 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Conditional Diffusion Probabilistic Model for Speech Enhancement
Feb 10, 2022
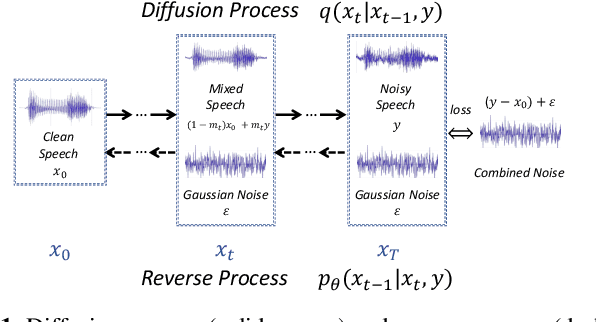
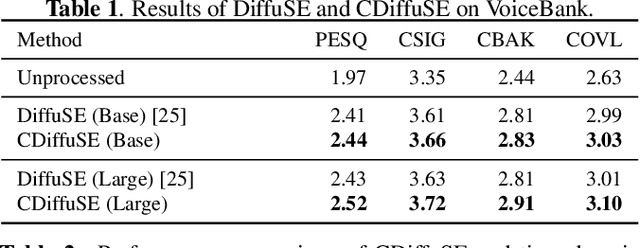
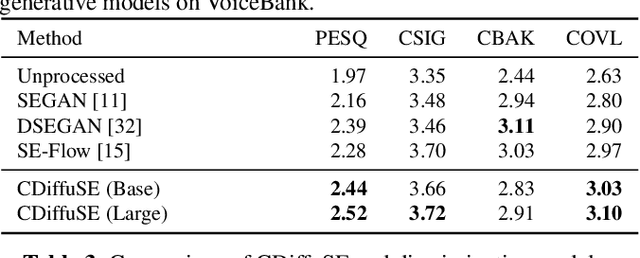
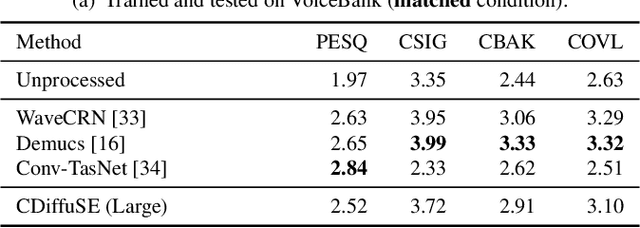
Speech enhancement is a critical component of many user-oriented audio applications, yet current systems still suffer from distorted and unnatural outputs. While generative models have shown strong potential in speech synthesis, they are still lagging behind in speech enhancement. This work leverages recent advances in diffusion probabilistic models, and proposes a novel speech enhancement algorithm that incorporates characteristics of the observed noisy speech signal into the diffusion and reverse processes. More specifically, we propose a generalized formulation of the diffusion probabilistic model named conditional diffusion probabilistic model that, in its reverse process, can adapt to non-Gaussian real noises in the estimated speech signal. In our experiments, we demonstrate strong performance of the proposed approach compared to representative generative models, and investigate the generalization capability of our models to other datasets with noise characteristics unseen during training.
