 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Wavebender GAN: An architecture for phonetically meaningful speech manipulation
Feb 22, 2022
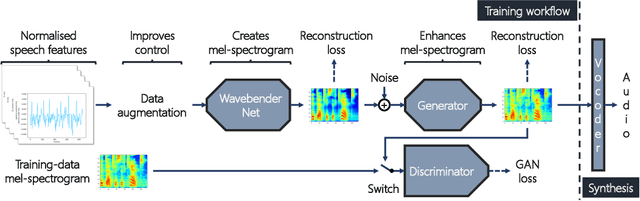
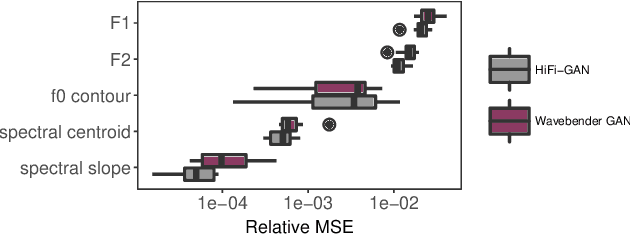
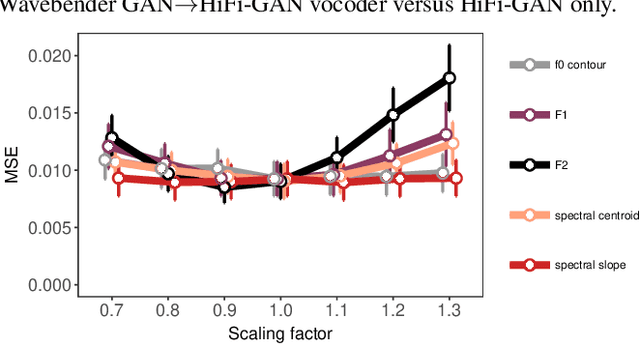
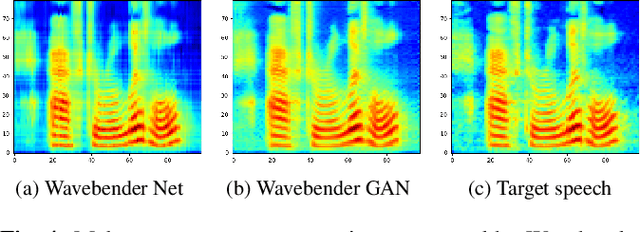
Deep learning has revolutionised synthetic speech quality. However, it has thus far delivered little value to the speech science community. The new methods do not meet the controllability demands that practitioners in this area require e.g.: in listening tests with manipulated speech stimuli. Instead, control of different speech properties in such stimuli is achieved by using legacy signal-processing methods. This limits the range, accuracy, and speech quality of the manipulations. Also, audible artefacts have a negative impact on the methodological validity of results in speech perception studies. This work introduces a system capable of manipulating speech properties through learning rather than design. The architecture learns to control arbitrary speech properties and leverages progress in neural vocoders to obtain realistic output. Experiments with copy synthesis and manipulation of a small set of core speech features (pitch, formants, and voice quality measures) illustrate the promise of the approach for producing speech stimuli that have accurate control and high perceptual quality.
