 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Continuous descriptor-based control for deep audio synthesis
Feb 27, 2023
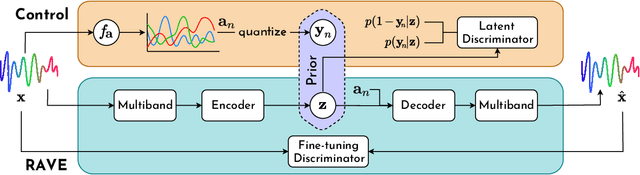

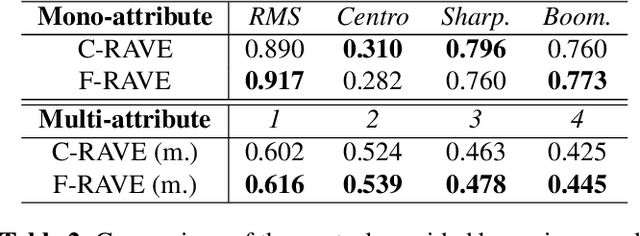
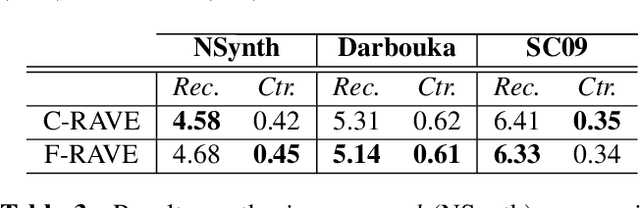
Despite significant advances in deep models for music generation, the use of these techniques remains restricted to expert users. Before being democratized among musicians, generative models must first provide expressive control over the generation, as this conditions the integration of deep generative models in creative workflows. In this paper, we tackle this issue by introducing a deep generative audio model providing expressive and continuous descriptor-based control, while remaining lightweight enough to be embedded in a hardware synthesizer. We enforce the controllability of real-time generation by explicitly removing salient musical features in the latent space using an adversarial confusion criterion. User-specified features are then reintroduced as additional conditioning information, allowing for continuous control of the generation, akin to a synthesizer knob. We assess the performance of our method on a wide variety of sounds including instrumental, percussive and speech recordings while providing both timbre and attributes transfer, allowing new ways of generating sounds.
NatiQ: An End-to-end Text-to-Speech System for Arabic
Jun 15, 2022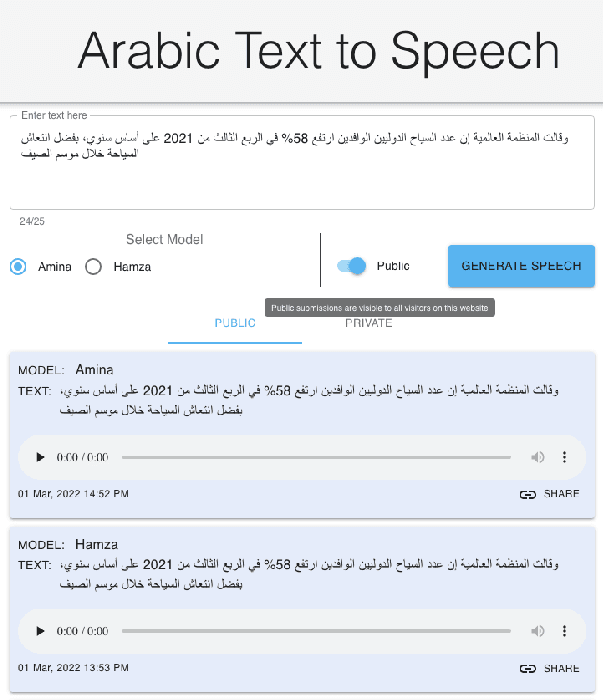
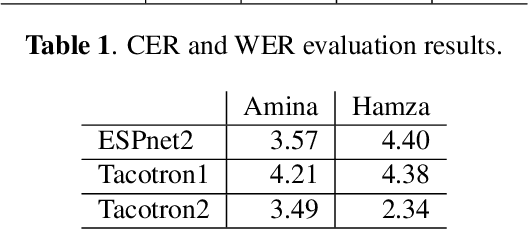
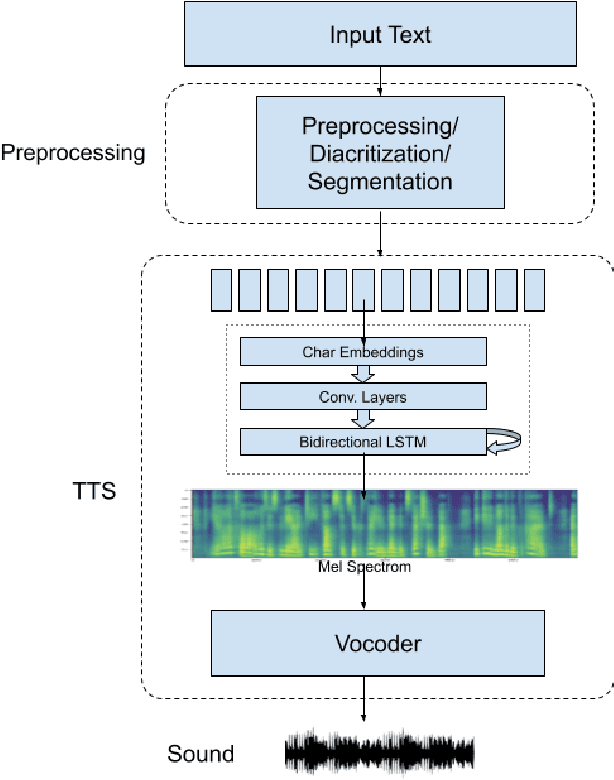
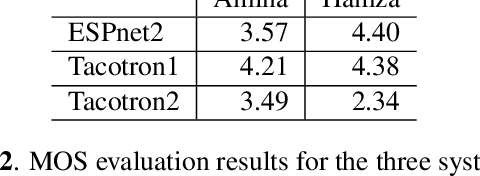
NatiQ is end-to-end text-to-speech system for Arabic. Our speech synthesizer uses an encoder-decoder architecture with attention. We used both tacotron-based models (tacotron-1 and tacotron-2) and the faster transformer model for generating mel-spectrograms from characters. We concatenated Tacotron1 with the WaveRNN vocoder, Tacotron2 with the WaveGlow vocoder and ESPnet transformer with the parallel wavegan vocoder to synthesize waveforms from the