 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Sentiment recognition of Italian elderly through domain adaptation on cross-corpus speech dataset
Nov 14, 2022
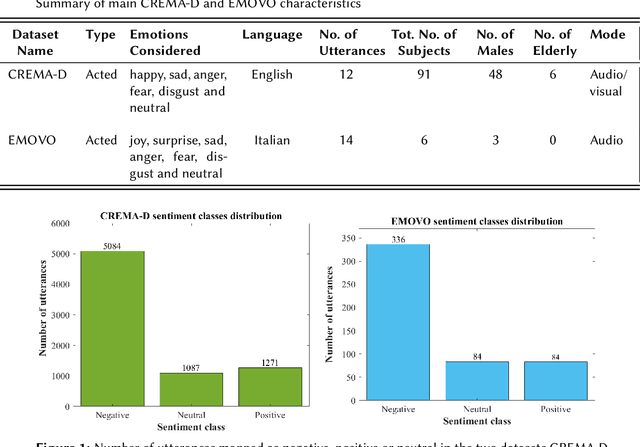
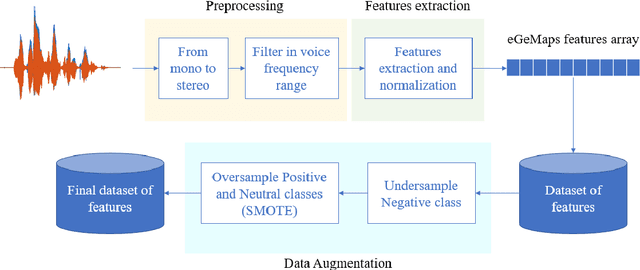
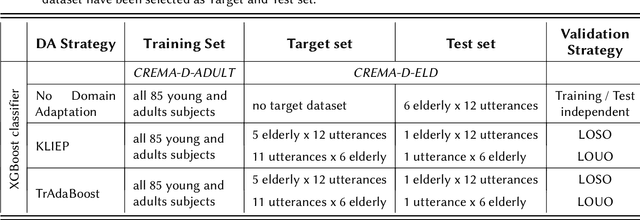
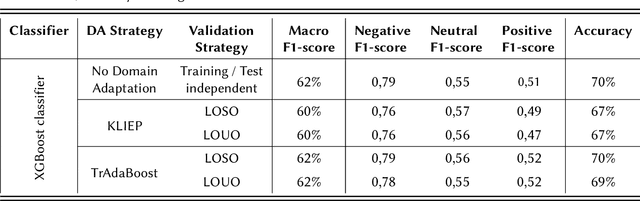
The aim of this work is to define a speech emotion recognition (SER) model able to recognize positive, neutral and negative emotions in natural conversations of Italian elderly people. Several datasets for SER are available in the literature. However most of them are in English or Chinese, have been recorded while actors and actresses pronounce short phrases and thus are not related to natural conversation. Moreover only few speeches among all the databases are related to elderly people. Therefore, in this work, a multi-language and multi-age corpus is considered merging a dataset in English, that includes also elderly people, with a dataset in Italian. A general model, trained on young and adult English actors and actresses is proposed, based on XGBoost. Then two strategies of domain adaptation are proposed to adapt the model either to elderly people and to Italian speakers. The results suggest that this approach increases the classification performance, underlining also that new datasets should be collected.
