 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
ClearBuds: Wireless Binaural Earbuds for Learning-Based Speech Enhancement
Jun 27, 2022
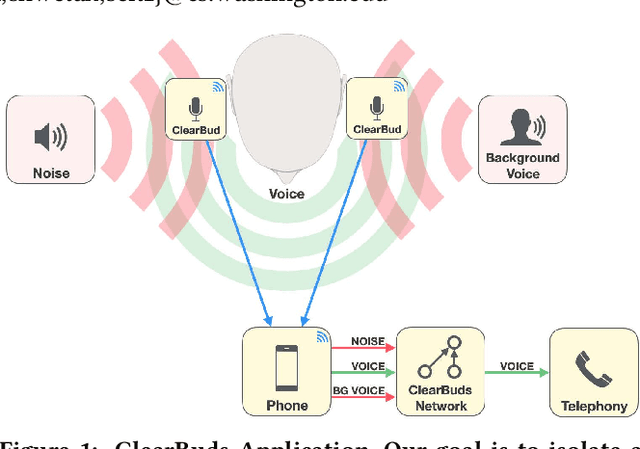

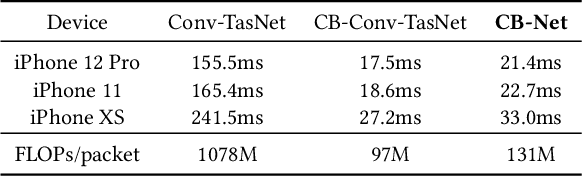
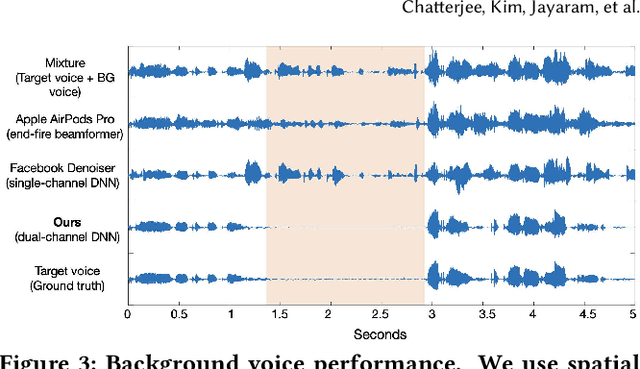
We present ClearBuds, the first hardware and software system that utilizes a neural network to enhance speech streamed from two wireless earbuds. Real-time speech enhancement for wireless earbuds requires high-quality sound separation and background cancellation, operating in real-time and on a mobile phone. Clear-Buds bridges state-of-the-art deep learning for blind audio source separation and in-ear mobile systems by making two key technical contributions: 1) a new wireless earbud design capable of operating as a synchronized, binaural microphone array, and 2) a lightweight dual-channel speech enhancement neural network that runs on a mobile device. Our neural network has a novel cascaded architecture that combines a time-domain conventional neural network with a spectrogram-based frequency masking neural network to reduce the artifacts in the audio output. Results show that our wireless earbuds achieve a synchronization error less than 64 microseconds and our network has a runtime of 21.4 milliseconds on an accompanying mobile phone. In-the-wild evaluation with eight users in previously unseen indoor and outdoor multipath scenarios demonstrates that our neural network generalizes to learn both spatial and acoustic cues to perform noise suppression and background speech removal. In a user-study with 37 participants who spent over 15.4 hours rating 1041 audio samples collected in-the-wild, our system achieves improved mean opinion score and background noise suppression. Project page with demos: https://clearbuds.cs.washington.edu
Blind Acoustic Room Parameter Estimation Using Phase Features
Mar 13, 2023
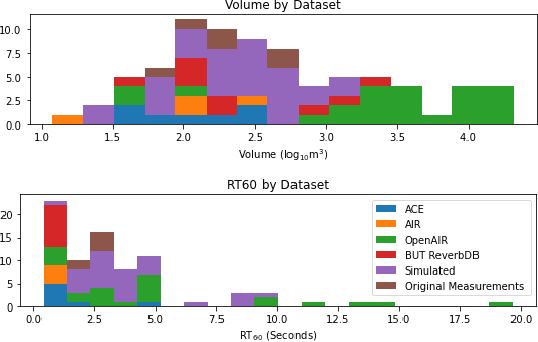
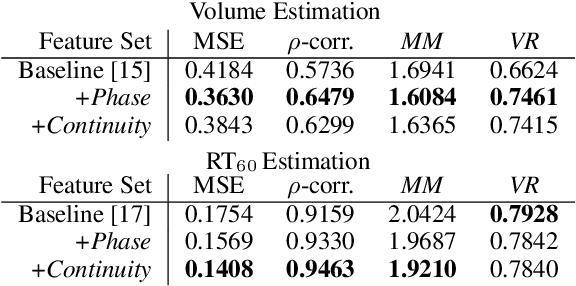

