 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Remap, warp and attend: Non-parallel many-to-many accent conversion with Normalizing Flows
Nov 10, 2022
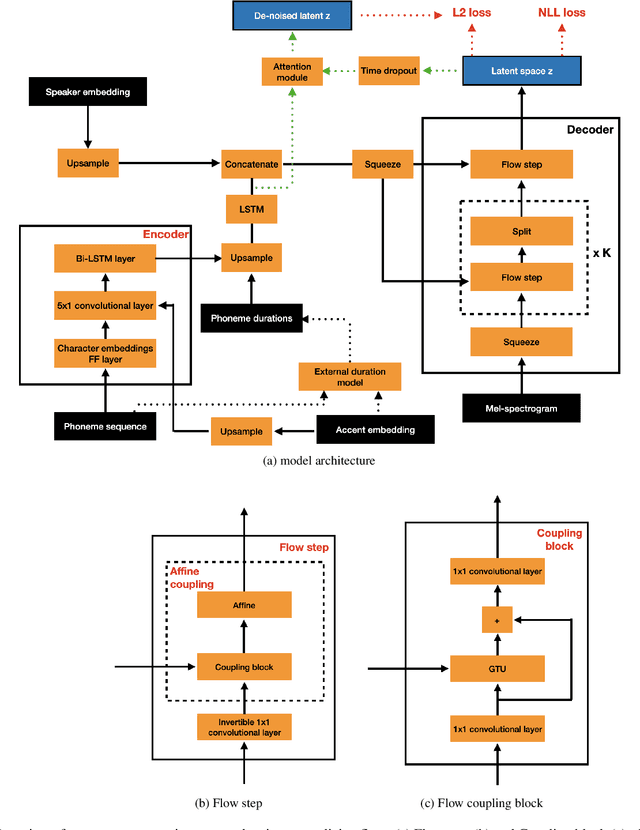

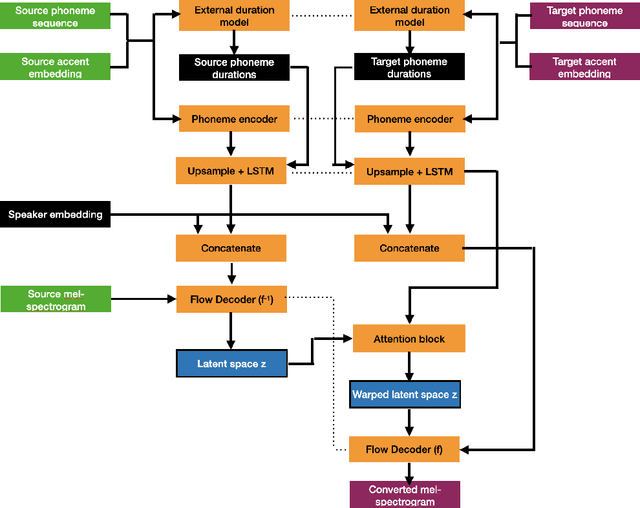

Regional accents of the same language affect not only how words are pronounced (i.e., phonetic content), but also impact prosodic aspects of speech such as speaking rate and intonation. This paper investigates a novel flow-based approach to accent conversion using normalizing flows. The proposed approach revolves around three steps: remapping the phonetic conditioning, to better match the target accent, warping the duration of the converted speech, to better suit the target phonemes, and an attention mechanism that implicitly aligns source and target speech sequences. The proposed remap-warp-attend system enables adaptation of both phonetic and prosodic aspects of speech while allowing for source and converted speech signals to be of different lengths. Objective and subjective evaluations show that the proposed approach significantly outperforms a competitive CopyCat baseline model in terms of similarity to the target accent, naturalness and intelligibility.
