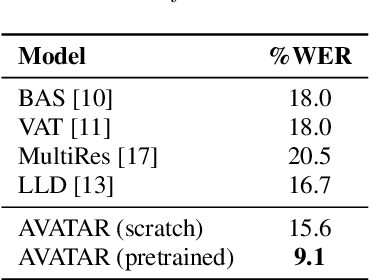
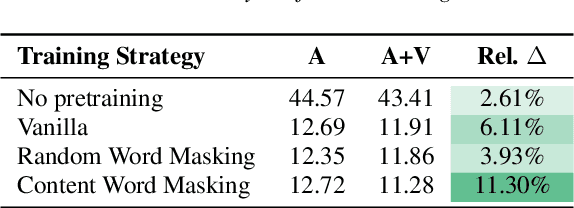
Audio-visual automatic speech recognition (AV-ASR) is an extension of ASR that incorporates visual cues, often from the movements of a speaker's mouth. Unlike works that simply focus on the lip motion, we investigate the contribution of entire visual frames (visual actions, objects, background etc.). This is particularly useful for unconstrained videos, where the speaker is not necessarily visible. To solve this task, we propose a new sequence-to-sequence AudioVisual ASR TrAnsformeR (AVATAR) which is trained end-to-end from spectrograms and full-frame RGB. To prevent the audio stream from dominating training, we propose different word-masking strategies, thereby encouraging our model to pay attention to the visual stream. We demonstrate the contribution of the visual modality on the How2 AV-ASR benchmark, especially in the presence of simulated noise, and show that our model outperforms all other prior work by a large margin. Finally, we also create a new, real-world test bed for AV-ASR called VisSpeech, which demonstrates the contribution of the visual modality under challenging audio conditions.
FFC-SE: Fast Fourier Convolution for Speech Enhancement
Apr 06, 2022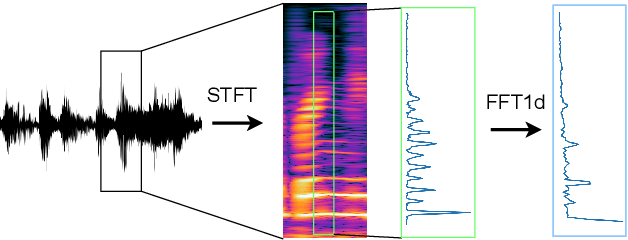
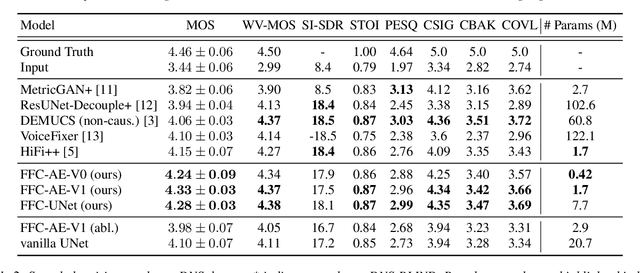
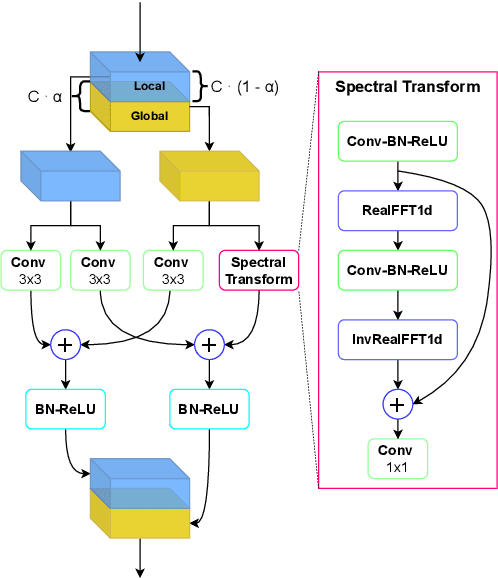
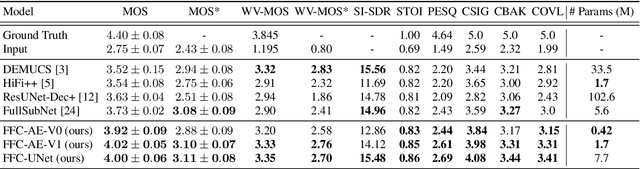
Fast Fourier convolution (FFC) is the recently proposed neural operator showing promising performance in several computer vision problems. The FFC operator allows employing large receptive field operations within early layers of the neural network. It was shown to be especially helpful for inpainting of periodic structures which are common in audio processing. In this work, we design neural network architectures which adapt FFC for speech enhancement. We hypothesize that a large receptive field allows these networks to produce more coherent phases than vanilla convolutional models, and validate this hypothesis experimentally. We found that neural networks based on Fast Fourier convolution outperform analogous convolutional models and show better or comparable results with other speech enhancement baselines.