SepIt: Approaching a Single Channel Speech Separation Bound
May 25, 2022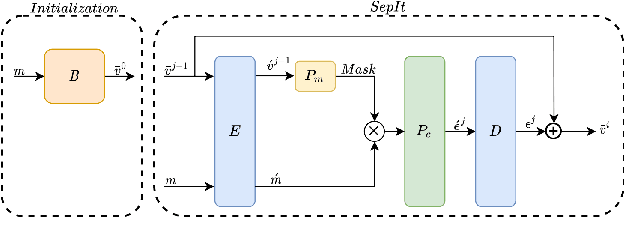
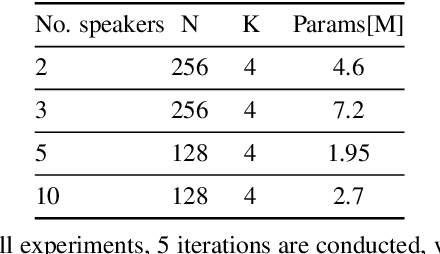
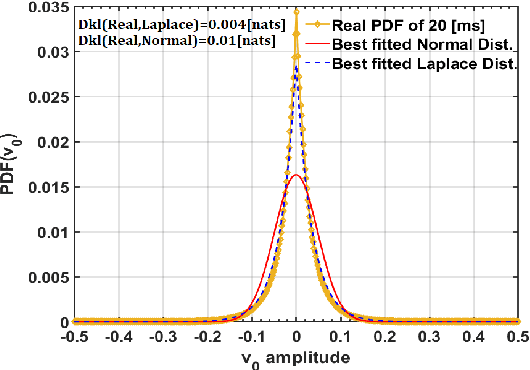
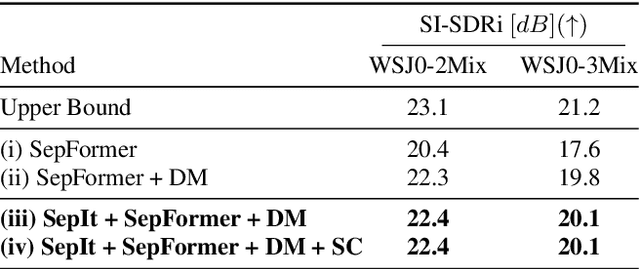
We present an upper bound for the Single Channel Speech Separation task, which is based on an assumption regarding the nature of short segments of speech. Using the bound, we are able to show that while the recent methods have made significant progress for a few speakers, there is room for improvement for five and ten speakers. We then introduce a Deep neural network, SepIt, that iteratively improves the different speakers' estimation. At test time, SpeIt has a varying number of iterations per test sample, based on a mutual information criterion that arises from our analysis. In an extensive set of experiments, SepIt outperforms the state-of-the-art neural networks for 2, 3, 5, and 10 speakers.
Joint Representations of Text and Knowledge Graphs for Retrieval and Evaluation
Feb 28, 2023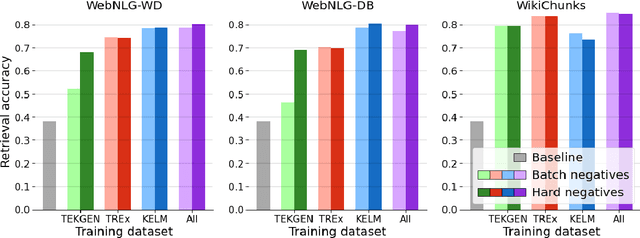

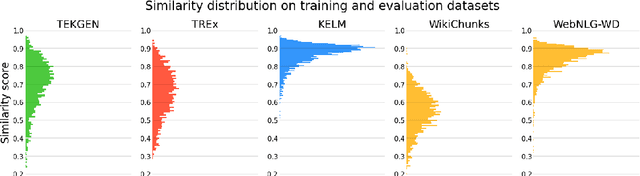
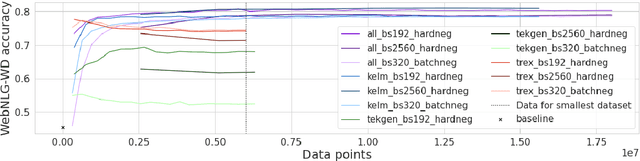
A key feature of neural models is that they can produce semantic vector representations of objects (texts, images, speech, etc.) ensuring that similar objects are close to each other in the vector space. While much work has focused on learning representations for other modalities, there are no aligned cross-modal representations for text and knowledge base (KB) elements. One challenge for learning such representations is the lack of parallel data, which we use contrastive training on heuristics-based datasets and data augmentation to overcome, training embedding models on (KB graph, text) pairs. On WebNLG, a cleaner manually crafted dataset, we show that they learn aligned representations suitable for retrieval. We then fine-tune on annotated data to create EREDAT (Ensembled Representations for Evaluation of DAta-to-Text), a similarity metric between English text and KB graphs. EREDAT outperforms or matches state-of-the-art metrics in terms of correlation with human judgments on WebNLG even though, unlike them, it does not require a reference text to compare against.