A two-stage full-band speech enhancement model with effective spectral compression mapping
Jun 27, 2022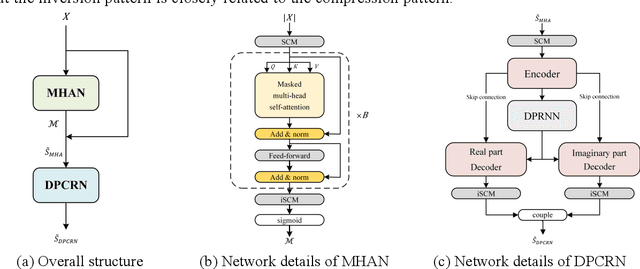
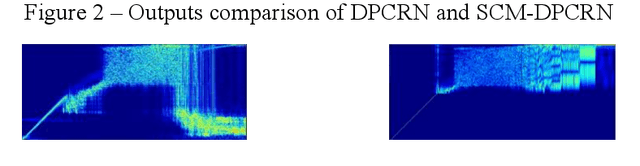
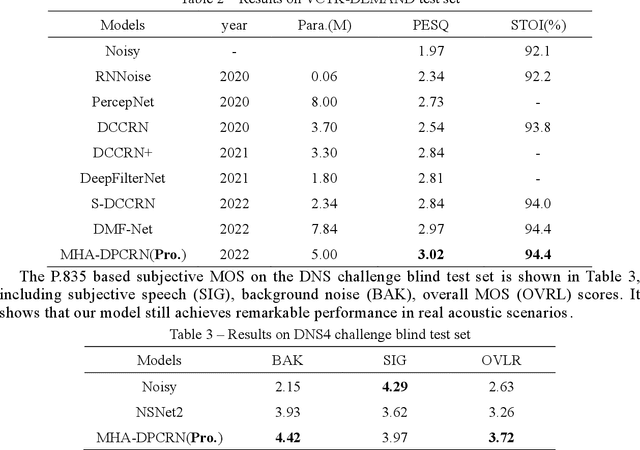

The direct expansion of deep neural network (DNN) based wide-band speech enhancement (SE) to full-band processing faces the challenge of low frequency resolution in low frequency range, which would highly likely lead to deteriorated performance of the model. In this paper, we propose a learnable spectral compression mapping (SCM) to effectively compress the high frequency components so that they can be processed in a more efficient manner. By doing so, the model can pay more attention to low and middle frequency range, where most of the speech power is concentrated. Instead of suppressing noise in a single network structure, we first estimate a spectral magnitude mask, converting the speech to a high signal-to-ratio (SNR) state, and then utilize a subsequent model to further optimize the real and imaginary mask of the pre-enhanced signal. We conduct comprehensive experiments to validate the efficacy of the proposed method.
Topic Modeling Based on Two-Step Flow Theory: Application to Tweets about Bitcoin
Mar 03, 2023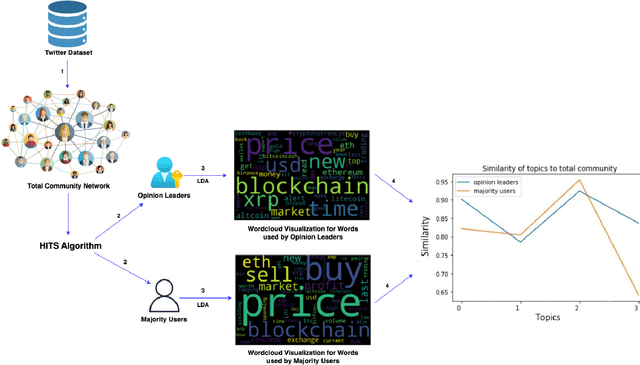
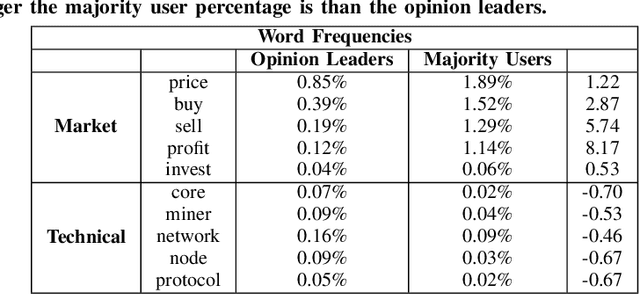
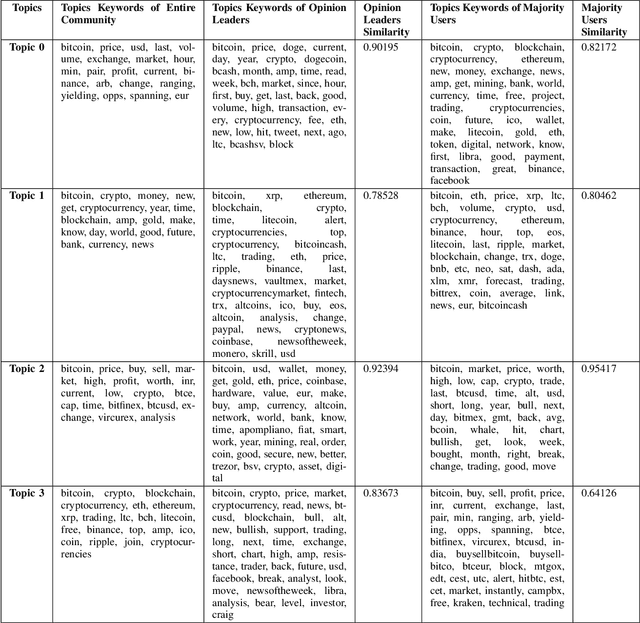
Digital cryptocurrencies such as Bitcoin have exploded in recent years in both popularity and value. By their novelty, cryptocurrencies tend to be both volatile and highly speculative. The capricious nature of these coins is helped facilitated by social media networks such as Twitter. However, not everyone's opinion matters equally, with most posts garnering little to no attention. Additionally, the majority of tweets are retweeted