 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Measuring Equality in Machine Learning Security Defenses
Mar 01, 2023

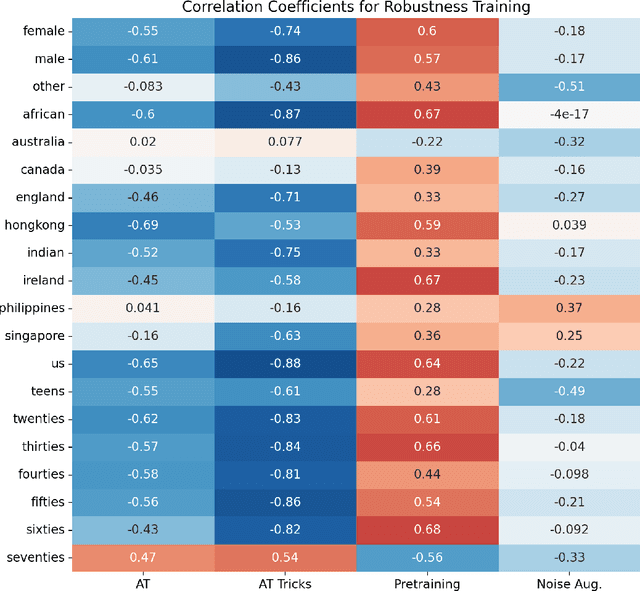
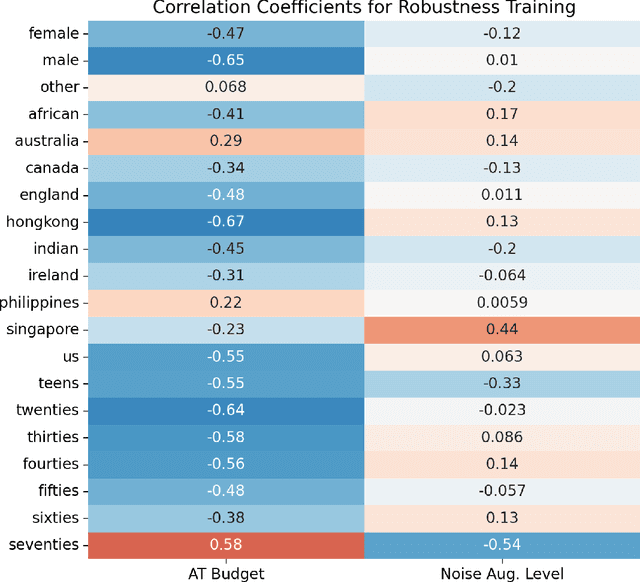
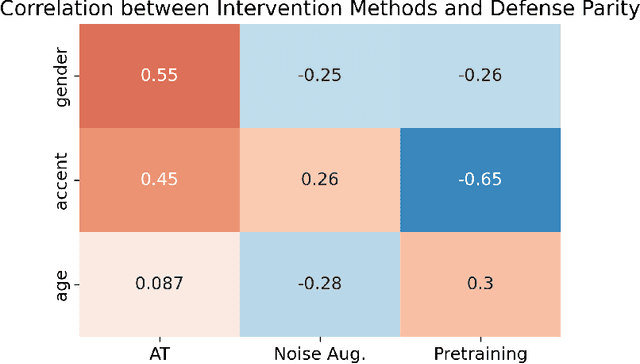
The machine learning security community has developed myriad defenses for evasion attacks over the past decade. An understudied question in that community is: for whom do these defenses defend? In this work, we consider some common approaches to defending learned systems and whether those approaches may offer unexpected performance inequities when used by different sub-populations. We outline simple parity metrics and a framework for analysis that can begin to answer this question through empirical results of the fairness implications of machine learning security methods. Many methods have been proposed that can cause direct harm, which we describe as biased vulnerability and biased rejection. Our framework and metric can be applied to robustly trained models, preprocessing-based methods, and rejection methods to capture behavior over security budgets. We identify a realistic dataset with a reasonable computational cost suitable for measuring the equality of defenses. Through a case study in speech command recognition, we show how such defenses do not offer equal protection for social subgroups and how to perform such analyses for robustness training, and we present a comparison of fairness between two rejection-based defenses: randomized smoothing and neural rejection. We offer further analysis of factors that correlate to equitable defenses to stimulate the future investigation of how to assist in building such defenses. To the best of our knowledge, this is the first work that examines the fairness disparity in the accuracy-robustness trade-off in speech data and addresses fairness evaluation for rejection-based defenses.
