 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Device Directedness with Contextual Cues for Spoken Dialog Systems
Nov 23, 2022

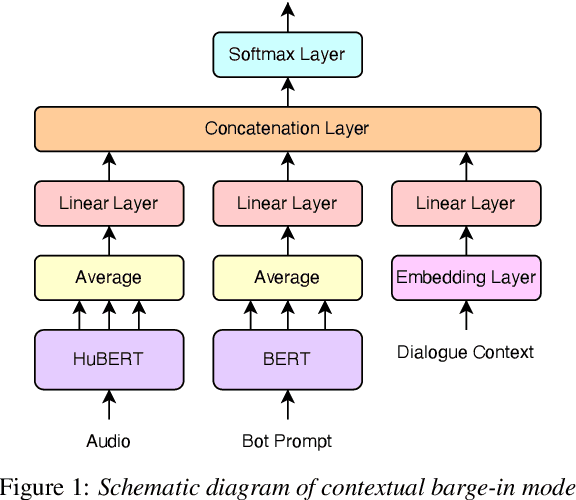
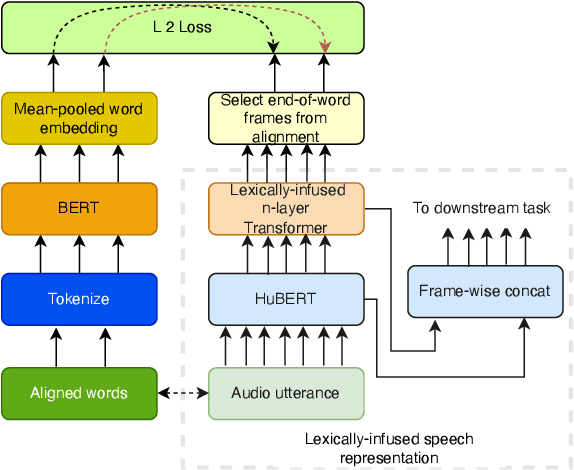
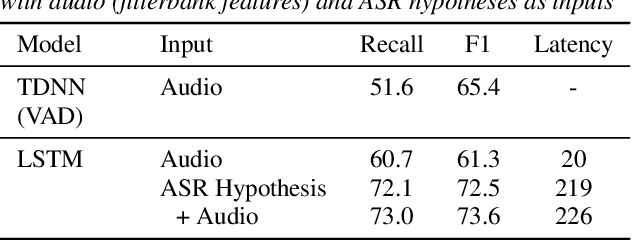
In this work, we define barge-in verification as a supervised learning task where audio-only information is used to classify user spoken dialogue into true and false barge-ins. Following the success of pre-trained models, we use low-level speech representations from a self-supervised representation learning model for our downstream classification task. Further, we propose a novel technique to infuse lexical information directly into speech representations to improve the domain-specific language information implicitly learned during pre-training. Experiments conducted on spoken dialog data show that our proposed model trained to validate barge-in entirely from speech representations is faster by 38% relative and achieves 4.5% relative F1 score improvement over a baseline LSTM model that uses both audio and Automatic Speech Recognition (ASR) 1-best hypotheses. On top of this, our best proposed model with lexically infused representations along with contextual features provides a further relative improvement of 5.7% in the F1 score but only 22% faster than the baseline.
