 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Improving Speech Recognition on Noisy Speech via Speech Enhancement with Multi-Discriminators CycleGAN
Dec 12, 2021
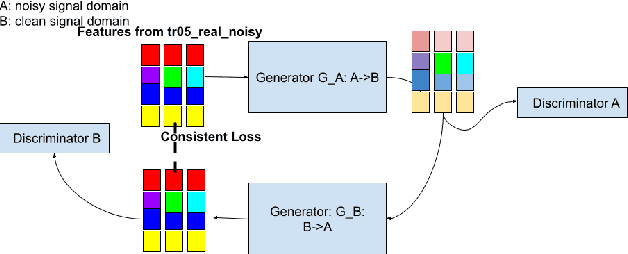
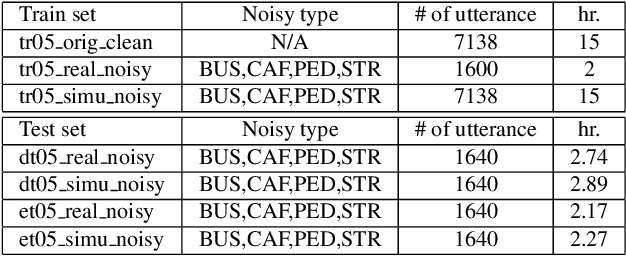
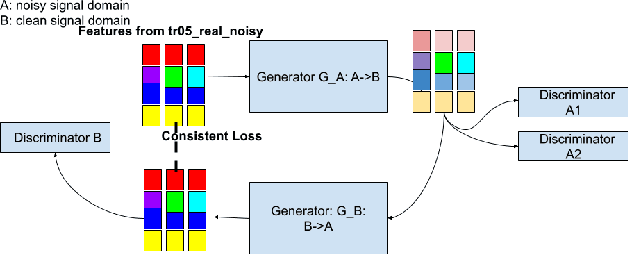
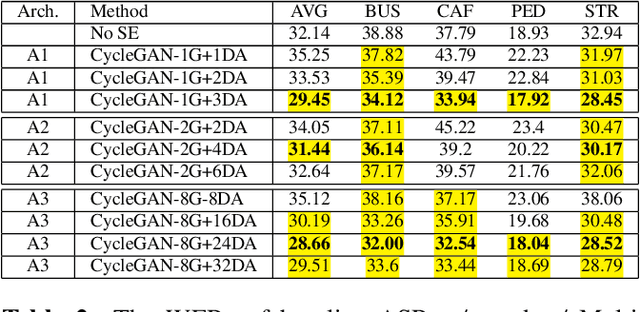
This paper presents our latest investigations on improving automatic speech recognition for noisy speech via speech enhancement. We propose a novel method named Multi-discriminators CycleGAN to reduce noise of input speech and therefore improve the automatic speech recognition performance. Our proposed method leverages the CycleGAN framework for speech enhancement without any parallel data and improve it by introducing multiple discriminators that check different frequency areas. Furthermore, we show that training multiple generators on homogeneous subset of the training data is better than training one generator on all the training data. We evaluate our method on CHiME-3 data set and observe up to 10.03% relatively WER improvement on the development set and up to 14.09% on the evaluation set.