spectrograms. We used in-house speech data for two voices: 1) neutral male "Hamza"- narrating general content and news, and 2) expressive female "Amina"- narrating children story books to train our models. Our best systems achieve an average Mean Opinion Score (MOS) of 4.21 and 4.40 for Amina and Hamza respectively. The objective evaluation of the systems using word and character error rate (WER and CER) as well as the response time measured by real-time factor favored the end-to-end architecture ESPnet. NatiQ demo is available on-line at https://tts.qcri.org
Spectrogram Inversion for Audio Source Separation via Consistency, Mixing, and Magnitude Constraints
Mar 03, 2023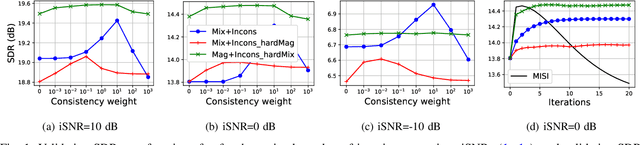
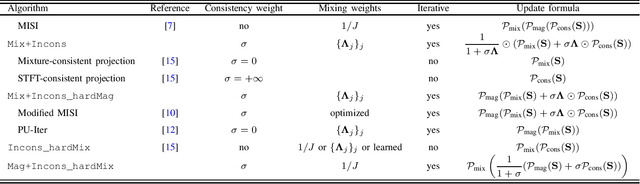
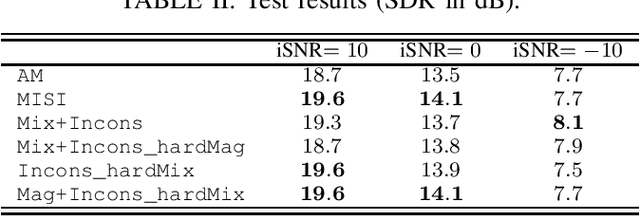
Audio source separation is often achieved by estimating the magnitude spectrogram of each source, and then applying a phase recovery (or spectrogram inversion) algorithm to retrieve time-domain signals. Typically, spectrogram inversion is treated as an optimization problem involving one or several terms in order to promote estimates that comply with a consistency property, a mixing constraint, and/or a target magnitude objective. Nonetheless, it is still unclear which set of constraints and problem formulation is the most appropriate in practice. In this paper, we design a general framework for deriving spectrogram inversion algorithm, which is based on formulating optimization problems by combining these objectives either as soft penalties or hard constraints. We solve these by means of algorithms that perform alternating projections on the subsets corresponding to each objective/constraint. Our framework encompasses existing techniques from the literature as well as novel algorithms. We investigate the potential of these approaches for a speech enhancement task. In particular, one of our novel algorithms outperforms other approaches in a realistic setting where the magnitudes are estimated beforehand using a neural network.
