 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Investigating self-supervised learning for speech enhancement and separation
Mar 15, 2022

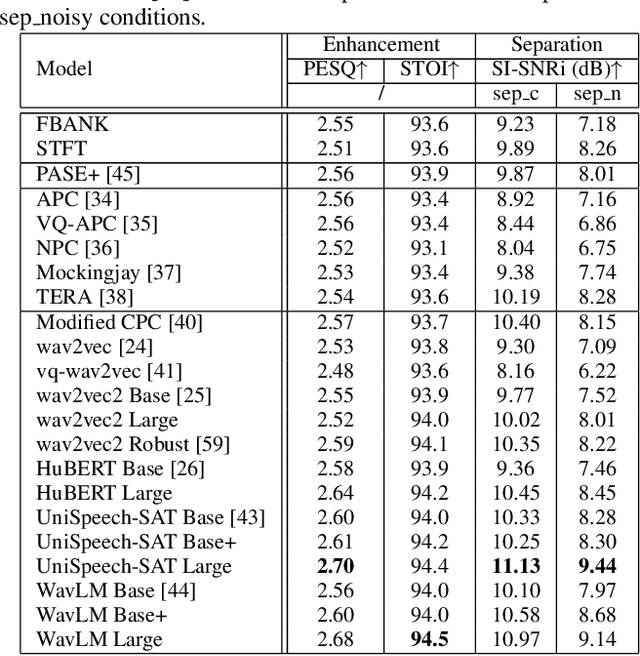
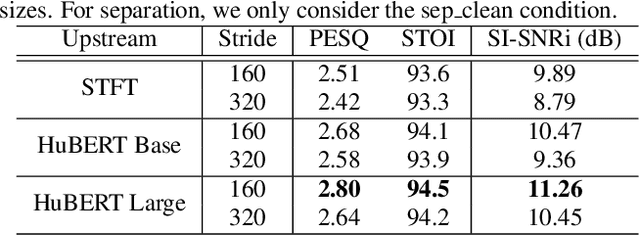
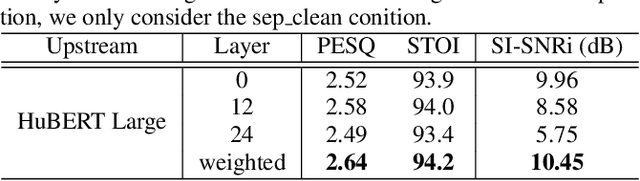
Speech enhancement and separation are two fundamental tasks for robust speech processing. Speech enhancement suppresses background noise while speech separation extracts target speech from interfering speakers. Despite a great number of supervised learning-based enhancement and separation methods having been proposed and achieving good performance, studies on applying self-supervised learning (SSL) to enhancement and separation are limited. In this paper, we evaluate 13 SSL upstream methods on speech enhancement and separation downstream tasks. Our experimental results on Voicebank-DEMAND and Libri2Mix show that some SSL representations consistently outperform baseline features including the short-time Fourier transform (STFT) magnitude and log Mel filterbank (FBANK). Furthermore, we analyze the factors that make existing SSL frameworks difficult to apply to speech enhancement and separation and discuss the representation properties desired for both tasks. Our study is included as the official speech enhancement and separation downstreams for SUPERB.
