 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
DP-Parse: Finding Word Boundaries from Raw Speech with an Instance Lexicon
Jun 22, 2022
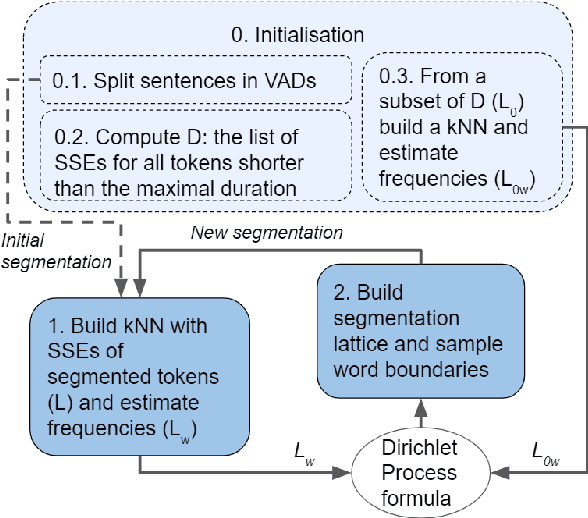

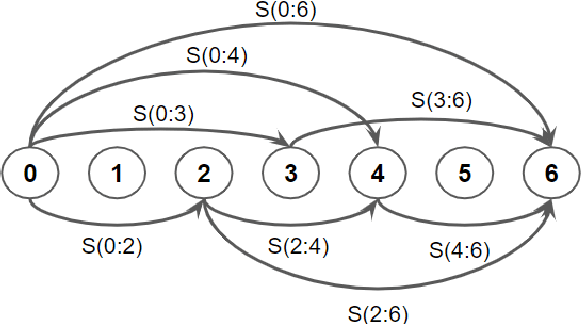

Finding word boundaries in continuous speech is challenging as there is little or no equivalent of a 'space' delimiter between words. Popular Bayesian non-parametric models for text segmentation use a Dirichlet process to jointly segment sentences and build a lexicon of word types. We introduce DP-Parse, which uses similar principles but only relies on an instance lexicon of word tokens, avoiding the clustering errors that arise with a lexicon of word types. On the Zero Resource Speech Benchmark 2017, our model sets a new speech segmentation state-of-the-art in 5 languages. The algorithm monotonically improves with better input representations, achieving yet higher scores when fed with weakly supervised inputs. Despite lacking a type lexicon, DP-Parse can be pipelined to a language model and learn semantic and syntactic representations as assessed by a new spoken word embedding benchmark.
An Empirical Study on L2 Accents of Cross-lingual Text-to-Speech Systems via Vowel Space
Nov 06, 2022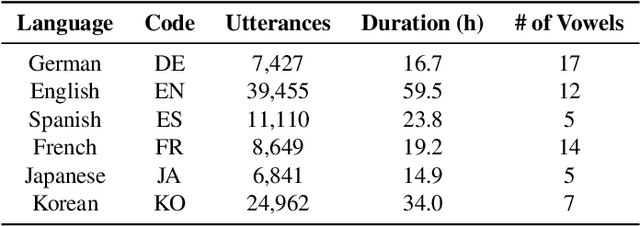
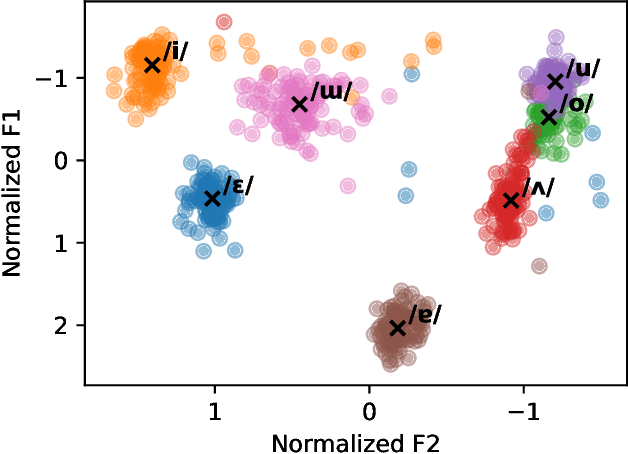
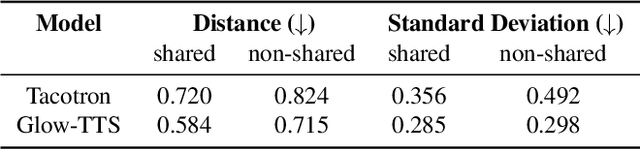
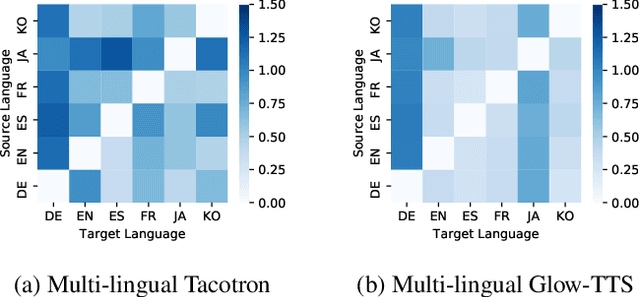
With the recent developments in cross-lingual Text-to-Speech (TTS) systems, L2 (second-language, or foreign) accent problems arise. Moreover, running a subjective evaluation for such cross-lingual TTS systems is troublesome. The vowel space analysis, which is often utilized to explore various aspects of language including L2 accents, is a great alternative analysis tool. In this study, we apply the vowel space analysis method to explore L2 accents of cross-lingual TTS systems. Through the vowel space analysis, we observe the three followings: a) a parallel architecture (Glow-TTS) is less