Improving Distortion Robustness of Self-supervised Speech Processing Tasks with Domain Adaptation
Mar 30, 2022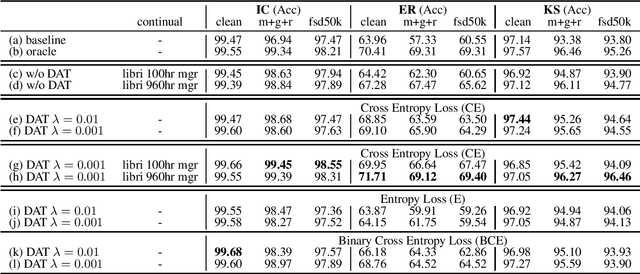
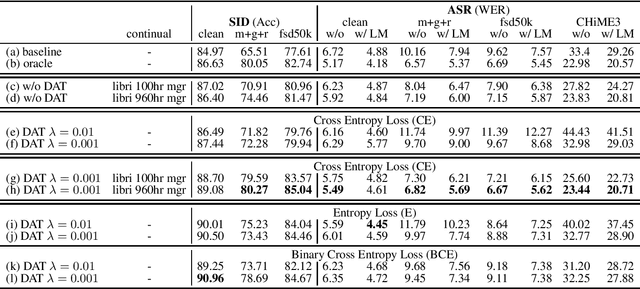
Speech distortions are a long-standing problem that degrades the performance of supervisely trained speech processing models. It is high time that we enhance the robustness of speech processing models to obtain good performance when encountering speech distortions while not hurting the original performance on clean speech. In this work, we propose to improve the robustness of speech processing models by domain adversarial training (DAT). We conducted experiments based on the SUPERB framework on five different speech processing tasks. In case we do not always have knowledge of the distortion types for speech data, we analyzed the binary-domain and multi-domain settings, where the former treats all distorted speech as one domain, and the latter views different distortions as different domains. In contrast to supervised training methods, we obtained promising results in target domains where speech data is distorted with different distortions including new unseen distortions introduced during testing.
Low-data? No problem: low-resource, language-agnostic conversational text-to-speech via F0-conditioned data augmentation
Jul 29, 2022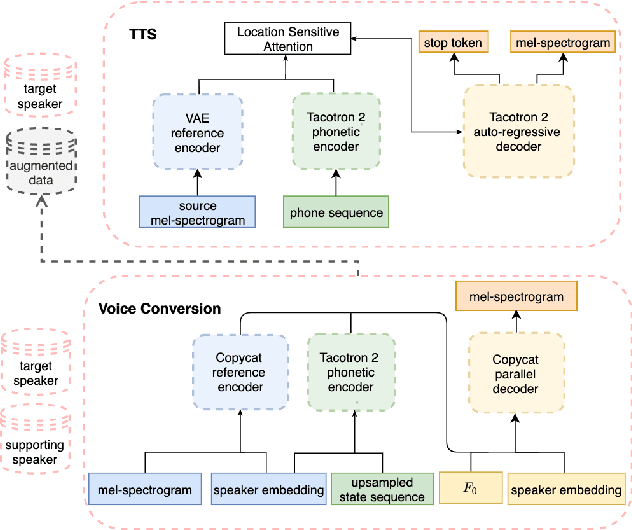

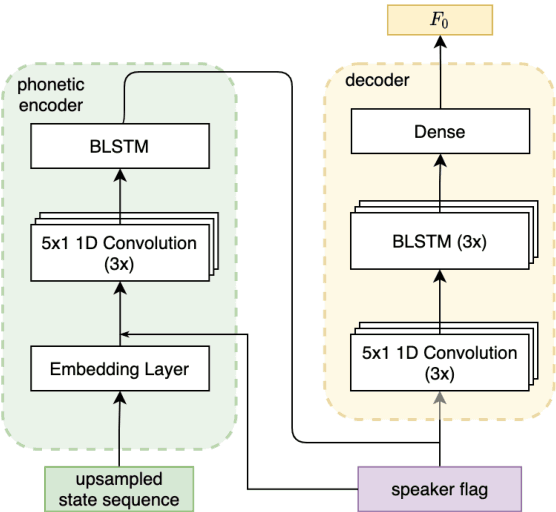
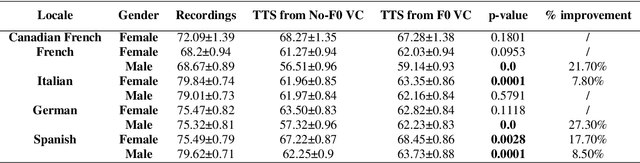
The availability of data in expressive styles across languages is limited, and recording sessions are costly and time consuming. To overcome these issues, we demonstrate how to build low-resource, neural text-to-speech (TTS) voices with only 1 hour of conversational speech, when no other conversational data are available in the same language. Assuming the availability of non-expressive speech data in that language, we propose a 3-step technology: 1) we train an F0-conditioned