 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Modelling word learning and recognition using visually grounded speech
Mar 14, 2022
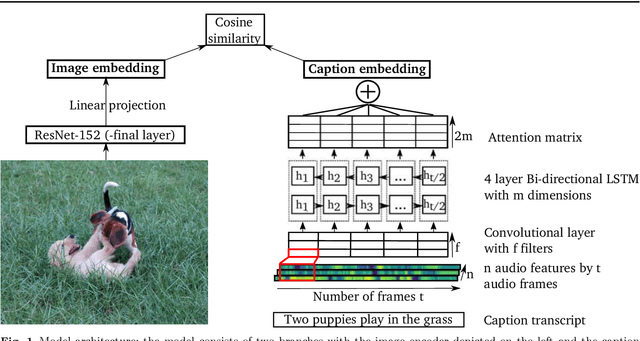
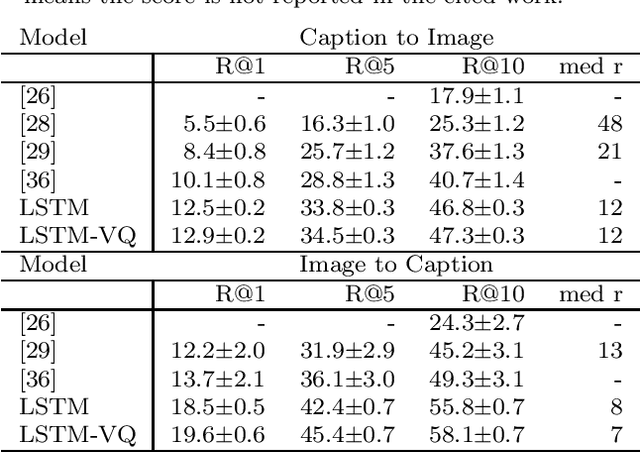
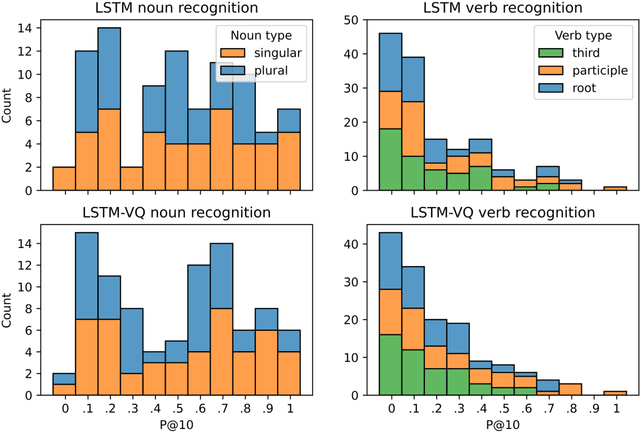
Background: Computational models of speech recognition often assume that the set of target words is already given. This implies that these models do not learn to recognise speech from scratch without prior knowledge and explicit supervision. Visually grounded speech models learn to recognise speech without prior knowledge by exploiting statistical dependencies between spoken and visual input. While it has previously been shown that visually grounded speech models learn to recognise the presence of words in the input, we explicitly investigate such a model as a model of human speech recognition. Methods: We investigate the time-course of word recognition as simulated by the model using a gating paradigm to test whether its recognition is affected by well-known word-competition effects in human speech processing. We furthermore investigate whether vector quantisation, a technique for discrete representation learning, aids the model in the discovery and recognition of words. Results/Conclusion: Our experiments show that the model is able to recognise nouns in isolation and even learns to properly differentiate between plural and singular nouns. We also find that recognition is influenced by word competition from the word-initial cohort and neighbourhood density, mirroring word competition effects in human speech comprehension. Lastly, we find no evidence that vector quantisation is helpful in discovering and recognising words. Our gating experiments even show that the vector quantised model requires more of the input sequence for correct recognition.
