 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Streaming End-to-End Multilingual Speech Recognition with Joint Language Identification
Sep 13, 2022
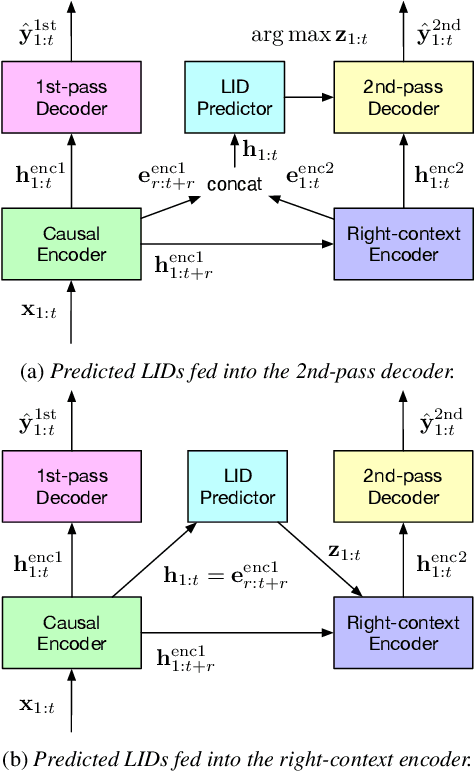


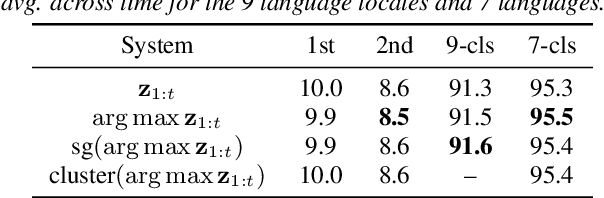
Language identification is critical for many downstream tasks in automatic speech recognition (ASR), and is beneficial to integrate into multilingual end-to-end ASR as an additional task. In this paper, we propose to modify the structure of the cascaded-encoder-based recurrent neural network transducer (RNN-T) model by integrating a per-frame language identifier (LID) predictor. RNN-T with cascaded encoders can achieve streaming ASR with low latency using first-pass decoding with no right-context, and achieve lower word error rates (WERs) using second-pass decoding with longer right-context. By leveraging such differences in the right-contexts and a streaming implementation of statistics pooling, the proposed method can achieve accurate streaming LID prediction with little extra test-time cost. Experimental results on a voice search dataset with 9 language locales shows that the proposed method achieves an average of 96.2% LID prediction accuracy and the same second-pass WER as that obtained by including oracle LID in the input.
Data Augmentation with Locally-time Reversed Speech for Automatic Speech Recognition
Oct 09, 2021
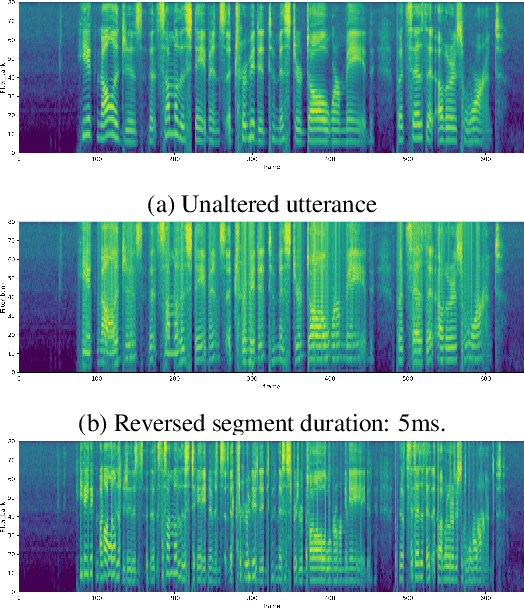
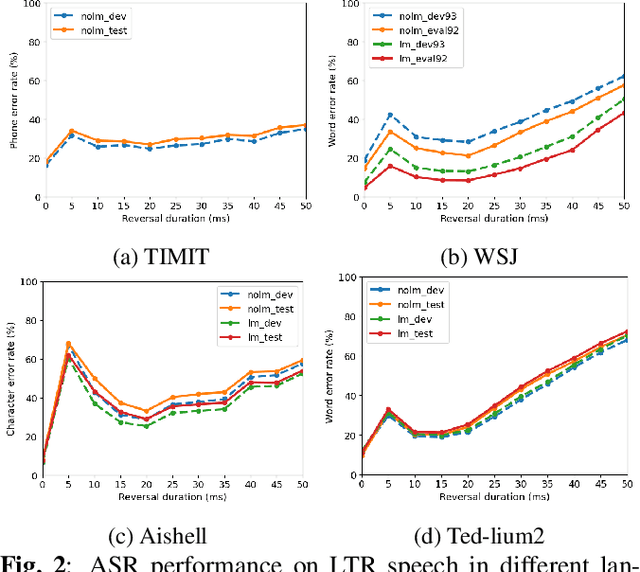
Psychoacoustic studies have shown that locally-time reversed (LTR) speech, i.e., signal samples time-reversed within a short segment, can be accurately recognised by human listeners. This study addresses the question of how well a state-of-the-art automatic speech recognition (ASR) system would perform on LTR speech. The underlying objective is to explore the feasibility of deploying LTR speech in the training of end-to-end (E2E) ASR models, as an attempt to data augmentation for improving the recognition performance. The investigation starts with experiments to understand the effect of LTR speech on general-purpose ASR. LTR speech with reversed segment duration of 5 ms - 50 ms is rendered and evaluated. For ASR training data augmentation with LTR speech, training sets are created by combining natural speech with different partitions of LTR speech. The efficacy of data augmentation is confirmed by ASR results on speech corpora in various languages and speaking styles. ASR on LTR speech with reversed segment duration of 15 ms - 30 ms is found to have lower error rate than with other segment duration. Data augmentation with these LTR speech achieves satisfactory and consistent improvement on ASR performance.