from popular posts. We must determine whose opinion matters and the difference between influential and non-influential users. This study separates these two groups and analyzes the differences between them. It uses Hypertext-induced Topic Selection (HITS) algorithm, which segregates the dataset based on influence. Topic modeling is then employed to uncover differences in each group's speech types and what group may best represent the entire community. We found differences in language and interest between these two groups regarding Bitcoin and that the opinion leaders of Twitter are not aligned with the majority of users. There were 2559 opinion leaders (0.72% of users) who accounted for 80% of the authority and the majority (99.28%) users for the remaining 20% out of a total of 355,139 users.
Tiny-Sepformer: A Tiny Time-Domain Transformer Network for Speech Separation
Jun 30, 2022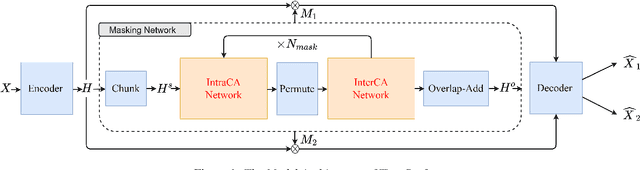

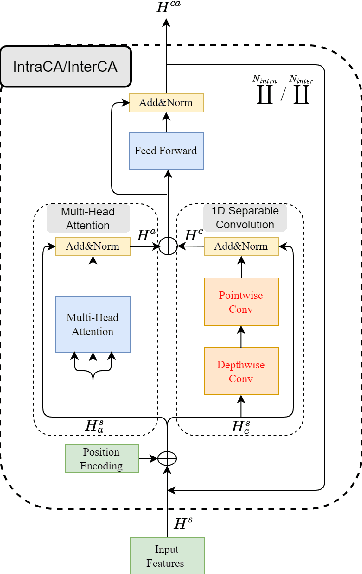
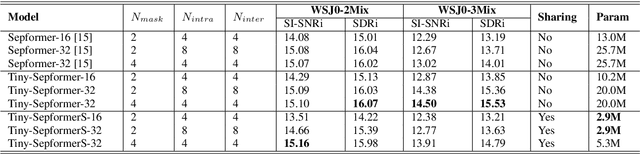
Time-domain Transformer neural networks have proven their superiority in speech separation tasks. However, these models usually have a large number of network parameters, thus often encountering the problem of GPU memory explosion. In this paper, we proposed Tiny-Sepformer, a tiny version of Transformer network for speech separation. We present two techniques to reduce the model parameters and memory consumption: (1) Convolution-Attention (CA) block, spliting the vanilla Transformer to two paths, multi-head attention and 1D depthwise separable convolution, (2) parameter sharing, sharing the layer parameters within the CA block. In our experiments, Tiny-Sepformer could greatly reduce the model size, and achieves comparable separation performance with vanilla Sepformer on WSJ0-2/3Mix datasets.
