 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Chain of Explanation: New Prompting Method to Generate Higher Quality Natural Language Explanation for Implicit Hate Speech
Sep 11, 2022
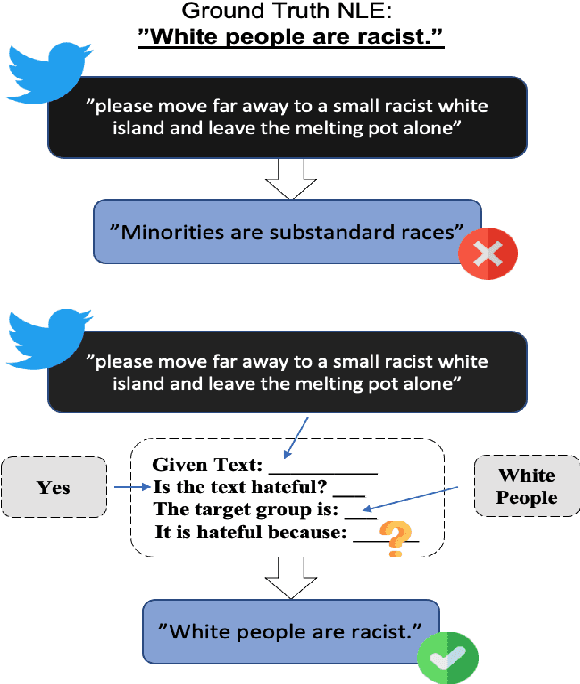

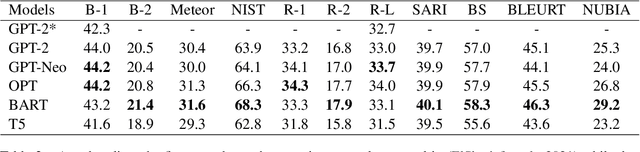

Recent studies have exploited advanced generative language models to generate Natural Language Explanations (NLE) for why a certain text could be hateful. We propose the Chain of Explanation Prompting method, inspired by the chain of thoughts study \cite{wei2022chain}, to generate high-quality NLE for implicit hate speech. We build a benchmark based on the selected mainstream Pre-trained Language Models (PLMs), including GPT-2, GPT-Neo, OPT, T5, and BART, with various evaluation metrics from lexical, semantic, and faithful aspects. To further evaluate the quality of the generated NLE from human perceptions, we hire human annotators to