 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Exploiting Audio-Visual Features with Pretrained AV-HuBERT for Multi-Modal Dysarthric Speech Reconstruction
Jan 31, 2024
Dysarthric speech reconstruction (DSR) aims to transform dysarthric speech into normal speech by improving the intelligibility and naturalness. This is a challenging task especially for patients with severe dysarthria and speaking in complex, noisy acoustic environments. To address these challenges, we propose a novel multi-modal framework to utilize visual information, e.g., lip movements, in DSR as extra clues for reconstructing the highly abnormal pronunciations. The multi-modal framework consists of: (i) a multi-modal encoder to extract robust phoneme embeddings from dysarthric speech with auxiliary visual features; (ii) a variance adaptor to infer the normal phoneme duration and pitch contour from the extracted phoneme embeddings; (iii) a speaker encoder to encode the speaker's voice characteristics; and (iv) a mel-decoder to generate the reconstructed mel-spectrogram based on the extracted phoneme embeddings, prosodic features and speaker embeddings. Both objective and subjective evaluations conducted on the commonly used UASpeech corpus show that our proposed approach can achieve significant improvements over baseline systems in terms of speech intelligibility and naturalness, especially for the speakers with more severe symptoms. Compared with original dysarthric speech, the reconstructed speech achieves 42.1\% absolute word error rate reduction for patients with more severe dysarthria levels.
Towards Event Extraction from Speech with Contextual Clues
Jan 27, 2024While text-based event extraction has been an active research area and has seen successful application in many domains, extracting semantic events from speech directly is an under-explored problem. In this paper, we introduce the Speech Event Extraction (SpeechEE) task and construct three synthetic training sets and one human-spoken test set. Compared to event extraction from text, SpeechEE poses greater challenges mainly due to complex speech signals that are continuous and have no word boundaries. Additionally, unlike perceptible sound events, semantic events are more subtle and require a deeper understanding. To tackle these challenges, we introduce a sequence-to-structure generation paradigm that can produce events from speech signals in an end-to-end manner, together with a conditioned generation method that utilizes speech recognition transcripts as the contextual clue. We further propose to represent events with a flat format to make outputs more natural language-like. Our experimental results show that our method brings significant improvements on all datasets, achieving a maximum F1 gain of 10.7%. The code and datasets are released on https://github.com/jodie-kang/SpeechEE.
PeriodGrad: Towards Pitch-Controllable Neural Vocoder Based on a Diffusion Probabilistic Model
Feb 22, 2024This paper presents a neural vocoder based on a denoising diffusion probabilistic model (DDPM) incorporating explicit periodic signals as auxiliary conditioning signals. Recently, DDPM-based neural vocoders have gained prominence as non-autoregressive models that can generate high-quality waveforms. The neural vocoders based on DDPM have the advantage of training with a simple time-domain loss. In practical applications, such as singing voice synthesis, there is a demand for neural vocoders to generate high-fidelity speech waveforms with flexible pitch control. However, conventional DDPM-based neural vocoders struggle to generate speech waveforms under such conditions. Our proposed model aims to accurately capture the periodic structure of speech waveforms by incorporating explicit periodic signals. Experimental results show that our model improves sound quality and provides better pitch control than conventional DDPM-based neural vocoders.
On combining acoustic and modulation spectrograms in an attention LSTM-based system for speech intelligibility level classification
Feb 05, 2024Speech intelligibility can be affected by multiple factors, such as noisy environments, channel distortions or physiological issues. In this work, we deal with the problem of automatic prediction of the speech intelligibility level in this latter case. Starting from our previous work, a non-intrusive system based on LSTM networks with attention mechanism designed for this task, we present two main contributions. In the first one, it is proposed the use of per-frame modulation spectrograms as input features, instead of compact representations derived from them that discard important temporal information. In the second one, two different strategies for the combination of per-frame acoustic log-mel and modulation spectrograms into the LSTM framework are explored: at decision level or late fusion and at utterance level or Weighted-Pooling (WP) fusion. The proposed models are evaluated with the UA-Speech database that contains dysarthric speech with different degrees of severity. On the one hand, results show that attentional LSTM networks are able to adequately modeling the modulation spectrograms sequences producing similar classification rates as in the case of log-mel spectrograms. On the other hand, both combination strategies, late and WP fusion, outperform the single-feature systems, suggesting that per-frame log-mel and modulation spectrograms carry complementary information for the task of speech intelligibility prediction, than can be effectively exploited by the LSTM-based architectures, being the system with the WP fusion strategy and Attention-Pooling the one that achieves best results.