A Novel Frame Structure for Cloud-Based Audio-Visual Speech Enhancement in Multimodal Hearing-aids
Oct 24, 2022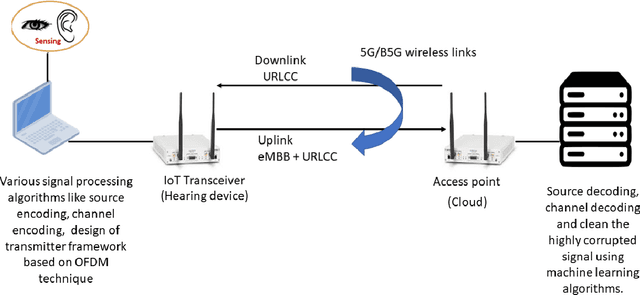
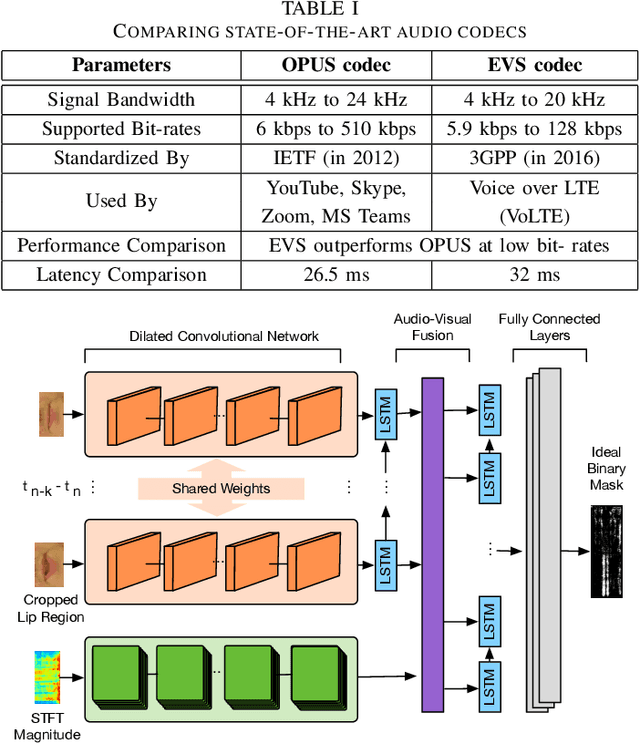
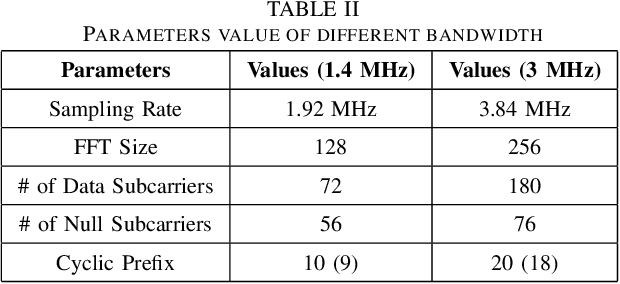
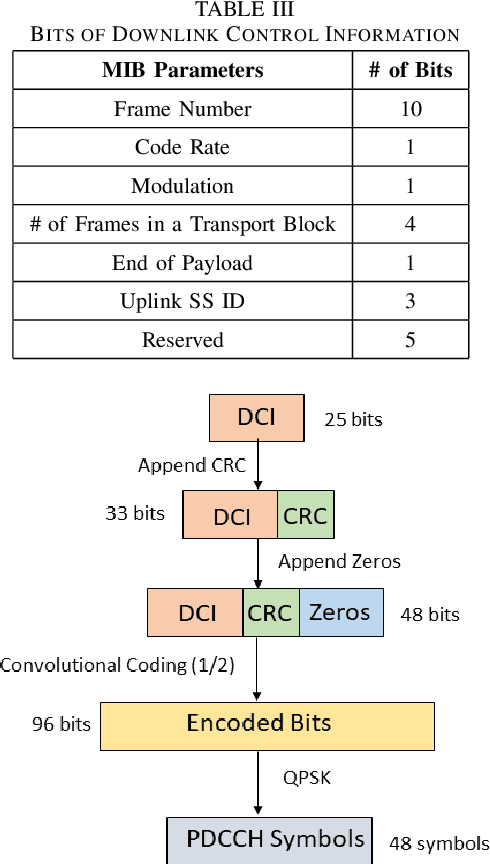
In this paper, we design a first of its kind transceiver (PHY layer) prototype for cloud-based audio-visual (AV) speech enhancement (SE) complying with high data rate and low latency requirements of future multimodal hearing assistive technology. The innovative design needs to meet multiple challenging constraints including up/down link communications, delay of transmission and signal processing, and real-time AV SE models processing. The transceiver includes device detection, frame detection, frequency offset estimation, and channel estimation capabilities. We develop both uplink (hearing aid to the cloud) and downlink (cloud to hearing aid) frame structures based on the data rate and latency requirements. Due to the varying nature of uplink information (audio and lip-reading), the uplink channel supports multiple data rate frame structure, while the downlink channel has a fixed data rate frame structure. In addition, we evaluate the latency of different PHY layer blocks of the transceiver for developed frame structures using LabVIEW NXG. This can be used with software defined radio (such as Universal Software Radio Peripheral) for real-time demonstration scenarios.
