 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speaker Change Detection for Transformer Transducer ASR
Feb 16, 2023
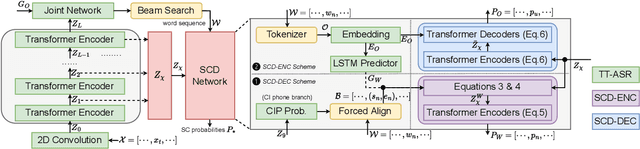
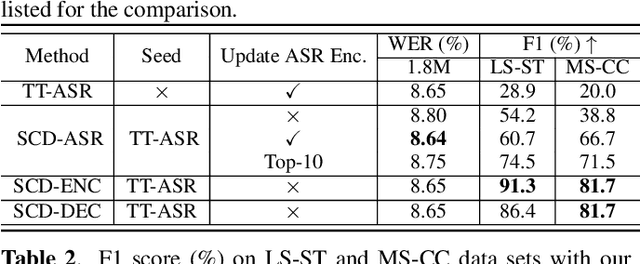
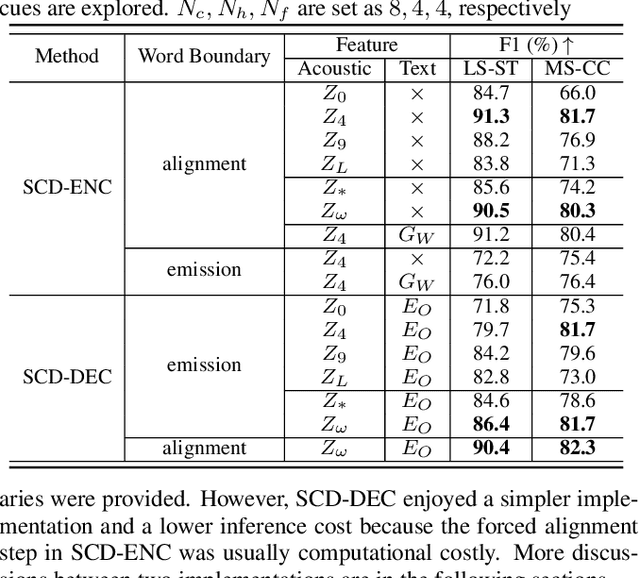
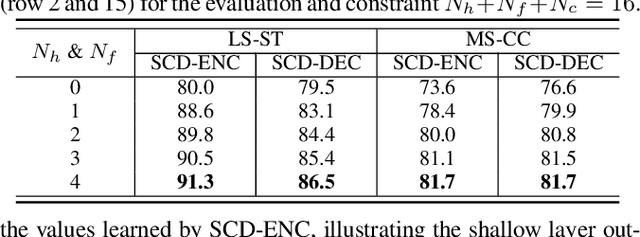
Speaker change detection (SCD) is an important feature that improves the readability of the recognized words from an automatic speech recognition (ASR) system by breaking the word sequence into paragraphs at speaker change points. Existing SCD solutions either require additional ensemble for the time based decisions and recognized word sequences, or implement a tight integration between ASR and SCD, limiting the potential optimum performance for both tasks. To address these issues, we propose a novel framework for the SCD task, where an additional SCD module is built on top of an existing Transformer Transducer ASR (TT-ASR) network. Two variants of the SCD network are explored in this framework that naturally estimate speaker change probability for each word, while allowing the ASR and SCD to have independent optimization scheme for the best performance. Experiments show that our methods can significantly improve the F1 score on LibriCSS and Microsoft call center data sets without ASR degradation, compared with a joint SCD and ASR baseline.