Recycling an anechoic pre-trained speech separation deep neural network for binaural dereverberation of a single source
Aug 09, 2022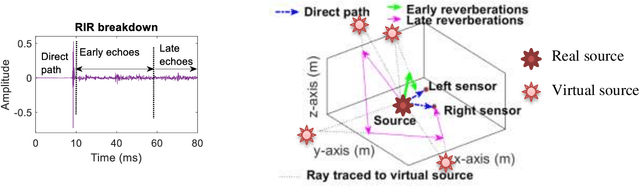

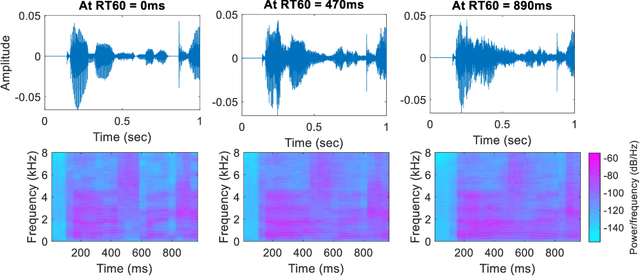

Reverberation results in reduced intelligibility for both normal and hearing-impaired listeners. This paper presents a novel psychoacoustic approach of dereverberation of a single speech source by recycling a pre-trained binaural anechoic speech separation neural network. As training the deep neural network (DNN) is a lengthy and computationally expensive process, the advantage of using a pre-trained separation network for dereverberation is that the network does not need to be retrained, saving both time and computational resources. The interaural cues of a reverberant source are given to this pretrained neural network to discriminate between the direct path signal and the reverberant speech. The results show an average improvement of 1.3% in signal intelligibility, 0.83 dB in SRMR (signal to reverberation energy ratio) and 0.16 points in perceptual evaluation of speech quality (PESQ) over other state-of-the-art signal processing dereverberation algorithms and 14% in intelligibility and 0.35 points in quality over orthogonal matching pursuit with spectral subtraction (OSS), a machine learning based dereverberation algorithm.
SVTS: Scalable Video-to-Speech Synthesis
May 04, 2022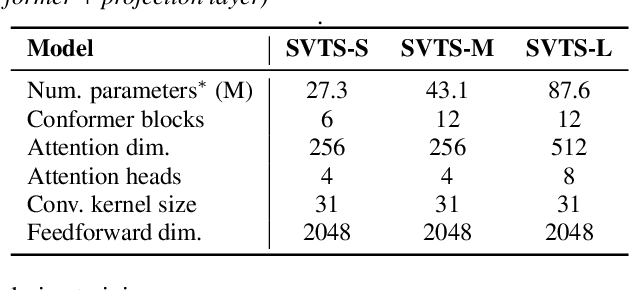
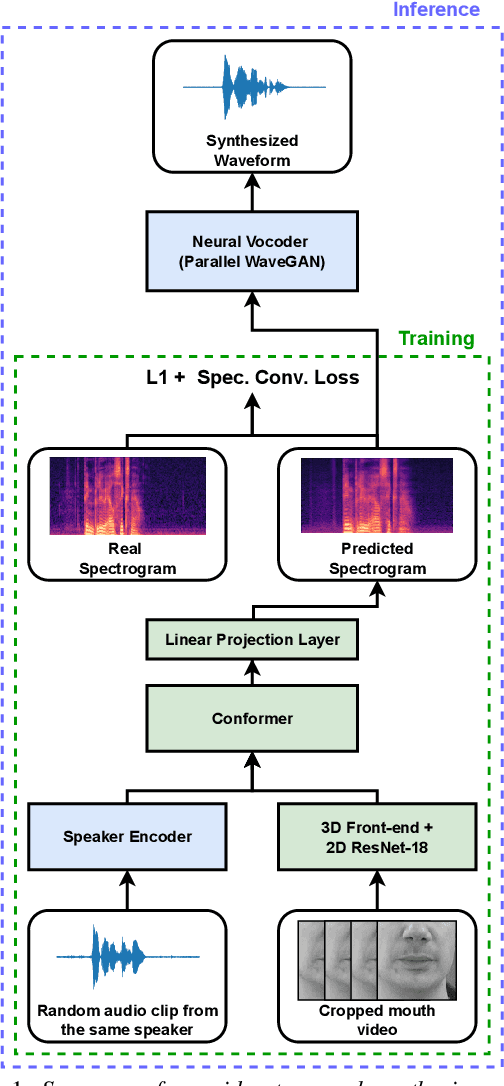
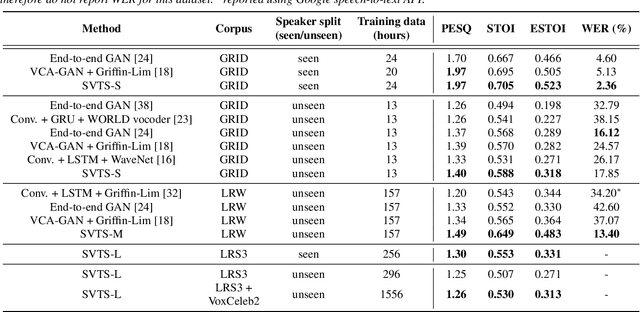
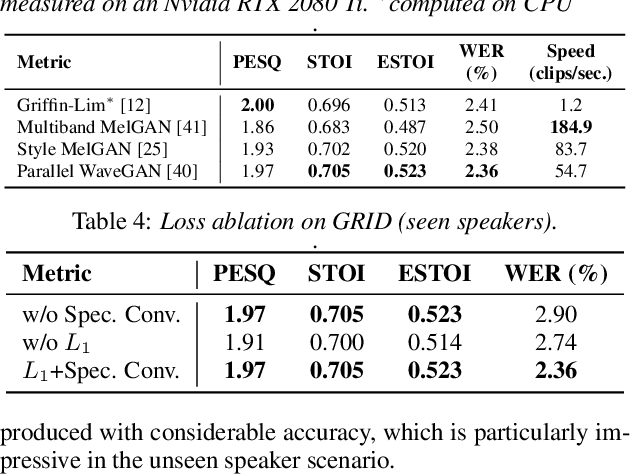
