 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Auditory-Based Data Augmentation for End-to-End Automatic Speech Recognition
Apr 08, 2022


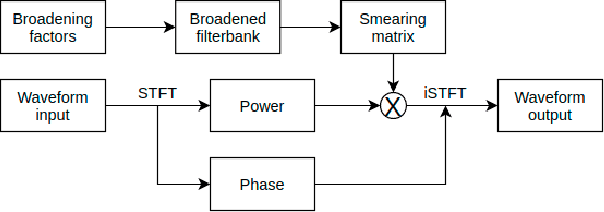
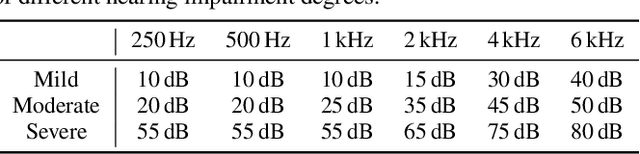
End-to-end models have achieved significant improvement on automatic speech recognition. One common method to improve performance of these models is expanding the data-space through data augmentation. Meanwhile, human auditory inspired front-ends have also demonstrated improvement for automatic speech recognisers. In this work, a well-verified auditory-based model, which can simulate various hearing abilities, is investigated for the purpose of data augmentation for end-to-end speech recognition. By introducing the auditory model into the data augmentation process, end-to-end systems are encouraged to ignore variation from the signal that cannot be heard and thereby focus on robust features for speech recognition. Two mechanisms in the auditory model, spectral smearing and loudness recruitment, are studied on the LibriSpeech dataset with a transformer-based end-to-end model. The results show that the proposed augmentation methods can bring statistically significant improvement on the performance of the state-of-the-art SpecAugment.
Improved Consistency Training for Semi-Supervised Sequence-to-Sequence ASR via Speech Chain Reconstruction and Self-Transcribing
May 14, 2022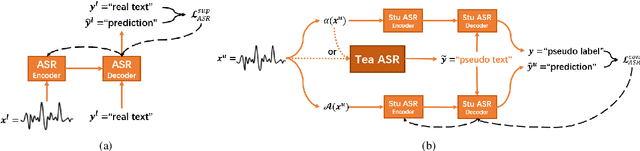
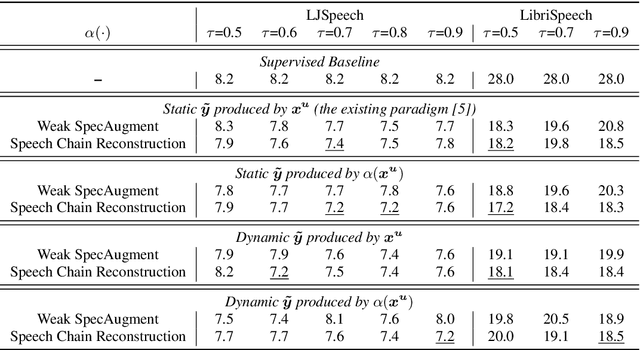
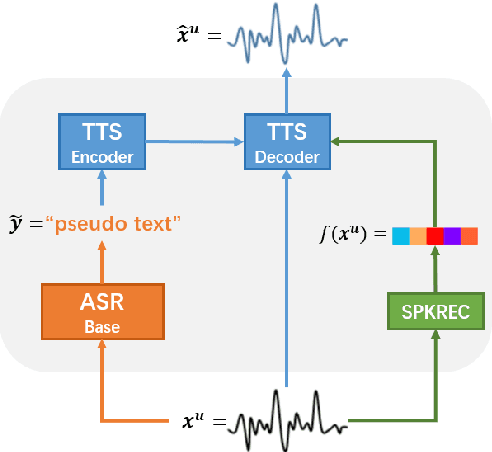
Consistency regularization has recently been applied to semi-supervised sequence-to-sequence (S2S) automatic speech recognition (ASR). This principle encourages an ASR model to output similar predictions for the same input speech with different perturbations. The existing paradigm of semi-supervised S2S ASR utilizes SpecAugment as data augmentation and requires a static teacher model to produce pseudo transcripts for untranscribed speech. However, this paradigm fails to take full advantage of consistency regularization. First, the masking operations of SpecAugment may damage the linguistic contents of the speech, thus influencing the quality of pseudo labels. Second, S2S ASR requires both input speech and prefix tokens to make the next prediction. The static prefix tokens made by the offline teacher model cannot match dynamic pseudo labels during consistency training. In this work, we propose an improved consistency training paradigm of semi-supervised S2S ASR. We utilize speech chain reconstruction as the weak augmentation to generate high-quality pseudo labels. Moreover, we demonstrate that dynamic pseudo transcripts produced by the student ASR model benefit the consistency training. Experiments on LJSpeech and LibriSpeech corpora show that compared to supervised baselines, our improved paradigm achieves a 12.2% CER improvement in the single-speaker setting and 38.6% in the multi-speaker setting.