score the informativeness and clarity of the generated NLE. Then, we inspect which automatic evaluation metric could be best correlated with the human-annotated informativeness and clarity metric scores.
A comparative study between linear and nonlinear speech prediction
Mar 31, 2022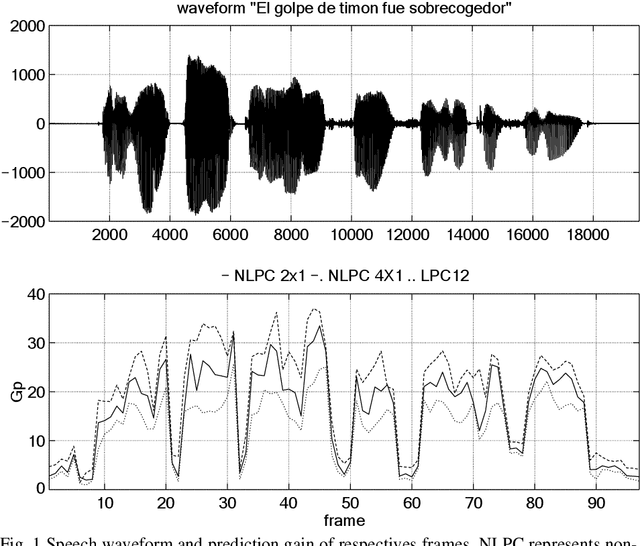
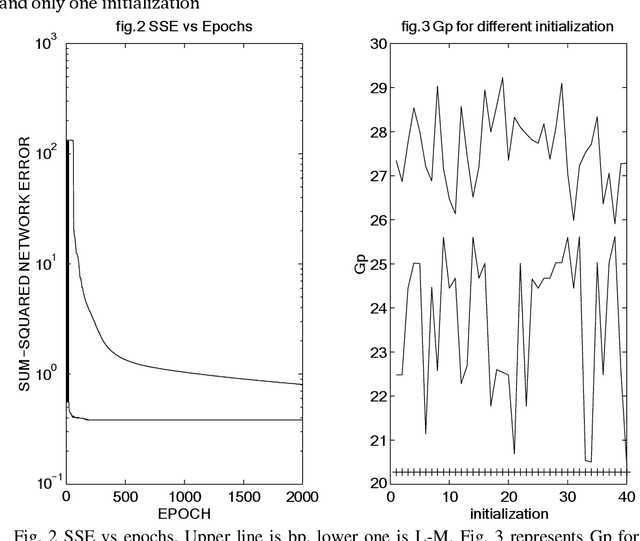
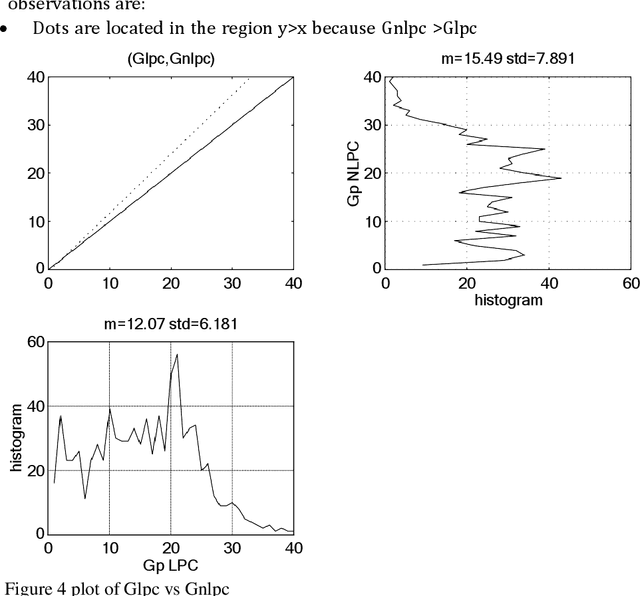
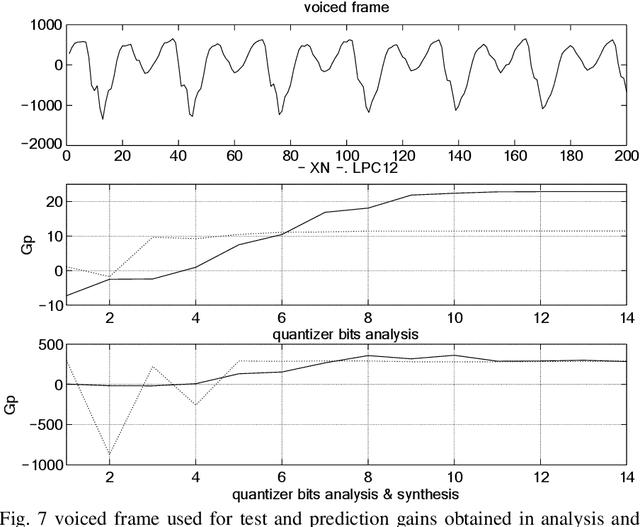
This paper is focused on nonlinear prediction coding, which consists on the prediction of a speech sample based on a nonlinear combination of previous samples. It is known that in the generation of the glottal pulse, the wave equation does not behave linearly [2], [10], and we model these effects by means of a nonlinear prediction of speech based on a parametric neural network model. This work is centred on the neural net weight's quantization and on the compression gain.
