 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
A Fast and Accurate Pitch Estimation Algorithm Based on the Pseudo Wigner-Ville Distribution
Oct 27, 2022
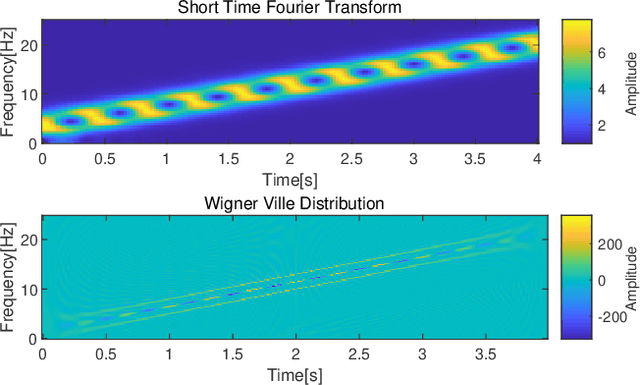
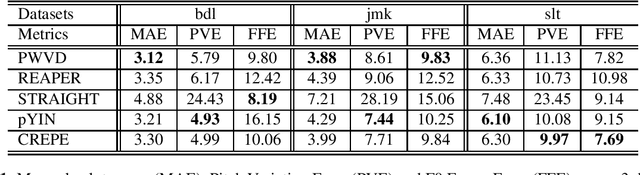
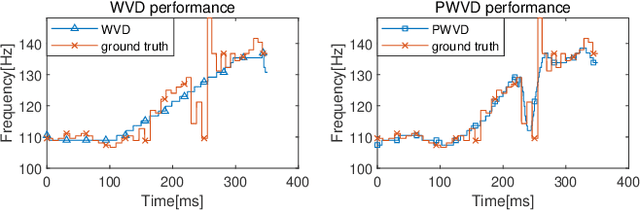
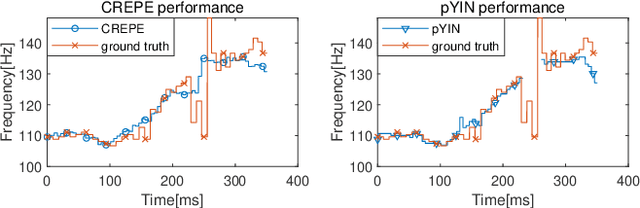
Estimation of fundamental frequency (F0) in voiced segments of speech signals, also known as pitch tracking, plays a crucial role in pitch synchronous speech analysis, speech synthesis, and speech manipulation. In this paper, we capitalize on the high time and frequency resolution of the pseudo Wigner-Ville distribution (PWVD) and propose a new PWVD-based pitch estimation method. We devise an efficient algorithm to compute PWVD faster and use cepstrum-based pre-filtering to avoid cross-term interference. Evaluating our approach on a database with speech and electroglottograph (EGG) recordings yields a state-of-the-art mean absolute error (MAE) of around 4Hz. Our approach is also effective at voiced/unvoiced classification and handling sudden frequency changes.
