 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
How to Leverage DNN-based speech enhancement for multi-channel speaker verification?
Oct 17, 2022
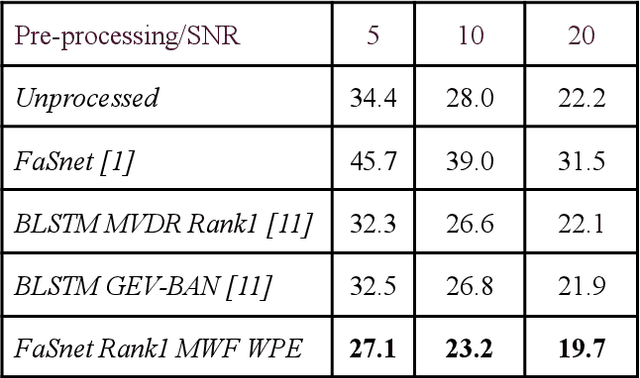
Speaker verification (SV) suffers from unsatisfactory performance in far-field scenarios due to environmental noise andthe adverse impact of room reverberation. This work presents a benchmark of multichannel speech enhancement for far-fieldspeaker verification. One approach is a deep neural network-based, and the other is a combination of deep neural network andsignal processing. We integrated a DNN architecture with signal processing techniques to carry out various experiments. Ourapproach is compared to the existing state-of-the-art approaches. We examine the importance of enrollment in pre-processing,which has been largely overlooked in previous studies. Experimental evaluation shows that pre-processing can improve the SVperformance as long as the enrollment files are processed similarly to the test data and that test and enrollment occur within similarSNR ranges. Considerable improvement is obtained on the generated and all the noise conditions of the VOiCES dataset.
Contrastive Representation Learning for Acoustic Parameter Estimation
Feb 22, 2023


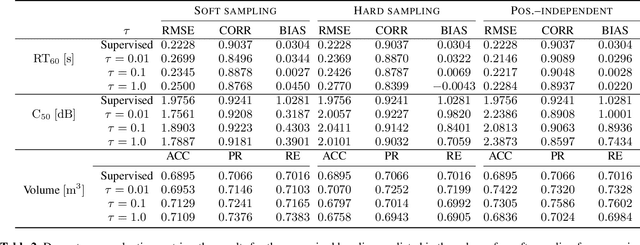
A study is presented in which a contrastive learning approach is used to extract low-dimensional representations of the acoustic environment from single-channel, reverberant speech signals. Convolution of room impulse responses (RIRs) with anechoic source signals is leveraged as a data augmentation technique that offers considerable flexibility in the design of the upstream task. We evaluate the embeddings across three different downstream tasks, which include the regression of acoustic parameters reverberation time RT60 and clarity index C50, and the classification into small and large rooms. We demonstrate that the learned representations generalize well to unseen data and achieve similar performance compared to a fully supervised baseline.
