 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Improving the quality of neural TTS using long-form content and multi-speaker multi-style modeling
Dec 20, 2022
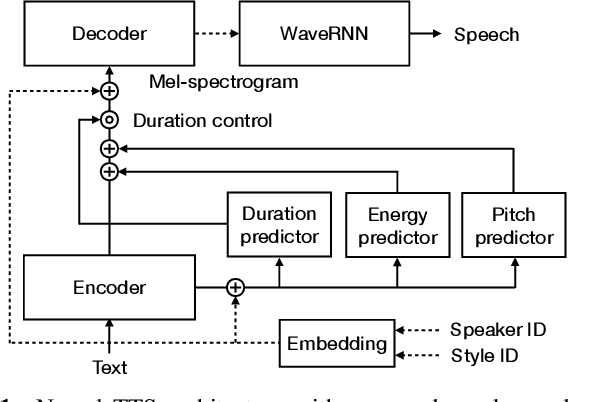
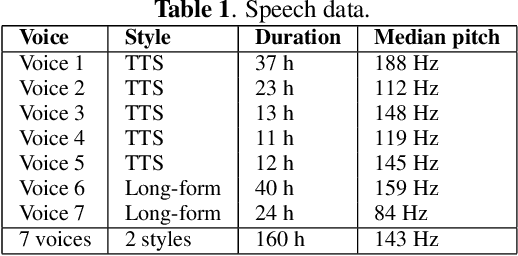
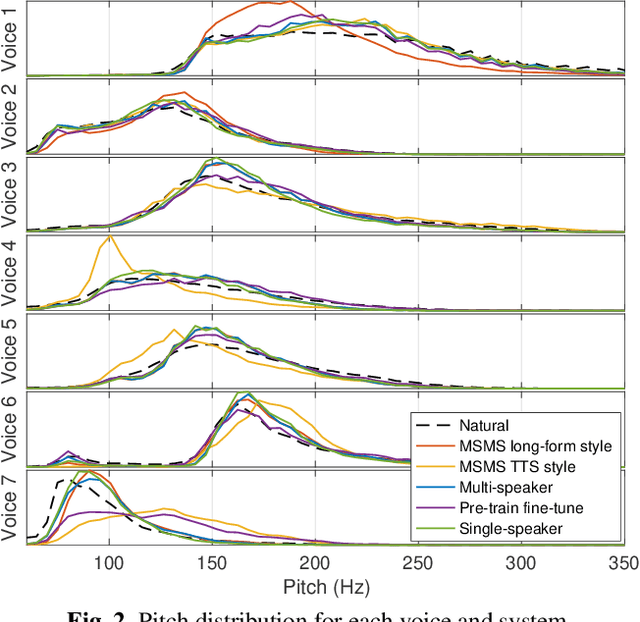
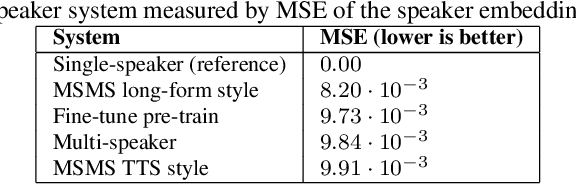
Neural text-to-speech (TTS) can provide quality close to natural speech if an adequate amount of high-quality speech material is available for training. However, acquiring speech data for TTS training is costly and time-consuming, especially if the goal is to generate different speaking styles. In this work, we show that we can transfer speaking style across speakers and improve the quality of synthetic speech by training a multi-speaker multi-style (MSMS) model with long-form recordings, in addition to regular TTS recordings. In particular, we show that 1) multi-speaker modeling improves the overall TTS quality, 2) the proposed MSMS approach outperforms pre-training and fine-tuning approach when utilizing additional multi-speaker data, and 3) long-form speaking style is highly rated regardless of the target text domain.