Vocal effort modeling in neural TTS for improving the intelligibility of synthetic speech in noise
Mar 29, 2022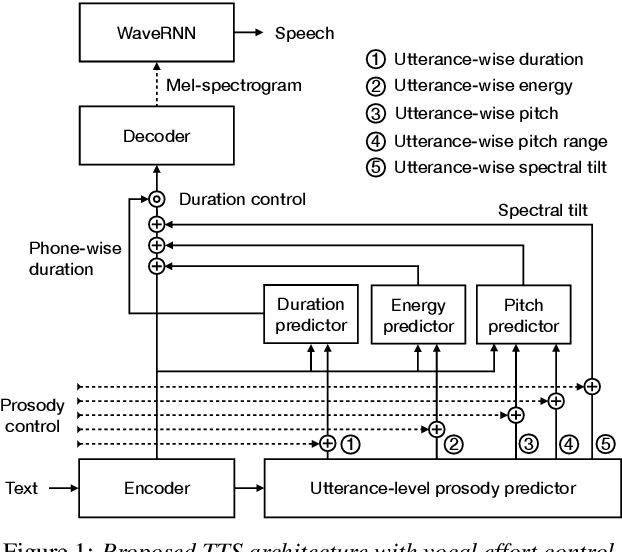
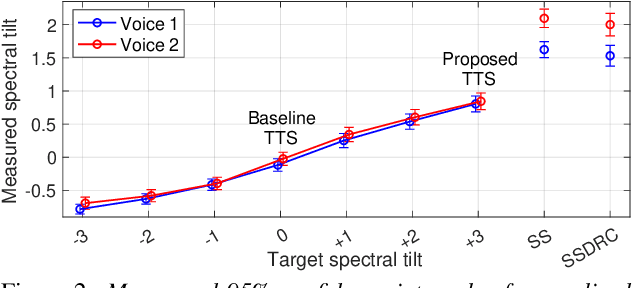
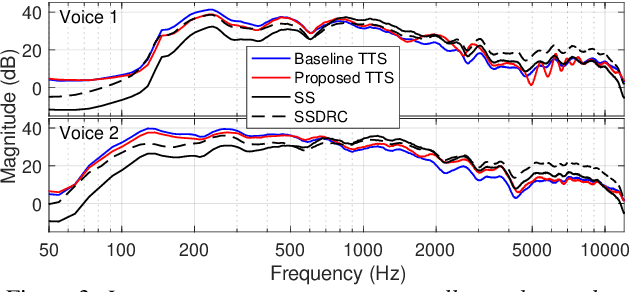
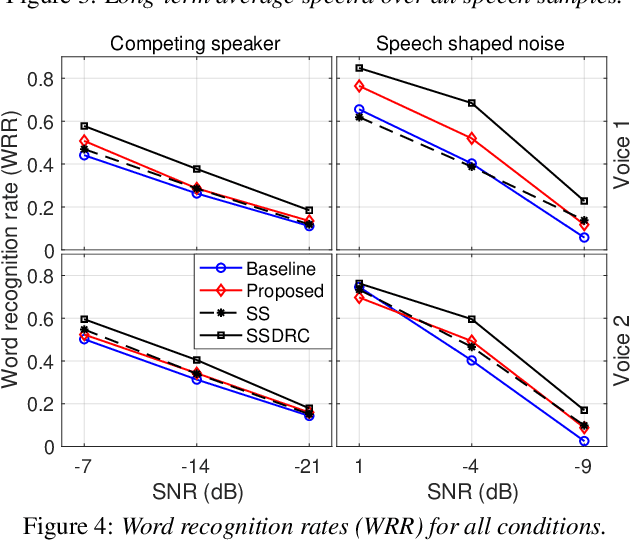
We present a neural text-to-speech (TTS) method that models natural vocal effort variation to improve the intelligibility of synthetic speech in the presence of noise. The method consists of first measuring the spectral tilt of unlabeled conventional speech data, and then conditioning a neural TTS model with normalized spectral tilt among other prosodic factors. Changing the spectral tilt parameter and keeping other prosodic factors unchanged enables effective vocal effort control at synthesis time independent of other prosodic factors. By extrapolation of the spectral tilt values beyond what has been seen in the original data, we can generate speech with high vocal effort levels, thus improving the intelligibility of speech in the presence of masking noise. We evaluate the intelligibility and quality of normal speech and speech with increased vocal effort in the presence of various masking noise conditions, and compare these to well-known speech intelligibility-enhancing algorithms. The evaluations show that the proposed method can improve the intelligibility of synthetic speech with little loss in speech quality.