Boosting Self-Supervised Embeddings for Speech Enhancement
Apr 07, 2022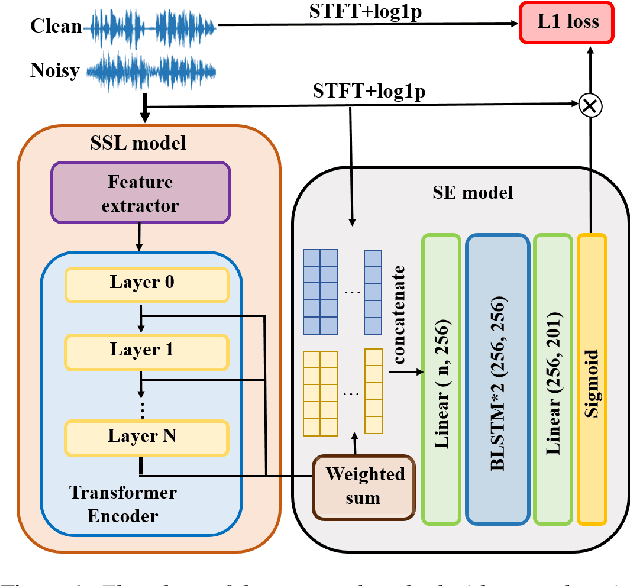
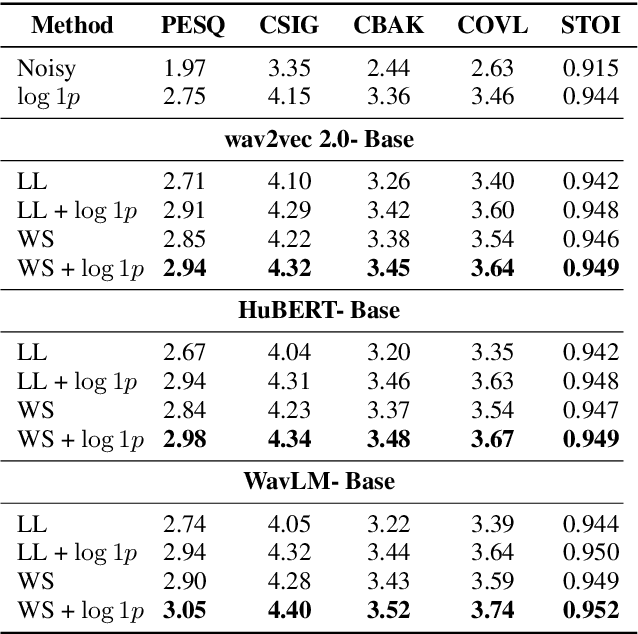
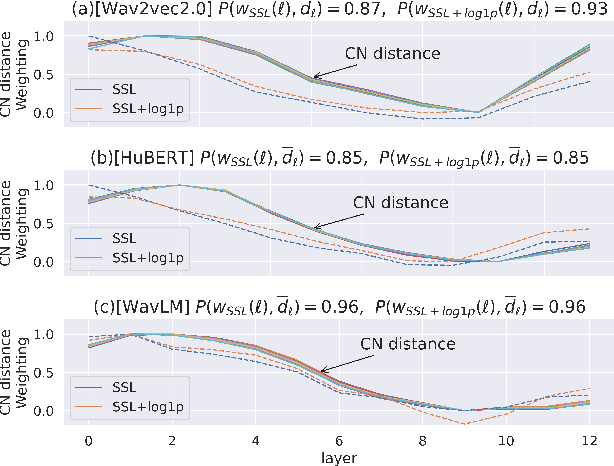
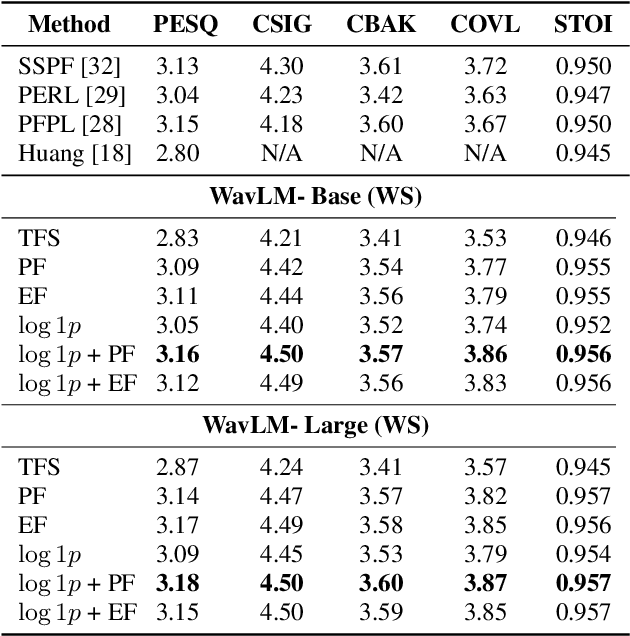
Self-supervised learning (SSL) representation for speech has achieved state-of-the-art (SOTA) performance on several downstream tasks. However, there remains room for improvement in speech enhancement (SE) tasks. In this study, we used a cross-domain feature to solve the problem that SSL embeddings may lack fine-grained information to regenerate speech signals. By integrating the SSL representation and spectrogram, the result can be significantly boosted. We further study the relationship between the noise robustness of SSL representation via clean-noisy distance (CN distance) and the layer importance for SE. Consequently, we found that SSL representations with lower noise robustness are more important. Furthermore, our experiments on the VCTK-DEMAND dataset demonstrated that fine-tuning an SSL representation with an SE model can outperform the SOTA SSL-based SE methods in PESQ, CSIG and COVL without invoking complicated network architectures. In later experiments, the CN distance in SSL embeddings was observed to increase after fine-tuning. These results verify our expectations and may help design SE-related SSL training in the future.