Modeling room acoustics in a field setting involves some degree of blind parameter estimation from noisy and reverberant audio. Modern approaches leverage convolutional neural networks (CNNs) in tandem with time-frequency representation. Using short-time Fourier transforms to develop these spectrogram-like features has shown promising results, but this method implicitly discards a significant amount of audio information in the phase domain. Inspired by recent works in speech enhancement, we propose utilizing novel phase-related features to extend recent approaches to blindly estimate the so-called "reverberation fingerprint" parameters, namely, volume and RT60. The addition of these features is shown to outperform existing methods that rely solely on magnitude-based spectral features across a wide range of acoustics spaces. We evaluate the effectiveness of the deployment of these novel features in both single-parameter and multi-parameter estimation strategies, using a novel dataset that consists of publicly available room impulse responses (RIRs), synthesized RIRs, and in-house measurements of real acoustic spaces.
Multi-Microphone Speaker Separation by Spatial Regions
Mar 13, 2023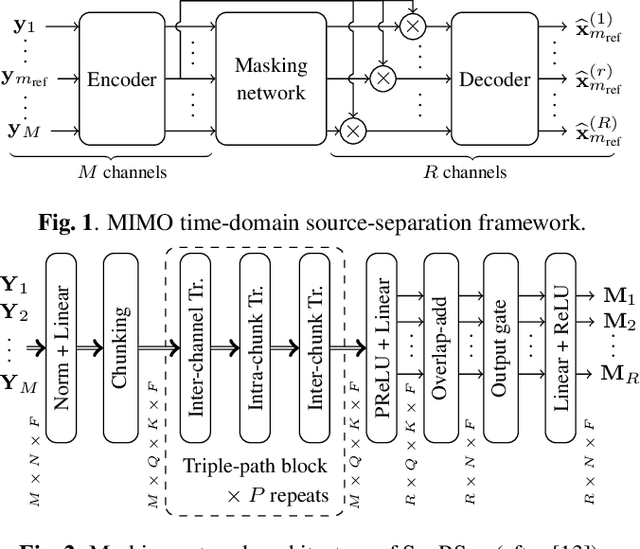
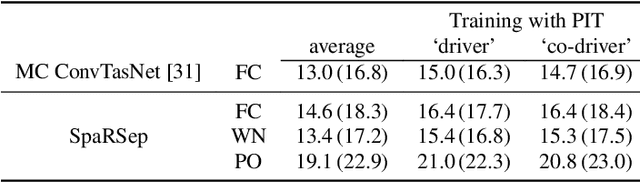
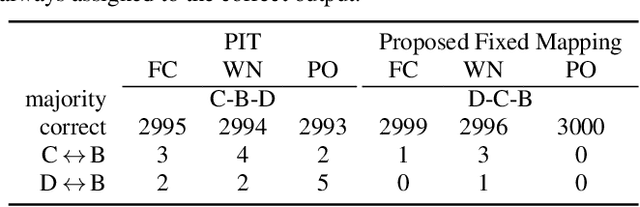

We consider the task of region-based source separation of reverberant multi-microphone recordings. We assume pre-defined spatial regions with a single active source per region. The objective is to estimate the signals from the individual spatial regions as captured by a reference microphone while retaining a correspondence between signals and spatial regions. We propose a data-driven approach using a modified version of a state-of-the-art network, where different layers model spatial and spectro-temporal information. The network is trained to enforce a fixed mapping of regions to network outputs. Using speech from LibriMix, we construct a data set specifically designed to contain the region information. Additionally, we train the network with permutation invariant training. We show that both training methods result in a fixed mapping of regions to network outputs, achieve comparable performance, and that the networks exploit spatial information. The proposed network outperforms a baseline network by 1.5 dB in scale-invariant signal-to-distortion ratio.
