 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Automatic Heteronym Resolution Pipeline Using RAD-TTS Aligners
Feb 28, 2023
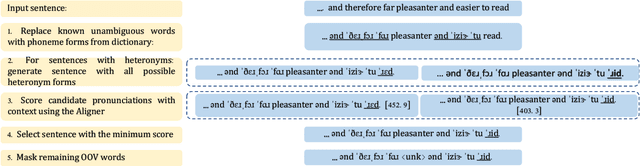


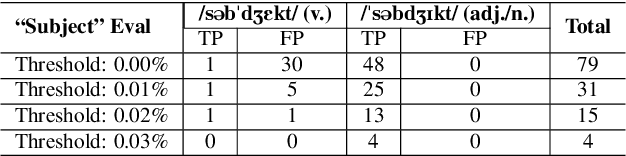
Grapheme-to-phoneme (G2P) transduction is part of the standard text-to-speech (TTS) pipeline. However, G2P conversion is difficult for languages that contain heteronyms -- words that have one spelling but can be pronounced in multiple ways. G2P datasets with annotated heteronyms are limited in size and expensive to create, as human labeling remains the primary method for heteronym disambiguation. We propose a RAD-TTS Aligner-based pipeline to automatically disambiguate heteronyms in datasets that contain both audio with text transcripts. The best pronunciation can be chosen by generating all possible candidates for each heteronym and scoring them with an Aligner model. The resulting labels can be used to create training datasets for use in both multi-stage and end-to-end G2P systems.
Preregistered protocol for: Articulatory changes in speech following treatment for oral or oropharyngeal cancer: a systematic review
Sep 14, 2022


This document outlines a PROSPERO pre-registered protocol for a systematic review regarding articulatory changes in speech following oral or orophayrngeal cancer treatment. Treatment of tumours in the oral cavity may result in physiological changes that could lead to articulatory difficulties. The tongue becomes less mobile due to scar tissue and/or potential (postoperative) radiation therapy. Moreover, tissue loss may create a bypass for airflow or limit constriction possibilities. In order to gain a better understanding of the nature of the speech problems, information regarding the movement of the articulators is needed since perceptual or acoustic information provide only indirect evidence of articulatory changes. Therefore, this systematic review will review studies that directly measured the articulatory movements of the tongue, jaw, and lips following treatment for oral or oropharyngeal cancer.
Incremental Speech Synthesis For Speech-To-Speech Translation
Oct 15, 2021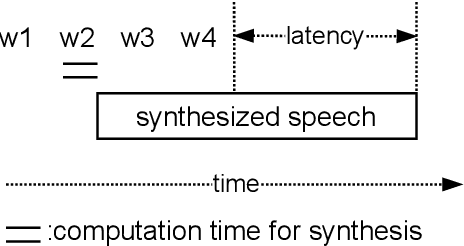
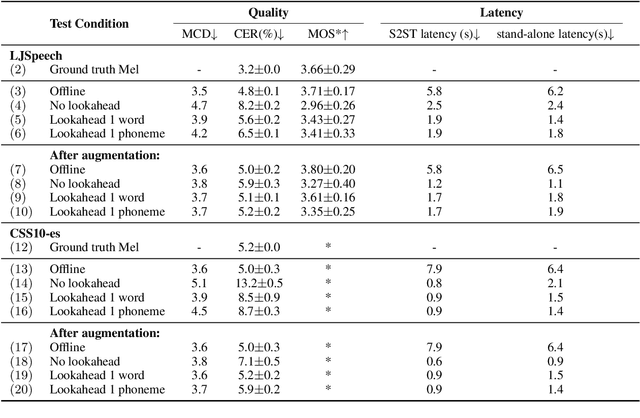

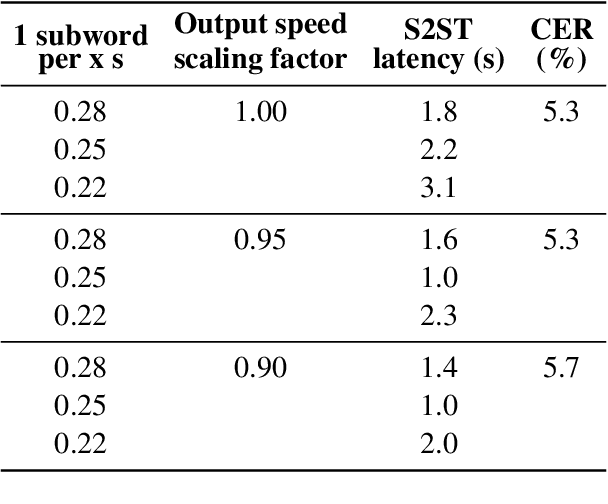