Experimental Study: Enhancing Voice Spoofing Detection Models with wav2vec 2.0
Feb 27, 2024Conventional spoofing detection systems have heavily relied on the use of handcrafted features derived from speech data. However, a notable shift has recently emerged towards the direct utilization of raw speech waveforms, as demonstrated by methods like SincNet filters. This shift underscores the demand for more sophisticated audio sample features. Moreover, the success of deep learning models, particularly those utilizing large pretrained wav2vec 2.0 as a featurization front-end, highlights the importance of refined feature encoders. In response, this research assessed the representational capability of wav2vec 2.0 as an audio feature extractor, modifying the size of its pretrained Transformer layers through two key adjustments: (1) selecting a subset of layers starting from the leftmost one and (2) fine-tuning a portion of the selected layers from the rightmost one. We complemented this analysis with five spoofing detection back-end models, with a primary focus on AASIST, enabling us to pinpoint the optimal configuration for the selection and fine-tuning process. In contrast to conventional handcrafted features, our investigation identified several spoofing detection systems that achieve state-of-the-art performance in the ASVspoof 2019 LA dataset. This comprehensive exploration offers valuable insights into feature selection strategies, advancing the field of spoofing detection.
Can Interpretability Layouts Influence Human Perception of Offensive Sentences?
Mar 01, 2024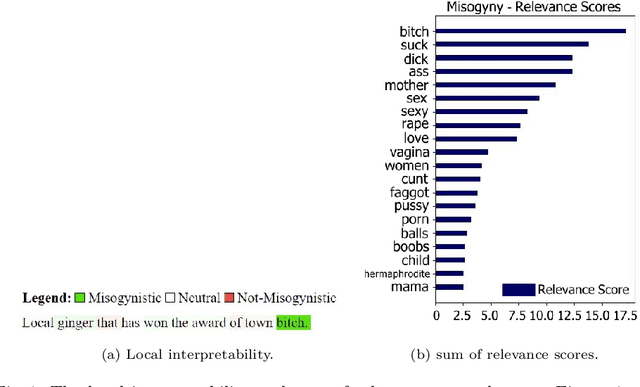
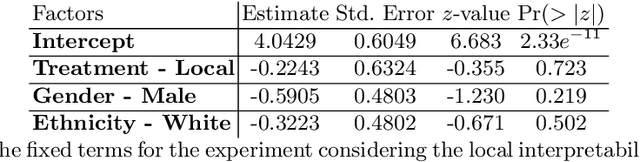
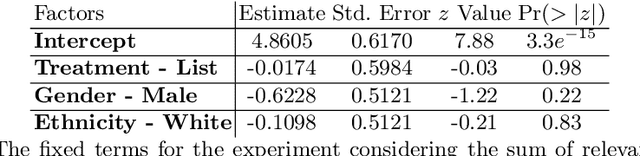
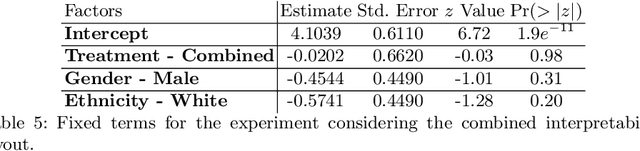
This paper conducts a user study to assess whether three machine learning (ML) interpretability layouts can influence participants' views when evaluating sentences containing hate speech, focusing on the "Misogyny" and "Racism" classes. Given the existence of divergent conclusions in the literature, we provide empirical evidence on using ML interpretability in online communities through statistical and qualitative analyses of questionnaire responses. The Generalized Additive Model estimates participants' ratings, incorporating within-subject and between-subject designs. While our statistical analysis indicates that none of the interpretability layouts significantly influences participants' views, our qualitative analysis demonstrates the advantages of ML interpretability: 1) triggering participants to provide corrective feedback in case of discrepancies between their views and the model, and 2) providing insights to evaluate a model's behavior beyond traditional performance metrics.
