 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Audio-visual video face hallucination with frequency supervision and cross modality support by speech based lip reading loss
Nov 20, 2022
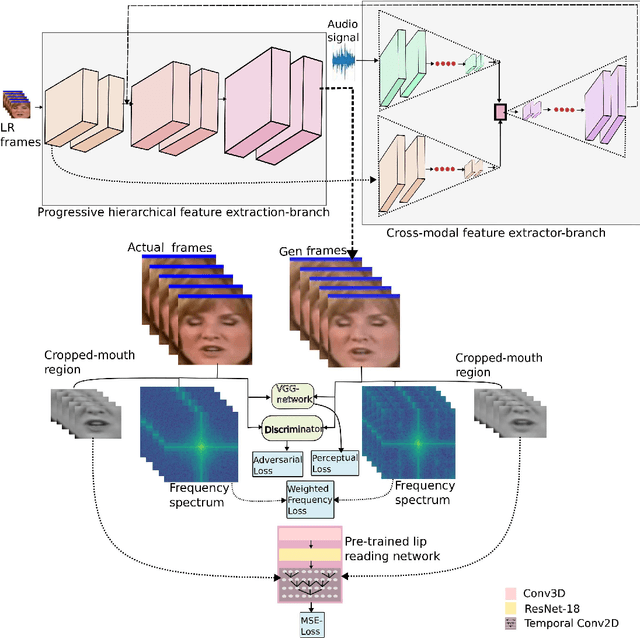
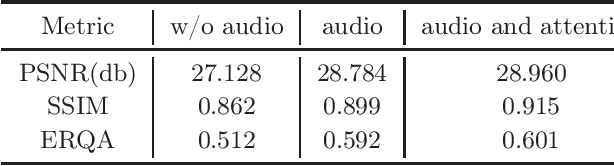

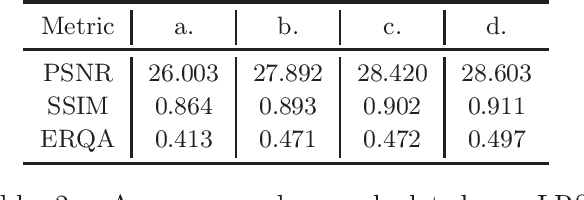
Recently, there has been numerous breakthroughs in face hallucination tasks. However, the task remains rather challenging in videos in comparison to the images due to inherent consistency issues. The presence of extra temporal dimension in video face hallucination makes it non-trivial to learn the facial motion through out the sequence. In order to learn these fine spatio-temporal motion details, we propose a novel cross-modal audio-visual Video Face Hallucination Generative Adversarial Network (VFH-GAN). The architecture exploits the semantic correlation of between the movement of the facial structure and the associated speech signal. Another major issue in present video based approaches is the presence of blurriness around the key facial regions such as mouth and lips - where spatial displacement is much higher in comparison to other areas. The proposed approach explicitly defines a lip reading loss to learn the fine grain motion in these facial areas. During training, GANs have potential to fit frequencies from low to high, which leads to miss the hard to synthesize frequencies. Therefore, to add salient frequency features to the network we add a frequency based loss function. The visual and the quantitative comparison with state-of-the-art shows a significant improvement in performance and efficacy.