A Study of Modeling Rising Intonation in Cantonese Neural Speech Synthesis
Aug 03, 2022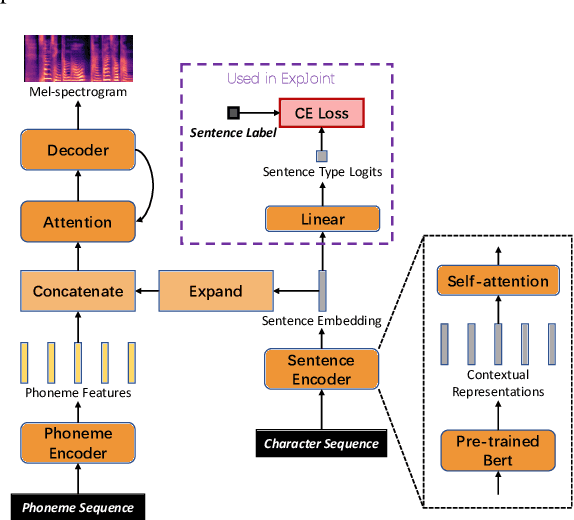
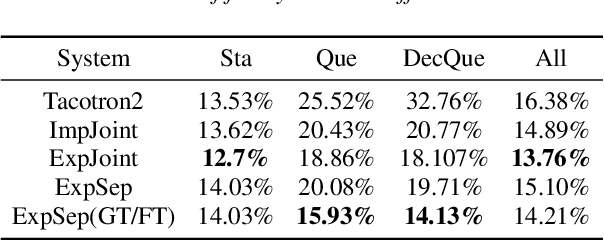
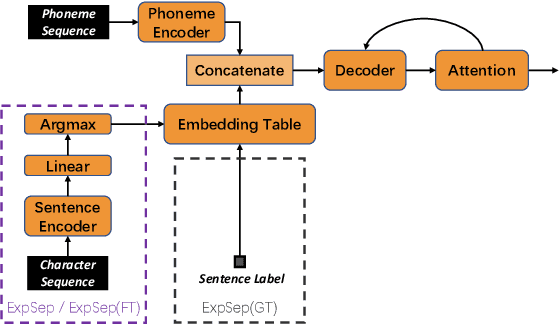

In human speech, the attitude of a speaker cannot be fully expressed only by the textual content. It has to come along with the intonation. Declarative questions are commonly used in daily Cantonese conversations, and they are usually uttered with rising intonation. Vanilla neural text-to-speech (TTS) systems are not capable of synthesizing rising intonation for these sentences due to the loss of semantic information. Though it has become more common to complement the systems with extra language models, their performance in modeling rising intonation is not well studied. In this paper, we propose to complement the Cantonese TTS model with a BERT-based statement/question classifier. We design different training strategies and compare their performance. We conduct our experiments on a Cantonese corpus named CanTTS. Empirical results show that the separate training approach obtains the best generalization performance and feasibility.
Self-supervised speech unit discovery from articulatory and acoustic features using VQ-VAE
Jun 17, 2022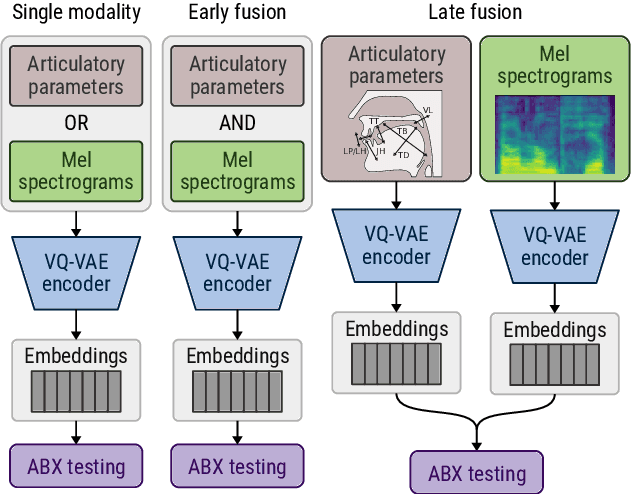
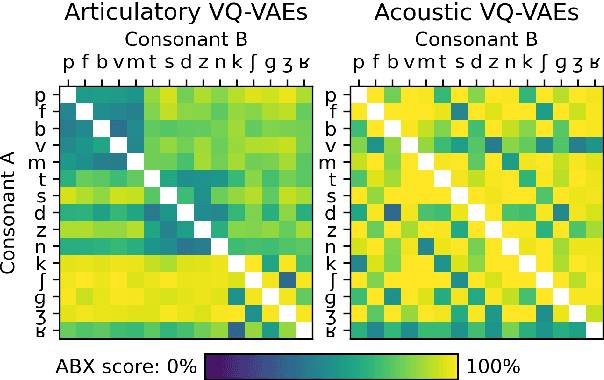
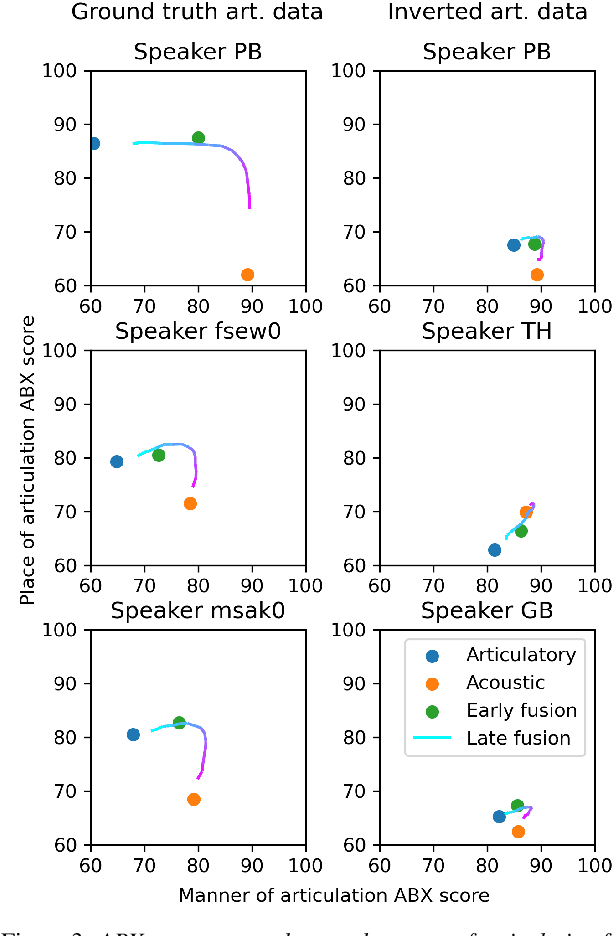
The human perception system is often assumed to recruit motor knowledge when processing auditory speech inputs. Using articulatory modeling and deep learning, this study examines how this articulatory information can be used for discovering speech units in a self-supervised setting. We used vector-quantized variational autoencoders (VQ-VAE) to learn discrete representations from articulatory and acoustic speech data. In line with the zero-resource paradigm, an ABX test was then used to investigate