Cross-domain Neural Pitch and Periodicity Estimation
Jan 28, 2023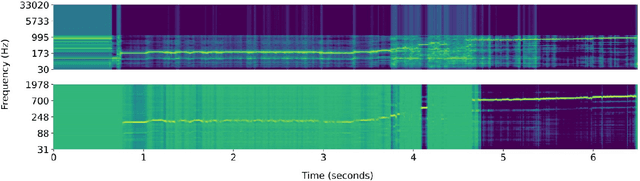
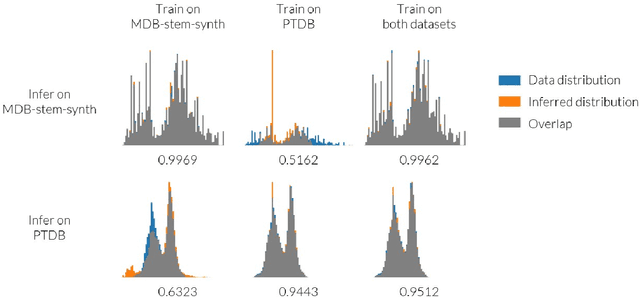
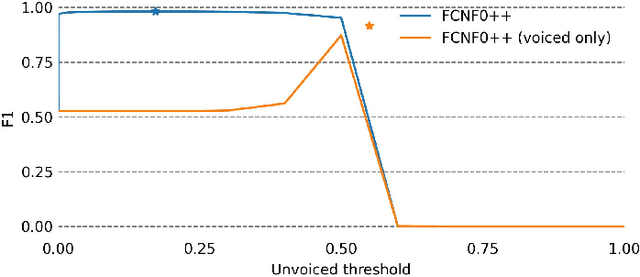
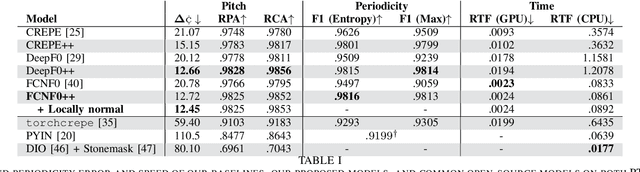
Pitch is a foundational aspect of our perception of audio signals. Pitch contours are commonly used to analyze speech and music signals and as input features for many audio tasks, including music transcription, singing voice synthesis, and prosody editing. In this paper, we describe a set of techniques for improving the accuracy of state-of-the-art neural pitch and periodicity estimators. We also introduce a novel entropy-based method for extracting periodicity and per-frame voiced-unvoiced classifications from statistical inference-based pitch estimators (e.g., neural networks), and show how to train a neural pitch estimator to simultaneously handle speech and music without performance degradation. While neural pitch trackers have historically been significantly slower than signal processing based pitch trackers, our estimator implementations approach the speed of state-of-the-art DSP-based pitch estimators on a standard CPU, but with significantly more accurate pitch and periodicity estimation. Our experiments show that an accurate, cross-domain pitch and periodicity estimator written in PyTorch with a hopsize of ten milliseconds can run 11.2x faster than real-time on a Intel i9-9820X 10-core 3.30 GHz CPU or 408x faster than real-time on a NVIDIA GeForce RTX 3090 GPU without hardware optimization. We release all of our code and models as Pitch-Estimating Neural Networks (penn), an open-source, pip-installable Python module for training, evaluating, and performing inference with pitch- and periodicity-estimating neural networks. The code for penn is available at https://github.com/interactiveaudiolab/penn.
Language-specific Characteristic Assistance for Code-switching Speech Recognition
Jul 05, 2022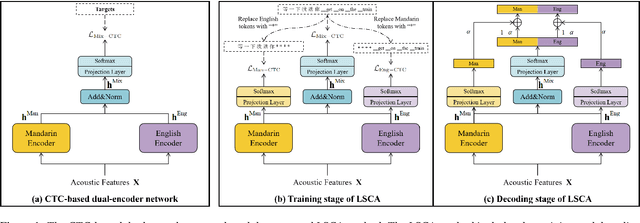

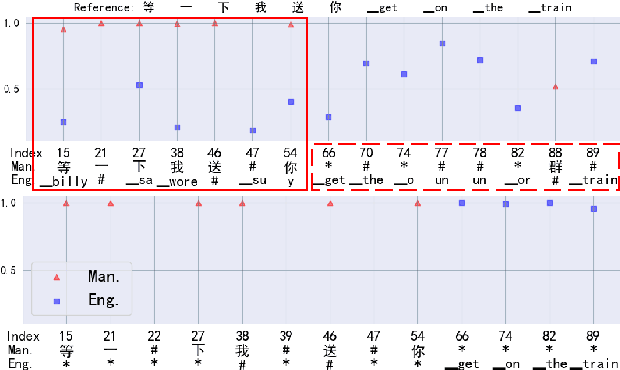
Dual-encoder structure successfully utilizes two language-specific encoders (LSEs) for code-switching speech recognition. Because LSEs are initialized by two pre-trained language-specific models (LSMs), the dual-encoder structure can exploit sufficient monolingual data and capture the individual language attributes. However, existing methods have no language constraints on LSEs and underutilize language-specific knowledge of LSMs. In this paper, we propose a language-specific characteristic assistance (LSCA) method to mitigate the above problems. Specifically, during training, we introduce two language-specific losses as language constraints and generate corresponding language-specific targets for them. During decoding, we take the decoding abilities of LSMs into account by combining the output probabilities of two LSMs and the mixture model to obtain the final predictions. Experiments show that either the training or decoding method of LSCA can improve the model's performance. Furthermore, the best result can obtain up to 15.4% relative error reduction on the code-switching test set by combining the training and decoding methods of LSCA. Moreover, the system can process code-switching speech recognition tasks well without extra shared parameters or even retraining based on two pre-trained LSMs by using our method.