Explainable Human-centered Traits from Head Motion and Facial Expression Dynamics
Feb 23, 2023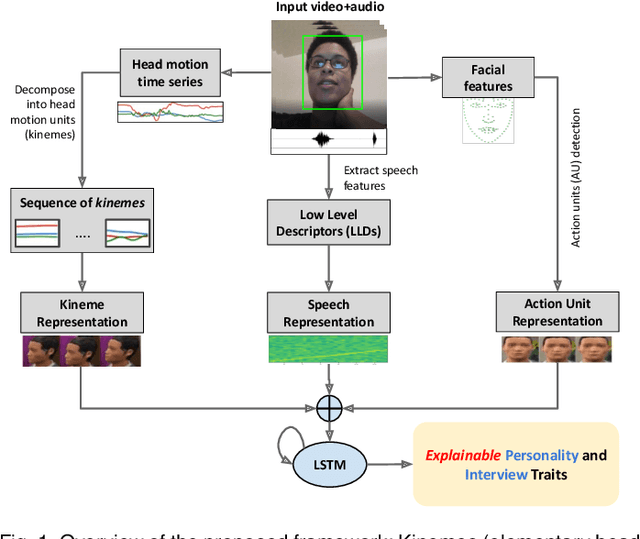
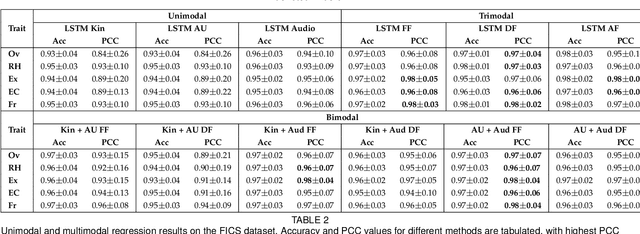
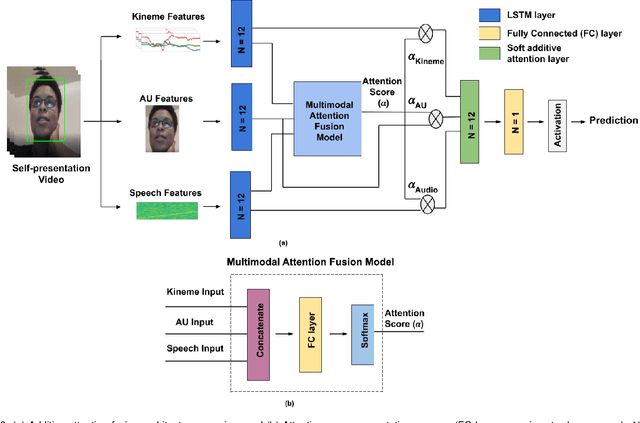
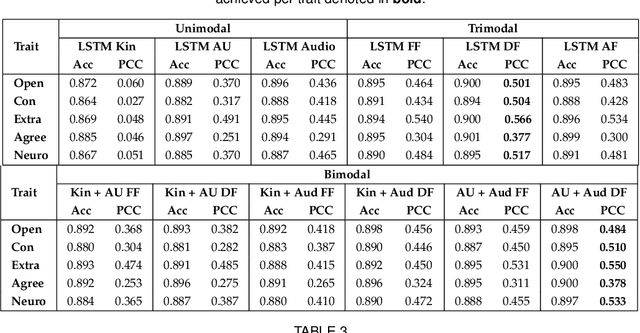
We explore the efficacy of multimodal behavioral cues for explainable prediction of personality and interview-specific traits. We utilize elementary head-motion units named kinemes, atomic facial movements termed action units and speech features to estimate these human-centered traits. Empirical results confirm that kinemes and action units enable discovery of multiple trait-specific behaviors while also enabling explainability in support of the predictions. For fusing cues, we explore decision and feature-level fusion, and an additive attention-based fusion strategy which quantifies the relative importance of the three modalities for trait prediction. Examining various long-short term memory (LSTM) architectures for classification and regression on the MIT Interview and First Impressions Candidate Screening (FICS) datasets, we note that: (1) Multimodal approaches outperform unimodal counterparts; (2) Efficient trait predictions and plausible explanations are achieved with both unimodal and multimodal approaches, and (3) Following the thin-slice approach, effective trait prediction is achieved even from two-second behavioral snippets.