Learning Hierarchical Cross-Modal Association for Co-Speech Gesture Generation
Mar 24, 2022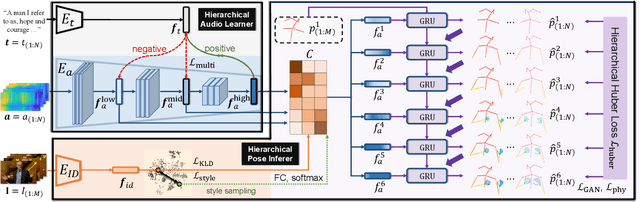
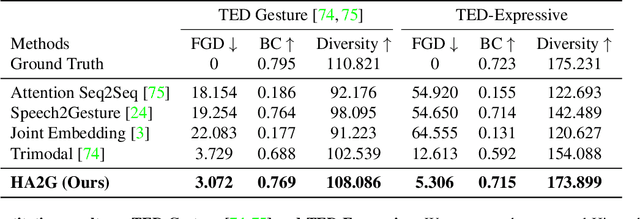
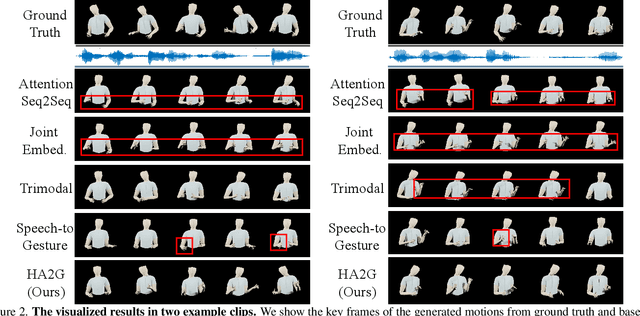

Generating speech-consistent body and gesture movements is a long-standing problem in virtual avatar creation. Previous studies often synthesize pose movement in a holistic manner, where poses of all joints are generated simultaneously. Such a straightforward pipeline fails to generate fine-grained co-speech gestures. One observation is that the hierarchical semantics in speech and the hierarchical structures of human gestures can be naturally described into multiple granularities and associated together. To fully utilize the rich connections between speech audio and human gestures, we propose a novel framework named Hierarchical Audio-to-Gesture (HA2G) for co-speech gesture generation. In HA2G, a Hierarchical Audio Learner extracts audio representations across semantic granularities. A Hierarchical Pose Inferer subsequently renders the entire human pose gradually in a hierarchical manner. To enhance the quality of synthesized gestures, we develop a contrastive learning strategy based on audio-text alignment for better audio representations. Extensive experiments and human evaluation demonstrate that the proposed method renders realistic co-speech gestures and outperforms previous methods in a clear margin. Project page: https://alvinliu0.github.io/projects/HA2G
What can predictive speech coders learn from speaker recognizers?