In a speech-to-speech translation (S2ST) pipeline, the text-to-speech (TTS) module is an important component for delivering the translated speech to users. To enable incremental S2ST, the TTS module must be capable of synthesizing and playing utterances while its input text is still streaming in. In this work, we focus on improving the incremental synthesis performance of TTS models. With a simple data augmentation strategy based on prefixes, we are able to improve the incremental TTS quality to approach offline performance. Furthermore, we bring our incremental TTS system to the practical scenario in combination with an upstream simultaneous speech translation system, and show the gains also carry over to this use-case. In addition, we propose latency metrics tailored to S2ST applications, and investigate methods for latency reduction in this context.
Chain-based Discriminative Autoencoders for Speech Recognition
Mar 28, 2022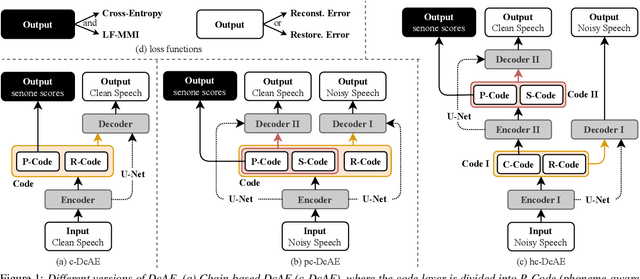
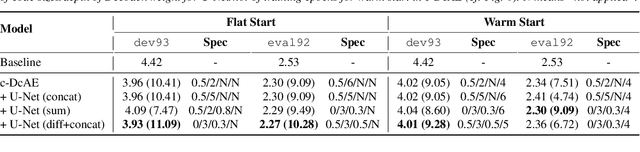
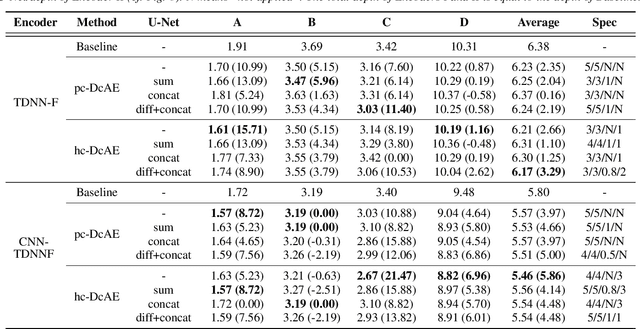
In our previous work, we proposed a discriminative autoencoder (DcAE) for speech recognition. DcAE combines two training schemes into one. First, since DcAE aims to learn encoder-decoder mappings, the squared error between the reconstructed speech and the input speech is minimized. Second, in the code layer, frame-based phonetic embeddings are obtained by minimizing the categorical cross-entropy between ground truth labels and predicted triphone-state scores. DcAE is developed based on the Kaldi toolkit by treating various TDNN models as encoders. In this paper, we further propose three new versions of DcAE. First, a new objective function that considers both categorical cross-entropy and mutual information between ground truth and predicted triphone-state sequences is used. The resulting DcAE is called a chain-based DcAE (c-DcAE). For application to robust speech recognition, we further extend c-DcAE to hierarchical and parallel structures, resulting in hc-DcAE and pc-DcAE. In these two models, both the error between the reconstructed noisy speech and the input noisy speech and the error between the enhanced speech and the reference clean speech are taken into the objective function. Experimental results on the WSJ and Aurora-4 corpora show that our DcAE models outperform baseline systems.