Branchformer: Parallel MLP-Attention Architectures to Capture Local and Global Context for Speech Recognition and Understanding
Jul 06, 2022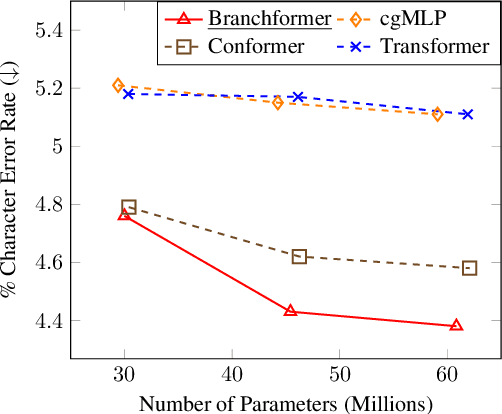
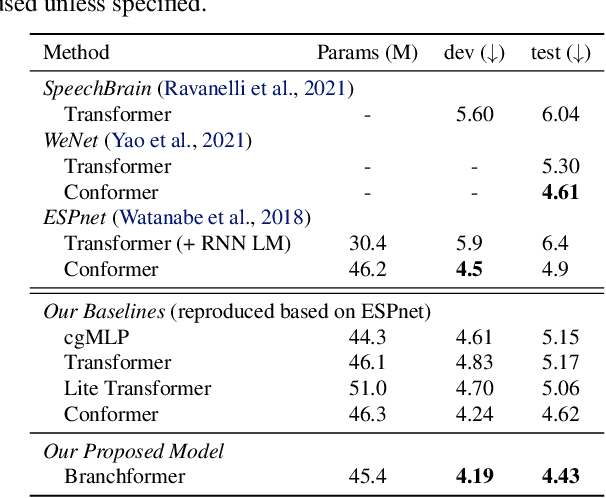
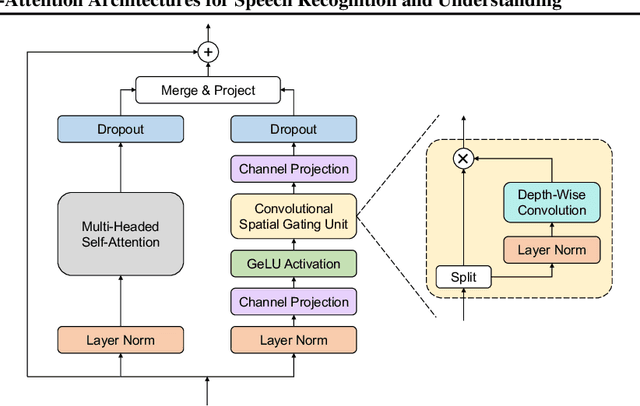
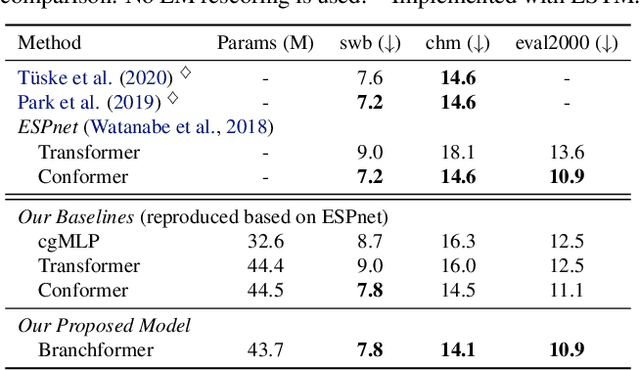
Conformer has proven to be effective in many speech processing tasks. It combines the benefits of extracting local dependencies using convolutions and global dependencies using self-attention. Inspired by this, we propose a more flexible, interpretable and customizable encoder alternative, Branchformer, with parallel branches for modeling various ranged dependencies in end-to-end speech processing. In each encoder layer, one branch employs self-attention or its variant to capture long-range dependencies, while the other branch utilizes an MLP module with convolutional gating (cgMLP) to extract local relationships. We conduct experiments on several speech recognition and spoken language understanding benchmarks. Results show that our model outperforms both Transformer and cgMLP. It also matches with or outperforms state-of-the-art results achieved by Conformer. Furthermore, we show various strategies to reduce computation thanks to the two-branch architecture, including the ability to have variable inference complexity in a single trained model. The weights learned for merging branches indicate how local and global dependencies are utilized in different layers, which benefits model designing.