Video-to-speech synthesis (also known as lip-to-speech) refers to the translation of silent lip movements into the corresponding audio. This task has received an increasing amount of attention due to its self-supervised nature (i.e., can be trained without manual labelling) combined with the ever-growing collection of audio-visual data available online. Despite these strong motivations, contemporary video-to-speech works focus mainly on small- to medium-sized corpora with substantial constraints in both vocabulary and setting. In this work, we introduce a scalable video-to-speech framework consisting of two components: a video-to-spectrogram predictor and a pre-trained neural vocoder, which converts the mel-frequency spectrograms into waveform audio. We achieve state-of-the art results for GRID and considerably outperform previous approaches on LRW. More importantly, by focusing on spectrogram prediction using a simple feedforward model, we can efficiently and effectively scale our method to very large and unconstrained datasets: To the best of our knowledge, we are the first to show intelligible results on the challenging LRS3 dataset.
Textless Speech-to-Speech Translation on Real Data
Dec 15, 2021
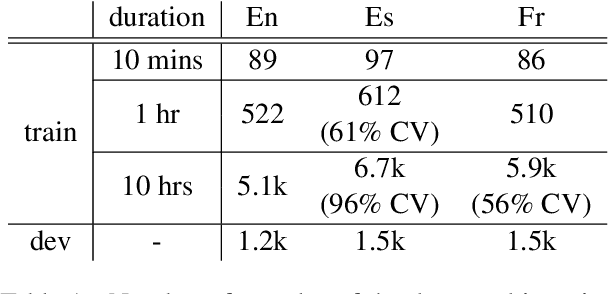
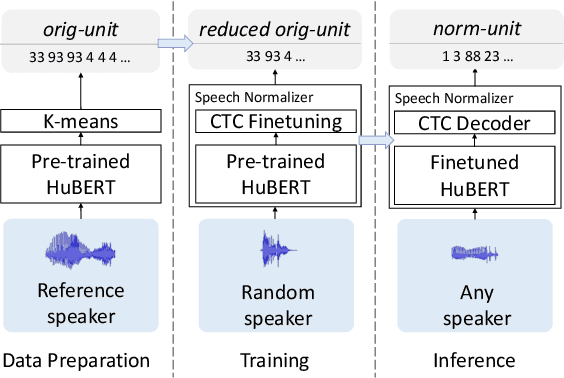
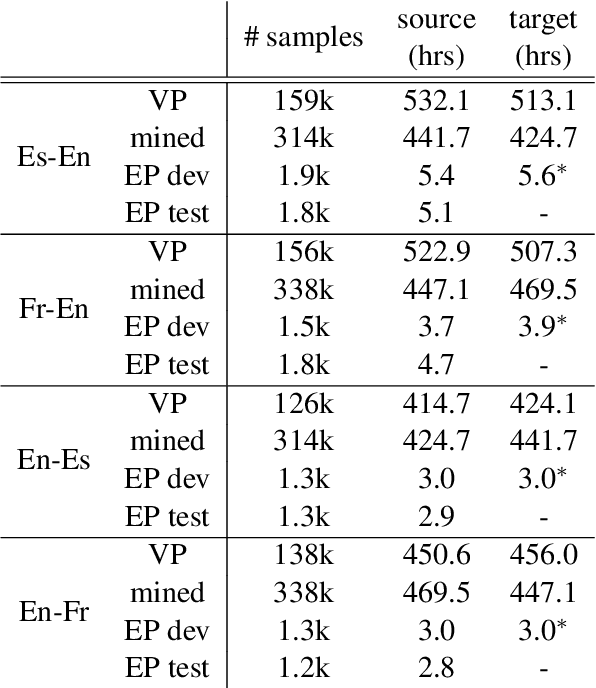
We present a textless speech-to-speech translation (S2ST) system that can translate speech from one language into another language and can be built without the need of any text data. Different from existing work in the literature, we tackle the challenge in modeling multi-speaker target speech and train the systems with real-world S2ST data. The key to our approach is a self-supervised unit-based speech normalization technique, which finetunes a pre-trained speech encoder with paired audios from multiple speakers and a single reference speaker to reduce the variations due to accents, while