 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SelfRemaster: Self-Supervised Speech Restoration with Analysis-by-Synthesis Approach Using Channel Modeling
Mar 24, 2022
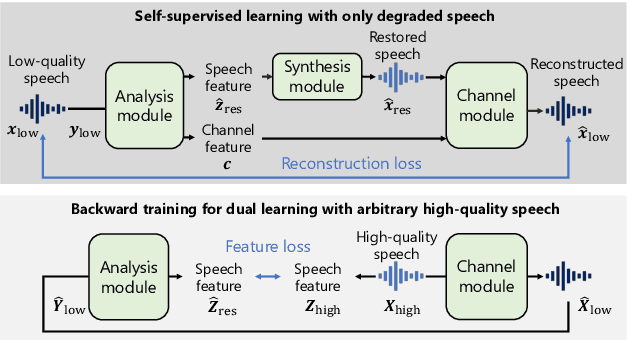
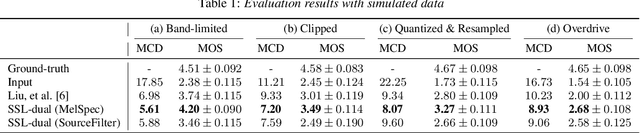
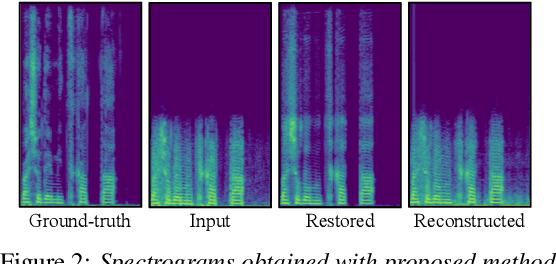
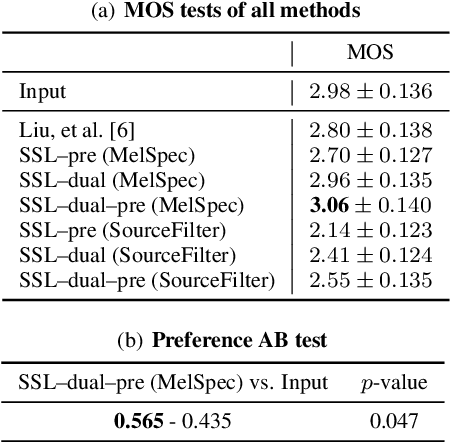
We present a self-supervised speech restoration method without paired speech corpora. Because the previous general speech restoration method uses artificial paired data created by applying various distortions to high-quality speech corpora, it cannot sufficiently represent acoustic distortions of real data, limiting the applicability. Our model consists of analysis, synthesis, and channel modules that simulate the recording process of degraded speech and is trained with real degraded speech data in a self-supervised manner. The analysis module extracts distortionless speech features and distortion features from degraded speech, while the synthesis module synthesizes the restored speech waveform, and the channel module adds distortions to the speech waveform. Our model also enables audio effect transfer, in which only acoustic distortions are extracted from degraded speech and added to arbitrary high-quality audio. Experimental evaluations with both simulated and real data show that our method achieves significantly higher-quality speech restoration than the previous supervised method, suggesting its applicability to real degraded speech materials.