Cross-modal Contrastive Learning for Speech Translation
May 05, 2022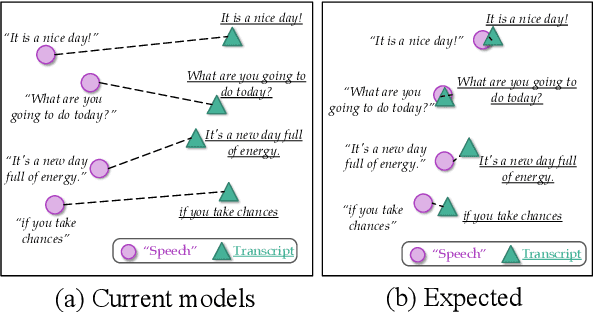
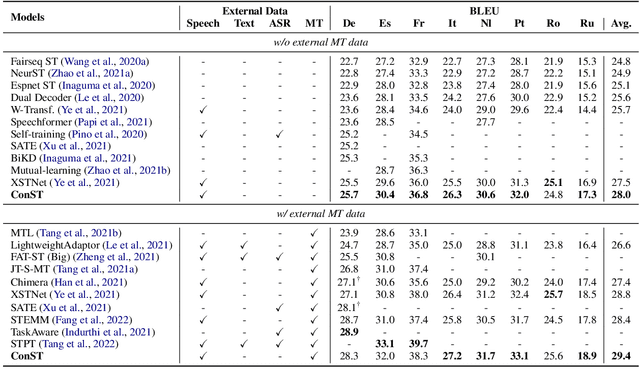
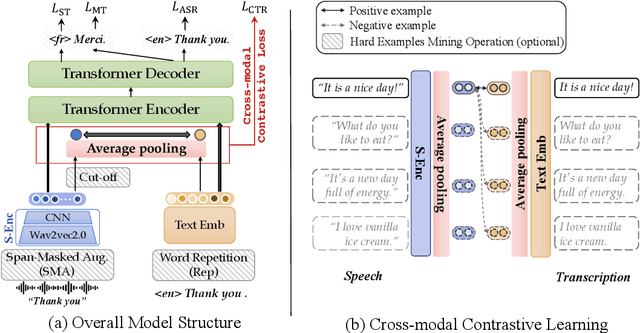
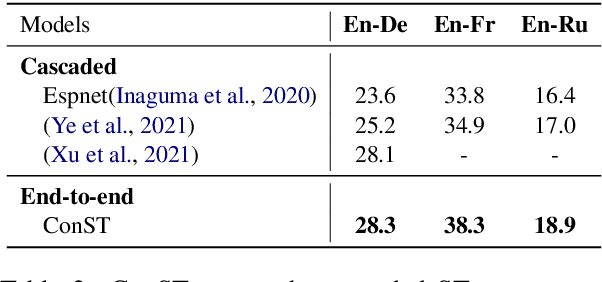
How can we learn unified representations for spoken utterances and their written text? Learning similar representations for semantically similar speech and text is important for speech translation. To this end, we propose ConST, a cross-modal contrastive learning method for end-to-end speech-to-text translation. We evaluate ConST and a variety of previous baselines on a popular benchmark MuST-C. Experiments show that the proposed ConST consistently outperforms the previous methods on, and achieves an average BLEU of 29.4. The analysis further verifies that ConST indeed closes the representation gap of different modalities -- its learned representation improves the accuracy of cross-modal speech-text retrieval from 4% to 88%. Code and models are available at https://github.com/ReneeYe/ConST.
Measuring Equality in Machine Learning Security Defenses
Mar 01, 2023
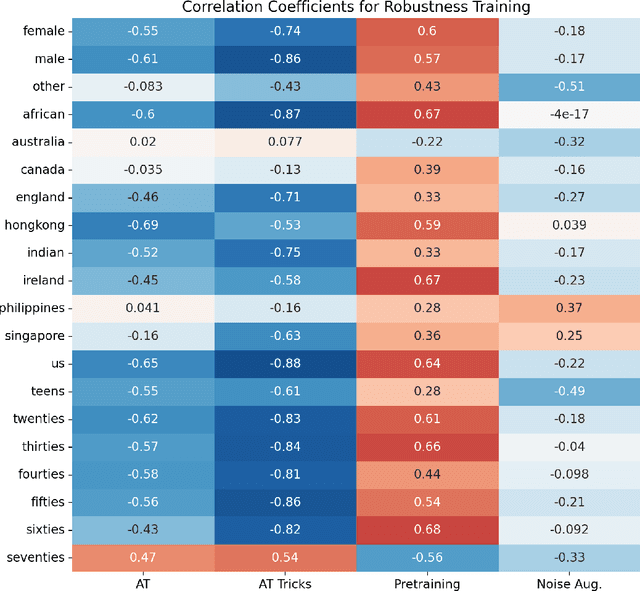
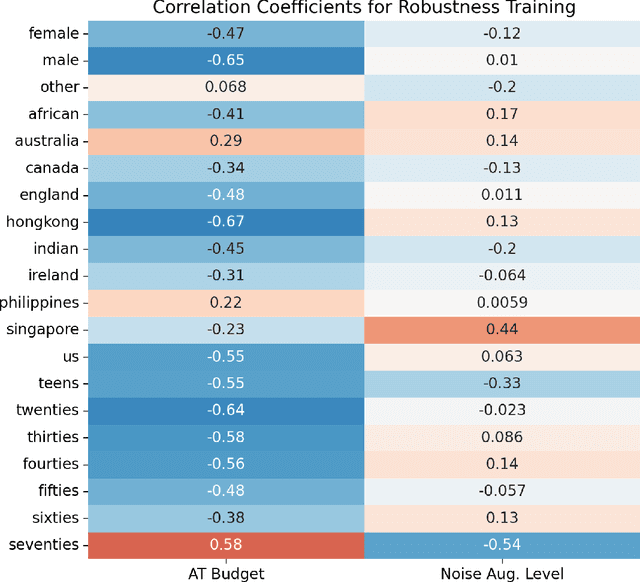
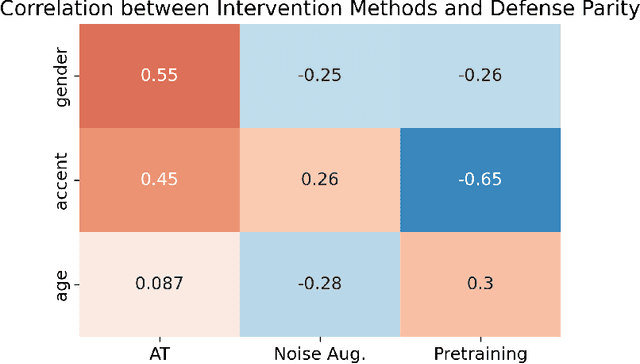
The machine learning security community has developed myriad defenses for evasion attacks over the past decade. An understudied question in that community is: for whom do these defenses defend? In this work, we consider some common approaches to defending learned systems and whether those approaches may offer unexpected performance inequities when used by different sub-populations. We outline simple parity metrics and a framework for analysis that can begin to answer this question through empirical results of the fairness implications of machine learning security methods. Many