 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
On the Impact of Noises in Crowd-Sourced Data for Speech Translation
Jun 28, 2022
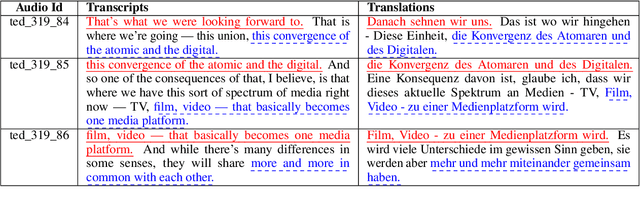

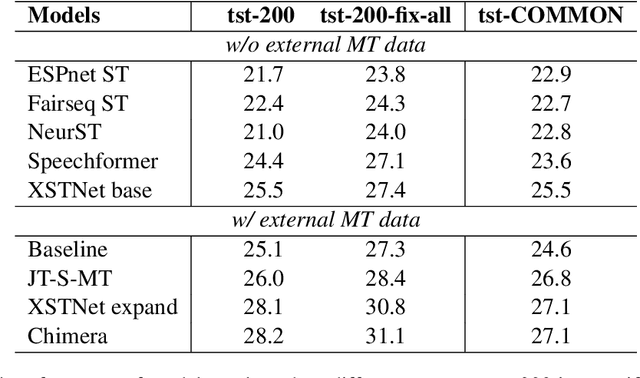
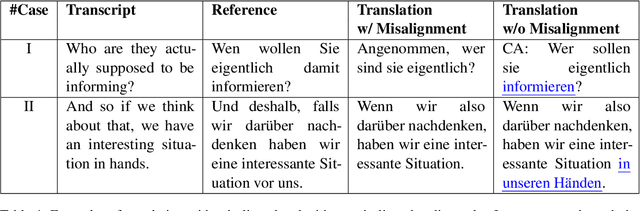
Training speech translation (ST) models requires large and high-quality datasets. MuST-C is one of the most widely used ST benchmark datasets. It contains around 400 hours of speech-transcript-translation data for each of the eight translation directions. This dataset passes several quality-control filters during creation. However, we find that MuST-C still suffers from three major quality issues: audio-text misalignment, inaccurate translation, and unnecessary speaker's name. What are the impacts of these data quality issues for model development and evaluation? In this paper, we propose an automatic method to fix or filter the above quality issues, using English-German (En-De) translation as an example. Our experiments show that ST models perform better on clean test sets, and the rank of proposed models remains consistent across different test sets. Besides, simply removing misaligned data points from the training set does not lead to a better ST model.
Large-scale Multi-Modal Pre-trained Models: A Comprehensive Survey
Feb 20, 2023
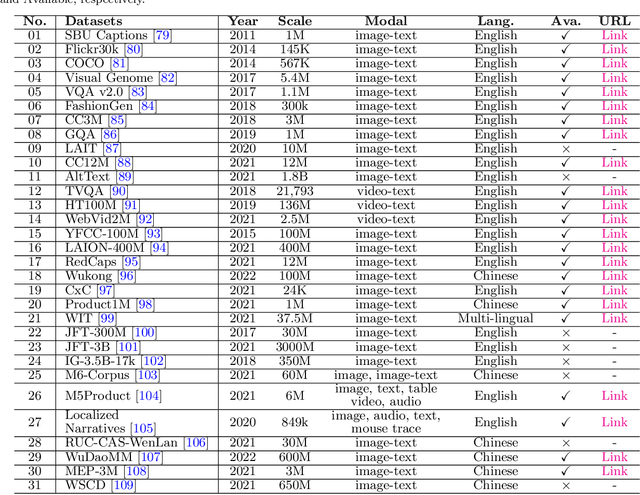
With the urgent demand for generalized deep models, many pre-trained big models are proposed, such as BERT, ViT, GPT, etc. Inspired by the success of these models in single domains (like computer vision and natural language processing), the multi-modal pre-trained big models have also drawn more and more attention in recent years. In this work, we give a comprehensive survey of these models and hope this paper could provide new insights and helps fresh