Multi-stage Progressive Compression of Conformer Transducer for On-device Speech Recognition
Oct 01, 2022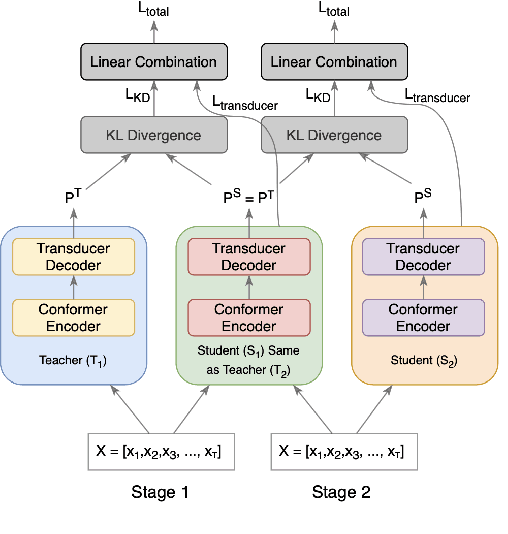
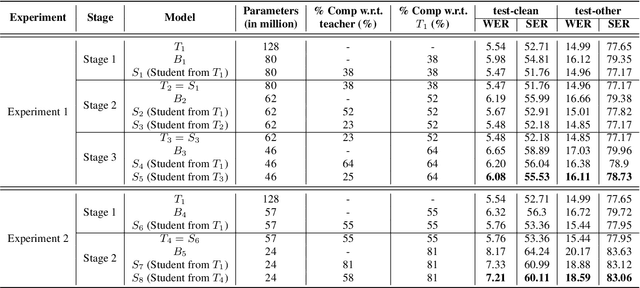
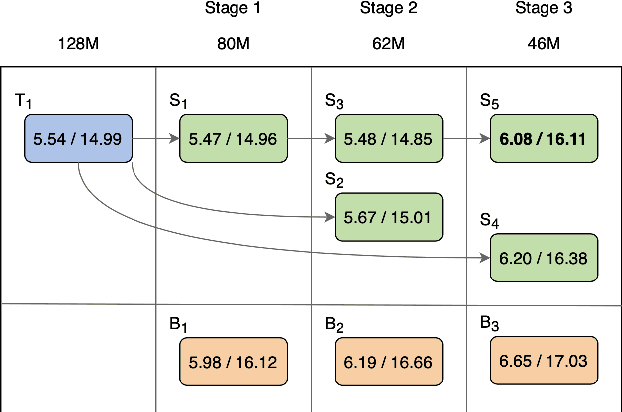
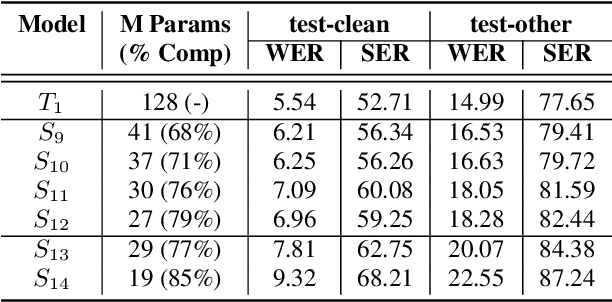
The smaller memory bandwidth in smart devices prompts development of smaller Automatic Speech Recognition (ASR) models. To obtain a smaller model, one can employ the model compression techniques. Knowledge distillation (KD) is a popular model compression approach that has shown to achieve smaller model size with relatively lesser degradation in the model performance. In this approach, knowledge is distilled from a trained large size teacher model to a smaller size student model. Also, the transducer based models have recently shown to perform well for on-device streaming ASR task, while the conformer models are efficient in handling long term dependencies. Hence in this work we employ a streaming transducer architecture with conformer as the encoder. We propose a multi-stage progressive approach to compress the conformer transducer model using KD. We progressively update our teacher model with the distilled student model in a multi-stage setup. On standard LibriSpeech dataset, our experimental results have successfully achieved compression rates greater than 60% without significant degradation in the performance compared to the larger teacher model.
