 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Visual Context-driven Audio Feature Enhancement for Robust End-to-End Audio-Visual Speech Recognition
Jul 13, 2022
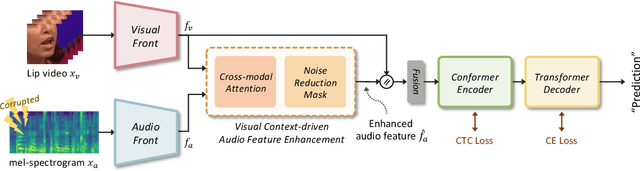
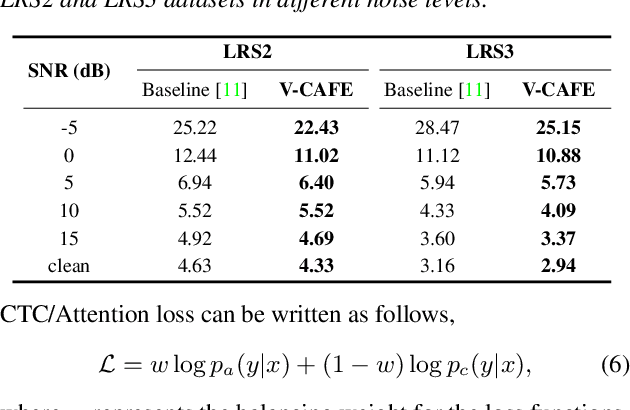
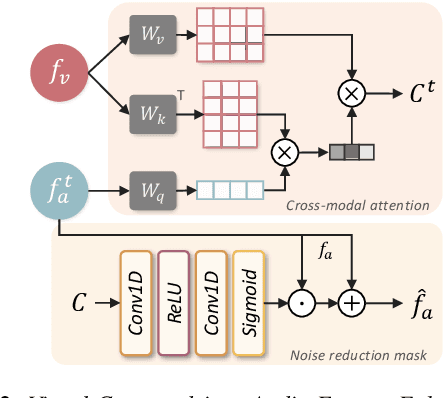
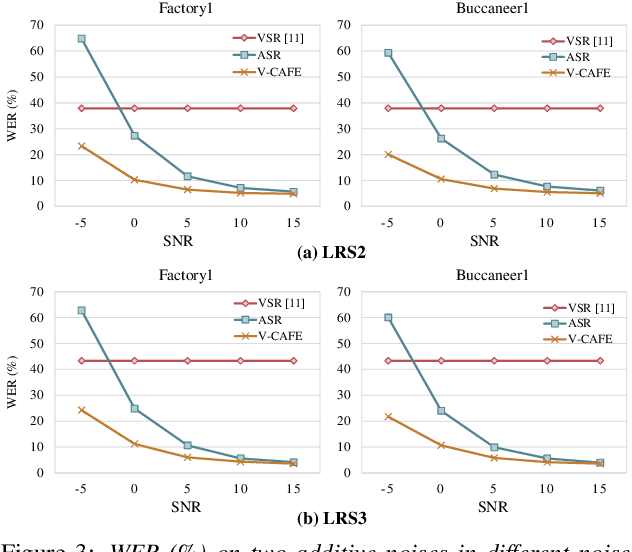
This paper focuses on designing a noise-robust end-to-end Audio-Visual Speech Recognition (AVSR) system. To this end, we propose Visual Context-driven Audio Feature Enhancement module (V-CAFE) to enhance the input noisy audio speech with a help of audio-visual correspondence. The proposed V-CAFE is designed to capture the transition of lip movements, namely visual context and to generate a noise reduction mask by considering the obtained visual context. Through context-dependent modeling, the ambiguity in viseme-to-phoneme mapping can be refined for mask generation. The noisy representations are masked out with the noise reduction mask resulting in enhanced audio features. The enhanced audio features are fused with the visual features and taken to an encoder-decoder model composed of Conformer and Transformer for speech recognition. We show the proposed end-to-end AVSR with the V-CAFE can further improve the noise-robustness of AVSR. The effectiveness of the proposed method is evaluated in noisy speech recognition and overlapped speech recognition experiments using the two largest audio-visual datasets, LRS2 and LRS3.
