 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Nonverbal Sound Detection for Disordered Speech
Feb 15, 2022
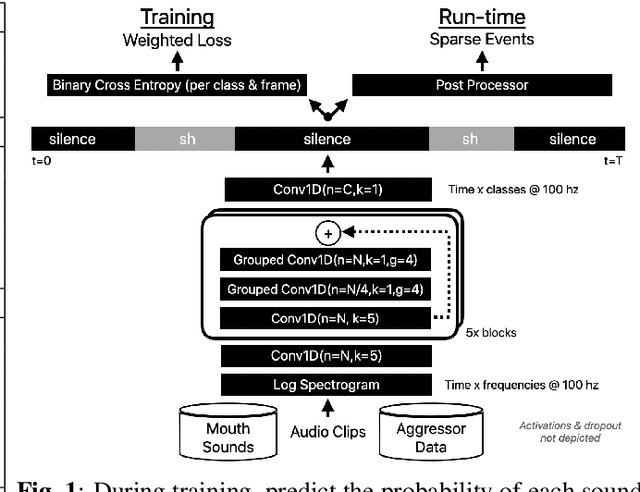
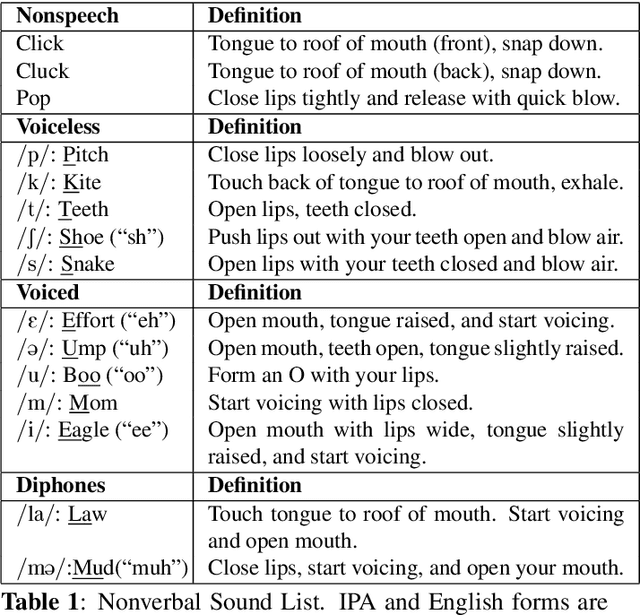
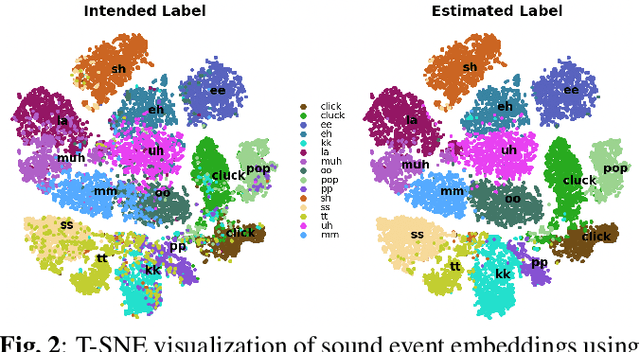
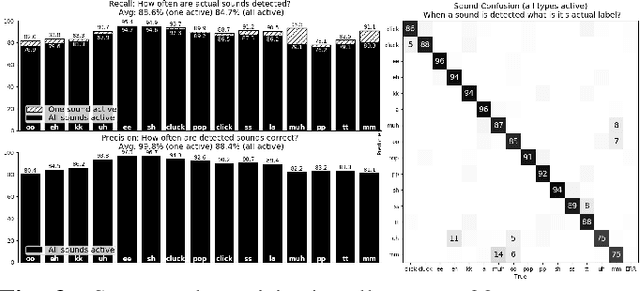
Voice assistants have become an essential tool for people with various disabilities because they enable complex phone- or tablet-based interactions without the need for fine-grained motor control, such as with touchscreens. However, these systems are not tuned for the unique characteristics of individuals with speech disorders, including many of those who have a motor-speech disorder, are deaf or hard of hearing, have a severe stutter, or are minimally verbal. We introduce an alternative voice-based input system which relies on sound event detection using fifteen nonverbal mouth sounds like "pop," "click," or "eh." This system was designed to work regardless of ones' speech abilities and allows full access to existing technology. In this paper, we describe the design of a dataset, model considerations for real-world deployment, and efforts towards model personalization. Our fully-supervised model achieves segment-level precision and recall of 88.6% and 88.4% on an internal dataset of 710 adults, while achieving 0.31 false positives per hour on aggressors such as speech. Five-shot personalization enables satisfactory performance in 84.5% of cases where the generic model fails.