Improving the transferability of speech separation by meta-learning
Mar 11, 2022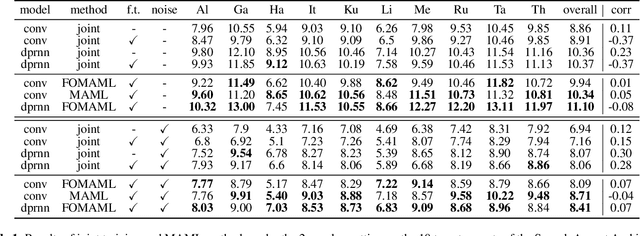
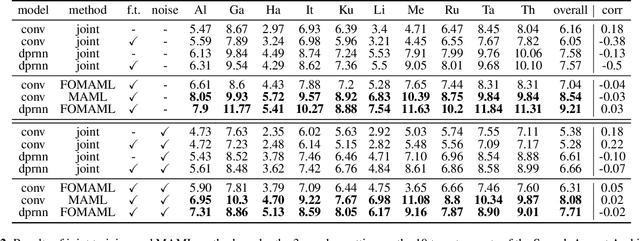
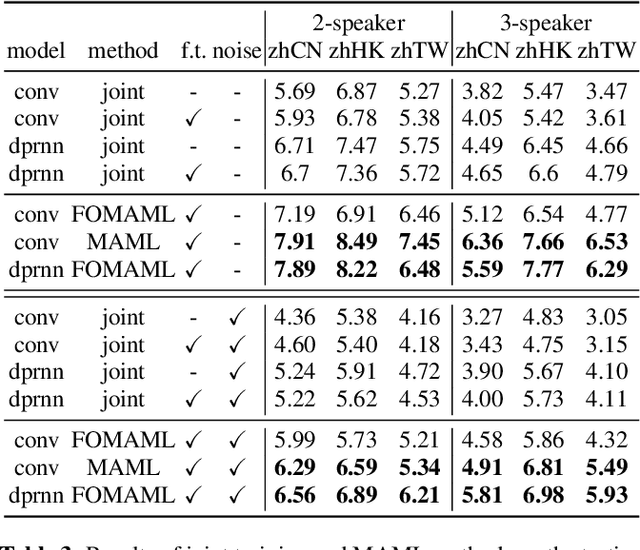
Speech separation aims to separate multiple speech sources from a speech mixture. Although speech separation is well-solved on some existing English speech separation benchmarks, it is worthy of more investigation on the generalizability of speech separation models on the accents or languages unseen during training. This paper adopts meta-learning based methods to improve the transferability of speech separation models. With the meta-learning based methods, we discovered that only using speech data with one accent, the native English accent, as our training data, the models still can be adapted to new unseen accents on the Speech Accent Archive. We compared the results with a human-rated native-likeness of accents, showing that the transferability of MAML methods has less relation to the similarity of data between the training and testing phase compared to the typical transfer learning methods. Furthermore, we found that models can deal with different language data from the CommonVoice corpus during the testing phase. Most of all, the MAML methods outperform typical transfer learning methods when it comes to new accents, new speakers, new languages, and noisy environments.
Dual-path Attention is All You Need for Audio-Visual Speech Extraction
Jul 09, 2022
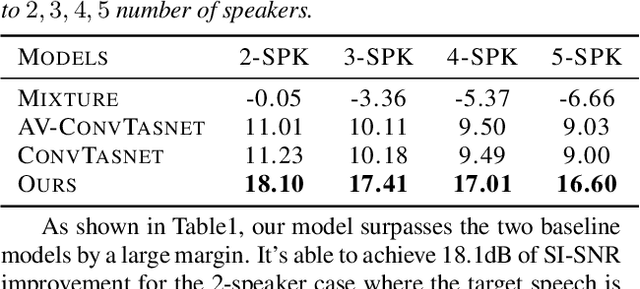
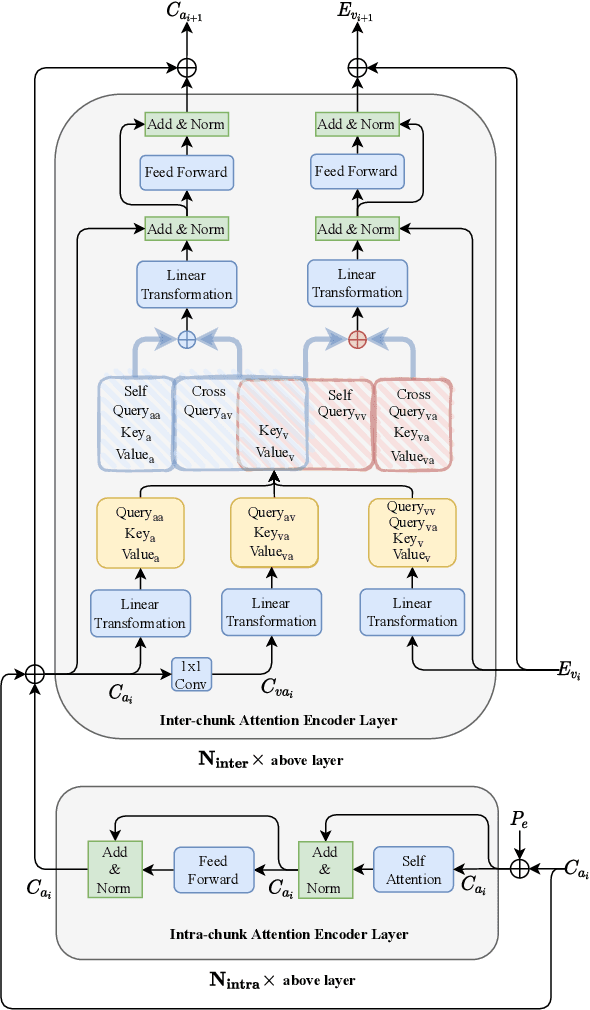