* Published in INTERSPEECH 2022
Explainable Human-centered Traits from Head Motion and Facial Expression Dynamics
Feb 20, 2023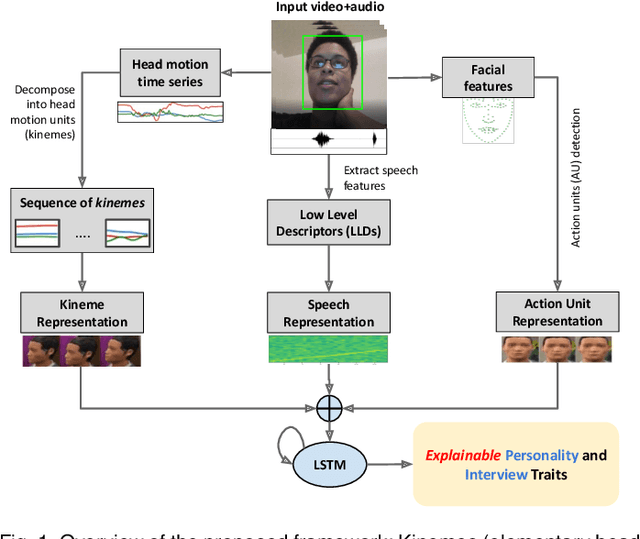
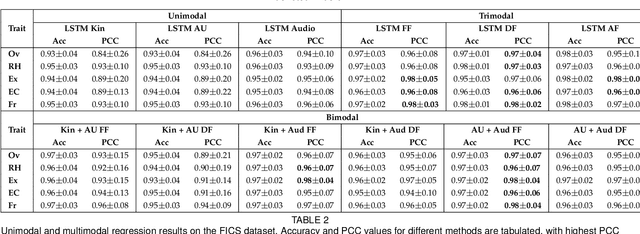
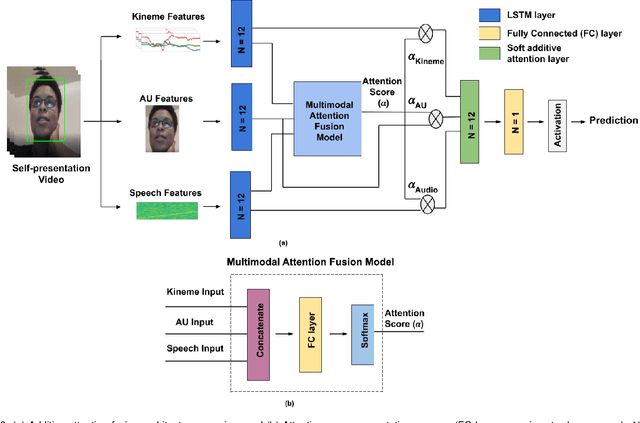
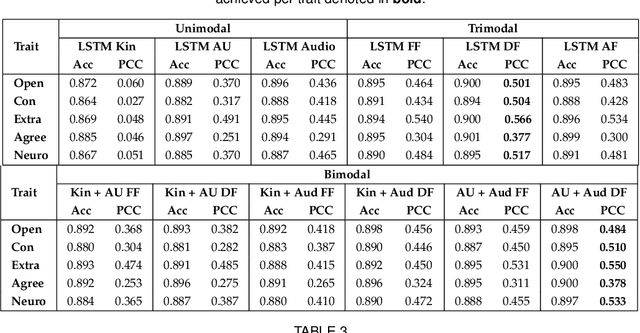
We explore the efficacy of multimodal behavioral cues for explainable prediction of personality and interview-specific traits. We utilize elementary head-motion units named kinemes, atomic facial movements termed action units and speech features to estimate these human-centered traits. Empirical results confirm that kinemes and action units enable discovery of multiple trait-specific behaviors while also enabling explainability in support of the predictions. For fusing cues, we explore decision and feature-level fusion, and an additive attention-based fusion strategy which quantifies the relative importance of the three modalities for trait prediction. Examining various long-short term memory (LSTM) architectures for classification and regression on the MIT Interview and First Impressions Candidate Screening (FICS) datasets, we note that: (1) Multimodal approaches outperform unimodal counterparts; (2) Efficient trait predictions and plausible explanations are achieved with both unimodal and multimodal approaches, and (3) Following the thin-slice approach, effective trait prediction is achieved even from two-second behavioral snippets.