preserving the lexical content. With only 10 minutes of paired data for speech normalization, we obtain on average 3.2 BLEU gain when training the S2ST model on the \vp~S2ST dataset, compared to a baseline trained on un-normalized speech target. We also incorporate automatically mined S2ST data and show an additional 2.0 BLEU gain. To our knowledge, we are the first to establish a textless S2ST technique that can be trained with real-world data and works for multiple language pairs.
Guided-TTS:Text-to-Speech with Untranscribed Speech
Nov 23, 2021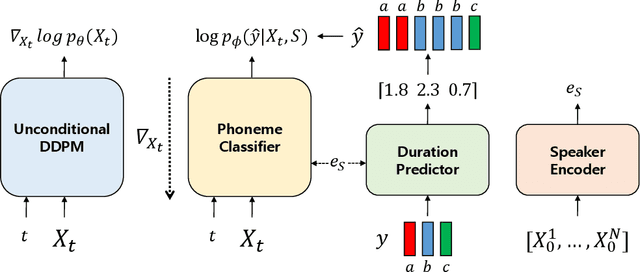

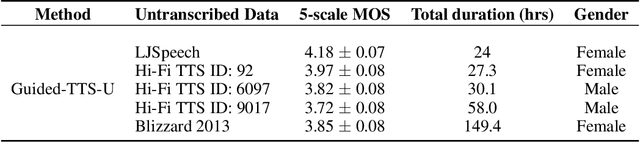
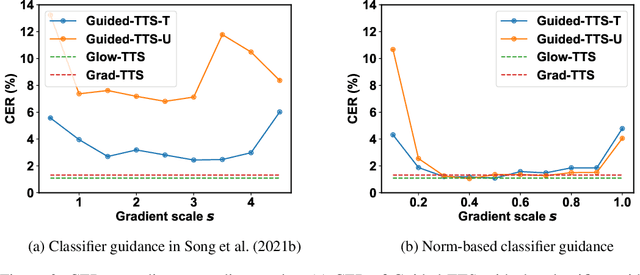
Most neural text-to-speech (TTS) models require <speech, transcript> paired data from the desired speaker for high-quality speech synthesis, which limits the usage of large amounts of untranscribed data for training. In this work, we present Guided-TTS, a high-quality TTS model that learns to generate speech from untranscribed speech data. Guided-TTS combines an unconditional diffusion probabilistic model with a separately trained phoneme classifier for text-to-speech. By modeling the unconditional distribution for speech, our model can utilize the untranscribed data for training. For text-to-speech synthesis, we guide the generative process of the unconditional DDPM via phoneme classification to produce mel-spectrograms from the conditional distribution given transcript. We show that Guided-TTS achieves comparable performance with the existing methods without any transcript for LJSpeech. Our results further show that a single speaker-dependent phoneme classifier trained on multispeaker large-scale data can guide unconditional DDPMs for various speakers to perform TTS.
