 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Leveraging Pretrained Representations with Task-related Keywords for Alzheimer's Disease Detection
Mar 14, 2023

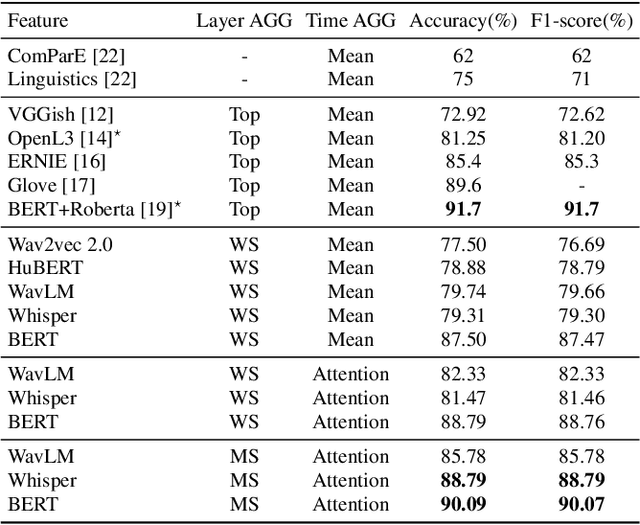
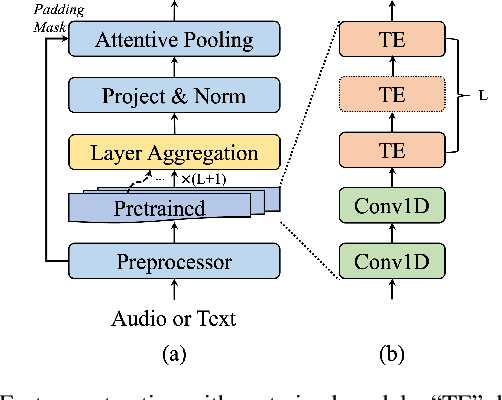
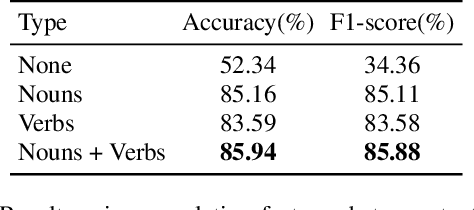
With the global population aging rapidly, Alzheimer's disease (AD) is particularly prominent in older adults, which has an insidious onset and leads to a gradual, irreversible deterioration in cognitive domains (memory, communication, etc.). Speech-based AD detection opens up the possibility of widespread screening and timely disease intervention. Recent advances in pre-trained models motivate AD detection modeling to shift from low-level features to high-level representations. This paper presents several efficient methods to extract better AD-related cues from high-level acoustic and linguistic features. Based on these features, the paper also proposes a novel task-oriented approach by modeling the relationship between the participants' description and the cognitive task. Experiments are carried out on the ADReSS dataset in a binary classification setup, and models are evaluated on the unseen test set. Results and comparison with recent literature demonstrate the efficiency and superior performance of proposed acoustic, linguistic and task-oriented methods. The findings also show the importance of semantic and syntactic information, and feasibility of automation and generalization with the promising audio-only and task-oriented methods for the AD detection task.