Audio-visual target speech extraction, which aims to extract a certain speaker's speech from the noisy mixture by looking at lip movements, has made significant progress combining time-domain speech separation models and visual feature extractors (CNN). One problem of fusing audio and video information is that they have different time resolutions. Most current research upsamples the visual features along the time dimension so that audio and video features are able to align in time. However, we believe that lip movement should mostly contain long-term, or phone-level information. Based on this assumption, we propose a new way to fuse audio-visual features. We observe that for DPRNN \cite{dprnn}, the interchunk dimension's time resolution could be very close to the time resolution of video frames. Like \cite{sepformer}, the LSTM in DPRNN is replaced by intra-chunk and inter-chunk self-attention, but in the proposed algorithm, inter-chunk attention incorporates the visual features as an additional feature stream. This prevents the upsampling of visual cues, resulting in more efficient audio-visual fusion. The result shows we achieve superior results compared with other time-domain based audio-visual fusion models.
Topic Modeling Based on Two-Step Flow Theory: Application to Tweets about Bitcoin
Mar 03, 2023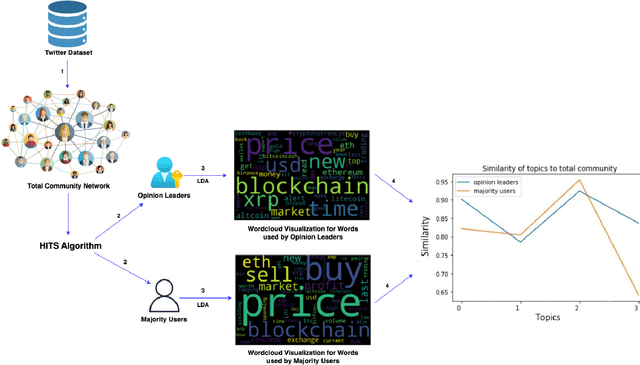
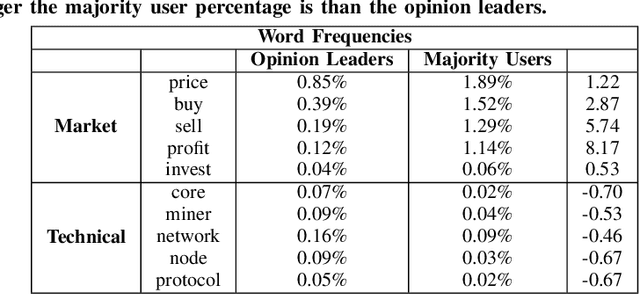
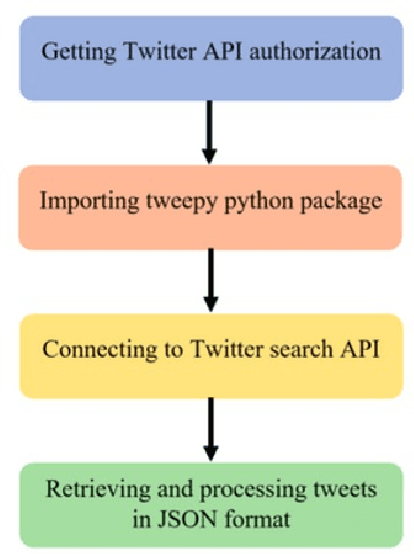
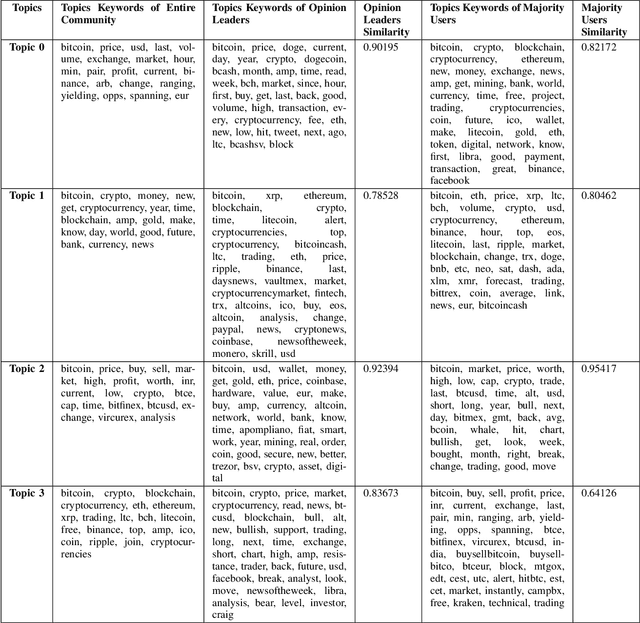
Digital cryptocurrencies such as Bitcoin have exploded in recent years in both popularity and value. By their novelty, cryptocurrencies tend to be both volatile and highly speculative. The capricious nature of these coins is helped facilitated by social media networks such as Twitter. However, not everyone's opinion matters equally, with most posts garnering little to no attention. Additionally, the majority of tweets are retweeted from popular posts. We must determine whose opinion matters and the difference between influential and non-influential users. This study separates