how the extracted representations encode phonetically relevant properties. Experiments were conducted on three different corpora in English and French. We found that articulatory information rather organises the latent representations in terms of place of articulation whereas the speech acoustics mainly structure the latent space in terms of manner of articulation. We show that an optimal fusion of the two modalities can lead to a joint representation of these phonetic dimensions more accurate than each modality considered individually. Since articulatory information is usually not available in a practical situation, we finally investigate the benefit it provides when inferred from the speech acoustics in a self-supervised manner.
Speech Emotion: Investigating Model Representations, Multi-Task Learning and Knowledge Distillation
Jul 02, 2022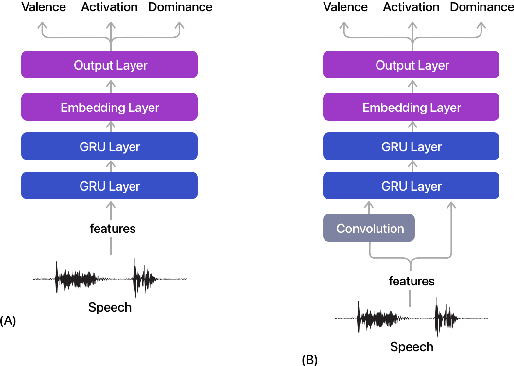
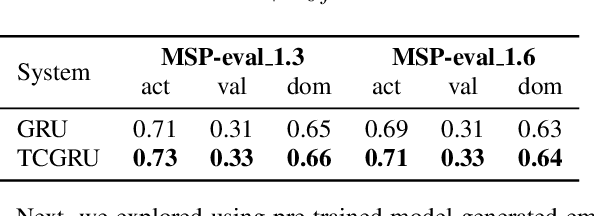
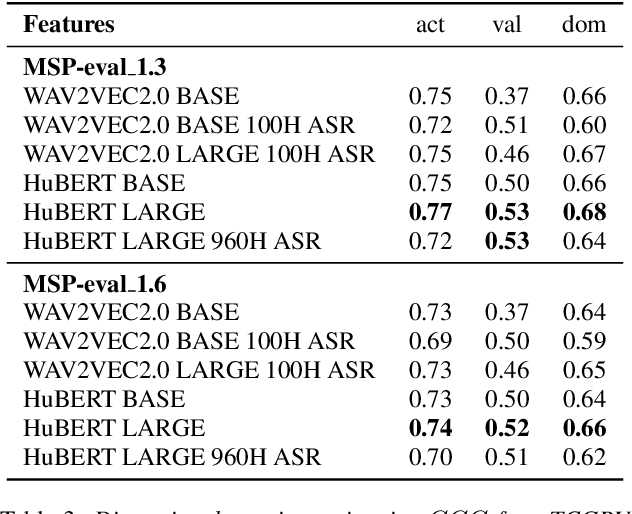
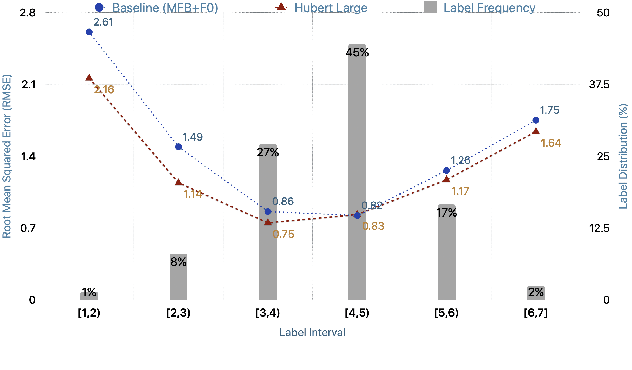
Estimating dimensional emotions, such as activation, valence and dominance, from acoustic speech signals has been widely explored over the past few years. While accurate estimation of activation and dominance from speech seem to be possible, the same for valence remains challenging. Previous research has shown that the use of lexical information can improve valence estimation performance. Lexical information can be obtained from pre-trained acoustic models, where the learned representations can improve valence estimation from speech. We investigate the use of pre-trained model representations to improve valence estimation from acoustic speech signal. We also explore fusion of representations to improve emotion estimation across all three emotion dimensions: activation, valence and dominance. Additionally, we investigate if representations from pre-trained