 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Layer-Wise Analysis of Self-Supervised Acoustic Word Embeddings: A Study on Speech Emotion Recognition
Feb 04, 2024
The efficacy of self-supervised speech models has been validated, yet the optimal utilization of their representations remains challenging across diverse tasks. In this study, we delve into Acoustic Word Embeddings (AWEs), a fixed-length feature derived from continuous representations, to explore their advantages in specific tasks. AWEs have previously shown utility in capturing acoustic discriminability. In light of this, we propose measuring layer-wise similarity between AWEs and word embeddings, aiming to further investigate the inherent context within AWEs. Moreover, we evaluate the contribution of AWEs, in comparison to other types of speech features, in the context of Speech Emotion Recognition (SER). Through a comparative experiment and a layer-wise accuracy analysis on two distinct corpora, IEMOCAP and ESD, we explore differences between AWEs and raw self-supervised representations, as well as the proper utilization of AWEs alone and in combination with word embeddings. Our findings underscore the acoustic context conveyed by AWEs and showcase the highly competitive SER accuracies by appropriately employing AWEs.
Real-time Stereo Speech Enhancement with Spatial-Cue Preservation based on Dual-Path Structure
Feb 01, 2024We introduce a real-time, multichannel speech enhancement algorithm which maintains the spatial cues of stereo recordings including two speech sources. Recognizing that each source has unique spatial information, our method utilizes a dual-path structure, ensuring the spatial cues remain unaffected during enhancement by applying source-specific common-band gain. This method also seamlessly integrates pretrained monaural speech enhancement, eliminating the need for retraining on stereo inputs. Source separation from stereo mixtures is achieved via spatial beamforming, with the steering vector for each source being adaptively updated using post-enhancement output signal. This ensures accurate tracking of the spatial information. The final stereo output is derived by merging the spatial images of the enhanced sources, with its efficacy not heavily reliant on the separation performance of the beamforming. The algorithm runs in real-time on 10-ms frames with a 40 ms of look-ahead. Evaluations reveal its effectiveness in enhancing speech and preserving spatial cues in both fully and sparsely overlapped mixtures.
Automatic Detection of Depression in Speech Using Ensemble Convolutional Neural Networks
Feb 05, 2024This paper proposes a speech-based method for automatic depression classification. The system is based on ensemble learning for Convolutional Neural Networks (CNNs) and is evaluated using the data and the experimental protocol provided in the Depression Classification Sub-Challenge (DCC) at the 2016 Audio-Visual Emotion Challenge (AVEC-2016). In the pre-processing phase, speech files are represented as a sequence of log-spectrograms and randomly sampled to balance positive and negative samples. For the classification task itself, first, a more suitable architecture for this task, based on One-Dimensional Convolutional Neural Networks, is built. Secondly, several of these CNN-based models are trained with different initializations and then the corresponding individual predictions are fused by using an Ensemble Averaging algorithm and combined per speaker to get an appropriate final decision. The proposed ensemble system achieves satisfactory results on the DCC at the AVEC-2016 in comparison with a reference system based on Support Vector Machines and hand-crafted features, with a CNN+LSTM-based system called DepAudionet, and with the case of a single CNN-based classifier.
Low-Resource Cross-Domain Singing Voice Synthesis via Reduced Self-Supervised Speech Representations
Feb 02, 2024In this paper, we propose a singing voice synthesis model, Karaoker-SSL, that is trained only on text and speech data as a typical multi-speaker acoustic model. It is a low-resource pipeline that does not utilize any singing data end-to-end, since its vocoder is also trained on speech data. Karaoker-SSL is conditioned by self-supervised speech representations in an unsupervised manner. We preprocess these representations by selecting only a subset of their task-correlated dimensions. The conditioning module is indirectly guided to capture style information during training by multi-tasking. This is achieved with a Conformer-based module, which predicts the pitch from the acoustic model's output. Thus, Karaoker-SSL allows singing voice synthesis without reliance on hand-crafted and domain-specific features. There are also no requirements for text alignments or lyrics timestamps. To refine the voice quality, we employ a U-Net discriminator that is conditioned on the target speaker and follows a Diffusion GAN training scheme.