these two groups and analyzes the differences between them. It uses Hypertext-induced Topic Selection (HITS) algorithm, which segregates the dataset based on influence. Topic modeling is then employed to uncover differences in each group's speech types and what group may best represent the entire community. We found differences in language and interest between these two groups regarding Bitcoin and that the opinion leaders of Twitter are not aligned with the majority of users. There were 2559 opinion leaders (0.72% of users) who accounted for 80% of the authority and the majority (99.28%) users for the remaining 20% out of a total of 355,139 users.
Low-Resource End-to-end Sanskrit TTS using Tacotron2, WaveGlow and Transfer Learning
Dec 07, 2022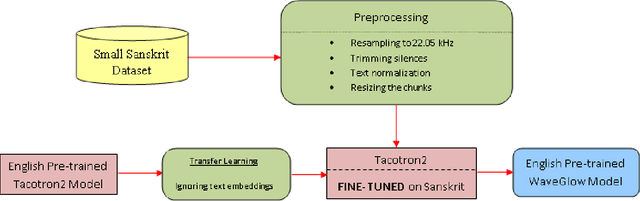
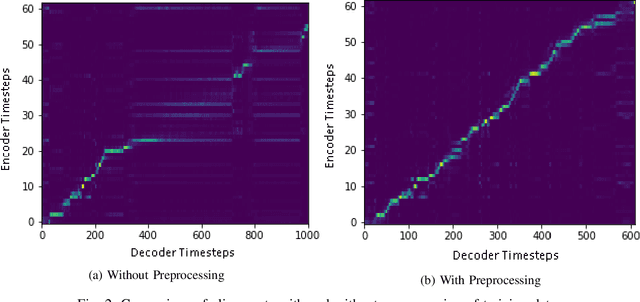
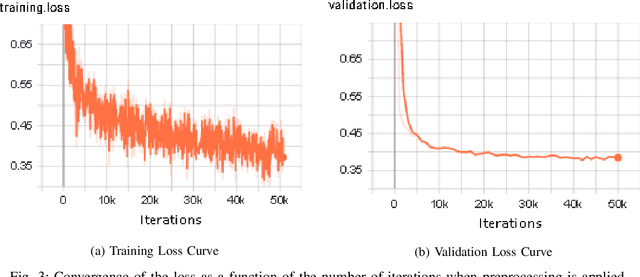

End-to-end text-to-speech (TTS) systems have been developed for European languages like English and Spanish with state-of-the-art speech quality, prosody, and naturalness. However, development of end-to-end TTS for Indian languages is lagging behind in terms of quality. The challenges involved in such a task are: 1) scarcity of quality training data; 2) low efficiency during training and inference; 3) slow convergence in the case of large vocabulary size. In our work reported in this paper, we have investigated the use of fine-tuning the English-pretrained Tacotron2 model with limited Sanskrit data to synthesize natural sounding speech in Sanskrit in low resource settings. Our experiments show encouraging results, achieving an overall MOS of 3.38 from 37 evaluators with good Sanskrit spoken knowledge. This is really a very good result, considering the fact that the speech data we have used is of duration 2.5 hours only.