methods have been proposed that can cause direct harm, which we describe as biased vulnerability and biased rejection. Our framework and metric can be applied to robustly trained models, preprocessing-based methods, and rejection methods to capture behavior over security budgets. We identify a realistic dataset with a reasonable computational cost suitable for measuring the equality of defenses. Through a case study in speech command recognition, we show how such defenses do not offer equal protection for social subgroups and how to perform such analyses for robustness training, and we present a comparison of fairness between two rejection-based defenses: randomized smoothing and neural rejection. We offer further analysis of factors that correlate to equitable defenses to stimulate the future investigation of how to assist in building such defenses. To the best of our knowledge, this is the first work that examines the fairness disparity in the accuracy-robustness trade-off in speech data and addresses fairness evaluation for rejection-based defenses.
UniSyn: An End-to-End Unified Model for Text-to-Speech and Singing Voice Synthesis
Dec 06, 2022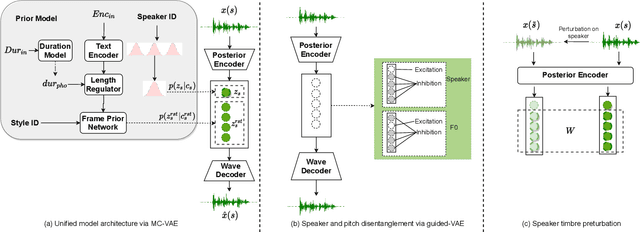
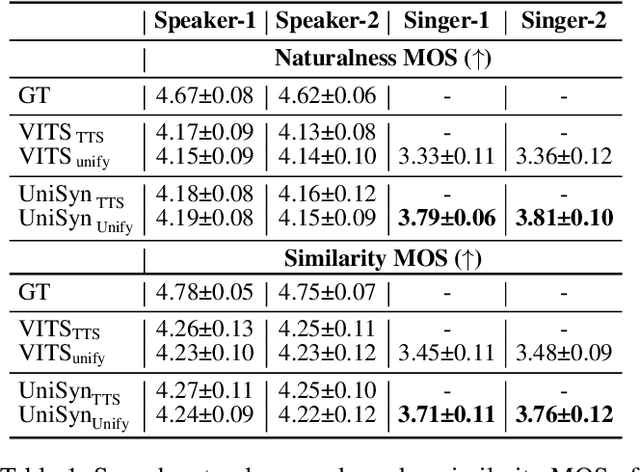
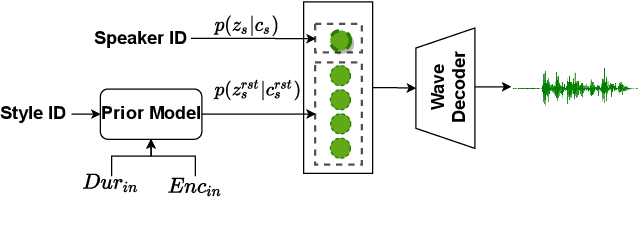
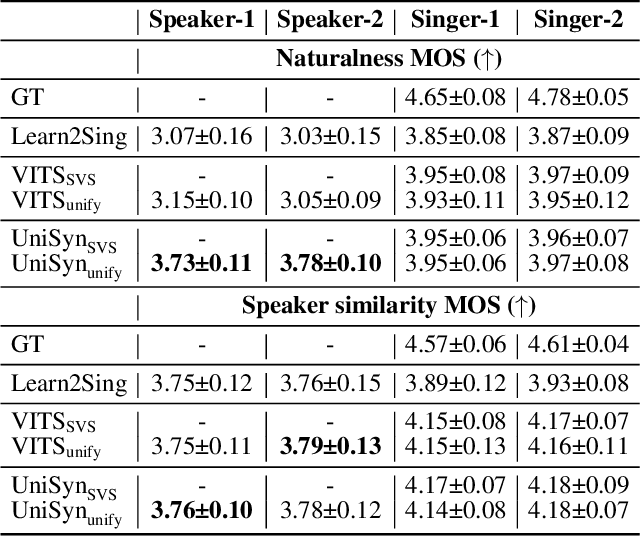
Text-to-speech (TTS) and singing voice synthesis (SVS) aim at generating high-quality speaking and singing voice according to textual input and music scores, respectively. Unifying TTS and SVS into a single system is crucial to the applications requiring both of them. Existing methods usually suffer from some limitations, which rely on either both singing and speaking data from the same person or cascaded models of multiple tasks. To address these problems, a simplified elegant framework