* 11 pages, published in Mira, J., Moreno-D\'iaz, R., Cabestany, J. (eds) Biological and Artificial Computation: From Neuroscience to Technology. IWANN 1997. Lecture Notes in Computer Science, vol 1240. Springer, Berlin, Heidelberg
Hearing voices at the National Library -- a speech corpus and acoustic model for the Swedish language
May 19, 2022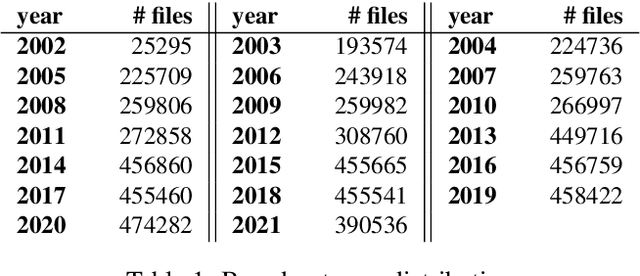
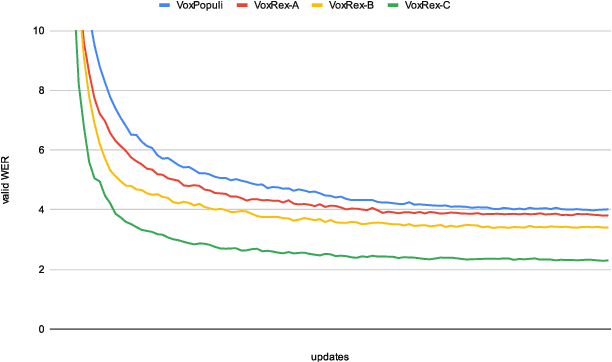
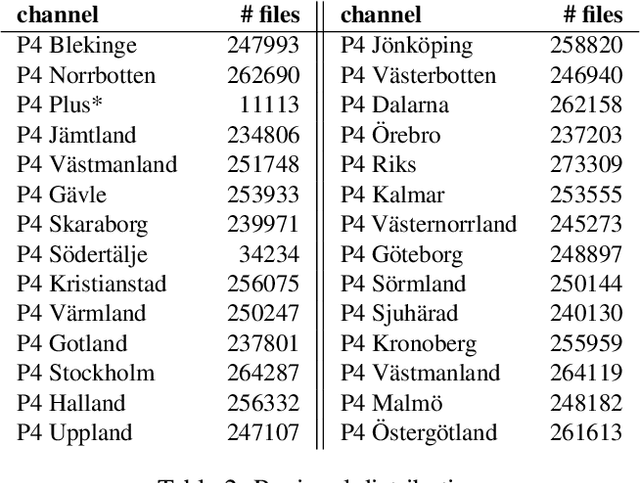
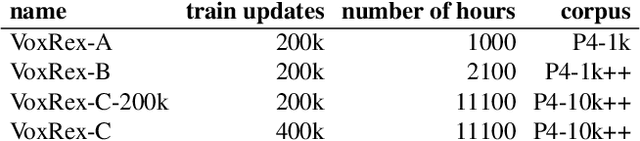
This paper explains our work in developing new acoustic models for automated speech recognition (ASR) at KBLab, the infrastructure for data-driven research at the National Library of Sweden (KB). We evaluate different approaches for a viable speech-to-text pipeline for audiovisual resources in Swedish, using the wav2vec 2.0 architecture in combination with speech corpuses created from KB's collections. These approaches include pretraining an acoustic model for Swedish from the ground up, and fine-tuning existing monolingual and multilingual models. The collections-based corpuses we use have been sampled from millions of hours of speech, with a conscious attempt to balance regional dialects to produce a more representative, and thus more democratic, model. The acoustic model this enabled, "VoxRex", outperforms existing models for Swedish ASR. We also evaluate combining this model with various pretrained language models, which further enhanced performance. We conclude by highlighting the potential of such technology for cultural heritage institutions with vast collections of previously unlabelled audiovisual data. Our models are released for further exploration and research here: https://huggingface.co/KBLab.
Emotional Prosody Control for Speech Generation
Nov 07, 2021
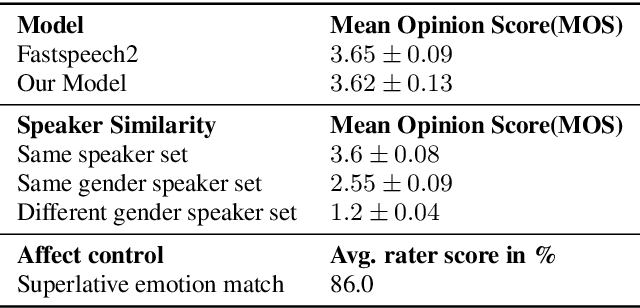
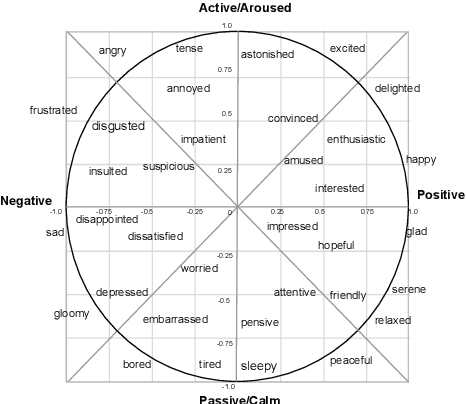
Machine-generated speech is characterized by its limited or unnatural emotional variation. Current text to speech systems generates speech with either a flat emotion, emotion selected from a predefined set, average variation learned from prosody sequences in training data or transferred from a source style. We propose a text to speech(TTS) system, where a user can choose the emotion of generated speech from a continuous and meaningful emotion space (Arousal-Valence space). The proposed TTS system can generate speech from the text in any speaker's style, with fine control of emotion. We show that the system works on emotion unseen during training and can scale to previously unseen speakers given his/her speech sample. Our work expands the horizon of the state-of-the-art FastSpeech2 backbone to a multi-speaker setting and gives it much-coveted continuous (and interpretable) affective control, without any observable degradation in the quality of the synthesized speech.