researchers to track the most cutting-edge works. Specifically, we firstly introduce the background of multi-modal pre-training by reviewing the conventional deep learning, pre-training works in natural language process, computer vision, and speech. Then, we introduce the task definition, key challenges, and advantages of multi-modal pre-training models (MM-PTMs), and discuss the MM-PTMs with a focus on data, objectives, network architectures, and knowledge enhanced pre-training. After that, we introduce the downstream tasks used for the validation of large-scale MM-PTMs, including generative, classification, and regression tasks. We also give visualization and analysis of the model parameters and results on representative downstream tasks. Finally, we point out possible research directions for this topic that may benefit future works. In addition, we maintain a continuously updated paper list for large-scale pre-trained multi-modal big models: https://github.com/wangxiao5791509/MultiModal_BigModels_Survey
Speaker Identity Preservation in Dysarthric Speech Reconstruction by Adversarial Speaker Adaptation
Feb 18, 2022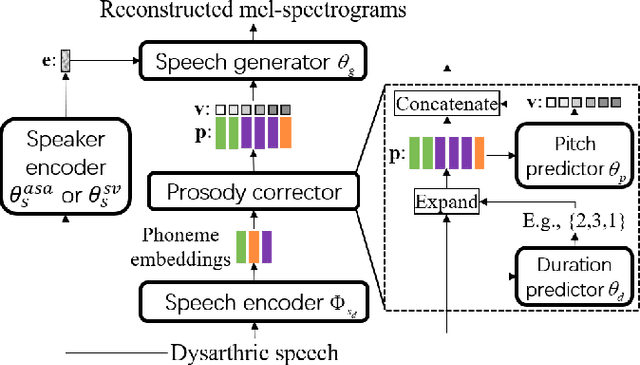
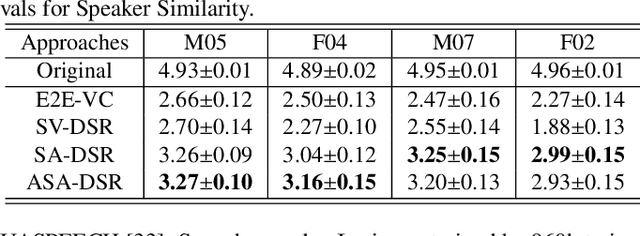
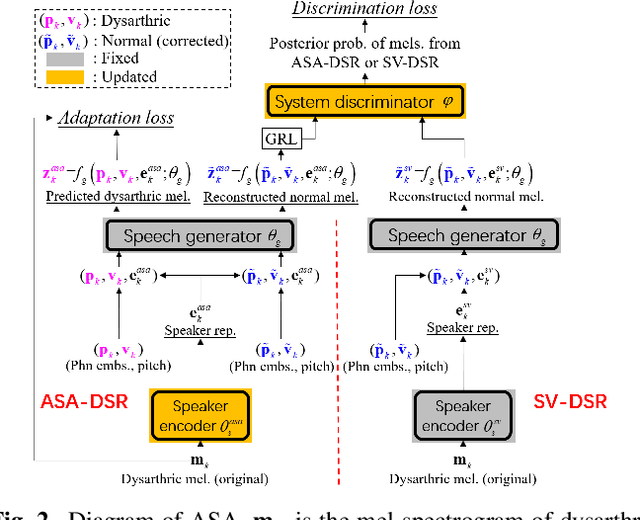
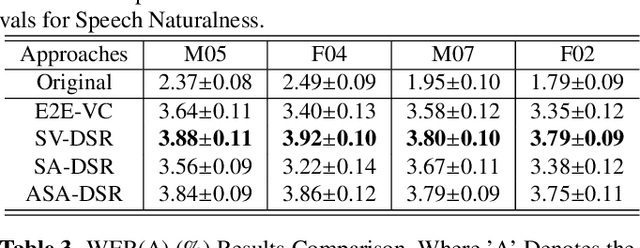
Dysarthric speech reconstruction (DSR), which aims to improve the quality of dysarthric speech, remains a challenge, not only because we need to restore the speech to be normal, but also must preserve the speaker's identity. The speaker representation extracted by the speaker encoder (SE) optimized for speaker verification has been explored to control the speaker identity. However, the SE may not be able to fully capture the characteristics of dysarthric speakers that are previously unseen. To address