Apr 05, 2022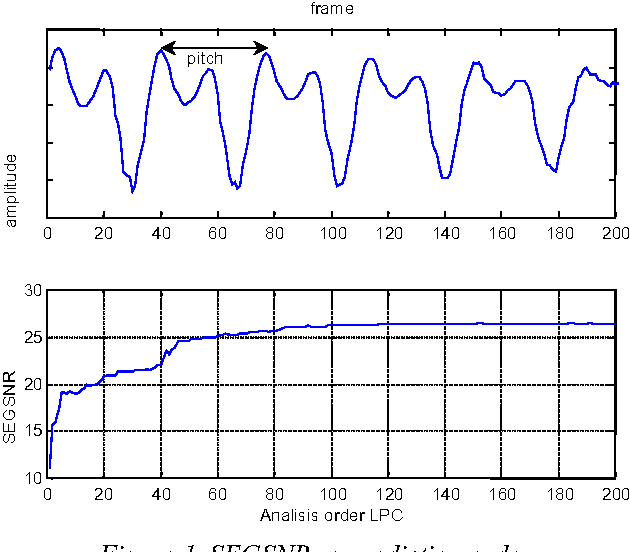
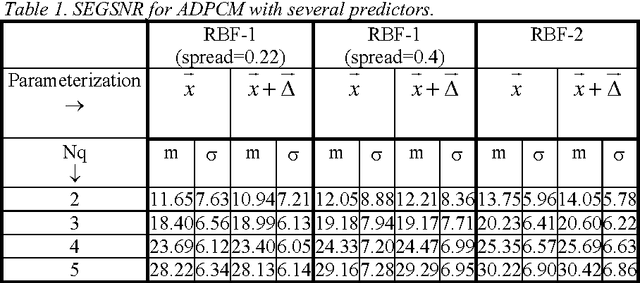
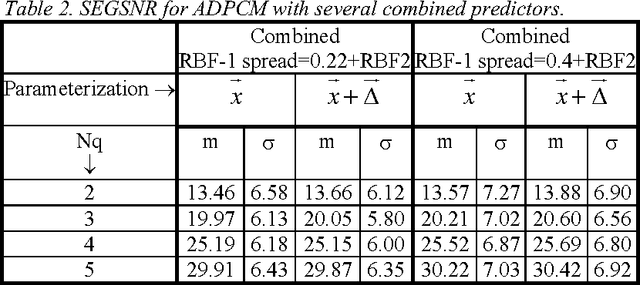
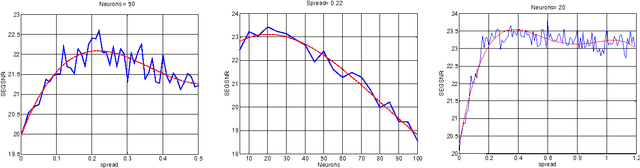
This paper compares the speech coder and speaker recognizer applications, showing some parallelism between them. In this paper, some approaches used for speaker recognition are applied to speech coding in order to improve the prediction accuracy. Experimental results show an improvement in Segmental SNR (SEGSNR).
* 7 pages, published in ITRW on Non-Linear Speech Processing (NOLISP 03), May 20-23, 2003, Le Croisic, France, paper 001. arXiv admin note: text overlap with arXiv:2204.02101
ProDiff: Progressive Fast Diffusion Model For High-Quality Text-to-Speech
Jul 13, 2022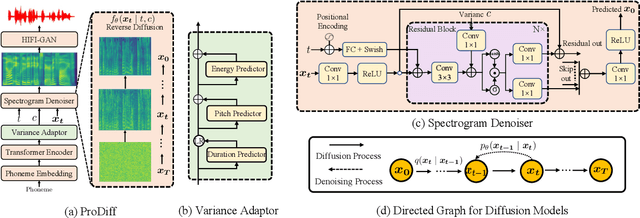
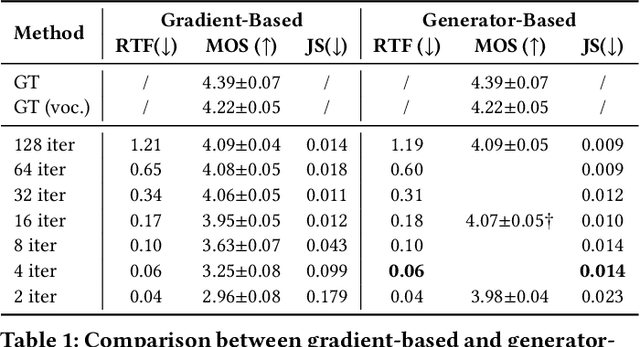
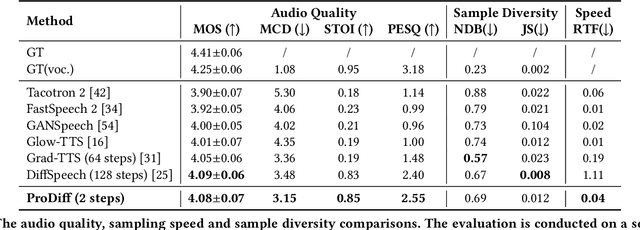
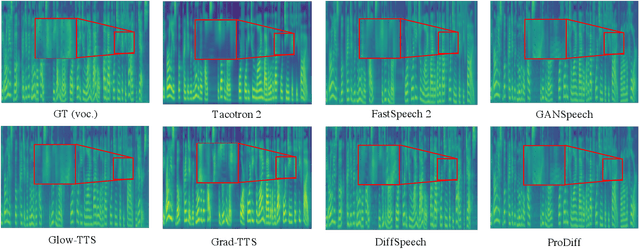
Denoising diffusion probabilistic models (DDPMs) have recently achieved leading performances in many generative tasks. However, the inherited iterative sampling process costs hinder their applications to text-to-speech deployment. Through the preliminary study on diffusion model parameterization, we find that previous gradient-based TTS models require hundreds or thousands of iterations to guarantee high sample quality, which poses a challenge for accelerating sampling. In this work, we propose ProDiff, on progressive fast diffusion model for high-quality text-to-speech. Unlike previous work estimating the gradient for data density, ProDiff parameterizes the denoising model by directly predicting clean data to avoid distinct quality degradation in accelerating sampling. To tackle the model convergence challenge with decreased diffusion iterations, ProDiff reduces the data variance in the target site via knowledge distillation. Specifically, the denoising model uses the generated mel-spectrogram from an N-step DDIM teacher as the training target and distills the behavior into a new model with N/2 steps. As such, it allows the TTS model to make