L2-accented than an auto-regressive one (Tacotron); b) L2 accents are more dominant in non-shared vowels in a language pair; and c) L2 accents of cross-lingual TTS systems share some phenomena with those of human L2 learners. Our findings imply that it is necessary for TTS systems to handle each language pair differently, depending on their linguistic characteristics such as non-shared vowels. They also hint that we can further incorporate linguistics knowledge in developing cross-lingual TTS systems.
Variable-rate hierarchical CPC leads to acoustic unit discovery in speech
Jun 07, 2022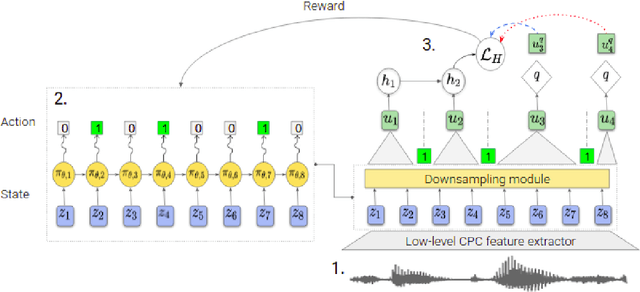
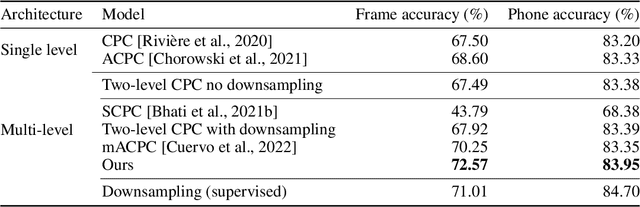

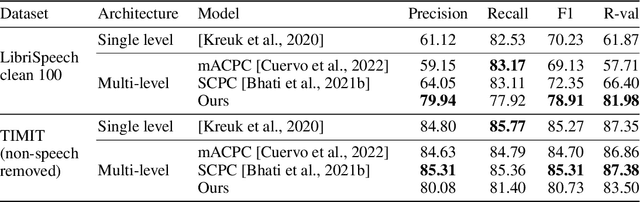
The success of deep learning comes from its ability to capture the hierarchical structure of data by learning high-level representations defined in terms of low-level ones. In this paper we explore self-supervised learning of hierarchical representations of speech by applying multiple levels of Contrastive Predictive Coding (CPC). We observe that simply stacking two CPC models does not yield significant improvements over single-level architectures. Inspired by the fact that speech is often described as a sequence of discrete units unevenly distributed in time, we propose a model in which the output of a low-level CPC module is non-uniformly downsampled to directly minimize the loss of a high-level CPC module. The latter is designed to also enforce a prior of separability and discreteness in its representations by enforcing dissimilarity of successive high-level representations through focused negative sampling, and by quantization of the prediction targets. Accounting for the structure of the speech signal improves upon single-level CPC features and enhances the disentanglement of the learned representations, as measured by downstream speech recognition tasks, while resulting in a meaningful segmentation of the signal that closely resembles phone boundaries.