voice conversion (VC) model as data augmentation technique; 2) we train an F0 predictor to control the conversational flavour of the voice-converted synthetic data; 3) we train a TTS system that consumes the augmented data. We prove that our technology enables F0 controllability, is scalable across speakers and languages and is competitive in terms of naturalness over a state-of-the-art baseline model, another augmented method which does not make use of F0 information.
PoCaP Corpus: A Multimodal Dataset for Smart Operating Room Speech Assistant using Interventional Radiology Workflow Analysis
Jun 24, 2022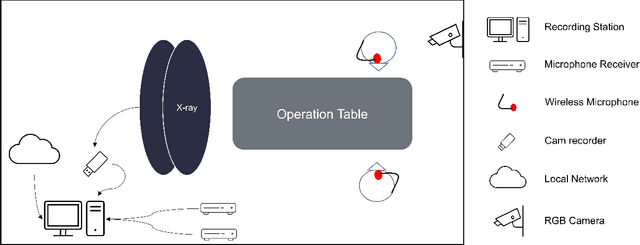
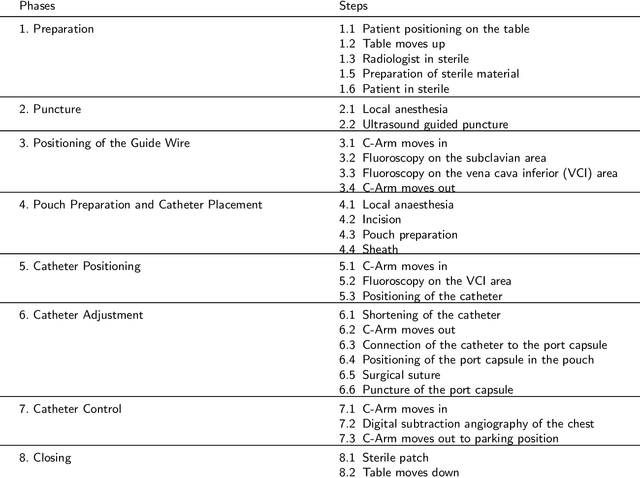
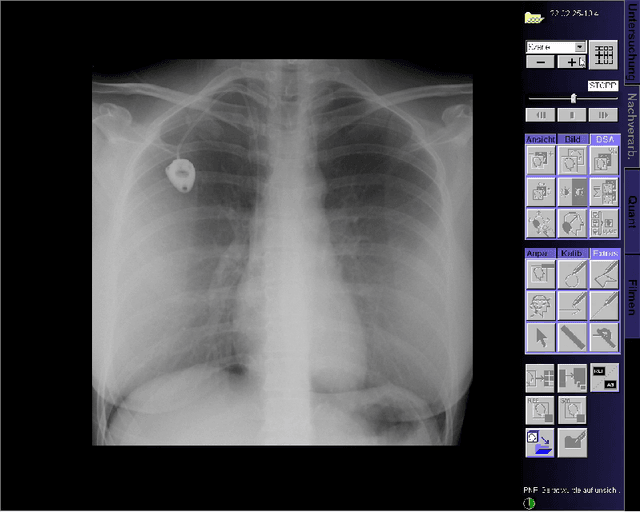

This paper presents a new multimodal interventional radiology dataset, called PoCaP (Port Catheter Placement) Corpus. This corpus consists of speech and audio signals in German, X-ray images, and system commands collected from 31 PoCaP interventions by six surgeons with average duration of 81.4 $\pm$ 41.0 minutes. The corpus aims to provide a resource for developing a smart speech assistant in operating rooms. In particular, it may be used to develop a speech controlled system that enables surgeons to control the operation parameters such as C-arm movements and table positions. In order to record the dataset, we acquired consent by the institutional review board and workers council in the University Hospital Erlangen and by the patients for data privacy. We describe the recording set-up, data structure, workflow and preprocessing steps, and report the first PoCaP Corpus speech recognition analysis results with 11.52 $\%$ word error rate using pretrained models. The findings suggest that the data has the potential to build a robust command recognition system and will allow the development of a novel intervention support systems using speech and image processing in the medical domain.