Guided-TTS 2: A Diffusion Model for High-quality Adaptive Text-to-Speech with Untranscribed Data
May 30, 2022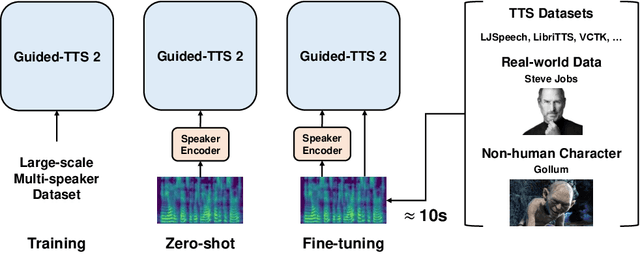
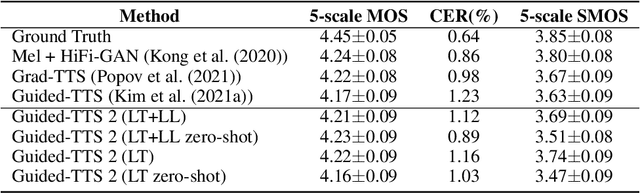
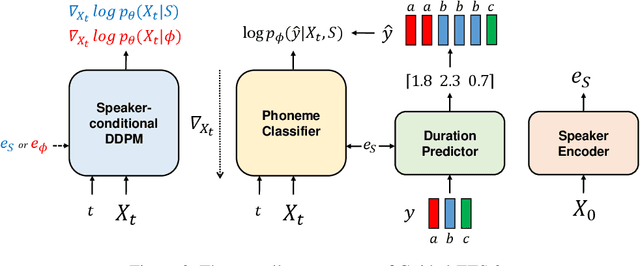
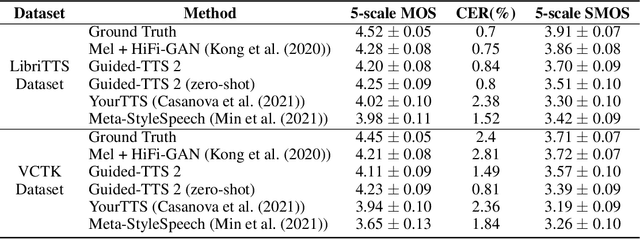
We propose Guided-TTS 2, a diffusion-based generative model for high-quality adaptive TTS using untranscribed data. Guided-TTS 2 combines a speaker-conditional diffusion model with a speaker-dependent phoneme classifier for adaptive text-to-speech. We train the speaker-conditional diffusion model on large-scale untranscribed datasets for a classifier-free guidance method and further fine-tune the diffusion model on the reference speech of the target speaker for adaptation, which only takes 40 seconds. We demonstrate that Guided-TTS 2 shows comparable performance to high-quality single-speaker TTS baselines in terms of speech quality and speaker similarity with only a ten-second untranscribed data. We further show that Guided-TTS 2 outperforms adaptive TTS baselines on multi-speaker datasets even with a zero-shot adaptation setting. Guided-TTS 2 can adapt to a wide range of voices only using untranscribed speech, which enables adaptive TTS with the voice of non-human characters such as Gollum in \textit{"The Lord of the Rings"}.
