 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
TRESTLE: Toolkit for Reproducible Execution of Speech, Text and Language Experiments
Feb 14, 2023

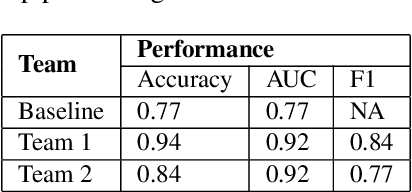
The evidence is growing that machine and deep learning methods can learn the subtle differences between the language produced by people with various forms of cognitive impairment such as dementia and cognitively healthy individuals. Valuable public data repositories such as TalkBank have made it possible for researchers in the computational community to join forces and learn from each other to make significant advances in this area. However, due to variability in approaches and data selection strategies used by various researchers, results obtained by different groups have been difficult to compare directly. In this paper, we present TRESTLE (\textbf{T}oolkit for \textbf{R}eproducible \textbf{E}xecution of \textbf{S}peech \textbf{T}ext and \textbf{L}anguage \textbf{E}xperiments), an open source platform that focuses on two datasets from the TalkBank repository with dementia detection as an illustrative domain. Successfully deployed in the hackallenge (Hackathon/Challenge) of the International Workshop on Health Intelligence at AAAI 2022, TRESTLE provides a precise digital blueprint of the data pre-processing and selection strategies that can be reused via TRESTLE by other researchers seeking comparable results with their peers and current state-of-the-art (SOTA) approaches.
Dual-path Attention is All You Need for Audio-Visual Speech Extraction
Jul 09, 2022
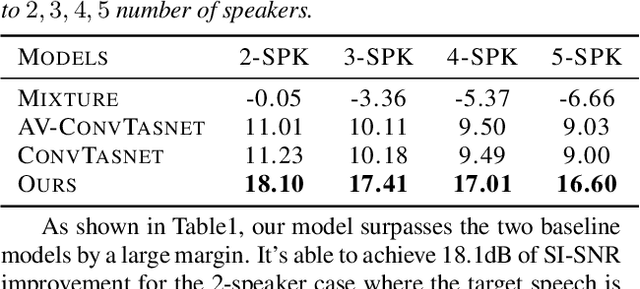
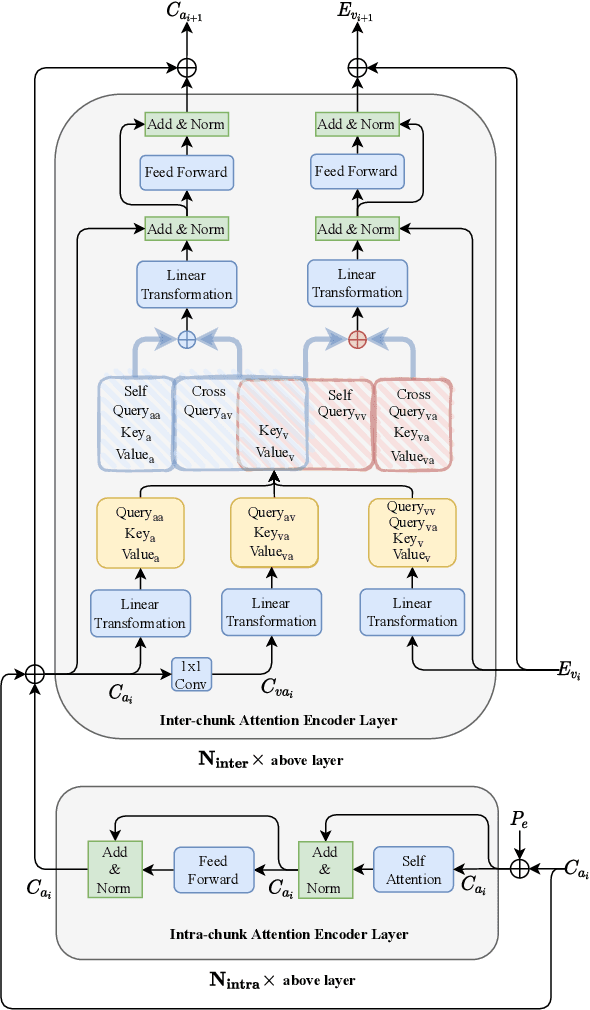
Audio-visual target speech extraction, which aims to extract a certain speaker's speech from the noisy mixture by looking at lip movements, has made significant progress combining time-domain speech separation models and visual feature extractors (CNN). One problem of fusing audio and video information is that they have different time resolutions. Most current research upsamples the visual features along the time dimension so that audio and video features are able to align in time. However, we believe that lip movement should mostly contain long-term, or phone-level information. Based on this assumption, we propose a new way to fuse audio-visual features. We observe that for DPRNN \cite{dprnn}, the interchunk dimension's time resolution could be very close to the time resolution of video frames. Like \cite{sepformer}, the LSTM in DPRNN is replaced by intra-chunk and inter-chunk self-attention, but in the proposed algorithm, inter-chunk attention incorporates the visual features as an additional feature stream. This prevents the upsampling of visual cues, resulting in more efficient audio-visual fusion. The result shows we achieve superior results compared with other time-domain based audio-visual fusion models.