Affective Faces for Goal-Driven Dyadic Communication
Jan 26, 2023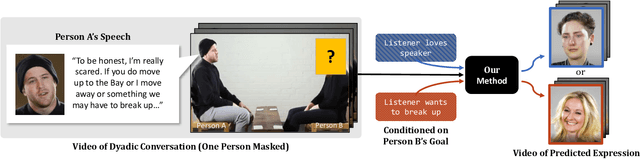
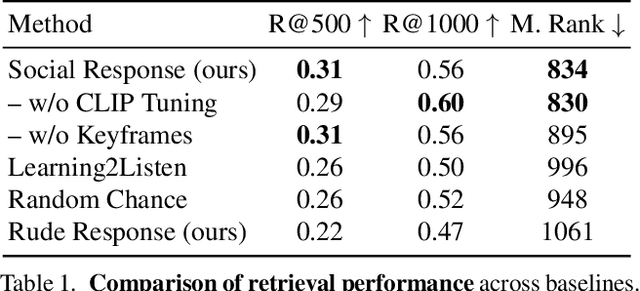
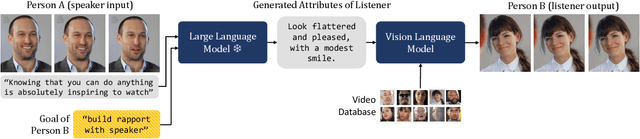

We introduce a video framework for modeling the association between verbal and non-verbal communication during dyadic conversation. Given the input speech of a speaker, our approach retrieves a video of a listener, who has facial expressions that would be socially appropriate given the context. Our approach further allows the listener to be conditioned on their own goals, personalities, or backgrounds. Our approach models conversations through a composition of large language models and vision-language models, creating internal representations that are interpretable and controllable. To study multimodal communication, we propose a new video dataset of unscripted conversations covering diverse topics and demographics. Experiments and visualizations show our approach is able to output listeners that are significantly more socially appropriate than baselines. However, many challenges remain, and we release our dataset publicly to spur further progress. See our website for video results, data, and code: https://realtalk.cs.columbia.edu.
Federated Self-supervised Speech Representations: Are We There Yet?
Apr 06, 2022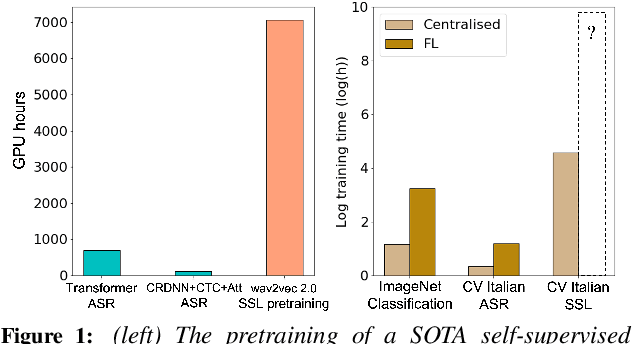
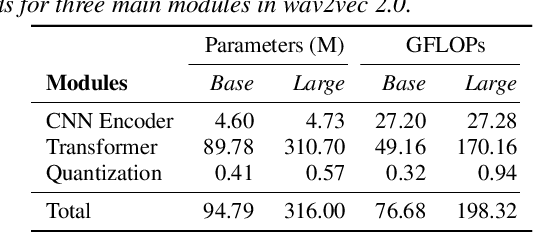
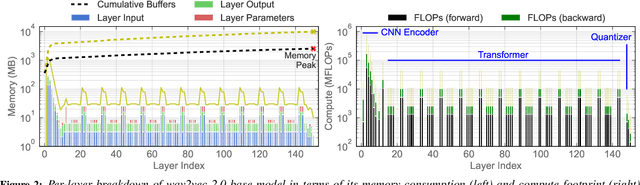
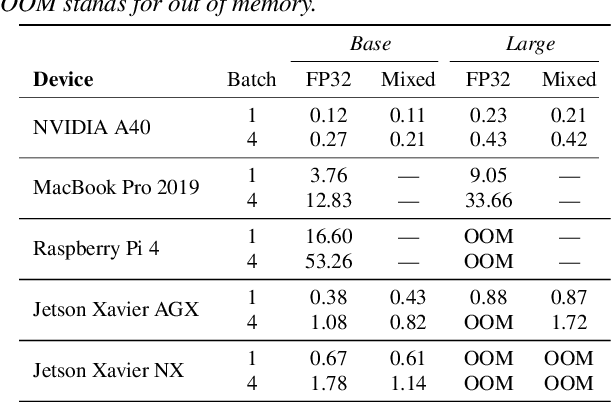
The ubiquity of microphone-enabled devices has lead to large amounts of unlabelled audio data being produced at the edge. The integration of self-supervised learning (SSL) and federated learning (FL) into one coherent system can potentially offer data privacy guarantees while also advancing the quality and robustness of speech representations. In this paper, we provide a first-of-its-kind systematic study of the feasibility and complexities for training speech SSL models under FL scenarios from the perspective of algorithms, hardware, and systems limits. Despite the high potential of their combination, we find existing system constraints and algorithmic behaviour make SSL and FL systems nearly impossible to build today. Yet critically, our results indicate specific performance bottlenecks and research opportunities that would allow this situation to be reversed. While our analysis suggests that, given existing trends in hardware, hybrid SSL and FL speech systems will not be viable until 2027. We believe this study can act as a roadmap to accelerate work towards reaching this milestone much earlier.