mSLAM: Massively multilingual joint pre-training for speech and text
Feb 03, 2022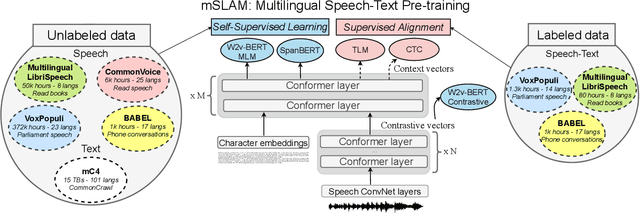
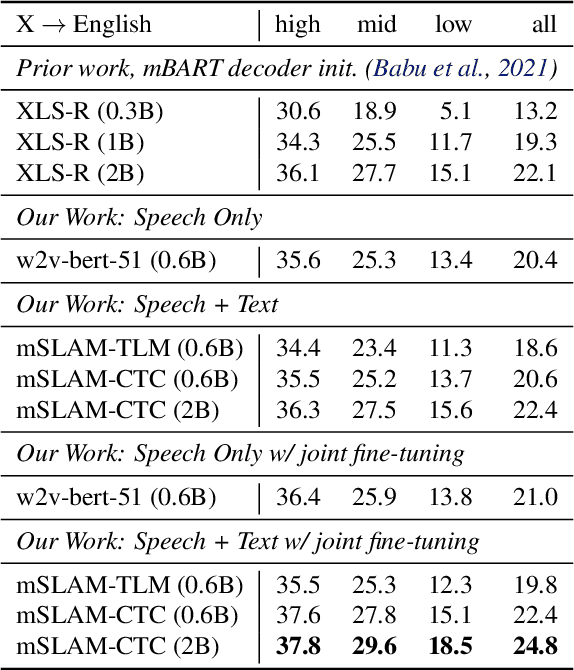
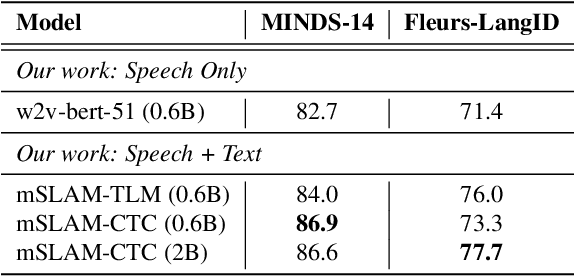
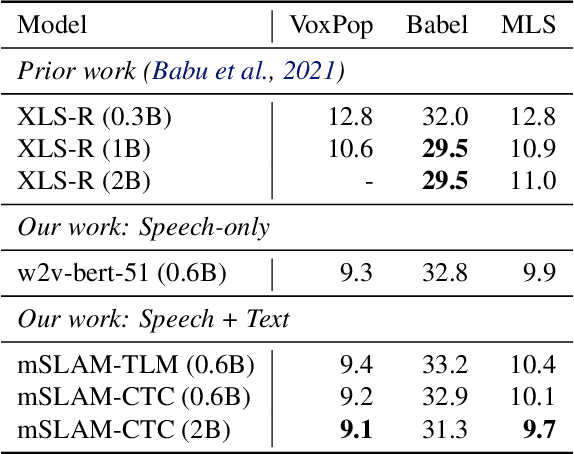
We present mSLAM, a multilingual Speech and LAnguage Model that learns cross-lingual cross-modal representations of speech and text by pre-training jointly on large amounts of unlabeled speech and text in multiple languages. mSLAM combines w2v-BERT pre-training on speech with SpanBERT pre-training on character-level text, along with Connectionist Temporal Classification (CTC) losses on paired speech and transcript data, to learn a single model capable of learning from and representing both speech and text signals in a shared representation space. We evaluate mSLAM on several downstream speech understanding tasks and find that joint pre-training with text improves quality on speech translation, speech intent classification and speech language-ID while being competitive on multilingual ASR, when compared against speech-only pre-training. Our speech translation model demonstrates zero-shot text translation without seeing any text translation data, providing evidence for cross-modal alignment of representations. mSLAM also benefits from multi-modal fine-tuning, further improving the quality of speech translation by directly leveraging text translation data during the fine-tuning process. Our empirical analysis highlights several opportunities and challenges arising from large-scale multimodal pre-training, suggesting directions for future research.
A$^3$T: Alignment-Aware Acoustic and Text Pretraining for Speech Synthesis and Editing
Mar 18, 2022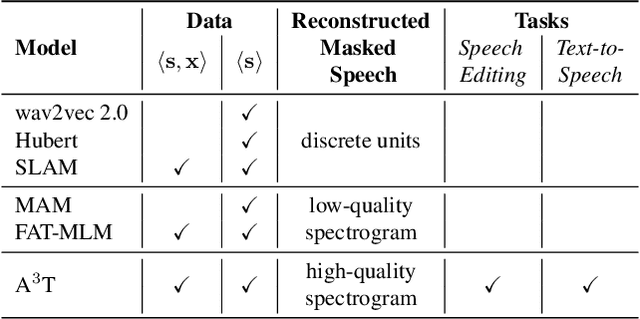

Recently, speech representation learning has improved many speech-related tasks such as speech recognition, speech classification, and speech-to-text translation. However, all the above tasks are in the direction of speech understanding, but for the inverse direction, speech synthesis, the potential of representation learning is yet to be realized, due to the challenging nature of generating high-quality speech. To address this problem, we propose our framework, Alignment-Aware Acoustic-Text Pretraining (A$^3$T), which reconstructs masked acoustic signals with text input and acoustic-text alignment during training. In this way, the pretrained model can generate high quality of reconstructed spectrogram, which can be applied to the speech editing and unseen speaker TTS directly. Experiments show A$^3$T outperforms SOTA models on speech editing, and improves multi-speaker speech synthesis without the external speaker verification model.