models can be distilled into models trained with low-level features, resulting in models with a less number of parameters. We show that fusion of pre-trained model embeddings result in a 79% relative improvement in concordance correlation coefficient CCC on valence estimation compared to standard acoustic feature baseline (mel-filterbank energies), while distillation from pre-trained model embeddings to lower-dimensional representations yielded a relative 12% improvement. Such performance gains were observed over two evaluation sets, indicating that our proposed architecture generalizes across those evaluation sets. We report new state-of-the-art "text-free" acoustic-only dimensional emotion estimation $CCC$ values on two MSP-Podcast evaluation sets.
A Novel Speech-Driven Lip-Sync Model with CNN and LSTM
May 02, 2022

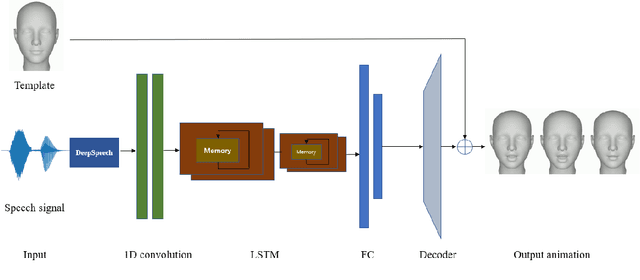
Generating synchronized and natural lip movement with speech is one of the most important tasks in creating realistic virtual characters. In this paper, we present a combined deep neural network of one-dimensional convolutions and LSTM to generate vertex displacement of a 3D template face model from variable-length speech input. The motion of the lower part of the face, which is represented by the vertex movement of 3D lip shapes, is consistent with the input speech. In order to enhance the robustness of the network to different sound signals, we adapt a trained speech recognition model to extract speech feature, and a velocity loss term is adopted to reduce the jitter of generated facial animation. We recorded a series of videos of a Chinese adult speaking Mandarin and created a new speech-animation dataset to compensate the lack of such public data. Qualitative and quantitative evaluations indicate that our model is able to generate smooth and natural lip movements synchronized with speech.