Exploration of A Self-Supervised Speech Model: A Study on Emotional Corpora
Oct 05, 2022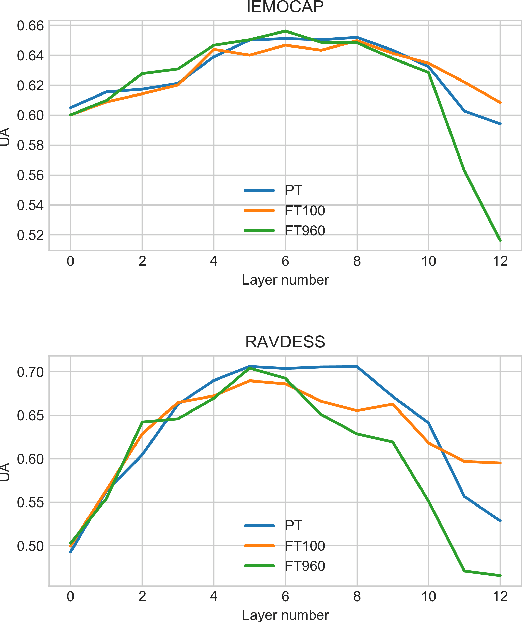
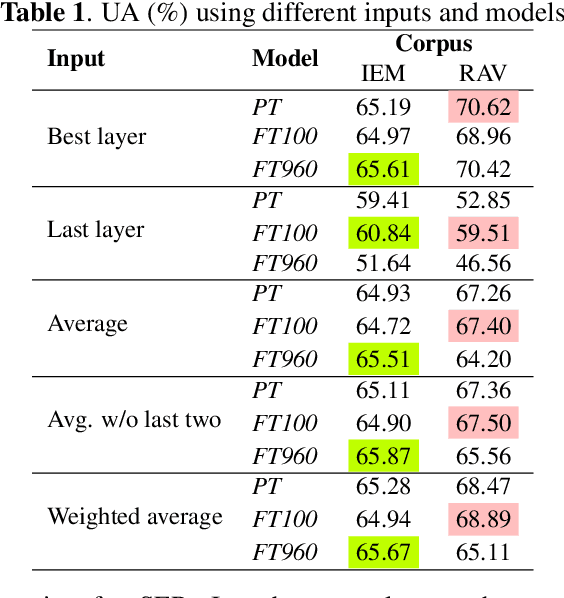
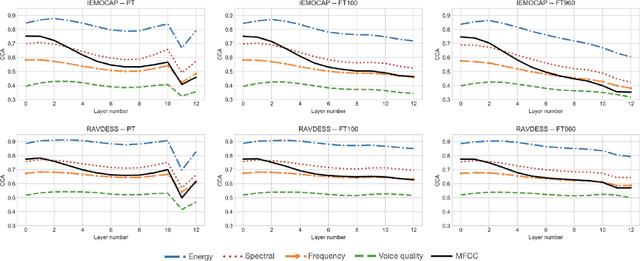

Self-supervised speech models have grown fast during the past few years and have proven feasible for use in various downstream tasks. Some recent work has started to look at the characteristics of these models, yet many concerns have not been fully addressed. In this work, we conduct a study on emotional corpora to explore a popular self-supervised model -- wav2vec 2.0. Via a set of quantitative analysis, we mainly demonstrate that: 1) wav2vec 2.0 appears to discard paralinguistic information that is less useful for word recognition purposes; 2) for emotion recognition, representations from the middle layer alone perform as well as those derived from layer averaging, while the final layer results in the worst performance in some cases; 3) current self-supervised models may not be the optimal solution for downstream tasks that make use of non-lexical features. Our work provides novel findings that will aid future research in this area and theoretical basis for the use of existing models.