Receptive Field Analysis of Temporal Convolutional Networks for Monaural Speech Dereverberation
Apr 14, 2022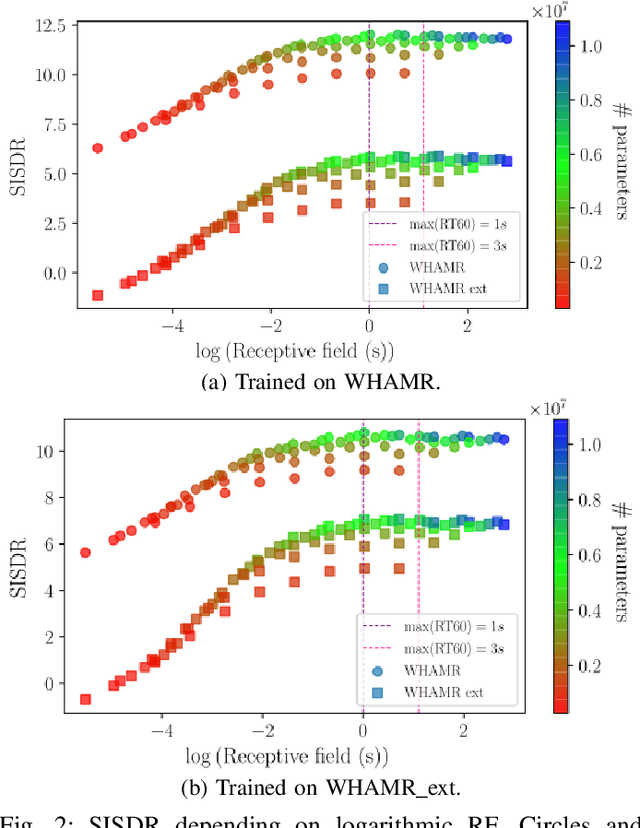
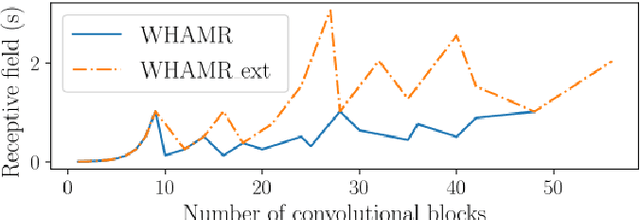
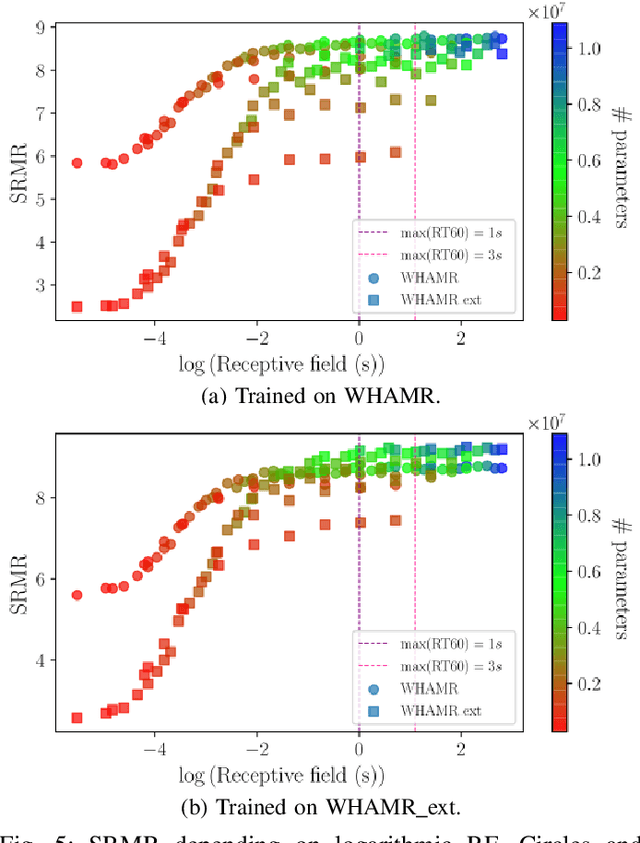
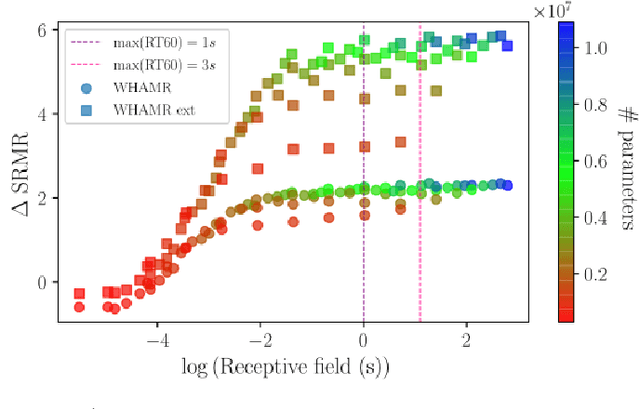
Speech dereverberation is often an important requirement in robust speech processing tasks. Supervised deep learning (DL) models give state-of-the-art performance for single-channel speech dereverberation. Temporal convolutional networks (TCNs) are commonly used for sequence modelling in speech enhancement tasks. A feature of TCNs is that they have a receptive field (RF) dependant on the specific model configuration which determines the number of input frames that can be observed to produce an individual output frame. It has been shown that TCNs are capable of performing dereverberation of simulated speech data, however a thorough analysis, especially with focus on the RF is yet lacking in the literature. This paper analyses dereverberation performance depending on the model size and the RF of TCNs. Experiments using the WHAMR corpus which is extended to include room impulse responses (RIRs) with larger T60 values demonstrate that a larger RF can have significant improvement in performance when training smaller TCN models. It is also demonstrated that TCNs benefit from a wider RF when dereverberating RIRs with larger RT60 values.