Multi-Level Modeling Units for End-to-End Mandarin Speech Recognition
May 24, 2022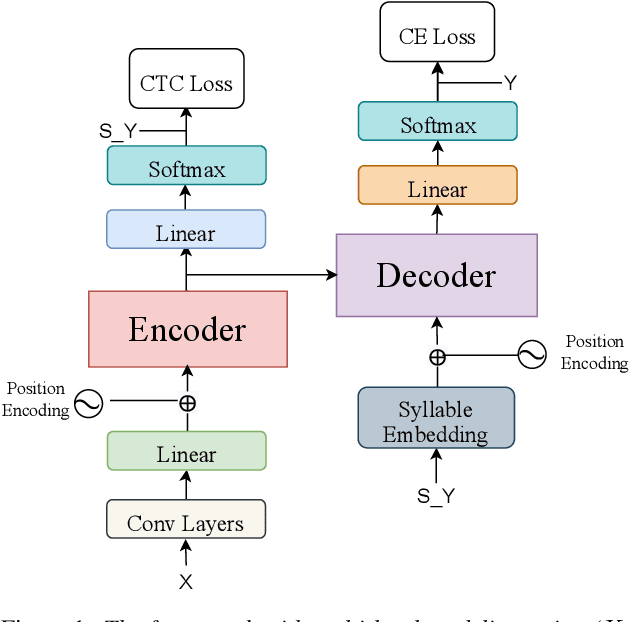

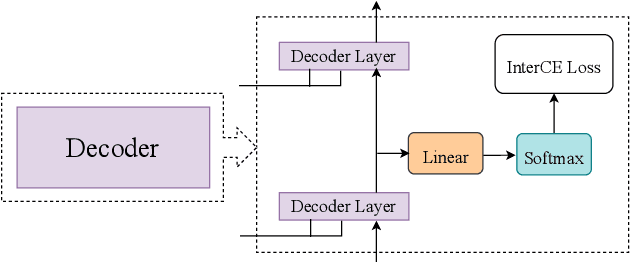
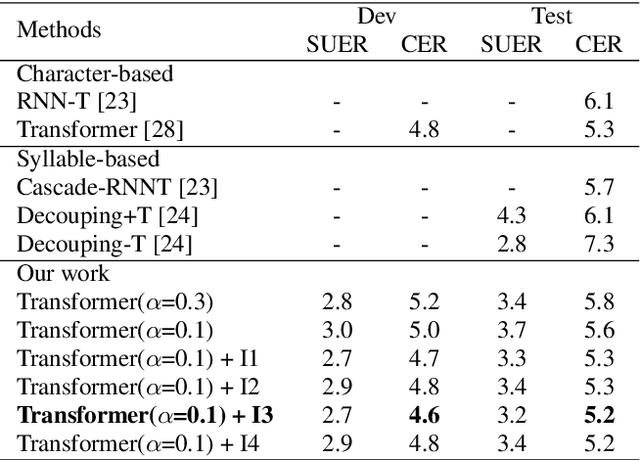
The choice of modeling units affects the performance of the acoustic modeling and plays an important role in automatic speech recognition (ASR). In mandarin scenarios, the Chinese characters represent meaning but are not directly related to the pronunciation. Thus only considering the writing of Chinese characters as modeling units is insufficient to capture speech features. In this paper, we present a novel method involves with multi-level modeling units, which integrates multi-level information for mandarin speech recognition. Specifically, the encoder block considers syllables as modeling units, and the decoder block deals with character modeling units. During inference, the input feature sequences are converted into syllable sequences by the encoder block and then converted into Chinese characters by the decoder block. This process is conducted by a unified end-to-end model without introducing additional conversion models. By introducing InterCE auxiliary task, our method achieves competitive results with CER of 4.1%/4.6% and 4.6%/5.2% on the widely used AISHELL-1 benchmark without a language model, using the Conformer and the Transformer backbones respectively.