SepIt: Approaching a Single Channel Speech Separation Bound
May 25, 2022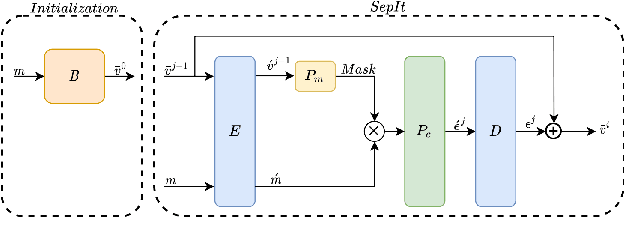
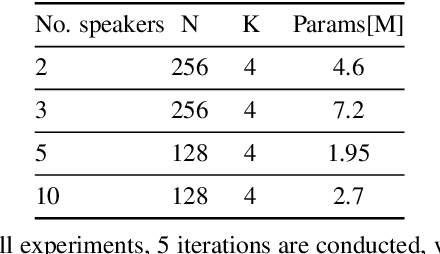
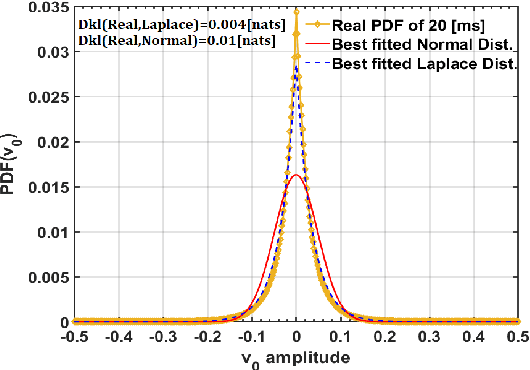
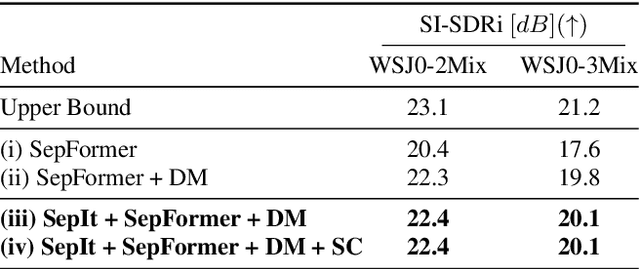
We present an upper bound for the Single Channel Speech Separation task, which is based on an assumption regarding the nature of short segments of speech. Using the bound, we are able to show that while the recent methods have made significant progress for a few speakers, there is room for improvement for five and ten speakers. We then introduce a Deep neural network, SepIt, that iteratively improves the different speakers' estimation. At test time, SpeIt has a varying number of iterations per test sample, based on a mutual information criterion that arises from our analysis. In an extensive set of experiments, SepIt outperforms the state-of-the-art neural networks for 2, 3, 5, and 10 speakers.
Conditional Diffusion Probabilistic Model for Speech Enhancement
Feb 10, 2022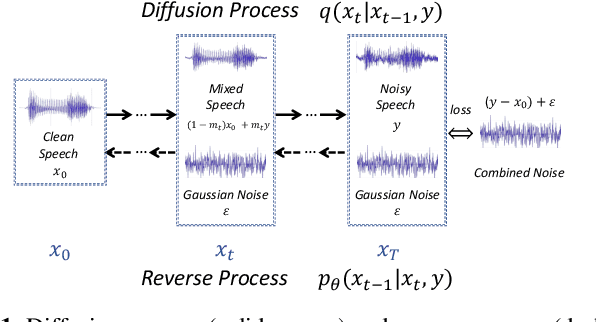
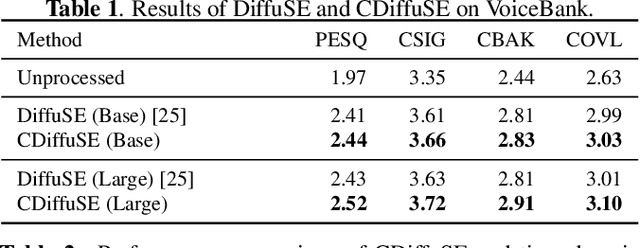
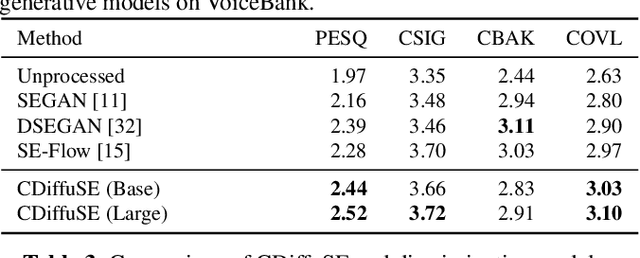
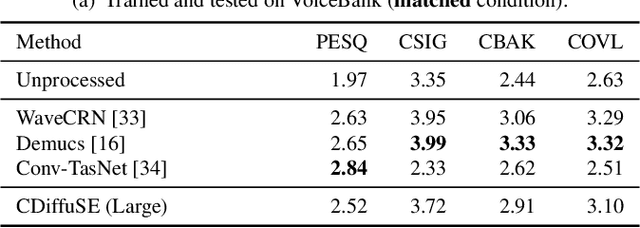
Speech enhancement is a critical component of many user-oriented audio applications, yet current systems still suffer from distorted and unnatural outputs. While generative models have shown strong potential in speech synthesis, they are still lagging behind in speech enhancement. This work leverages recent advances in diffusion probabilistic models, and proposes a novel speech enhancement algorithm that incorporates characteristics of the observed noisy speech signal into the diffusion and reverse processes. More specifically, we propose a generalized formulation of the diffusion probabilistic model named conditional diffusion probabilistic model that, in its reverse process, can adapt to non-Gaussian real noises in the estimated speech signal. In our experiments, we demonstrate strong performance of the proposed approach compared to representative generative models, and investigate the generalization capability of our models to other datasets with noise characteristics unseen during training.