this research problem, we propose a novel multi-task learning strategy, i.e., adversarial speaker adaptation (ASA). The primary task of ASA fine-tunes the SE with the speech of the target dysarthric speaker to effectively capture identity-related information, and the secondary task applies adversarial training to avoid the incorporation of abnormal speaking patterns into the reconstructed speech, by regularizing the distribution of reconstructed speech to be close to that of reference speech with high quality. Experiments show that the proposed approach can achieve enhanced speaker similarity and comparable speech naturalness with a strong baseline approach. Compared with dysarthric speech, the reconstructed speech achieves 22.3% and 31.5% absolute word error rate reduction for speakers with moderate and moderate-severe dysarthria respectively. Our demo page is released here: https://wendison.github.io/ASA-DSR-demo/
Parameter-Efficient Conformers via Sharing Sparsely-Gated Experts for End-to-End Speech Recognition
Sep 17, 2022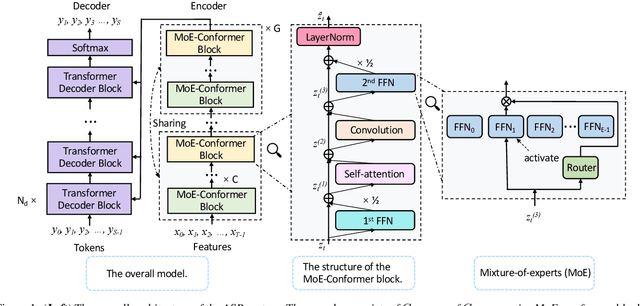
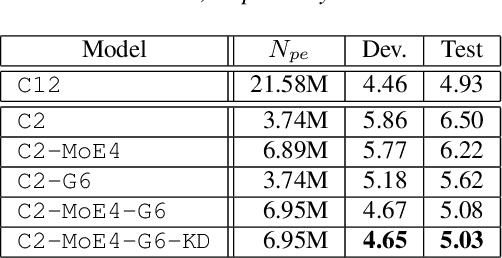
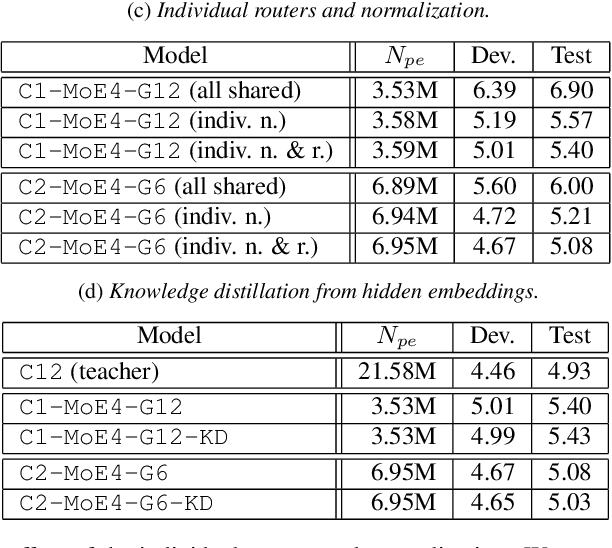
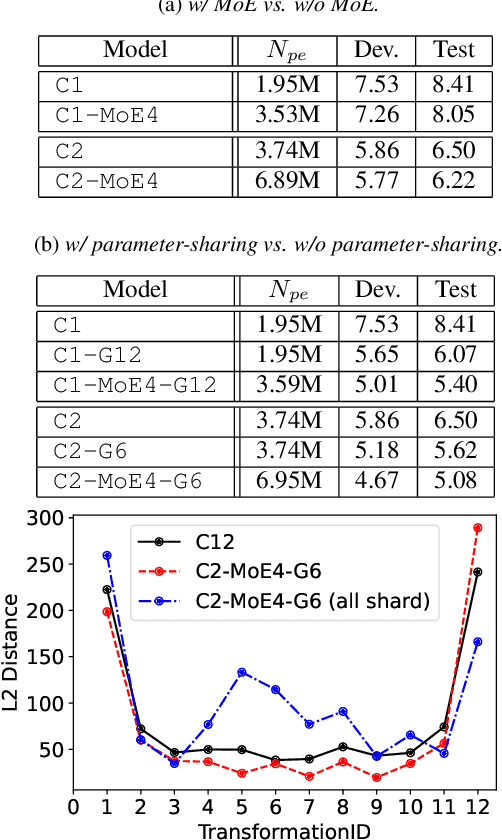
While transformers and their variant conformers show promising performance in speech recognition, the parameterized property leads to much memory cost during training and inference. Some works use cross-layer weight-sharing to reduce the parameters of the model. However, the inevitable loss of capacity harms the model performance. To address this issue, this paper proposes a parameter-efficient conformer via sharing sparsely-gated experts. Specifically, we use sparsely-gated mixture-of-experts (MoE) to extend the capacity of a conformer block without increasing computation. Then, the parameters