Multilingual Simultaneous Speech Translation
Mar 29, 2022
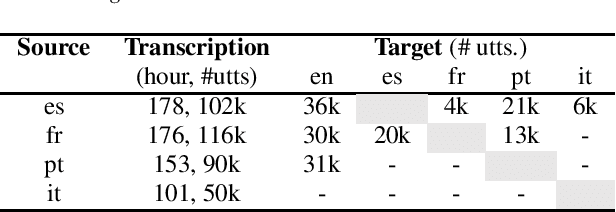
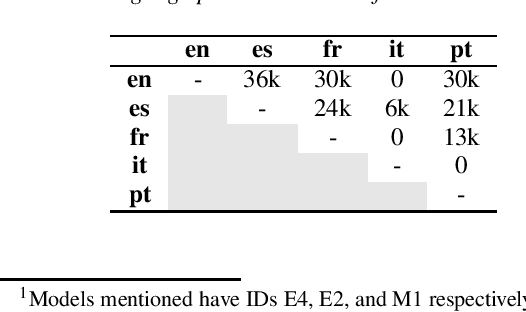

Applications designed for simultaneous speech translation during events such as conferences or meetings need to balance quality and lag while displaying translated text to deliver a good user experience. One common approach to building online spoken language translation systems is by leveraging models built for offline speech translation. Based on a technique to adapt end-to-end monolingual models, we investigate multilingual models and different architectures (end-to-end and cascade) on the ability to perform online speech translation. On the multilingual TEDx corpus, we show that the approach generalizes to different architectures. We see similar gains in latency reduction (40% relative) across languages and architectures. However, the end-to-end architecture leads to smaller translation quality losses after adapting to the online model. Furthermore, the approach even scales to zero-shot directions.
Freeform Body Motion Generation from Speech
Mar 04, 2022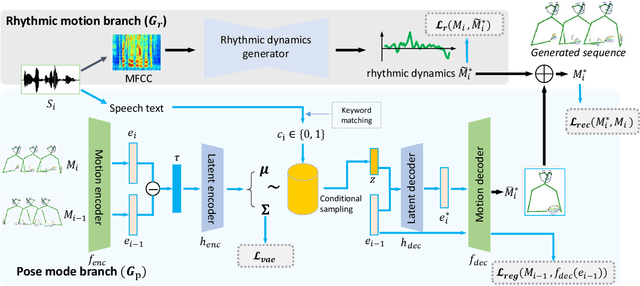
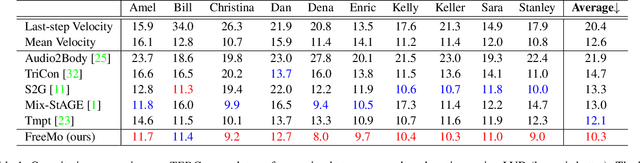
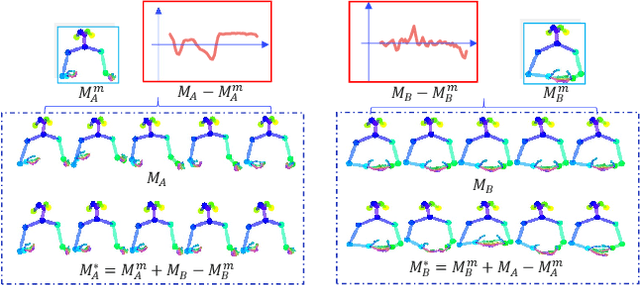
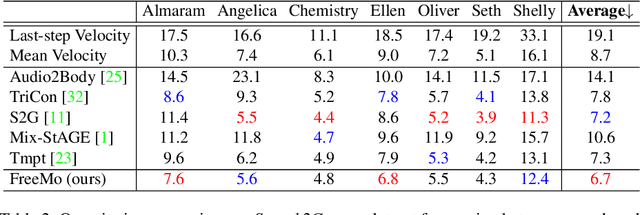
People naturally conduct spontaneous body motions to enhance their speeches while giving talks. Body motion generation from speech is inherently difficult due to the non-deterministic mapping from speech to body motions. Most existing works map speech to motion in a deterministic way by conditioning on certain styles, leading to sub-optimal results. Motivated by studies in linguistics, we decompose the co-speech motion into two complementary parts: pose modes and rhythmic dynamics. Accordingly, we introduce a novel freeform motion generation model (FreeMo) by equipping a two-stream architecture, i.e., a pose mode branch for primary posture generation, and a rhythmic motion branch for rhythmic dynamics synthesis. On one hand, diverse pose modes are generated by conditional sampling in a latent space, guided by speech semantics. On the other hand, rhythmic dynamics are synced with the speech prosody. Extensive experiments demonstrate the superior performance against several baselines, in terms of motion diversity, quality and syncing with speech. Code and pre-trained models will be publicly available through https://github.com/TheTempAccount/Co-Speech-Motion-Generation.