Audio-visual multi-channel speech separation, dereverberation and recognition
Apr 08, 2022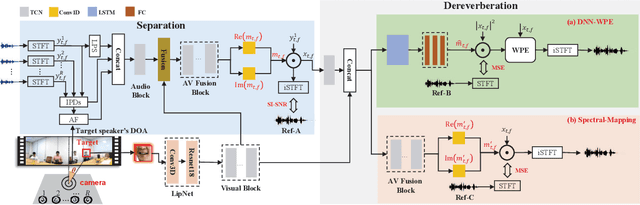

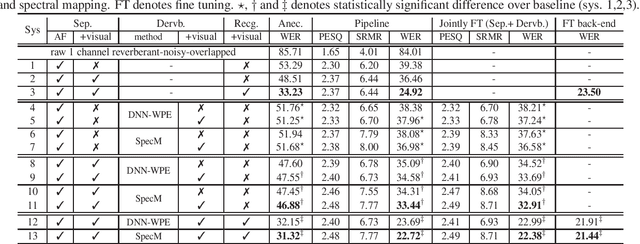
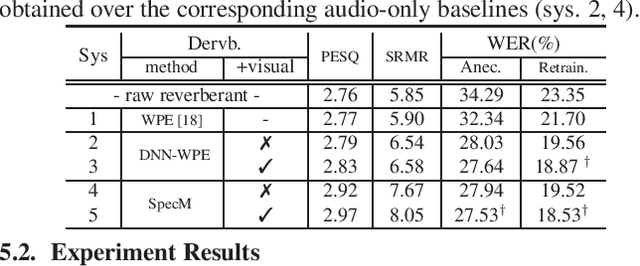
Despite the rapid advance of automatic speech recognition (ASR) technologies, accurate recognition of cocktail party speech characterised by the interference from overlapping speakers, background noise and room reverberation remains a highly challenging task to date. Motivated by the invariance of visual modality to acoustic signal corruption, audio-visual speech enhancement techniques have been developed, although predominantly targeting overlapping speech separation and recognition tasks. In this paper, an audio-visual multi-channel speech separation, dereverberation and recognition approach featuring a full incorporation of visual information into all three stages of the system is proposed. The advantage of the additional visual modality over using audio only is demonstrated on two neural dereverberation approaches based on DNN-WPE and spectral mapping respectively. The learning cost function mismatch between the separation and dereverberation models and their integration with the back-end recognition system is minimised using fine-tuning on the MSE and LF-MMI criteria. Experiments conducted on the LRS2 dataset suggest that the proposed audio-visual multi-channel speech separation, dereverberation and recognition system outperforms the baseline audio-visual multi-channel speech separation and recognition system containing no dereverberation module by a statistically significant word error rate (WER) reduction of 2.06% absolute (8.77% relative).
A Composite T60 Regression and Classification Approach for Speech Dereverberation
Feb 09, 2023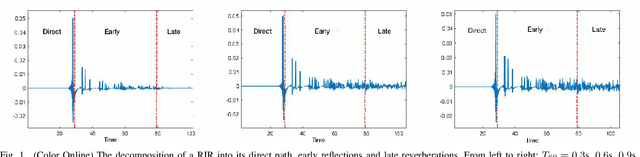
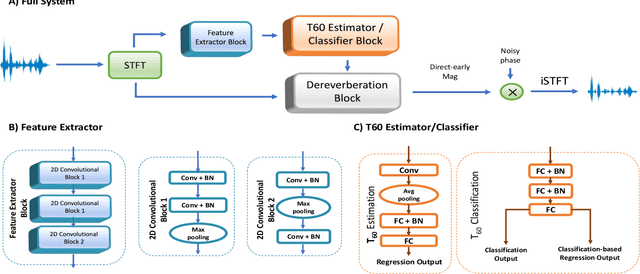
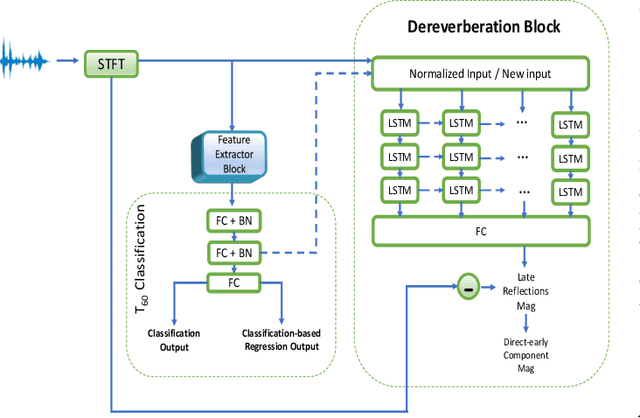
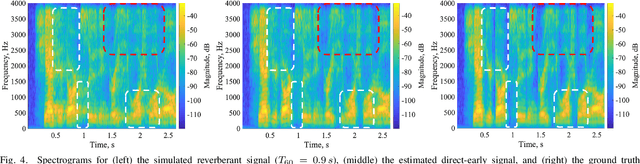
Dereverberation is often performed directly on the reverberant audio signal, without knowledge of the acoustic environment. Reverberation time, T60, however, is an essential acoustic factor that reflects how reverberation may impact a signal. In this work, we propose to perform dereverberation while leveraging key acoustic information from the environment. More specifically, we develop a joint learning approach that uses a composite T60 module and a separate dereverberation module to simultaneously perform reverberation time estimation and dereverberation. The reverberation time module provides key features to the dereverberation module during fine tuning. We evaluate our approach in simulated and real environments, and compare against several approaches. The results show that this composite framework improves performance in environments.