sharp predictions and further reduces the sampling time by orders of magnitude. Our evaluation demonstrates that ProDiff needs only 2 iterations to synthesize high-fidelity mel-spectrograms, while it maintains sample quality and diversity competitive with state-of-the-art models using hundreds of steps. ProDiff enables a sampling speed of 24x faster than real-time on a single NVIDIA 2080Ti GPU, making diffusion models practically applicable to text-to-speech synthesis deployment for the first time. Our extensive ablation studies demonstrate that each design in ProDiff is effective, and we further show that ProDiff can be easily extended to the multi-speaker setting. Audio samples are available at \url{https://ProDiff.github.io/.}
Open Source MagicData-RAMC: A Rich Annotated Mandarin Conversational(RAMC) Speech Dataset
Mar 31, 2022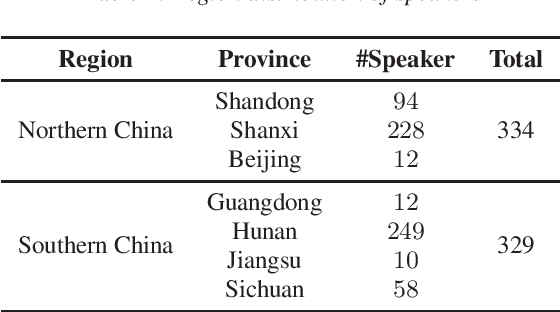
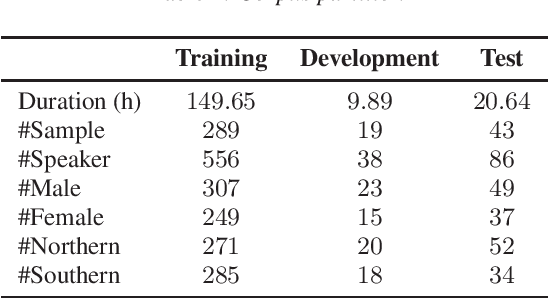
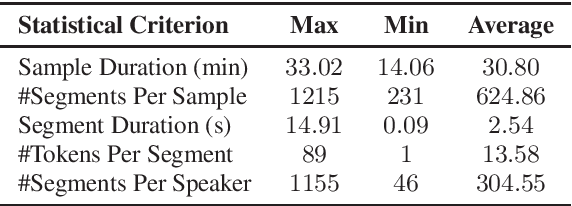
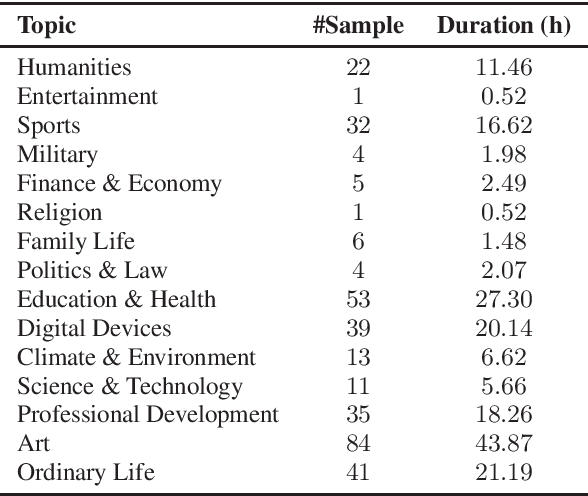
This paper introduces a high-quality rich annotated Mandarin conversational (RAMC) speech dataset called MagicData-RAMC. The MagicData-RAMC corpus contains 180 hours of conversational speech data recorded from native speakers of Mandarin Chinese over mobile phones with a sampling rate of 16 kHz. The dialogs in MagicData-RAMC are classified into 15 diversified domains and tagged with topic labels, ranging from science and technology to ordinary life. Accurate transcription and precise speaker voice activity timestamps are manually labeled for each sample. Speakers' detailed information is also provided. As a Mandarin speech dataset designed for dialog scenarios with high quality and rich annotations, MagicData-RAMC enriches the data diversity in the Mandarin speech community and allows extensive research on a series of speech-related tasks, including automatic speech recognition, speaker diarization, topic detection, keyword search, text-to-speech, etc. We also conduct several relevant tasks and provide experimental results to help evaluate the dataset.