A Single Self-Supervised Model for Many Speech Modalities Enables Zero-Shot Modality Transfer
Jul 14, 2022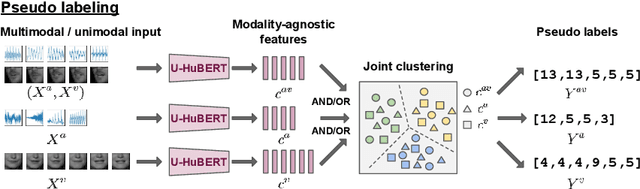
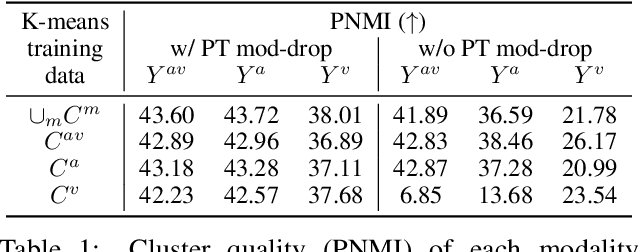
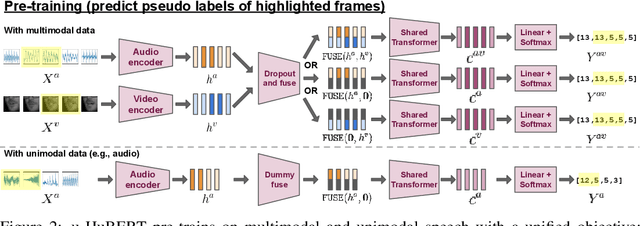
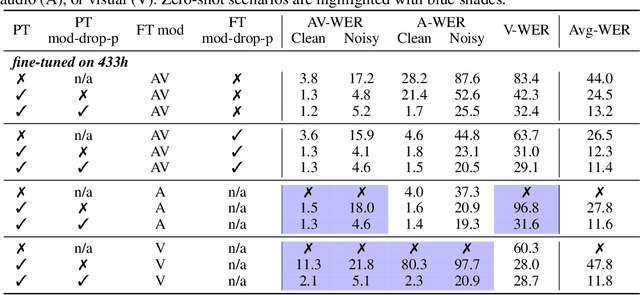
While audio-visual speech models can yield superior performance and robustness compared to audio-only models, their development and adoption are hindered by the lack of labeled and unlabeled audio-visual data and the cost to deploy one model per modality. In this paper, we present u-HuBERT, a self-supervised pre-training framework that can leverage both multimodal and unimodal speech with a unified masked cluster prediction objective. By utilizing modality dropout during pre-training, we demonstrate that a single fine-tuned model can achieve performance on par or better than the state-of-the-art modality-specific models. Moreover, our model fine-tuned only on audio can perform well with audio-visual and visual speech input, achieving zero-shot modality generalization for speech recognition and speaker verification. In particular, our single model yields 1.2%/1.4%/27.2% speech recognition word error rate on LRS3 with audio-visual/audio/visual input.
Synthesizing Dysarthric Speech Using Multi-talker TTS for Dysarthric Speech Recognition
Jan 27, 2022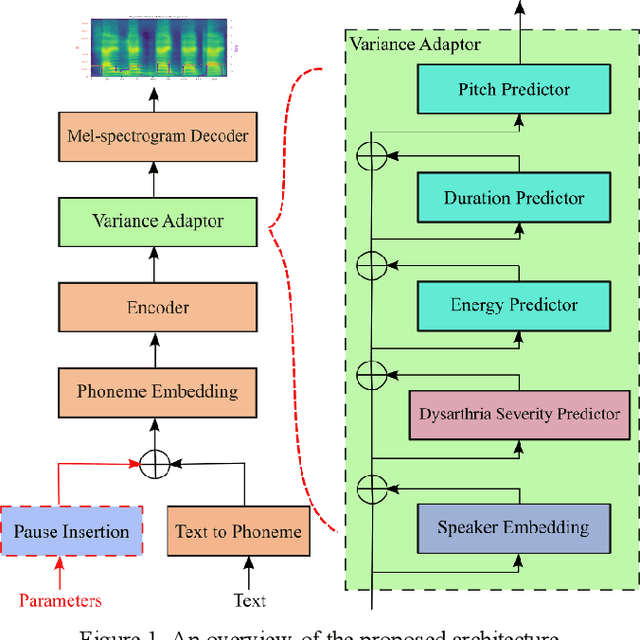
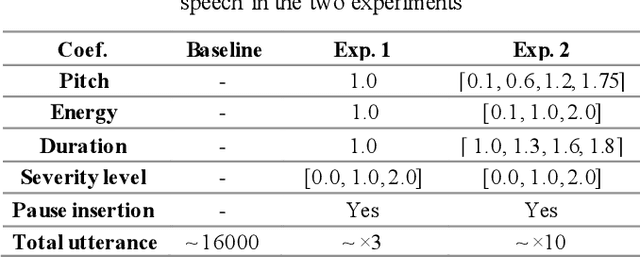
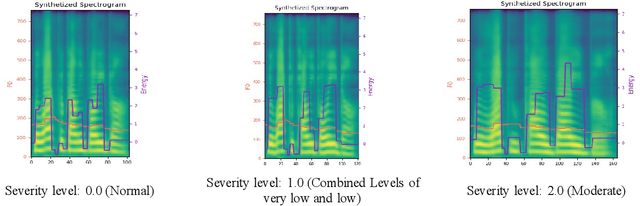
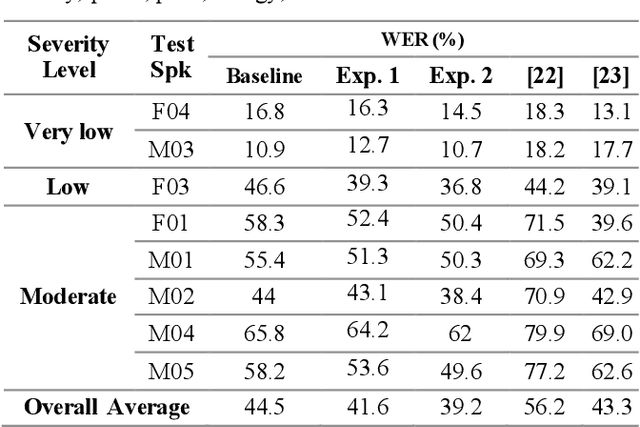
Dysarthria is a motor speech disorder often characterized by reduced speech intelligibility through slow, uncoordinated control of speech production muscles. Automatic Speech recognition (ASR) systems may help dysarthric talkers communicate more effectively. To have robust dysarthria-specific ASR, sufficient training speech is required, which is not readily available. Recent advances in Text-To-Speech (TTS) synthesis multi-speaker