Direct simultaneous speech to speech translation
Oct 15, 2021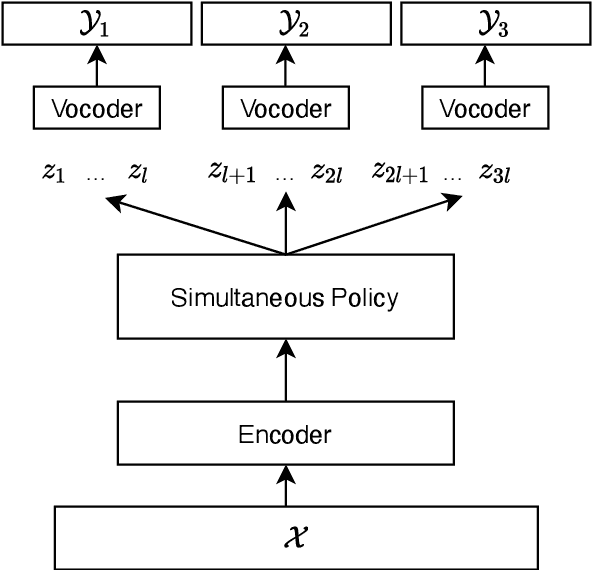
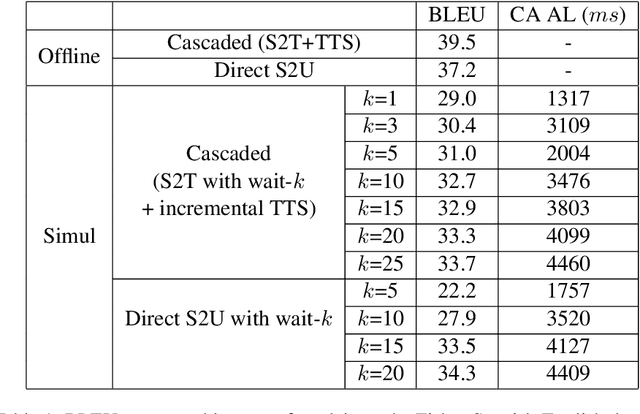
We present the first direct simultaneous speech-to-speech translation (Simul-S2ST) model, with the ability to start generating translation in the target speech before consuming the full source speech content and independently from intermediate text representations. Our approach leverages recent progress on direct speech-to-speech translation with discrete units. Instead of continuous spectrogram features, a sequence of direct representations, which are learned in a unsupervised manner, are predicted from the model and passed directly to a vocoder for speech synthesis. The simultaneous policy then operates on source speech features and target discrete units. Finally, a vocoder synthesize the target speech from discrete units on-the-fly. We carry out numerical studies to compare cascaded and direct approach on Fisher Spanish-English dataset.