Disentangled Latent Speech Representation for Automatic Pathological Intelligibility Assessment
Apr 08, 2022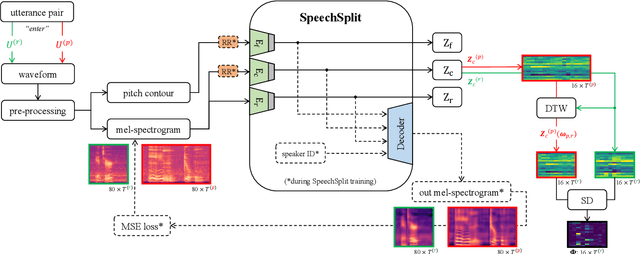
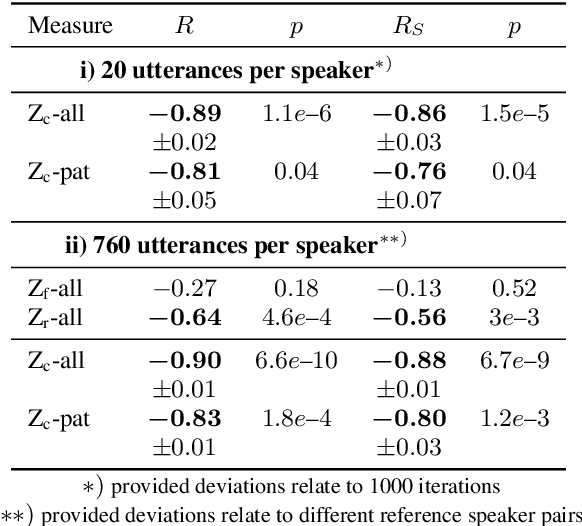
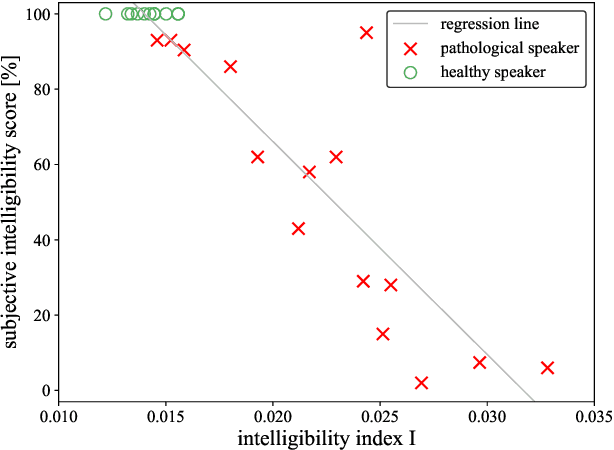
Speech intelligibility assessment plays an important role in the therapy of patients suffering from pathological speech disorders. Automatic and objective measures are desirable to assist therapists in their traditionally subjective and labor-intensive assessments. In this work, we investigate a novel approach for obtaining such a measure using the divergence in disentangled latent speech representations of a parallel utterance pair, obtained from a healthy reference and a pathological speaker. Experiments on an English database of Cerebral Palsy patients, using all available utterances per speaker, show high and significant correlation values (R = -0.9) with subjective intelligibility measures, while having only minimal deviation (+-0.01) across four different reference speaker pairs. We also demonstrate the robustness of the proposed method (R = -0.89 deviating +-0.02 over 1000 iterations) by considering a significantly smaller amount of utterances per speaker. Our results are among the first to show that disentangled speech representations can be used for automatic pathological speech intelligibility assessment, resulting in a reference speaker pair invariant method, applicable in scenarios with only few utterances available.