Spoofed training data for speech spoofing countermeasure can be efficiently created using neural vocoders
Oct 19, 2022
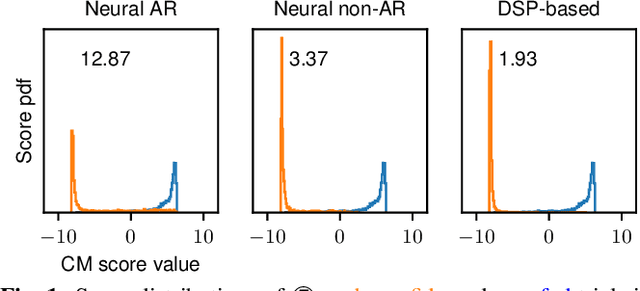
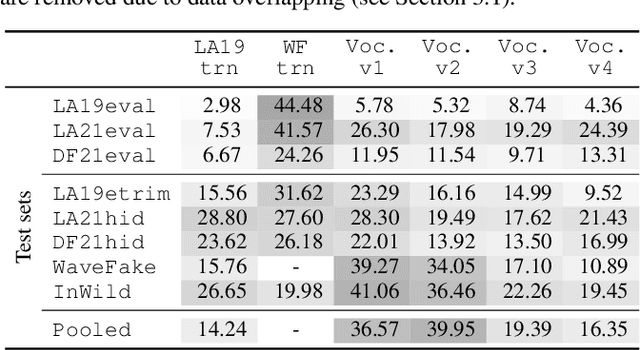
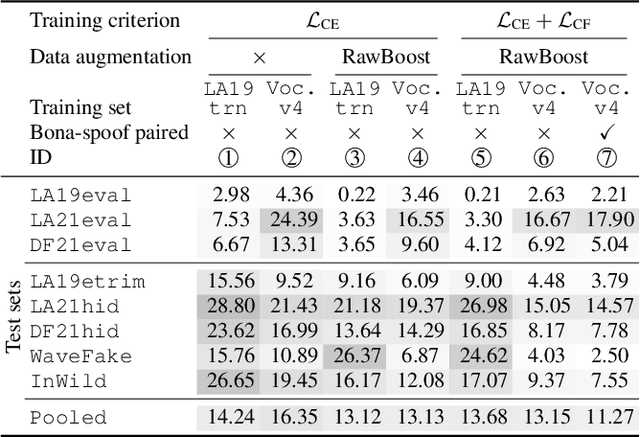
A good training set for speech spoofing countermeasures requires diverse TTS and VC spoofing attacks, but generating TTS and VC spoofed trials for a target speaker may be technically demanding. Instead of using full-fledged TTS and VC systems, this study uses neural-network-based vocoders to do copy-synthesis on bona fide utterances. The output data can be used as spoofed data. To make better use of pairs of bona fide and spoofed data, this study introduces a contrastive feature loss that can be plugged into the standard training criterion. On the basis of the bona fide trials from the ASVspoof 2019 logical access training set, this study empirically compared a few training sets created in the proposed manner using a few neural non-autoregressive vocoders. Results on multiple test sets suggest good practices such as fine-tuning neural vocoders using bona fide data from the target domain. The results also demonstrated the effectiveness of the contrastive feature loss. Combining the best practices, the trained CM achieved overall competitive performance. Its EERs on the ASVspoof 2021 hidden subsets also outperformed the top-1 challenge submissions.
Language-specific Characteristic Assistance for Code-switching Speech Recognition
Jul 05, 2022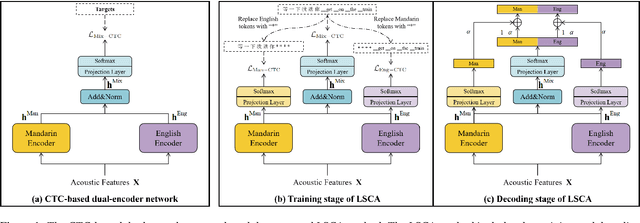
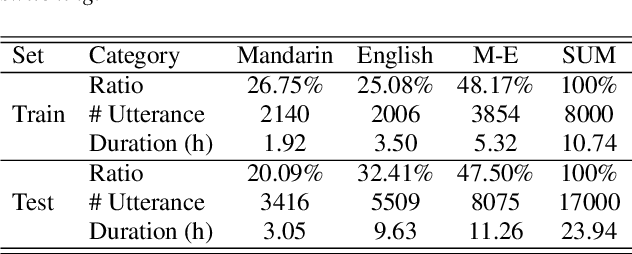

Dual-encoder structure successfully utilizes two language-specific encoders (LSEs) for code-switching speech recognition. Because LSEs are initialized by two pre-trained language-specific models (LSMs), the dual-encoder structure can exploit sufficient monolingual data and capture the individual language attributes. However, existing methods have no language constraints on LSEs and underutilize language-specific knowledge of LSMs. In this paper, we propose a language-specific characteristic assistance (LSCA) method to mitigate the above problems. Specifically, during training, we introduce two language-specific losses as language constraints and generate corresponding language-specific targets for them. During decoding, we take the decoding abilities of LSMs into account by combining the output probabilities of two LSMs and the mixture model to obtain the final predictions. Experiments show that either the training or decoding method of LSCA can improve the model's performance. Furthermore, the best result can obtain up to 15.4% relative error reduction on the code-switching test set by combining the training and decoding methods of LSCA. Moreover, the system can process code-switching speech recognition tasks well without extra shared parameters or even retraining based on two pre-trained LSMs by using our method.