Fine-grained Noise Control for Multispeaker Speech Synthesis
Apr 11, 2022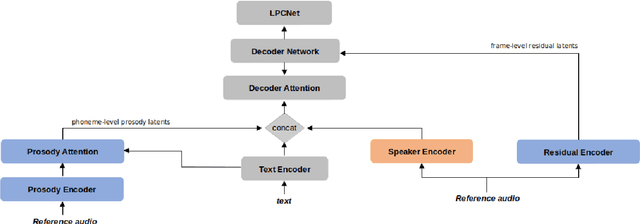
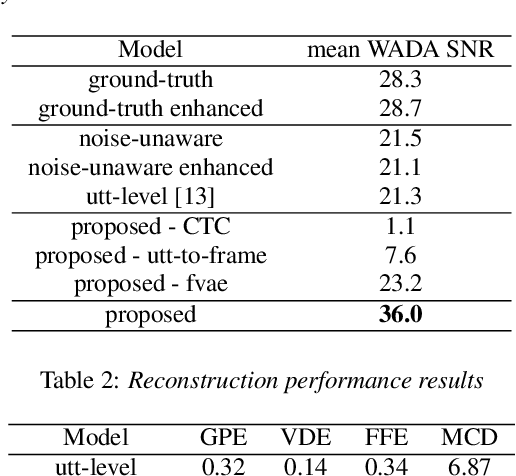
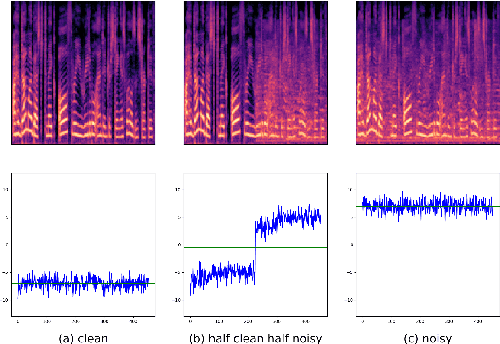
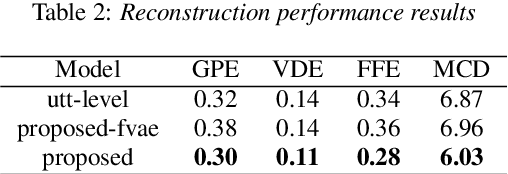
A text-to-speech (TTS) model typically factorizes speech attributes such as content, speaker and prosody into disentangled representations.Recent works aim to additionally model the acoustic conditions explicitly, in order to disentangle the primary speech factors, i.e. linguistic content, prosody and timbre from any residual factors, such as recording conditions and background noise.This paper proposes unsupervised, interpretable and fine-grained noise and prosody modeling. We incorporate adversarial training, representation bottleneck and utterance-to-frame modeling in order to learn frame-level noise representations. To the same end, we perform fine-grained prosody modeling via a Fully Hierarchical Variational AutoEncoder (FVAE) which additionally results in more expressive speech synthesis.
Robust Knowledge Distillation from RNN-T Models With Noisy Training Labels Using Full-Sum Loss
Mar 10, 2023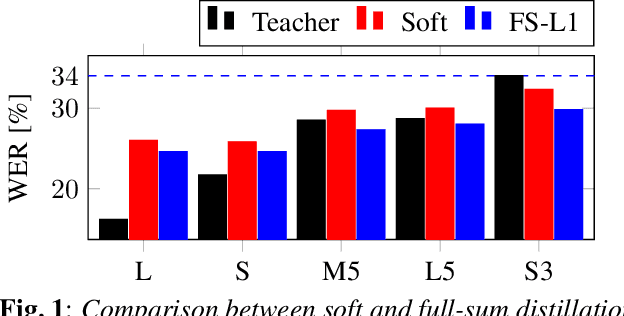
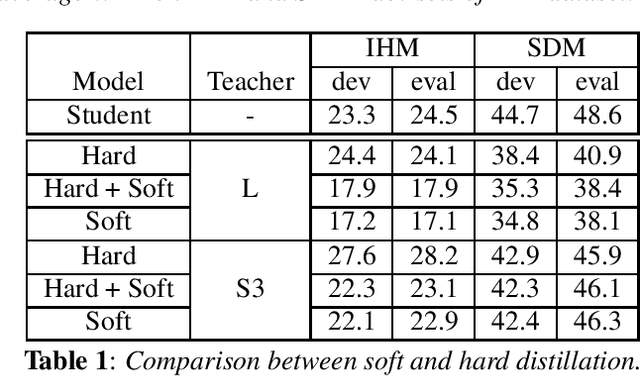
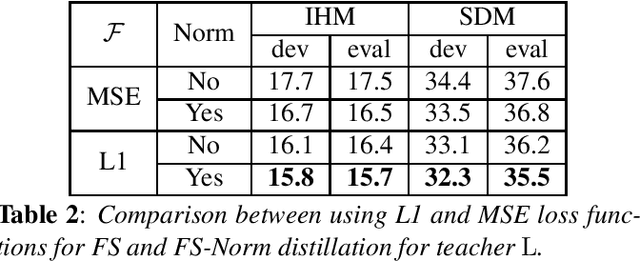
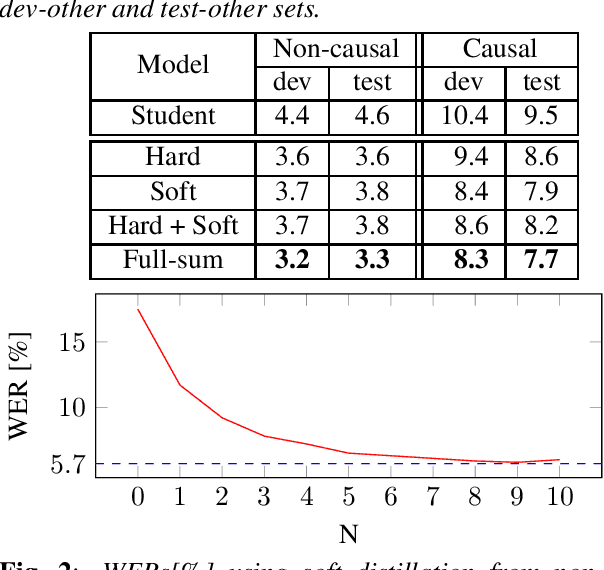
This work studies knowledge distillation (KD) and addresses its constraints for recurrent neural network transducer (RNN-T) models. In hard distillation, a teacher model transcribes large amounts of unlabelled speech to train a student model. Soft distillation is another popular KD method that distills the output logits of the teacher model. Due to the nature of RNN-T alignments, applying soft distillation between RNN-T architectures having