A light-weight full-band speech enhancement model
Jul 03, 2022
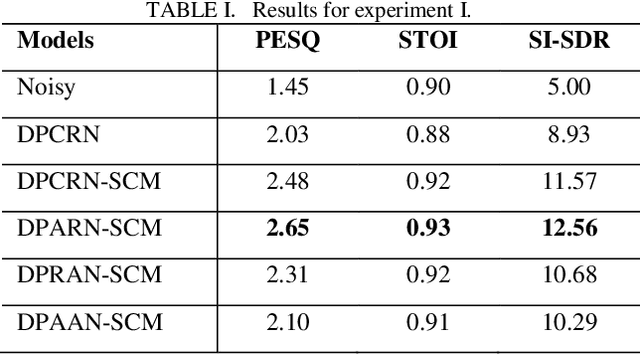
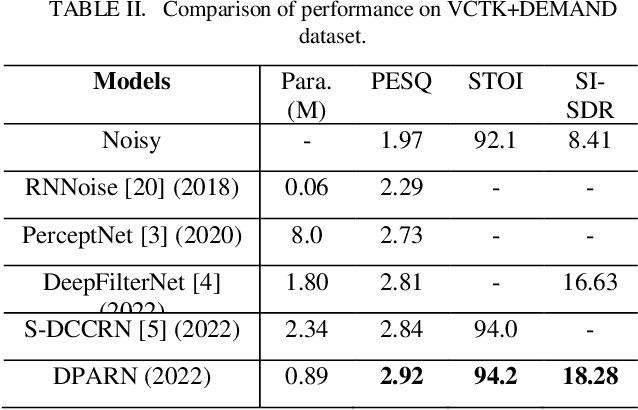
Deep neural network based full-band speech enhancement systems face challenges of high demand of computational resources and imbalanced frequency distribution. In this paper, a light-weight full-band model is proposed with two dedicated strategies, i.e., a learnable spectral compression mapping for more effective high-band spectral information compression, and the utilization of the multi-head attention mechanism for more effective modeling of the global spectral pattern. Experiments validate the efficacy of the proposed strategies and show that the proposed model achieves competitive performance with only 0.89M parameters.