Generalization of Auto-Regressive Hidden Markov Models to Non-Linear Dynamics and Non-Euclidean Observation Space
Feb 23, 2023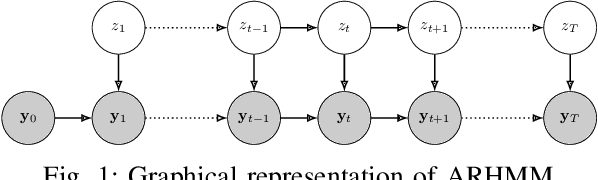
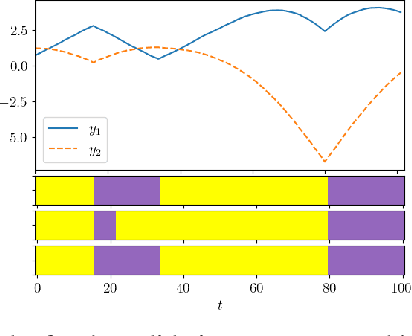
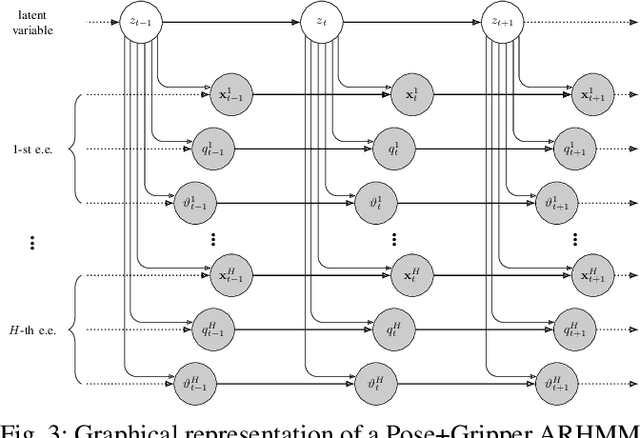
Latent variable models are widely used to perform unsupervised segmentation of time series in different context such as robotics, speech recognition, and economics. One of the most widely used latent variable model is the Auto-Regressive Hidden Markov Model (ARHMM), which combines a latent mode governed by a Markov chain dynamics with a linear Auto-Regressive dynamics of the observed state. In this work, we propose two generalizations of the ARHMM. First, we propose a more general AR dynamics in Cartesian space, described as a linear combination of non-linear basis functions. Second, we propose a linear dynamics in unit quaternion space, in order to properly describe orientations. These extensions allow to describe more complex dynamics of the observed state. Although this extension is proposed for the ARHMM, it can be easily extended to other latent variable models with AR dynamics in the observed space, such as Auto-Regressive Hidden semi-Markov Models.