Joint Speech Recognition and Audio Captioning
Feb 03, 2022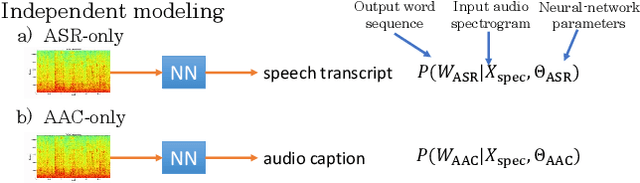
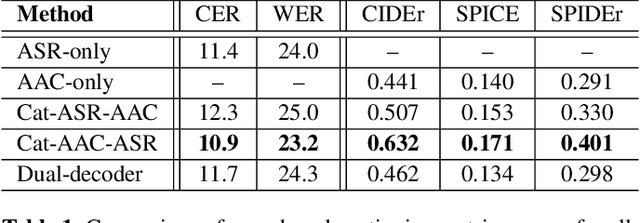
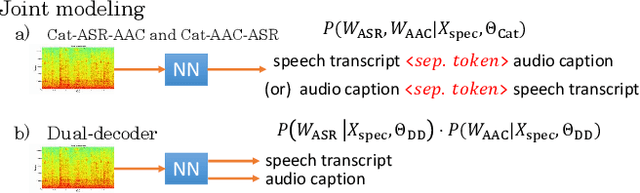
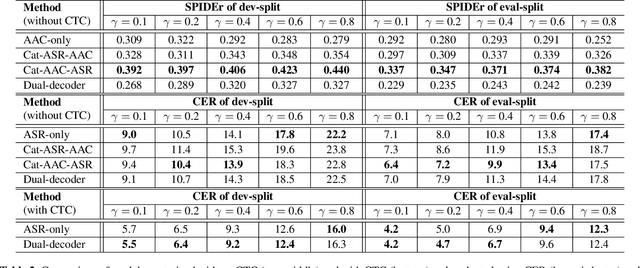
Speech samples recorded in both indoor and outdoor environments are often contaminated with secondary audio sources. Most end-to-end monaural speech recognition systems either remove these background sounds using speech enhancement or train noise-robust models. For better model interpretability and holistic understanding, we aim to bring together the growing field of automated audio captioning (AAC) and the thoroughly studied automatic speech recognition (ASR). The goal of AAC is to generate natural language descriptions of contents in audio samples. We propose several approaches for end-to-end joint modeling of ASR and AAC tasks and demonstrate their advantages over traditional approaches, which model these tasks independently. A major hurdle in evaluating our proposed approach is the lack of labeled audio datasets with both speech transcriptions and audio captions. Therefore we also create a multi-task dataset by mixing the clean speech Wall Street Journal corpus with multiple levels of background noises chosen from the AudioCaps dataset. We also perform extensive experimental evaluation and show improvements of our proposed methods as compared to existing state-of-the-art ASR and AAC methods.
SepIt Approaching a Single Channel Speech Separation Bound
May 24, 2022We present an upper bound for the Single Channel Speech Separation task, which is based on an assumption regarding the nature of short segments of speech. Using the bound, we are able to show that while the recent methods have made significant progress for a few speakers, there is room for improvement for five and ten speakers. We then introduce a Deep neural network, SepIt, that iteratively improves the different speakers' estimation. At test time, SpeIt has a varying number of iterations per test sample, based on a mutual information criterion that arises from our analysis. In an extensive set of experiments, SepIt outperforms the state-of-the-art neural networks for 2, 3, 5, and 10 speakers.