Articulation GAN: Unsupervised modeling of articulatory learning
Oct 27, 2022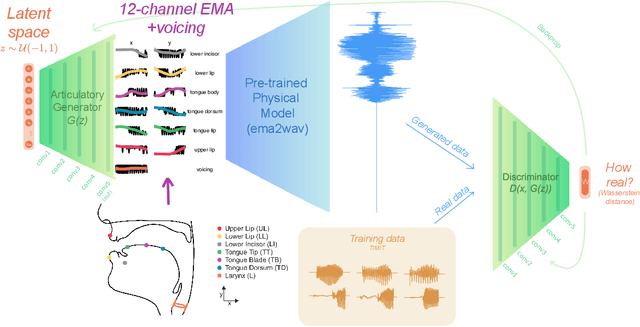

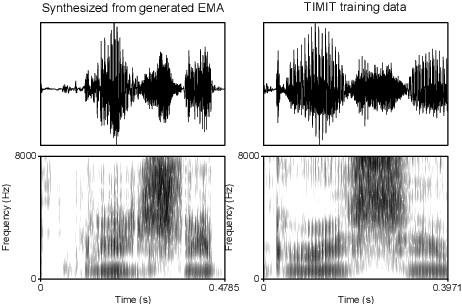
Generative deep neural networks are widely used for speech synthesis, but most existing models directly generate waveforms or spectral outputs. Humans, however, produce speech by controlling articulators, which results in the production of speech sounds through physical properties of sound propagation. We propose a new unsupervised generative model of speech production/synthesis that includes articulatory representations and thus more closely mimics human speech production. We introduce the Articulatory Generator to the Generative Adversarial Network paradigm. The Articulatory Generator needs to learn to generate articulatory representations (electromagnetic articulography or EMA) in a fully unsupervised manner without ever accessing EMA data. A separate pre-trained physical model (ema2wav) then transforms the generated EMA representations to speech waveforms, which get sent to the Discriminator for evaluation. Articulatory analysis of the generated EMA representations suggests that the network learns to control articulators in a manner that closely follows human articulators during speech production. Acoustic analysis of the outputs suggest that the network learns to generate words that are part of training data as well as novel innovative words that are absent from training data. Our proposed architecture thus allows modeling of articulatory learning with deep neural networks from raw audio inputs in a fully unsupervised manner. We additionally discuss implications of articulatory representations for cognitive models of human language and speech technology in general.
Visual Speech-Aware Perceptual 3D Facial Expression Reconstruction from Videos
Jul 22, 2022
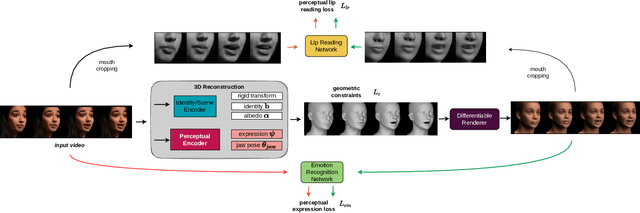


The recent state of the art on monocular 3D face reconstruction from image data has made some impressive advancements, thanks to the advent of Deep Learning. However, it has mostly focused on input coming from a single RGB image, overlooking the following important factors: a) Nowadays, the vast majority of facial image data of interest do not originate from single images but rather from videos, which contain rich dynamic information. b) Furthermore, these videos typically capture individuals in some form of verbal communication (public talks, teleconferences, audiovisual human-computer interactions, interviews, monologues/dialogues in movies, etc). When existing 3D face reconstruction methods are applied in such videos, the artifacts in the reconstruction of the shape and motion of the mouth area are often severe, since they do not match well with the speech audio. To overcome the aforementioned limitations, we present the first method for visual speech-aware perceptual reconstruction of 3D mouth expressions. We do this by proposing a "lipread" loss, which guides the fitting process so that the elicited perception from the 3D reconstructed talking head resembles that of the original video footage. We demonstrate that, interestingly, the lipread loss is better suited for 3D reconstruction of mouth movements compared to traditional landmark losses, and even direct 3D supervision. Furthermore, the devised method does not rely on any text transcriptions or corresponding audio, rendering it ideal for training in unlabeled datasets. We verify the efficiency of our method through exhaustive objective evaluations on three large-scale datasets, as well as subjective evaluation with two web-based user studies.
Can Self-Supervised Learning solve the problem of child speech recognition?