Incorporating Uncertainty from Speaker Embedding Estimation to Speaker Verification
Feb 23, 2023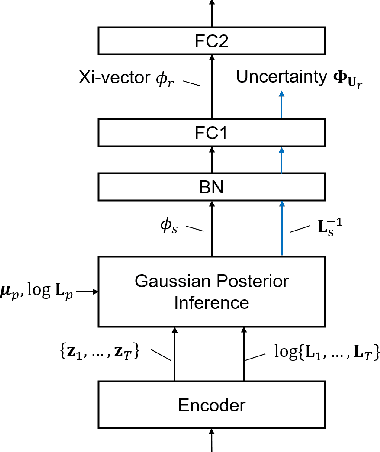

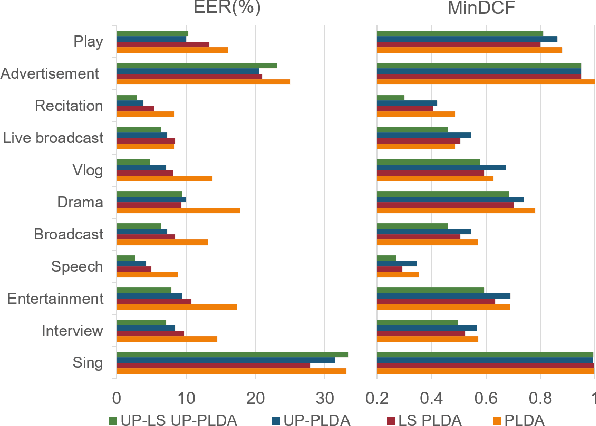
Speech utterances recorded under differing conditions exhibit varying degrees of confidence in their embedding estimates, i.e., uncertainty, even if they are extracted using the same neural network. This paper aims to incorporate the uncertainty estimate produced in the xi-vector network front-end with a probabilistic linear discriminant analysis (PLDA) back-end scoring for speaker verification. To achieve this we derive a posterior covariance matrix, which measures the uncertainty, from the frame-wise precisions to the embedding space. We propose a log-likelihood ratio function for the PLDA scoring with the uncertainty propagation. We also propose to replace the length normalization pre-processing technique with a length scaling technique for the application of uncertainty propagation in the back-end. Experimental results on the VoxCeleb-1, SITW test sets as well as a domain-mismatched CNCeleb1-E set show the effectiveness of the proposed techniques with 14.5%-41.3% EER reductions and 4.6%-25.3% minDCF reductions.
Multilingual Transformer Language Model for Speech Recognition in Low-resource Languages
Sep 08, 2022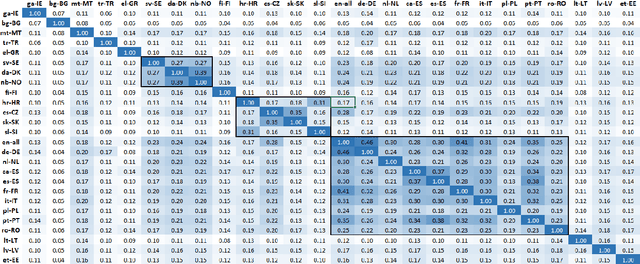

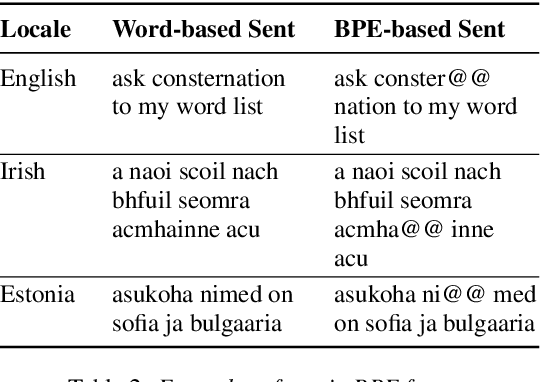
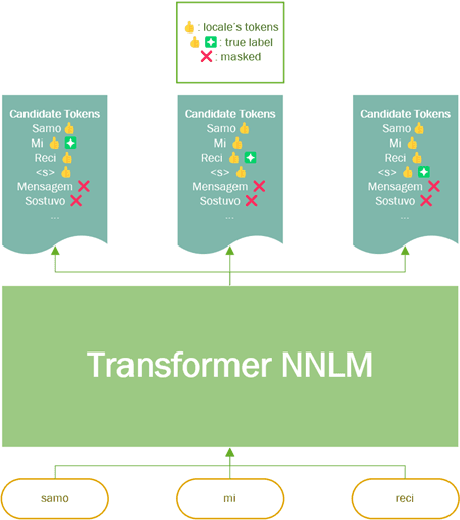
It is challenging to train and deploy Transformer LMs for hybrid speech recognition 2nd pass re-ranking in low-resource languages due to (1) data scarcity in low-resource languages, (2) expensive computing costs for training and refreshing 100+ monolingual models, and (3) hosting inefficiency considering sparse traffic. In this study, we present a new way to group multiple low-resource locales together and optimize the performance