Scaling Up Adaptive Filter Optimizers
Mar 01, 2024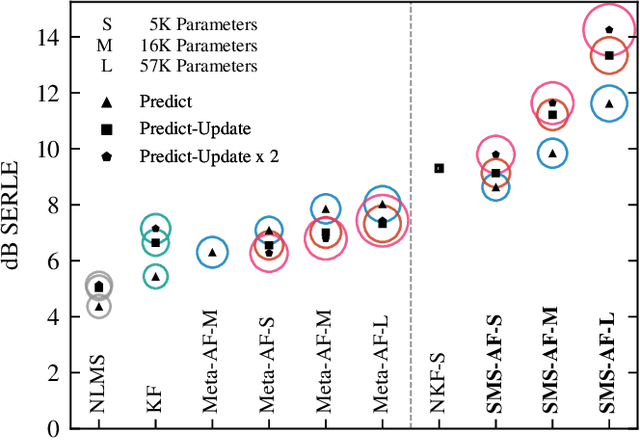
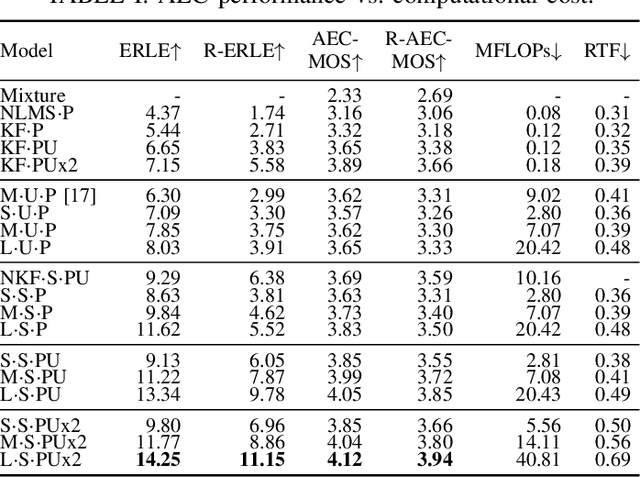
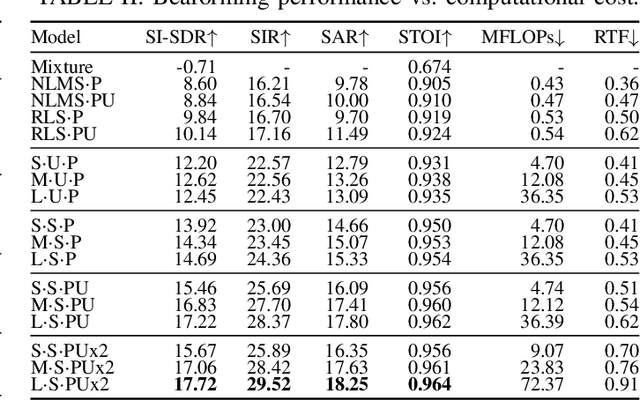
We introduce a new online adaptive filtering method called supervised multi-step adaptive filters (SMS-AF). Our method uses neural networks to control or optimize linear multi-delay or multi-channel frequency-domain filters and can flexibly scale-up performance at the cost of increased compute -- a property rarely addressed in the AF literature, but critical for many applications. To do so, we extend recent work with a set of improvements including feature pruning, a supervised loss, and multiple optimization steps per time-frame. These improvements work in a cohesive manner to unlock scaling. Furthermore, we show how our method relates to Kalman filtering and meta-adaptive filtering, making it seamlessly applicable to a diverse set of AF tasks. We evaluate our method on acoustic echo cancellation (AEC) and multi-channel speech enhancement tasks and compare against several baselines on standard synthetic and real-world datasets. Results show our method performance scales with inference cost and model capacity, yields multi-dB performance gains for both tasks, and is real-time capable on a single CPU core.
What Do Self-Supervised Speech and Speaker Models Learn? New Findings From a Cross Model Layer-Wise Analysis
Jan 31, 2024Self-supervised learning (SSL) has attracted increased attention for learning meaningful speech representations. Speech SSL models, such as WavLM, employ masked prediction training to encode general-purpose representations. In contrast, speaker SSL models, exemplified by DINO-based models, adopt utterance-level training objectives primarily for speaker representation. Understanding how these models represent information is essential for refining model efficiency and effectiveness. Unlike the various analyses of speech SSL, there has been limited investigation into what information speaker SSL captures and how its representation differs from speech SSL or other fully-supervised speaker models. This paper addresses these fundamental questions. We explore the capacity to capture various speech properties by applying SUPERB evaluation probing tasks to speech and speaker SSL models. We also examine which layers are predominantly utilized for each task to identify differences in how speech is represented. Furthermore, we conduct direct comparisons to measure the similarities between layers within and across models. Our analysis unveils that 1) the capacity to represent content information is somewhat unrelated to enhanced speaker representation, 2) specific layers of speech SSL models would be partly specialized in capturing linguistic information, and 3) speaker SSL models tend to disregard linguistic information but exhibit more sophisticated speaker representation.