Coarse-to-Fine Recursive Speech Separation for Unknown Number of Speakers
Mar 30, 2022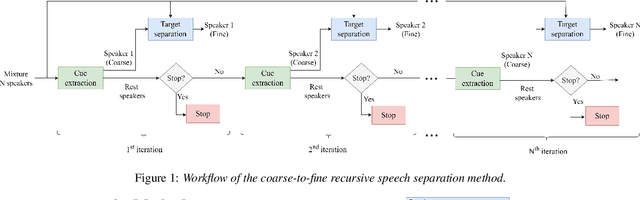
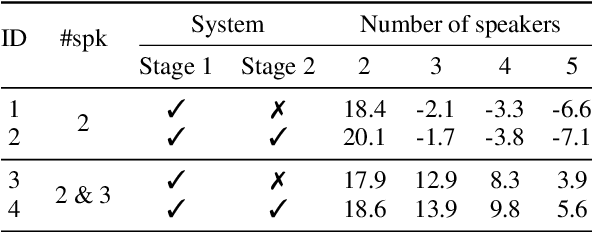
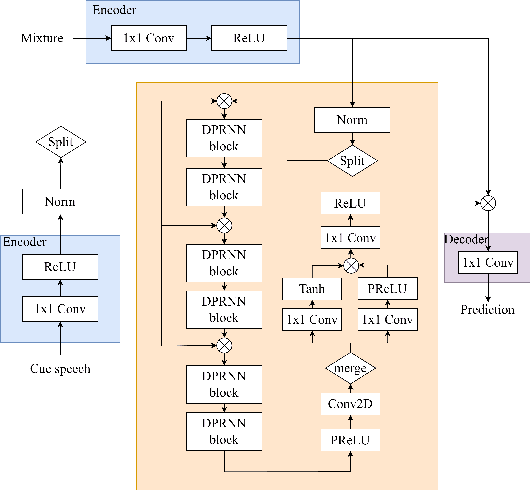
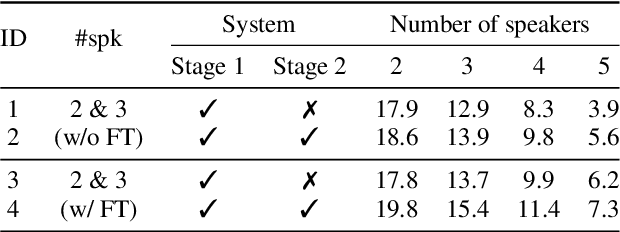
The vast majority of speech separation methods assume that the number of speakers is known in advance, hence they are specific to the number of speakers. By contrast, a more realistic and challenging task is to separate a mixture in which the number of speakers is unknown. This paper formulates the speech separation with the unknown number of speakers as a multi-pass source extraction problem and proposes a coarse-to-fine recursive speech separation method. This method comprises two stages, namely, recursive cue extraction and target speaker extraction. The recursive cue extraction stage determines how many computational iterations need to be performed and outputs a coarse cue speech by monitoring statistics in the mixture. As the number of recursive iterations increases, the accumulation of distortion eventually comes into the extracted speech and reminder. Therefore, in the second stage, we use a target speaker extraction network to extract a fine speech based on the coarse target cue and the original distortionless mixture. Experiments show that the proposed method archived state-of-the-art performance on the WSJ0 dataset with a different number of speakers. Furthermore, it generalizes well to an unseen large number of speakers.