end-to-end TTS systems suggest the possibility of using synthesis for data augmentation. In this paper, we aim to improve multi-speaker end-to-end TTS systems to synthesize dysarthric speech for improved training of a dysarthria-specific DNN-HMM ASR. In the synthesized speech, we add dysarthria severity level and pause insertion mechanisms to other control parameters such as pitch, energy, and duration. Results show that a DNN-HMM model trained on additional synthetic dysarthric speech achieves WER improvement of 12.2% compared to the baseline, the addition of the severity level and pause insertion controls decrease WER by 6.5%, showing the effectiveness of adding these parameters. Audio samples are available at
Toward Fairness in Speech Recognition: Discovery and mitigation of performance disparities
Jul 22, 2022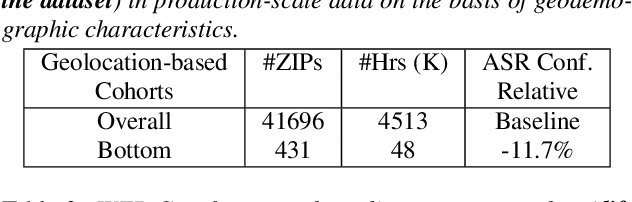
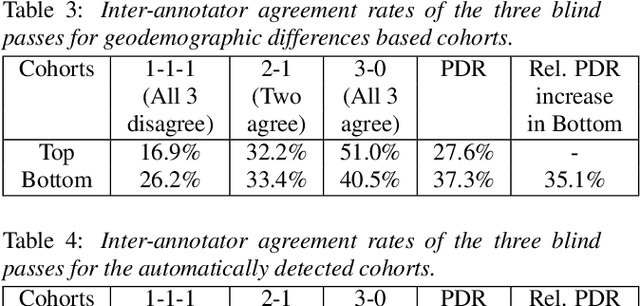
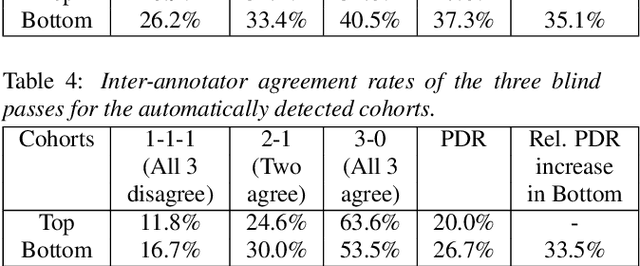

As for other forms of AI, speech recognition has recently been examined with respect to performance disparities across different user cohorts. One approach to achieve fairness in speech recognition is to (1) identify speaker cohorts that suffer from subpar performance and (2) apply fairness mitigation measures targeting the cohorts discovered. In this paper, we report on initial findings with both discovery and mitigation of performance disparities using data from a product-scale AI assistant speech recognition system. We compare cohort discovery based on geographic and demographic information to a more scalable method that groups speakers without human labels, using speaker embedding technology. For fairness mitigation, we find that oversampling of underrepresented cohorts, as well as modeling speaker cohort membership by additional input variables, reduces the gap between top- and bottom-performing cohorts, without deteriorating overall recognition accuracy.