BERT Meets CTC: New Formulation of End-to-End Speech Recognition with Pre-trained Masked Language Model
Oct 29, 2022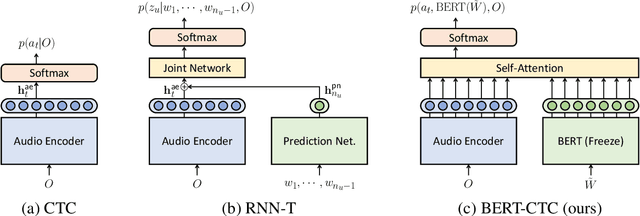
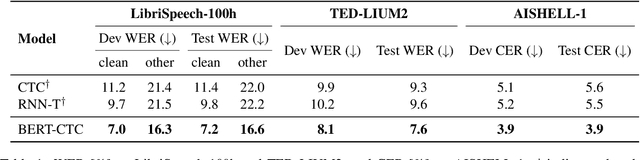
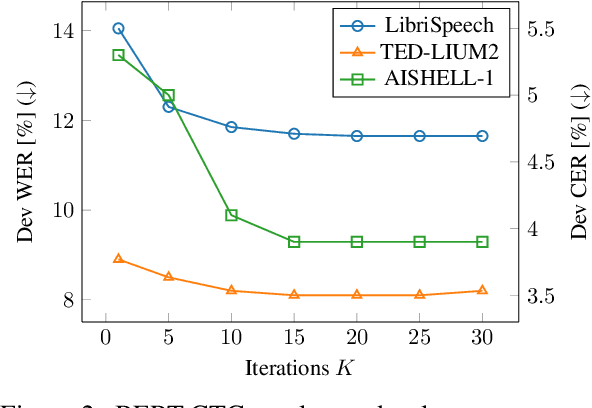

This paper presents BERT-CTC, a novel formulation of end-to-end speech recognition that adapts BERT for connectionist temporal classification (CTC). Our formulation relaxes the conditional independence assumptions used in conventional CTC and incorporates linguistic knowledge through the explicit output dependency obtained by BERT contextual embedding. BERT-CTC attends to the full contexts of the input and hypothesized output sequences via the self-attention mechanism. This mechanism encourages a model to learn inner/inter-dependencies between the audio and token representations while maintaining CTC's training efficiency. During inference, BERT-CTC combines a mask-predict algorithm with CTC decoding, which iteratively refines an output sequence. The experimental results reveal that BERT-CTC improves over conventional approaches across variations in speaking styles and languages. Finally, we show that the semantic representations in BERT-CTC are beneficial towards downstream spoken language understanding tasks.
Text-to-ECG: 12-Lead Electrocardiogram Synthesis conditioned on Clinical Text Reports
Mar 09, 2023

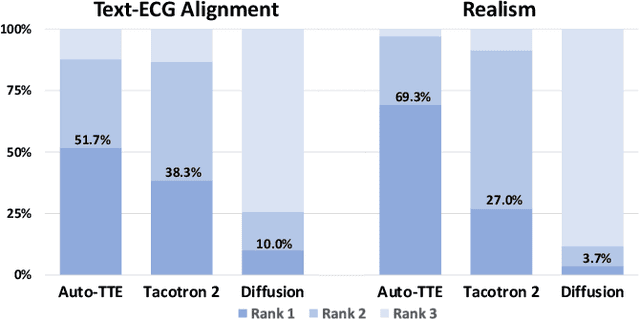
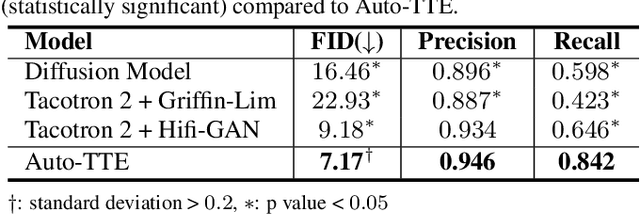
Electrocardiogram (ECG) synthesis is the area of research focused on generating realistic synthetic ECG signals for medical use without concerns over annotation costs or clinical data privacy restrictions. Traditional ECG generation models consider a single ECG lead and utilize GAN-based generative models. These models can only generate single lead samples and require separate training for each diagnosis class. The diagnosis classes of ECGs are insufficient to capture the intricate differences between ECGs depending on various features (e.g. patient demographic details, co-existing diagnosis classes, etc.). To alleviate these challenges, we present a text-to-ECG task, in which textual inputs are used to produce ECG outputs. Then we propose Auto-TTE, an autoregressive generative model conditioned on