Disentangled Latent Speech Representation for Automatic Pathological Intelligibility Assessment
Apr 08, 2022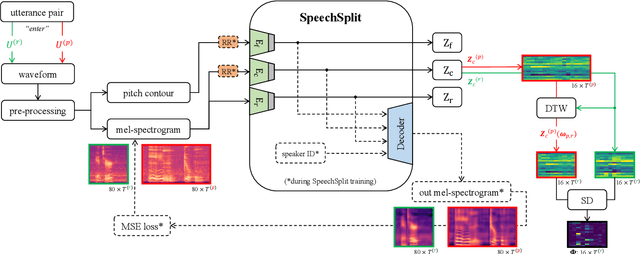
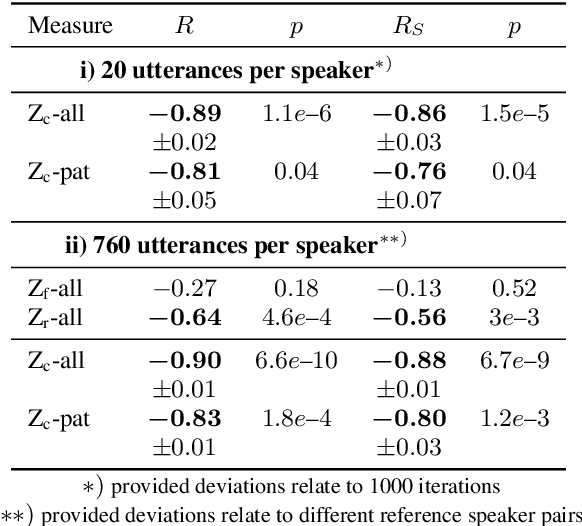
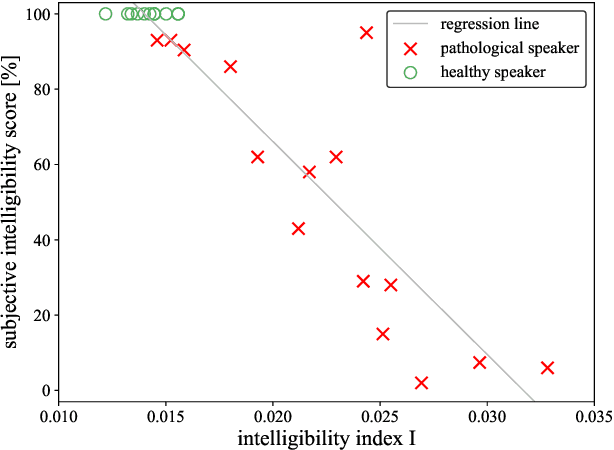
Speech intelligibility assessment plays an important role in the therapy of patients suffering from pathological speech disorders. Automatic and objective measures are desirable to assist therapists in their traditionally subjective and labor-intensive assessments. In this work, we investigate a novel approach for obtaining such a measure using the divergence in disentangled latent speech representations of a parallel utterance pair, obtained from a healthy reference and a pathological speaker. Experiments on an English database of Cerebral Palsy patients, using all available utterances per speaker, show high and significant correlation values (R = -0.9) with subjective intelligibility measures, while having only minimal deviation (+-0.01) across four different reference speaker pairs. We also demonstrate the robustness of the proposed method (R = -0.89 deviating +-0.02 over 1000 iterations) by considering a significantly smaller amount of utterances per speaker. Our results are among the first to show that disentangled speech representations can be used for automatic pathological speech intelligibility assessment, resulting in a reference speaker pair invariant method, applicable in scenarios with only few utterances available.