Filter and evolve: progressive pseudo label refining for semi-supervised automatic speech recognition
Oct 28, 2022
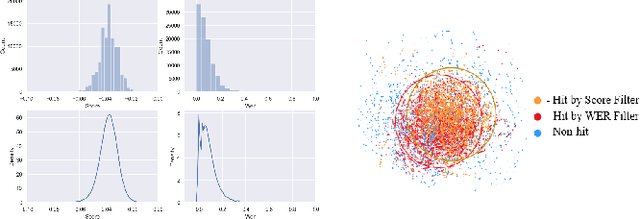
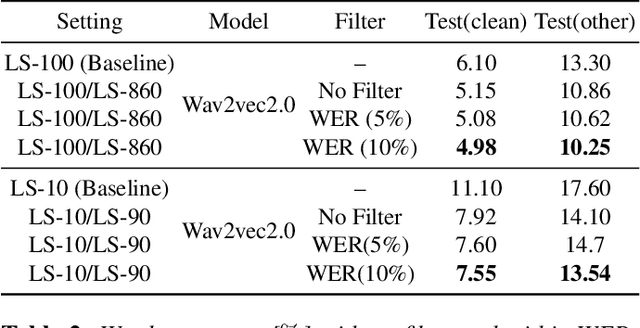
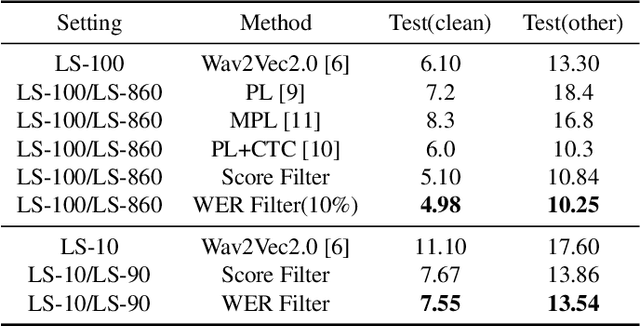
Fine tuning self supervised pretrained models using pseudo labels can effectively improve speech recognition performance. But, low quality pseudo labels can misguide decision boundaries and degrade performance. We propose a simple yet effective strategy to filter low quality pseudo labels to alleviate this problem. Specifically, pseudo-labels are produced over the entire training set and filtered via average probability scores calculated from the model output. Subsequently, an optimal percentage of utterances with high probability scores are considered reliable training data with trustworthy labels. The model is iteratively updated to correct the unreliable pseudo labels to minimize the effect of noisy labels. The process above is repeated until unreliable pseudo abels have been adequately corrected. Extensive experiments on LibriSpeech show that these filtered samples enable the refined model to yield more correct predictions, leading to better ASR performances under various experimental settings.
Improving Few-Shot Learning for Talking Face System with TTS Data Augmentation
Mar 09, 2023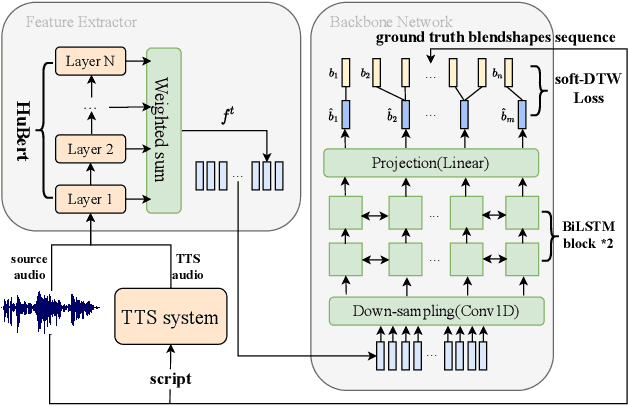
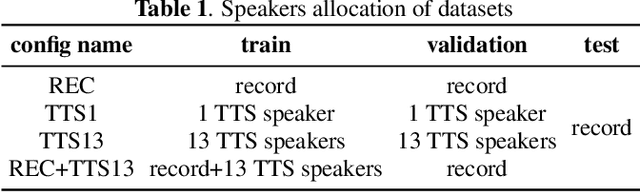
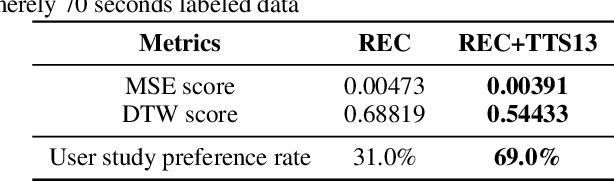
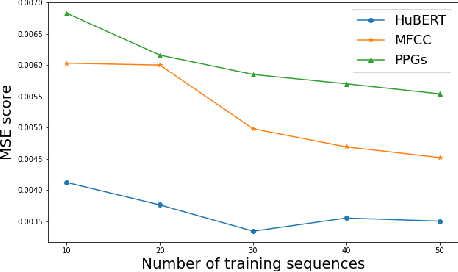