AISHELL-NER: Named Entity Recognition from Chinese Speech
Feb 17, 2022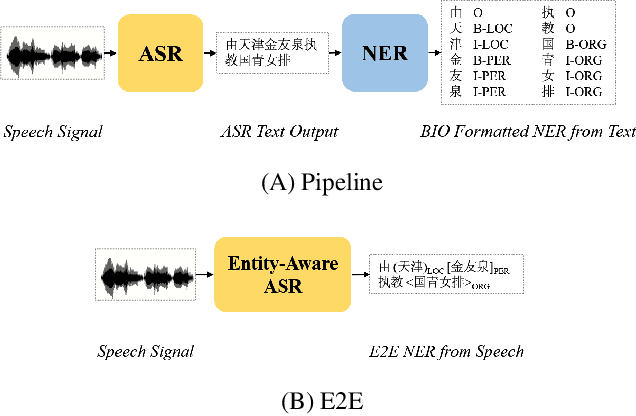
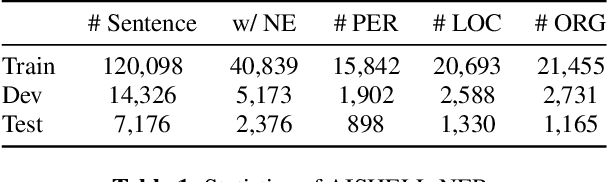
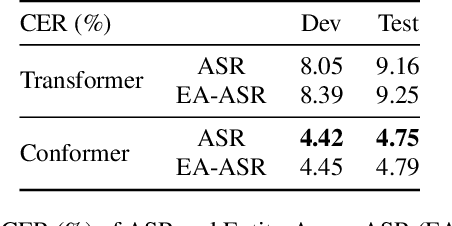
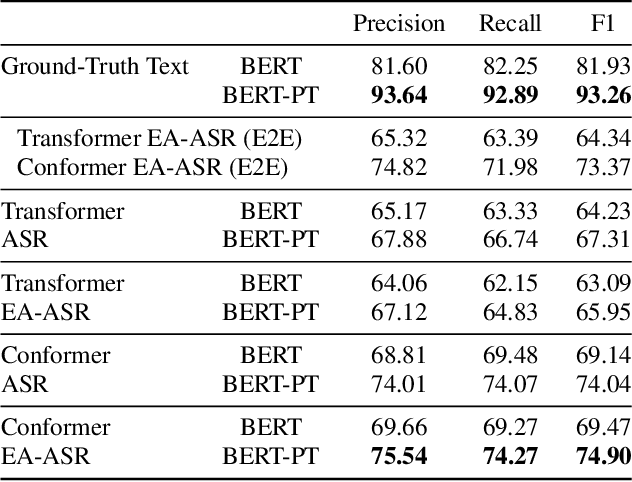
Named Entity Recognition (NER) from speech is among Spoken Language Understanding (SLU) tasks, aiming to extract semantic information from the speech signal. NER from speech is usually made through a two-step pipeline that consists of (1) processing the audio using an Automatic Speech Recognition (ASR) system and (2) applying an NER tagger to the ASR outputs. Recent works have shown the capability of the End-to-End (E2E) approach for NER from English and French speech, which is essentially entity-aware ASR. However, due to the many homophones and polyphones that exist in Chinese, NER from Chinese speech is effectively a more challenging task. In this paper, we introduce a new dataset AISEHLL-NER for NER from Chinese speech. Extensive experiments are conducted to explore the performance of several state-of-the-art methods. The results demonstrate that the performance could be improved by combining entity-aware ASR and pretrained NER tagger, which can be easily applied to the modern SLU pipeline. The dataset is publicly available at github.com/Alibaba-NLP/AISHELL-NER.