TRILLsson: Distilled Universal Paralinguistic Speech Representations
Mar 20, 2022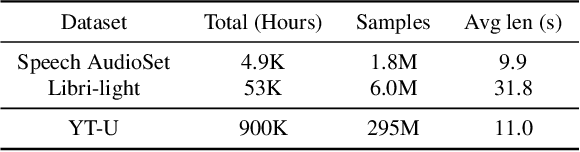
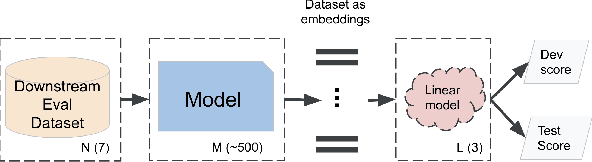
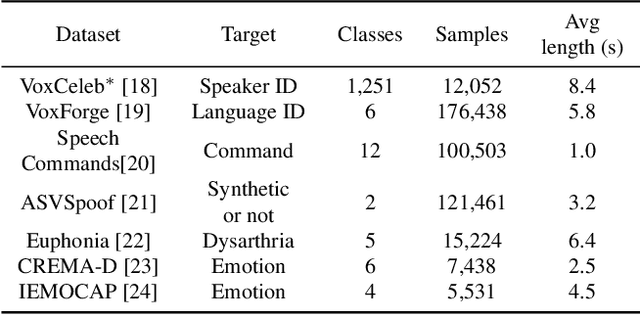
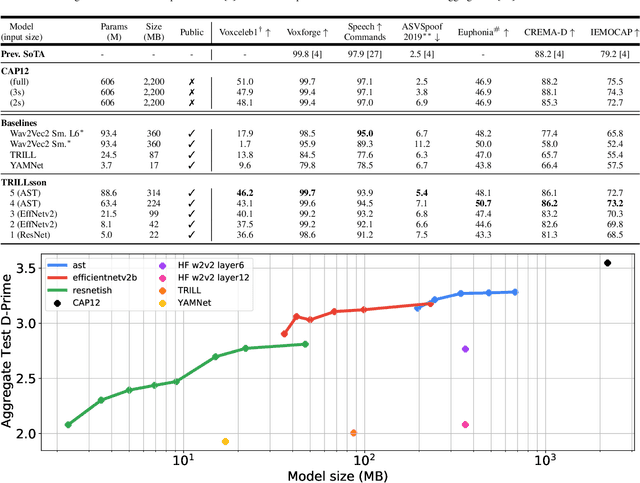
Recent advances in self-supervision have dramatically improved the quality of speech representations. However, deployment of state-of-the-art embedding models on devices has been restricted due to their limited public availability and large resource footprint. Our work addresses these issues by publicly releasing a collection of paralinguistic speech models that are small and near state-of-the-art performance. Our approach is based on knowledge distillation, and our models are distilled on public data only. We explore different architectures and thoroughly evaluate our models on the Non-Semantic Speech (NOSS) benchmark. Our largest distilled model is less than 15% the size of the original model (314MB vs 2.2GB), achieves over 96% the accuracy on 6 of 7 tasks, and is trained on 6.5% the data. The smallest model is 1% in size (22MB) and achieves over 90% the accuracy on 6 of 7 tasks. Our models outperform the open source Wav2Vec 2.0 model on 6 of 7 tasks, and our smallest model outperforms the open source Wav2Vec 2.0 on both emotion recognition tasks despite being 7% the size.
Contrastive Siamese Network for Semi-supervised Speech Recognition
May 27, 2022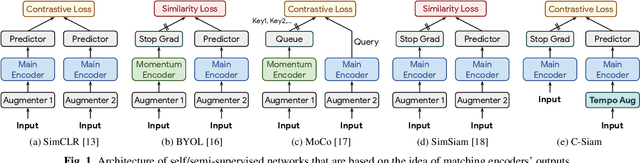
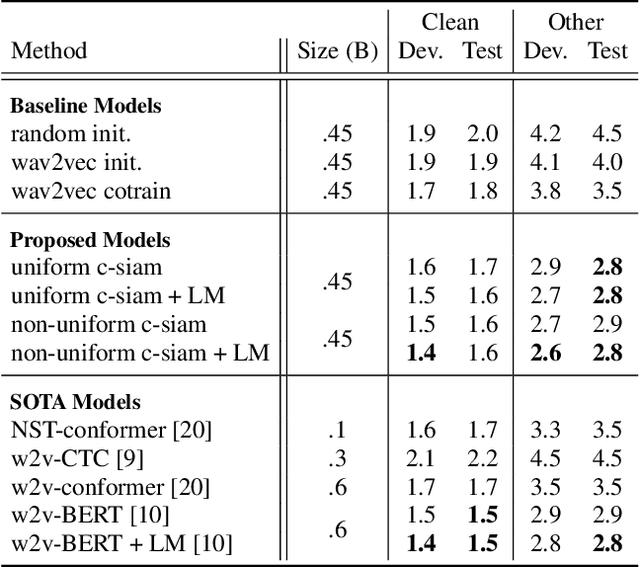
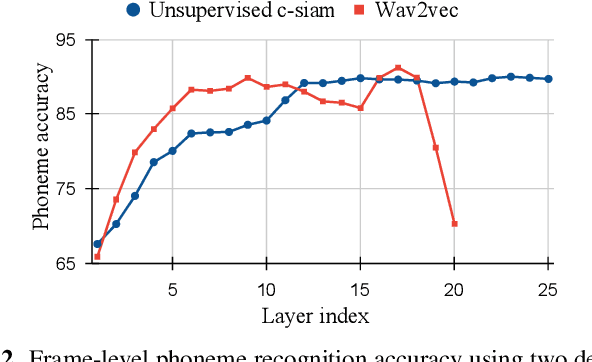
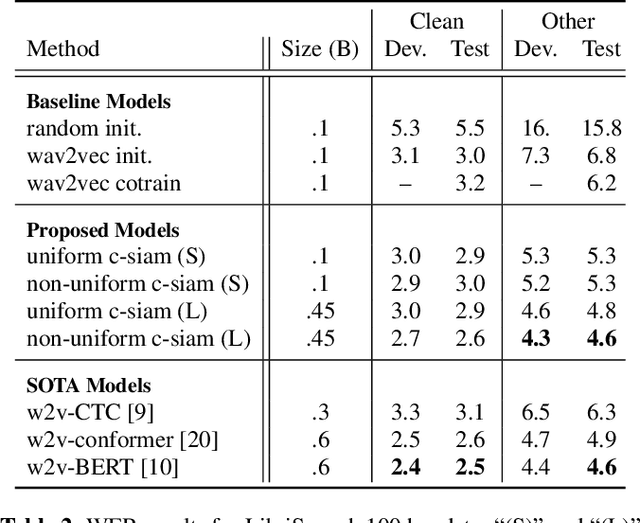
This paper introduces contrastive siamese (c-siam) network, an architecture for leveraging unlabeled acoustic data in speech recognition. c-siam is the first network that extracts high-level linguistic information from speech by matching outputs of two identical transformer encoders. It contains augmented and target branches which are trained by: (1) masking inputs and matching outputs with a contrastive loss, (2) incorporating a stop gradient operation on the target branch, (3) using an