Hate Speech and Offensive Language Detection in Bengali
Oct 07, 2022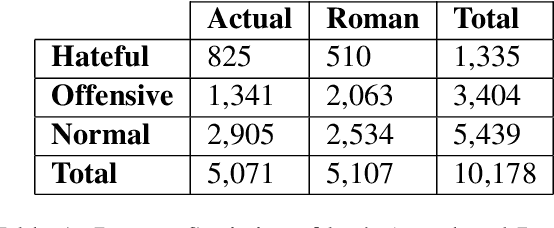
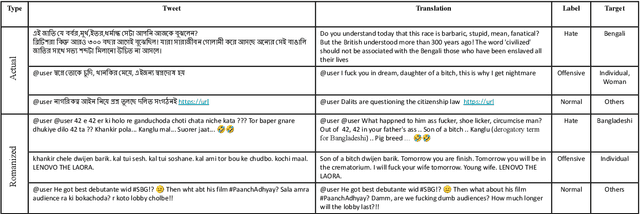
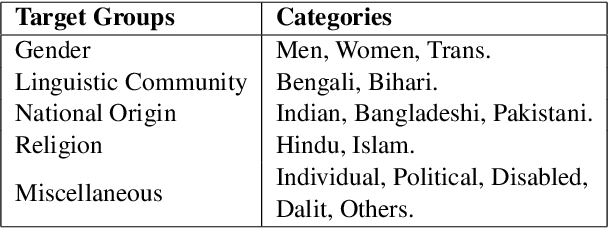

Social media often serves as a breeding ground for various hateful and offensive content. Identifying such content on social media is crucial due to its impact on the race, gender, or religion in an unprejudiced society. However, while there is extensive research in hate speech detection in English, there is a gap in hateful content detection in low-resource languages like Bengali. Besides, a current trend on social media is the use of Romanized Bengali for regular interactions. To overcome the existing research's limitations, in this study, we develop an annotated dataset of 10K Bengali posts consisting of 5K actual and 5K Romanized Bengali tweets. We implement several baseline models for the classification of such hateful posts. We further explore the interlingual transfer mechanism to boost classification performance. Finally, we perform an in-depth error analysis by looking into the misclassified posts by the models. While training actual and Romanized datasets separately, we observe that XLM-Roberta performs the best. Further, we witness that on joint training and few-shot training, MuRIL outperforms other models by interpreting the semantic expressions better. We make our code and dataset public for others.