Weight Averaging: A Simple Yet Effective Method to Overcome Catastrophic Forgetting in Automatic Speech Recognition
Oct 27, 2022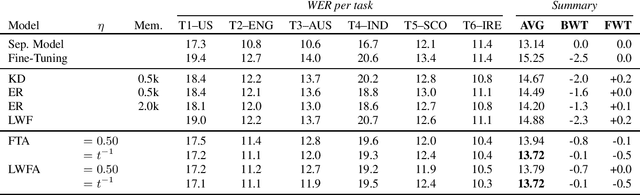
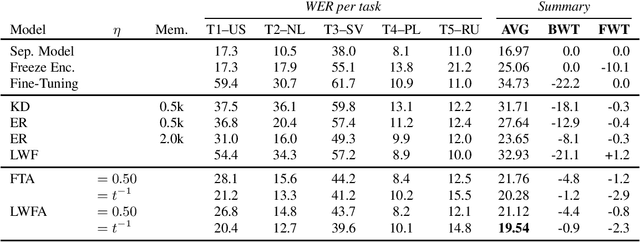
Adapting a trained Automatic Speech Recognition (ASR) model to new tasks results in catastrophic forgetting of old tasks, limiting the model's ability to learn continually and to be extended to new speakers, dialects, languages, etc. Focusing on End-to-End ASR, in this paper, we propose a simple yet effective method to overcome catastrophic forgetting: weight averaging. By simply taking the average of the previous and the adapted model, our method achieves high performance on both the old and new tasks. It can be further improved by introducing a knowledge distillation loss during the adaptation. We illustrate the effectiveness of our method on both monolingual and multilingual ASR. In both cases, our method strongly outperforms all baselines, even in its simplest form.
Wideband Audio Waveform Evaluation Networks: Efficient, Accurate Estimation of Speech Qualities
Jun 27, 2022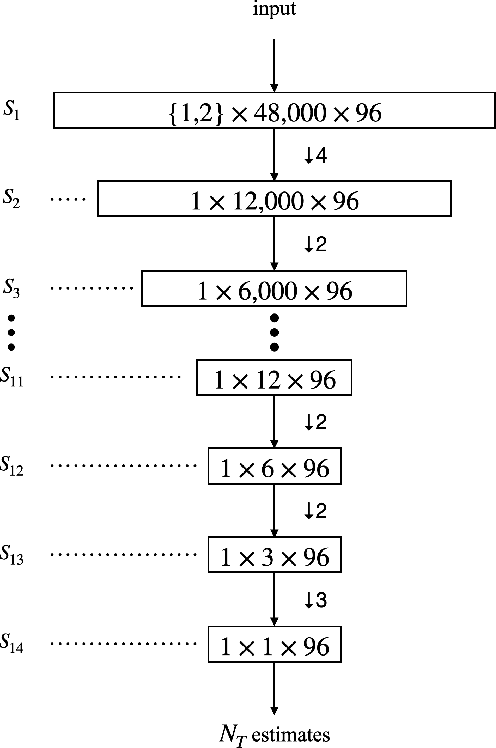
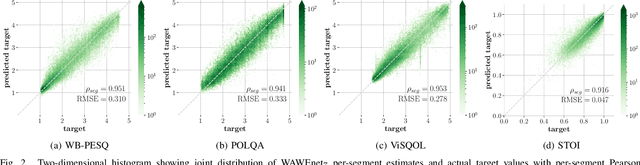
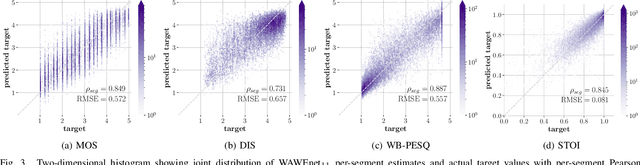
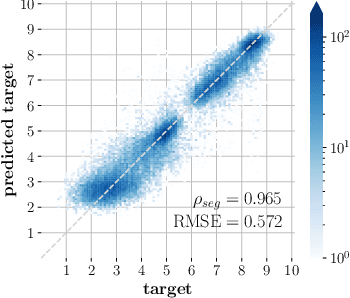
Wideband Audio Waveform Evaluation Networks (WAWEnets) are convolutional neural networks that operate directly on wideband audio waveforms in order to produce evaluations of those waveforms. In the present work these evaluations give qualities of telecommunications speech (e.g., noisiness, intelligibility, overall speech quality). WAWEnets are no-reference networks because they do not require ``reference'' (original or undistorted) versions of the waveforms they evaluate. Our initial WAWEnet publication introduced four WAWEnets and each emulated the output of an established full-reference