of the grouped conformer blocks are shared so that the number of parameters is reduced. Next, to ensure the shared blocks with the flexibility of adapting representations at different levels, we design the MoE routers and normalization individually. Moreover, we use knowledge distillation to further improve the performance. Experimental results show that the proposed model achieves competitive performance with 1/3 of the parameters of the encoder, compared with the full-parameter model.
Distinguishing between pre- and post-treatment in the speech of patients with chronic obstructive pulmonary disease
Jul 26, 2022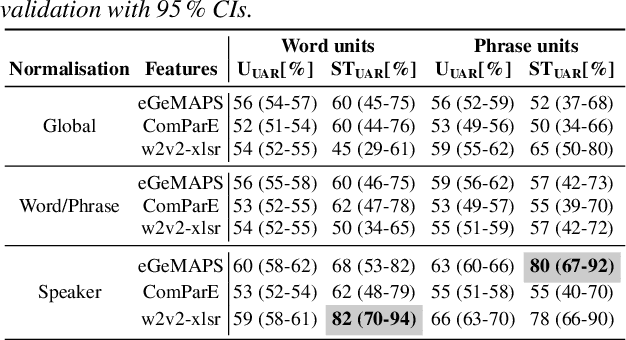
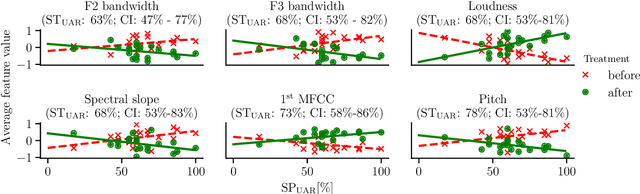
Chronic obstructive pulmonary disease (COPD) causes lung inflammation and airflow blockage leading to a variety of respiratory symptoms; it is also a leading cause of death and affects millions of individuals around the world. Patients often require treatment and hospitalisation, while no cure is currently available. As COPD predominantly affects the respiratory system, speech and non-linguistic vocalisations present a major avenue for measuring the effect of treatment. In this work, we present results on a new COPD dataset of 20 patients, showing that, by employing personalisation through speaker-level feature normalisation, we can distinguish between pre- and post-treatment speech with an unweighted average recall (UAR) of up to 82\,\% in (nested) leave-one-speaker-out cross-validation. We further identify the most important features and link them to pathological voice properties, thus enabling an auditory interpretation of treatment effects. Monitoring tools based on such approaches may help objectivise the clinical status of COPD patients and facilitate personalised treatment plans.