Predicting non-native speech perception using the Perceptual Assimilation Model and state-of-the-art acoustic models
May 31, 2022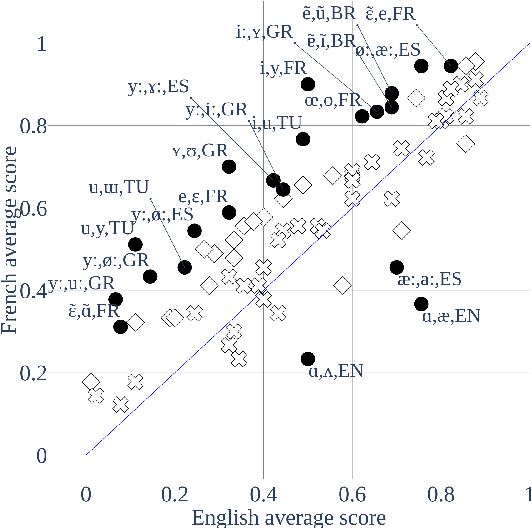
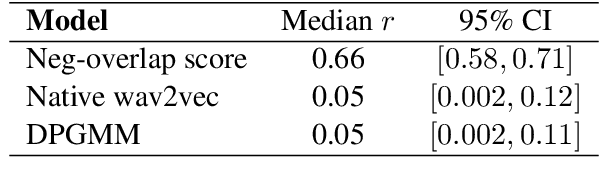
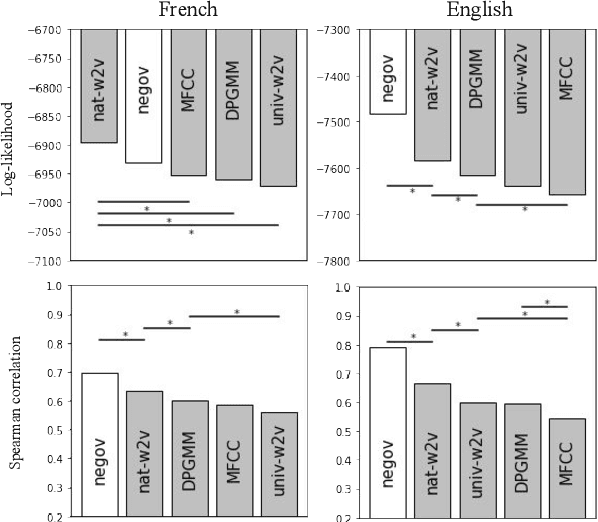

Our native language influences the way we perceive speech sounds, affecting our ability to discriminate non-native sounds. We compare two ideas about the influence of the native language on speech perception: the Perceptual Assimilation Model, which appeals to a mental classification of sounds into native phoneme categories, versus the idea that rich, fine-grained phonetic representations tuned to the statistics of the native language, are sufficient. We operationalize this idea using representations from two state-of-the-art speech models, a Dirichlet process Gaussian mixture model and the more recent wav2vec 2.0 model. We present a new, open dataset of French- and English-speaking participants' speech perception behaviour for 61 vowel sounds from six languages. We show that phoneme assimilation is a better predictor than fine-grained phonetic modelling, both for the discrimination behaviour as a whole, and for predicting differences in discriminability associated with differences in native language background. We also show that wav2vec 2.0, while not good at capturing the effects of native language on speech perception, is complementary to information about native phoneme assimilation, and provides a good model of low-level phonetic representations, supporting the idea that both categorical and fine-grained perception are used during speech perception.