Mixture to Mixture: Leveraging Close-talk Mixtures as Weak-supervision for Speech Separation
Feb 14, 2024We propose mixture to mixture (M2M) training, a weakly-supervised neural speech separation algorithm that leverages close-talk mixtures as a weak supervision for training discriminative models to separate far-field mixtures. Our idea is that, for a target speaker, its close-talk mixture has a much higher signal-to-noise ratio (SNR) of the target speaker than any far-field mixtures, and hence could be utilized to design a weak supervision for separation. To realize this, at each training step we feed a far-field mixture to a deep neural network (DNN) to produce an intermediate estimate for each speaker, and, for each of considered close-talk and far-field microphones, we linearly filter the DNN estimates and optimize a loss so that the filtered estimates of all the speakers can sum up to the mixture captured by each of the considered microphones. Evaluation results on a 2-speaker separation task in simulated reverberant conditions show that M2M can effectively leverage close-talk mixtures as a weak supervision for separating far-field mixtures.
FaceChain-ImagineID: Freely Crafting High-Fidelity Diverse Talking Faces from Disentangled Audio
Mar 04, 2024
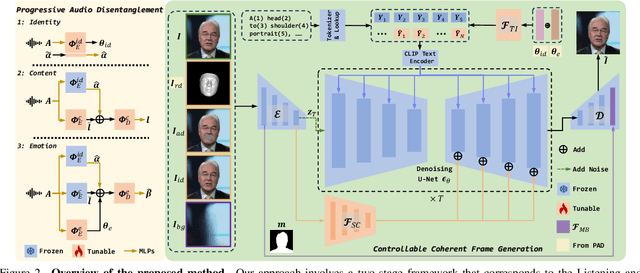
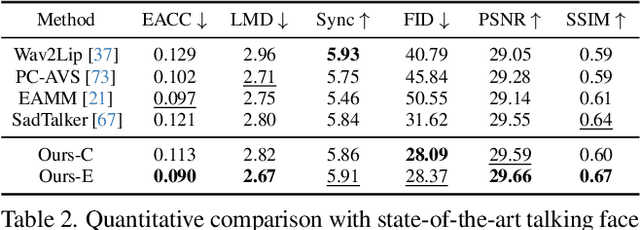
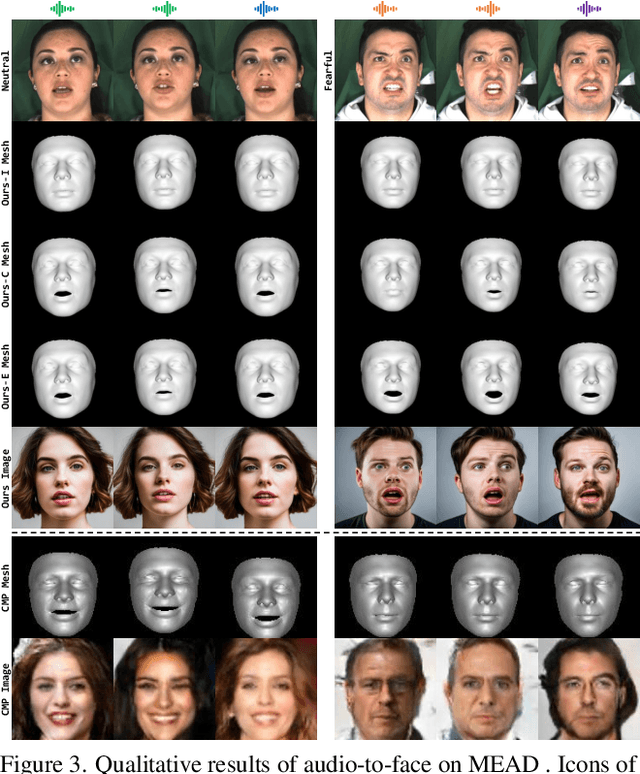
In this paper, we abstract the process of people hearing speech, extracting meaningful cues, and creating various dynamically audio-consistent talking faces, termed Listening and Imagining, into the task of high-fidelity diverse talking faces generation from a single audio. Specifically, it involves two critical challenges: one is to effectively decouple identity, content, and emotion from entangled audio, and the other is to maintain intra-video diversity and inter-video consistency. To tackle the issues, we first dig out the intricate relationships among facial factors and simplify the decoupling process, tailoring a Progressive Audio Disentanglement for accurate facial geometry and semantics learning, where each stage incorporates a customized training module responsible for a specific factor. Secondly, to achieve visually diverse and audio-synchronized animation solely from input audio within a single model, we introduce the Controllable Coherent Frame generation, which involves the flexible integration of three trainable adapters with frozen Latent Diffusion Models (LDMs) to focus on maintaining facial geometry and semantics, as well as texture and temporal coherence between frames. In this way, we inherit high-quality diverse generation from LDMs while significantly improving their controllability at a low training cost. Extensive experiments demonstrate the flexibility and effectiveness of our method in handling this paradigm. The codes will be released at https://github.com/modelscope/facechain.