extra learnable transformation on the augmented branch, (4) introducing new temporal augment functions to prevent the shortcut learning problem. We use the Libri-light 60k unsupervised data and the LibriSpeech 100hrs/960hrs supervised data to compare c-siam and other best-performing systems. Our experiments show that c-siam provides 20% relative word error rate improvement over wav2vec baselines. A c-siam network with 450M parameters achieves competitive results compared to the state-of-the-art networks with 600M parameters.
Bootstrapping meaning through listening: Unsupervised learning of spoken sentence embeddings
Oct 23, 2022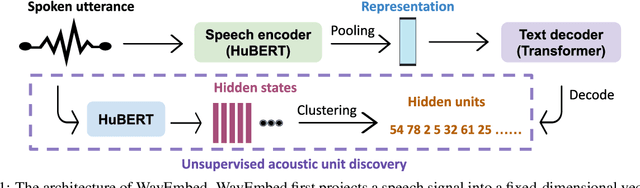
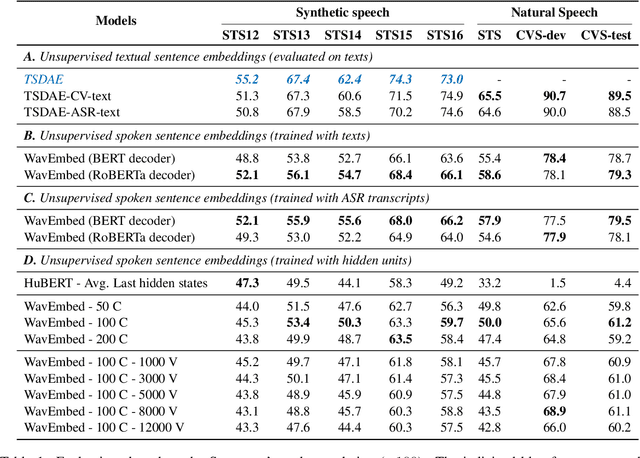
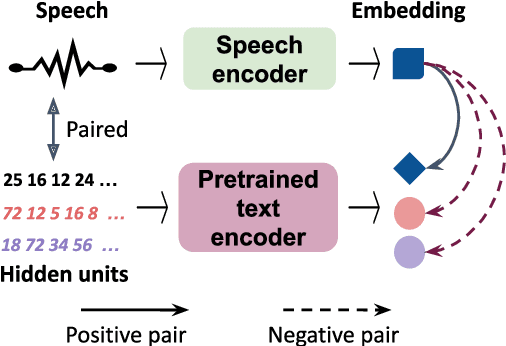
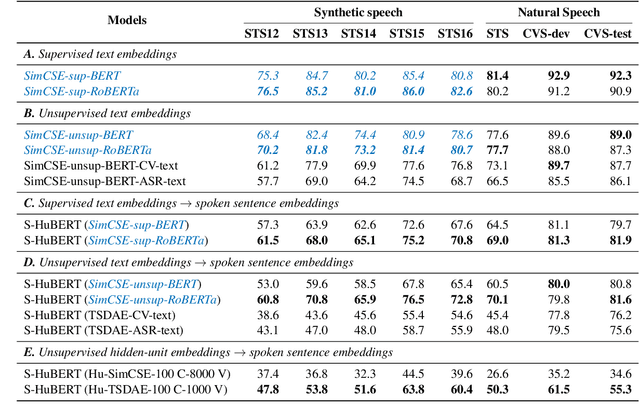
Inducing semantic representations directly from speech signals is a highly challenging task but has many useful applications in speech mining and spoken language understanding. This study tackles the unsupervised learning of semantic representations for spoken utterances. Through converting speech signals into hidden units generated from acoustic unit discovery, we propose WavEmbed, a multimodal sequential autoencoder that predicts hidden units from a dense representation of speech. Secondly, we also propose S-HuBERT to induce meaning through knowledge distillation, in which a sentence embedding model is first trained on hidden units and passes its knowledge to a speech encoder through contrastive learning. The best performing model achieves a moderate correlation (0.5~0.6) with human judgments, without relying on any labels or transcriptions. Furthermore, these models can also be easily extended to leverage textual transcriptions of speech to learn much better speech embeddings that are strongly correlated with human annotations. Our proposed methods are applicable to the development of purely data-driven systems for speech mining, indexing and search.
The Effectiveness of Time Stretching for Enhancing Dysarthric Speech for Improved Dysarthric Speech Recognition