Scaling Laws for Generative Mixed-Modal Language Models
Jan 10, 2023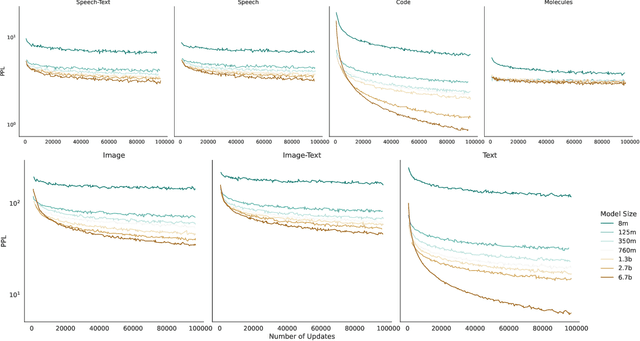
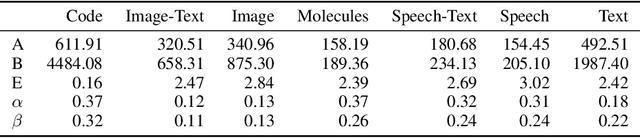
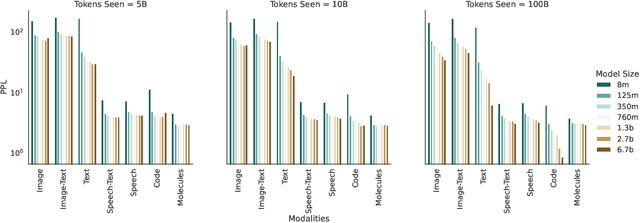
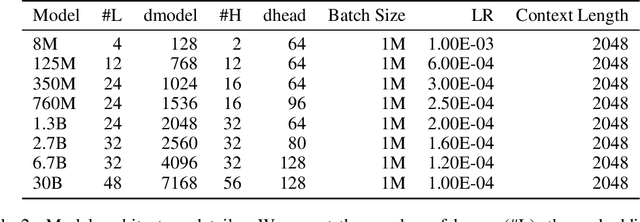
Generative language models define distributions over sequences of tokens that can represent essentially any combination of data modalities (e.g., any permutation of image tokens from VQ-VAEs, speech tokens from HuBERT, BPE tokens for language or code, and so on). To better understand the scaling properties of such mixed-modal models, we conducted over 250 experiments using seven different modalities and model sizes ranging from 8 million to 30 billion, trained on 5-100 billion tokens. We report new mixed-modal scaling laws that unify the contributions of individual modalities and the interactions between them. Specifically, we explicitly model the optimal synergy and competition due to data and model size as an additive term to previous uni-modal scaling laws. We also find four empirical phenomena observed during the training, such as emergent coordinate-ascent style training that naturally alternates between modalities, guidelines for selecting critical hyper-parameters, and connections between mixed-modal competition and training stability. Finally, we test our scaling law by training a 30B speech-text model, which significantly outperforms the corresponding unimodal models. Overall, our research provides valuable insights into the design and training of mixed-modal generative models, an important new class of unified models that have unique distributional properties.