Joint Speech Recognition and Audio Captioning
Feb 03, 2022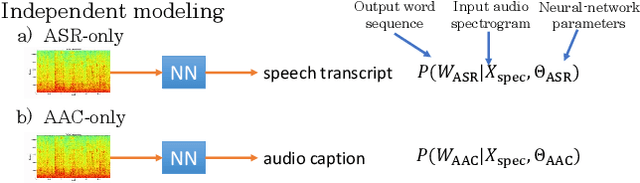
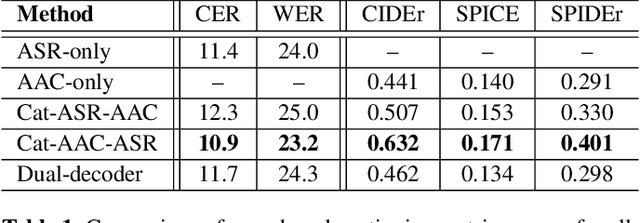
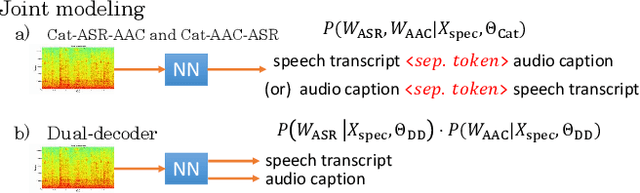
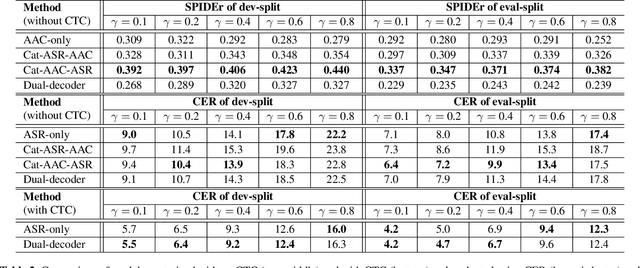
Speech samples recorded in both indoor and outdoor environments are often contaminated with secondary audio sources. Most end-to-end monaural speech recognition systems either remove these background sounds using speech enhancement or train noise-robust models. For better model interpretability and holistic understanding, we aim to bring together the growing field of automated audio captioning (AAC) and the thoroughly studied automatic speech recognition (ASR). The goal of AAC is to generate natural language descriptions of contents in audio samples. We propose several approaches for end-to-end joint modeling of ASR and AAC tasks and demonstrate their advantages over traditional approaches, which model these tasks independently. A major hurdle in evaluating our proposed approach is the lack of labeled audio datasets with both speech transcriptions and audio captions. Therefore we also create a multi-task dataset by mixing the clean speech Wall Street Journal corpus with multiple levels of background noises chosen from the AudioCaps dataset. We also perform extensive experimental evaluation and show improvements of our proposed methods as compared to existing state-of-the-art ASR and AAC methods.
SepIt Approaching a Single Channel Speech Separation Bound
May 24, 2022We present an upper bound for the Single Channel Speech Separation task, which is based on an assumption regarding the nature of short segments of speech. Using the bound, we are able to show that while the recent methods have made significant progress for a few speakers, there is room for improvement for five and ten speakers. We then introduce a Deep neural network, SepIt, that iteratively improves the different speakers' estimation. At test time, SpeIt has a varying number of iterations per test sample, based on a mutual information criterion that arises from our analysis. In an extensive set of experiments, SepIt outperforms the state-of-the-art neural networks for 2, 3, 5, and 10 speakers.