Inference skipping for more efficient real-time speech enhancement with parallel RNNs
Jul 22, 2022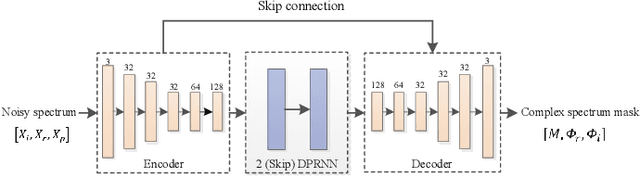
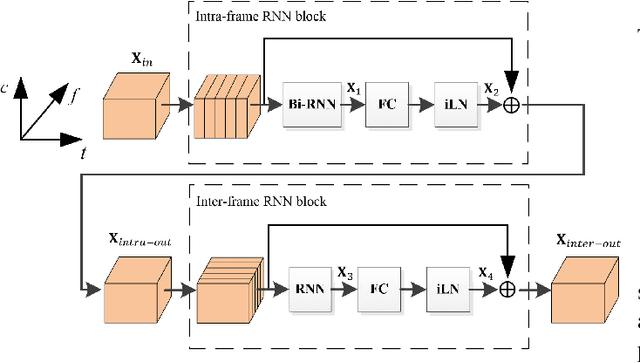
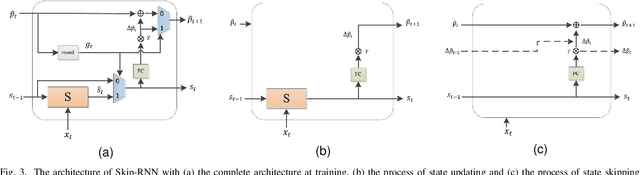
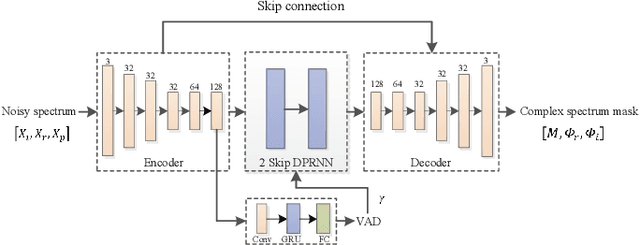
Deep neural network (DNN) based speech enhancement models have attracted extensive attention due to their promising performance. However, it is difficult to deploy a powerful DNN in real-time applications because of its high computational cost. Typical compression methods such as pruning and quantization do not make good use of the data characteristics. In this paper, we introduce the Skip-RNN strategy into speech enhancement models with parallel RNNs. The states of the RNNs update intermittently without interrupting the update of the output mask, which leads to significant reduction of computational load without evident audio artifacts. To better leverage the difference between the voice and the noise, we further regularize the skipping strategy with voice activity detection (VAD) guidance, saving more computational load. Experiments on a high-performance speech enhancement model, dual-path convolutional recurrent network (DPCRN), show the superiority of our strategy over strategies like network pruning or directly training a smaller model. We also validate the generalization of the proposed strategy on two other competitive speech enhancement models.