Apr 06, 2022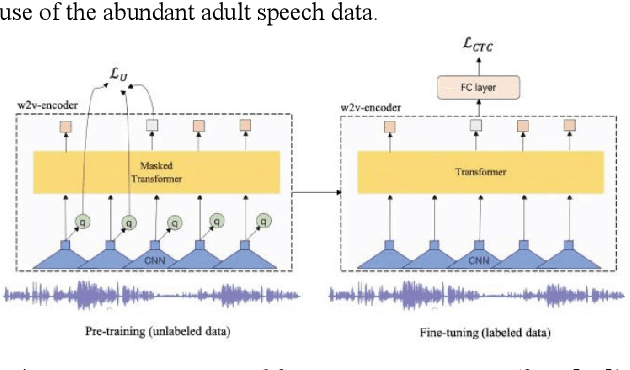
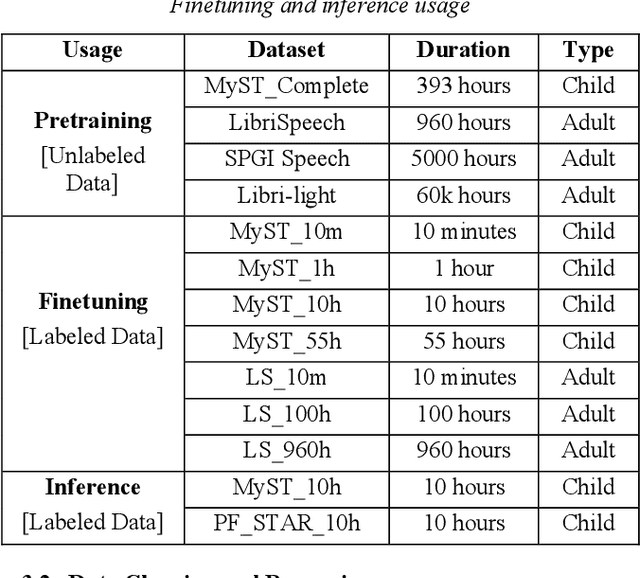
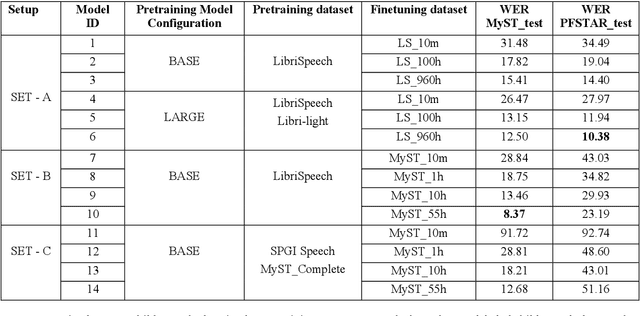
Despite recent advancements in deep learning technologies, Child Speech Recognition remains a challenging task. Current Automatic Speech Recognition (ASR) models required substantial amounts of annotated data for training, which is scarce. In this work, we explore using the ASR model, wav2vec2, with different pretraining and finetuning configurations for self supervised learning (SSL) towards improving automatic child speech recognition. The pretrained wav2vec2 models were finetuned using different amounts of child speech training data to discover the optimum amount of data required to finetune the model for the task of child ASR. Our trained model receives the best word error rate (WER) of 8.37 on the in domain MyST dataset and WER of 10.38 on the out of domain PFSTAR dataset. We do not use any Language Models (LM) in our experiments.
Multi-Channel Speech Denoising for Machine Ears
Feb 17, 2022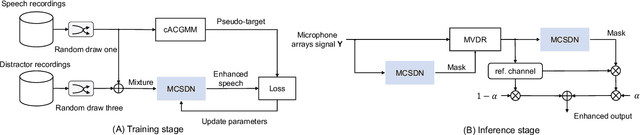
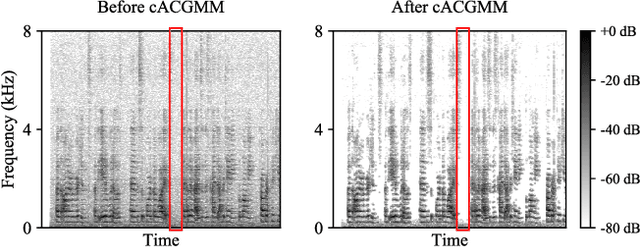
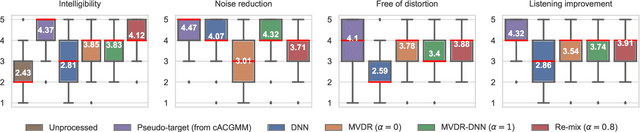
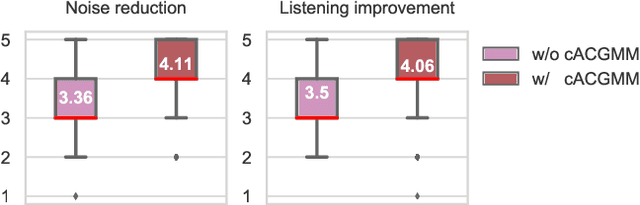
This work describes a speech denoising system for machine ears that aims to improve speech intelligibility and the overall listening experience in noisy environments. We recorded approximately 100 hours of audio data with reverberation and moderate environmental noise using a pair of microphone arrays placed around each of the two ears and then mixed sound recordings to simulate adverse acoustic scenes. Then, we trained a multi-channel speech denoising network (MCSDN) on the mixture of recordings. To improve the training, we employ an unsupervised method, complex angular central Gaussian mixture model (cACGMM), to acquire cleaner speech from noisy recordings to serve as the learning target. We propose a MCSDN-Beamforming-MCSDN framework in the inference stage. The results of the subjective evaluation show that the cACGMM improves the training data, resulting in better noise reduction and user preference, and the entire system improves the intelligibility and listening experience in noisy situations.