FusionFormer: Fusing Operations in Transformer for Efficient Streaming Speech Recognition
Oct 31, 2022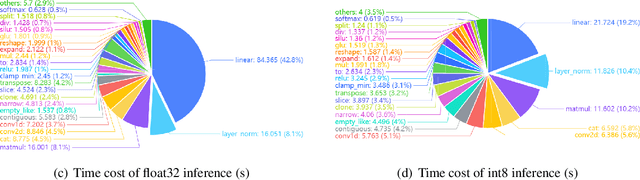

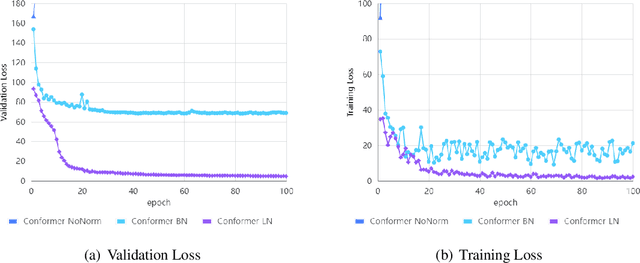
The recently proposed Conformer architecture which combines convolution with attention to capture both local and global dependencies has become the \textit{de facto} backbone model for Automatic Speech Recognition~(ASR). Inherited from the Natural Language Processing (NLP) tasks, the architecture takes Layer Normalization~(LN) as a default normalization technique. However, through a series of systematic studies, we find that LN might take 10\% of the inference time despite that it only contributes to 0.1\% of the FLOPs. This motivates us to replace LN with other normalization techniques, e.g., Batch Normalization~(BN), to speed up inference with the help of operator fusion methods and the avoidance of calculating the mean and variance statistics during inference. After examining several plain attempts which directly remove all LN layers or replace them with BN in the same place, we find that the divergence issue is mainly caused by the unstable layer output. We therefore propose to append a BN layer to each linear or convolution layer where stabilized training results are observed. We also propose to simplify the activations in Conformer, such as Swish and GLU, by replacing them with ReLU. All these exchanged modules can be fused into the weights of the adjacent linear/convolution layers and hence have zero inference cost. Therefore, we name it FusionFormer. Our experiments indicate that FusionFormer is as effective as the LN-based Conformer and is about 10\% faster.
Hybrid-SD ($\text{H}_{\text{SD}}$) : A new hybrid evaluation metric for automatic speech recognition tasks
Nov 03, 2022

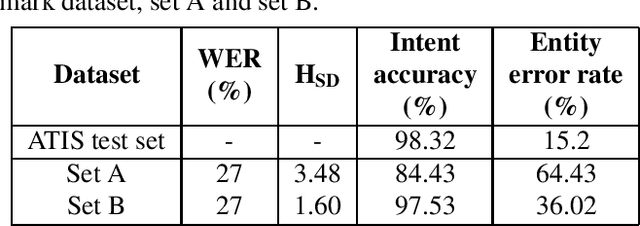

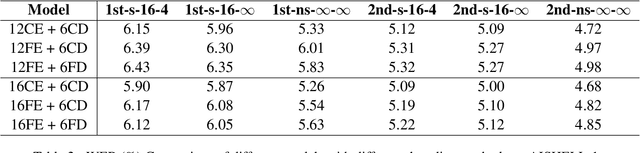
Many studies have examined the shortcomings of word error rate (WER) as an evaluation metric for automatic speech recognition (ASR) systems, particularly when used for spoken language understanding tasks such as intent recognition and dialogue systems. In this paper, we propose Hybrid-SD ($\text{H}_{\text{SD}}$), a new hybrid evaluation metric for ASR systems that takes into account both semantic correctness and error rate. To generate sentence dissimilarity scores (SD), we built a fast and lightweight SNanoBERT model using distillation techniques. Our experiments show that the SNanoBERT model is 25.9x smaller and 38.8x faster than SRoBERTa while achieving comparable results on well-known benchmarks. Hence, making it suitable for deploying with ASR models on edge devices. We also show that $\text{H}_{\text{SD}}$ correlates more strongly with downstream tasks such as intent recognition and named-entity recognition (NER).