Four-in-One: A Joint Approach to Inverse Text Normalization, Punctuation, Capitalization, and Disfluency for Automatic Speech Recognition
Oct 26, 2022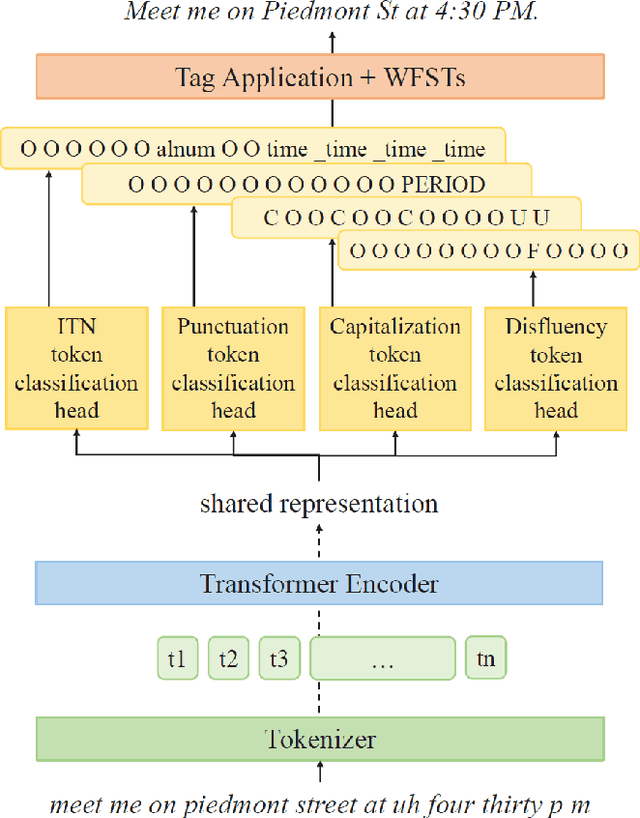
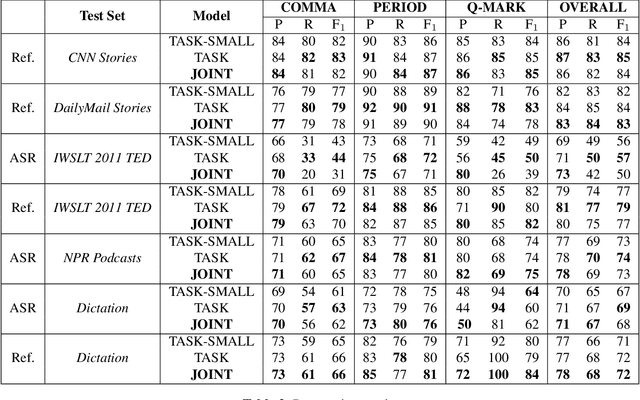
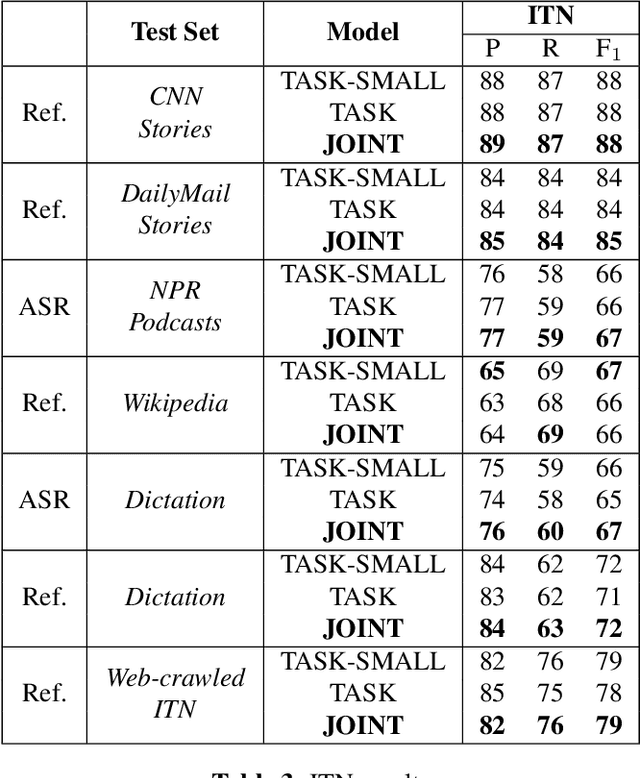
Features such as punctuation, capitalization, and formatting of entities are important for readability, understanding, and natural language processing tasks. However, Automatic Speech Recognition (ASR) systems produce spoken-form text devoid of formatting, and tagging approaches to formatting address just one or two features at a time. In this paper, we unify spoken-to-written text conversion via a two-stage process: First, we use a single transformer tagging model to jointly produce token-level tags for inverse text normalization (ITN), punctuation, capitalization, and disfluencies. Then, we apply the tags to generate written-form text and use weighted finite state transducer (WFST) grammars to format tagged ITN entity spans. Despite joining four models into one, our unified tagging approach matches or outperforms task-specific models across all four tasks on benchmark test sets across several domains.
Wavebender GAN: An architecture for phonetically meaningful speech manipulation