Incremental Speech Synthesis For Speech-To-Speech Translation
Oct 15, 2021
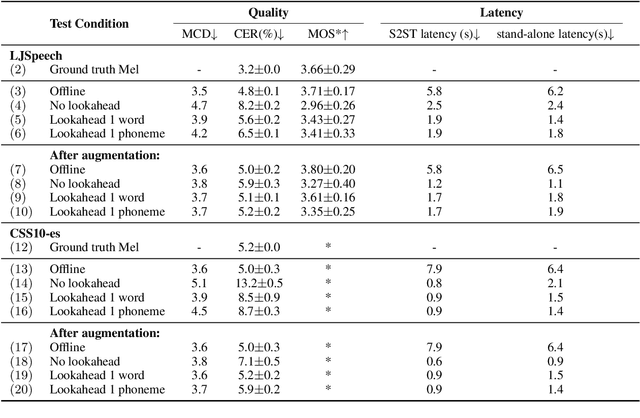

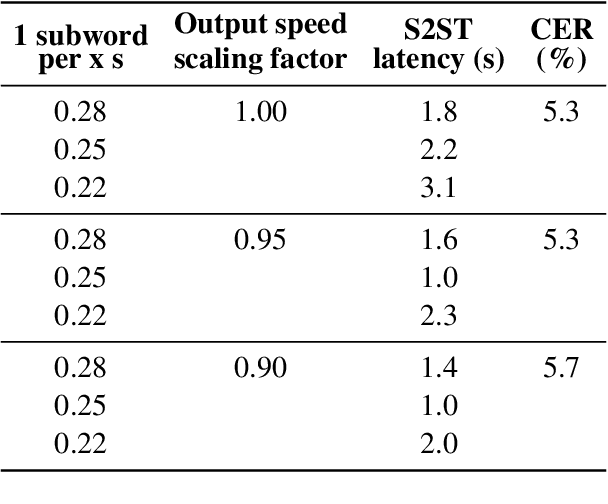
In a speech-to-speech translation (S2ST) pipeline, the text-to-speech (TTS) module is an important component for delivering the translated speech to users. To enable incremental S2ST, the TTS module must be capable of synthesizing and playing utterances while its input text is still streaming in. In this work, we focus on improving the incremental synthesis performance of TTS models. With a simple data augmentation strategy based on prefixes, we are able to improve the incremental TTS quality to approach offline performance. Furthermore, we bring our incremental TTS system to the practical scenario in combination with an upstream simultaneous speech translation system, and show the gains also carry over to this use-case. In addition, we propose latency metrics tailored to S2ST applications, and investigate methods for latency reduction in this context.
ClearBuds: Wireless Binaural Earbuds for Learning-Based Speech Enhancement
Jun 27, 2022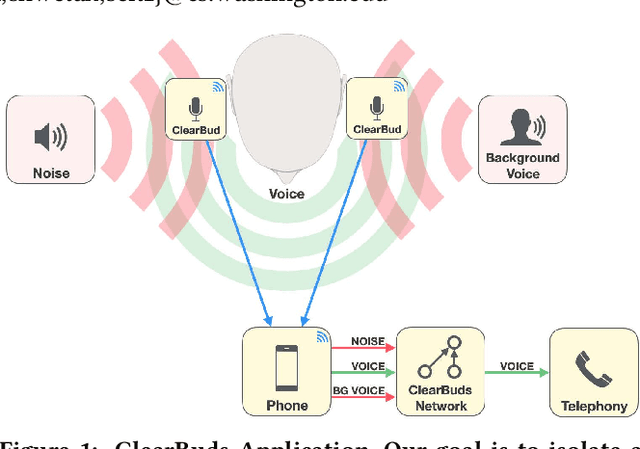

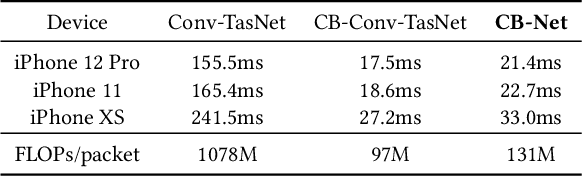
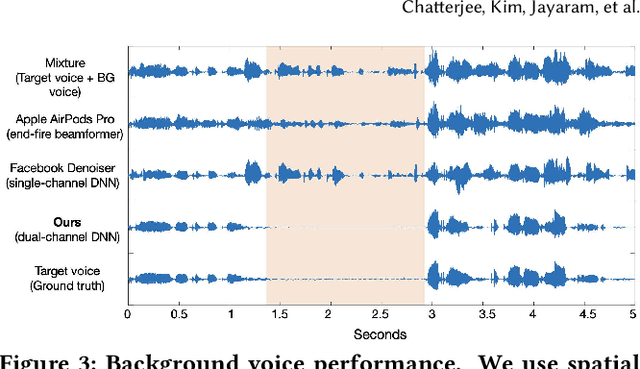
We present ClearBuds, the first hardware and software system that utilizes a neural network to enhance speech streamed from two wireless earbuds. Real-time speech enhancement for wireless earbuds requires high-quality sound separation and background cancellation, operating in real-time and on a mobile phone. Clear-Buds bridges state-of-the-art deep learning for blind audio source separation and in-ear mobile systems by making two key technical contributions: 1) a new wireless earbud design capable of operating as a synchronized, binaural microphone array, and 2) a lightweight dual-channel speech enhancement neural network that runs on a mobile device. Our neural network has a novel cascaded architecture that combines a time-domain