WaBERT: A Low-resource End-to-end Model for Spoken Language Understanding and Speech-to-BERT Alignment
Apr 22, 2022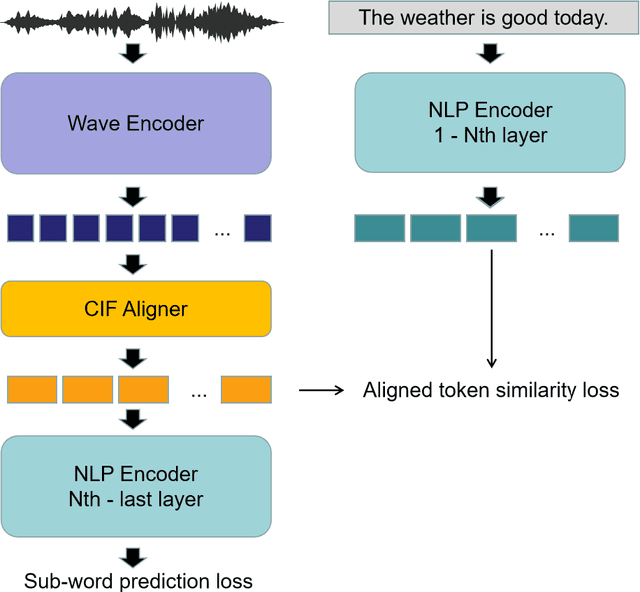


Historically lower-level tasks such as automatic speech recognition (ASR) and speaker identification are the main focus in the speech field. Interest has been growing in higher-level spoken language understanding (SLU) tasks recently, like sentiment analysis (SA). However, improving performances on SLU tasks remains a big challenge. Basically, there are two main methods for SLU tasks: (1) Two-stage method, which uses a speech model to transfer speech to text, then uses a language model to get the results of downstream tasks; (2) One-stage method, which just fine-tunes a pre-trained speech model to fit in the downstream tasks. The first method loses emotional cues such as intonation, and causes recognition errors during ASR process, and the second one lacks necessary language knowledge. In this paper, we propose the Wave BERT (WaBERT), a novel end-to-end model combining the speech model and the language model for SLU tasks. WaBERT is based on the pre-trained speech and language model, hence training from scratch is not needed. We also set most parameters of WaBERT frozen during training. By introducing WaBERT, audio-specific information and language knowledge are integrated in the short-time and low-resource training process to improve results on the dev dataset of SLUE SA tasks by 1.15% of recall score and 0.82% of F1 score. Additionally, we modify the serial Continuous Integrate-and-Fire (CIF) mechanism to achieve the monotonic alignment between the speech and text modalities.