Approaching an unknown communication system by latent space exploration and causal inference
Mar 20, 2023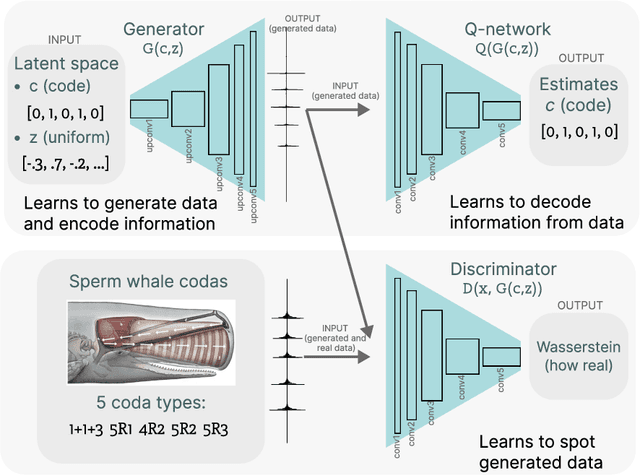
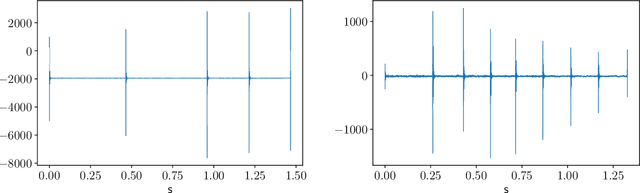
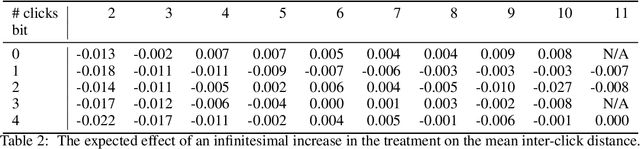
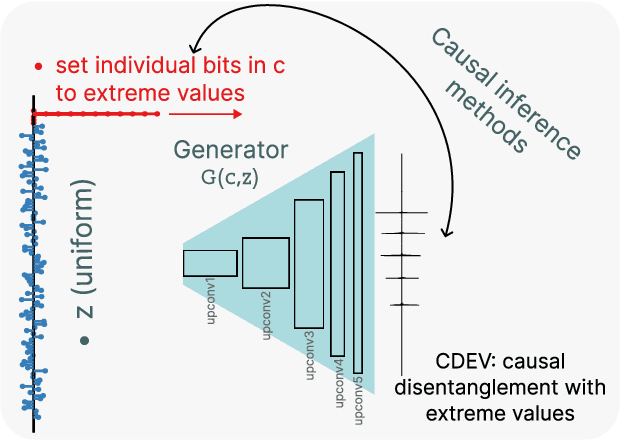
This paper proposes a methodology for discovering meaningful properties in data by exploring the latent space of unsupervised deep generative models. We combine manipulation of individual latent variables to extreme values outside the training range with methods inspired by causal inference into an approach we call causal disentanglement with extreme values (CDEV) and show that this approach yields insights for model interpretability. Using this technique, we can infer what properties of unknown data the model encodes as meaningful. We apply the methodology to test what is meaningful in the communication system of sperm whales, one of the most intriguing and understudied animal communication systems. We train a network that has been shown to learn meaningful representations of speech and test whether we can leverage such unsupervised learning to decipher the properties of another vocal communication system for which we have no ground truth. The proposed technique suggests that sperm whales encode information using the number of clicks in a sequence, the regularity of their timing, and audio properties such as the spectral mean and the acoustic regularity of the sequences. Some of these findings are consistent with existing hypotheses, while others are proposed for the first time. We also argue that our models uncover rules that govern the structure of communication units in the sperm whale communication system and apply them while generating innovative data not shown during training. This paper suggests that an interpretation of the outputs of deep neural networks with causal methodology can be a viable strategy for approaching data about which little is known and presents another case of how deep learning can limit the hypothesis space. Finally, the proposed approach combining latent space manipulation and causal inference can be extended to other architectures and arbitrary datasets.