speech quality or intelligibility estimation algorithm. We have updated the WAWEnet architecture to be more efficient and effective. Here we present a single WAWEnet that closely tracks seven different quality and intelligibility values. We create a second network that additionally tracks four subjective speech quality dimensions. We offer a third network that focuses on just subjective quality scores and achieves very high levels of agreement. This work has leveraged 334 hours of speech in 13 languages, over two million full-reference target values and over 93,000 subjective mean opinion scores. We also interpret the operation of WAWEnets and identify the key to their operation using the language of signal processing: ReLUs strategically move spectral information from non-DC components into the DC component. The DC values of 96 output signals define a vector in a 96-D latent space and this vector is then mapped to a quality or intelligibility value for the input waveform.
Contrastive Representation Learning for Acoustic Parameter Estimation
Feb 22, 2023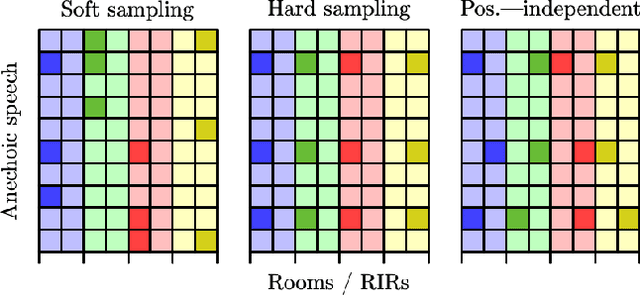


A study is presented in which a contrastive learning approach is used to extract low-dimensional representations of the acoustic environment from single-channel, reverberant speech signals. Convolution of room impulse responses (RIRs) with anechoic source signals is leveraged as a data augmentation technique that offers considerable flexibility in the design of the upstream task. We evaluate the embeddings across three different downstream tasks, which include the regression of acoustic parameters reverberation time RT60 and clarity index C50, and the classification into small and large rooms. We demonstrate that the learned representations generalize well to unseen data and achieve similar performance compared to a fully supervised baseline.