Fast Blind Audio Copy-Move Detection and Localization Using Local Feature Tensors in Noise
Feb 15, 2023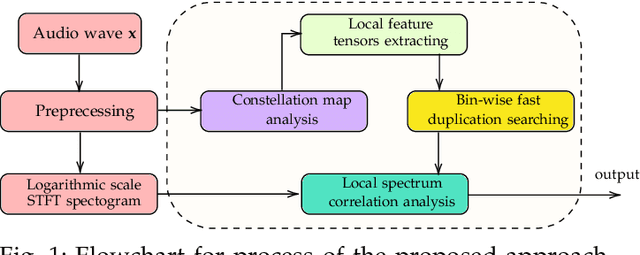
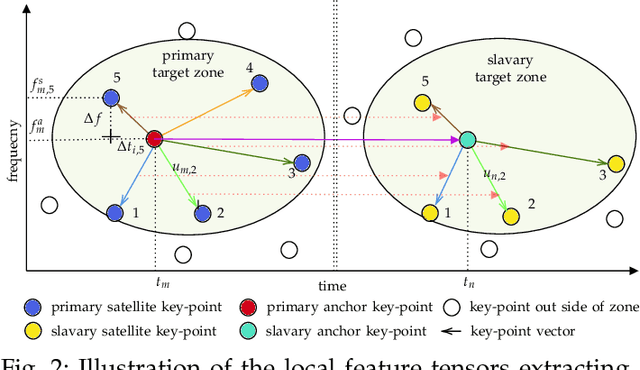
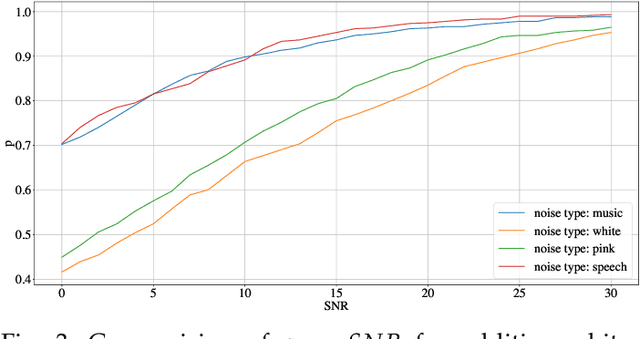
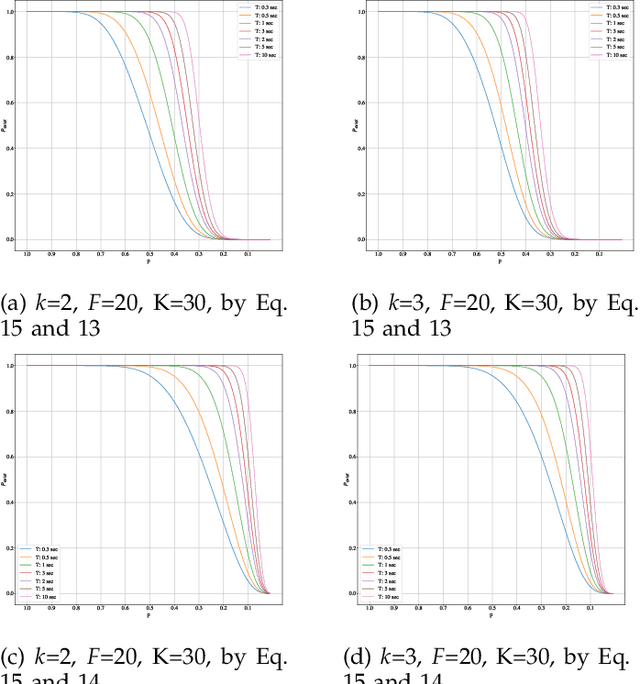
The increasing availability of audio editing software altering digital audios and their ease of use allows create forgeries at low cost. A copy-move forgery (CMF) is one of easiest and popular audio forgeries, which created by copying and pasting audio segments within the same audio, and potentially post-processing it. Three main approaches to audio copy-move detection exist nowadays: samples/frames comparison, acoustic features coherence searching and dynamic time warping. But these approaches will suffer from computational complexity and/or sensitive to noise and post-processing. In this paper, we propose a new local feature tensors-based copy-move detection algorithm that can be applied to transformed duplicates detection and localization problem to a special locality sensitive hash like procedure. The experimental results with massive online real-time audios datasets reveal that the proposed technique effectively determines and locating copy-move forgeries even on a forged speech segment are as short as fractional second. This method is also computational efficient and robust against the audios processed with severe nonlinear transformation, such as resampling, filtering, jsittering, compression and