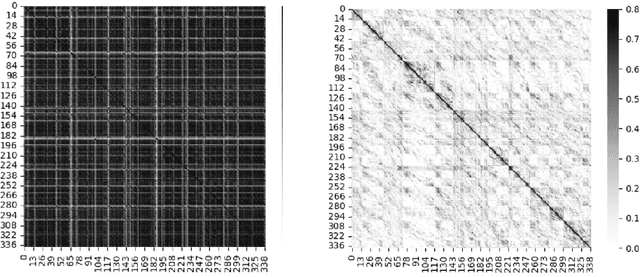
Exploring Attention Map Reuse for Efficient Transformer Neural Networks
Jan 29, 2023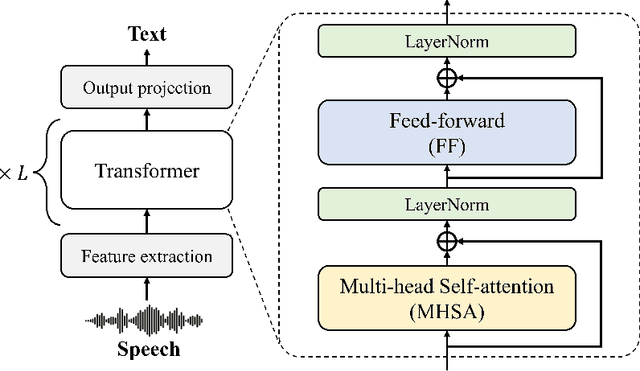
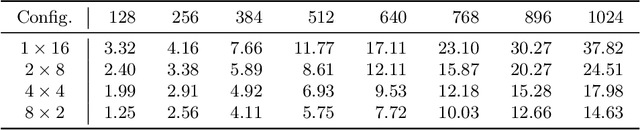
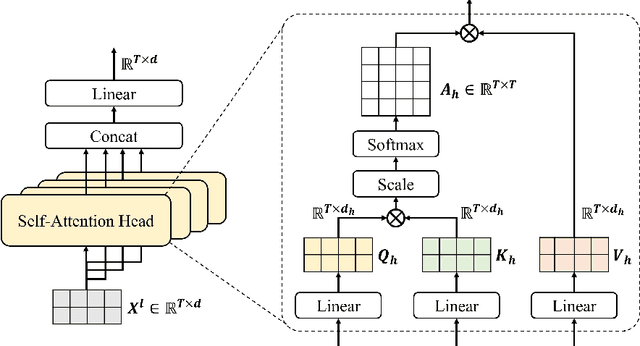
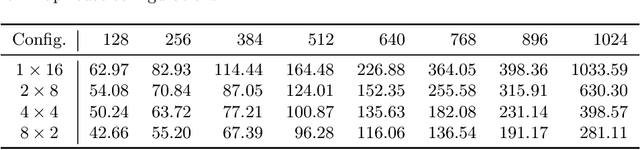
Transformer-based deep neural networks have achieved great success in various sequence applications due to their powerful ability to model long-range dependency. The key module of Transformer is self-attention (SA) which extracts features from the entire sequence regardless of the distance between positions. Although SA helps Transformer performs particularly well on long-range tasks, SA requires quadratic computation and memory complexity with the input sequence length. Recently, attention map reuse, which groups multiple SA layers to share one attention map, has been proposed and achieved significant speedup for speech recognition models. In this paper, we provide a comprehensive study on attention map reuse focusing on its ability to accelerate inference. We compare the method with other SA compression techniques and conduct a breakdown analysis of its advantages for a long sequence. We demonstrate the effectiveness of attention map reuse by measuring the latency on both CPU and GPU platforms.
Automatic Pronunciation Assessment using Self-Supervised Speech Representation Learning
Apr 08, 2022
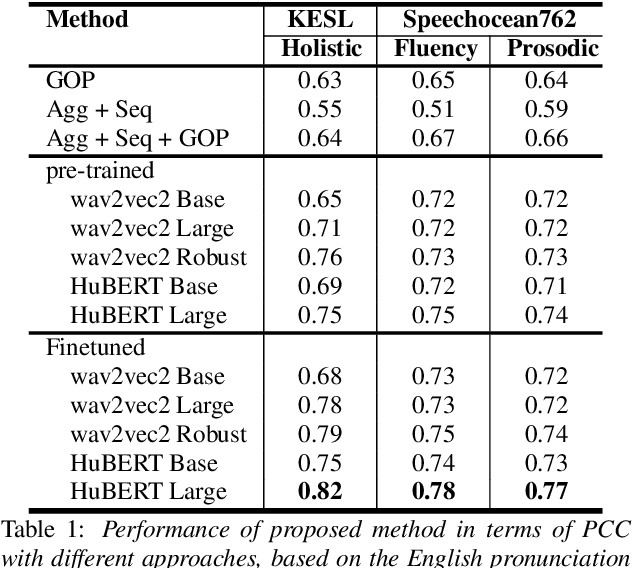

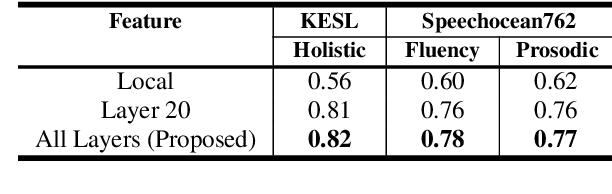
Self-supervised learning (SSL) approaches such as wav2vec 2.0 and HuBERT models have shown promising results in various downstream tasks in the speech community. In particular, speech representations learned by SSL models have been shown to be effective for encoding various speech-related characteristics. In this context, we propose a novel automatic pronunciation assessment method based on SSL models. First, the proposed method fine-tunes the pre-trained SSL models with connectionist temporal classification to adapt the English pronunciation of English-as-a-second-language (ESL) learners in a data environment. Then, the layer-wise contextual representations are extracted from all across the transformer layers of the SSL models. Finally, the automatic pronunciation score is estimated using bidirectional long short-term memory with the layer-wise contextual representations and the corresponding text. We show that the proposed SSL model-based methods outperform the baselines, in terms of the Pearson correlation coefficient, on datasets of Korean ESL learner children and Speechocean762. Furthermore, we analyze how different representations of transformer layers in the SSL model affect the performance of the pronunciation assessment task.