TRESTLE: Toolkit for Reproducible Execution of Speech, Text and Language Experiments
Feb 14, 2023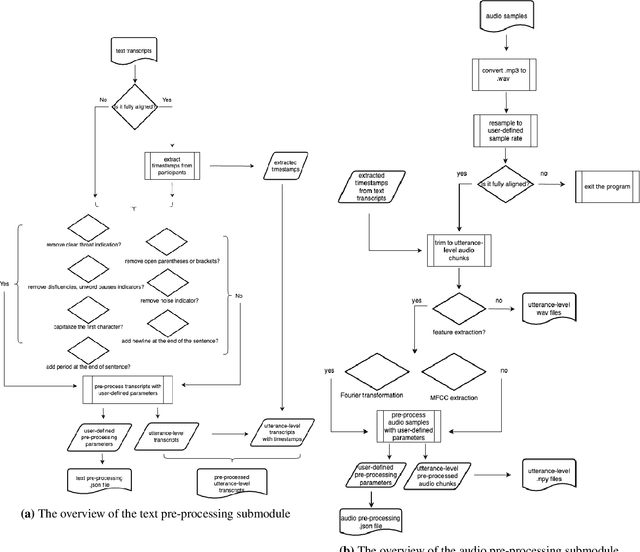

The evidence is growing that machine and deep learning methods can learn the subtle differences between the language produced by people with various forms of cognitive impairment such as dementia and cognitively healthy individuals. Valuable public data repositories such as TalkBank have made it possible for researchers in the computational community to join forces and learn from each other to make significant advances in this area. However, due to variability in approaches and data selection strategies used by various researchers, results obtained by different groups have been difficult to compare directly. In this paper, we present TRESTLE (\textbf{T}oolkit for \textbf{R}eproducible \textbf{E}xecution of \textbf{S}peech \textbf{T}ext and \textbf{L}anguage \textbf{E}xperiments), an open source platform that focuses on two datasets from the TalkBank repository with dementia detection as an illustrative domain. Successfully deployed in the hackallenge (Hackathon/Challenge) of the International Workshop on Health Intelligence at AAAI 2022, TRESTLE provides a precise digital blueprint of the data pre-processing and selection strategies that can be reused via TRESTLE by other researchers seeking comparable results with their peers and current state-of-the-art (SOTA) approaches.
FedNST: Federated Noisy Student Training for Automatic Speech Recognition
Jun 06, 2022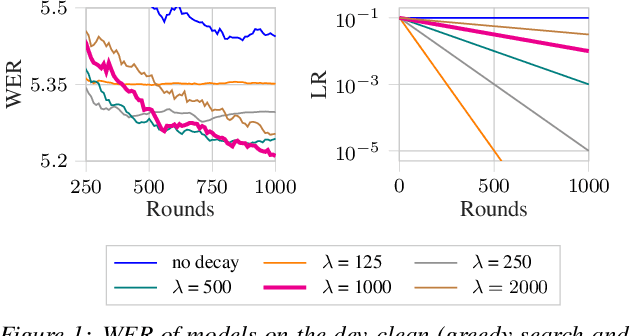
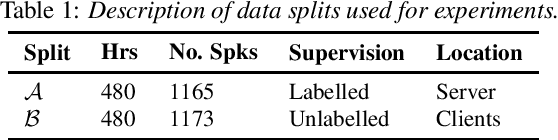
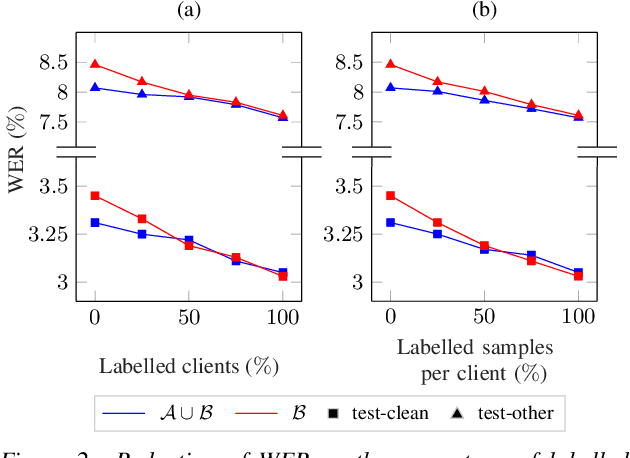
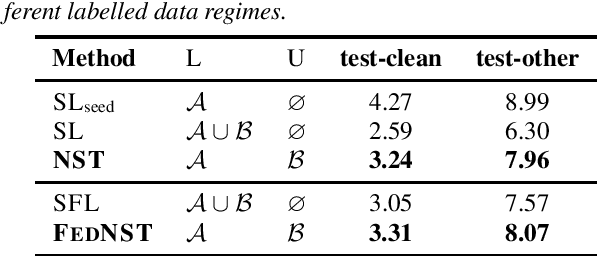