What can Speech and Language Tell us About the Working Alliance in Psychotherapy
Jun 27, 2022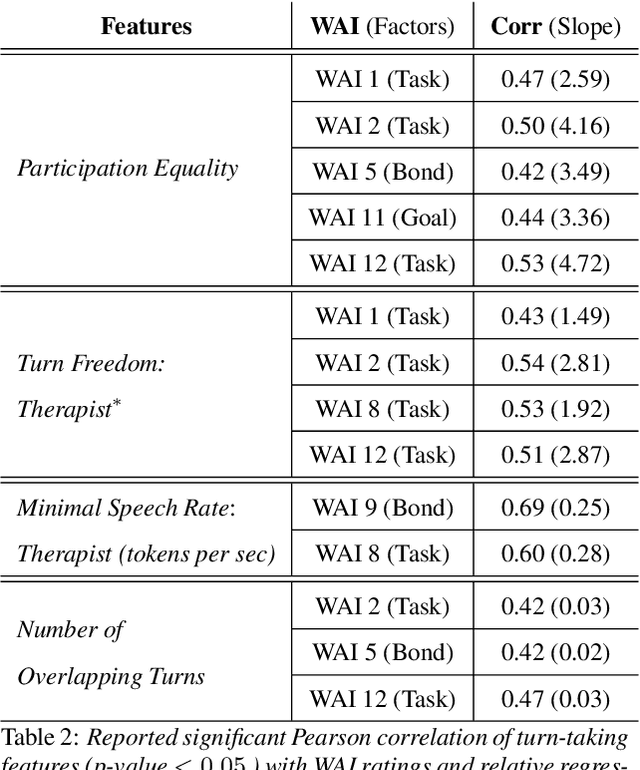
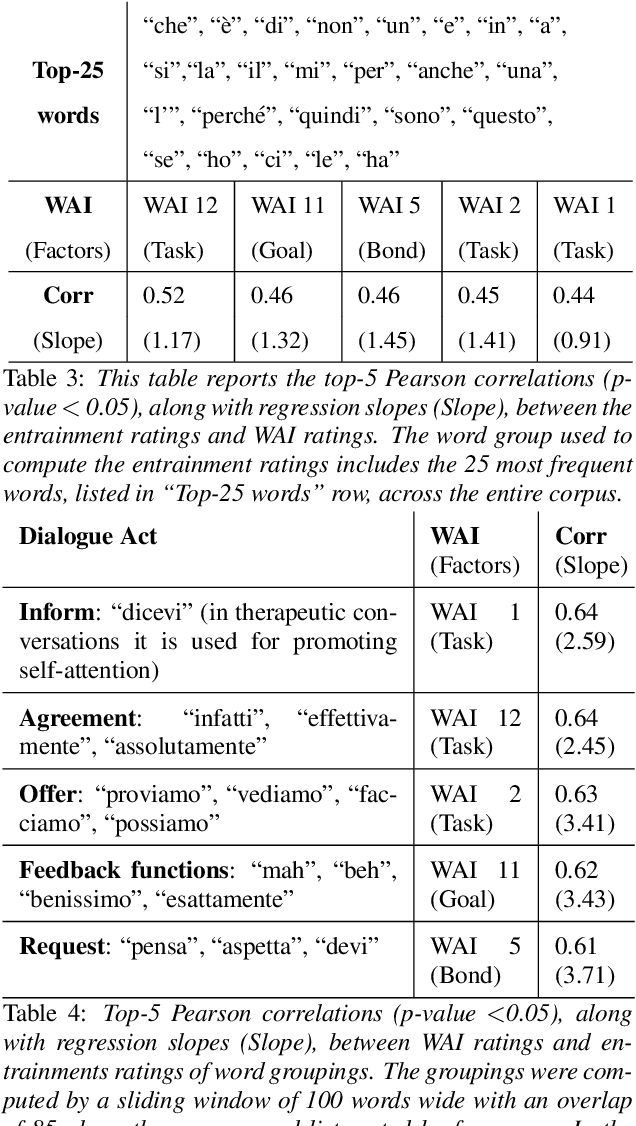
We are interested in the problem of conversational analysis and its application to the health domain. Cognitive Behavioral Therapy is a structured approach in psychotherapy, allowing the therapist to help the patient to identify and modify the malicious thoughts, behavior, or actions. This cooperative effort can be evaluated using the Working Alliance Inventory Observer-rated Shortened - a 12 items inventory covering task, goal, and relationship - which has a relevant influence on therapeutic outcomes. In this work, we investigate the relation between this alliance inventory and the spoken conversations (sessions) between the patient and the psychotherapist. We have delivered eight weeks of e-therapy, collected their audio and video call sessions, and manually transcribed them. The spoken conversations have been annotated and evaluated with WAI ratings by professional therapists. We have investigated speech and language features and their association with WAI items. The feature types include turn dynamics, lexical entrainment, and conversational descriptors extracted from the speech and language signals. Our findings provide strong evidence that a subset of these features are strong indicators of working alliance. To the best of our knowledge, this is the first and a novel study to exploit speech and language for characterising working alliance.