Tragic and Comical Networks. Clustering Dramatic Genres According to Structural Properties
Feb 16, 2023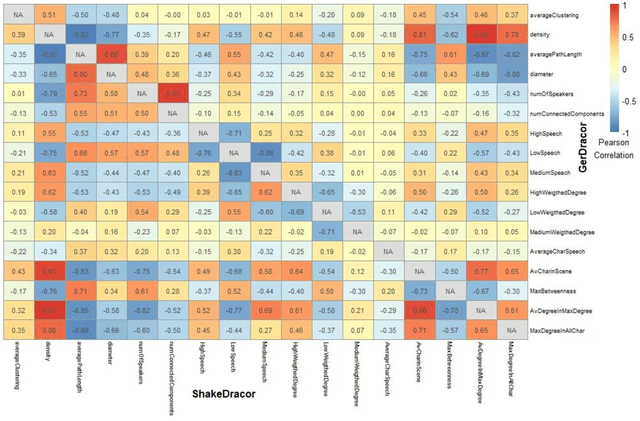
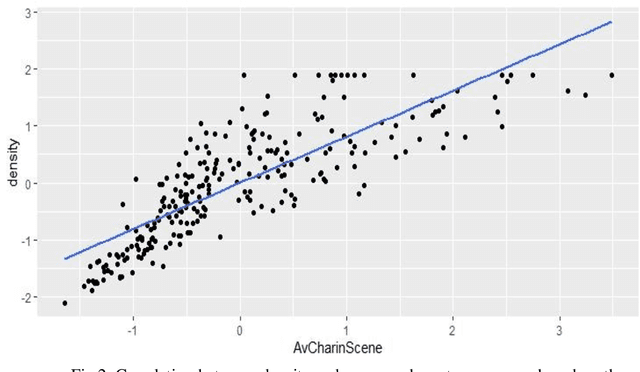
There is a growing tradition in the joint field of network studies and drama history that produces interpretations from the character networks of the plays.The potential of such an interpretation is that the diagrams provide a different representation of the relationships between characters as compared to reading the text or watching the performance. Our aim is to create a method that is able to cluster texts with similar structures on the basis of the play's well-interpretable and simple properties, independent from the number of characters in the drama, or in other words, the size of the network. Finding these features is the most important part of our research, as well as establishing the appropriate statistical procedure to calculate the similarities between the texts. Our data was downloaded from the DraCor database and analyzed in R (we use the GerDracor and the ShakeDraCor sub-collection). We want to propose a robust method based on the distribution of words among characters; distribution of characters in scenes, average length of speech acts, or character-specific and macro-level network properties such as clusterization coefficient and network density. Based on these metrics a supervised classification procedure is applied to the sub-collections to classify comedies and tragedies using the Support Vector Machine (SVM) method. Our research shows that this approach can also produce reliable results on a small sample size.