Leveraging Speech Separation for Conversational Telephone Speaker Diarization
Apr 05, 2022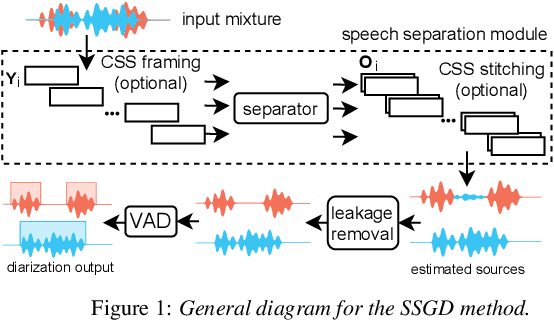
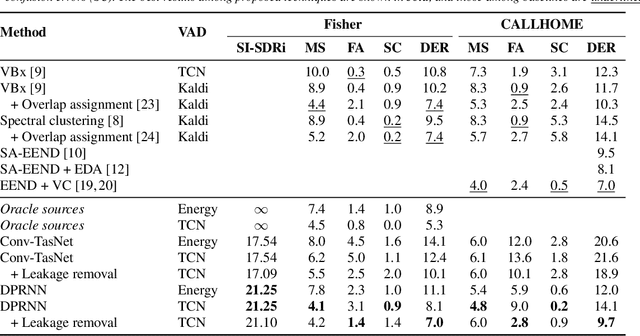

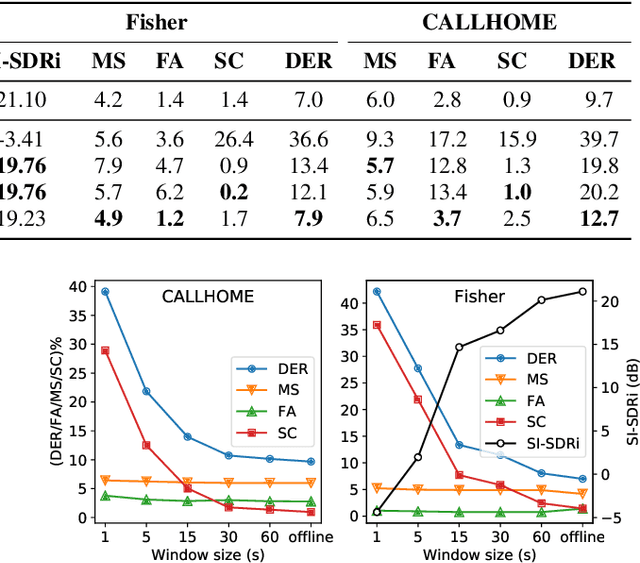
Speech separation and speaker diarization have strong similarities. In particular with respect to end-to-end neural diarization (EEND) methods. Separation aims at extracting each speaker from overlapped speech, while diarization identifies time boundaries of speech segments produced by the same speaker. In this paper, we carry out an analysis of the use of speech separation guided diarization (SSGD) where diarization is performed simply by separating the speakers signals and applying voice activity detection. In particular we compare two speech separation (SSep) models, both in offline and online settings. In the online setting we consider both the use of continuous source separation (CSS) and causal SSep models architectures. As an additional contribution, we show a simple post-processing algorithm which reduces significantly the false alarm errors of a SSGD pipeline. We perform our experiments on Fisher Corpus Part 1 and CALLHOME datasets evaluating both separation and diarization metrics. Notably, without fine-tuning, our SSGD DPRNN-based online model achieves 12.7% DER on CALLHOME, comparable with state-of-the-art EEND models despite having considerably lower latency, i.e., 50 ms vs 1 s.