cropping, even contaminated with background noise and music. Hence, the proposed technique provides an efficient and reliable way of copy-move forgery detection that increases the credibility of audio in practical forensics applications
Improving Cross-lingual Speech Synthesis with Triplet Training Scheme
Feb 22, 2022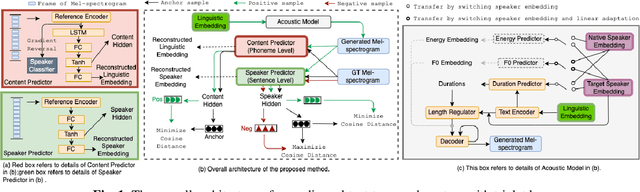
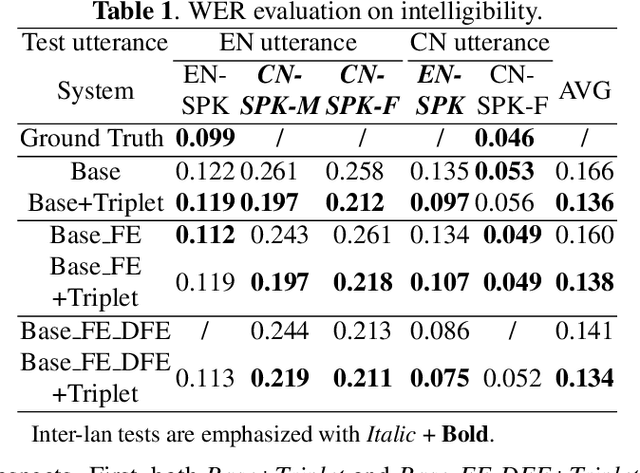
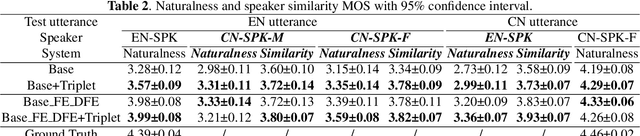
Recent advances in cross-lingual text-to-speech (TTS) made it possible to synthesize speech in a language foreign to a monolingual speaker. However, there is still a large gap between the pronunciation of generated cross-lingual speech and that of native speakers in terms of naturalness and intelligibility. In this paper, a triplet training scheme is proposed to enhance the cross-lingual pronunciation by allowing previously unseen content and speaker combinations to be seen during training. Proposed method introduces an extra fine-tune stage with triplet loss during training, which efficiently draws the pronunciation of the synthesized foreign speech closer to those from the native anchor speaker, while preserving the non-native speaker's timbre. Experiments are conducted based on a state-of-the-art baseline cross-lingual TTS system and its enhanced variants. All the objective and subjective evaluations show the proposed method brings significant improvement in both intelligibility and naturalness of the synthesized cross-lingual speech.