Improving Monaural Speech Enhancement with Multi-head Self and Cross Attention
May 20, 2022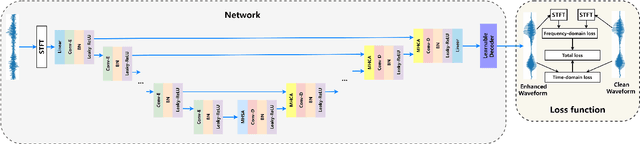
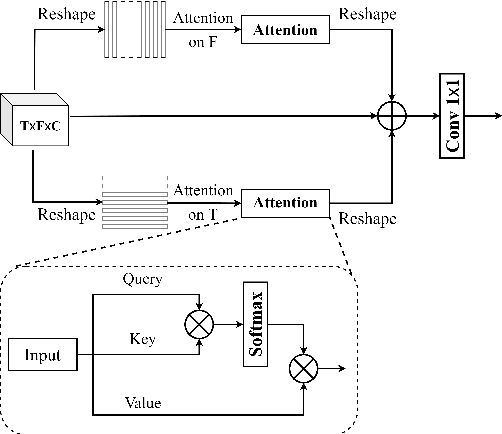
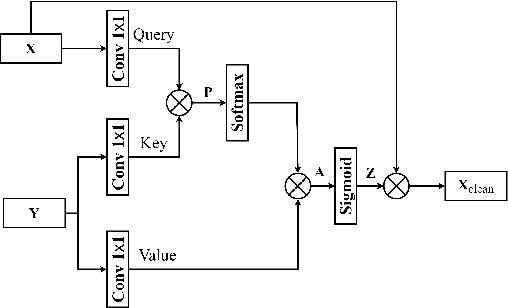
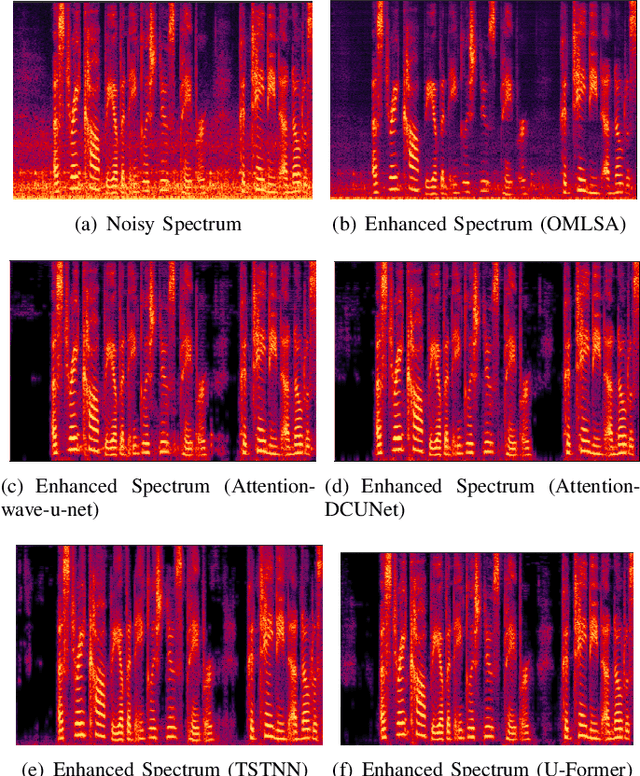
For supervised speech enhancement, contextual information is important for accurate spectral mapping. However, commonly used deep neural networks (DNNs) are limited in capturing temporal contexts. To leverage long-term contexts for tracking a target speaker, this paper treats the speech enhancement as sequence-to-sequence mapping, and propose a novel monaural speech enhancement U-net structure based on Transformer, dubbed U-Former. The key idea is to model long-term correlations and dependencies, which are crucial for accurate noisy speech modeling, through the multi-head attention mechanisms. For this purpose, U-Former incorporates multi-head attention mechanisms at two levels: 1) a multi-head self-attention module which calculate the attention map along both time- and frequency-axis to generate time and frequency sub-attention maps for leveraging global interactions between encoder features, while 2) multi-head cross-attention module which are inserted in the skip connections allows a fine recovery in the decoder by filtering out uncorrelated features. Experimental results illustrate that the U-Former obtains consistently better performance than recent models of PESQ, STOI, and SSNR scores.
Approaching an unknown communication system by latent space exploration and causal inference
Mar 20, 2023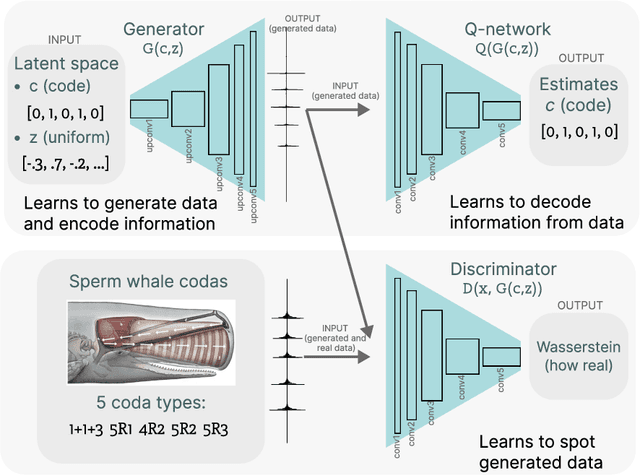
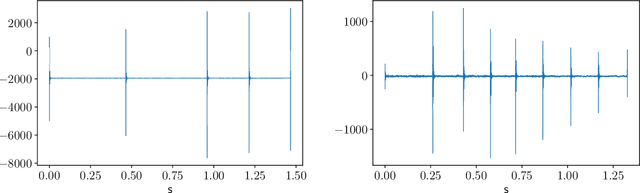
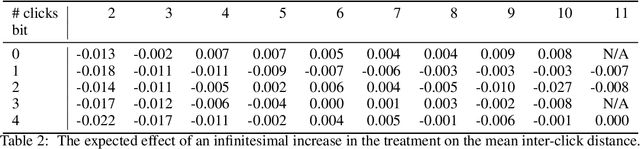
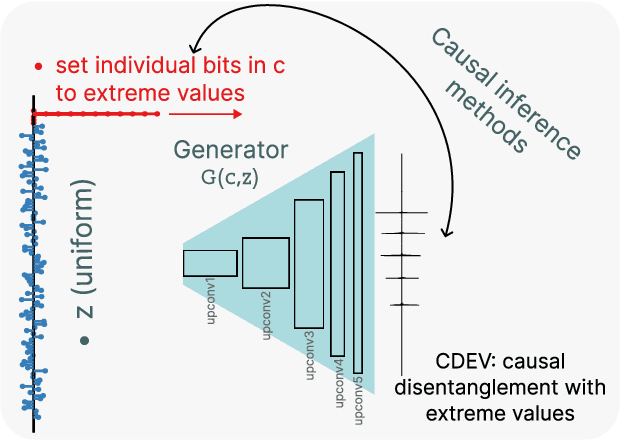
This paper proposes a methodology for discovering meaningful properties in data by exploring the latent space of unsupervised deep generative models. We combine manipulation of individual latent variables to extreme values outside the training range with methods inspired by causal inference into an approach we call causal disentanglement with extreme values (CDEV) and show that this approach yields insights for model interpretability. Using this technique, we can infer what properties of unknown data the model encodes as meaningful. We apply the methodology to test what is meaningful in the communication system of sperm whales, one of the most intriguing and understudied animal communication systems. We train a network that has been shown to learn