different posterior distributions is challenging. In addition, bad teachers having high word-error-rate (WER) reduce the efficacy of KD. We investigate how to effectively distill knowledge from variable quality ASR teachers, which has not been studied before to the best of our knowledge. We show that a sequence-level KD, full-sum distillation, outperforms other distillation methods for RNN-T models, especially for bad teachers. We also propose a variant of full-sum distillation that distills the sequence discriminative knowledge of the teacher leading to further improvement in WER. We conduct experiments on public datasets namely SpeechStew and LibriSpeech, and on in-house production data.
Does human speech follow Benford's Law?
Mar 24, 2022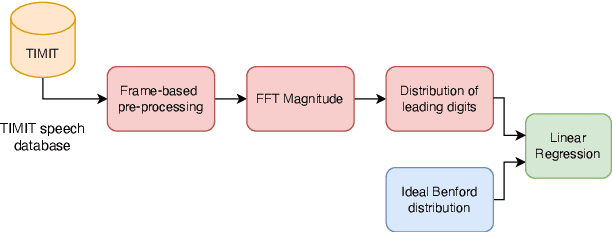
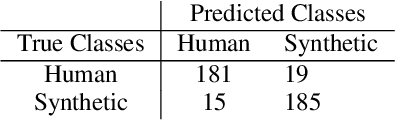
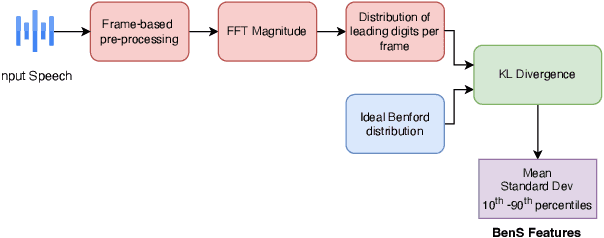
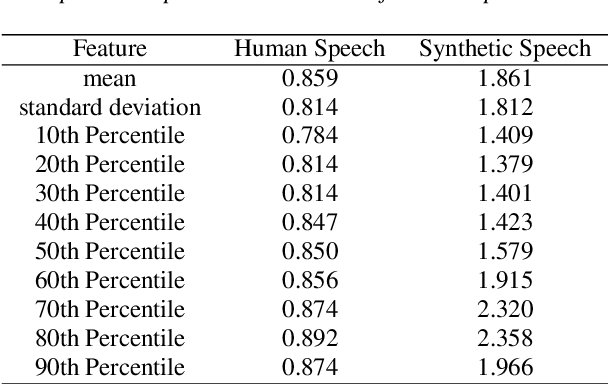
Researchers have observed that the frequencies of leading digits in many man-made and naturally occurring datasets follow a logarithmic curve, with digits that start with the number 1 accounting for $\sim 30\%$ of all numbers in the dataset and digits that start with the number 9 accounting for $\sim 5\%$ of all numbers in the dataset. This phenomenon, known as Benford's Law, is highly repeatable and appears in lists of numbers from electricity bills, stock prices, tax returns, house prices, death rates, lengths of rivers, and naturally occurring images. In this paper we demonstrate that human speech spectra also follow Benford's Law. We use this observation to motivate a new set of features that can be efficiently extracted from speech and demonstrate that these features can be used to classify between human speech and synthetic speech.