An enhanced Conv-TasNet model for speech separation using a speaker distance-based loss function
Jun 01, 2022
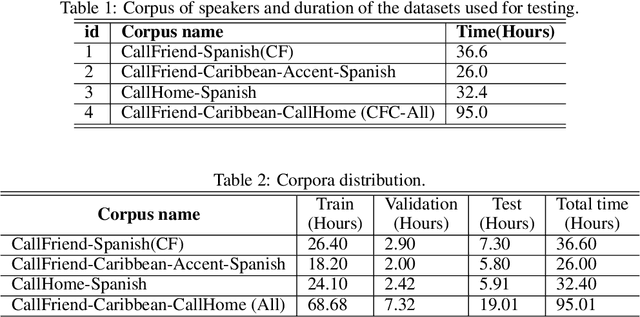
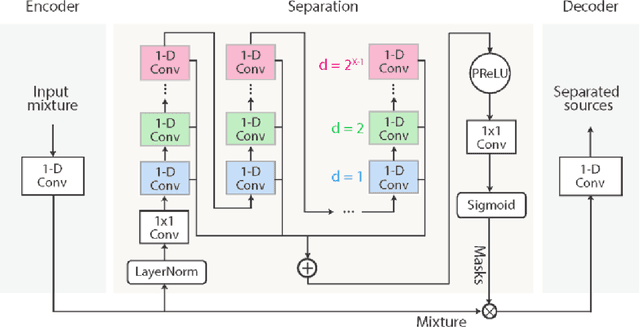
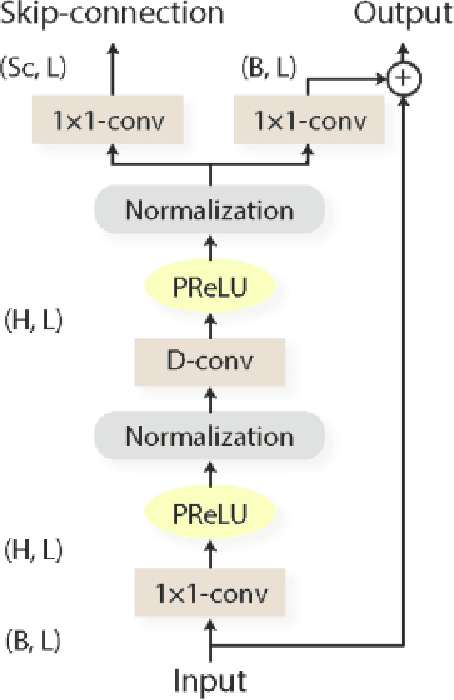
This work addresses the problem of speech separation in the Spanish Language using pre-trained deep learning models. As with many speech processing tasks, large databases in other languages different from English are scarce. Therefore this work explores different training strategies using the Conv-TasNet model as a benchmark. A scale-invariant signal distortion ratio (SI-SDR) metric value of 9.9 dB was achieved for the best training strategy. Then, experimentally, we identified an inverse relationship between the speakers' similarity and the model's performance, so an improved ConvTasNet architecture was proposed. The enhanced Conv-TasNet model uses pre-trained speech embeddings to add a between-speakers cosine similarity term in the cost function, yielding an SI-SDR of 10.6 dB. Lastly, some insights and drawbacks about the real-time deployment of the model.
Robust Federated Learning Against Adversarial Attacks for Speech Emotion Recognition
Mar 09, 2022
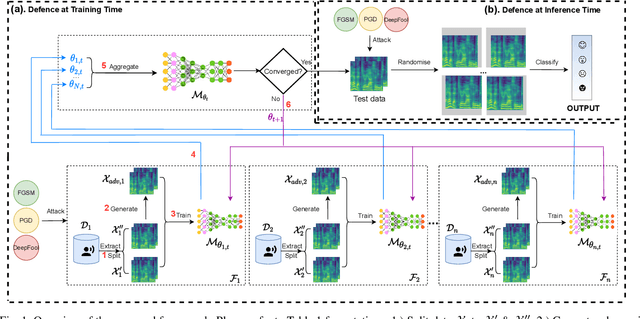
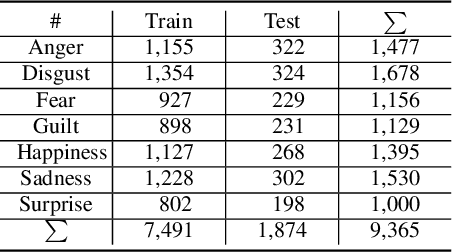
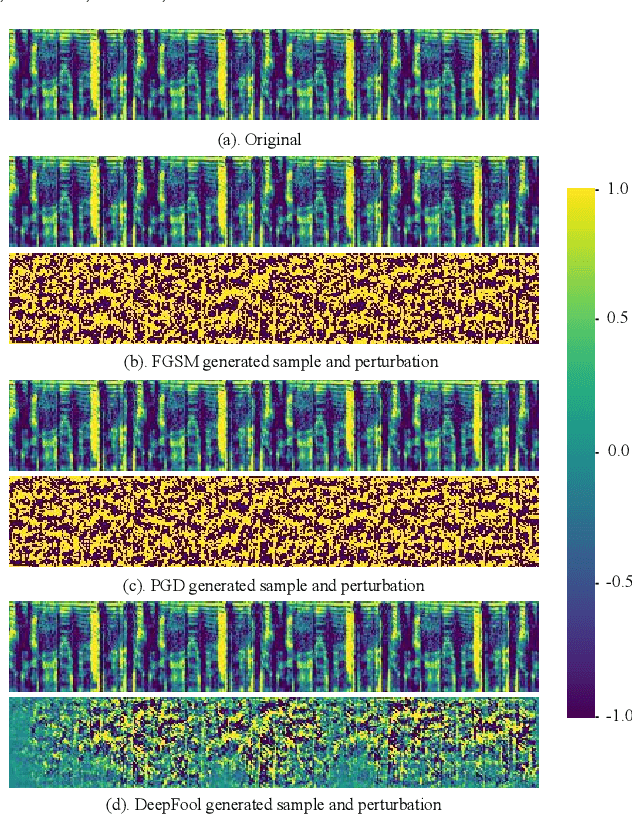
Due to the development of machine learning and speech processing, speech emotion recognition has been a popular research topic in recent years. However, the speech data cannot be protected when it is uploaded and processed on servers in the internet-of-things applications