A Systematic Comparison of Phonetic Aware Techniques for Speech Enhancement
Jun 22, 2022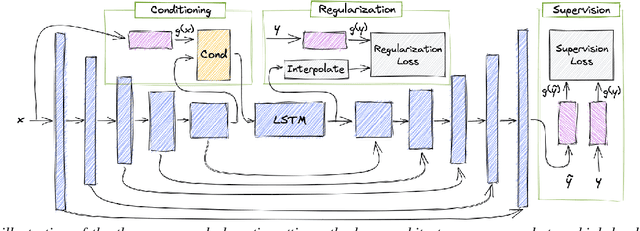
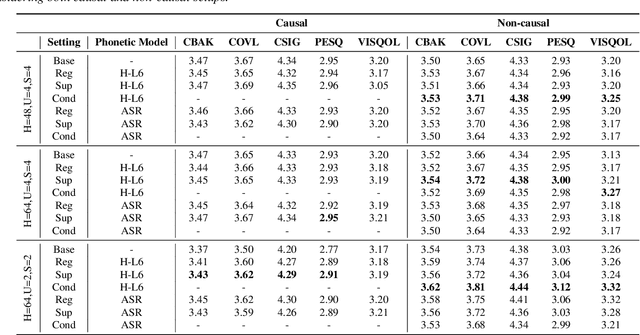
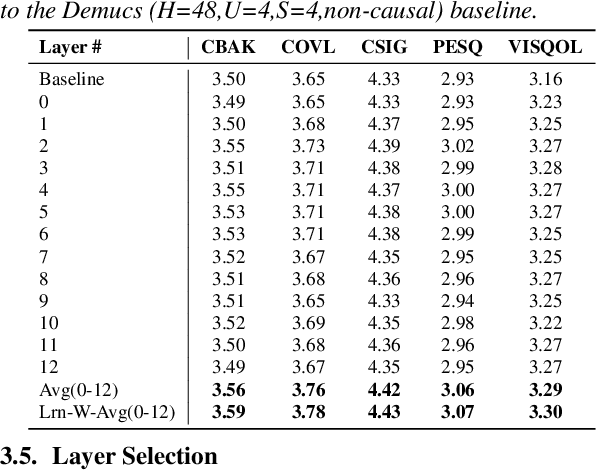
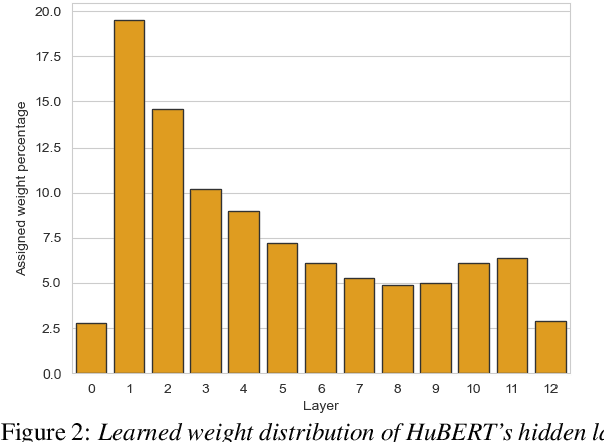
Speech enhancement has seen great improvement in recent years using end-to-end neural networks. However, most models are agnostic to the spoken phonetic content. Recently, several studies suggested phonetic-aware speech enhancement, mostly using perceptual supervision. Yet, injecting phonetic features during model optimization can take additional forms (e.g., model conditioning). In this paper, we conduct a systematic comparison between different methods of incorporating phonetic information in a speech enhancement model. By conducting a series of controlled experiments, we observe the influence of different phonetic content models as well as various feature-injection techniques on enhancement performance, considering both causal and non-causal models. Specifically, we evaluate three settings for injecting phonetic information, namely: i) feature conditioning; ii) perceptual supervision; and iii) regularization. Phonetic features are obtained using an intermediate layer of either a supervised pre-trained Automatic Speech Recognition (ASR) model or by using a pre-trained Self-Supervised Learning (SSL) model. We further observe the effect of choosing different embedding layers on performance, considering both manual and learned configurations. Results suggest that using a SSL model as phonetic features outperforms the ASR one in most cases. Interestingly, the conditioning setting performs best among the evaluated configurations.