Language Model-Based Emotion Prediction Methods for Emotional Speech Synthesis Systems
Jul 01, 2022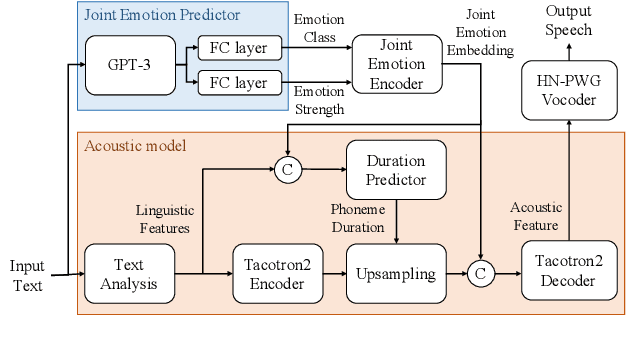

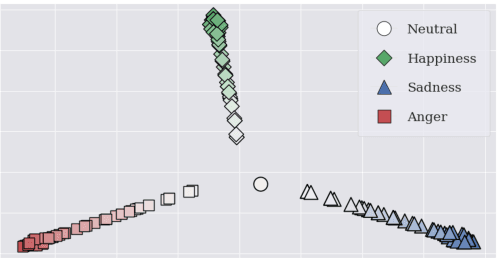

This paper proposes an effective emotional text-to-speech (TTS) system with a pre-trained language model (LM)-based emotion prediction method. Unlike conventional systems that require auxiliary inputs such as manually defined emotion classes, our system directly estimates emotion-related attributes from the input text. Specifically, we utilize generative pre-trained transformer (GPT)-3 to jointly predict both an emotion class and its strength in representing emotions coarse and fine properties, respectively. Then, these attributes are combined in the emotional embedding space and used as conditional features of the TTS model for generating output speech signals. Consequently, the proposed system can produce emotional speech only from text without any auxiliary inputs. Furthermore, because the GPT-3 enables to capture emotional context among the consecutive sentences, the proposed method can effectively handle the paragraph-level generation of emotional speech.
Provable Robustness for Streaming Models with a Sliding Window
Mar 28, 2023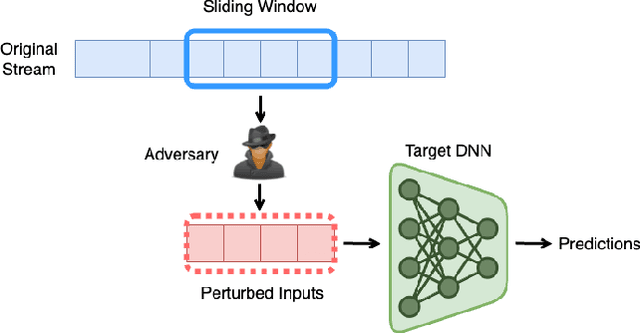
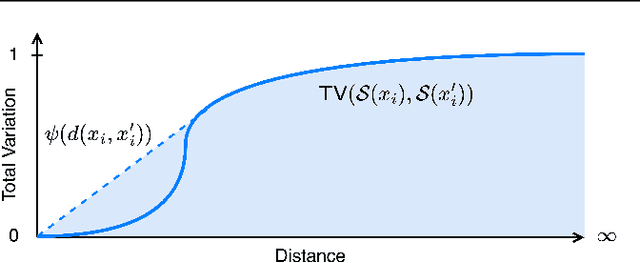

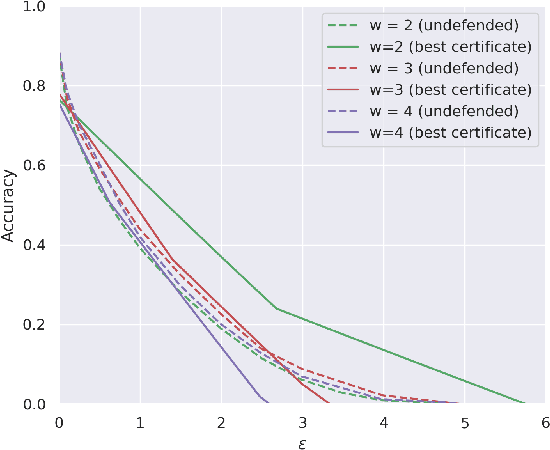
The literature on provable robustness in machine learning has primarily focused on static prediction problems, such as image classification, in which input samples are assumed to be independent and model performance is measured as an expectation over the input distribution. Robustness certificates are derived for individual input instances with the assumption that the model is evaluated on each instance separately. However, in many deep learning applications such as online content recommendation and stock market analysis, models use historical data to make predictions. Robustness certificates based on the assumption of independent input samples are not directly applicable in such scenarios. In this work, we focus on the provable robustness of machine learning models in the context of data streams, where inputs are presented as a sequence of potentially correlated items. We derive robustness certificates for models that use a fixed-size sliding window over the input stream. Our guarantees hold for the average model performance across the entire stream and are independent of stream size, making them suitable for large data streams. We perform experiments on speech detection and human activity recognition tasks and show that our certificates can produce meaningful performance guarantees against adversarial perturbations.