Efficiency 360: Efficient Vision Transformers
Feb 23, 2023
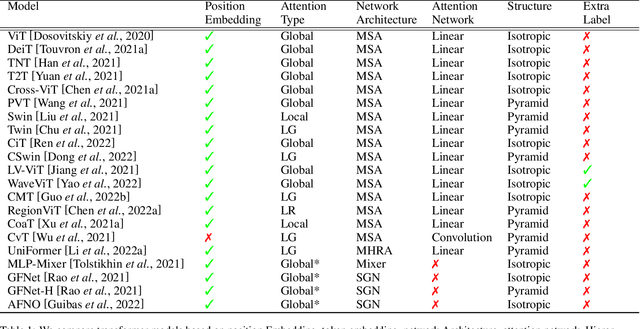
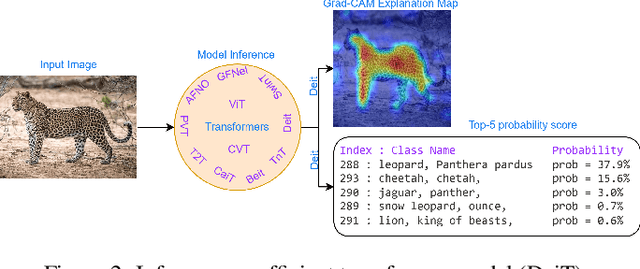
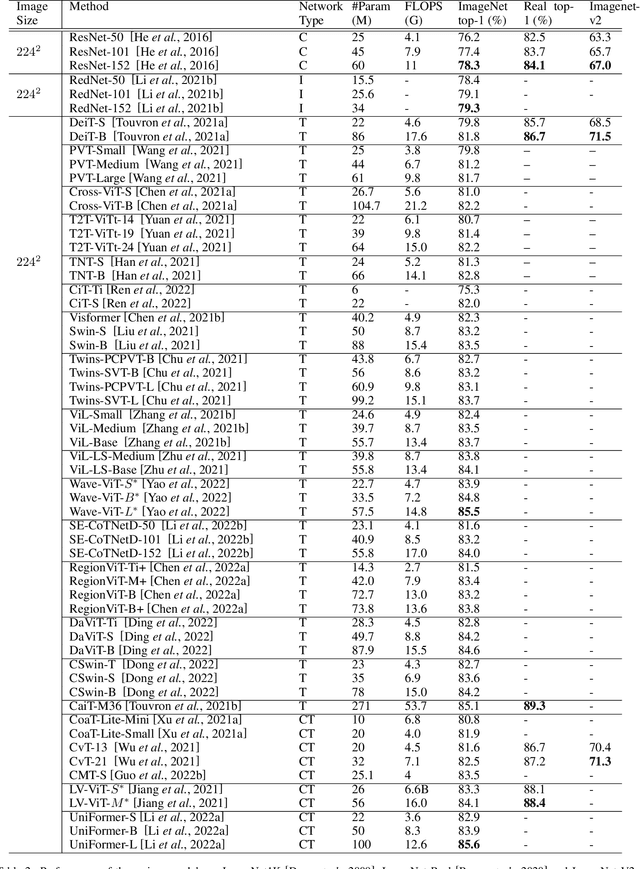
Transformers are widely used for solving tasks in natural language processing, computer vision, speech, and music domains. In this paper, we talk about the efficiency of transformers in terms of memory (the number of parameters), computation cost (number of floating points operations), and performance of models, including accuracy, the robustness of the model, and fair \& bias-free features. We mainly discuss the vision transformer for the image classification task. Our contribution is to introduce an efficient 360 framework, which includes various aspects of the vision transformer, to make it more efficient for industrial applications. By considering those applications, we categorize them into multiple dimensions such as privacy, robustness, transparency, fairness, inclusiveness, continual learning, probabilistic models, approximation, computational complexity, and spectral complexity. We compare various vision transformer models based on their performance, the number of parameters, and the number of floating point operations (FLOPs) on multiple datasets.
Knowledge-Based Counterfactual Queries for Visual Question Answering
Mar 05, 2023
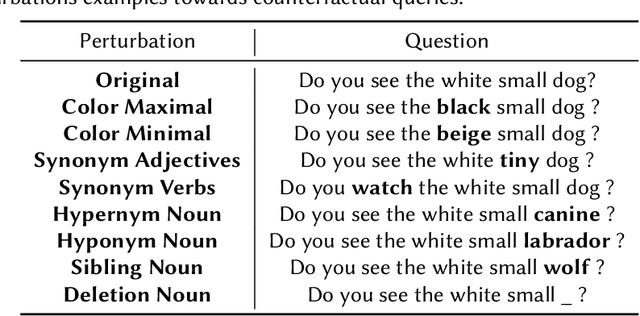
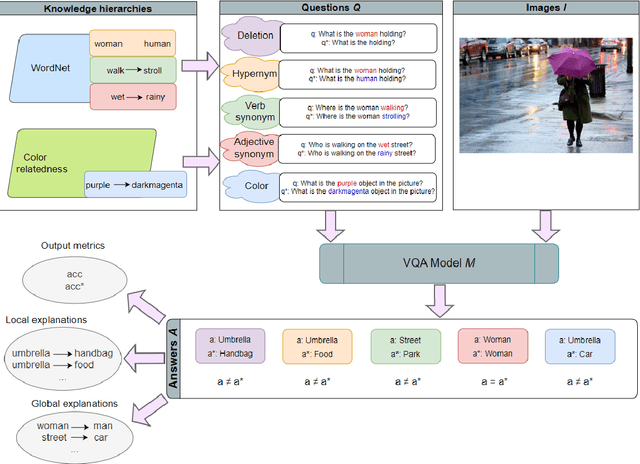

Visual Question Answering (VQA) has been a popular task that combines vision and language, with numerous relevant implementations in literature. Even though there are some attempts that approach explainability and robustness issues in VQA models, very few of them employ counterfactuals as a means of probing such challenges in a model-agnostic way. In this work, we propose a systematic method for explaining the behavior and investigating the robustness of VQA models through counterfactual perturbations. For this reason, we exploit structured knowledge bases to perform deterministic, optimal and controllable word-level replacements targeting the linguistic modality, and we then evaluate the model's response against such counterfactual inputs. Finally, we qualitatively extract local and global explanations based on counterfactual responses, which are ultimately proven insightful towards interpreting VQA model behaviors. By performing a variety of perturbation types, targeting different parts of speech of the input question, we gain insights to the reasoning of the model, through the comparison of its responses in different adversarial circumstances. Overall, we reveal possible biases in the decision-making process of the model, as well as expected and unexpected patterns, which impact its performance quantitatively and qualitatively, as indicated by our analysis.