Handling and extracting key entities from customer conversations using Speech recognition and Named Entity recognition
Nov 28, 2022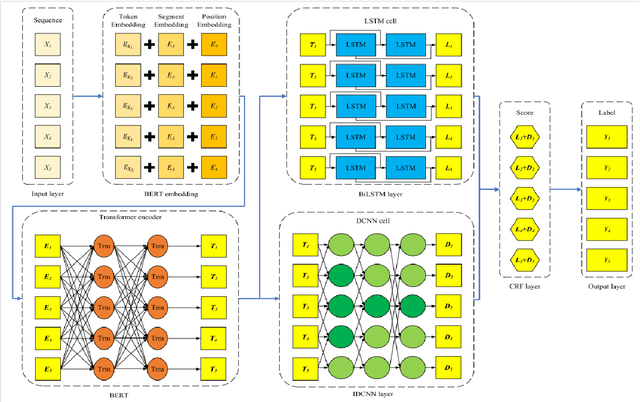
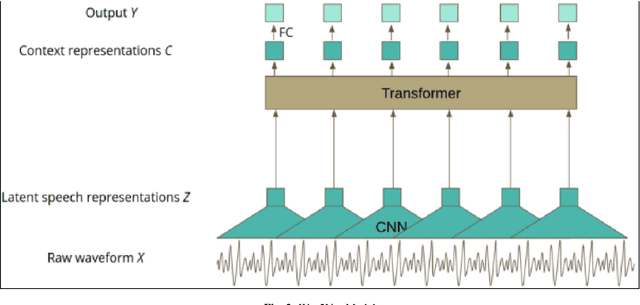
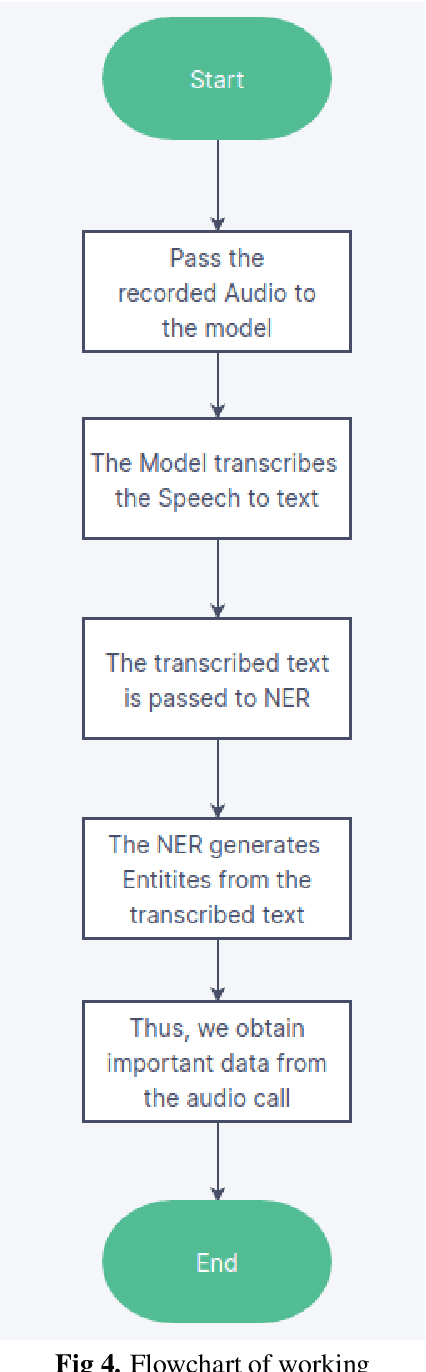
In this modern era of technology with e-commerce developing at a rapid pace, it is very important to understand customer requirements and details from a business conversation. It is very crucial for customer retention and satisfaction. Extracting key insights from these conversations is very important when it comes to developing their product or solving their issue. Understanding customer feedback, responses, and important details of the product are essential and it would be done using Named entity recognition (NER). For extracting the entities we would be converting the conversations to text using the optimal speech-to-text model. The model would be a two-stage network in which the conversation is converted to text. Then, suitable entities are extracted using robust techniques using a NER BERT transformer model. This will aid in the enrichment of customer experience when there is an issue which is faced by them. If a customer faces a problem he will call and register his complaint. The model will then extract the key features from this conversation which will be necessary to look into the problem. These features would include details like the order number, and the exact problem. All these would be extracted directly from the conversation and this would reduce the effort of going through the conversation again.
DISPLACE Challenge: DIarization of SPeaker and LAnguage in Conversational Environments
Mar 01, 2023