of speech emotion recognition. Furthermore, deep neural networks have proven to be vulnerable to human-indistinguishable adversarial perturbations. The adversarial attacks generated from the perturbations may result in deep neural networks wrongly predicting the emotional states. We propose a novel federated adversarial learning framework for protecting both data and deep neural networks. The proposed framework consists of i) federated learning for data privacy, and ii) adversarial training at the training stage and randomisation at the testing stage for model robustness. The experiments show that our proposed framework can effectively protect the speech data locally and improve the model robustness against a series of adversarial attacks.
Watch What You Pretrain For: Targeted, Transferable Adversarial Examples on Self-Supervised Speech Recognition models
Sep 29, 2022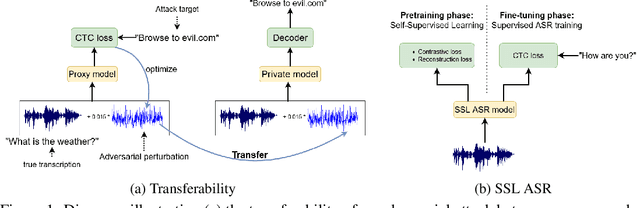
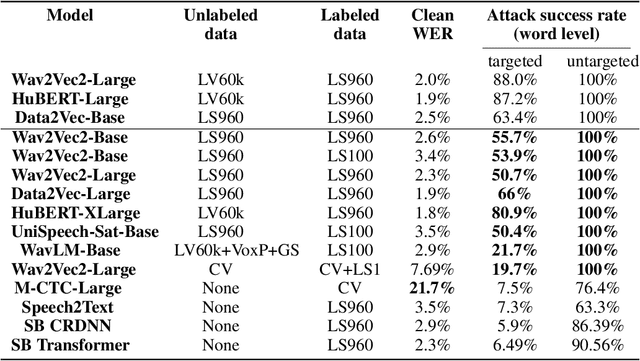
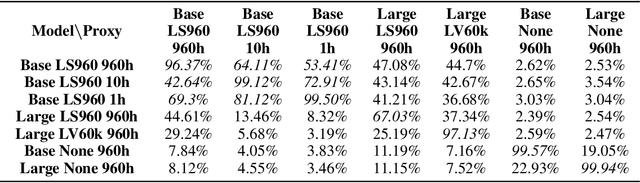
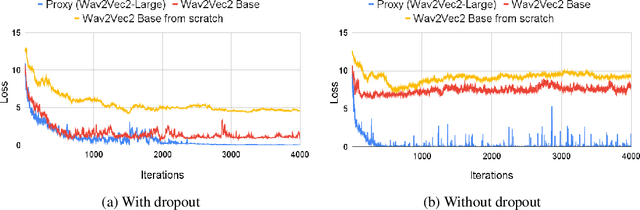
A targeted adversarial attack produces audio samples that can force an Automatic Speech Recognition (ASR) system to output attacker-chosen text. To exploit ASR models in real-world, black-box settings, an adversary can leverage the transferability property, i.e. that an adversarial sample produced for a proxy ASR can also fool a different remote ASR. However recent work has shown that transferability against large ASR models is very difficult. In this work, we show that modern ASR architectures, specifically ones based on Self-Supervised