Speech Swin-Transformer: Exploring a Hierarchical Transformer with Shifted Windows for Speech Emotion Recognition
Jan 19, 2024Swin-Transformer has demonstrated remarkable success in computer vision by leveraging its hierarchical feature representation based on Transformer. In speech signals, emotional information is distributed across different scales of speech features, e.\,g., word, phrase, and utterance. Drawing above inspiration, this paper presents a hierarchical speech Transformer with shifted windows to aggregate multi-scale emotion features for speech emotion recognition (SER), called Speech Swin-Transformer. Specifically, we first divide the speech spectrogram into segment-level patches in the time domain, composed of multiple frame patches. These segment-level patches are then encoded using a stack of Swin blocks, in which a local window Transformer is utilized to explore local inter-frame emotional information across frame patches of each segment patch. After that, we also design a shifted window Transformer to compensate for patch correlations near the boundaries of segment patches. Finally, we employ a patch merging operation to aggregate segment-level emotional features for hierarchical speech representation by expanding the receptive field of Transformer from frame-level to segment-level. Experimental results demonstrate that our proposed Speech Swin-Transformer outperforms the state-of-the-art methods.
Predicting positive transfer for improved low-resource speech recognition using acoustic pseudo-tokens
Feb 03, 2024While massively multilingual speech models like wav2vec 2.0 XLSR-128 can be directly fine-tuned for automatic speech recognition (ASR), downstream performance can still be relatively poor on languages that are under-represented in the pre-training data. Continued pre-training on 70-200 hours of untranscribed speech in these languages can help -- but what about languages without that much recorded data? For such cases, we show that supplementing the target language with data from a similar, higher-resource 'donor' language can help. For example, continued pre-training on only 10 hours of low-resource Punjabi supplemented with 60 hours of donor Hindi is almost as good as continued pretraining on 70 hours of Punjabi. By contrast, sourcing data from less similar donors like Bengali does not improve ASR performance. To inform donor language selection, we propose a novel similarity metric based on the sequence distribution of induced acoustic units: the Acoustic Token Distribution Similarity (ATDS). Across a set of typologically different target languages (Punjabi, Galician, Iban, Setswana), we show that the ATDS between the target language and its candidate donors precisely predicts target language ASR performance.
Multi-Modal Emotion Recognition by Text, Speech and Video Using Pretrained Transformers
Feb 11, 2024Due to the complex nature of human emotions and the diversity of emotion representation methods in humans, emotion recognition is a challenging field. In this research, three input modalities, namely text, audio (speech), and video, are employed to generate multimodal feature vectors. For generating features for each of these modalities, pre-trained Transformer models with fine-tuning are utilized. In each modality, a Transformer model is used with transfer learning to extract feature and emotional structure. These features are then fused together, and emotion recognition is performed using a classifier. To select an appropriate fusion method and classifier, various feature-level and decision-level fusion techniques have been experimented with, and ultimately, the best model, which combines feature-level fusion by concatenating feature vectors and classification using a Support Vector Machine on the IEMOCAP multimodal dataset, achieves an accuracy of 75.42%. Keywords: Multimodal Emotion Recognition, IEMOCAP, Self-Supervised Learning, Transfer Learning, Transformer.
STAA-Net: A Sparse and Transferable Adversarial Attack for Speech Emotion Recognition
Feb 02, 2024Speech contains rich information on the emotions of humans, and Speech Emotion Recognition (SER) has been an important topic in the area of human-computer interaction. The robustness of SER models is crucial, particularly in privacy-sensitive and reliability-demanding domains like private healthcare. Recently, the vulnerability of deep neural networks in the audio domain to adversarial attacks has become a popular area of research. However, prior works on adversarial attacks in the audio domain primarily rely on iterative gradient-based techniques, which are time-consuming and prone to overfitting the specific threat model. Furthermore, the exploration of sparse perturbations, which have the potential for better stealthiness, remains limited in the audio domain. To address these challenges, we propose a generator-based attack method to generate sparse and transferable adversarial examples to deceive SER models in an end-to-end and efficient manner. We evaluate our method on two widely-used SER datasets, Database of Elicited Mood in Speech (DEMoS) and Interactive Emotional dyadic MOtion CAPture (IEMOCAP), and demonstrate its ability to generate successful sparse adversarial examples in an efficient manner. Moreover, our generated adversarial examples exhibit model-agnostic transferability, enabling effective adversarial attacks on advanced victim models.