The DISPLACE challenge entails a first-of-kind task to perform speaker and language diarization on the same data, as the data contains multi-speaker social conversations in multilingual code-mixed speech. The challenge attempts to benchmark and improve Speaker Diarization (SD) in multilingual settings and Language Diarization (LD) in multi-speaker settings. For this challenge, a natural multilingual, multi-speaker conversational dataset is distributed for development and evaluation purposes. Automatic systems are evaluated on single-channel far-field recordings containing natural code-mix, code-switch, overlap, reverberation, short turns, short pauses, and multiple dialects of the same language. A total of 60 teams from industry and academia have registered for this challenge.
VoxSRC 2022: The Fourth VoxCeleb Speaker Recognition Challenge
Mar 06, 2023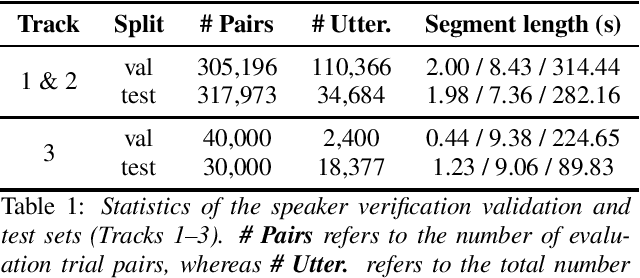
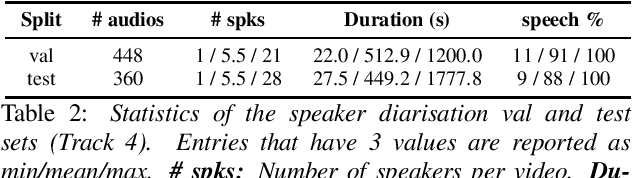
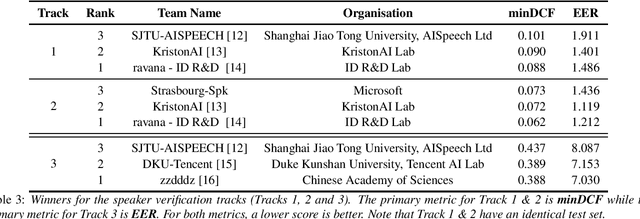

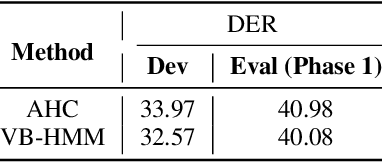
This paper summarises the findings from the VoxCeleb Speaker Recognition Challenge 2022 (VoxSRC-22), which was held in conjunction with INTERSPEECH 2022. The goal of this challenge was to evaluate how well state-of-the-art speaker recognition systems can diarise and recognise speakers from speech obtained "in the wild". The challenge consisted of: (i) the provision of publicly available speaker recognition and diarisation data from YouTube videos together with ground truth annotation and standardised evaluation software; and (ii) a public challenge and hybrid workshop held at INTERSPEECH 2022. We describe the four tracks of our challenge along with the baselines, methods, and results. We conclude with a discussion on the new domain-transfer focus of VoxSRC-22, and on the progression of the challenge from the previous three editions.