for TTS and SVS, named UniSyn, is proposed in this paper. It is an end-to-end unified model that can make a voice speak and sing with only singing or speaking data from this person. To be specific, a multi-conditional variational autoencoder (MC-VAE), which constructs two independent latent sub-spaces with the speaker- and style-related (i.e. speak or sing) conditions for flexible control, is proposed in UniSyn. Moreover, supervised guided-VAE and timbre perturbation with the Wasserstein distance constraint are leveraged to further disentangle the speaker timbre and style. Experiments conducted on two speakers and two singers demonstrate that UniSyn can generate natural speaking and singing voice without corresponding training data. The proposed approach outperforms the state-of-the-art end-to-end voice generation work, which proves the effectiveness and advantages of UniSyn.
Dynamic Alignment Mask CTC: Improved Mask-CTC with Aligned Cross Entropy
Mar 14, 2023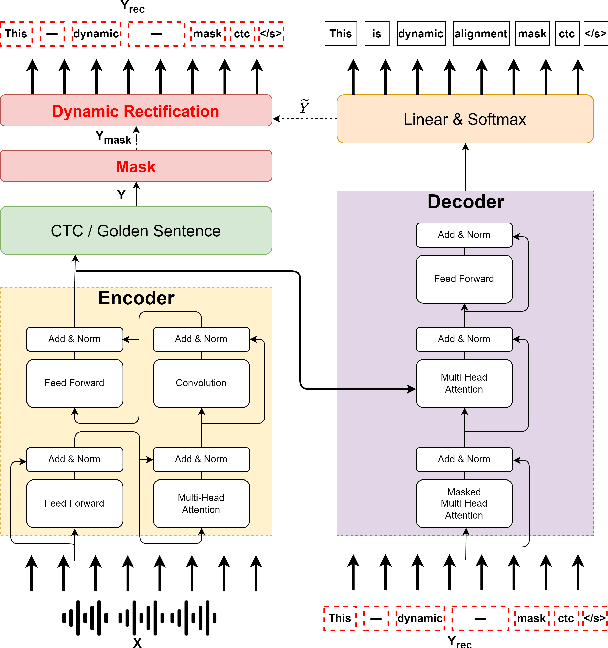

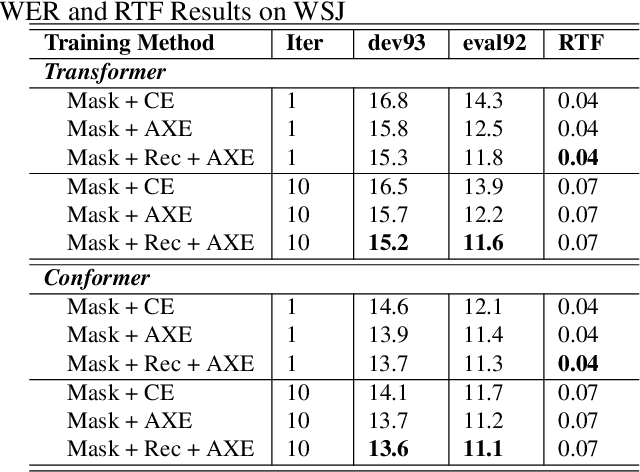
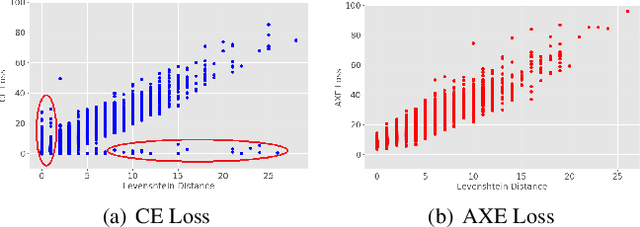
Because of predicting all the target tokens in parallel, the non-autoregressive models greatly improve the decoding efficiency of speech recognition compared with traditional autoregressive models. In this work, we present dynamic alignment Mask CTC, introducing two methods: (1) Aligned Cross Entropy (AXE), finding the monotonic alignment that minimizes the cross-entropy loss through dynamic programming, (2) Dynamic Rectification, creating new training samples by replacing some masks with model predicted tokens. The AXE ignores the absolute position alignment between prediction and ground truth sentence and focuses on tokens matching in relative order. The dynamic rectification method makes the model capable of simulating the non-mask but possible wrong tokens, even if they have high confidence. Our experiments on WSJ dataset demonstrated that not only AXE loss but also the rectification method could improve the WER performance of Mask CTC.