Deep Learning Approach for Classifying the Aggressive Comments on Social Media: Machine Translated Data Vs Real Life Data
Mar 13, 2023
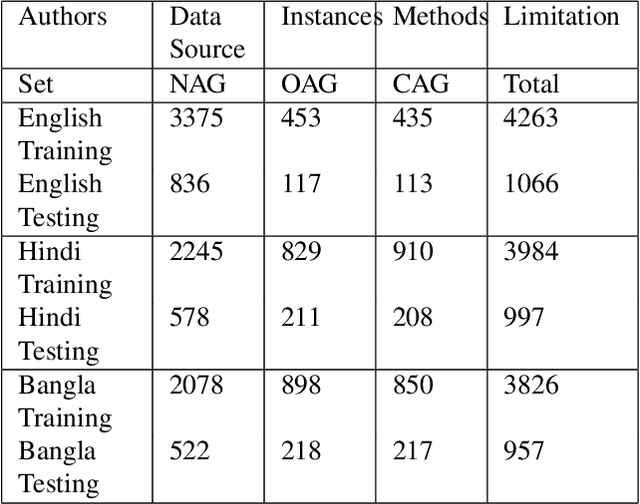
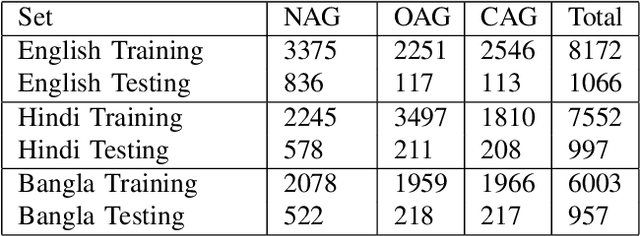

Aggressive comments on social media negatively impact human life. Such offensive contents are responsible for depression and suicidal-related activities. Since online social networking is increasing day by day, the hate content is also increasing. Several investigations have been done on the domain of cyberbullying, cyberaggression, hate speech, etc. The majority of the inquiry has been done in the English language. Some languages (Hindi and Bangla) still lack proper investigations due to the lack of a dataset. This paper particularly worked on the Hindi, Bangla, and English datasets to detect aggressive comments and have shown a novel way of generating machine-translated data to resolve data unavailability issues. A fully machine-translated English dataset has been analyzed with the models such as the Long Short term memory model (LSTM), Bidirectional Long-short term memory model (BiLSTM), LSTM-Autoencoder, word2vec, Bidirectional Encoder Representations from Transformers (BERT), and generative pre-trained transformer (GPT-2) to make an observation on how the models perform on a machine-translated noisy dataset. We have compared the performance of using the noisy data with two more datasets such as raw data, which does not contain any noises, and semi-noisy data, which contains a certain amount of noisy data. We have classified both the raw and semi-noisy data using the aforementioned models. To evaluate the performance of the models, we have used evaluation metrics such as F1-score,accuracy, precision, and recall. We have achieved the highest accuracy on raw data using the gpt2 model, semi-noisy data using the BERT model, and fully machine-translated data using the BERT model. Since many languages do not have proper data availability, our approach will help researchers create machine-translated datasets for several analysis purposes.