Towards Multi-Scale Speaking Style Modelling with Hierarchical Context Information for Mandarin Speech Synthesis
Apr 06, 2022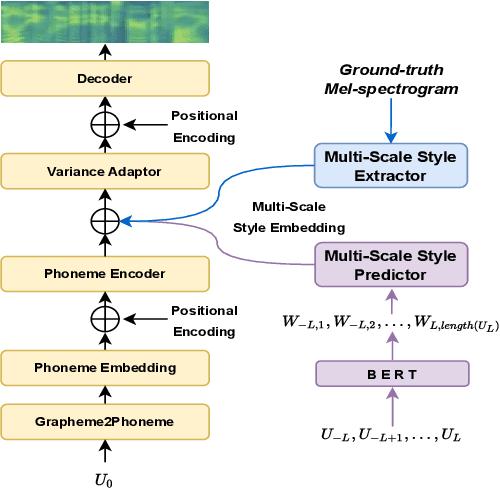
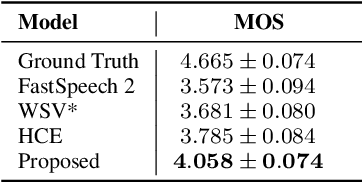
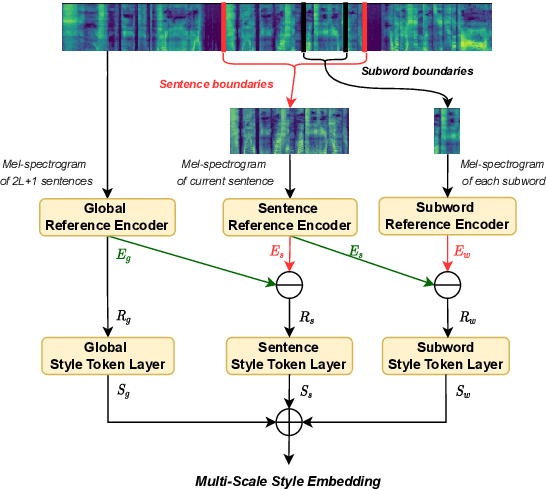
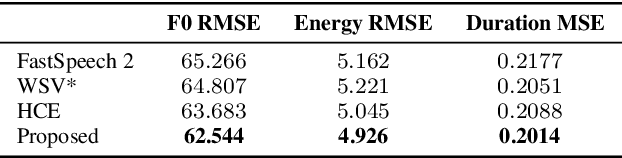
Previous works on expressive speech synthesis focus on modelling the mono-scale style embedding from the current sentence or context, but the multi-scale nature of speaking style in human speech is neglected. In this paper, we propose a multi-scale speaking style modelling method to capture and predict multi-scale speaking style for improving the naturalness and expressiveness of synthetic speech. A multi-scale extractor is proposed to extract speaking style embeddings at three different levels from the ground-truth speech, and explicitly guide the training of a multi-scale style predictor based on hierarchical context information. Both objective and subjective evaluations on a Mandarin audiobooks dataset demonstrate that our proposed method can significantly improve the naturalness and expressiveness of the synthesized speech.