What can Speech and Language Tell us About the Working Alliance in Psychotherapy
Jun 17, 2022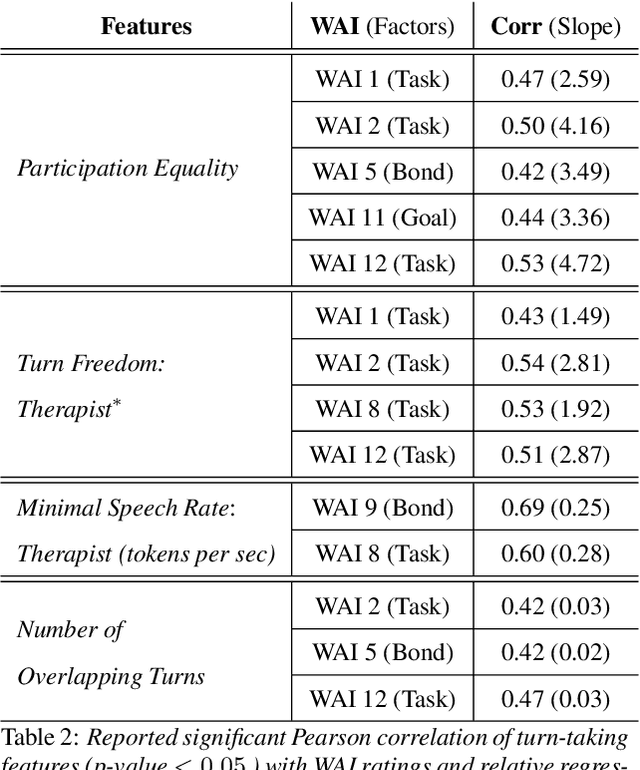
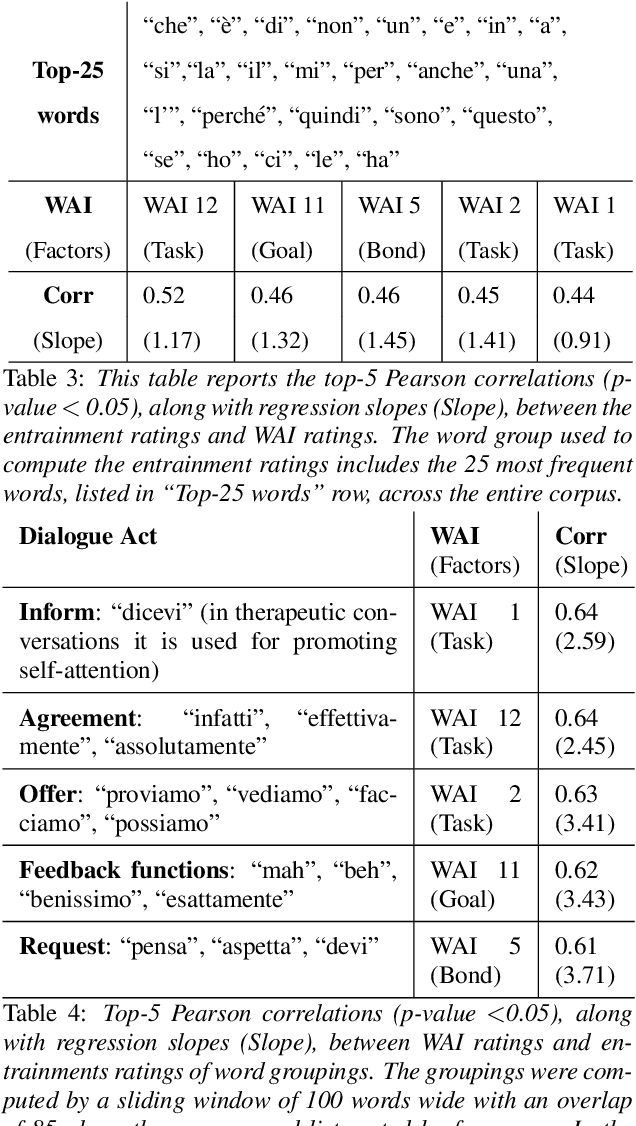
We are interested in the problem of conversational analysis and its application to the health domain. Cognitive Behavioral Therapy is a structured approach in psychotherapy, allowing the therapist to help the patient to identify and modify the malicious thoughts, behavior, or actions. This cooperative effort can be evaluated using the Working Alliance Inventory Observer-rated Shortened - a 12 items inventory covering task, goal, and relationship - which has a relevant influence on therapeutic outcomes. In this work, we investigate the relation between this alliance inventory and the spoken conversations (sessions) between the patient and the psychotherapist. We have delivered eight weeks of e-therapy, collected their audio and video call sessions, and manually transcribed them. The spoken conversations have been annotated and evaluated with WAI ratings by professional therapists. We have investigated speech and language features and their association with WAI items. The feature types include turn dynamics, lexical entrainment, and conversational descriptors extracted from the speech and language signals. Our findings provide strong evidence that a subset of these features are strong indicators of working alliance. To the best of our knowledge, this is the first and a novel study to exploit speech and language for characterising working alliance.