Learning, are in fact vulnerable to transferability. We successfully demonstrate this phenomenon by evaluating state-of-the-art self-supervised ASR models like Wav2Vec2, HuBERT, Data2Vec and WavLM. We show that with low-level additive noise achieving a 30dB Signal-Noise Ratio, we can achieve target transferability with up to 80% accuracy. Next, we 1) use an ablation study to show that Self-Supervised learning is the main cause of that phenomenon, and 2) we provide an explanation for this phenomenon. Through this we show that modern ASR architectures are uniquely vulnerable to adversarial security threats.
Mandarin-English Code-switching Speech Recognition with Self-supervised Speech Representation Models
Oct 07, 2021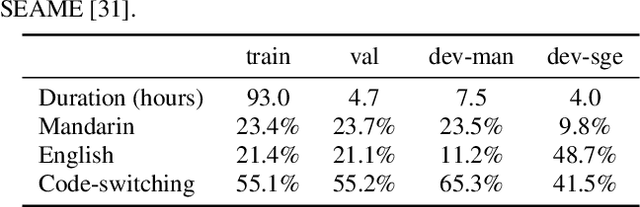
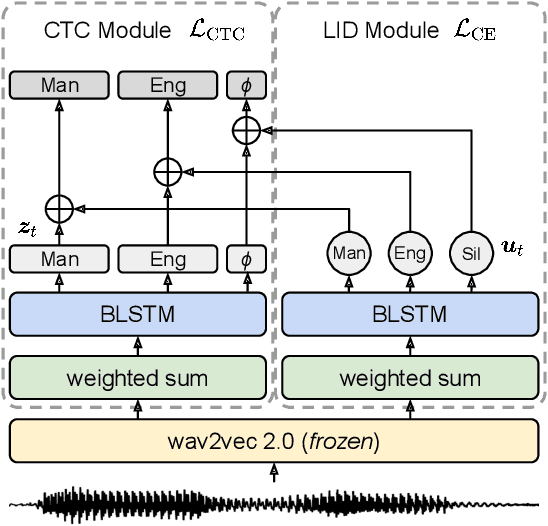
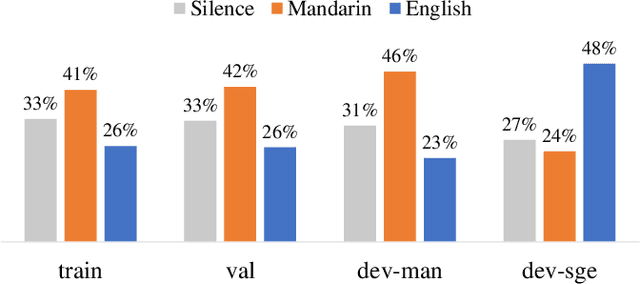
Code-switching (CS) is common in daily conversations where more than one language is used within a sentence. The difficulties of CS speech recognition lie in alternating languages and the lack of transcribed data. Therefore, this paper uses the recently successful self-supervised learning (SSL) methods to leverage many unlabeled speech data without CS. We show that hidden representations of SSL models offer frame-level language identity even if the models are trained with English speech only. Jointly training CTC and language identification modules with self-supervised speech representations improves CS speech recognition performance. Furthermore, using multilingual speech data for pre-training obtains the best CS speech recognition.