Applying Automated Machine Translation to Educational Video Courses
Jan 09, 2023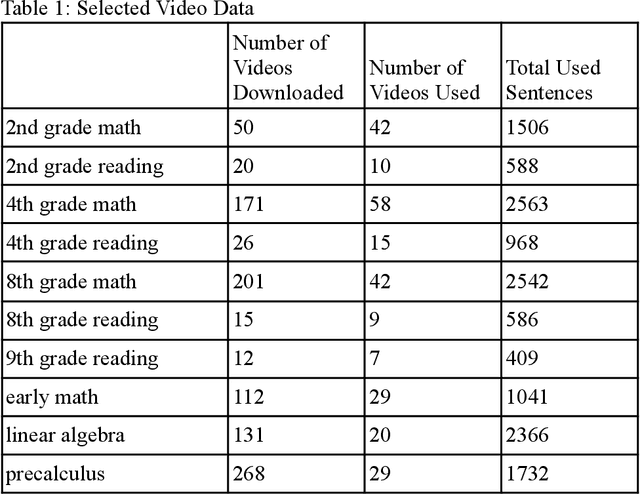
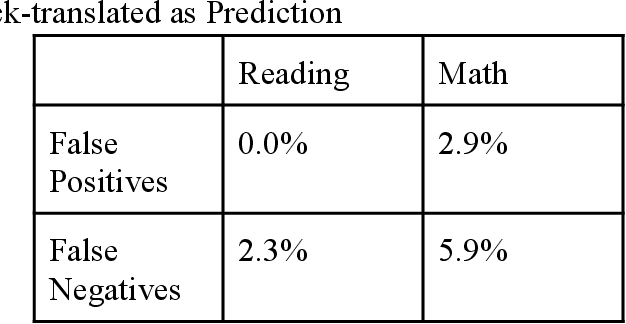
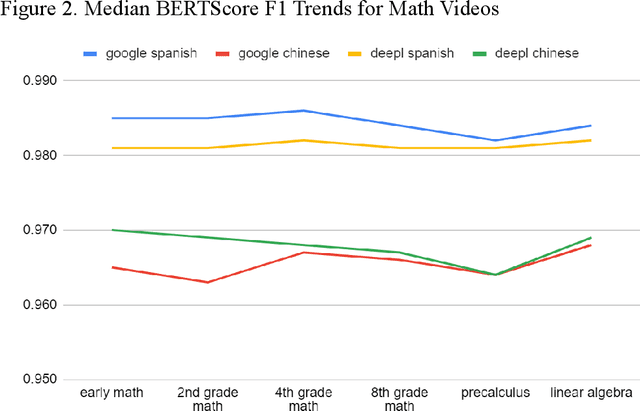
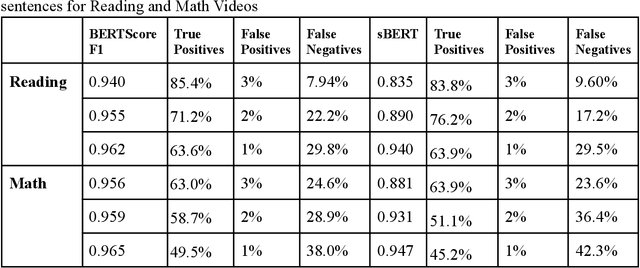
We studied the capability of automated machine translation in the online video education space by automatically translating Khan Academy videos with state of the art translation models and applying Text-to-Speech synthesis to build engaging videos in target languages. We also analyzed and established a reliable translation confidence estimator based on round-trip translations in order to efficiently manage translation quality and reduce human translation effort. Finally, we developed a deployable system to deliver translated videos to end users and collect user corrections for iterative improvement.