UFO2: A unified pre-training framework for online and offline speech recognition
Oct 26, 2022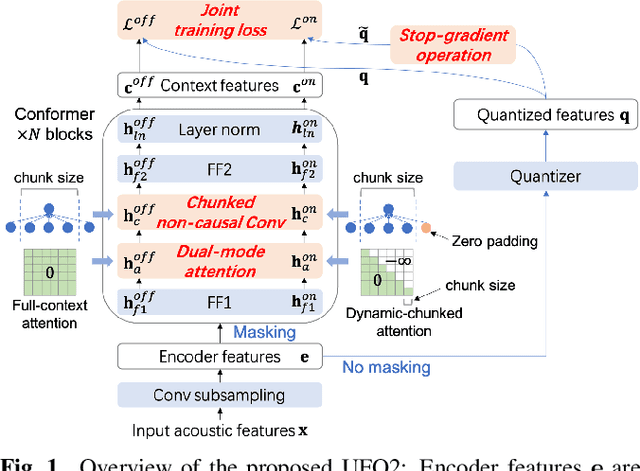
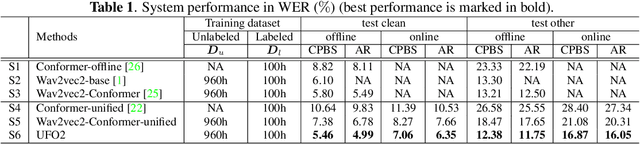


In this paper, we propose a Unified pre-training Framework for Online and Offline (UFO2) Automatic Speech Recognition (ASR), which 1) simplifies the two separate training workflows for online and offline modes into one process, and 2) improves the Word Error Rate (WER) performance with limited utterance annotating. Specifically, we extend the conventional offline-mode Self-Supervised Learning (SSL)-based ASR approach to a unified manner, where the model training is conditioned on both the full-context and dynamic-chunked inputs. To enhance the pre-trained representation model, stop-gradient operation is applied to decouple the online-mode objectives to the quantizer. Moreover, in both the pre-training and the downstream fine-tuning stages, joint losses are proposed to train the unified model with full-weight sharing for the two modes. Experimental results on the LibriSpeech dataset show that UFO2 outperforms the SSL-based baseline method by 29.7% and 18.2% relative WER reduction in offline and online modes, respectively.