Explainable Human-centered Traits from Head Motion and Facial Expression Dynamics
Feb 23, 2023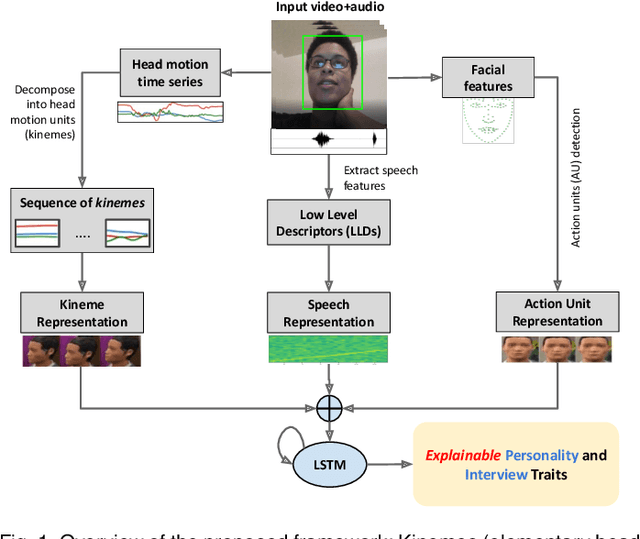
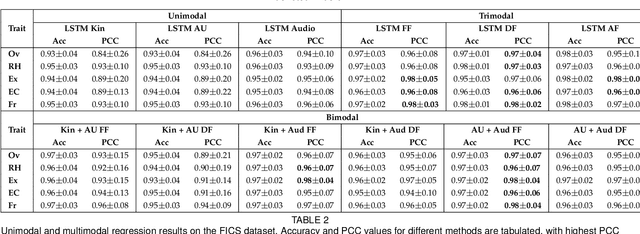
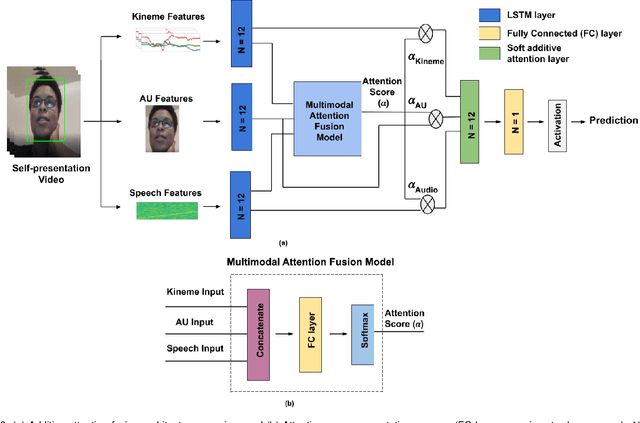
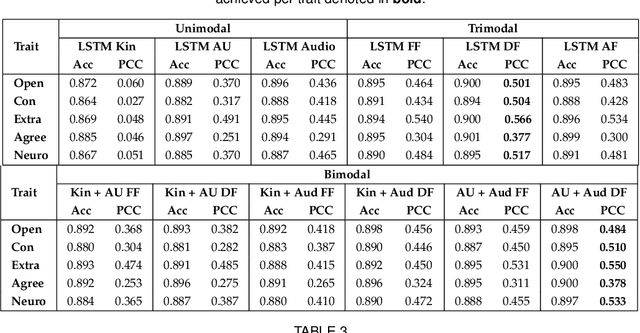
We explore the efficacy of multimodal behavioral cues for explainable prediction of personality and interview-specific traits. We utilize elementary head-motion units named kinemes, atomic facial movements termed action units and speech features to estimate these human-centered traits. Empirical results confirm that kinemes and action units enable discovery of multiple trait-specific behaviors while also enabling explainability in support of the predictions. For fusing cues, we explore decision and feature-level fusion, and an additive attention-based fusion strategy which quantifies the relative importance of the three modalities for trait prediction. Examining various long-short term memory (LSTM) architectures for classification and regression on the MIT Interview and First Impressions Candidate Screening (FICS) datasets, we note that: (1) Multimodal approaches outperform unimodal counterparts; (2) Efficient trait predictions and plausible explanations are achieved with both unimodal and multimodal approaches, and (3) Following the thin-slice approach, effective trait prediction is achieved even from two-second behavioral snippets.