Relating the fundamental frequency of speech with EEG using a dilated convolutional network
Jul 05, 2022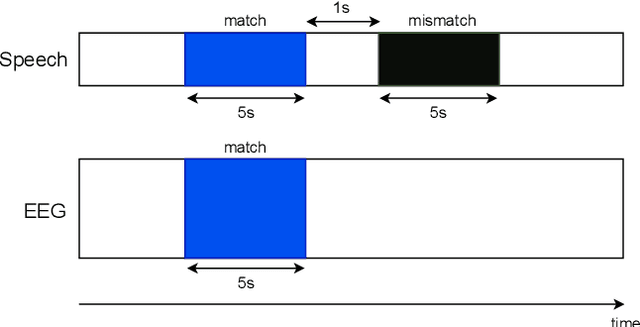
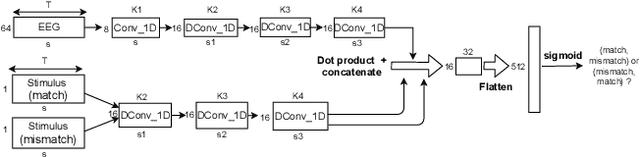
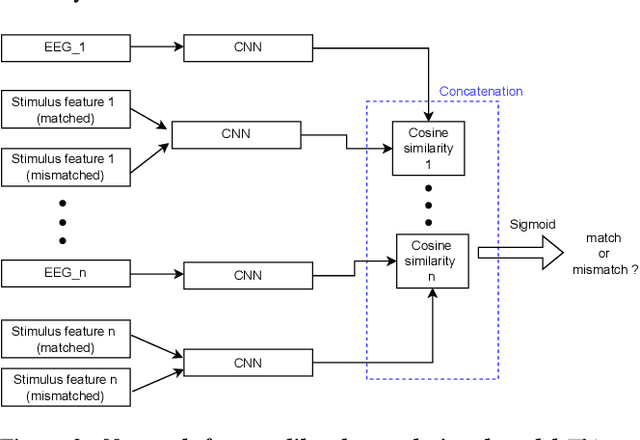
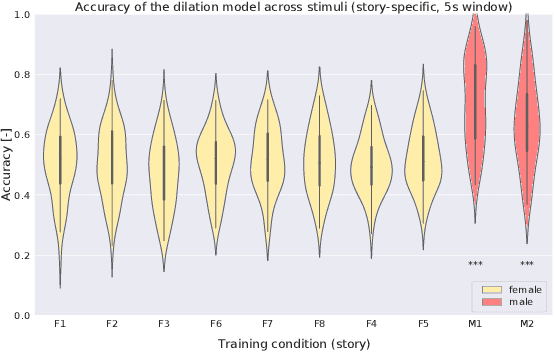
To investigate how speech is processed in the brain, we can model the relation between features of a natural speech signal and the corresponding recorded electroencephalogram (EEG). Usually, linear models are used in regression tasks. Either EEG is predicted, or speech is reconstructed, and the correlation between predicted and actual signal is used to measure the brain's decoding ability. However, given the nonlinear nature of the brain, the modeling ability of linear models is limited. Recent studies introduced nonlinear models to relate the speech envelope to EEG. We set out to include other features of speech that are not coded in the envelope, notably the fundamental frequency of the voice (f0). F0 is a higher-frequency feature primarily coded at the brainstem to midbrain level. We present a dilated-convolutional model to provide evidence of neural tracking of the f0. We show that a combination of f0 and the speech envelope improves the performance of a state-of-the-art envelope-based model. This suggests the dilated-convolutional model can extract non-redundant information from both f0 and the envelope. We also show the ability of the dilated-convolutional model to generalize to subjects not included during training. This latter finding will accelerate f0-based hearing diagnosis.