Improving Language Identification of Accented Speech
Apr 01, 2022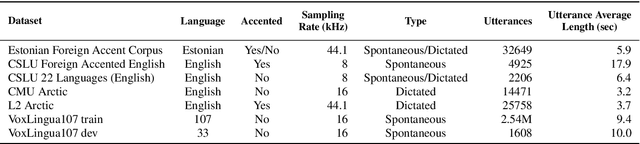
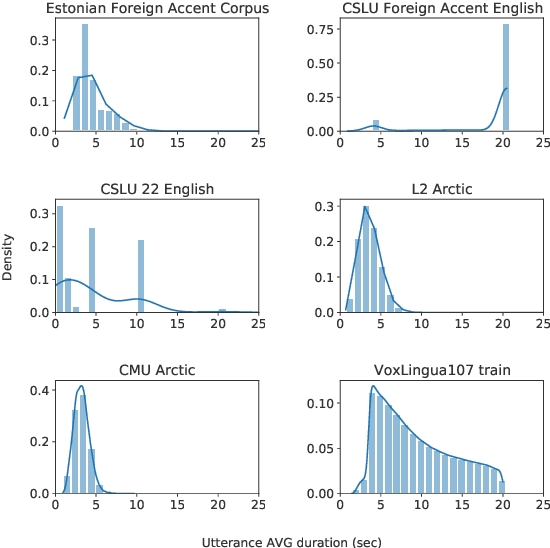
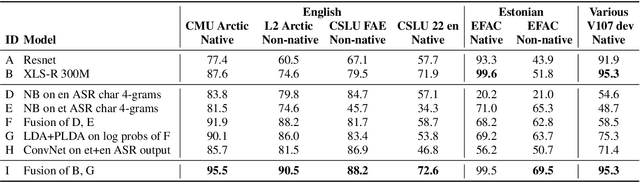
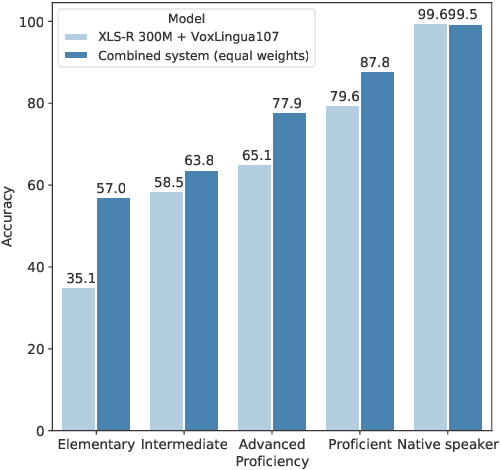
Language identification from speech is a common preprocessing step in many spoken language processing systems. In recent years, this field has seen a fast progress, mostly due to the use of self-supervised models pretrained on multilingual data and the use of large training corpora. This paper shows that for speech with a non-native or regional accent, the accuracy of spoken language identification systems drops dramatically, and that the accuracy of identifying the language is inversely correlated with the strength of the accent. We also show that using the output of a lexicon-free speech recognition system of the particular language helps to improve language identification performance on accented speech by a large margin, without sacrificing accuracy on native speech. We obtain relative error rate reductions ranging from to 35 to 63% over the state-of-the-art model across several non-native speech datasets.