Highly Generalizable Models for Multilingual Hate Speech Detection
Jan 27, 2022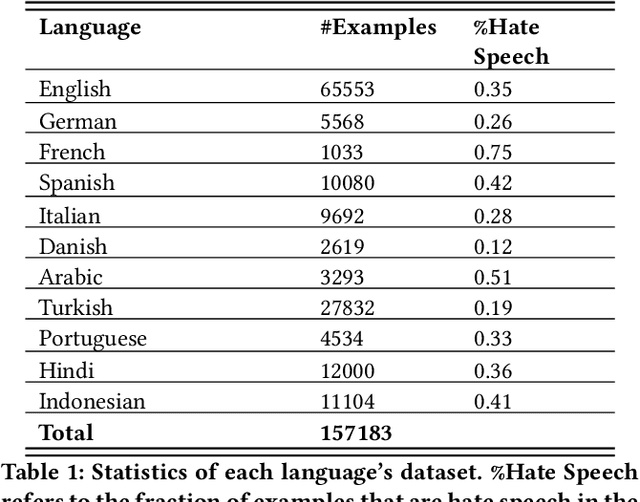
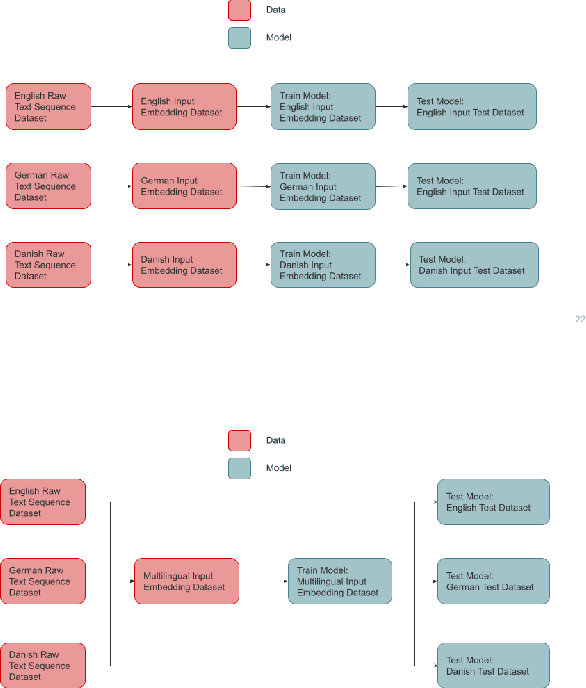

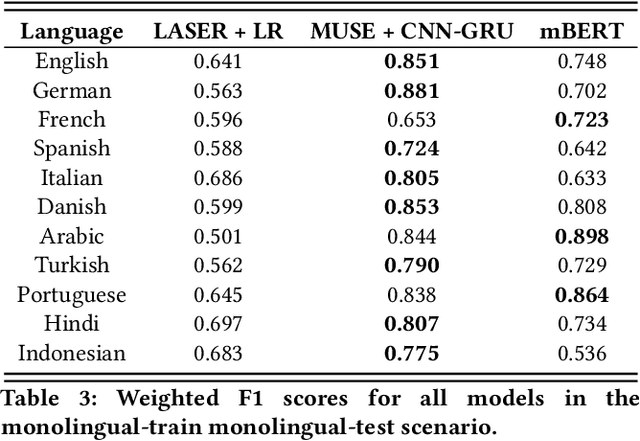
Hate speech detection has become an important research topic within the past decade. More private corporations are needing to regulate user generated content on different platforms across the globe. In this paper, we introduce a study of multilingual hate speech classification. We compile a dataset of 11 languages and resolve different taxonomies by analyzing the combined data with binary labels: hate speech or not hate speech. Defining hate speech in a single way across different languages and datasets may erase cultural nuances to the definition, therefore, we utilize language agnostic embeddings provided by LASER and MUSE in order to develop models that can use a generalized definition of hate speech across datasets. Furthermore, we evaluate prior state of the art methodologies for hate speech detection under our expanded dataset. We conduct three types of experiments for a binary hate speech classification task: Multilingual-Train Monolingual-Test, MonolingualTrain Monolingual-Test and Language-Family-Train Monolingual Test scenarios to see if performance increases for each language due to learning more from other language data.