Tackling the Cocktail Fork Problem for Separation and Transcription of Real-World Soundtracks
Dec 14, 2022

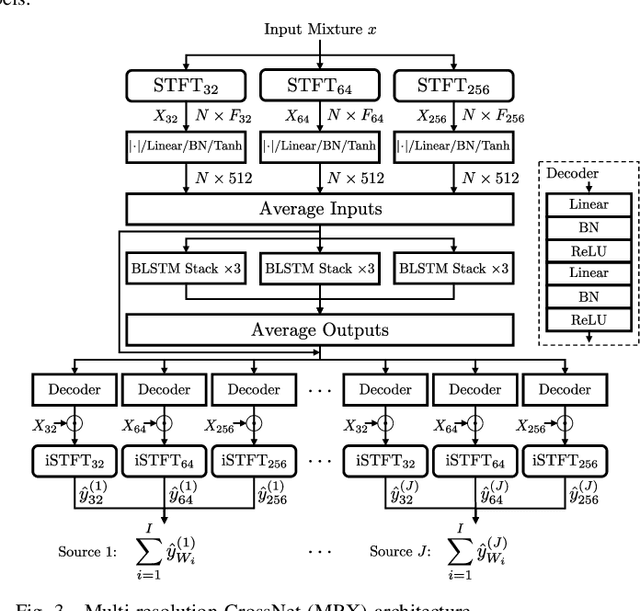
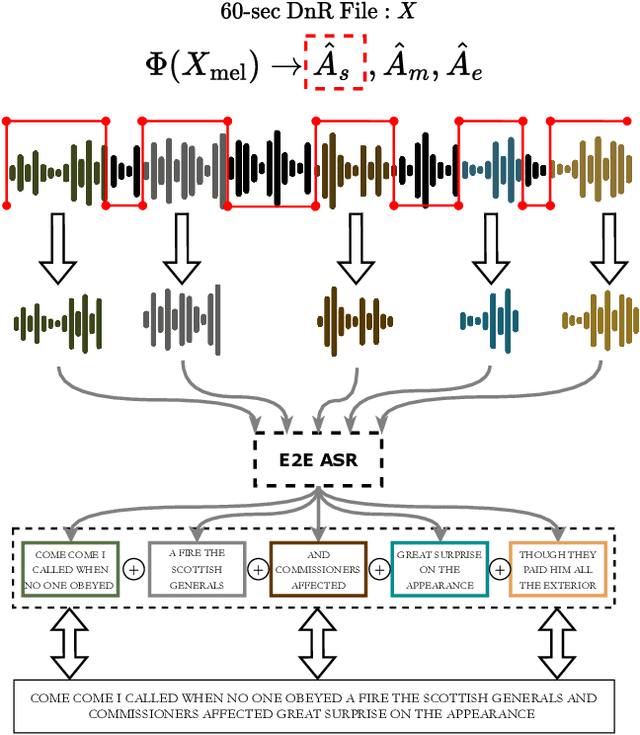
Emulating the human ability to solve the cocktail party problem, i.e., focus on a source of interest in a complex acoustic scene, is a long standing goal of audio source separation research. Much of this research investigates separating speech from noise, speech from speech, musical instruments from each other, or sound events from each other. In this paper, we focus on the cocktail fork problem, which takes a three-pronged approach to source separation by separating an audio mixture such as a movie soundtrack or podcast into the three broad categories of speech, music, and sound effects (SFX - understood to include ambient noise and natural sound events). We benchmark the performance of several deep learning-based source separation models on this task and evaluate them with respect to simple objective measures such as signal-to-distortion ratio (SDR) as well as objective metrics that better correlate with human perception. Furthermore, we thoroughly evaluate how source separation can influence downstream transcription tasks. First, we investigate the task of activity detection on the three sources as a way to both further improve source separation and perform transcription. We formulate the transcription tasks as speech recognition for speech and audio tagging for music and SFX. We observe that, while the use of source separation estimates improves transcription performance in comparison to the original soundtrack, performance is still sub-optimal due to artifacts introduced by the separation process. Therefore, we thoroughly investigate how remixing of the three separated source stems at various relative levels can reduce artifacts and consequently improve the transcription performance. We find that remixing music and SFX interferences at a target SNR of 17.5 dB reduces speech recognition word error rate, and similar impact from remixing is observed for tagging music and SFX content.