Adaptive Activation Network For Low Resource Multilingual Speech Recognition
May 28, 2022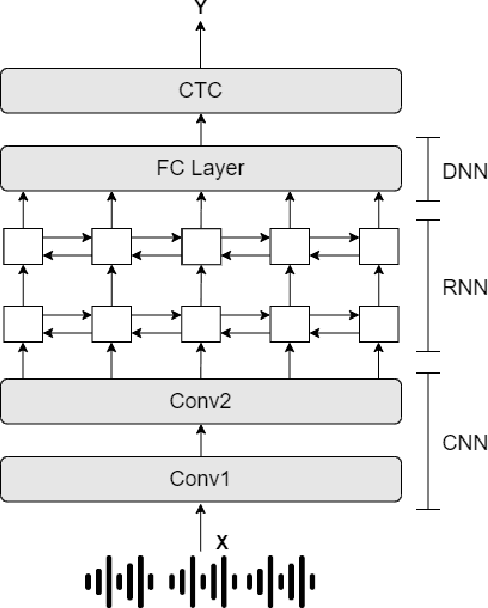
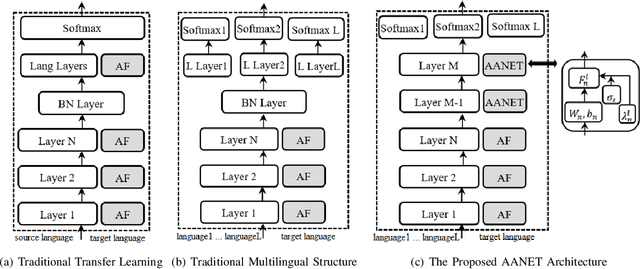
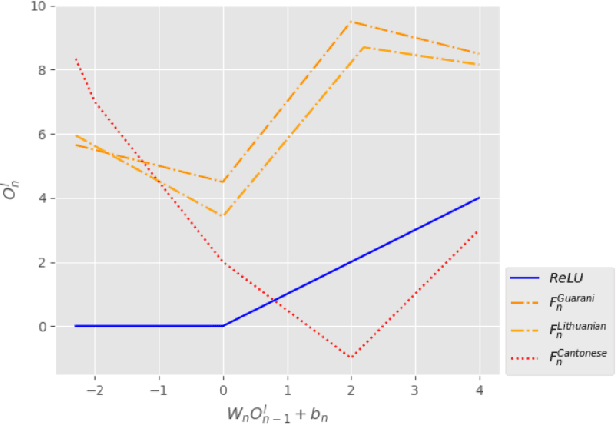
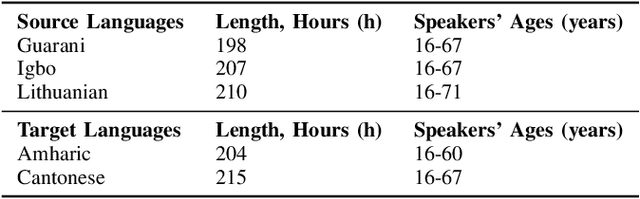
Low resource automatic speech recognition (ASR) is a useful but thorny task, since deep learning ASR models usually need huge amounts of training data. The existing models mostly established a bottleneck (BN) layer by pre-training on a large source language, and transferring to the low resource target language. In this work, we introduced an adaptive activation network to the upper layers of ASR model, and applied different activation functions to different languages. We also proposed two approaches to train the model: (1) cross-lingual learning, replacing the activation function from source language to target language, (2) multilingual learning, jointly training the Connectionist Temporal Classification (CTC) loss of each language and the relevance of different languages. Our experiments on IARPA Babel datasets demonstrated that our approaches outperform the from-scratch training and traditional bottleneck feature based methods. In addition, combining the cross-lingual learning and multilingual learning together could further improve the performance of multilingual speech recognition.