Bayesian Neural Network Language Modeling for Speech Recognition
Aug 28, 2022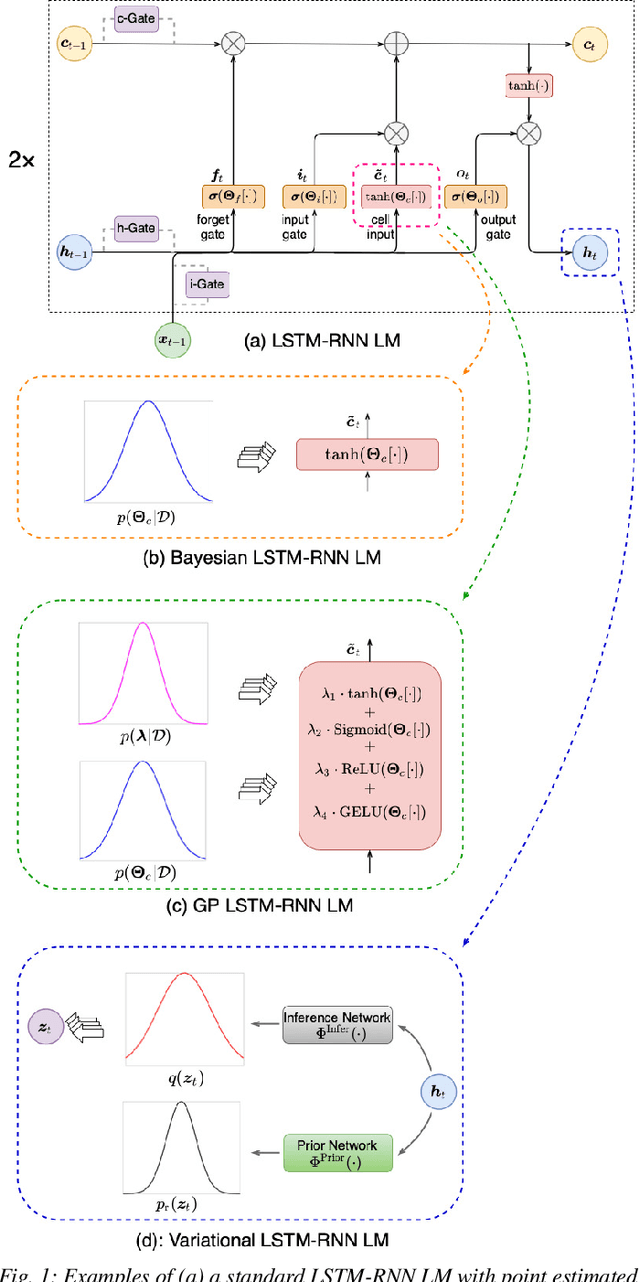
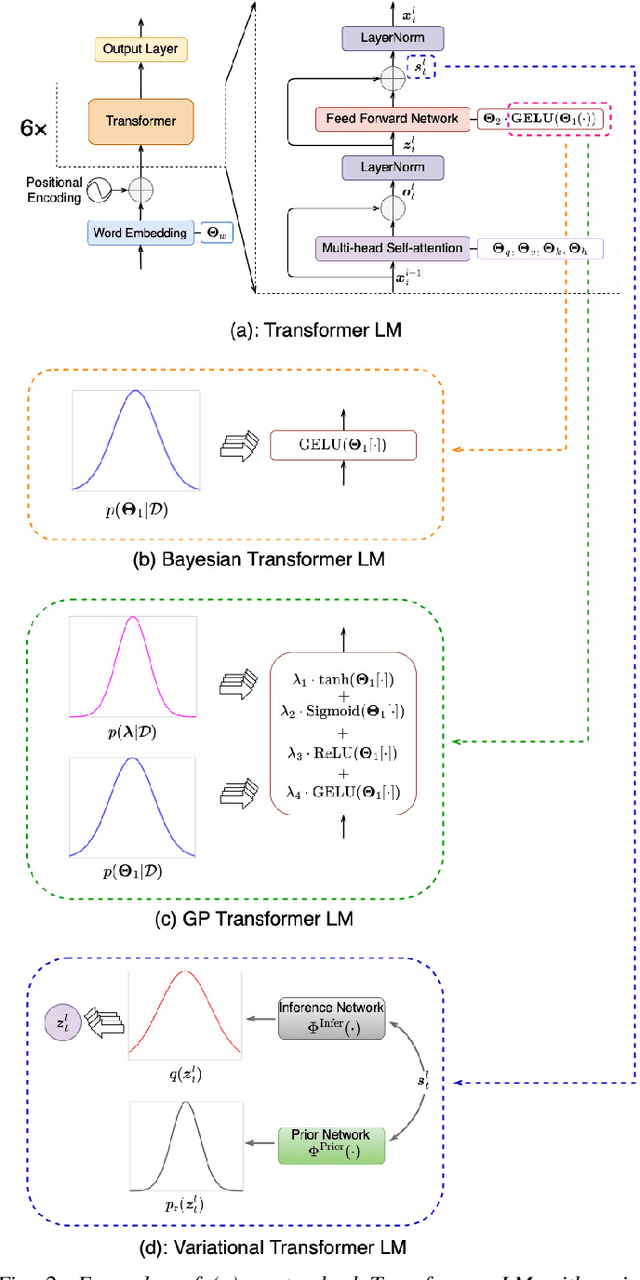
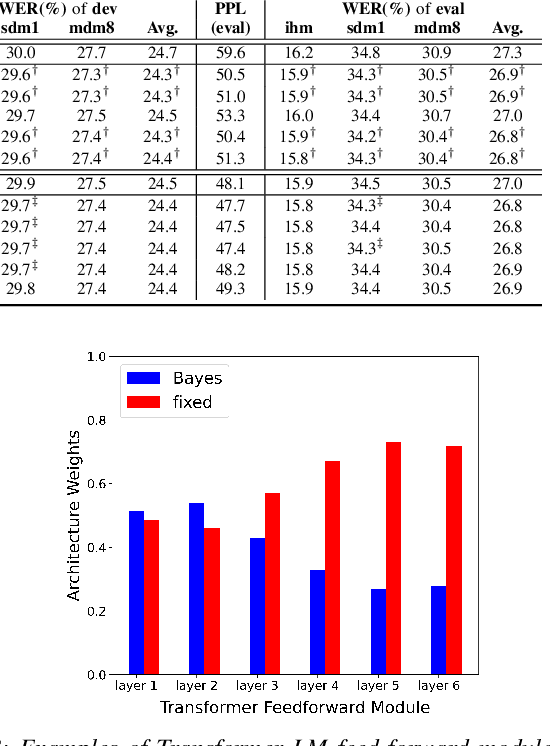
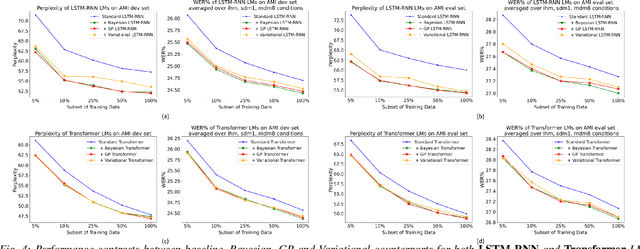
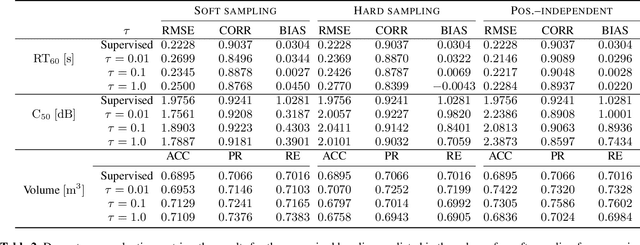
State-of-the-art neural network language models (NNLMs) represented by long short term memory recurrent neural networks (LSTM-RNNs) and Transformers are becoming highly complex. They are prone to overfitting and poor generalization when given limited training data. To this end, an overarching full Bayesian learning framework encompassing three methods is proposed in this paper to account for the underlying uncertainty in LSTM-RNN and Transformer LMs. The uncertainty over their model parameters, choice of neural activations and hidden output representations are modeled using Bayesian, Gaussian Process and variational LSTM-RNN or Transformer LMs respectively. Efficient inference approaches were used to automatically select the optimal network internal components to be Bayesian learned using neural architecture search. A minimal number of Monte Carlo parameter samples as low as one was also used. These allow the computational costs incurred in Bayesian NNLM training and evaluation to be minimized. Experiments are conducted on two tasks: AMI meeting transcription and Oxford-BBC LipReading Sentences 2 (LRS2) overlapped speech recognition using state-of-the-art LF-MMI trained factored TDNN systems featuring data augmentation, speaker adaptation and audio-visual multi-channel beamforming for overlapped speech. Consistent performance improvements over the baseline LSTM-RNN and Transformer LMs with point estimated model parameters and drop-out regularization were obtained across both tasks in terms of perplexity and word error rate (WER). In particular, on the LRS2 data, statistically significant WER reductions up to 1.3% and 1.2% absolute (12.1% and 11.3% relative) were obtained over the baseline LSTM-RNN and Transformer LMs respectively after model combination between Bayesian NNLMs and their respective baselines.