Non-parallel Accent Conversion using Pseudo Siamese Disentanglement Network
Dec 12, 2022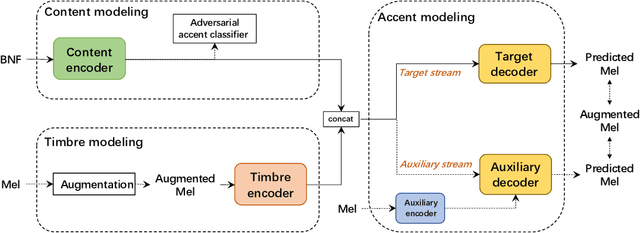
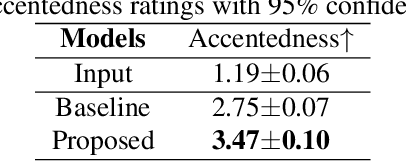
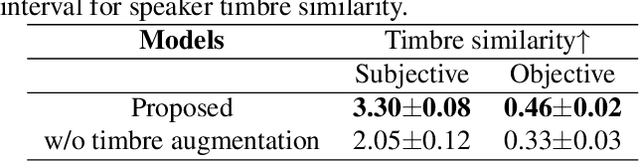
The main goal of accent conversion (AC) is to convert the accent of speech into the target accent while preserving the content and timbre. Previous reference-based methods rely on reference utterances in the inference phase, which limits their practical application. What's more, previous reference-free methods mostly require parallel data in the training phase. In this paper, we propose a reference-free method based on non-parallel data from the perspective of feature disentanglement. Pseudo Siamese Disentanglement Network (PSDN) is proposed to disentangle the accent information from the content representation and model the target accent. Besides, a timbre augmentation method is proposed to enhance the ability of timbre retaining for speakers without target-accent data. Experimental results show that the proposed system can convert the accent of native American English speech into Indian accent with higher accentedness (3.47) than the baseline (2.75) and input (1.19). The naturalness of converted speech is also comparable to that of the input.
Efficient Transformer-based Speech Enhancement Using Long Frames and STFT Magnitudes
Jun 23, 2022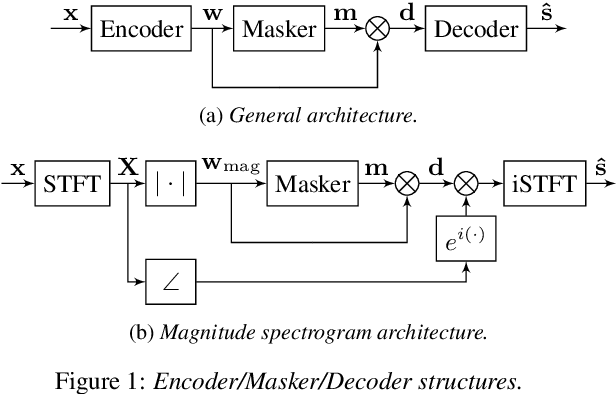
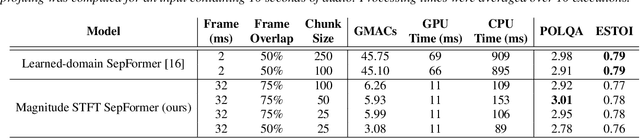
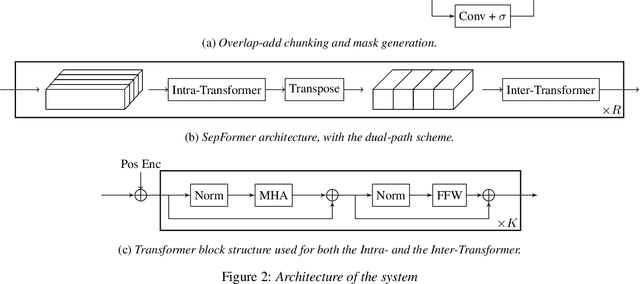
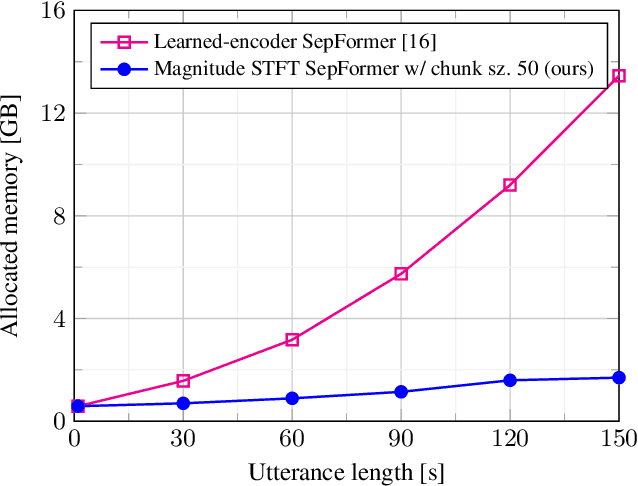
The SepFormer architecture shows very good results in speech separation. Like other learned-encoder models, it uses short frames, as they have been shown to obtain better performance in these cases. This results in a large number of frames at the input, which is problematic; since the SepFormer is transformer-based, its computational complexity drastically increases with longer sequences. In this paper, we employ the SepFormer in a speech enhancement task and show that by replacing the learned-encoder features with a magnitude short-time Fourier transform (STFT) representation, we can use long frames without compromising perceptual enhancement performance. We obtained equivalent quality and intelligibility evaluation scores while reducing the number of operations by a factor of approximately 8 for a 10-second utterance.