Audio-driven talking face has attracted broad interest from academia and industry recently. However, data acquisition and labeling in audio-driven talking face are labor-intensive and costly. The lack of data resource results in poor synthesis effect. To alleviate this issue, we propose to use TTS (Text-To-Speech) for data augmentation to improve few-shot ability of the talking face system. The misalignment problem brought by the TTS audio is solved with the introduction of soft-DTW, which is first adopted in the talking face task. Moreover, features extracted by HuBERT are explored to utilize underlying information of audio, and found to be superior over other features. The proposed method achieves 17%, 14%, 38% dominance on MSE score, DTW score and user study preference repectively over the baseline model, which shows the effectiveness of improving few-shot learning for talking face system with TTS augmentation.
Transfer Learning Framework for Low-Resource Text-to-Speech using a Large-Scale Unlabeled Speech Corpus
Mar 29, 2022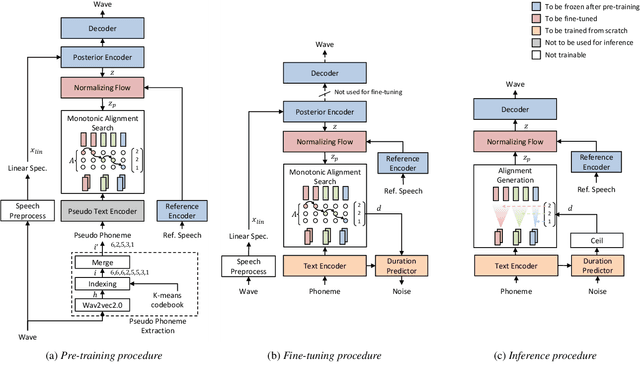
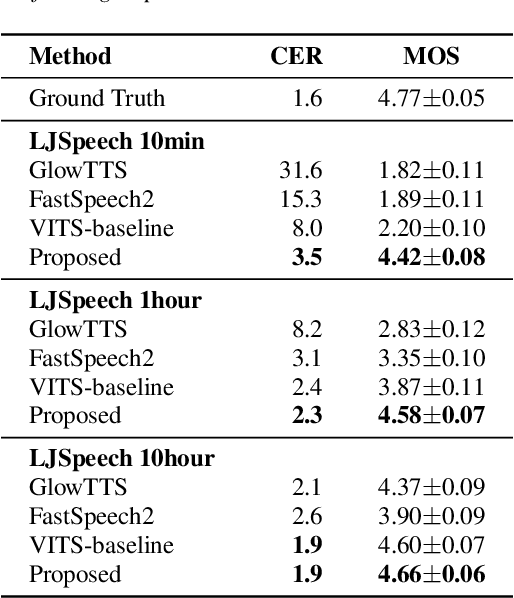
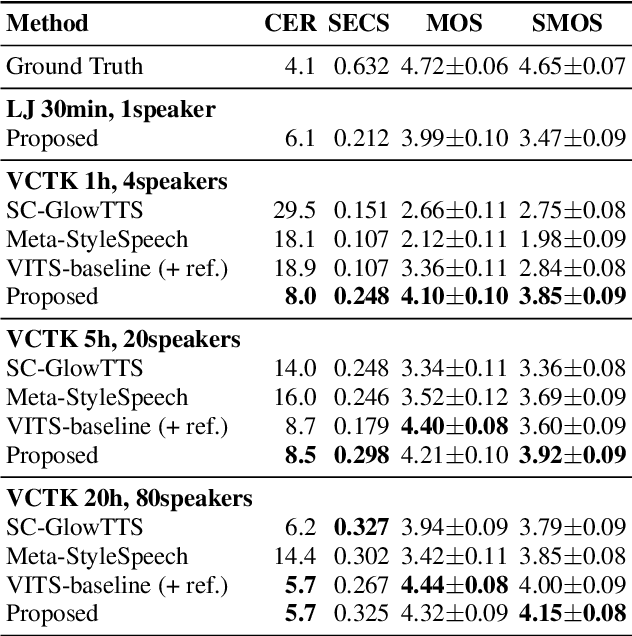
Training a text-to-speech (TTS) model requires a large scale text labeled speech corpus, which is troublesome to collect. In this paper, we propose a transfer learning framework for TTS that utilizes a large amount of unlabeled speech dataset for pre-training. By leveraging wav2vec2.0 representation, unlabeled speech can highly improve performance, especially in the lack of labeled speech. We also extend the proposed method to zero-shot multi-speaker TTS (ZS-TTS). The experimental results verify the effectiveness of the proposed method in terms of naturalness, intelligibility, and speaker