Crossword: A Semantic Approach to Data Compression via Masking
Apr 03, 2023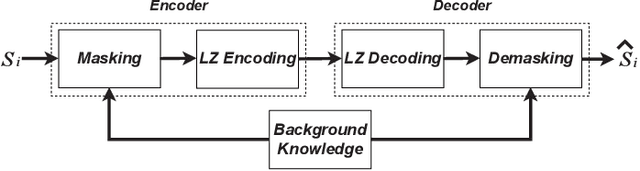
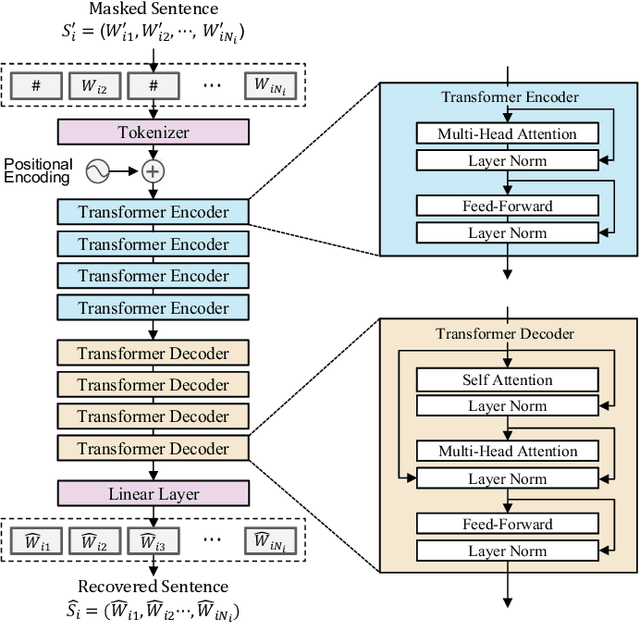
The traditional methods for data compression are typically based on the symbol-level statistics, with the information source modeled as a long sequence of i.i.d. random variables or a stochastic process, thus establishing the fundamental limit as entropy for lossless compression and as mutual information for lossy compression. However, the source (including text, music, and speech) in the real world is often statistically ill-defined because of its close connection to human perception, and thus the model-driven approach can be quite suboptimal. This study places careful emphasis on English text and exploits its semantic aspect to enhance the compression efficiency further. The main idea stems from the puzzle crossword, observing that the hidden words can still be precisely reconstructed so long as some key letters are provided. The proposed masking-based strategy resembles the above game. In a nutshell, the encoder evaluates the semantic importance of each word according to the semantic loss and then masks the minor ones, while the decoder aims to recover the masked words from the semantic context by means of the Transformer. Our experiments show that the proposed semantic approach can achieve much higher compression efficiency than the traditional methods such as Huffman code and UTF-8 code, while preserving the meaning in the target text to a great extent.
Trustera: A Live Conversation Redaction System
Mar 16, 2023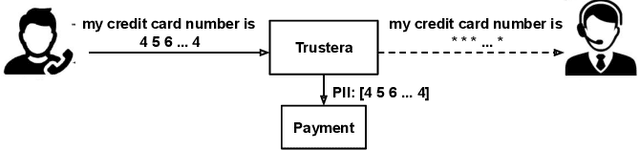
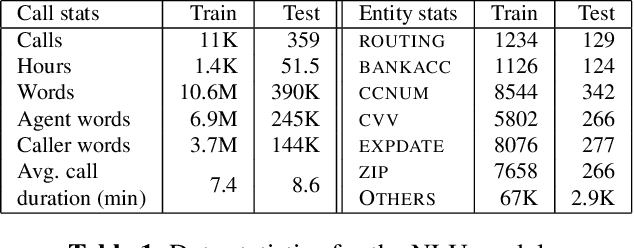

Trustera, the first functional system that redacts personally identifiable information (PII) in real-time spoken conversations to remove agents' need to hear sensitive information while preserving the naturalness of live customer-agent conversations. As opposed to post-call redaction, audio masking starts as soon as the customer begins speaking to a PII entity. This significantly reduces the risk of PII being intercepted or stored in insecure data storage. Trustera's architecture consists of a pipeline of automatic speech recognition, natural language understanding, and a live audio redactor module. The system's goal is three-fold: redact entities that are PII, mask the audio that goes to the agent, and at the same time capture the entity, so that the captured PII can be used for a payment transaction or caller identification. Trustera is currently being used by thousands of agents to secure customers' sensitive information.