Unsupervised Model-based speaker adaptation of end-to-end lattice-free MMI model for speech recognition
Nov 17, 2022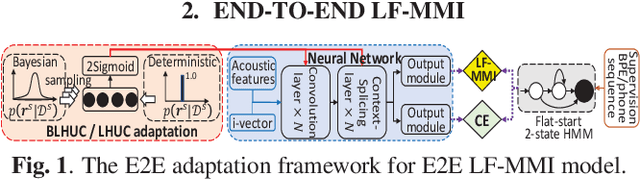
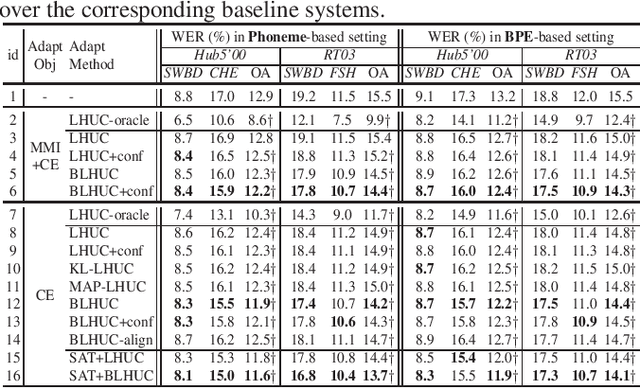
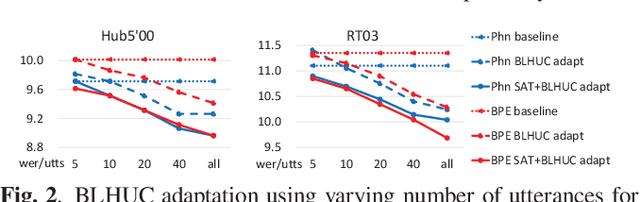
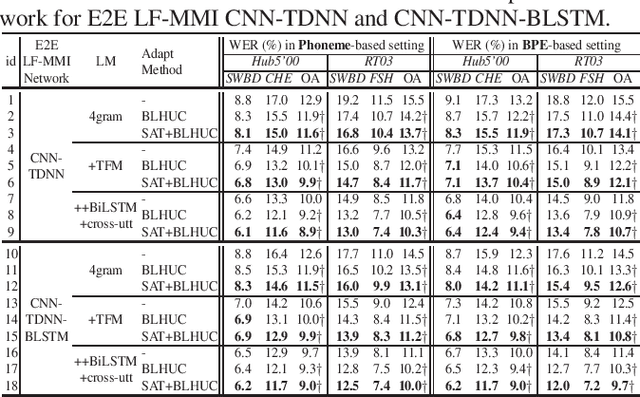
Modeling the speaker variability is a key challenge for automatic speech recognition (ASR) systems. In this paper, the learning hidden unit contributions (LHUC) based adaptation techniques with compact speaker dependent (SD) parameters are used to facilitate both speaker adaptive training (SAT) and unsupervised test-time speaker adaptation for end-to-end (E2E) lattice-free MMI (LF-MMI) models. An unsupervised model-based adaptation framework is proposed to estimate the SD parameters in E2E paradigm using LF-MMI and cross entropy (CE) criterions. Various regularization methods of the standard LHUC adaptation, e.g., the Bayesian LHUC (BLHUC) adaptation, are systematically investigated to mitigate the risk of overfitting, on E2E LF-MMI CNN-TDNN and CNN-TDNN-BLSTM models. Lattice-based confidence score estimation is used for adaptation data selection to reduce the supervision label uncertainty. Experiments on the 300-hour Switchboard task suggest that applying BLHUC in the proposed unsupervised E2E adaptation framework to byte pair encoding (BPE) based E2E LF-MMI systems consistently outperformed the baseline systems by relative word error rate (WER) reductions up to 10.5% and 14.7% on the NIST Hub5'00 and RT03 evaluation sets, and achieved the best performance in WERs of 9.0% and 9.7%, respectively. These results are comparable to the results of state-of-the-art adapted LF-MMI hybrid systems and adapted Conformer-based E2E systems.