Federated Learning (FL) enables training state-of-the-art Automatic Speech Recognition (ASR) models on user devices (clients) in distributed systems, hence preventing transmission of raw user data to a central server. A key challenge facing practical adoption of FL for ASR is obtaining ground-truth labels on the clients. Existing approaches rely on clients to manually transcribe their speech, which is impractical for obtaining large training corpora. A promising alternative is using semi-/self-supervised learning approaches to leverage unlabelled user data. To this end, we propose a new Federated ASR method called FedNST for noisy student training of distributed ASR models with private unlabelled user data. We explore various facets of FedNST , such as training models with different proportions of unlabelled and labelled data, and evaluate the proposed approach on 1173 simulated clients. Evaluating FedNST on LibriSpeech, where 960 hours of speech data is split equally into server (labelled) and client (unlabelled) data, showed a 22.5% relative word error rate reduction (WERR) over a supervised baseline trained only on server data.
DP-Parse: Finding Word Boundaries from Raw Speech with an Instance Lexicon
Jun 22, 2022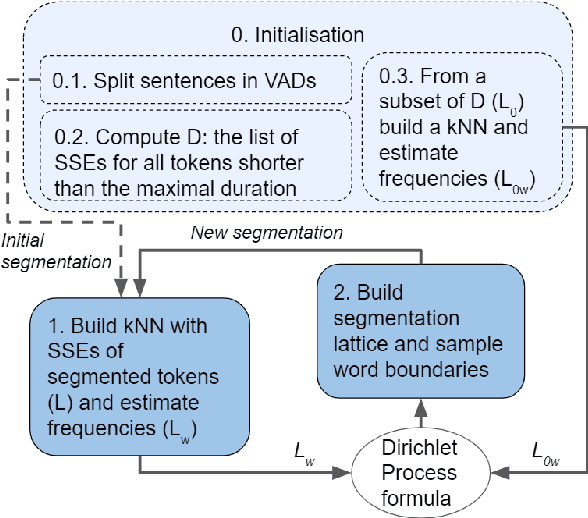

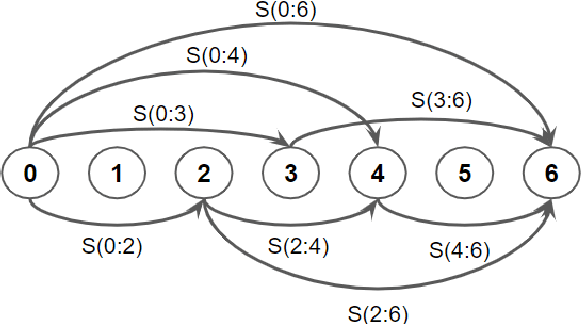

Finding word boundaries in continuous speech is challenging as there is little or no equivalent of a 'space' delimiter between words. Popular Bayesian non-parametric models for text segmentation use a Dirichlet process to jointly segment sentences and build a lexicon of word types. We introduce DP-Parse, which uses similar principles but only relies on an instance lexicon of word tokens, avoiding the clustering errors that arise with a lexicon of word types. On the Zero Resource Speech Benchmark 2017, our model sets a new speech segmentation state-of-the-art in 5 languages. The algorithm monotonically improves with better input representations, achieving yet higher scores when fed with weakly supervised inputs. Despite lacking a type lexicon, DP-Parse can be pipelined to a language model and learn semantic and syntactic representations as assessed by a new spoken word embedding benchmark.