Feb 22, 2022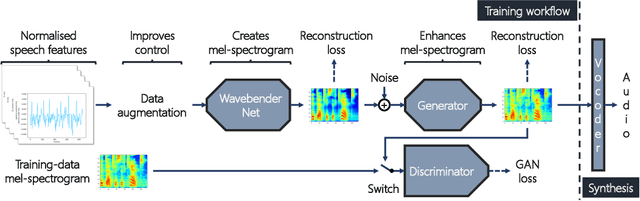
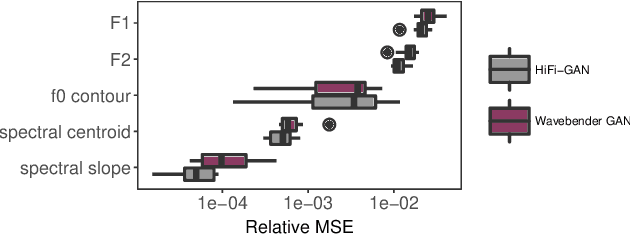
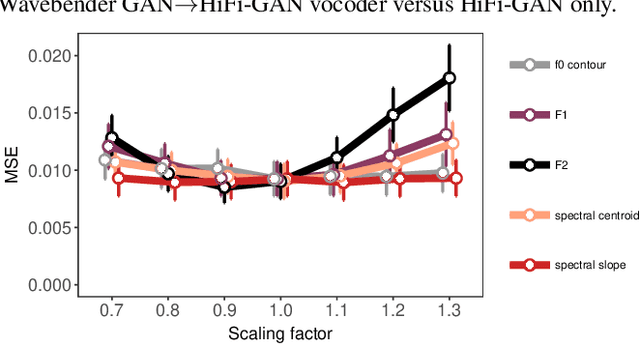
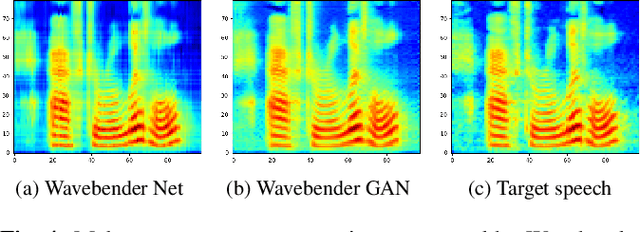
Deep learning has revolutionised synthetic speech quality. However, it has thus far delivered little value to the speech science community. The new methods do not meet the controllability demands that practitioners in this area require e.g.: in listening tests with manipulated speech stimuli. Instead, control of different speech properties in such stimuli is achieved by using legacy signal-processing methods. This limits the range, accuracy, and speech quality of the manipulations. Also, audible artefacts have a negative impact on the methodological validity of results in speech perception studies. This work introduces a system capable of manipulating speech properties through learning rather than design. The architecture learns to control arbitrary speech properties and leverages progress in neural vocoders to obtain realistic output. Experiments with copy synthesis and manipulation of a small set of core speech features (pitch, formants, and voice quality measures) illustrate the promise of the approach for producing speech stimuli that have accurate control and high perceptual quality.