Generalization of Auto-Regressive Hidden Markov Models to Non-Linear Dynamics and Non-Euclidean Observation Space
Feb 23, 2023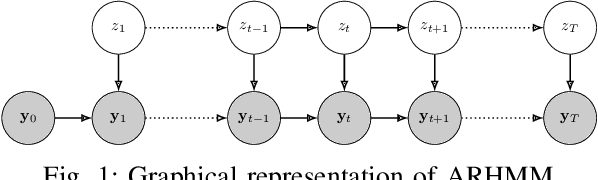
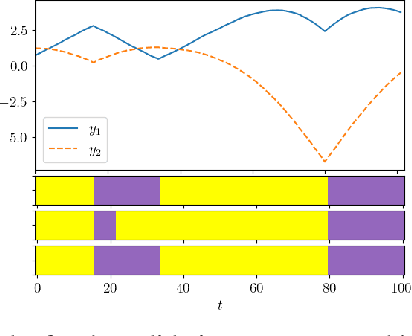
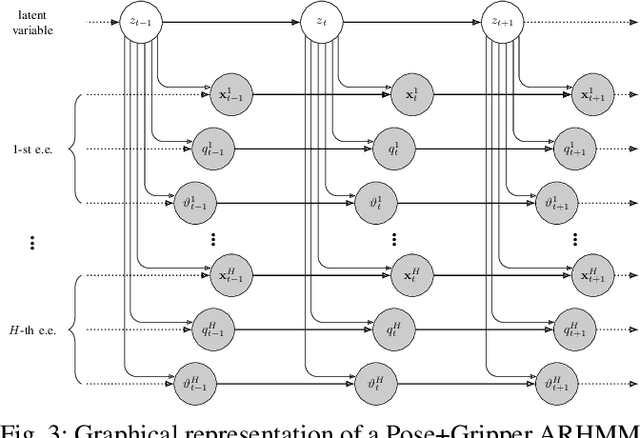
Latent variable models are widely used to perform unsupervised segmentation of time series in different context such as robotics, speech recognition, and economics. One of the most widely used latent variable model is the Auto-Regressive Hidden Markov Model (ARHMM), which combines a latent mode governed by a Markov chain dynamics with a linear Auto-Regressive dynamics of the observed state. In this work, we propose two generalizations of the ARHMM. First, we propose a more general AR dynamics in Cartesian space, described as a linear combination of non-linear basis functions. Second, we propose a linear dynamics in unit quaternion space, in order to properly describe orientations. These extensions allow to describe more complex dynamics of the observed state. Although this extension is proposed for the ARHMM, it can be easily extended to other latent variable models with AR dynamics in the observed space, such as Auto-Regressive Hidden semi-Markov Models.