The Norwegian Parliamentary Speech Corpus
Jan 26, 2022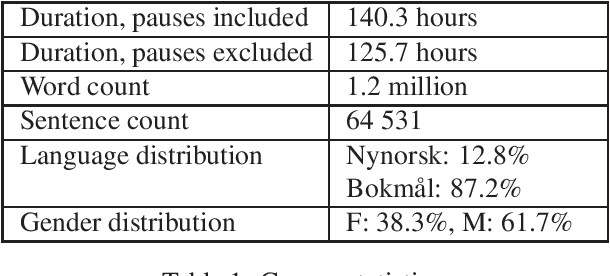
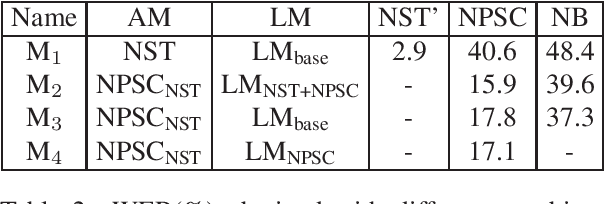
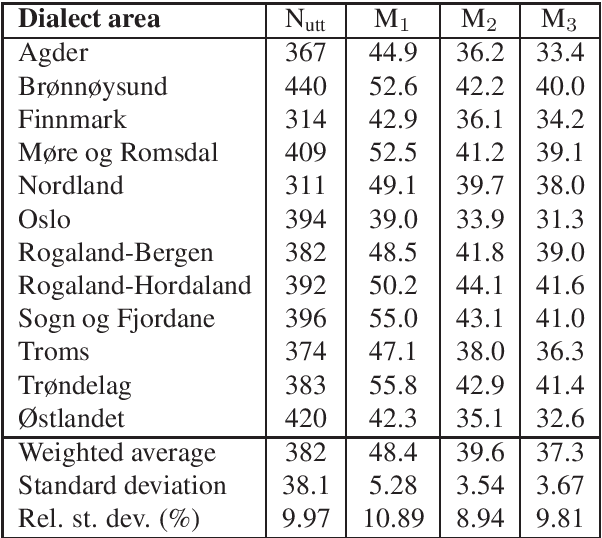
The Norwegian Parliamentary Speech Corpus (NPSC) is a speech dataset with recordings of meetings from Stortinget, the Norwegian parliament. It is the first, publicly available dataset containing unscripted, Norwegian speech designed for training of automatic speech recognition (ASR) systems. The recordings are manually transcribed and annotated with language codes and speakers, and there are detailed metadata about the speakers. The transcriptions exist in both normalized and non-normalized form, and non-standardized words are explicitly marked and annotated with standardized equivalents. To test the usefulness of this dataset, we have compared an ASR system trained on the NPSC with a baseline system trained on only manuscript-read speech. These systems were tested on an independent dataset containing spontaneous, dialectal speech. The NPSC-trained system performed significantly better, with a 22.9% relative improvement in word error rate (WER). Moreover, training on the NPSC is shown to have a "democratizing" effect in terms of dialects, as improvements are generally larger for dialects with higher WER from the baseline system.
Privacy-Preserving Speech Representation Learning using Vector Quantization
Mar 15, 2022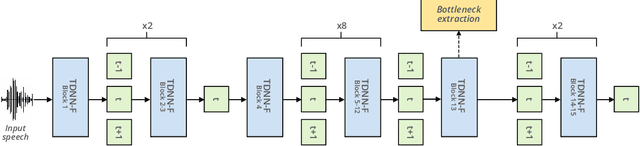

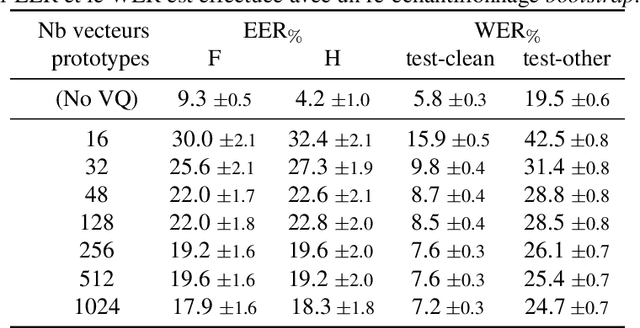
With the popularity of virtual assistants (e.g., Siri, Alexa), the use of speech recognition is now becoming more and more widespread.However, speech signals contain a lot of sensitive information, such as the speaker's identity, which raises privacy concerns.The presented experiments show that the representations extracted by the deep layers of speech recognition networks contain speaker information.This paper aims to produce an anonymous representation while preserving speech recognition performance.To this end, we propose to use vector quantization to constrain the representation space and induce the network to suppress the speaker identity.The choice of the quantization dictionary size allows to configure the trade-off between utility (speech recognition) and privacy (speaker identity concealment).