clinical text reports to synthesize 12-lead ECGs, for the first time to our knowledge. We compare the performance of our model with other representative models in text-to-speech and text-to-image. Experimental results show the superiority of our model in various quantitative evaluations and qualitative analysis. Finally, we conduct a user study with three board-certified cardiologists to confirm the fidelity and semantic alignment of generated samples. our code will be available at https://github.com/TClife/text_to_ecg
Modeling speech recognition and synthesis simultaneously: Encoding and decoding lexical and sublexical semantic information into speech with no direct access to speech data
Mar 29, 2022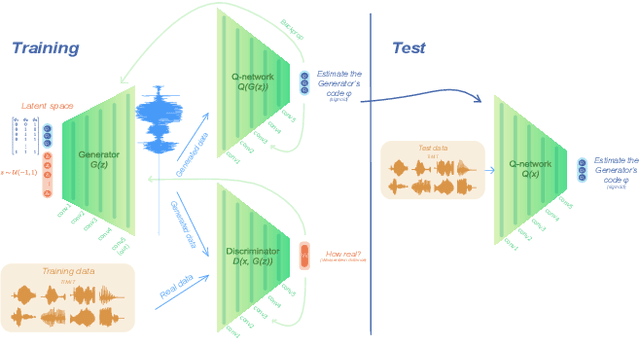
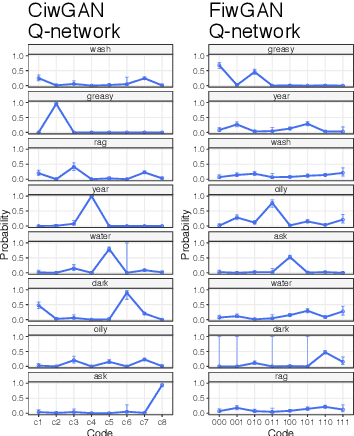
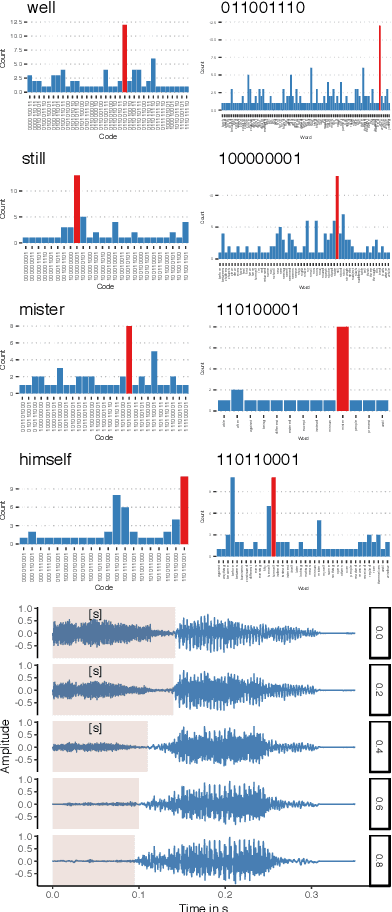
Human speakers encode information into raw speech which is then decoded by the listeners. This complex relationship between encoding (production) and decoding (perception) is often modeled separately. Here, we test how encoding and decoding of lexical semantic information can emerge automatically from raw speech in unsupervised generative deep convolutional networks that combine the production and perception principles of speech. We introduce, to our knowledge, the most challenging objective in unsupervised lexical learning: a network that must learn unique representations for lexical items with no direct access to training data. We train several models (ciwGAN and fiwGAN arXiv:2006.02951) and test how the networks classify acoustic lexical items in unobserved test data. Strong evidence in favor of lexical learning and a causal relationship between latent codes and meaningful sublexical units emerge. The architecture that combines the production and perception principles is thus able to learn to decode unique information from raw acoustic data without accessing real training data directly. We propose a technique to explore lexical (holistic) and sublexical (featural) learned representations in the classifier network. The results bear implications for unsupervised speech technology, as well as for unsupervised semantic modeling as language models increasingly bypass text and operate from raw acoustics.