ERNIE-Music: Text-to-Waveform Music Generation with Diffusion Models
Feb 09, 2023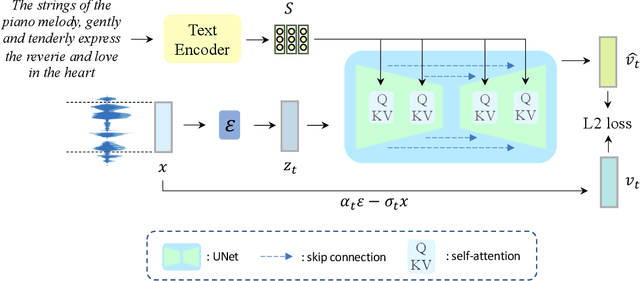

In recent years, there has been an increased popularity in image and speech generation using diffusion models. However, directly generating music waveforms from free-form text prompts is still under-explored. In this paper, we propose the first text-to-waveform music generation model that can receive arbitrary texts using diffusion models. We incorporate the free-form textual prompt as the condition to guide the waveform generation process of diffusion models. To solve the problem of lacking such text-music parallel data, we collect a dataset of text-music pairs from the Internet with weak supervision. Besides, we compare the effect of two prompt formats of conditioning texts (music tags and free-form texts) and prove the superior performance of our method in terms of text-music relevance. We further demonstrate that our generated music in the waveform domain outperforms previous works by a large margin in terms of diversity, quality, and text-music relevance.
A light-weight full-band speech enhancement model
Jun 29, 2022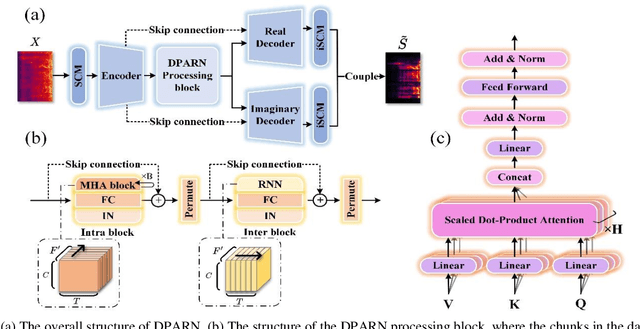
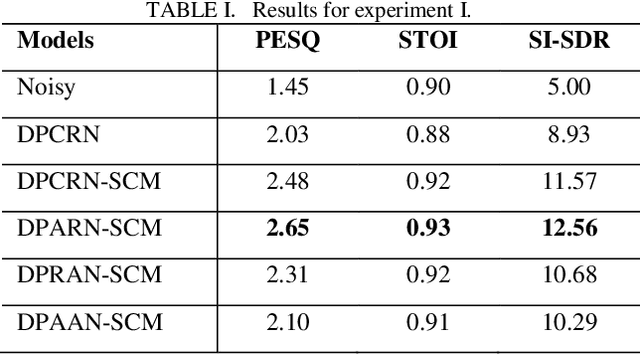
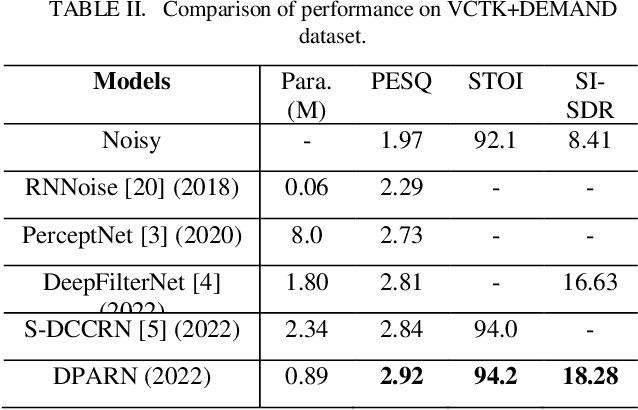
Deep neural network based full-band speech enhancement systems face challenges of high demand of computational resources and imbalanced frequency distribution. In this paper, a light-weight full-band model is proposed with two dedicated strategies, i.e., a learnable spectral compression mapping for more effective high-band spectral information compression, and the utilization of the multi-head attention mechanism for more effective modeling of the global spectral pattern. Experiments validate the efficacy of the proposed strategies and show that the proposed model achieves competitive performance with only 0.89M parameters.