Modelling word learning and recognition using visually grounded speech
Mar 14, 2022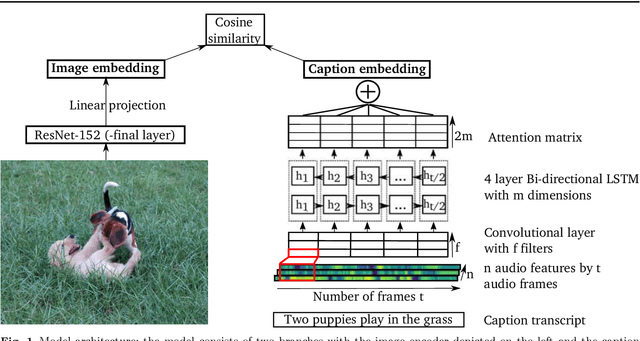
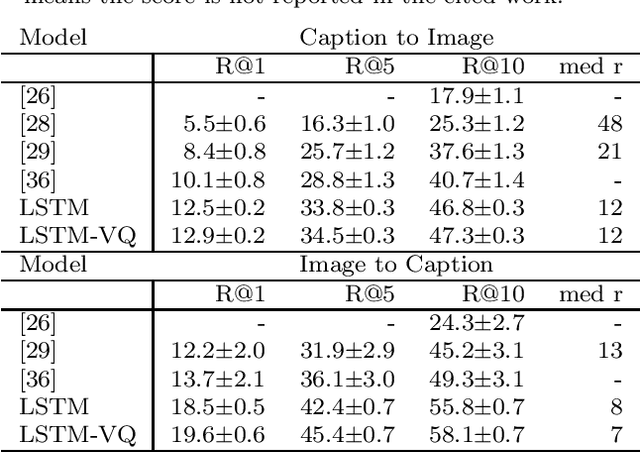
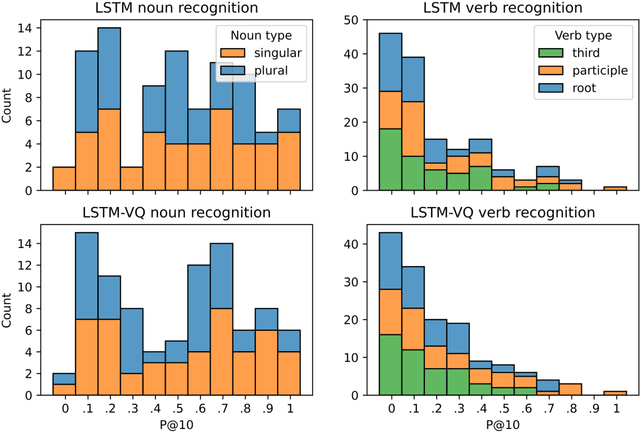
Background: Computational models of speech recognition often assume that the set of target words is already given. This implies that these models do not learn to recognise speech from scratch without prior knowledge and explicit supervision. Visually grounded speech models learn to recognise speech without prior knowledge by exploiting statistical dependencies between spoken and visual input. While it has previously been shown that visually grounded speech models learn to recognise the presence of words in the input, we explicitly investigate such a model as a model of human speech recognition. Methods: We investigate the time-course of word recognition as simulated by the model using a gating paradigm to test whether its recognition is affected by well-known word-competition effects in human speech processing. We furthermore investigate whether vector quantisation, a technique for discrete representation learning, aids the model in the discovery and recognition of words. Results/Conclusion: Our experiments show that the model is able to recognise nouns in isolation and even learns to properly differentiate between plural and singular nouns. We also find that recognition is influenced by word competition from the word-initial cohort and neighbourhood density, mirroring word competition effects in human speech comprehension. Lastly, we find no evidence that vector quantisation is helpful in discovering and recognising words. Our gating experiments even show that the vector quantised model requires more of the input sequence for correct recognition.