Improving the transferability of speech separation by meta-learning
Mar 11, 2022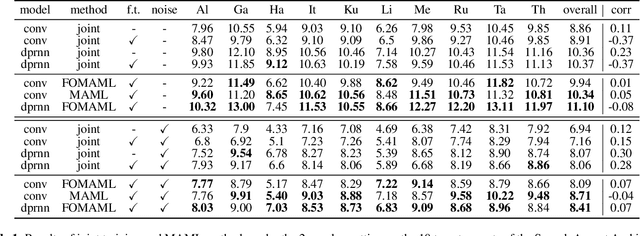
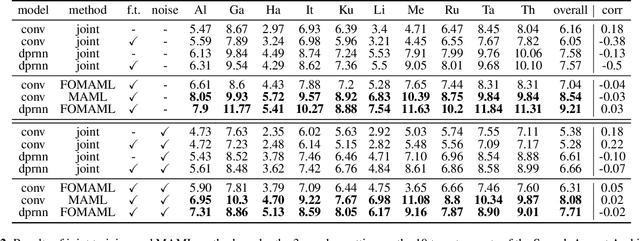
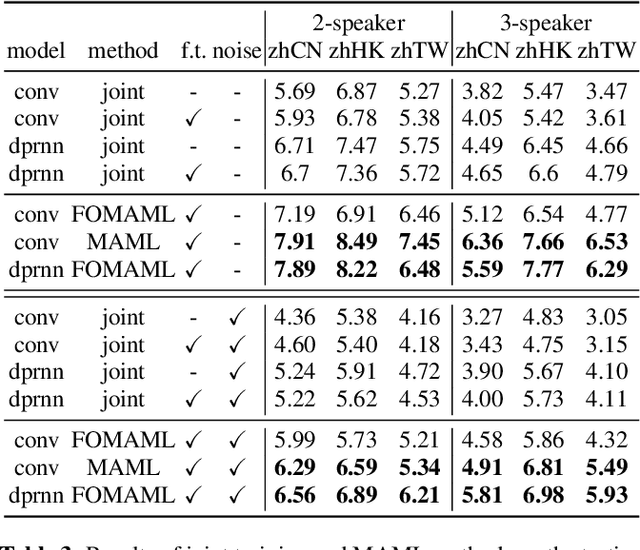
Speech separation aims to separate multiple speech sources from a speech mixture. Although speech separation is well-solved on some existing English speech separation benchmarks, it is worthy of more investigation on the generalizability of speech separation models on the accents or languages unseen during training. This paper adopts meta-learning based methods to improve the transferability of speech separation models. With the meta-learning based methods, we discovered that only using speech data with one accent, the native English accent, as our training data, the models still can be adapted to new unseen accents on the Speech Accent Archive. We compared the results with a human-rated native-likeness of accents, showing that the transferability of MAML methods has less relation to the similarity of data between the training and testing phase compared to the typical transfer learning methods. Furthermore, we found that models can deal with different language data from the CommonVoice corpus during the testing phase. Most of all, the MAML methods outperform typical transfer learning methods when it comes to new accents, new speakers, new languages, and noisy environments.
Towards domain generalisation in ASR with elitist sampling and ensemble knowledge distillation
Mar 01, 2023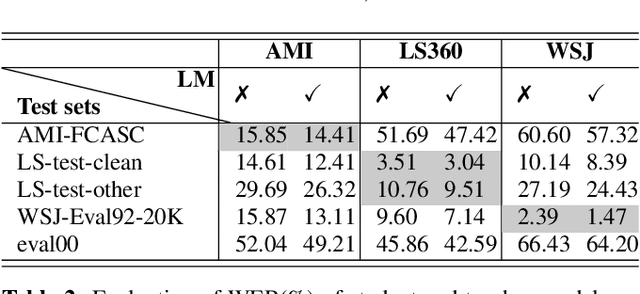
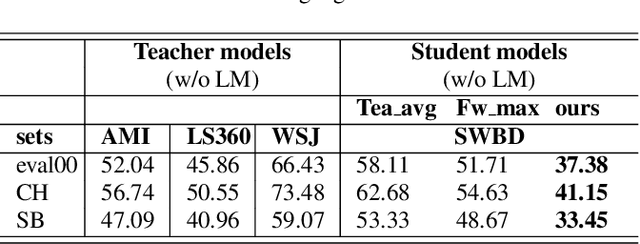
Knowledge distillation has widely been used for model compression and domain adaptation for speech applications. In the presence of multiple teachers, knowledge can easily be transferred to the student by averaging the models output. However, previous research shows that the student do not adapt well with such combination. This paper propose to use an elitist sampling strategy at the output of ensemble teacher models to select the best-decoded utterance generated by completely out-of-domain teacher models for generalizing unseen domain. The teacher models are trained on AMI, LibriSpeech and WSJ while the student is adapted for the Switchboard data. The results show that with the selection strategy based on the individual models posteriors the student model achieves a better WER compared to all the teachers and baselines with a minimum absolute improvement of about 8.4 percent. Furthermore, an insights on the model adaptation with out-of-domain data has also been studied via correlation analysis.