Multi-modal deep learning system for depression and anxiety detection
Dec 30, 2022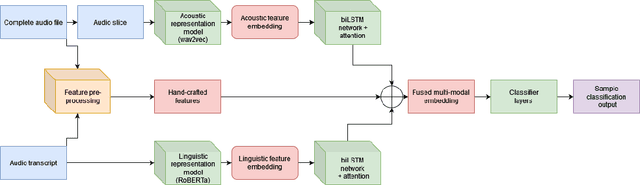

Traditional screening practices for anxiety and depression pose an impediment to monitoring and treating these conditions effectively. However, recent advances in NLP and speech modelling allow textual, acoustic, and hand-crafted language-based features to jointly form the basis of future mental health screening and condition detection. Speech is a rich and readily available source of insight into an individual's cognitive state and by leveraging different aspects of speech, we can develop new digital biomarkers for depression and anxiety. To this end, we propose a multi-modal system for the screening of depression and anxiety from self-administered speech tasks. The proposed model integrates deep-learned features from audio and text, as well as hand-crafted features that are informed by clinically-validated domain knowledge. We find that augmenting hand-crafted features with deep-learned features improves our overall classification F1 score comparing to a baseline of hand-crafted features alone from 0.58 to 0.63 for depression and from 0.54 to 0.57 for anxiety. The findings of our work suggest that speech-based biomarkers for depression and anxiety hold significant promise in the future of digital health.
Simultaneous Speech Extraction for Multiple Target Speakers under the Meeting Scenarios(V1)
Jun 17, 2022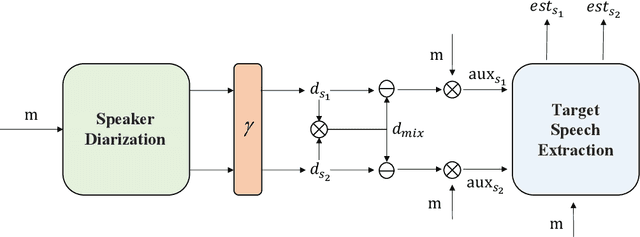
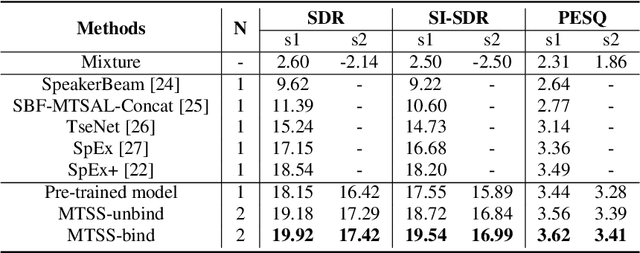
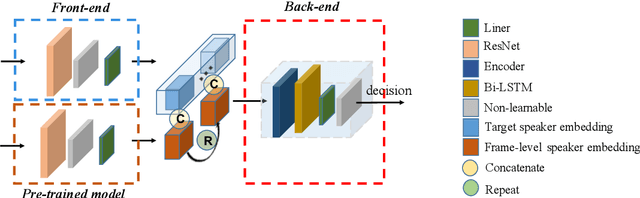
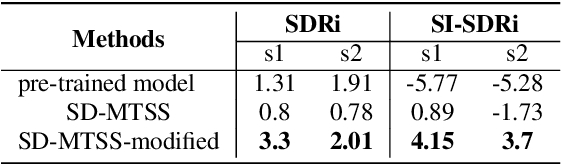
Recently, the target speech separation or extraction techniques under the meeting scenario have become a hot research trend. We propose a speaker diarization aware multiple target speech separation system (SD-MTSS) to simultaneously extract the voice of each speaker from the mixed speech, rather than requiring a succession of independent processes as presented in previous solutions. SD-MTSS consists of a speaker diarization (SD) module and a multiple target speech separation (MTSS) module. The former one infers the target speaker voice activity detection (TSVAD) states of the mixture, as well as gets different speakers' single-talker audio segments as the reference speech. The latter one employs both the mixed audio and reference speech as inputs, and then it generates an estimated mask. By exploiting the TSVAD decision and the estimated mask, our SD-MTSS model can extract the speech of each speaker concurrently in a conversion recording without additional enrollment audio in advance.Experimental results show that our MTSS model outperforms our baselines with a large margin, achieving 1.38dB SDR, 1.34dB SI-SNR, and 0.13 PESQ improvements over the state-of-the-art SpEx+ baseline on the WSJ0-2mix-extr dataset, respectively. The SD-MTSS system makes a significant improvement than the baseline on the Alimeeting dataset as well.