VLSP2022 EVJVQA Challenge: Multilingual Visual Question Answering
Feb 24, 2023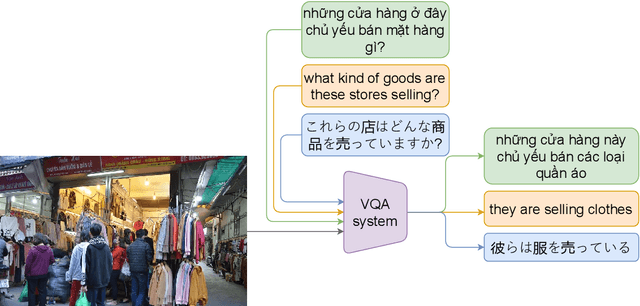
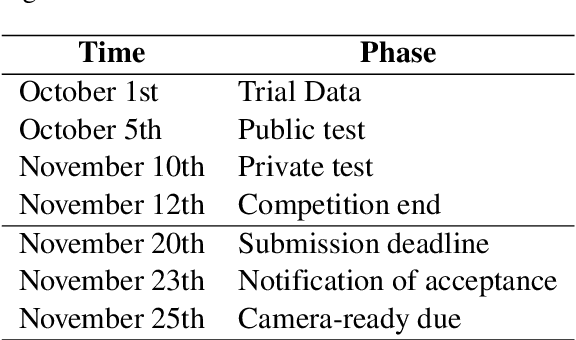

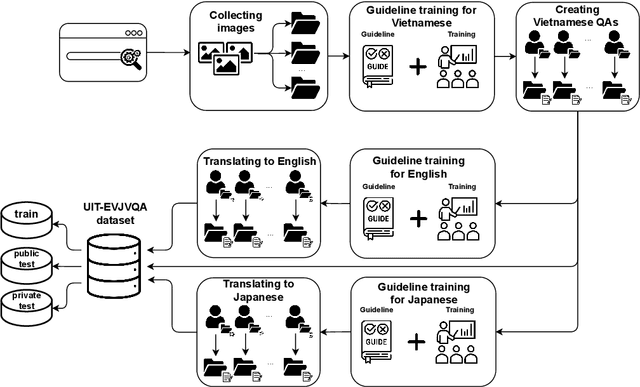
Visual Question Answering (VQA) is a challenging task of natural language processing (NLP) and computer vision (CV), attracting significant attention from researchers. English is a resource-rich language that has witnessed various developments in datasets and models for visual question answering. Visual question answering in other languages also would be developed for resources and models. In addition, there is no multilingual dataset targeting the visual content of a particular country with its own objects and cultural characteristics. To address the weakness, we provide the research community with a benchmark dataset named EVJVQA, including 33,000+ pairs of question-answer over three languages: Vietnamese, English, and Japanese, on approximately 5,000 images taken from Vietnam for evaluating multilingual VQA systems or models. EVJVQA is used as a benchmark dataset for the challenge of multilingual visual question answering at the 9th Workshop on Vietnamese Language and Speech Processing (VLSP 2022). This task attracted 62 participant teams from various universities and organizations. In this article, we present details of the organization of the challenge, an overview of the methods employed by shared-task participants, and the results. The highest performances are 0.4392 in F1-score and 0.4009 in BLUE on the private test set. The multilingual QA systems proposed by the top 2 teams use ViT for the pre-trained vision model and mT5 for the pre-trained language model, a powerful pre-trained language model based on the transformer architecture. EVJVQA is a challenging dataset that motivates NLP and CV researchers to further explore the multilingual models or systems for visual question answering systems.