conventional neural network with a spectrogram-based frequency masking neural network to reduce the artifacts in the audio output. Results show that our wireless earbuds achieve a synchronization error less than 64 microseconds and our network has a runtime of 21.4 milliseconds on an accompanying mobile phone. In-the-wild evaluation with eight users in previously unseen indoor and outdoor multipath scenarios demonstrates that our neural network generalizes to learn both spatial and acoustic cues to perform noise suppression and background speech removal. In a user-study with 37 participants who spent over 15.4 hours rating 1041 audio samples collected in-the-wild, our system achieves improved mean opinion score and background noise suppression. Project page with demos: https://clearbuds.cs.washington.edu
Extending DNN-based Multiplicative Masking to Deep Subband Filtering for Improved Dereverberation
Mar 01, 2023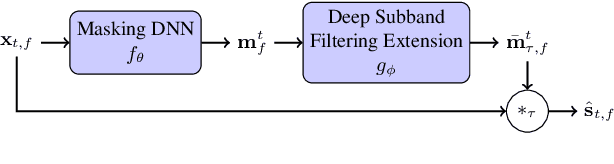
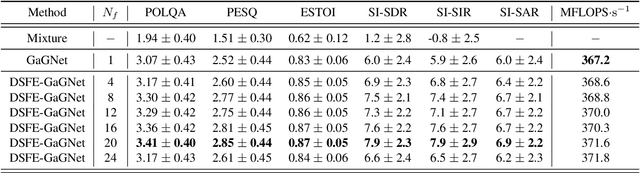
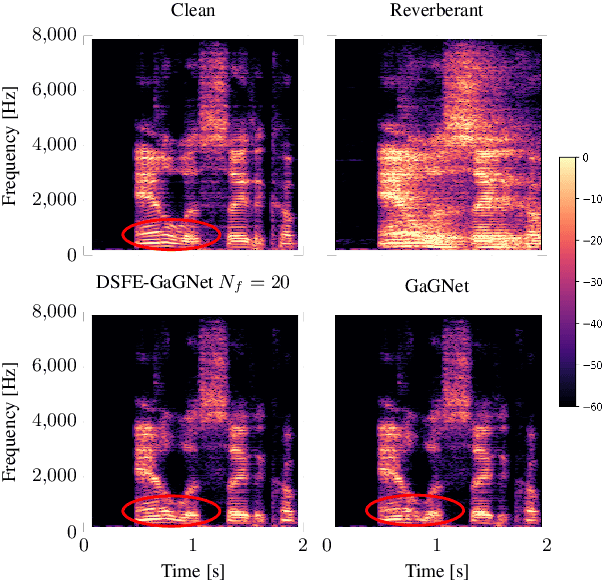
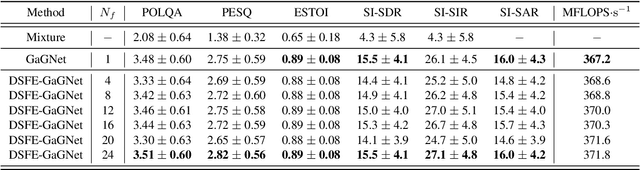
In this paper, we present a scheme for extending deep neural network-based multiplicative maskers to deep subband filters for speech restoration in the time-frequency domain. The resulting method can be generically applied to any deep neural network providing masks in the time-frequency domain, while requiring only few more trainable parameters and a computational overhead that is negligible for state-of-the-art neural networks. We demonstrate that the resulting deep subband filtering scheme outperforms multiplicative masking for dereverberation, while leaving the denoising performance virtually the same. We argue that this is because deep subband filtering in the time-frequency domain fits the subband approximation often assumed in the dereverberation literature, whereas multiplicative masking corresponds to the narrowband approximation generally employed in denoising.