AI-Based Automated Speech Therapy Tools for persons with Speech Sound Disorders: A Systematic Literature Review
Apr 21, 2022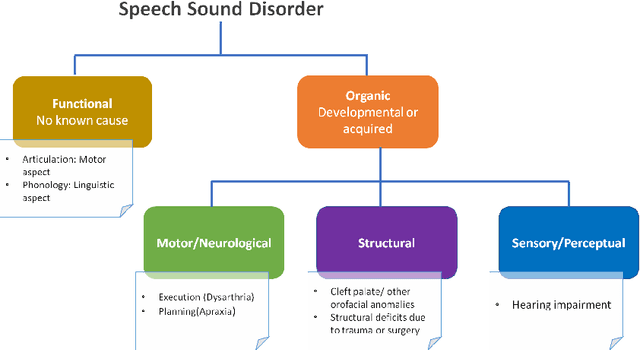
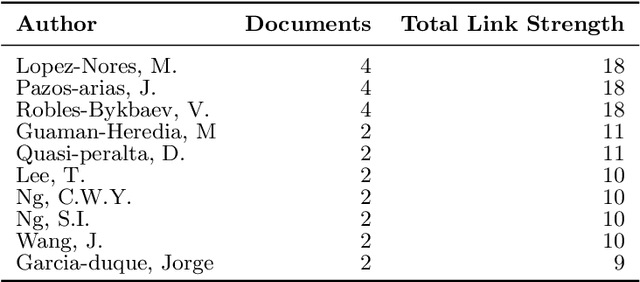
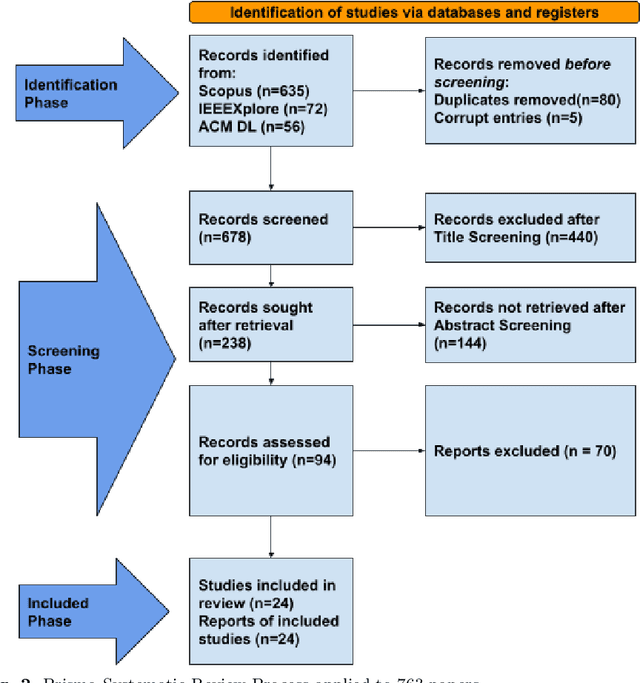
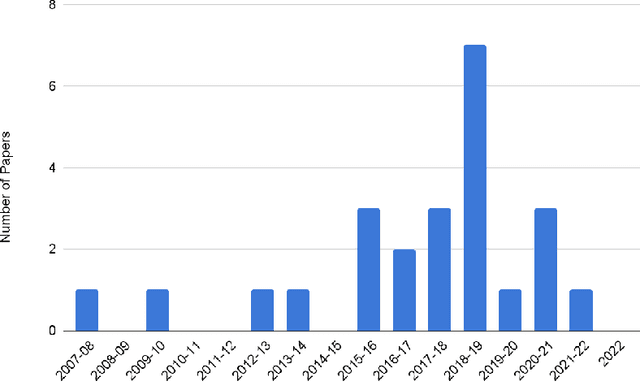
This paper presents a systematic literature review of published studies on AI-based automated speech therapy tools for persons with speech sound disorders (SSD). The COVID-19 pandemic has initiated the requirement for automated speech therapy tools for persons with SSD making speech therapy accessible and affordable. However, there are no guidelines for designing such automated tools and their required degree of automation compared to human experts. In this systematic review, we followed the PRISMA framework to address four research questions: 1) what types of SSD do AI-based automated speech therapy tools address, 2) what is the level of autonomy achieved by such tools, 3) what are the different modes of intervention, and 4) how effective are such tools in comparison with human experts. An extensive search was conducted on digital libraries to find research papers relevant to our study from 2007 to 2022. The results show that AI-based automated speech therapy tools for persons with SSD are increasingly gaining attention among researchers. Articulation disorders were the most frequently addressed SSD based on the reviewed papers. Further, our analysis shows that most researchers proposed fully automated tools without considering the