Leveraging Speaker Embeddings with Adversarial Multi-task Learning for Age Group Classification
Jan 22, 2023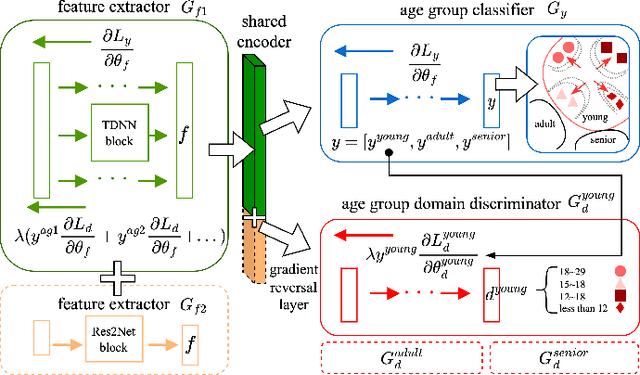
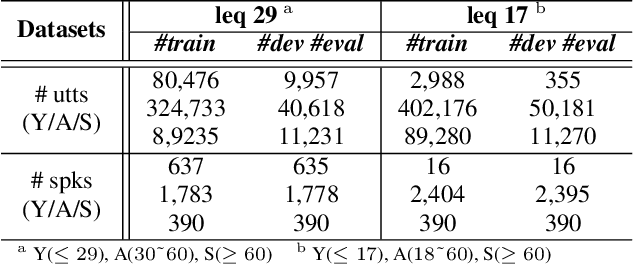
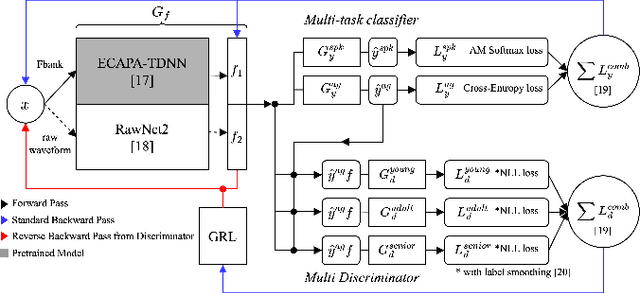
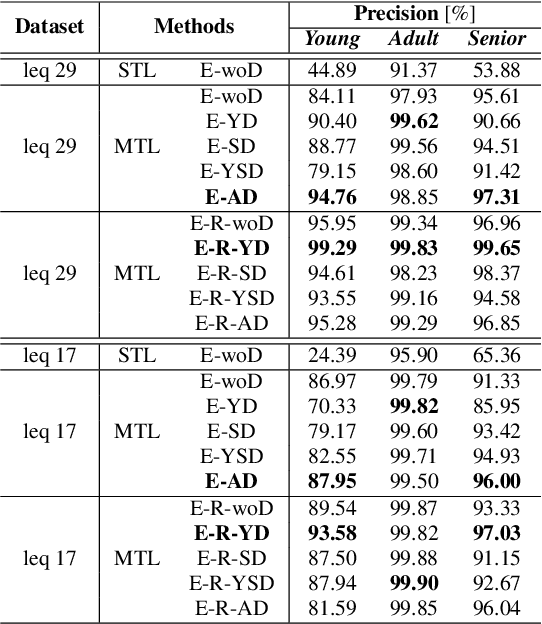
Recently, researchers have utilized neural network-based speaker embedding techniques in speaker-recognition tasks to identify speakers accurately. However, speaker-discriminative embeddings do not always represent speech features such as age group well. In an embedding model that has been highly trained to capture speaker traits, the task of age group classification is closer to speech information leakage. Hence, to improve age group classification performance, we consider the use of speaker-discriminative embeddings derived from adversarial multi-task learning to align features and reduce the domain discrepancy in age subgroups. In addition, we investigated different types of speaker embeddings to learn and generalize the domain-invariant representations for age groups. Experimental results on the VoxCeleb Enrichment dataset verify the effectiveness of our proposed adaptive adversarial network in multi-objective scenarios and leveraging speaker embeddings for the domain adaptation task.