Building High-accuracy Multilingual ASR with Gated Language Experts and Curriculum Training
Mar 01, 2023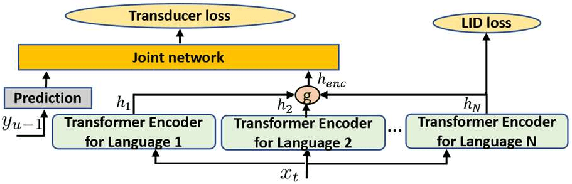
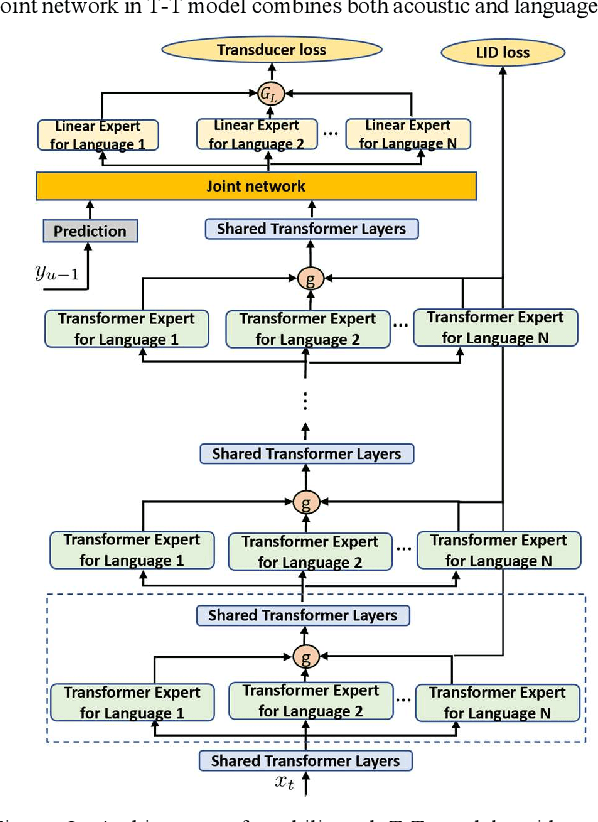
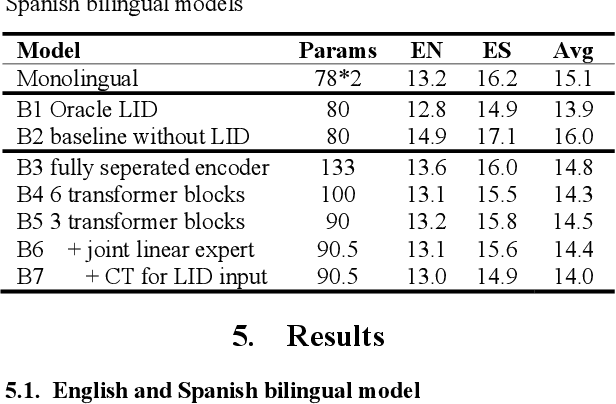
We propose gated language experts to improve multilingual transformer transducer models without any language identification (LID) input from users during inference. We define gating mechanism and LID loss to let transformer encoders learn language-dependent information, construct the multilingual transformer block with gated transformer experts and shared transformer layers for compact models, and apply linear experts on joint network output to better regularize speech acoustic and token label joint information. Furthermore, a curriculum training scheme is proposed to let LID guide the gated language experts for better serving their corresponding languages. Evaluated on the English and Spanish bilingual task, our methods achieve average 12.5% and 7.3% relative word error reductions over the baseline bilingual model and monolingual models, respectively, obtaining similar results to the upper bound model trained and inferred with oracle LID. We further explore our method on trilingual, quadrilingual, and pentalingual models, and observe similar advantages as in the bilingual models, which demonstrates the easy extension to more languages.
Hey Dona! Can you help me with student course registration?