VLSP2022-EVJVQA Challenge: Multilingual Visual Question Answering
Feb 28, 2023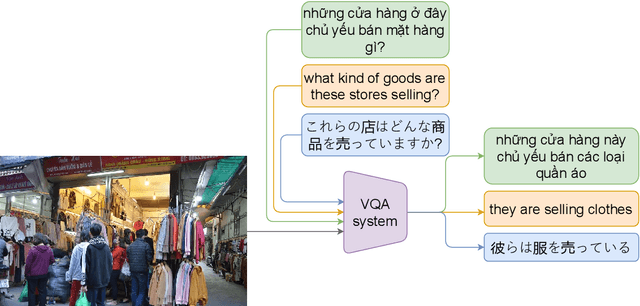
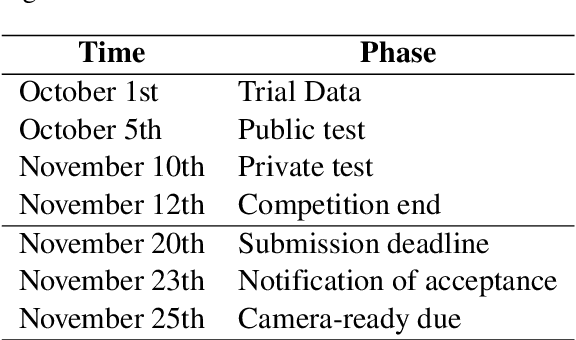

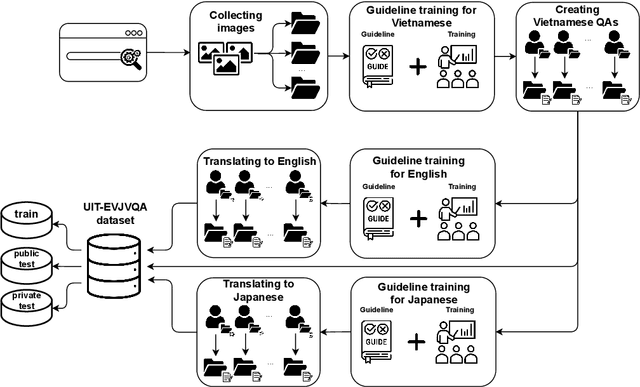
Visual Question Answering (VQA) is a challenging task of natural language processing (NLP) and computer vision (CV), attracting significant attention from researchers. English is a resource-rich language that has witnessed various developments in datasets and models for visual question answering. Visual question answering in other languages also would be developed for resources and models. In addition, there is no multilingual dataset targeting the visual content of a particular country with its own objects and cultural characteristics. To address the weakness, we provide the research community with a benchmark dataset named EVJVQA, including 33,000+ pairs of question-answer over three languages: Vietnamese, English, and Japanese, on approximately 5,000 images taken from Vietnam for evaluating multilingual VQA systems or models. EVJVQA is used as a benchmark dataset for the challenge of multilingual visual question answering at the 9th Workshop on Vietnamese Language and Speech Processing (VLSP 2022). This task attracted 62 participant teams from various universities and organizations. In this article, we present details of the organization of the challenge, an overview of the methods employed by shared-task participants, and the results. The highest performances are 0.4392 in F1-score and 0.4009 in BLUE on the private test set. The multilingual QA systems proposed by the top 2 teams use ViT for the pre-trained vision model and mT5 for the pre-trained language model, a powerful pre-trained language model based on the transformer architecture. EVJVQA is a challenging dataset that motivates NLP and CV researchers to further explore the multilingual models or systems for visual question answering systems.