meaningful representations of speech and test whether we can leverage such unsupervised learning to decipher the properties of another vocal communication system for which we have no ground truth. The proposed technique suggests that sperm whales encode information using the number of clicks in a sequence, the regularity of their timing, and audio properties such as the spectral mean and the acoustic regularity of the sequences. Some of these findings are consistent with existing hypotheses, while others are proposed for the first time. We also argue that our models uncover rules that govern the structure of communication units in the sperm whale communication system and apply them while generating innovative data not shown during training. This paper suggests that an interpretation of the outputs of deep neural networks with causal methodology can be a viable strategy for approaching data about which little is known and presents another case of how deep learning can limit the hypothesis space. Finally, the proposed approach combining latent space manipulation and causal inference can be extended to other architectures and arbitrary datasets.
Learnable Frontends that do not Learn: Quantifying Sensitivity to Filterbank Initialisation
Feb 20, 2023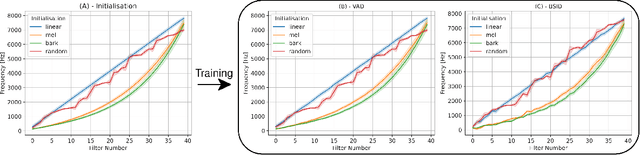
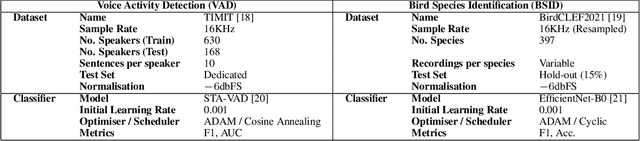
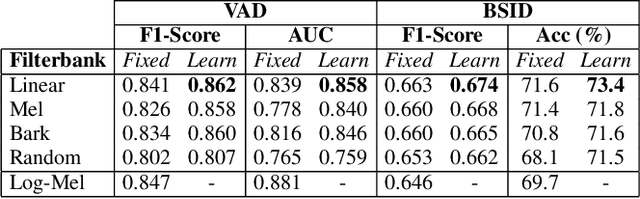
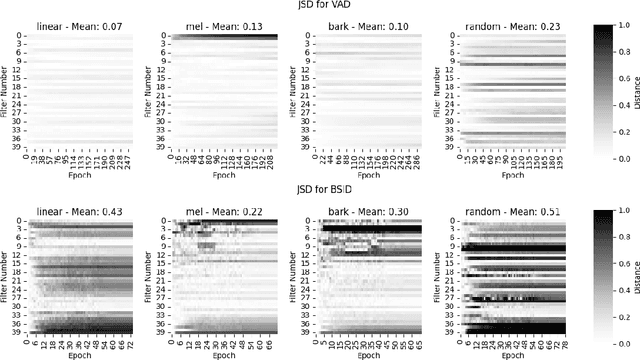
While much of modern speech and audio processing relies on deep neural networks trained using fixed audio representations, recent studies suggest great potential in acoustic frontends learnt jointly with a backend. In this study, we focus specifically on learnable filterbanks. Prior studies have reported that in frontends using learnable filterbanks initialised to a mel scale, the learned filters do not differ substantially from their initialisation. Using a Gabor-based filterbank, we investigate the sensitivity of a learnable filterbank to its initialisation using several initialisation strategies on two audio tasks: voice activity detection and bird species identification. We use the Jensen-Shannon Distance and analysis of the learned filters before and after training. We show that although performance is overall improved, the filterbanks exhibit strong sensitivity to their initialisation strategy. The limited movement from initialised values suggests that alternate optimisation strategies may allow a learnable frontend to reach better overall performance.