Controlling High-Dimensional Data With Sparse Input
Mar 14, 2023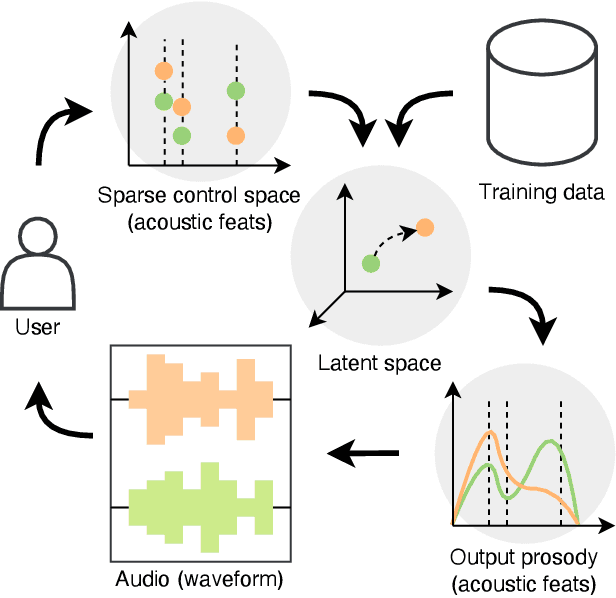
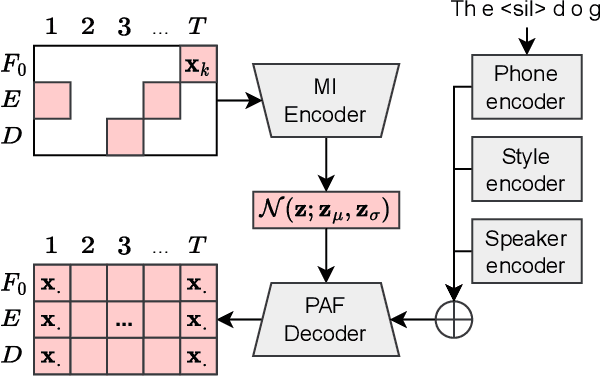
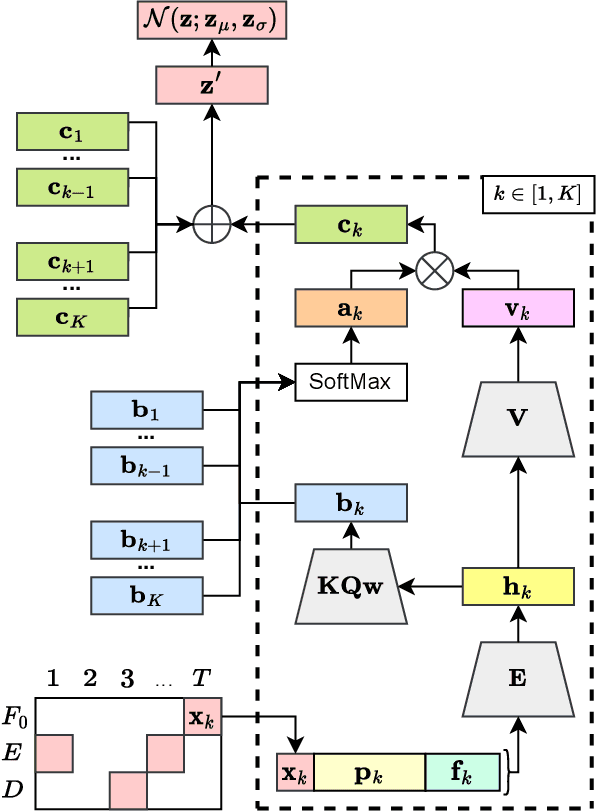
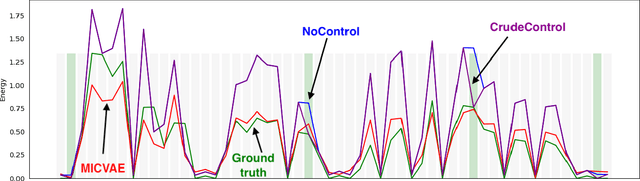
We address the problem of human-in-the-loop control for generating highly-structured data. This task is challenging because existing generative models lack an efficient interface through which users can modify the output. Users have the option to either manually explore a non-interpretable latent space, or to laboriously annotate the data with conditioning labels. To solve this, we introduce a novel framework whereby an encoder maps a sparse, human interpretable control space onto the latent space of a generative model. We apply this framework to the task of controlling prosody in text-to-speech synthesis. We propose a model, called Multiple-Instance CVAE (MICVAE), that is specifically designed to encode sparse prosodic features and output complete waveforms. We show empirically that MICVAE displays desirable qualities of a sparse human-in-the-loop control mechanism: efficiency, robustness, and faithfulness. With even a very small number of input values (~4), MICVAE enables users to improve the quality of the output significantly, in terms of listener preference (4:1).