SDS-200: A Swiss German Speech to Standard German Text Corpus
May 19, 2022
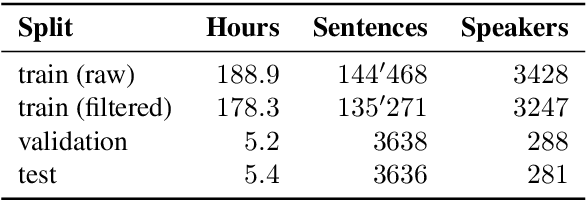
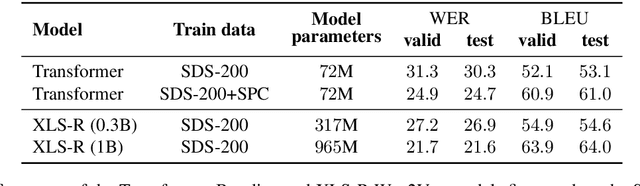
We present SDS-200, a corpus of Swiss German dialectal speech with Standard German text translations, annotated with dialect, age, and gender information of the speakers. The dataset allows for training speech translation, dialect recognition, and speech synthesis systems, among others. The data was collected using a web recording tool that is open to the public. Each participant was given a text in Standard German and asked to translate it to their Swiss German dialect before recording it. To increase the corpus quality, recordings were validated by other participants. The data consists of 200 hours of speech by around 4000 different speakers and covers a large part of the Swiss-German dialect landscape. We release SDS-200 alongside a baseline speech translation model, which achieves a word error rate (WER) of 30.3 and a BLEU score of 53.1 on the SDS-200 test set. Furthermore, we use SDS-200 to fine-tune a pre-trained XLS-R model, achieving 21.6 WER and 64.0 BLEU.
Multichannel Speech Separation with Narrow-band Conformer
Apr 09, 2022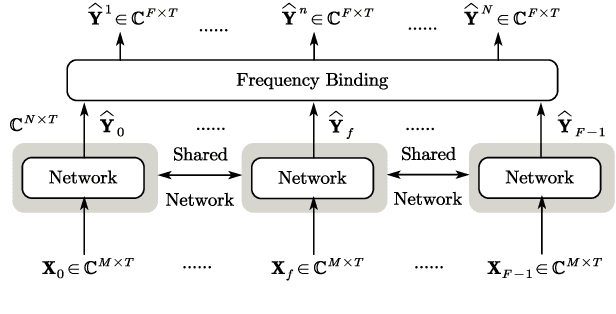
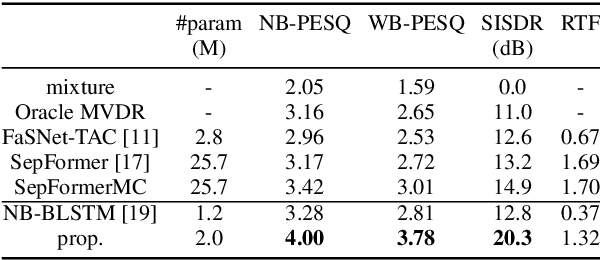
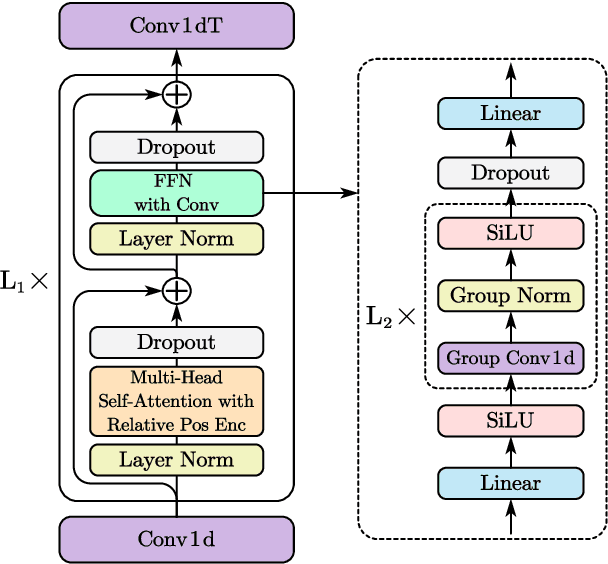
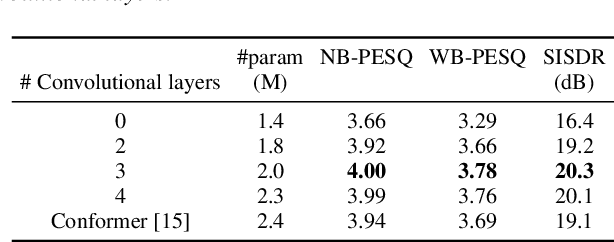