BrainBERT: Self-supervised representation learning for intracranial recordings
Feb 28, 2023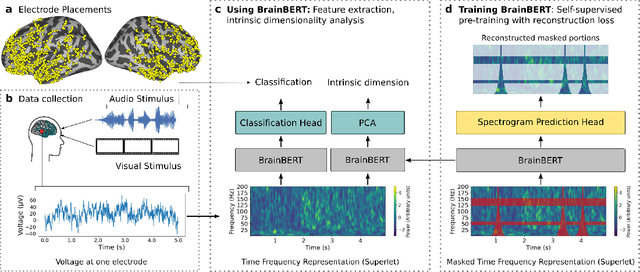
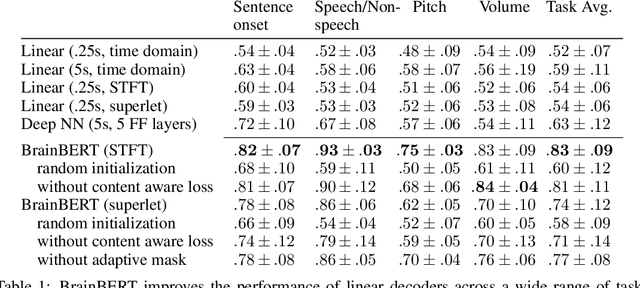
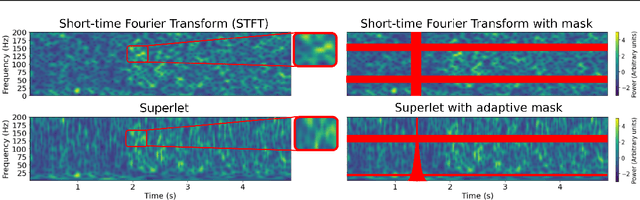
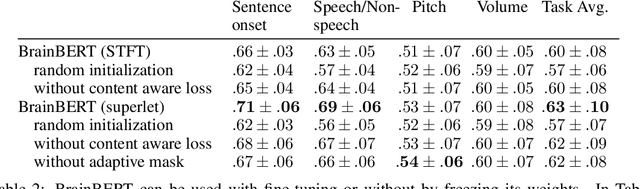
We create a reusable Transformer, BrainBERT, for intracranial recordings bringing modern representation learning approaches to neuroscience. Much like in NLP and speech recognition, this Transformer enables classifying complex concepts, i.e., decoding neural data, with higher accuracy and with much less data by being pretrained in an unsupervised manner on a large corpus of unannotated neural recordings. Our approach generalizes to new subjects with electrodes in new positions and to unrelated tasks showing that the representations robustly disentangle the neural signal. Just like in NLP where one can study language by investigating what a language model learns, this approach opens the door to investigating the brain by what a model of the brain learns. As a first step along this path, we demonstrate a new analysis of the intrinsic dimensionality of the computations in different areas of the brain. To construct these representations, we combine a technique for producing super-resolution spectrograms of neural data with an approach designed for generating contextual representations of audio by masking. In the future, far more concepts will be decodable from neural recordings by using representation learning, potentially unlocking the brain like language models unlocked language.
Speech-to-SQL: Towards Speech-driven SQL Query Generation From Natural Language Question
Jan 04, 2022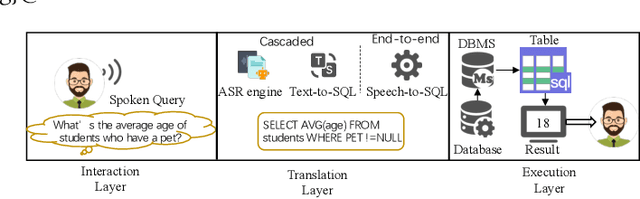
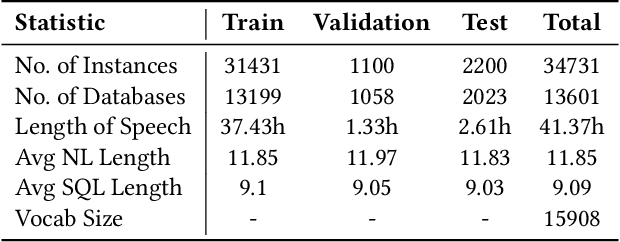
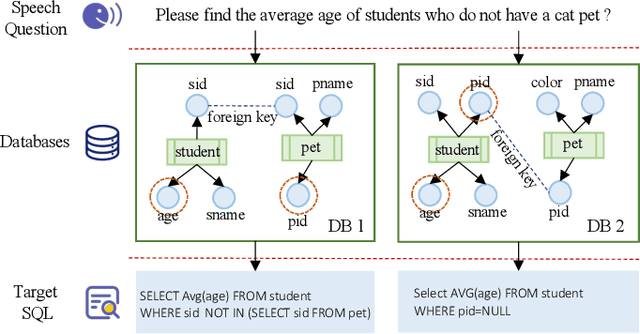
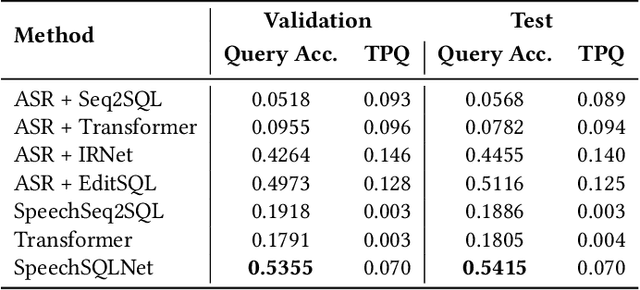
Speech-based inputs have been gaining significant momentum with the popularity of smartphones and tablets in our daily lives, since voice is the most easiest and efficient way for human-computer interaction. This paper works towards designing more effective speech-based interfaces to query the structured data in relational databases. We first identify a new task named Speech-to-SQL, which aims to understand the information conveyed by human speech and directly translate it into structured query language (SQL) statements. A naive solution to this problem can work in a cascaded manner, that