GeneFace: Generalized and High-Fidelity Audio-Driven 3D Talking Face Synthesis
Jan 31, 2023
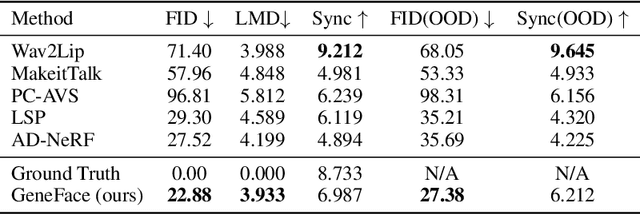
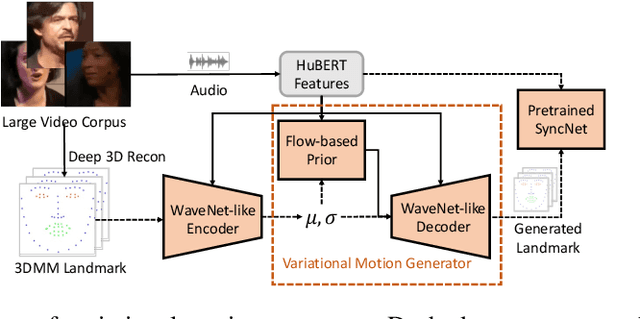

Generating photo-realistic video portrait with arbitrary speech audio is a crucial problem in film-making and virtual reality. Recently, several works explore the usage of neural radiance field in this task to improve 3D realness and image fidelity. However, the generalizability of previous NeRF-based methods to out-of-domain audio is limited by the small scale of training data. In this work, we propose GeneFace, a generalized and high-fidelity NeRF-based talking face generation method, which can generate natural results corresponding to various out-of-domain audio. Specifically, we learn a variaitional motion generator on a large lip-reading corpus, and introduce a domain adaptative post-net to calibrate the result. Moreover, we learn a NeRF-based renderer conditioned on the predicted facial motion. A head-aware torso-NeRF is proposed to eliminate the head-torso separation problem. Extensive experiments show that our method achieves more generalized and high-fidelity talking face generation compared to previous methods.
A benchmark for toxic comment classification on Civil Comments dataset
Jan 26, 2023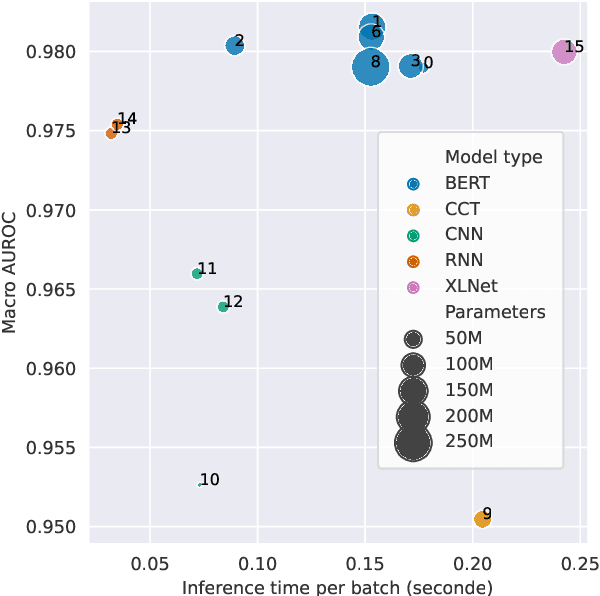
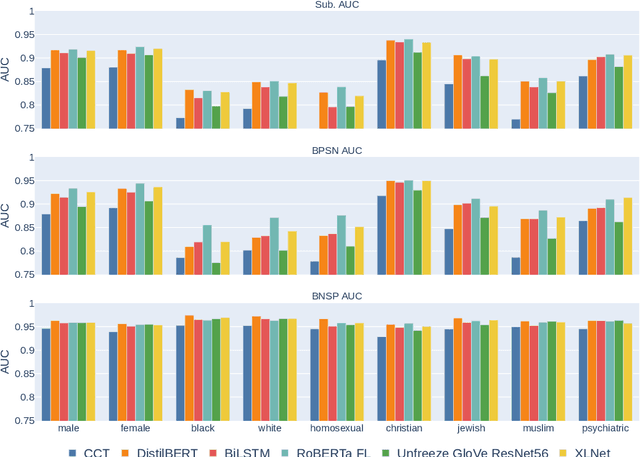
Toxic comment detection on social media has proven to be essential for content moderation. This paper compares a wide set of different models on a highly skewed multi-label hate speech dataset. We consider inference time and several metrics to measure performance and bias in our comparison. We show that all BERTs have similar performance regardless of the size, optimizations or language used to pre-train the models. RNNs are much faster at inference than any of the BERT. BiLSTM remains a good compromise between performance and inference time. RoBERTa with Focal Loss offers the best performance on biases and AUROC. However, DistilBERT combines both good AUROC and a low inference time. All models are affected by the bias of associating identities. BERT, RNN, and XLNet are less sensitive than the CNN and Compact Convolutional Transformers.