This work proposes a multichannel speech separation method with narrow-band Conformer (named NBC). The network is trained to learn to automatically exploit narrow-band speech separation information, such as spatial vector clustering of multiple speakers. Specifically, in the short-time Fourier transform (STFT) domain, the network processes each frequency independently, and is shared by all frequencies. For one frequency, the network inputs the STFT coefficients of multichannel mixture signals, and predicts the STFT coefficients of separated speech signals. Clustering of spatial vectors shares a similar principle with the self-attention mechanism in the sense of computing the similarity of vectors and then aggregating similar vectors. Therefore, Conformer would be especially suitable for the present problem. Experiments show that the proposed narrow-band Conformer achieves better speech separation performance than other state-of-the-art methods by a large margin.
Benchmarking Generative Latent Variable Models for Speech
Apr 05, 2022
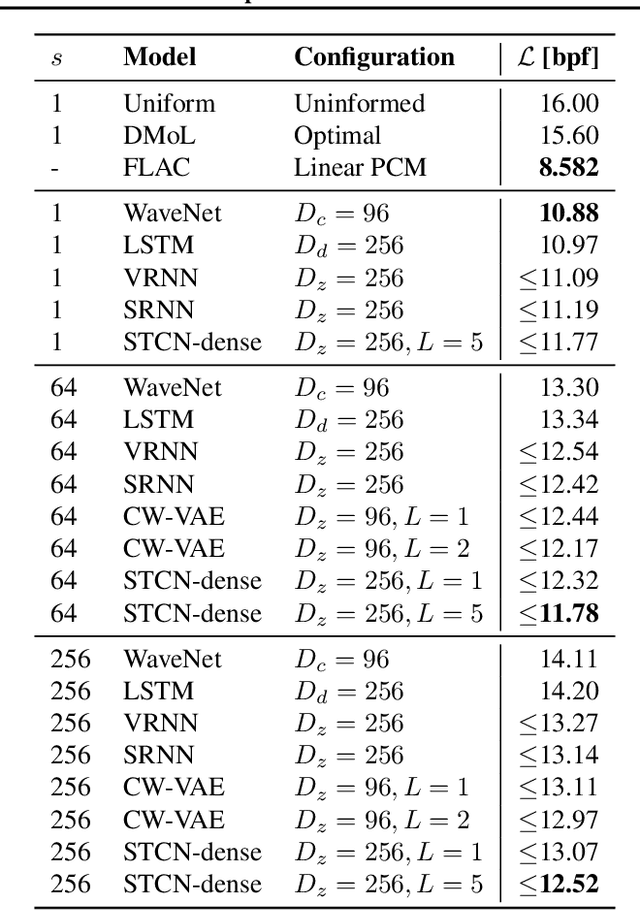
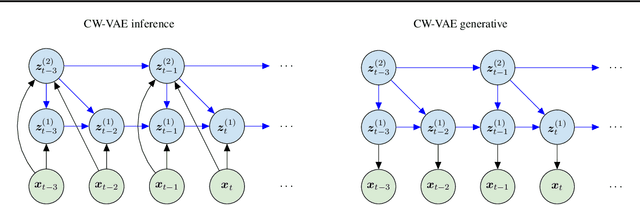
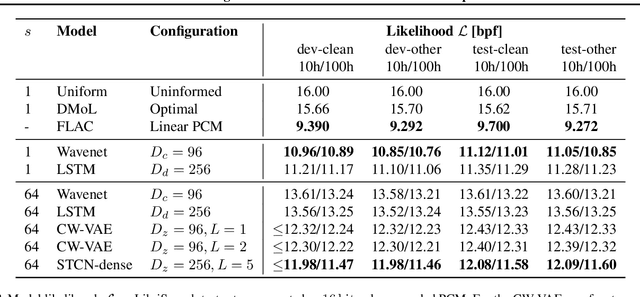
Stochastic latent variable models (LVMs) achieve state-of-the-art performance on natural image generation but are still inferior to deterministic models on speech. In this paper, we develop a speech benchmark of popular temporal LVMs and compare them against state-of-the-art deterministic models. We report the likelihood, which is a much used metric in the image domain, but rarely, or incomparably, reported for speech models. To assess the quality of the learned representations, we