GenerSpeech: Towards Style Transfer for Generalizable Out-Of-Domain Text-to-Speech Synthesis
May 15, 2022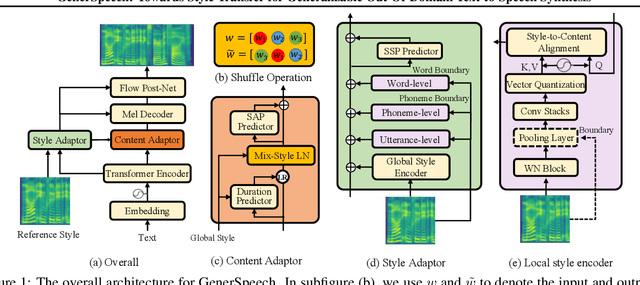
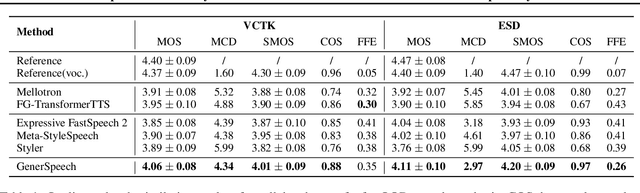
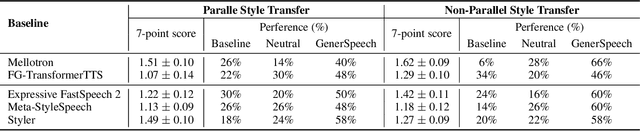
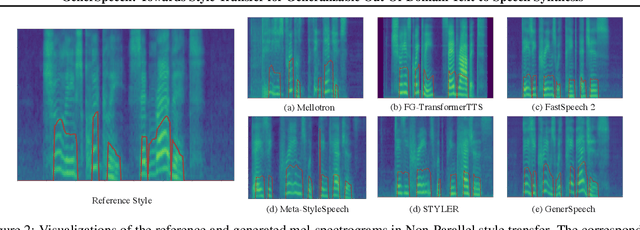
Style transfer for out-of-domain (OOD) speech synthesis aims to generate speech samples with unseen style (e.g., speaker identity, emotion, and prosody) derived from an acoustic reference, while facing the following challenges: 1) The highly dynamic style features in expressive voice are difficult to model and transfer; and 2) the TTS models should be robust enough to handle diverse OOD conditions that differ from the source data. This paper proposes GenerSpeech, a text-to-speech model towards high-fidelity zero-shot style transfer of OOD custom voice. GenerSpeech decomposes the speech variation into the style-agnostic and style-specific parts by introducing two components: 1) a multi-level style adaptor to efficiently model a large range of style conditions, including global speaker and emotion characteristics, and the local (utterance, phoneme, and word-level) fine-grained prosodic representations; and 2) a generalizable content adaptor with Mix-Style Layer Normalization to eliminate style information in the linguistic content representation and thus improve model generalization. Our evaluations on zero-shot style transfer demonstrate that GenerSpeech surpasses the state-of-the-art models in terms of audio quality and style similarity. The extension studies to adaptive style transfer further show that GenerSpeech performs robustly in the few-shot data setting. Audio samples are available at \url{https://GenerSpeech.github.io/}
A Survey of research in Deep Learning for Robotics for Undergraduate research interns
Jan 23, 2023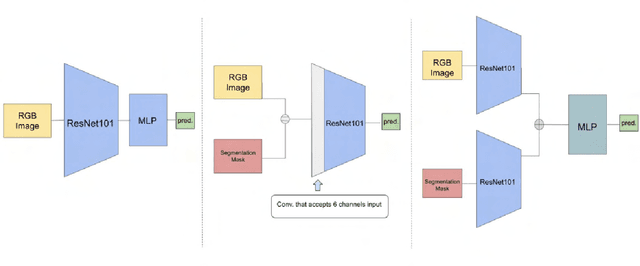