A Complementary Joint Training Approach Using Unpaired Speech and Text for Low-Resource Automatic Speech Recognition
Apr 05, 2022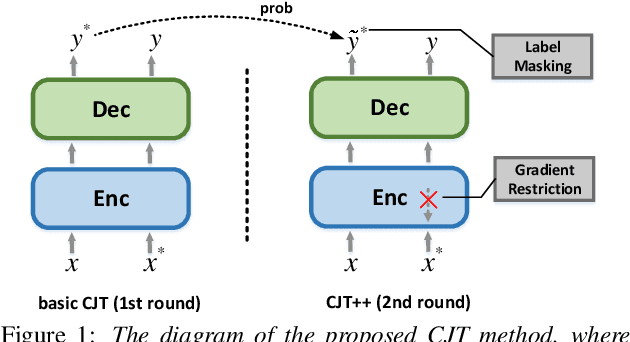
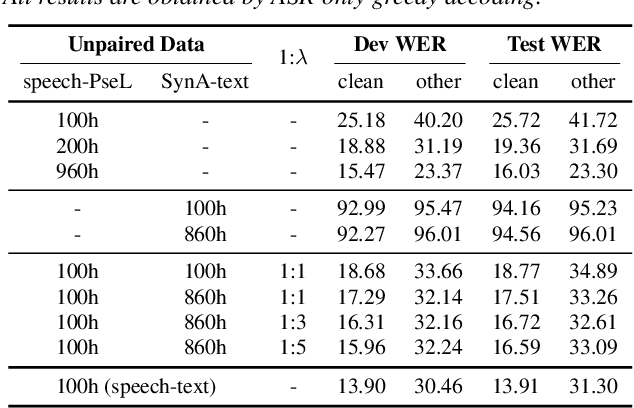
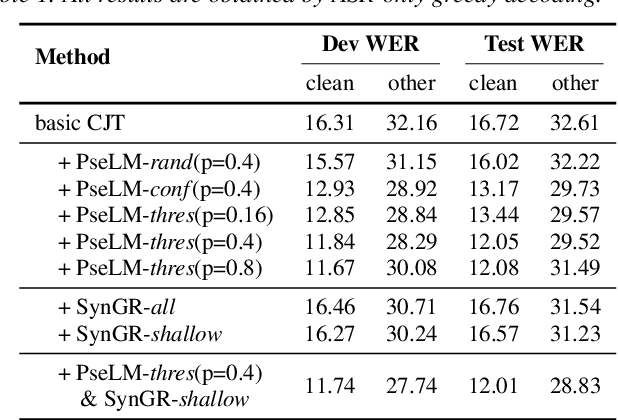
Unpaired data has shown to be beneficial for low-resource automatic speech recognition~(ASR), which can be involved in the design of hybrid models with multi-task training or language model dependent pre-training. In this work, we leverage unpaired data to train a general sequence-to-sequence model. Unpaired speech and text are used in the form of data pairs by generating the corresponding missing parts in prior to model training. Inspired by the complementarity of speech-PseudoLabel pair and SynthesizedAudio-text pair in both acoustic features and linguistic features, we propose a complementary joint training~(CJT) method that trains a model alternatively with two data pairs. Furthermore, label masking for pseudo-labels and gradient restriction for synthesized audio are proposed to further cope with the deviations from real data, termed as CJT++. Experimental results show that compared to speech-only training, the proposed basic CJT achieves great performance improvements on clean/other test sets, and the CJT++ re-training yields further performance enhancements. It is also apparent that the proposed method outperforms the wav2vec2.0 model with the same model size and beam size, particularly in extreme low-resource cases.