of Multilingual Transformer LMs in ASR. Our Locale-group Multilingual Transformer LMs outperform traditional multilingual LMs along with reducing maintenance costs and operating expenses. Further, for low-resource but high-traffic locales where deploying monolingual models is feasible, we show that fine-tuning our locale-group multilingual LMs produces better monolingual LM candidates than baseline monolingual LMs.
Lip to Speech Synthesis with Visual Context Attentional GAN
Apr 04, 2022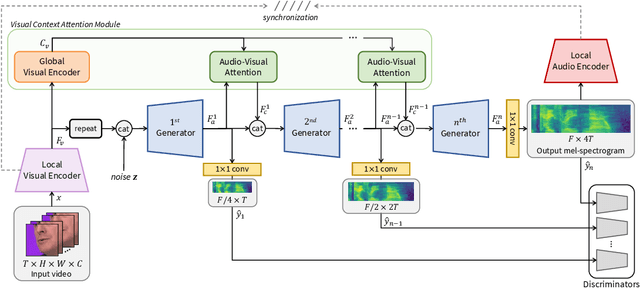

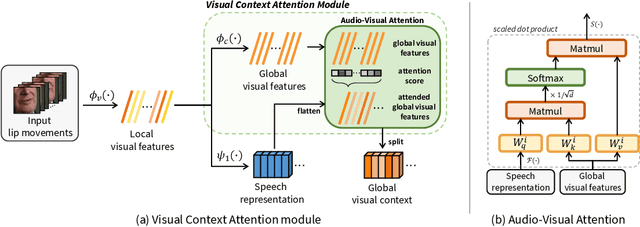
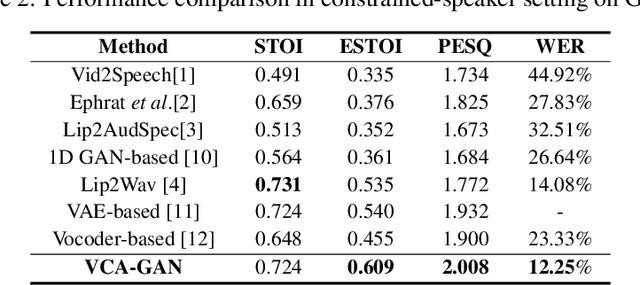
In this paper, we propose a novel lip-to-speech generative adversarial network, Visual Context Attentional GAN (VCA-GAN), which can jointly model local and global lip movements during speech synthesis. Specifically, the proposed VCA-GAN synthesizes the speech from local lip visual features by finding a mapping function of viseme-to-phoneme, while global visual context is embedded into the intermediate layers of the generator to clarify the ambiguity in the mapping induced by homophene. To achieve this, a visual context attention module is proposed where it encodes global representations from the local visual features, and provides the desired global visual context corresponding to the given coarse speech representation to the generator through audio-visual attention. In addition to the explicit modelling of local and global visual representations, synchronization learning is introduced as a form of contrastive learning that guides the generator to synthesize a speech in sync with the given input lip movements. Extensive experiments demonstrate that the proposed VCA-GAN outperforms existing state-of-the-art and is able to effectively synthesize the speech from multi-speaker that has been barely handled in the previous works.