Variable-rate hierarchical CPC leads to acoustic unit discovery in speech
Jun 07, 2022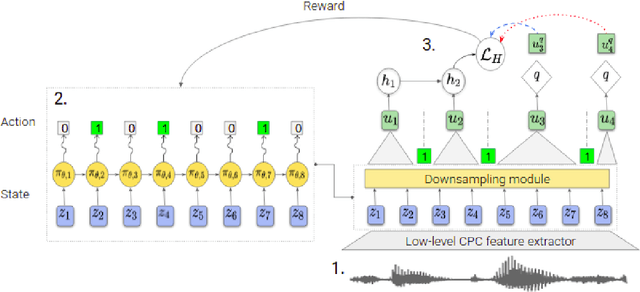
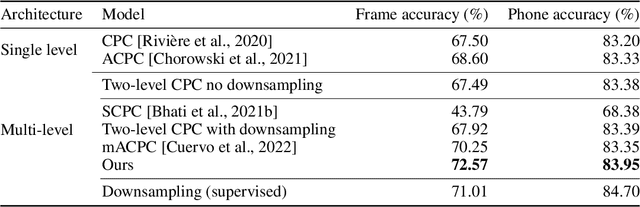

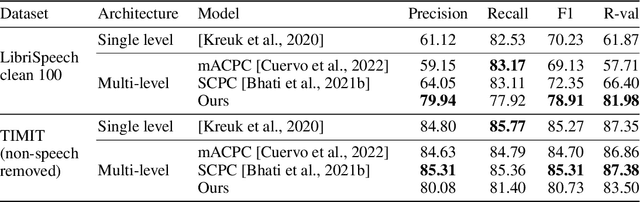
The success of deep learning comes from its ability to capture the hierarchical structure of data by learning high-level representations defined in terms of low-level ones. In this paper we explore self-supervised learning of hierarchical representations of speech by applying multiple levels of Contrastive Predictive Coding (CPC). We observe that simply stacking two CPC models does not yield significant improvements over single-level architectures. Inspired by the fact that speech is often described as a sequence of discrete units unevenly distributed in time, we propose a model in which the output of a low-level CPC module is non-uniformly downsampled to directly minimize the loss of a high-level CPC module. The latter is designed to also enforce a prior of separability and discreteness in its representations by enforcing dissimilarity of successive high-level representations through focused negative sampling, and by quantization of the prediction targets. Accounting for the structure of the speech signal improves upon single-level CPC features and enhances the disentanglement of the learned representations, as measured by downstream speech recognition tasks, while resulting in a meaningful segmentation of the signal that closely resembles phone boundaries.