How Much Hate with #china? A Preliminary Analysis on China-related Hateful Tweets Two Years After the Covid Pandemic Began
Nov 11, 2022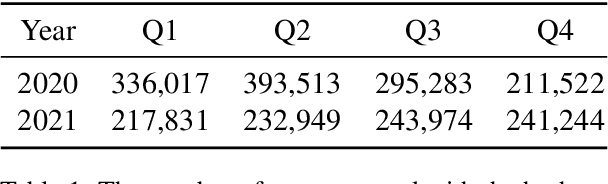
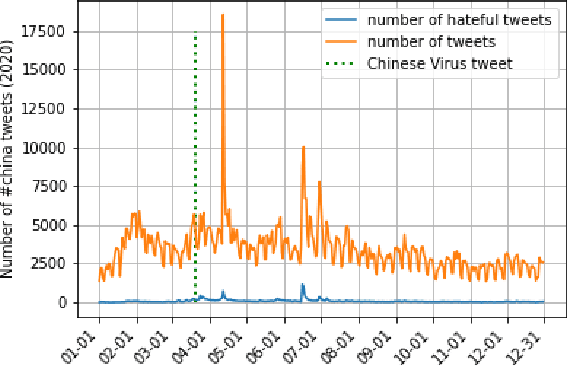

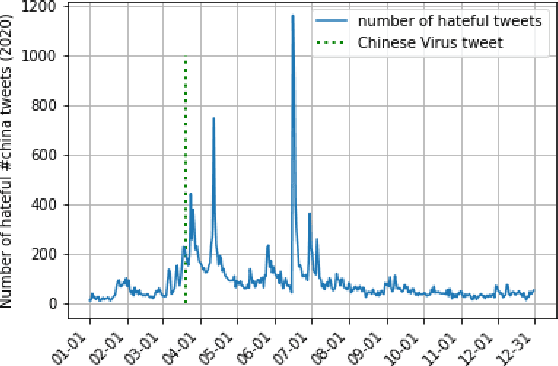
Following the outbreak of a global pandemic, online content is filled with hate speech. Donald Trump's ''Chinese Virus'' tweet shifted the blame for the spread of the Covid-19 virus to China and the Chinese people, which triggered a new round of anti-China hate both online and offline. This research intends to examine China-related hate speech on Twitter during the two years following the burst of the pandemic (2020 and 2021). Through Twitter's API, in total 2,172,333 tweets hashtagged #china posted during the time were collected. By employing multiple state-of-the-art pretrained language models for hate speech detection, we identify a wide range of hate of various types, resulting in an automatically labeled anti-China hate speech dataset. We identify a hateful rate in #china tweets of 2.5% in 2020 and 1.9% in 2021. This is well above the average rate of online hate speech on Twitter at 0.6% identified in Gao et al., 2017. We further analyzed the longitudinal development of #china tweets and those identified as hateful in 2020 and 2021 through visualizing the daily number and hate rate over the two years. Our keyword analysis of hate speech in #china tweets reveals the most frequently mentioned terms in the hateful #china tweets, which can be used for further social science studies.
Proactively Reducing the Hate Intensity of Online Posts via Hate Speech Normalization
Jun 08, 2022
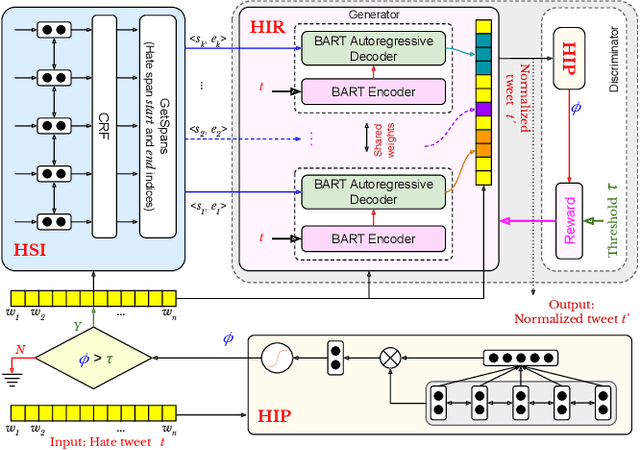
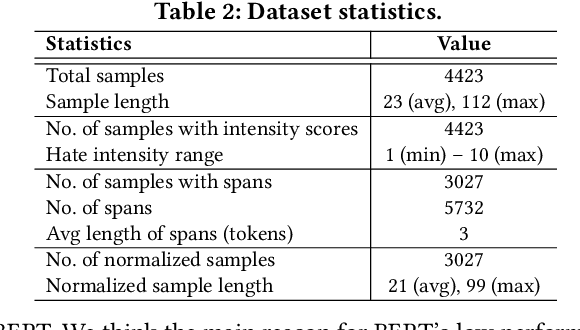
Curbing online hate speech has become the need of the hour; however, a blanket ban on such activities is infeasible for several geopolitical and cultural reasons. To reduce the severity of the problem, in this paper, we introduce a novel task, hate speech normalization, that aims to weaken the intensity of hatred exhibited by an online post. The intention of hate speech normalization is not to support hate but instead to provide the users with a stepping stone towards non-hate while giving online platforms more time to monitor any improvement in the user's behavior. To this end, we manually curated a parallel corpus - hate texts and their normalized counterparts (a normalized text is less hateful and more benign). We introduce NACL, a simple yet efficient hate speech normalization model that operates in three stages - first, it measures the hate intensity of the original