Sentiment-Aware Automatic Speech Recognition pre-training for enhanced Speech Emotion Recognition
Jan 27, 2022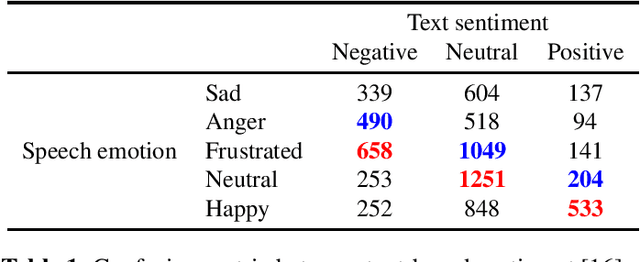
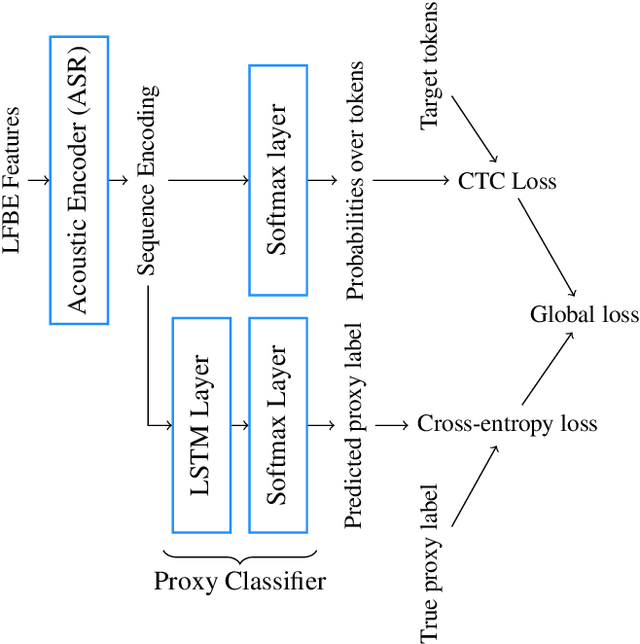
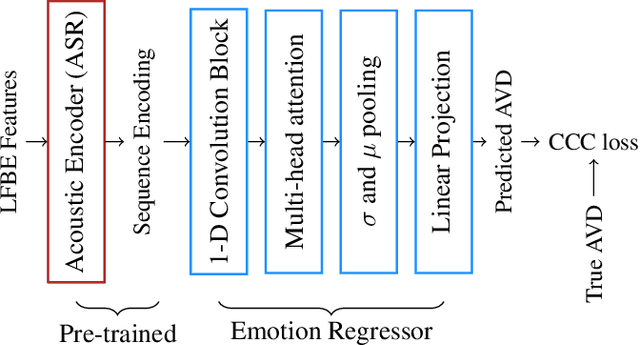
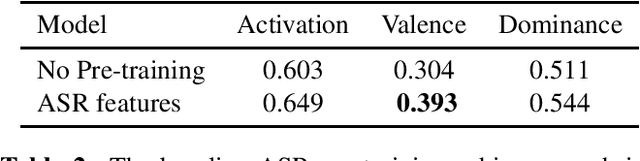
We propose a novel multi-task pre-training method for Speech Emotion Recognition (SER). We pre-train SER model simultaneously on Automatic Speech Recognition (ASR) and sentiment classification tasks to make the acoustic ASR model more ``emotion aware''. We generate targets for the sentiment classification using text-to-sentiment model trained on publicly available data. Finally, we fine-tune the acoustic ASR on emotion annotated speech data. We evaluated the proposed approach on the MSP-Podcast dataset, where we achieved the best reported concordance correlation coefficient (CCC) of 0.41 for valence prediction.