Deep Learning Approach for Classifying the Aggressive Comments on Social Media: Machine Translated Data Vs Real Life Data
Mar 13, 2023
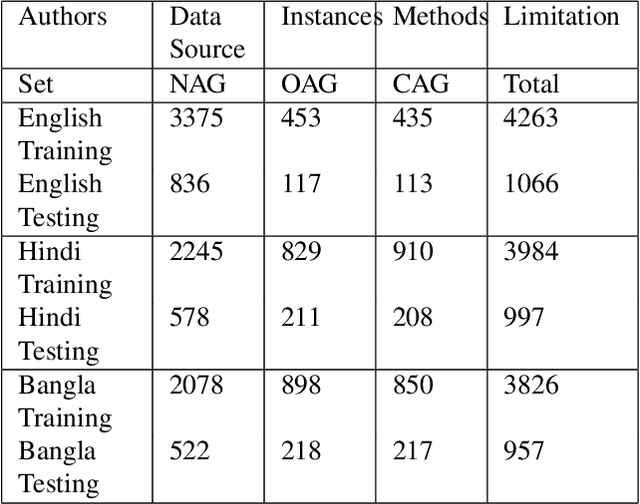
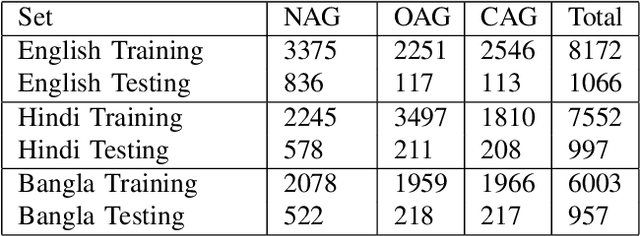

Aggressive comments on social media negatively impact human life. Such offensive contents are responsible for depression and suicidal-related activities. Since online social networking is increasing day by day, the hate content is also increasing. Several investigations have been done on the domain of cyberbullying, cyberaggression, hate speech, etc. The majority of the inquiry has been done in the English language. Some languages (Hindi and Bangla) still lack proper investigations due to the lack of a dataset. This paper particularly worked on the Hindi, Bangla, and English datasets to detect aggressive comments and have shown a novel way of generating machine-translated data to resolve data unavailability issues. A fully machine-translated English dataset has been analyzed with the models such as the Long Short term memory model (LSTM), Bidirectional Long-short term memory model (BiLSTM), LSTM-Autoencoder, word2vec, Bidirectional Encoder Representations from Transformers (BERT), and generative pre-trained transformer (GPT-2) to make an observation on how the models perform on a machine-translated noisy dataset. We have compared the performance of using the noisy data with two more datasets such as raw data, which does not contain any noises, and semi-noisy data, which contains a certain amount of noisy data. We have classified both the raw and semi-noisy data using the aforementioned models. To evaluate the performance of the models, we have used evaluation metrics such as F1-score,accuracy, precision, and recall. We have achieved the highest accuracy on raw data using the gpt2 model, semi-noisy data using the BERT model, and fully machine-translated data using the BERT model. Since many languages do not have proper data availability, our approach will help researchers create machine-translated datasets for several analysis purposes.