role of other stakeholders. Our review indicates that mobile-based and gamified applications were the most frequent mode of intervention. The results further show that only a few studies compared the effectiveness of such tools compared to expert Speech-Language Pathologists (SLP). Our paper presents the state-of-the-art in the field, contributes significant insights based on the research questions, and provides suggestions for future research directions.
Improving Speech Recognition on Noisy Speech via Speech Enhancement with Multi-Discriminators CycleGAN
Dec 12, 2021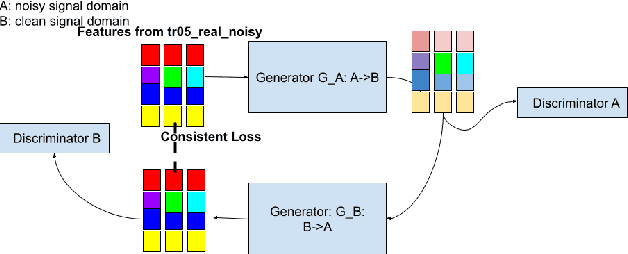
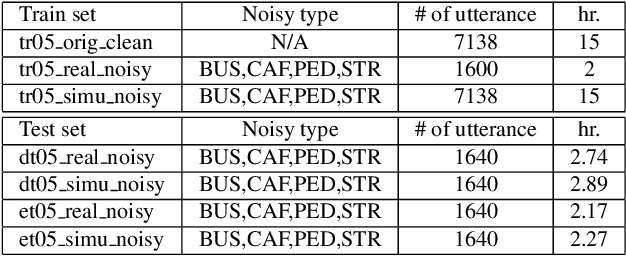
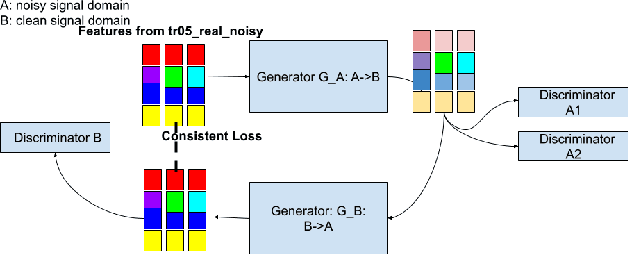
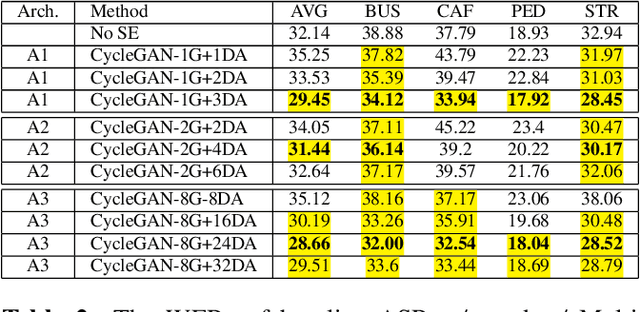
This paper presents our latest investigations on improving automatic speech recognition for noisy speech via speech enhancement. We propose a novel method named Multi-discriminators CycleGAN to reduce noise of input speech and therefore improve the automatic speech recognition performance. Our proposed method leverages the CycleGAN framework for speech enhancement without any parallel data and improve it by introducing multiple discriminators that check different frequency areas. Furthermore, we show that training multiple generators on homogeneous subset of the training data is better than training one generator on all the training data. We evaluate our method on CHiME-3 data set and observe up to 10.03% relatively WER improvement on the development set and up to 14.09% on the evaluation set.