generalization. We highlight that the single speaker TTS model fine-tuned on the only 10 minutes of labeled dataset outperforms the other baselines, and the ZS-TTS model fine-tuned on the only 30 minutes of single speaker dataset can generate the voice of the arbitrary speaker, by pre-training on unlabeled multi-speaker speech corpus.
StyleTTS: A Style-Based Generative Model for Natural and Diverse Text-to-Speech Synthesis
May 30, 2022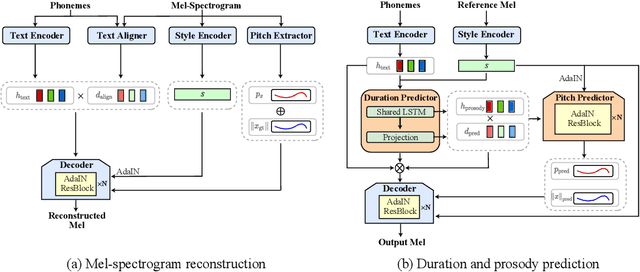

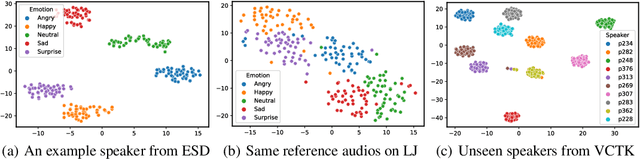

Text-to-Speech (TTS) has recently seen great progress in synthesizing high-quality speech owing to the rapid development of parallel TTS systems, but producing speech with naturalistic prosodic variations, speaking styles and emotional tones remains challenging. Moreover, since duration and speech are generated separately, parallel TTS models still have problems finding the best monotonic alignments that are crucial for naturalistic speech synthesis. Here, we propose StyleTTS, a style-based generative model for parallel TTS that can synthesize diverse speech with natural prosody from a reference speech utterance. With novel Transferable Monotonic Aligner (TMA) and duration-invariant data augmentation schemes, our method significantly outperforms state-of-the-art models on both single and multi-speaker datasets in subjective tests of speech naturalness and speaker similarity. Through self-supervised learning of the speaking styles, our model can synthesize speech with the same prosodic and emotional tone as any given reference speech without the need for explicitly labeling these categories.