Audio-Visual Activity Guided Cross-Modal Identity Association for Active Speaker Detection
Dec 01, 2022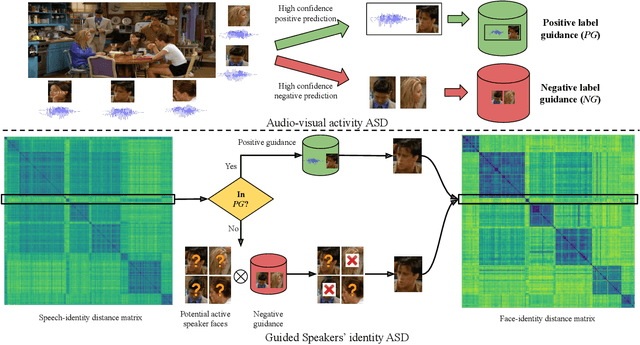
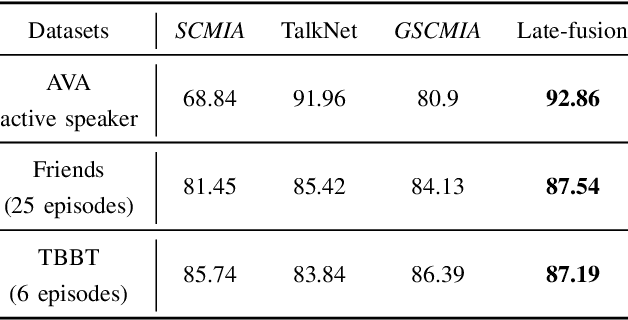
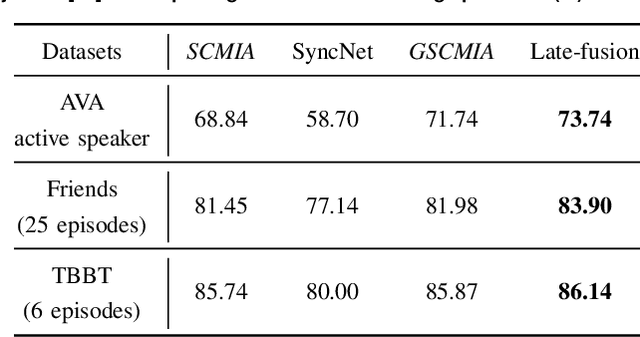
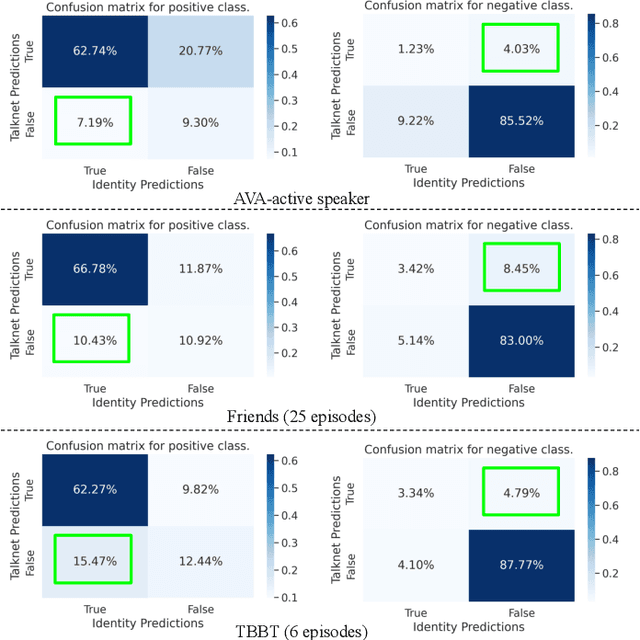
Active speaker detection in videos addresses associating a source face, visible in the video frames, with the underlying speech in the audio modality. The two primary sources of information to derive such a speech-face relationship are i) visual activity and its interaction with the speech signal and ii) co-occurrences of speakers' identities across modalities in the form of face and speech. The two approaches have their limitations: the audio-visual activity models get confused with other frequently occurring vocal activities, such as laughing and chewing, while the speakers' identity-based methods are limited to videos having enough disambiguating information to establish a speech-face association. Since the two approaches are independent, we investigate their complementary nature in this work. We propose a novel unsupervised framework to guide the speakers' cross-modal identity association with the audio-visual activity for active speaker detection. Through experiments on entertainment media videos from two benchmark datasets, the AVA active speaker (movies) and Visual Person Clustering Dataset (TV shows), we show that a simple late fusion of the two approaches enhances the active speaker detection performance.