Efficient data selection employing Semantic Similarity-based Graph Structures for model training
Feb 22, 2024Recent developments in natural language processing (NLP) have highlighted the need for substantial amounts of data for models to capture textual information accurately. This raises concerns regarding the computational resources and time required for training such models. This paper introduces Semantics for data SAliency in Model performance Estimation (SeSaME). It is an efficient data sampling mechanism solely based on textual information without passing the data through a compute-heavy model or other intensive pre-processing transformations. The application of this approach is demonstrated in the use case of low-resource automated speech recognition (ASR) models, which excessively rely on text-to-speech (TTS) calls when using augmented data. SeSaME learns to categorize new incoming data points into speech recognition difficulty buckets by employing semantic similarity-based graph structures and discrete ASR information from homophilous neighbourhoods through message passing. The results indicate reliable projections of ASR performance, with a 93% accuracy increase when using the proposed method compared to random predictions, bringing non-trivial information on the impact of textual representations in speech models. Furthermore, a series of experiments show both the benefits and challenges of using the ASR information on incoming data to fine-tune the model. We report a 7% drop in validation loss compared to random sampling, 7% WER drop with non-local aggregation when evaluating against a highly difficult dataset, and 1.8% WER drop with local aggregation and high semantic similarity between datasets.
Layer-Wise Analysis of Self-Supervised Acoustic Word Embeddings: A Study on Speech Emotion Recognition
Feb 04, 2024The efficacy of self-supervised speech models has been validated, yet the optimal utilization of their representations remains challenging across diverse tasks. In this study, we delve into Acoustic Word Embeddings (AWEs), a fixed-length feature derived from continuous representations, to explore their advantages in specific tasks. AWEs have previously shown utility in capturing acoustic discriminability. In light of this, we propose measuring layer-wise similarity between AWEs and word embeddings, aiming to further investigate the inherent context within AWEs. Moreover, we evaluate the contribution of AWEs, in comparison to other types of speech features, in the context of Speech Emotion Recognition (SER). Through a comparative experiment and a layer-wise accuracy analysis on two distinct corpora, IEMOCAP and ESD, we explore differences between AWEs and raw self-supervised representations, as well as the proper utilization of AWEs alone and in combination with word embeddings. Our findings underscore the acoustic context conveyed by AWEs and showcase the highly competitive SER accuracies by appropriately employing AWEs.