Hate Speech and Offensive Language Detection in Bengali
Oct 07, 2022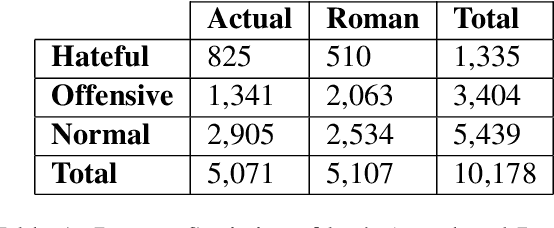
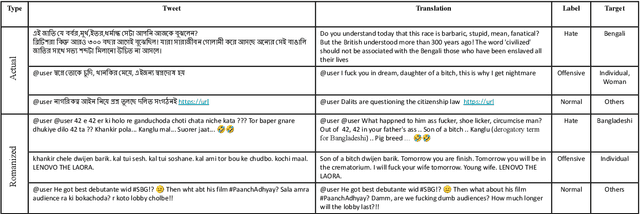

Social media often serves as a breeding ground for various hateful and offensive content. Identifying such content on social media is crucial due to its impact on the race, gender, or religion in an unprejudiced society. However, while there is extensive research in hate speech detection in English, there is a gap in hateful content detection in low-resource languages like Bengali. Besides, a current trend on social media is the use of Romanized Bengali for regular interactions. To overcome the existing research's limitations, in this study, we develop an annotated dataset of 10K Bengali posts consisting of 5K actual and 5K Romanized Bengali tweets. We implement several baseline models for the classification of such hateful posts. We further explore the interlingual transfer mechanism to boost classification performance. Finally, we perform an in-depth error analysis by looking into the misclassified posts by the models. While training actual and Romanized datasets separately, we observe that XLM-Roberta performs the best. Further, we witness that on joint training and few-shot training, MuRIL outperforms other models by interpreting the semantic expressions better. We make our code and dataset public for others.
The Casual Conversations v2 Dataset
Mar 08, 2023
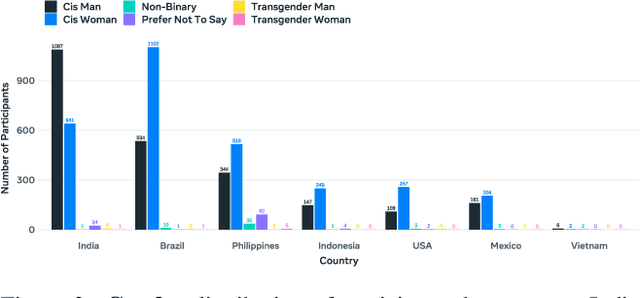
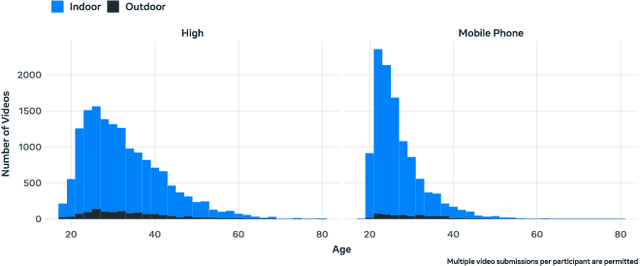
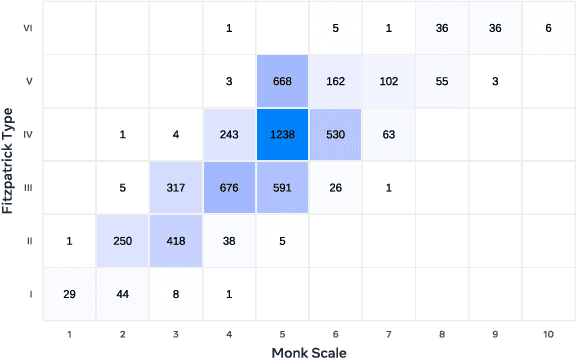
This paper introduces a new large consent-driven dataset aimed at assisting in the evaluation of algorithmic bias and robustness of computer vision and audio speech models in regards to 11 attributes that are self-provided or labeled by trained annotators. The dataset includes 26,467 videos of 5,567 unique paid participants, with an average of almost 5 videos per person, recorded in Brazil, India, Indonesia, Mexico, Vietnam, Philippines, and the USA, representing diverse demographic characteristics. The participants agreed for their data to be used in assessing fairness of AI models and provided self-reported age, gender, language/dialect, disability status, physical adornments, physical attributes and geo-location information, while trained annotators labeled apparent skin tone using the Fitzpatrick Skin Type and Monk Skin Tone scales, and voice timbre. Annotators also labeled for different recording setups and per-second activity annotations.