Improving Monaural Speech Enhancement with Multi-head Self and Cross Attention
May 20, 2022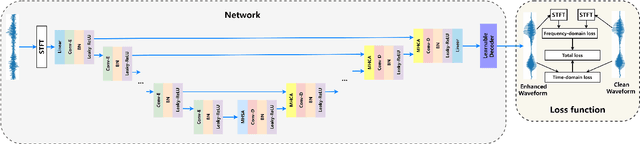
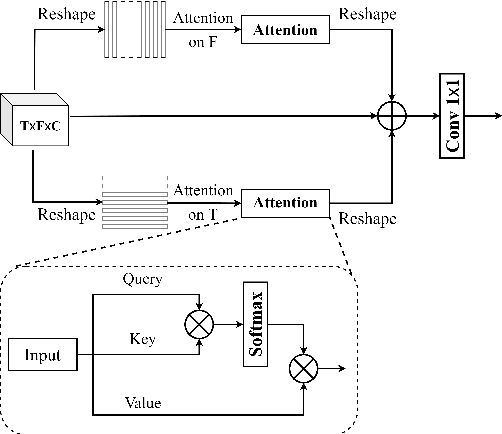
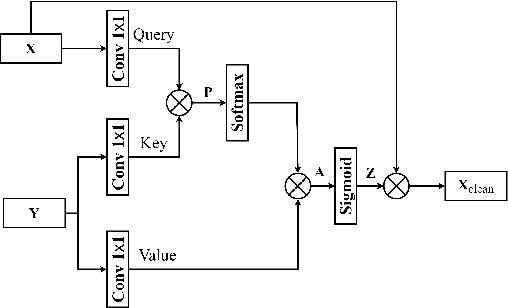
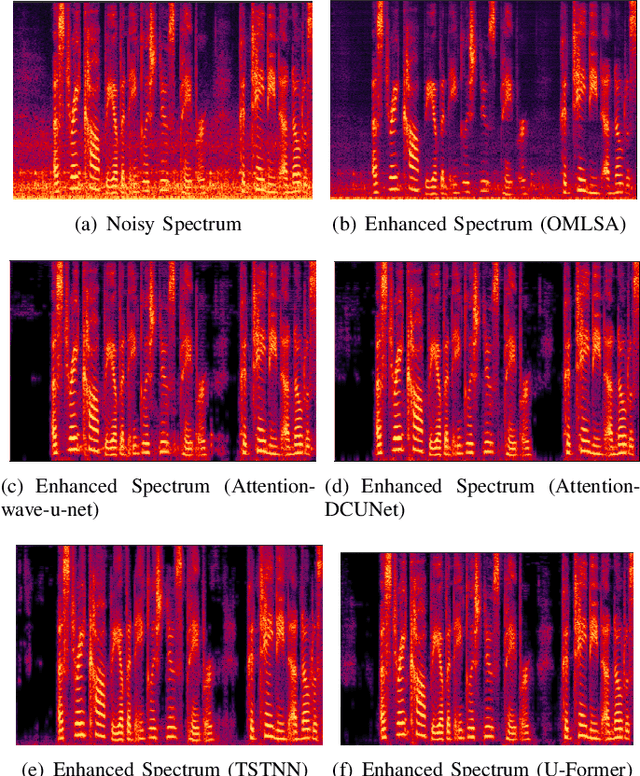
For supervised speech enhancement, contextual information is important for accurate spectral mapping. However, commonly used deep neural networks (DNNs) are limited in capturing temporal contexts. To leverage long-term contexts for tracking a target speaker, this paper treats the speech enhancement as sequence-to-sequence mapping, and propose a novel monaural speech enhancement U-net structure based on Transformer, dubbed U-Former. The key idea is to model long-term correlations and dependencies, which are crucial for accurate noisy speech modeling, through the multi-head attention mechanisms. For this purpose, U-Former incorporates multi-head attention mechanisms at two levels: 1) a multi-head self-attention module which calculate the attention map along both time- and frequency-axis to generate time and frequency sub-attention maps for leveraging global interactions between encoder features, while 2) multi-head cross-attention module which are inserted in the skip connections allows a fine recovery in the decoder by filtering out uncorrelated features. Experimental results illustrate that the U-Former obtains consistently better performance than recent models of PESQ, STOI, and SSNR scores.