is, an automatic speech recognition (ASR) component followed by a text-to-SQL component. However, it requires a high-quality ASR system and also suffers from the error compounding problem between the two components, resulting in limited performance. To handle these challenges, we further propose a novel end-to-end neural architecture named SpeechSQLNet to directly translate human speech into SQL queries without an external ASR step. SpeechSQLNet has the advantage of making full use of the rich linguistic information presented in speech. To the best of our knowledge, this is the first attempt to directly synthesize SQL based on arbitrary natural language questions, rather than a natural language-based version of SQL or its variants with a limited SQL grammar. To validate the effectiveness of the proposed problem and model, we further construct a dataset named SpeechQL, by piggybacking the widely-used text-to-SQL datasets. Extensive experimental evaluations on this dataset show that SpeechSQLNet can directly synthesize high-quality SQL queries from human speech, outperforming various competitive counterparts as well as the cascaded methods in terms of exact match accuracies.
Preliminary Study on SSCF-derived Polar Coordinate for ASR
Nov 30, 2022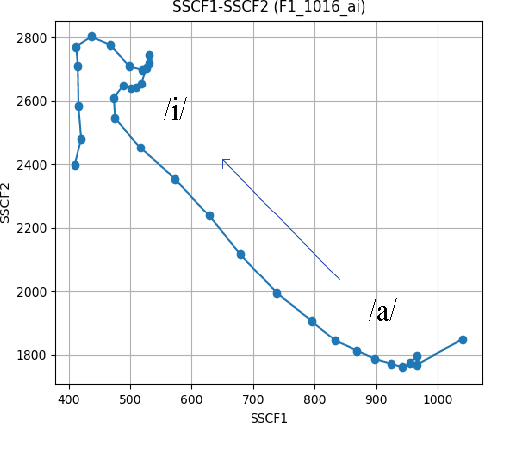

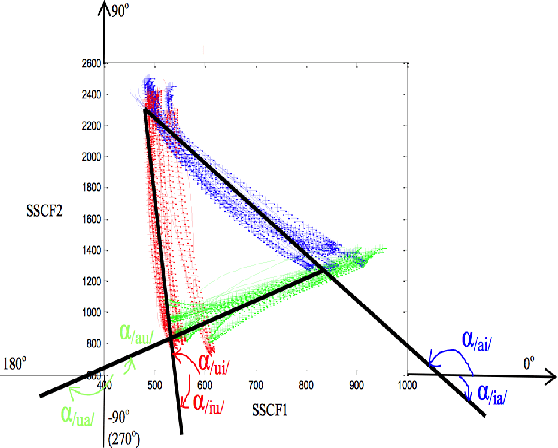

The transition angles are defined to describe the vowel-to-vowel transitions in the acoustic space of the Spectral Subband Centroids, and the findings show that they are similar among speakers and speaking rates. In this paper, we propose to investigate the usage of polar coordinates in favor of angles to describe a speech signal by characterizing its acoustic trajectory and using them in Automatic Speech Recognition. According to the experimental results evaluated on the BRAF100 dataset, the polar coordinates achieved significantly higher accuracy than the angles in the mixed and cross-gender speech recognitions, demonstrating that these representations are superior at defining the acoustic trajectory of the speech signal. Furthermore, the accuracy was significantly improved when they were utilized with their first and second-order derivatives ($\Delta$, $\Delta$$\Delta$), especially in cross-female recognition. However, the results showed they were not much more gender-independent than the conventional Mel-frequency Cepstral Coefficients (MFCCs).