Chaotic Variational Auto encoder-based Adversarial Machine Learning
Feb 25, 2023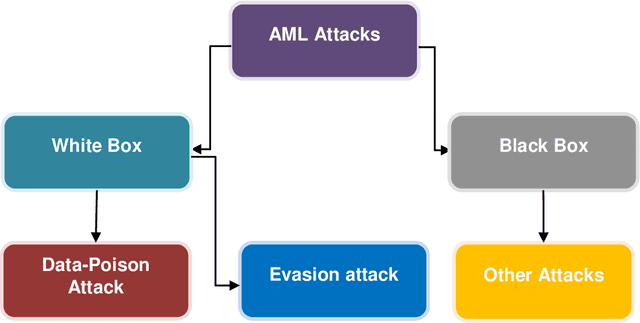
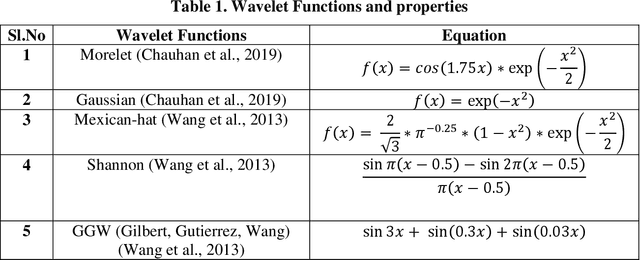
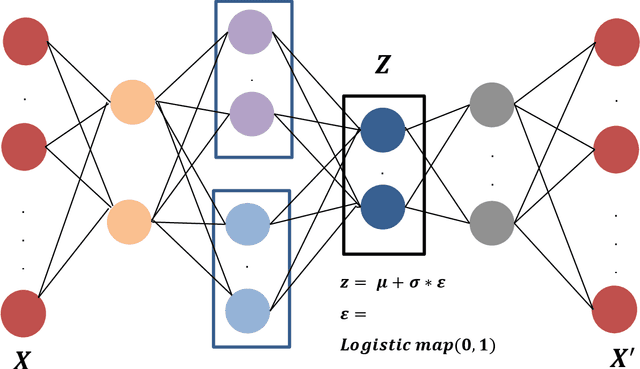
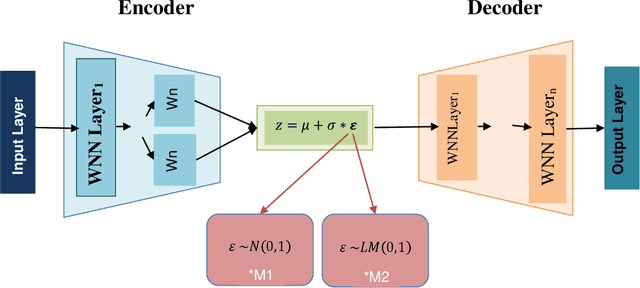
Machine Learning (ML) has become the new contrivance in almost every field. This makes them a target of fraudsters by various adversary attacks, thereby hindering the performance of ML models. Evasion and Data-Poison-based attacks are well acclaimed, especially in finance, healthcare, etc. This motivated us to propose a novel computationally less expensive attack mechanism based on the adversarial sample generation by Variational Auto Encoder (VAE). It is well known that Wavelet Neural Network (WNN) is considered computationally efficient in solving image and audio processing, speech recognition, and time-series forecasting. This paper proposed VAE-Deep-Wavelet Neural Network (VAE-Deep-WNN), where Encoder and Decoder employ WNN networks. Further, we proposed chaotic variants of both VAE with Multi-layer perceptron (MLP) and Deep-WNN and named them C-VAE-MLP and C-VAE-Deep-WNN, respectively. Here, we employed a Logistic map to generate random noise in the latent space. In this paper, we performed VAE-based adversary sample generation and applied it to various problems related to finance and cybersecurity domain-related problems such as loan default, credit card fraud, and churn modelling, etc., We performed both Evasion and Data-Poison attacks on Logistic Regression (LR) and Decision Tree (DT) models. The results indicated that VAE-Deep-WNN outperformed the rest in the majority of the datasets and models. However, its chaotic variant C-VAE-Deep-WNN performed almost similarly to VAE-Deep-WNN in the majority of the datasets.