also compare their usefulness for phoneme recognition. Finally, we adapt the Clockwork VAE, a state-of-the-art temporal LVM for video generation, to the speech domain. Despite being autoregressive only in latent space, we find that the Clockwork VAE can outperform previous LVMs and reduce the gap to deterministic models by using a hierarchy of latent variables.
NeuralEcho: A Self-Attentive Recurrent Neural Network For Unified Acoustic Echo Suppression And Speech Enhancement
May 20, 2022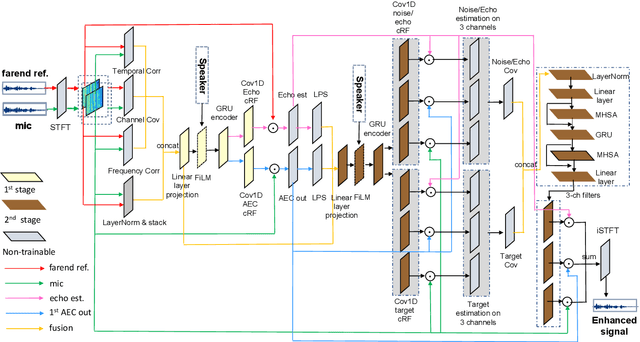
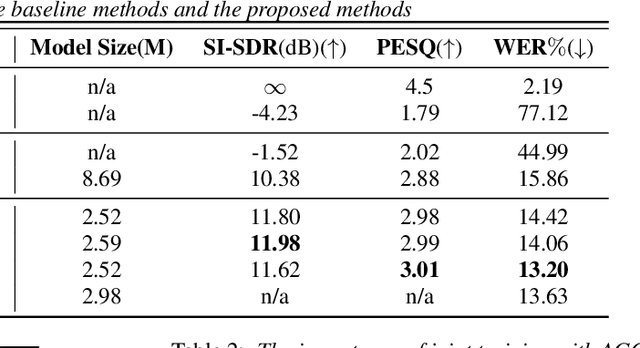
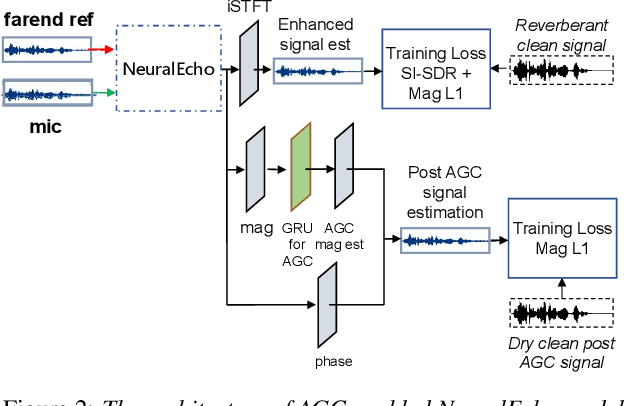

Acoustic echo cancellation (AEC) plays an important role in the full-duplex speech communication as well as the front-end speech enhancement for recognition in the conditions when the loudspeaker plays back. In this paper, we present an all-deep-learning framework that implicitly estimates the second order statistics of echo/noise and target speech, and jointly solves echo and noise suppression through an attention based recurrent neural network. The proposed model outperforms the state-of-the-art joint echo cancellation and speech enhancement method F-T-LSTM in terms of objective speech quality metrics, speech recognition accuracy and model complexity. We show that this model can work with speaker embedding for better target speech enhancement and furthermore develop a branch for automatic gain control (AGC) task to form an all-in-one front-end speech enhancement system.