Accurate Emotion Strength Assessment for Seen and Unseen Speech Based on Data-Driven Deep Learning
Jun 15, 2022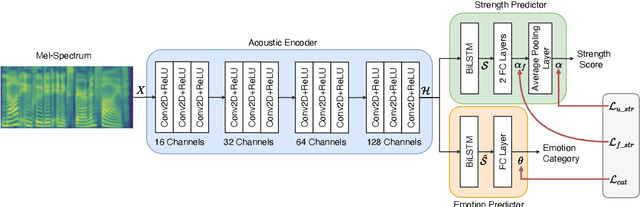
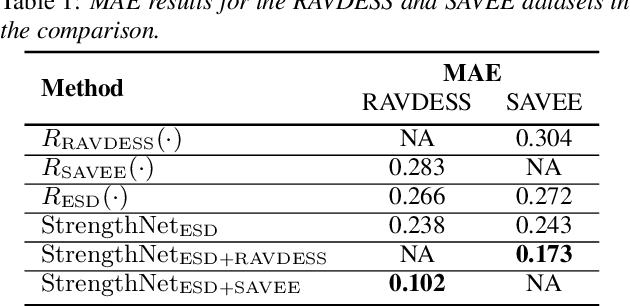
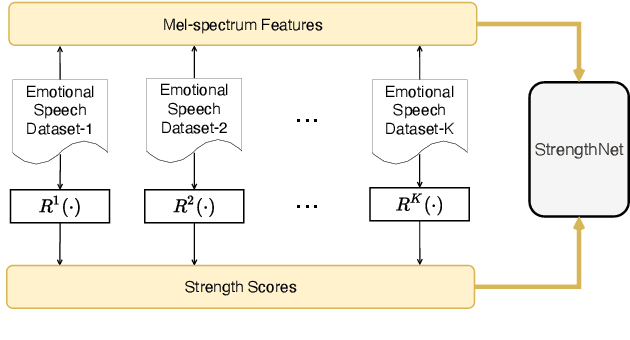
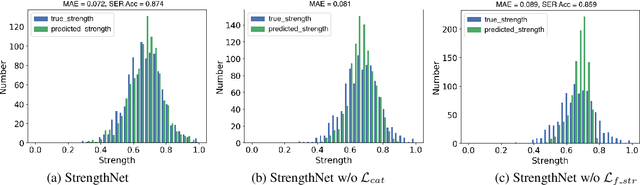
Emotion classification of speech and assessment of the emotion strength are required in applications such as emotional text-to-speech and voice conversion. The emotion attribute ranking function based on Support Vector Machine (SVM) was proposed to predict emotion strength for emotional speech corpus. However, the trained ranking function doesn't generalize to new domains, which limits the scope of applications, especially for out-of-domain or unseen speech. In this paper, we propose a data-driven deep learning model, i.e. StrengthNet, to improve the generalization of emotion strength assessment for seen and unseen speech. This is achieved by the fusion of emotional data from various domains. We follow a multi-task learning network architecture that includes an acoustic encoder, a strength predictor, and an auxiliary emotion predictor. Experiments show that the predicted emotion strength of the proposed StrengthNet is highly correlated with ground truth scores for both seen and unseen speech. We release the source codes at: https://github.com/ttslr/StrengthNet.