Multilingual Content Moderation: A Case Study on Reddit
Feb 19, 2023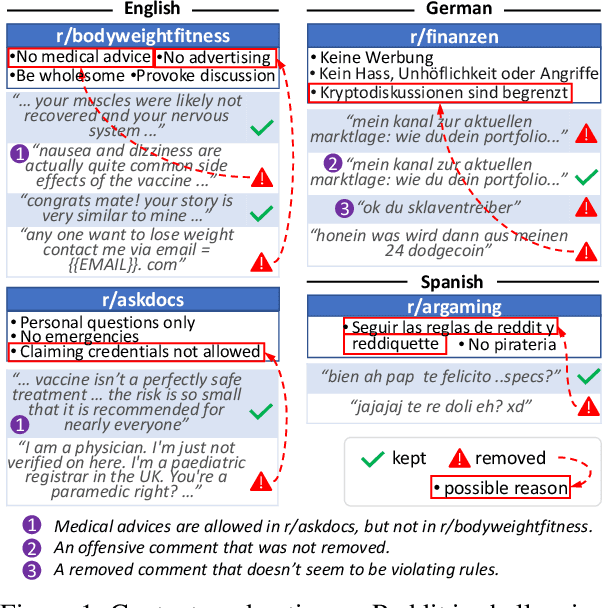
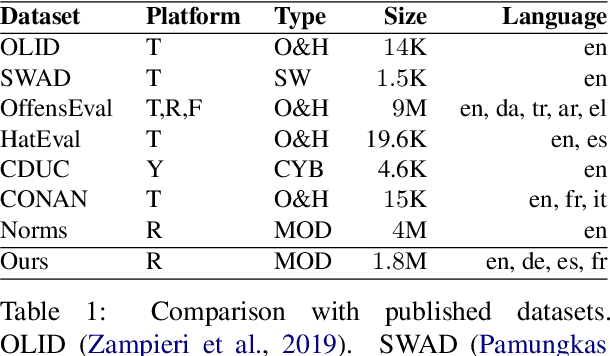
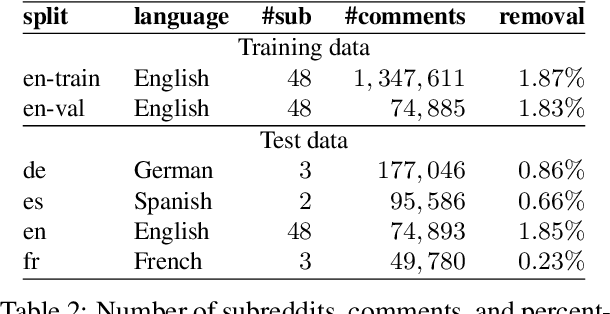
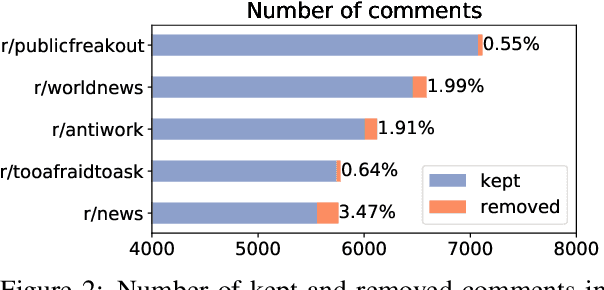
Content moderation is the process of flagging content based on pre-defined platform rules. There has been a growing need for AI moderators to safeguard users as well as protect the mental health of human moderators from traumatic content. While prior works have focused on identifying hateful/offensive language, they are not adequate for meeting the challenges of content moderation since 1) moderation decisions are based on violation of rules, which subsumes detection of offensive speech, and 2) such rules often differ across communities which entails an adaptive solution. We propose to study the challenges of content moderation by introducing a multilingual dataset of 1.8 Million Reddit comments spanning 56 subreddits in English, German, Spanish and French. We perform extensive experimental analysis to highlight the underlying challenges and suggest related research problems such as cross-lingual transfer, learning under label noise (human biases), transfer of moderation models, and predicting the violated rule. Our dataset and analysis can help better prepare for the challenges and opportunities of auto moderation.