Mar 21, 2023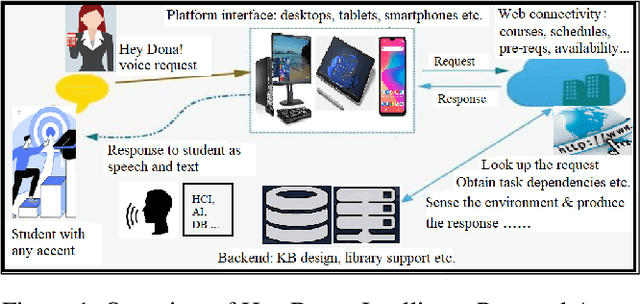
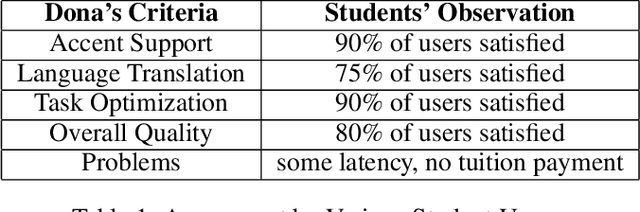
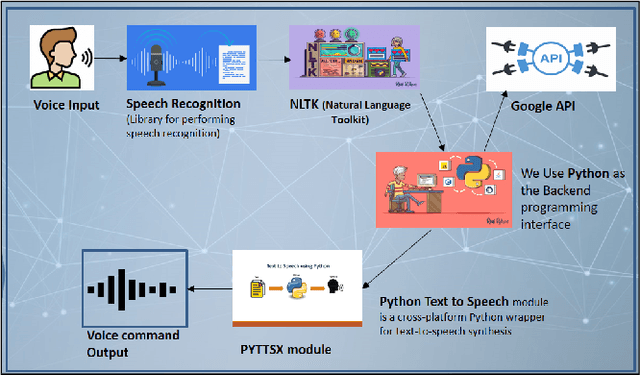
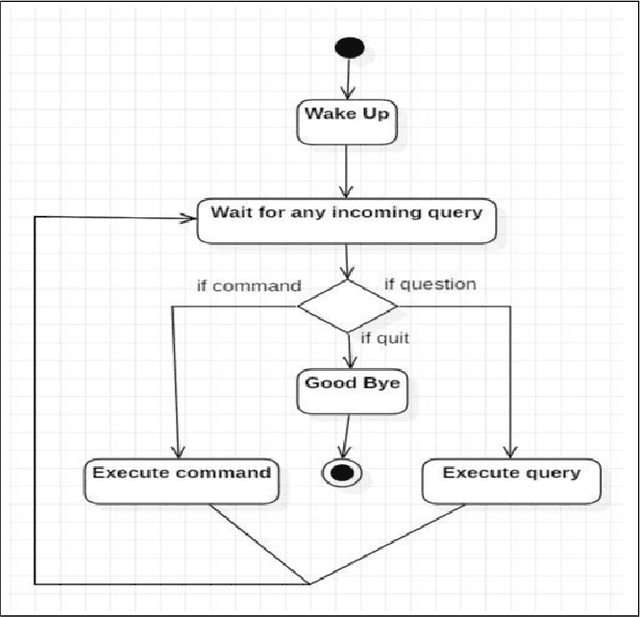
In this paper, we present a demo of an intelligent personal agent called Hey Dona (or just Dona) with virtual voice assistance in student course registration. It is a deployed project in the theme of AI for education. In this digital age with a myriad of smart devices, users often delegate tasks to agents. While pointing and clicking supersedes the erstwhile command-typing, modern devices allow users to speak commands for agents to execute tasks, enhancing speed and convenience. In line with this progress, Dona is an intelligent agent catering to student needs by automated, voice-operated course registration, spanning a multitude of accents, entailing task planning optimization, with some language translation as needed. Dona accepts voice input by microphone (Bluetooth, wired microphone), converts human voice to computer understandable language, performs query processing as per user commands, connects with the Web to search for answers, models task dependencies, imbibes quality control, and conveys output by speaking to users as well as displaying text, thus enabling human-AI interaction by speech cum text. It is meant to work seamlessly on desktops, smartphones etc. and in indoor as well as outdoor settings. To the best of our knowledge, Dona is among the first of its kind as an intelligent personal agent for voice assistance in student course registration. Due to its ubiquitous access for educational needs, Dona directly impacts AI for education. It makes a broader impact on smart city characteristics of smart living and smart people due to its contributions to providing benefits for new ways of living and assisting 21st century education, respectively.