End-to-End Text-to-Speech Based on Latent Representation of Speaking Styles Using Spontaneous Dialogue
Jun 24, 2022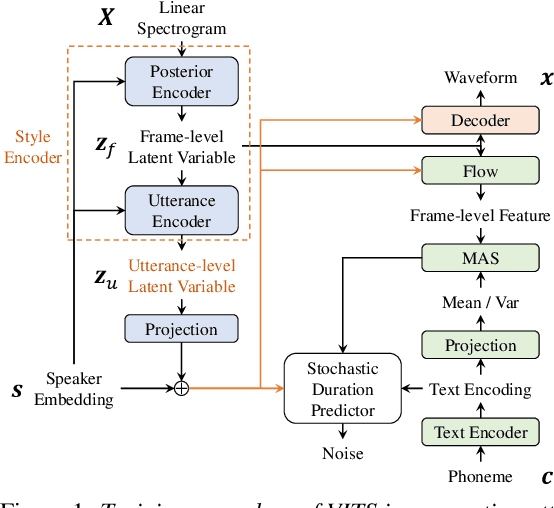
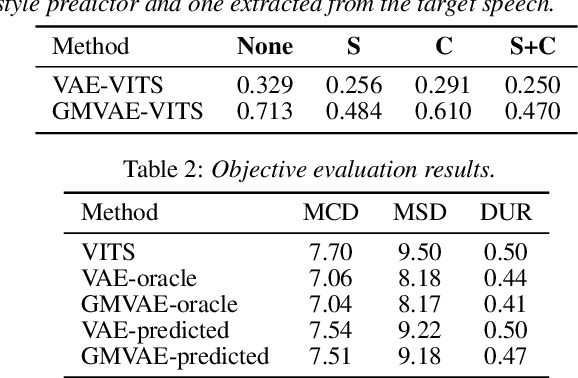
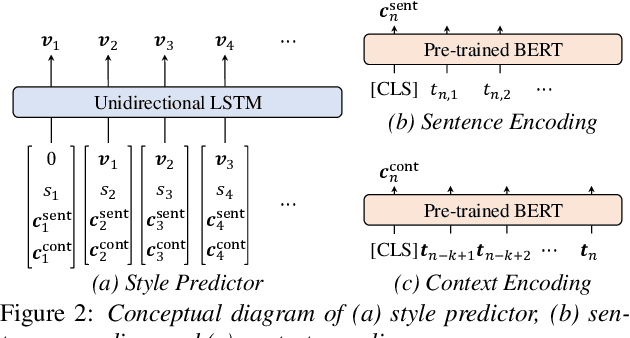
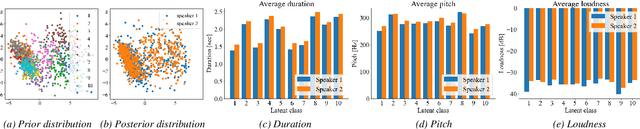
The recent text-to-speech (TTS) has achieved quality comparable to that of humans; however, its application in spoken dialogue has not been widely studied. This study aims to realize a TTS that closely resembles human dialogue. First, we record and transcribe actual spontaneous dialogues. Then, the proposed dialogue TTS is trained in two stages: first stage, variational autoencoder (VAE)-VITS or Gaussian mixture variational autoencoder (GMVAE)-VITS is trained, which introduces an utterance-level latent variable into variational inference with adversarial learning for end-to-end text-to-speech (VITS), a recently proposed end-to-end TTS model. A style encoder that extracts a latent speaking style representation from speech is trained jointly with TTS. In the second stage, a style predictor is trained to predict the speaking style to be synthesized from dialogue history. During inference, by passing the speaking style representation predicted by the style predictor to VAE/GMVAE-VITS, speech can be synthesized in a style appropriate to the context of the dialogue. Subjective evaluation results demonstrate that the proposed method outperforms the original VITS in terms of dialogue-level naturalness.