DDS: A new device-degraded speech dataset for speech enhancement
Sep 21, 2021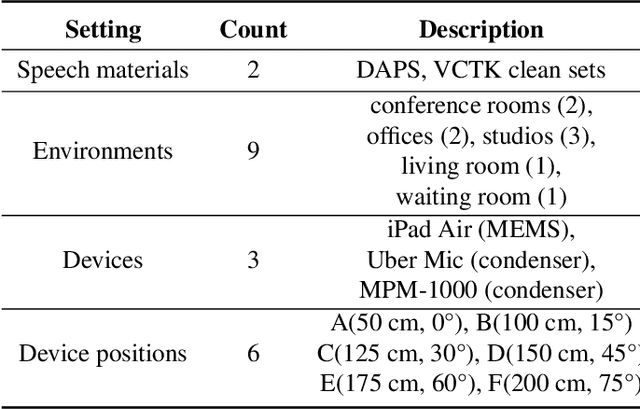
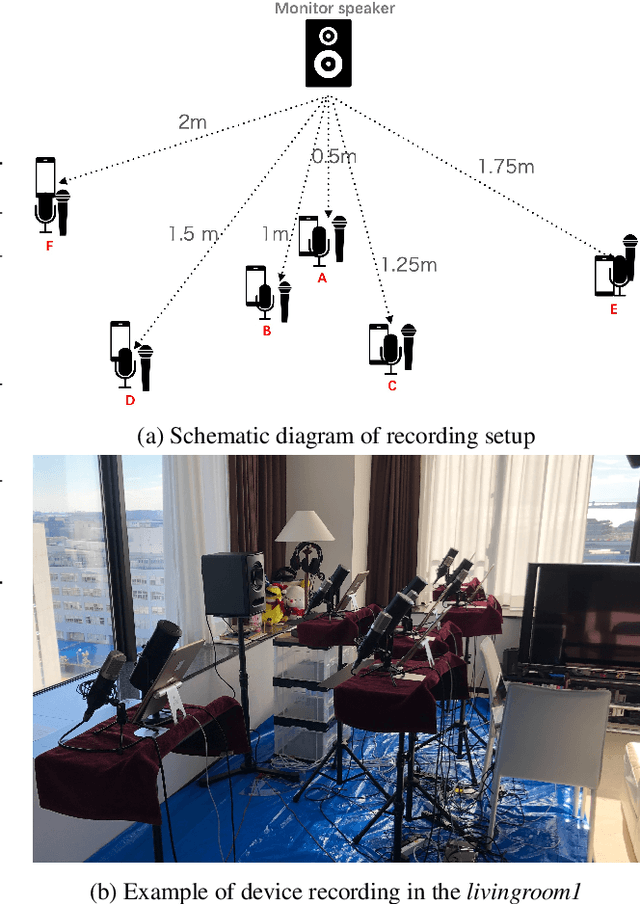
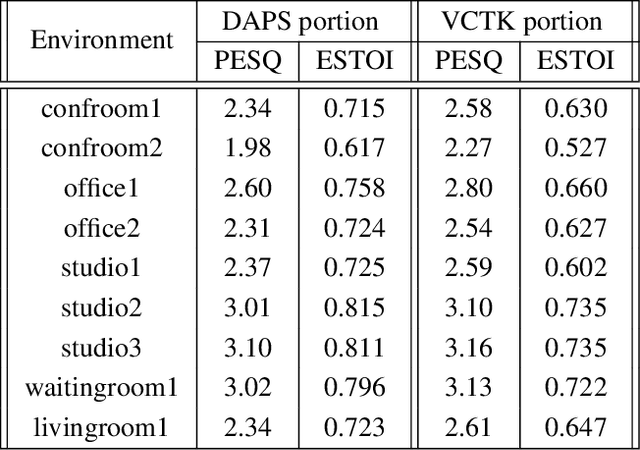
A large and growing amount of speech content in real-life scenarios is being recorded on common consumer devices in uncontrolled environments, resulting in degraded speech quality. Transforming such low-quality device-degraded speech into high-quality speech is a goal of speech enhancement (SE). This paper introduces a new speech dataset, DDS, to facilitate the research on SE. DDS provides aligned parallel recordings of high-quality speech (recorded in professional studios) and a number of versions of low-quality speech, producing approximately 2,000 hours speech data. The DDS dataset covers 27 realistic recording conditions by combining diverse acoustic environments and microphone devices, and each version of a condition consists of multiple recordings from six different microphone positions to simulate various signal-to-noise ratio (SNR) and reverberation levels. We also test several SE baseline systems on the DDS dataset and show the impact of recording diversity on performance.