Wav2Seq: Pre-training Speech-to-Text Encoder-Decoder Models Using Pseudo Languages
May 02, 2022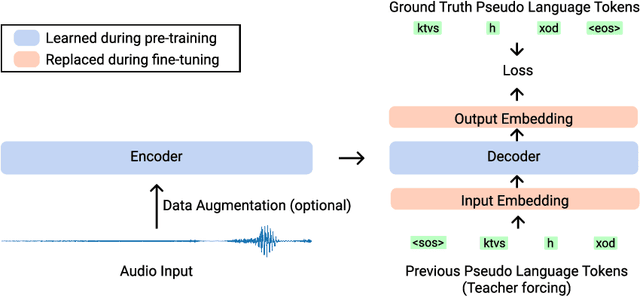

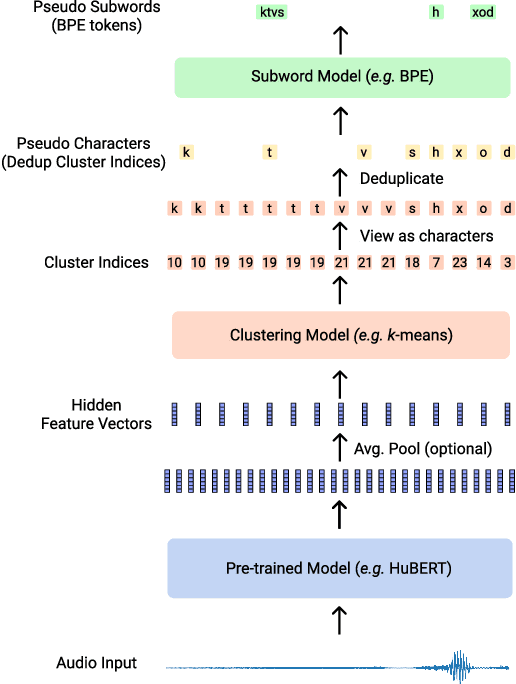
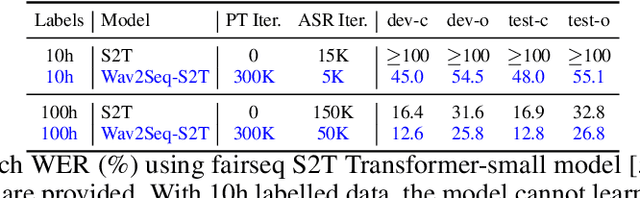
We introduce Wav2Seq, the first self-supervised approach to pre-train both parts of encoder-decoder models for speech data. We induce a pseudo language as a compact discrete representation, and formulate a self-supervised pseudo speech recognition task -- transcribing audio inputs into pseudo subword sequences. This process stands on its own, or can be applied as low-cost second-stage pre-training. We experiment with automatic speech recognition (ASR), spoken named entity recognition, and speech-to-text translation. We set new state-of-the-art results for end-to-end spoken named entity recognition, and show consistent improvements on 20 language pairs for speech-to-text translation, even when competing methods use additional text data for training. Finally, on ASR, our approach enables encoder-decoder methods to benefit from pre-training for all parts of the network, and shows comparable performance to highly optimized recent methods.