A Systematic Comparison of Phonetic Aware Techniques for Speech Enhancement
Jun 22, 2022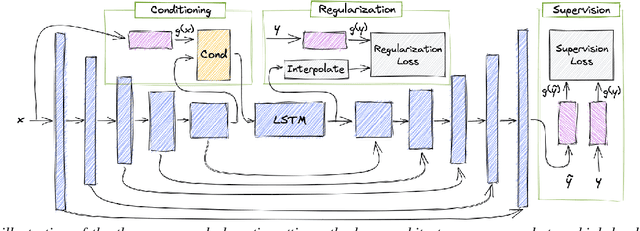
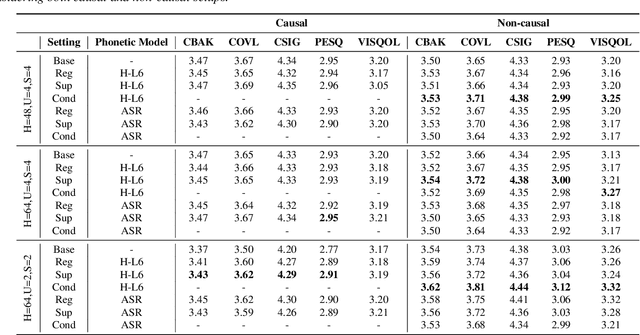
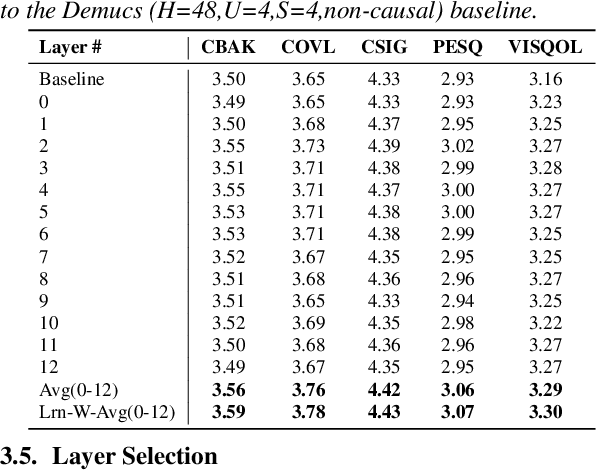
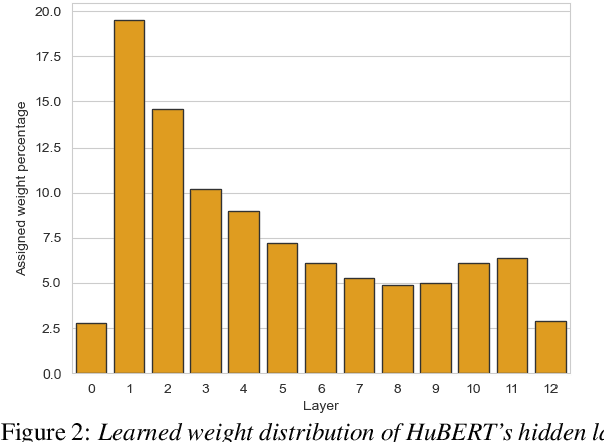
Speech enhancement has seen great improvement in recent years using end-to-end neural networks. However, most models are agnostic to the spoken phonetic content. Recently, several studies suggested phonetic-aware speech enhancement, mostly using perceptual supervision. Yet, injecting phonetic features during model optimization can take additional forms (e.g., model conditioning). In this paper, we conduct a systematic comparison between different methods of incorporating phonetic information in a speech enhancement model. By conducting a series of controlled experiments, we observe the influence of different phonetic content models as well as various feature-injection techniques on enhancement performance, considering both causal and non-causal models. Specifically, we evaluate three settings for injecting phonetic information, namely: i) feature conditioning; ii) perceptual supervision; and iii) regularization. Phonetic features are obtained using an intermediate layer of either a supervised pre-trained Automatic Speech Recognition (ASR) model or by using a pre-trained Self-Supervised Learning (SSL) model. We further observe the effect of choosing different embedding layers on performance, considering both manual and learned configurations. Results suggest that using a SSL model as phonetic features outperforms the ASR one in most cases. Interestingly, the conditioning setting performs best among the evaluated configurations.