Listening to Affected Communities to Define Extreme Speech: Dataset and Experiments
Mar 22, 2022
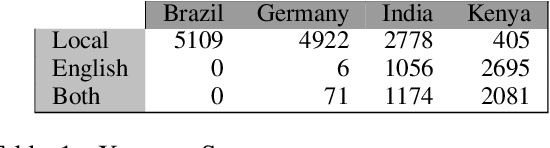

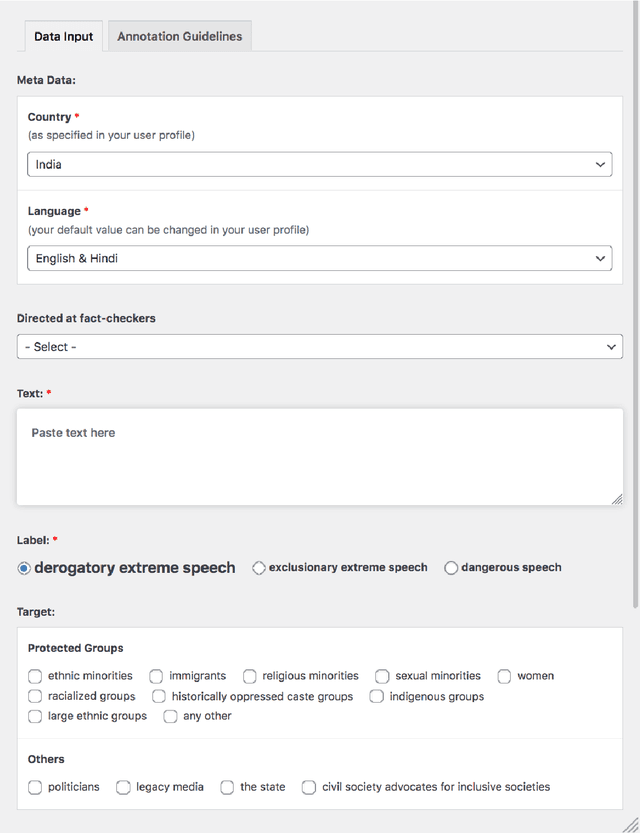
Building on current work on multilingual hate speech (e.g., Ousidhoum et al. (2019)) and hate speech reduction (e.g., Sap et al. (2020)), we present XTREMESPEECH, a new hate speech dataset containing 20,297 social media passages from Brazil, Germany, India and Kenya. The key novelty is that we directly involve the affected communities in collecting and annotating the data - as opposed to giving companies and governments control over defining and combatting hate speech. This inclusive approach results in datasets more representative of actually occurring online speech and is likely to facilitate the removal of the social media content that marginalized communities view as causing the most harm. Based on XTREMESPEECH, we establish novel tasks with accompanying baselines, provide evidence that cross-country training is generally not feasible due to cultural differences between countries and perform an interpretability analysis of BERT's predictions.