Efficiency 360: Efficient Vision Transformers
Feb 23, 2023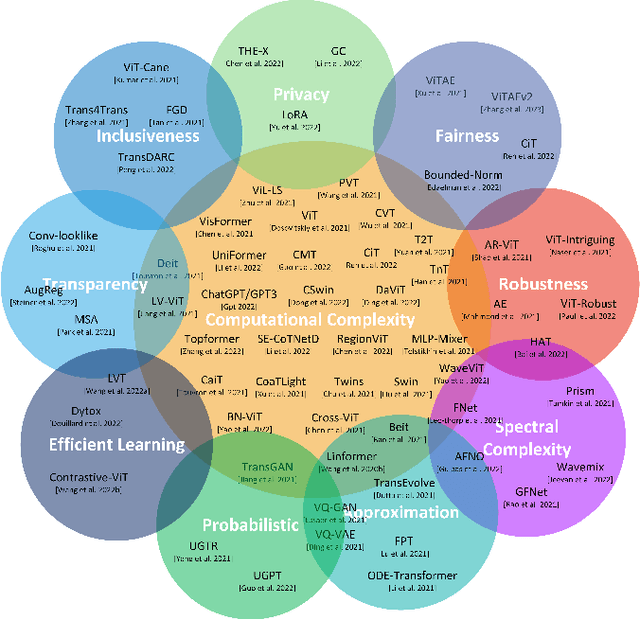
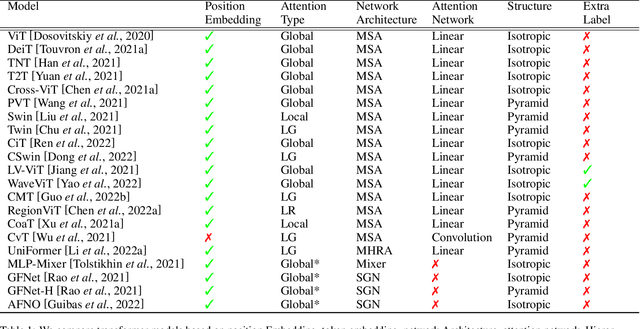
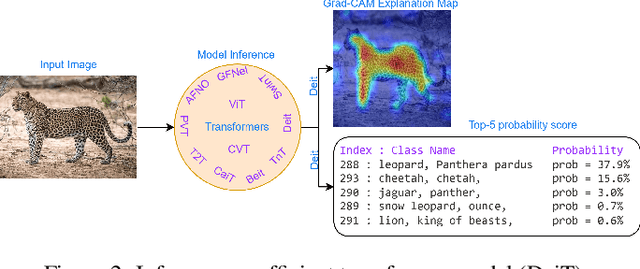
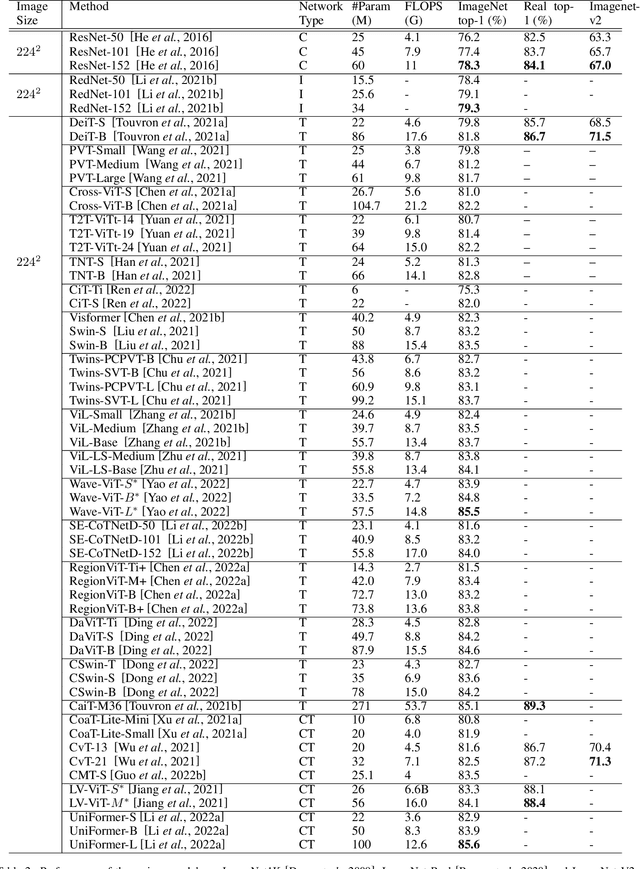
Transformers are widely used for solving tasks in natural language processing, computer vision, speech, and music domains. In this paper, we talk about the efficiency of transformers in terms of memory (the number of parameters), computation cost (number of floating points operations), and performance of models, including accuracy, the robustness of the model, and fair \& bias-free features. We mainly discuss the vision transformer for the image classification task. Our contribution is to introduce an efficient 360 framework, which includes various aspects of the vision transformer, to make it more efficient for industrial applications. By considering those applications, we categorize them into multiple dimensions such as privacy, robustness, transparency, fairness, inclusiveness, continual learning, probabilistic models, approximation, computational complexity, and spectral complexity. We compare various vision transformer models based on their performance, the number of parameters, and the number of floating point operations (FLOPs) on multiple datasets.