sample; second, it identifies the hate span(s) within it; and finally, it reduces hate intensity by paraphrasing the hate spans. We perform extensive experiments to measure the efficacy of NACL via three-way evaluation (intrinsic, extrinsic, and human-study). We observe that NACL outperforms six baselines - NACL yields a score of 0.1365 RMSE for the intensity prediction, 0.622 F1-score in the span identification, and 82.27 BLEU and 80.05 perplexity for the normalized text generation. We further show the generalizability of NACL across other platforms (Reddit, Facebook, Gab). An interactive prototype of NACL was put together for the user study. Further, the tool is being deployed in a real-world setting at Wipro AI as a part of its mission to tackle harmful content on online platforms.
Defending against Adversarial Audio via Diffusion Model
Mar 02, 2023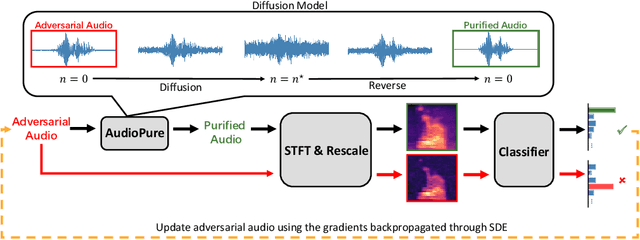

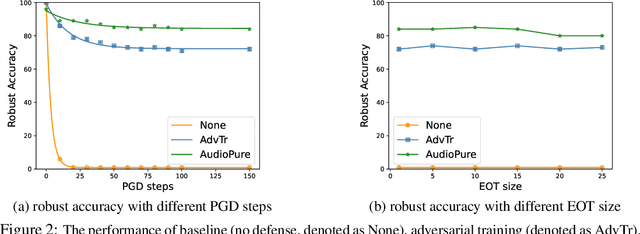

Deep learning models have been widely used in commercial acoustic systems in recent years. However, adversarial audio examples can cause abnormal behaviors for those acoustic systems, while being hard for humans to perceive. Various methods, such as transformation-based defenses and adversarial training, have been proposed to protect acoustic systems from adversarial attacks, but they are less effective against adaptive attacks. Furthermore, directly applying the methods from the image domain can lead to suboptimal results because of the unique properties of audio data. In this paper, we propose an adversarial purification-based defense pipeline, AudioPure, for acoustic systems via off-the-shelf diffusion models. Taking advantage of the strong generation ability of diffusion models, AudioPure first adds a small amount of noise to the adversarial audio and then runs the reverse sampling step to purify the noisy audio and recover clean audio. AudioPure is a plug-and-play method that can be directly applied to any pretrained classifier without any fine-tuning or re-training. We conduct extensive experiments on speech command recognition task to evaluate the robustness of AudioPure. Our method is effective against diverse adversarial attacks (e.g. $\mathcal{L}_2$ or $\mathcal{L}_\infty$-norm). It outperforms the existing methods under both strong adaptive white-box and black-box attacks bounded by $\mathcal{L}_2$ or $\mathcal{L}_\infty$-norm (up to +20\% in robust accuracy). Besides, we also evaluate the certified robustness for perturbations bounded by $\mathcal{L}_2$-norm via randomized smoothing. Our pipeline achieves a higher certified accuracy than baselines.