Tandem Multitask Training of Speaker Diarisation and Speech Recognition for Meeting Transcription
Jul 08, 2022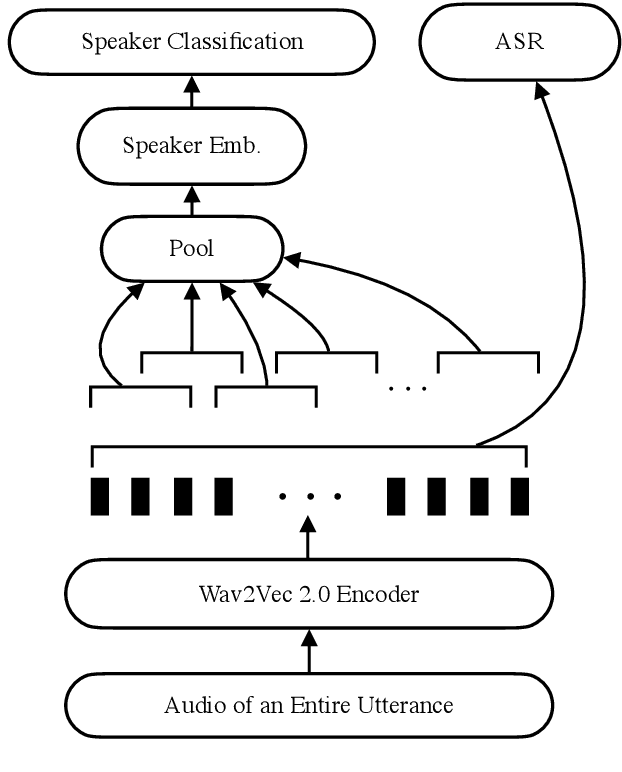
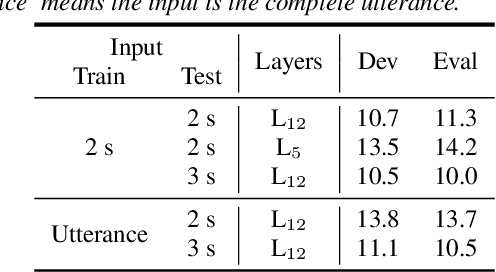
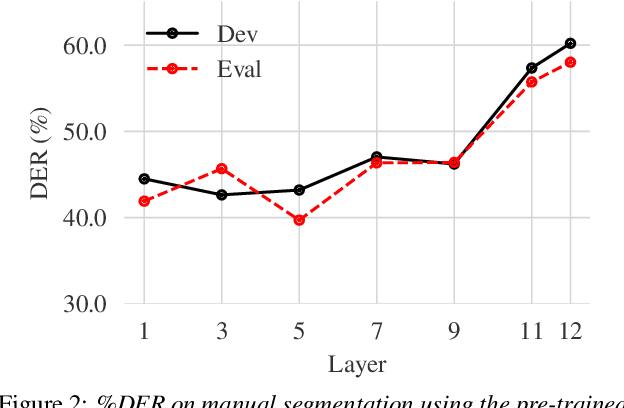
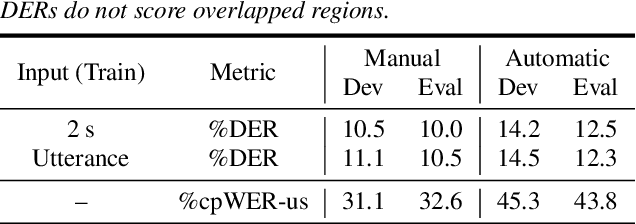
Self-supervised-learning-based pre-trained models for speech data, such as Wav2Vec 2.0 (W2V2), have become the backbone of many speech tasks. In this paper, to achieve speaker diarisation and speech recognition using a single model, a tandem multitask training (TMT) method is proposed to fine-tune W2V2. For speaker diarisation, the tasks of voice activity detection (VAD) and speaker classification (SC) are required, and connectionist temporal classification (CTC) is used for ASR. The multitask framework implements VAD, SC, and ASR using an early layer, middle layer, and late layer of W2V2, which coincides with the order of segmenting the audio with VAD, clustering the segments based on speaker embeddings, and transcribing each segment with ASR. Experimental results on the augmented multi-party (AMI) dataset showed that using different W2V2 layers for VAD, SC, and ASR from the earlier to later layers for TMT not only saves computational cost, but also reduces diarisation error rates (DERs). Joint fine-tuning of VAD, SC, and ASR yielded 16%/17% relative reductions of DER with manual/automatic segmentation respectively, and consistent reductions in speaker attributed word error rate, compared to the baseline with separately fine-tuned models.