Meeting the Needs of Low-Resource Languages: The Value of Automatic Alignments via Pretrained Models
Feb 15, 2023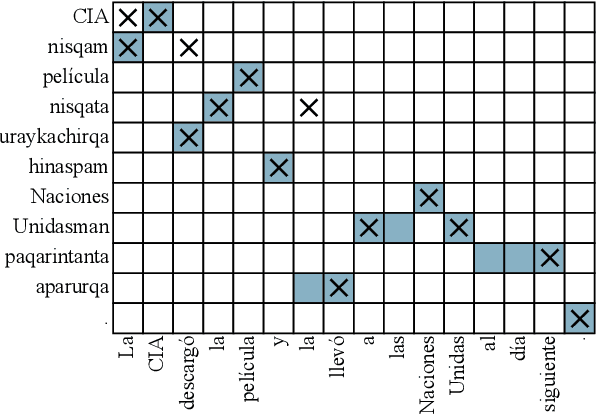
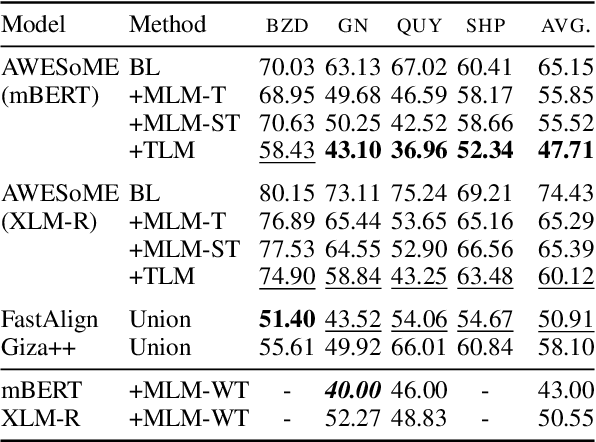
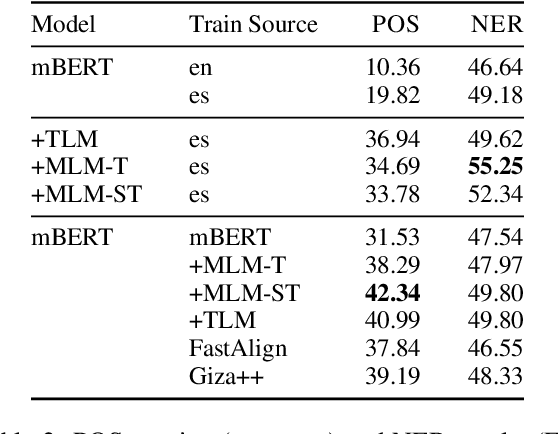
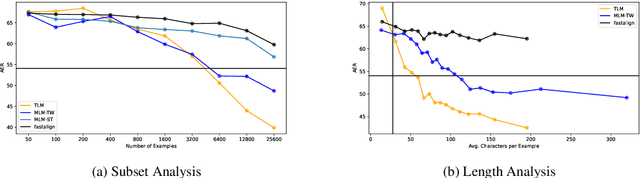
Large multilingual models have inspired a new class of word alignment methods, which work well for the model's pretraining languages. However, the languages most in need of automatic alignment are low-resource and, thus, not typically included in the pretraining data. In this work, we ask: How do modern aligners perform on unseen languages, and are they better than traditional methods? We contribute gold-standard alignments for Bribri--Spanish, Guarani--Spanish, Quechua--Spanish, and Shipibo-Konibo--Spanish. With these, we evaluate state-of-the-art aligners with and without model adaptation to the target language. Finally, we also evaluate the resulting alignments extrinsically through two downstream tasks: named entity recognition and part-of-speech tagging. We find that although transformer-based methods generally outperform traditional models, the two classes of approach remain competitive with each other.