Chain-based Discriminative Autoencoders for Speech Recognition
Mar 28, 2022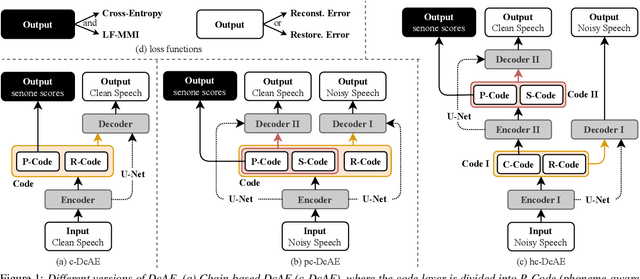
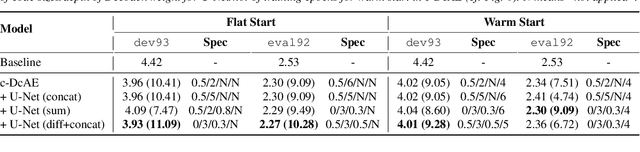
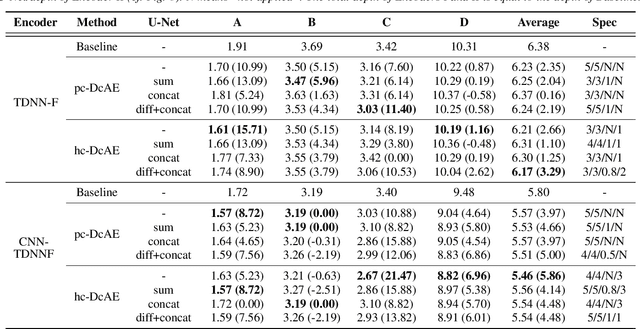
In our previous work, we proposed a discriminative autoencoder (DcAE) for speech recognition. DcAE combines two training schemes into one. First, since DcAE aims to learn encoder-decoder mappings, the squared error between the reconstructed speech and the input speech is minimized. Second, in the code layer, frame-based phonetic embeddings are obtained by minimizing the categorical cross-entropy between ground truth labels and predicted triphone-state scores. DcAE is developed based on the Kaldi toolkit by treating various TDNN models as encoders. In this paper, we further propose three new versions of DcAE. First, a new objective function that considers both categorical cross-entropy and mutual information between ground truth and predicted triphone-state sequences is used. The resulting DcAE is called a chain-based DcAE (c-DcAE). For application to robust speech recognition, we further extend c-DcAE to hierarchical and parallel structures, resulting in hc-DcAE and pc-DcAE. In these two models, both the error between the reconstructed noisy speech and the input noisy speech and the error between the enhanced speech and the reference clean speech are taken into the objective function. Experimental results on the WSJ and Aurora-4 corpora show that our DcAE models outperform baseline systems.