Learning to Dub Movies via Hierarchical Prosody Models
Dec 08, 2022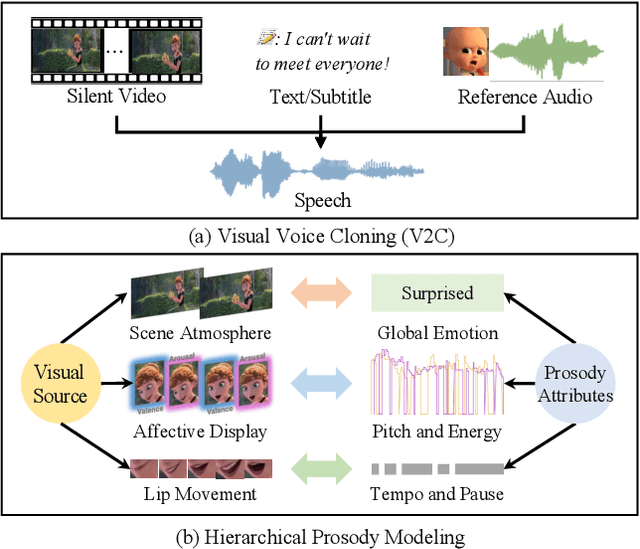
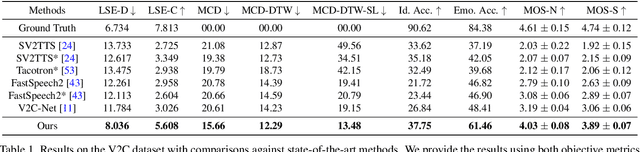
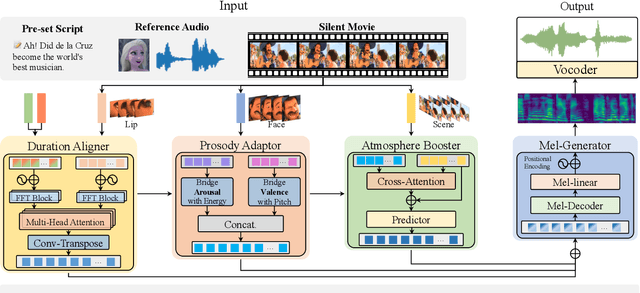
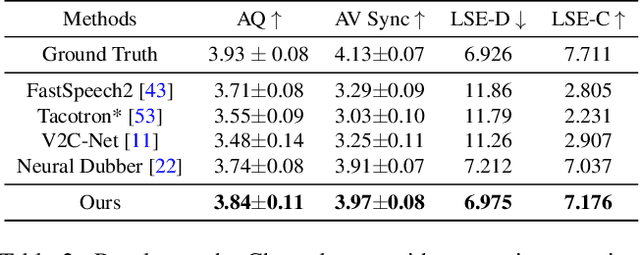
Given a piece of text, a video clip and a reference audio, the movie dubbing (also known as visual voice clone V2C) task aims to generate speeches that match the speaker's emotion presented in the video using the desired speaker voice as reference. V2C is more challenging than conventional text-to-speech tasks as it additionally requires the generated speech to exactly match the varying emotions and speaking speed presented in the video. Unlike previous works, we propose a novel movie dubbing architecture to tackle these problems via hierarchical prosody modelling, which bridges the visual information to corresponding speech prosody from three aspects: lip, face, and scene. Specifically, we align lip movement to the speech duration, and convey facial expression to speech energy and pitch via attention mechanism based on valence and arousal representations inspired by recent psychology findings. Moreover, we design an emotion booster to capture the atmosphere from global video scenes. All these embeddings together are used to generate mel-spectrogram and then convert to speech waves via existing vocoder. Extensive experimental results on the Chem and V2C benchmark datasets demonstrate the favorable performance of the proposed method. The source code and trained models will be released to the public.