Wav2Seq: Pre-training Speech-to-Text Encoder-Decoder Models Using Pseudo Languages
May 02, 2022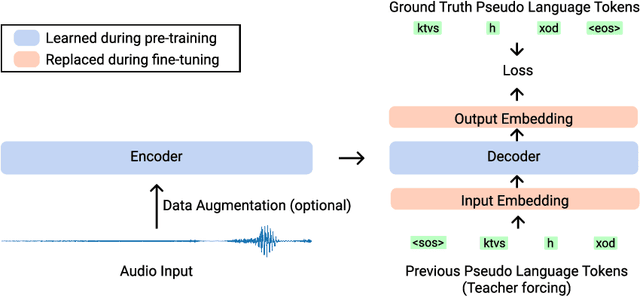

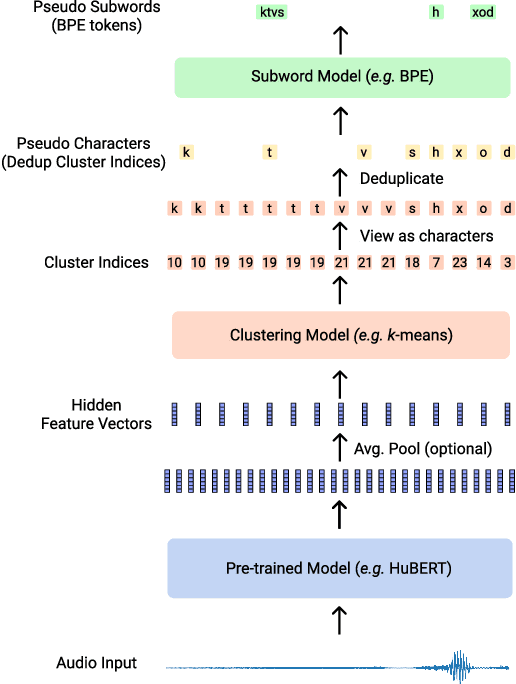
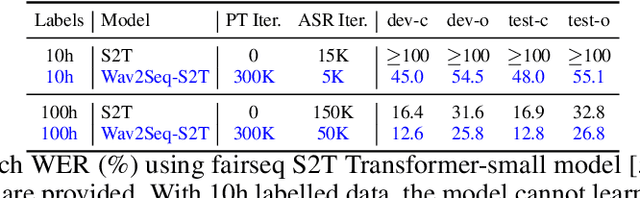
We introduce Wav2Seq, the first self-supervised approach to pre-train both parts of encoder-decoder models for speech data. We induce a pseudo language as a compact discrete representation, and formulate a self-supervised pseudo speech recognition task -- transcribing audio inputs into pseudo subword sequences. This process stands on its own, or can be applied as low-cost second-stage pre-training. We experiment with automatic speech recognition (ASR), spoken named entity recognition, and speech-to-text translation. We set new state-of-the-art results for end-to-end spoken named entity recognition, and show consistent improvements on 20 language pairs for speech-to-text translation, even when competing methods use additional text data for training. Finally, on ASR, our approach enables encoder-decoder methods to benefit from pre-training for all parts of the network, and shows comparable performance to highly optimized recent methods.