AmbiSep: Ambisonic-to-Ambisonic Reverberant Speech Separation Using Transformer Networks
Jun 13, 2022
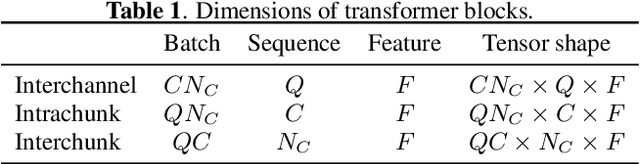
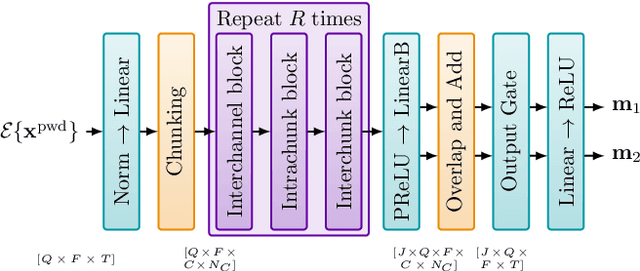

Consider a multichannel Ambisonic recording containing a mixture of several reverberant speech signals. Retreiving the reverberant Ambisonic signals corresponding to the individual speech sources blindly from the mixture is a challenging task as it requires to estimate multiple signal channels for each source. In this work, we propose AmbiSep, a deep neural network-based plane-wave domain masking approach to solve this task. The masking network uses learned feature representations and transformers in a triple-path processing configuration. We train and evaluate the proposed network architecture on a spatialized WSJ0-2mix dataset, and show that the method achieves a multichannel scale-invariant signal-to-distortion ratio improvement of 17.7 dB on the blind test set, while preserving the spatial characteristics of the separated sounds.
Streaming End-to-End Multilingual Speech Recognition with Joint Language Identification
Sep 13, 2022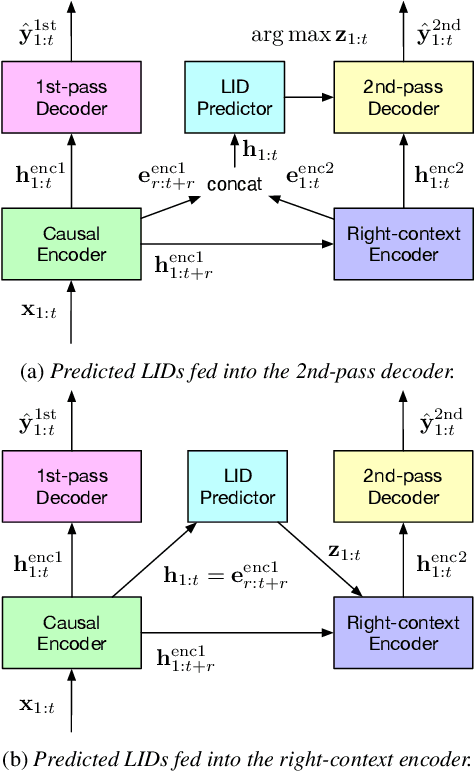


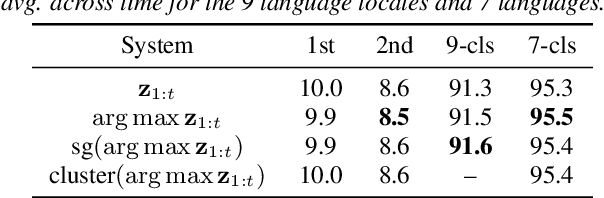
Language identification is critical for many downstream tasks in automatic speech recognition (ASR), and is beneficial to integrate into multilingual end-to-end ASR as an additional task. In this paper, we propose to modify the structure of the cascaded-encoder-based recurrent neural network transducer (RNN-T) model by integrating a per-frame language identifier (LID) predictor. RNN-T with cascaded encoders can achieve streaming ASR with low latency using first-pass decoding with no right-context, and achieve lower word error rates (WERs) using second-pass decoding with longer right-context. By leveraging such differences in the right-contexts and a streaming implementation of statistics pooling, the proposed method can achieve accurate streaming LID prediction with little extra test-time cost. Experimental results on a voice search dataset with 9 language locales shows that the proposed method achieves an average of 96.2% LID prediction accuracy and the same second-pass WER as that obtained by including oracle LID in the input.