Fast-U2++: Fast and Accurate End-to-End Speech Recognition in Joint CTC/Attention Frames
Nov 02, 2022Recently, the unified streaming and non-streaming two-pass (U2/U2++) end-to-end model for speech recognition has shown great performance in terms of streaming capability, accuracy and latency. In this paper, we present fast-U2++, an enhanced version of U2++ to further reduce partial latency. The core idea of fast-U2++ is to output partial results of the bottom layers in its encoder with a small chunk, while using a large chunk in the top layers of its encoder to compensate the performance degradation caused by the small chunk. Moreover, we use knowledge distillation method to reduce the token emission latency. We present extensive experiments on Aishell-1 dataset. Experiments and ablation studies show that compared to U2++, fast-U2++ reduces model latency from 320ms to 80ms, and achieves a character error rate (CER) of 5.06% with a streaming setup.
WavThruVec: Latent speech representation as intermediate features for neural speech synthesis
Mar 31, 2022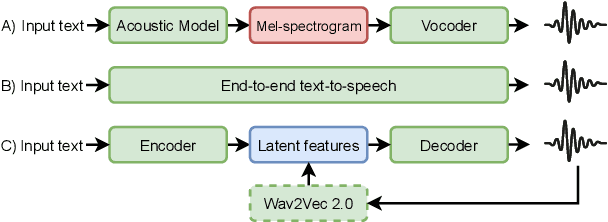

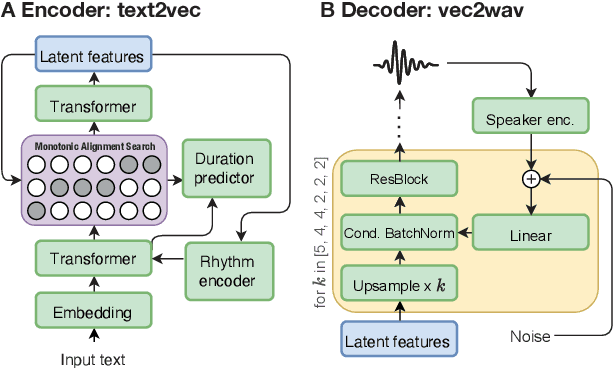
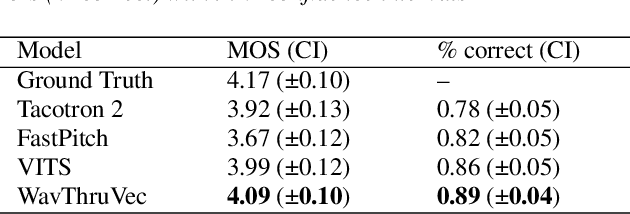
Recent advances in neural text-to-speech research have been dominated by two-stage pipelines utilizing low-level intermediate speech representation such as mel-spectrograms. However, such predetermined features are fundamentally limited, because they do not allow to exploit the full potential of a data-driven approach through learning hidden representations. For this reason, several end-to-end methods have been proposed. However, such models are harder to train and require a large number of high-quality recordings with transcriptions. Here, we propose WavThruVec - a two-stage architecture that resolves the bottleneck by using high-dimensional Wav2Vec 2.0 embeddings as intermediate speech representation. Since these hidden activations provide high-level linguistic features, they are more robust to noise. That allows us to utilize annotated speech datasets of a lower quality to train the first-stage module. At the same time, the second-stage component can be trained on large-scale untranscribed audio corpora, as Wav2Vec 2.0 embeddings are time-aligned and speaker-independent. This results in an increased generalization capability to out-of-vocabulary words, as well as to a better generalization to unseen speakers. We show that the proposed model not only matches the quality of state-of-the-art neural models, but also presents useful properties enabling tasks like voice conversion or zero-shot synthesis.