On incorporating social speaker characteristics in synthetic speech
Apr 03, 2022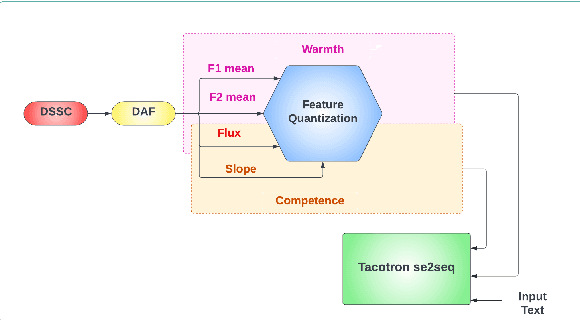
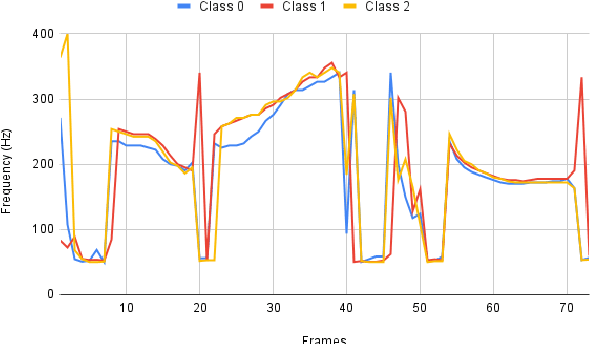
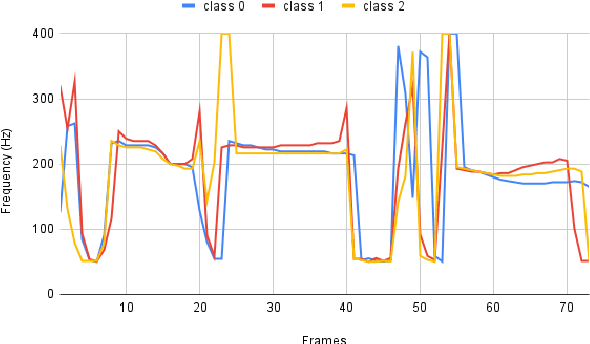
In our previous work, we derived the acoustic features, that contribute to the perception of warmth and competence in synthetic speech. As an extension, in our current work, we investigate the impact of the derived vocal features in the generation of the desired characteristics. The acoustic features, spectral flux, F1 mean and F2 mean and their convex combinations were explored for the generation of higher warmth in female speech. The voiced slope, spectral flux, and their convex combinations were investigated for the generation of higher competence in female speech. We have employed a feature quantization approach in the traditional end-to-end tacotron based speech synthesis model. The listening tests have shown that the convex combination of acoustic features displays higher Mean Opinion Scores of warmth and competence when compared to that of individual features.