Jan 13, 2022
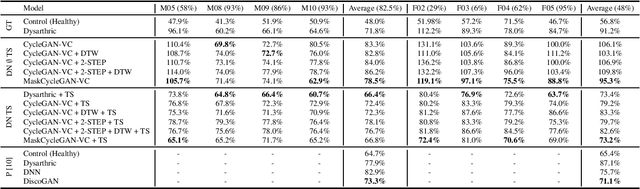
In this paper, we investigate several existing and a new state-of-the-art generative adversarial network-based (GAN) voice conversion method for enhancing dysarthric speech for improved dysarthric speech recognition. We compare key components of existing methods as part of a rigorous ablation study to find the most effective solution to improve dysarthric speech recognition. We find that straightforward signal processing methods such as stationary noise removal and vocoder-based time stretching lead to dysarthric speech recognition results comparable to those obtained when using state-of-the-art GAN-based voice conversion methods as measured using a phoneme recognition task. Additionally, our proposed solution of a combination of MaskCycleGAN-VC and time stretched enhancement is able to improve the phoneme recognition results for certain dysarthric speakers compared to our time stretched baseline.
Exploring Capabilities of Monolingual Audio Transformers using Large Datasets in Automatic Speech Recognition of Czech
Jun 15, 2022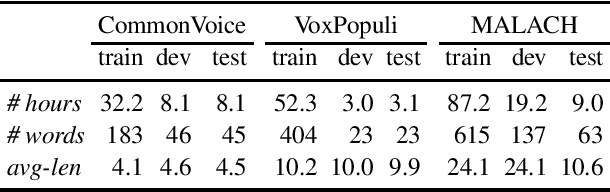


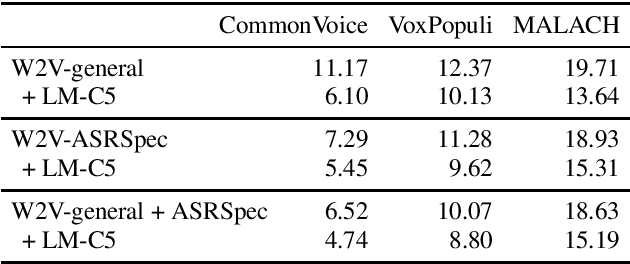
In this paper, we present our progress in pretraining Czech monolingual audio transformers from a large dataset containing more than 80 thousand hours of unlabeled speech, and subsequently fine-tuning the model on automatic speech recognition tasks using a combination of in-domain data and almost 6 thousand hours of out-of-domain transcribed speech. We are presenting a large palette of experiments with various fine-tuning setups evaluated on two public datasets (CommonVoice and VoxPopuli) and one extremely challenging dataset from the MALACH project. Our results show that monolingual Wav2Vec 2.0 models are robust ASR systems, which can take advantage of large labeled and unlabeled datasets and successfully compete with state-of-the-art LVCSR systems. Moreover, Wav2Vec models proved to be good zero-shot learners when no training data are available for the target ASR task.