Fixed-point quantization aware training for on-device keyword-spotting
Mar 04, 2023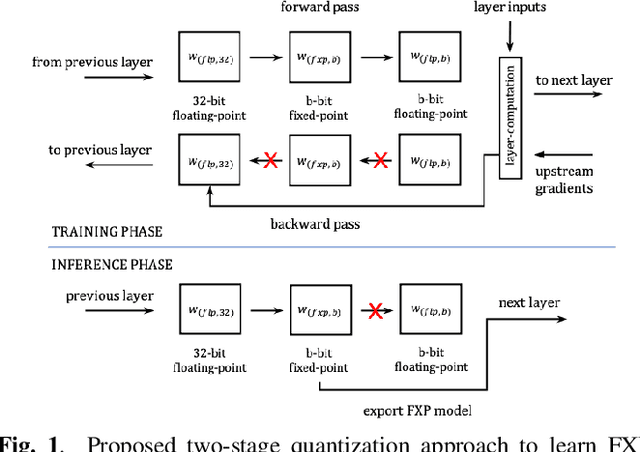

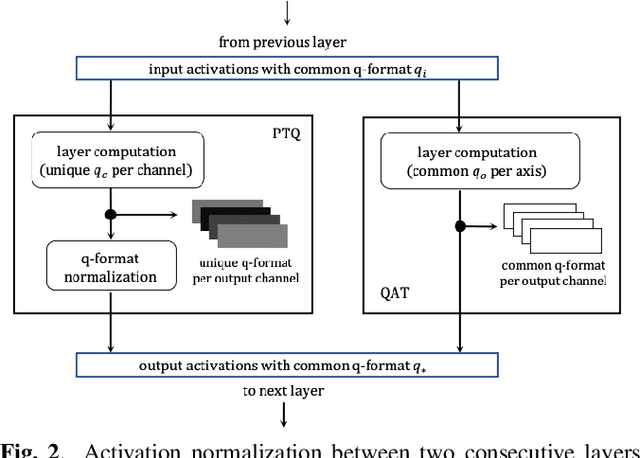
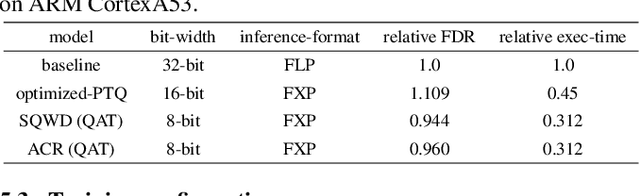
Fixed-point (FXP) inference has proven suitable for embedded devices with limited computational resources, and yet model training is continually performed in floating-point (FLP). FXP training has not been fully explored and the non-trivial conversion from FLP to FXP presents unavoidable performance drop. We propose a novel method to train and obtain FXP convolutional keyword-spotting (KWS) models. We combine our methodology with two quantization-aware-training (QAT) techniques - squashed weight distribution and absolute cosine regularization for model parameters, and propose techniques for extending QAT over transient variables, otherwise neglected by previous paradigms. Experimental results on the Google Speech Commands v2 dataset show that we can reduce model precision up to 4-bit with no loss in accuracy. Furthermore, on an in-house KWS dataset, we show that our 8-bit FXP-QAT models have a 4-6% improvement in relative false discovery rate at fixed false reject rate compared to full precision FLP models. During inference we argue that FXP-QAT eliminates q-format normalization and enables the use of low-bit accumulators while maximizing SIMD throughput to reduce user perceived latency. We demonstrate that we can reduce execution time by 68% without compromising KWS model's predictive performance or requiring model architectural changes. Our work provides novel findings that aid future research in this area and enable accurate and efficient models.