iEmoTTS: Toward Robust Cross-Speaker Emotion Transfer and Control for Speech Synthesis based on Disentanglement between Prosody and Timbre
Jun 29, 2022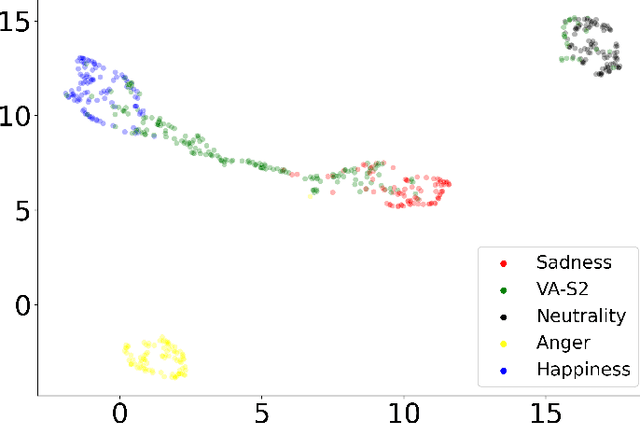
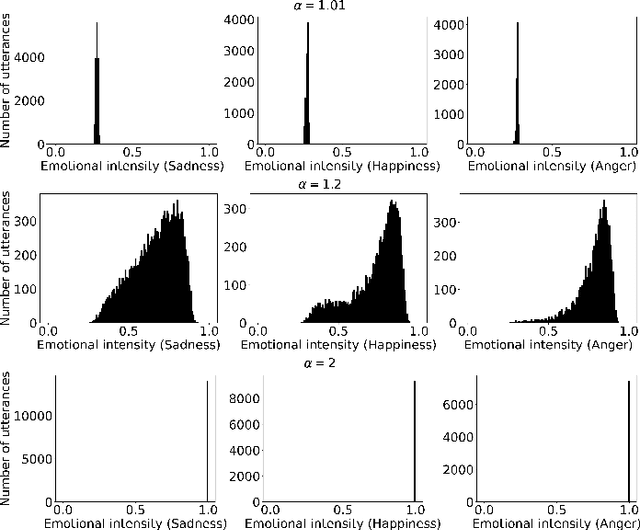
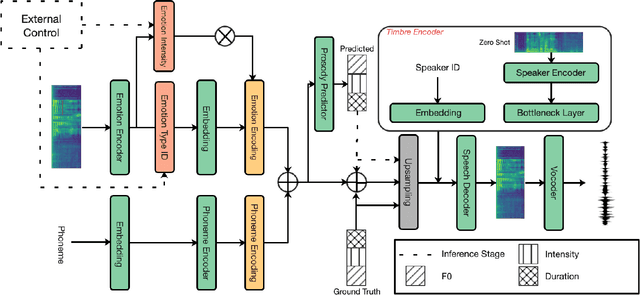
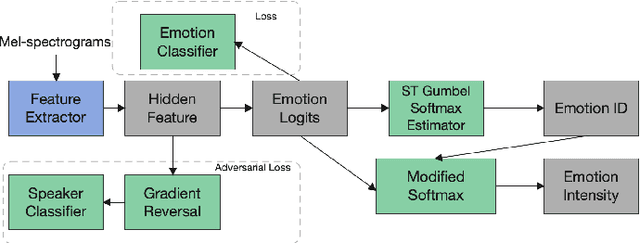
The capability of generating speech with specific type of emotion is desired for many applications of human-computer interaction. Cross-speaker emotion transfer is a common approach to generating emotional speech when speech with emotion labels from target speakers is not available for model training. This paper presents a novel cross-speaker emotion transfer system, named iEmoTTS. The system is composed of an emotion encoder, a prosody predictor, and a timbre encoder. The emotion encoder extracts the identity of emotion type as well as the respective emotion intensity from the mel-spectrogram of input speech. The emotion intensity is measured by the posterior probability that the input utterance carries that emotion. The prosody predictor is used to provide prosodic features for emotion transfer. The timber encoder provides timbre-related information for the system. Unlike many other studies which focus on disentangling speaker and style factors of speech, the iEmoTTS is designed to achieve cross-speaker emotion transfer via disentanglement between prosody and timbre. Prosody is considered as the main carrier of emotion-related speech characteristics and timbre accounts for the essential characteristics for speaker identification. Zero-shot emotion transfer, meaning that speech of target speakers are not seen in model training, is also realized with iEmoTTS. Extensive experiments of subjective evaluation have been carried out. The results demonstrate the effectiveness of iEmoTTS as compared with other recently proposed systems of cross-speaker emotion transfer. It is shown that iEmoTTS can produce speech with designated emotion type and controllable emotion intensity. With appropriate information bottleneck capacity, iEmoTTS is able to effectively transfer emotion information to a new speaker. Audio samples are publicly available\footnote{https://patrick-g-zhang.github.io/iemotts/}.