Match to Win: Analysing Sequences Lengths for Efficient Self-supervised Learning in Speech and Audio
Oct 03, 2022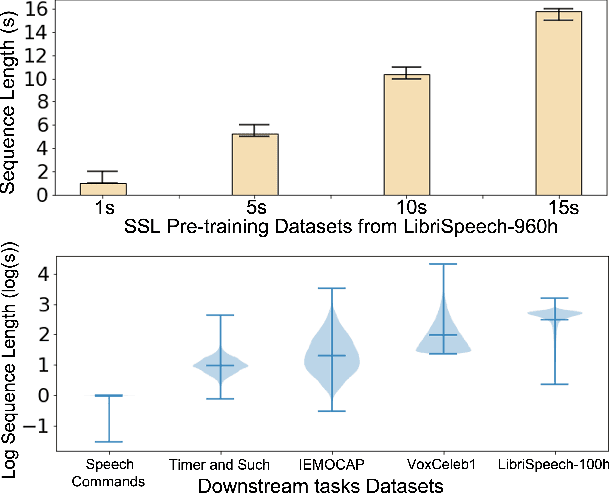

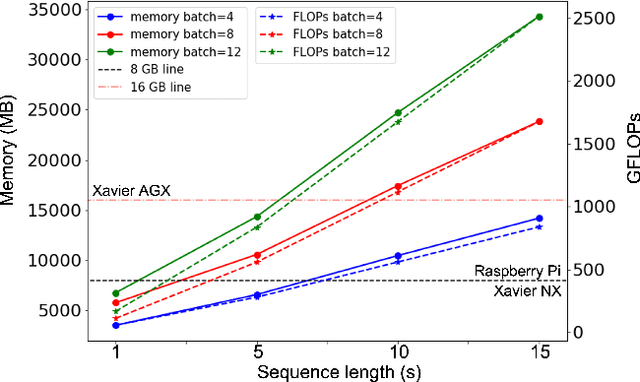
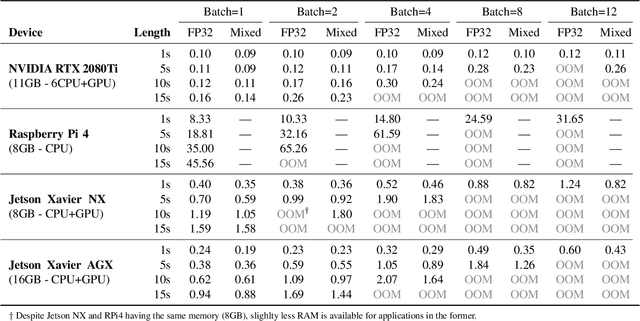
Self-supervised learning (SSL) has proven vital in speech and audio-related applications. The paradigm trains a general model on unlabeled data that can later be used to solve specific downstream tasks. This type of model is costly to train as it requires manipulating long input sequences that can only be handled by powerful centralised servers. Surprisingly, despite many attempts to increase training efficiency through model compression, the effects of truncating input sequence lengths to reduce computation have not been studied. In this paper, we provide the first empirical study of SSL pre-training for different specified sequence lengths and link this to various downstream tasks. We find that training on short sequences can dramatically reduce resource costs while retaining a satisfactory performance for all tasks. This simple one-line change would promote the migration of SSL training from data centres to user-end edge devices for more realistic and personalised applications.