* 5 pages, 3 figures, 4 tables
MOSRA: Joint Mean Opinion Score and Room Acoustics Speech Quality Assessment
Apr 04, 2022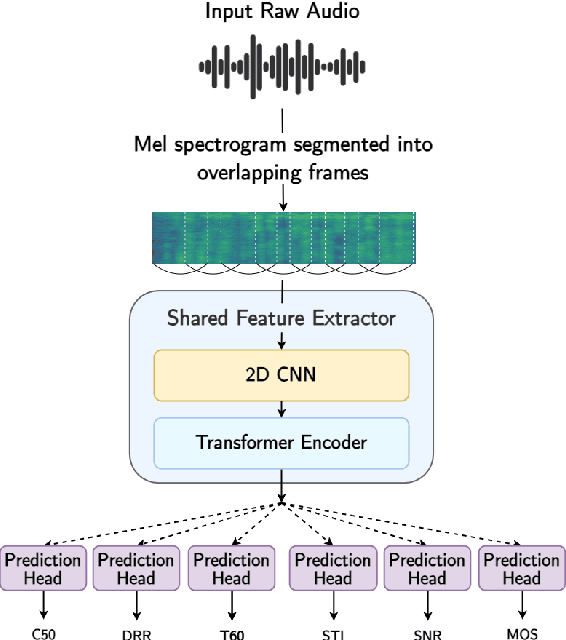
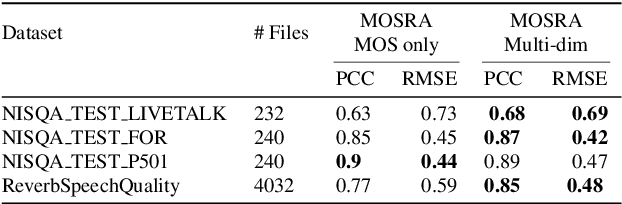
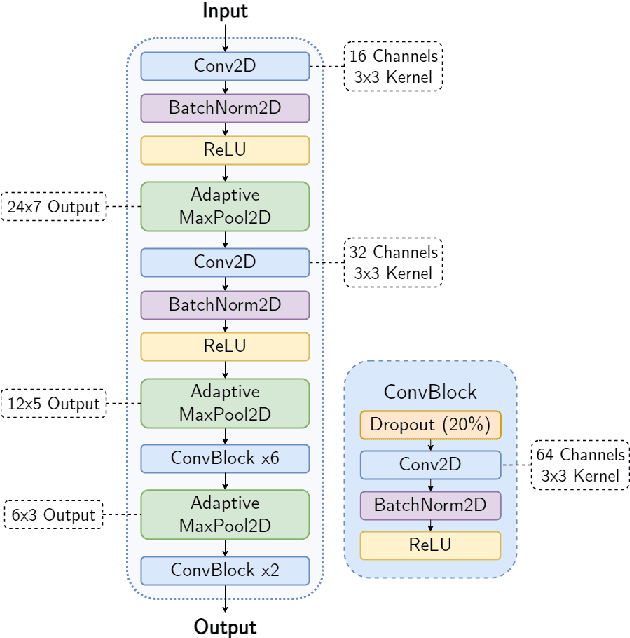
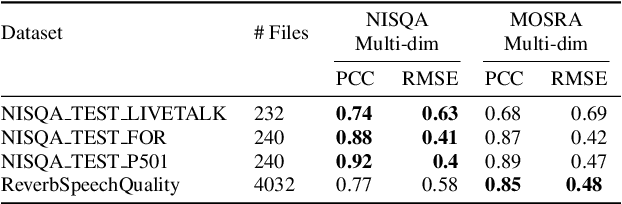
The acoustic environment can degrade speech quality during communication (e.g., video call, remote presentation, outside voice recording), and its impact is often unknown. Objective metrics for speech quality have proven challenging to develop given the multi-dimensionality of factors that affect speech quality and the difficulty of collecting labeled data. Hypothesizing the impact of acoustics on speech quality, this paper presents MOSRA: a non-intrusive multi-dimensional speech quality metric that can predict room acoustics parameters (SNR, STI, T60, DRR, and C50) alongside the overall mean opinion score (MOS) for speech quality. By explicitly optimizing the model to learn these room acoustics parameters, we can extract more informative features and improve the generalization for the MOS task when the training data is limited. Furthermore, we also show that this joint training method enhances the blind estimation of room acoustics, improving the performance of current state-of-the-art models. An additional side-effect of this joint prediction is the improvement in the explainability of the predictions, which is a valuable feature for many applications.