Automatic Detection of Speech Sound Disorder in Child Speech Using Posterior-based Speaker Representations
Mar 29, 2022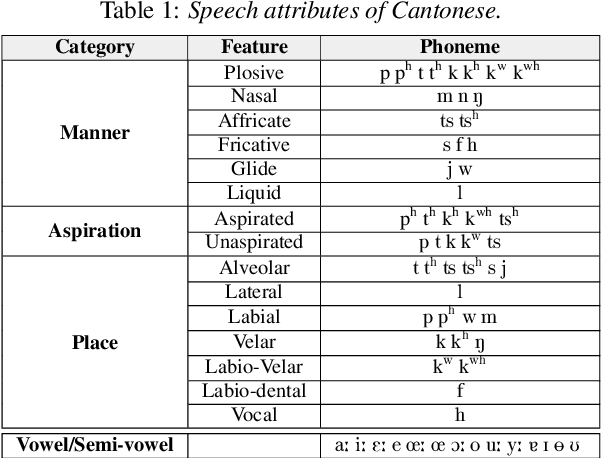
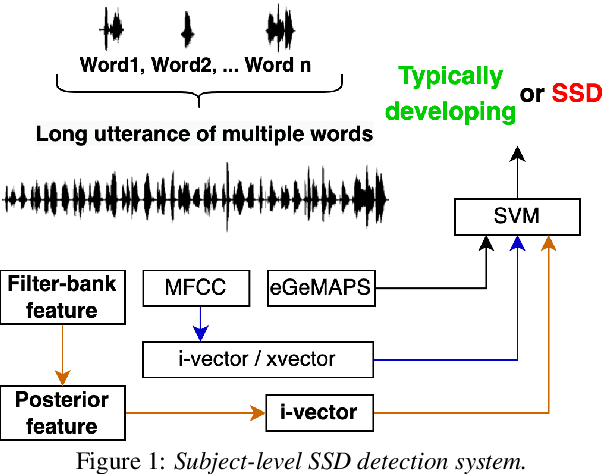
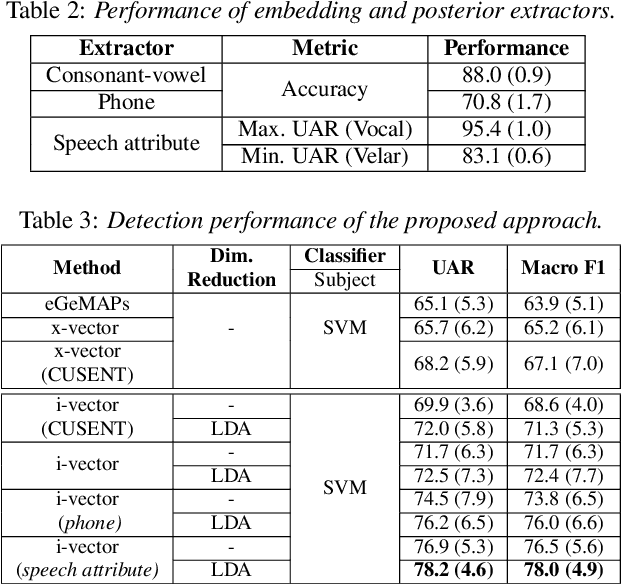
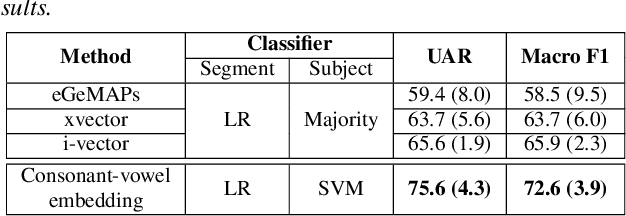
This paper presents a macroscopic approach to automatic detection of speech sound disorder (SSD) in child speech. Typically, SSD is manifested by persistent articulation and phonological errors on specific phonemes in the language. The disorder can be detected by focally analyzing the phonemes or the words elicited by the child subject. In the present study, instead of attempting to detect individual phone- and word-level errors, we propose to extract a subject-level representation from a long utterance that is constructed by concatenating multiple test words. The speaker verification approach, and posterior features generated by deep neural network models, are applied to derive various types of holistic representations. A linear classifier is trained to differentiate disordered speech in normal one. On the task of detecting SSD in Cantonese-speaking children, experimental results show that the proposed approach achieves improved detection performance over previous method that requires fusing phone-level detection results. Using articulatory posterior features to derive i-vectors from multiple-word utterances achieves an unweighted average recall of 78.2% and a macro F1 score of 78.0%.