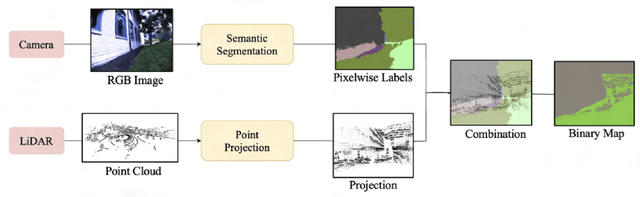
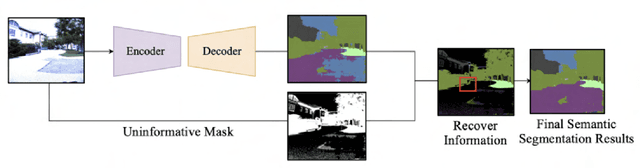
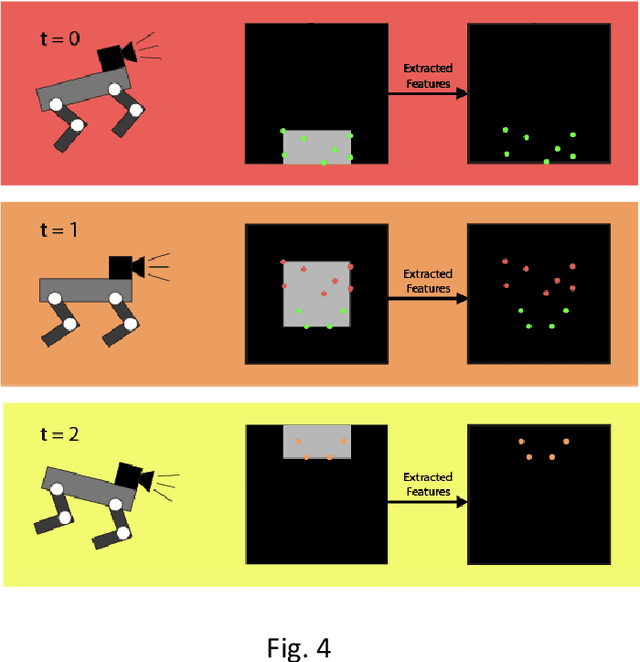
Over the last several years, use cases for robotics based solutions have diversified from factory floors to domestic applications. In parallel, Deep Learning approaches are replacing traditional techniques in Computer Vision, Natural Language Processing, Speech processing, etc. and are delivering robust results. Our goal is to survey a number of research internship projects in the broad area of 'Deep Learning as applied to Robotics' and present a concise view for the benefit of aspiring student interns. In this paper, we survey the research work done by Robotic Institute Summer Scholars (RISS), CMU. We particularly focus on papers that use deep learning to solve core robotic problems and also robotic solutions. We trust this would be useful particularly for internship aspirants for the Robotics Institute, CMU
Curriculum optimization for low-resource speech recognition
Feb 17, 2022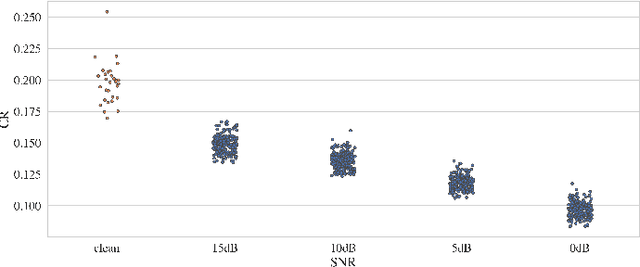
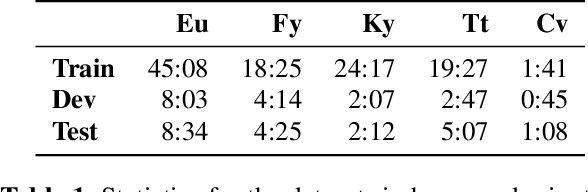
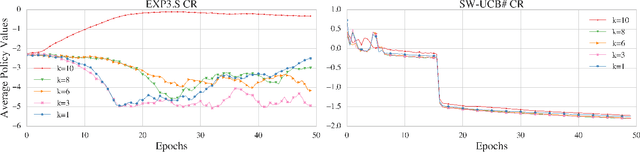
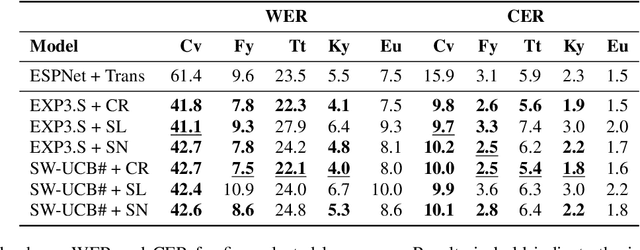
Modern end-to-end speech recognition models show astonishing results in transcribing audio signals into written text. However, conventional data feeding pipelines may be sub-optimal for low-resource speech recognition, which still remains a challenging task. We propose an automated curriculum learning approach to optimize the sequence of training examples based on both the progress of the model while training and prior knowledge about the difficulty of the training examples. We introduce a new difficulty measure called compression ratio that can be used as a scoring function for raw audio in various noise conditions. The proposed method improves speech recognition Word Error Rate performance by up to 33% relative over the baseline system