Incorporating Uncertainty from Speaker Embedding Estimation to Speaker Verification
Feb 23, 2023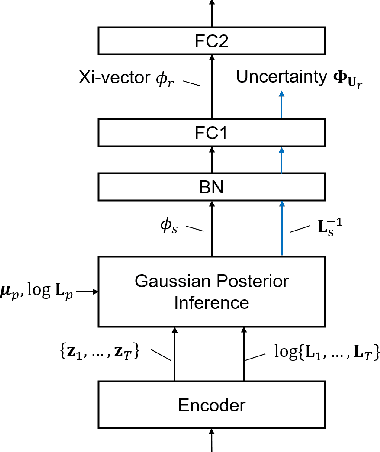

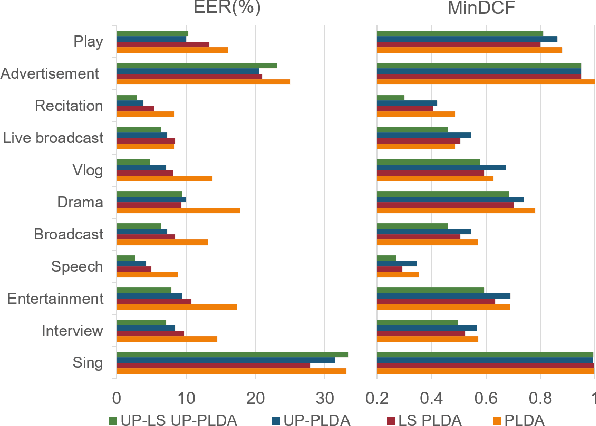
Speech utterances recorded under differing conditions exhibit varying degrees of confidence in their embedding estimates, i.e., uncertainty, even if they are extracted using the same neural network. This paper aims to incorporate the uncertainty estimate produced in the xi-vector network front-end with a probabilistic linear discriminant analysis (PLDA) back-end scoring for speaker verification. To achieve this we derive a posterior covariance matrix, which measures the uncertainty, from the frame-wise precisions to the embedding space. We propose a log-likelihood ratio function for the PLDA scoring with the uncertainty propagation. We also propose to replace the length normalization pre-processing technique with a length scaling technique for the application of uncertainty propagation in the back-end. Experimental results on the VoxCeleb-1, SITW test sets as well as a domain-mismatched CNCeleb1-E set show the effectiveness of the proposed techniques with 14.5%-41.3% EER reductions and 4.6%-25.3% minDCF reductions.
Make More of Your Data: Minimal Effort Data Augmentation for Automatic Speech Recognition and Translation
Oct 27, 2022
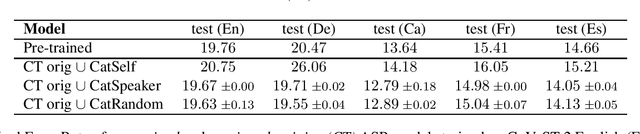

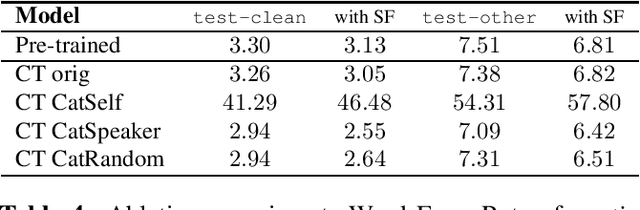
Data augmentation is a technique to generate new training data based on existing data. We evaluate the simple and cost-effective method of concatenating the original data examples to build new training instances. Continued training with such augmented data is able to improve off-the-shelf Transformer and Conformer models that were optimized on the original data only. We demonstrate considerable improvements on the LibriSpeech-960h test sets (WER 2.83 and 6.87 for test-clean and test-other), which carry over to models combined with shallow fusion (WER 2.55 and 6.27). Our method of continued training also leads to improvements of up to 0.9 WER on the ASR part of CoVoST-2 for four non English languages, and we observe that the gains are highly dependent on the size of the original training data. We compare different concatenation strategies and found that our method does not need speaker information to achieve its improvements. Finally, we demonstrate on two datasets that our methods also works for speech translation tasks.