Multilingual Content Moderation: A Case Study on Reddit
Feb 19, 2023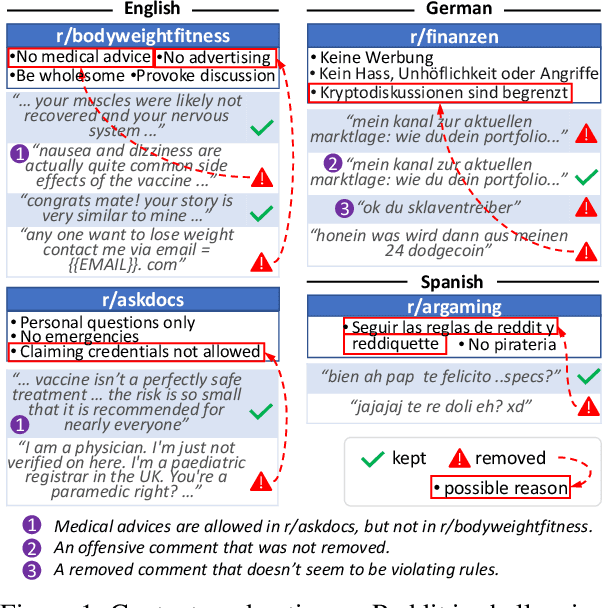
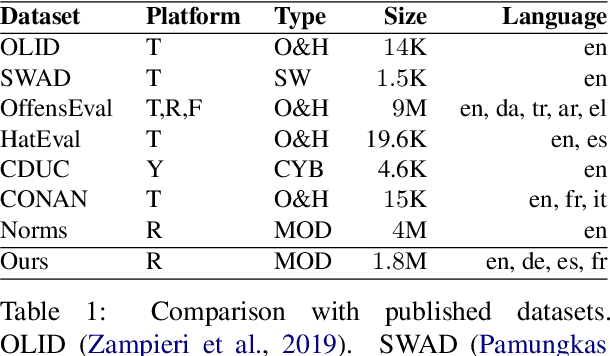
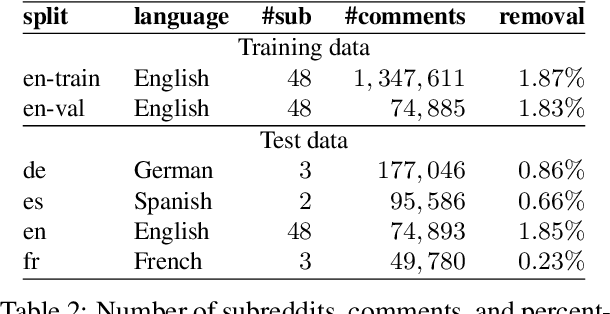
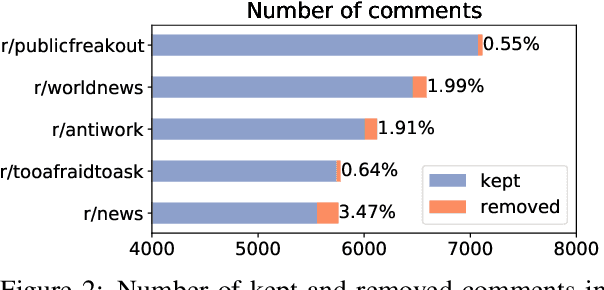
Content moderation is the process of flagging content based on pre-defined platform rules. There has been a growing need for AI moderators to safeguard users as well as protect the mental health of human moderators from traumatic content. While prior works have focused on identifying hateful/offensive language, they are not adequate for meeting the challenges of content moderation since 1) moderation decisions are based on violation of rules, which subsumes detection of offensive speech, and 2) such rules often differ across communities which entails an adaptive solution. We propose to study the challenges of content moderation by introducing a multilingual dataset of 1.8 Million Reddit comments spanning 56 subreddits in English, German, Spanish and French. We perform extensive experimental analysis to highlight the underlying challenges and suggest related research problems such as cross-lingual transfer, learning under label noise (human biases), transfer of moderation models, and predicting the violated rule. Our dataset and analysis can help better prepare for the challenges and opportunities of auto moderation.