Creating Speech-to-Speech Corpus from Dubbed Series
Mar 07, 2022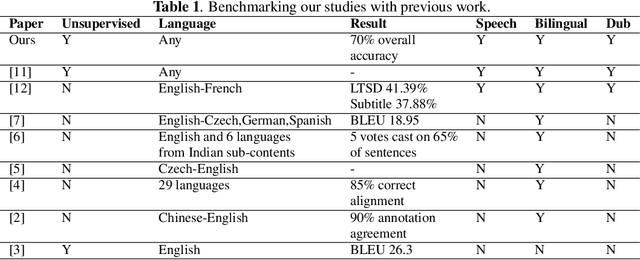
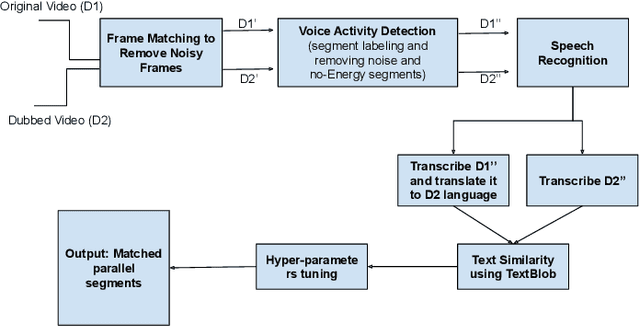
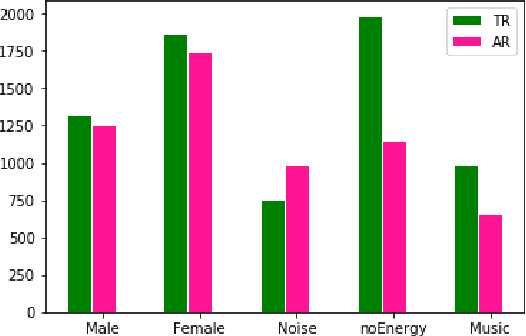

Dubbed series are gaining a lot of popularity in recent years with strong support from major media service providers. Such popularity is fueled by studies that showed that dubbed versions of TV shows are more popular than their subtitled equivalents. We propose an unsupervised approach to construct speech-to-speech corpus, aligned on short segment levels, to produce a parallel speech corpus in the source- and target- languages. Our methodology exploits video frames, speech recognition, machine translation, and noisy frames removal algorithms to match segments in both languages. To verify the performance of the proposed method, we apply it on long and short dubbed clips. Out of 36 hours TR-AR dubbed series, our pipeline was able to generate 17 hours of paired segments, which is about 47% of the corpus. We applied our method on another language pair, EN-AR, to ensure it is robust enough and not tuned for a specific language or a specific corpus. Regardless of the language pairs, the accuracy of the paired segments was around 70% when evaluated using human subjective evaluation. The corpus will be freely available for the research community.
Unsupervised Uncertainty Measures of Automatic Speech Recognition for Non-intrusive Speech Intelligibility Prediction
Apr 08, 2022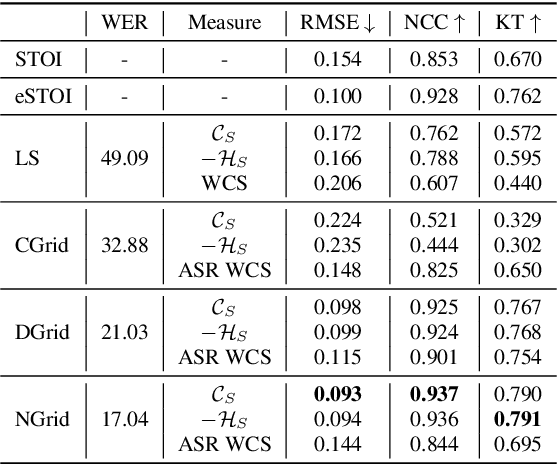
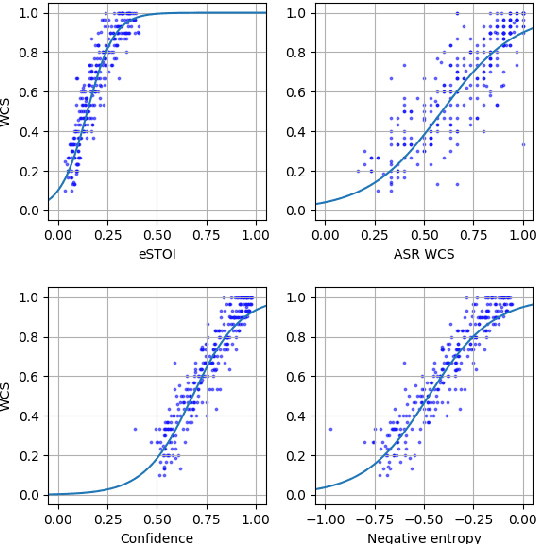
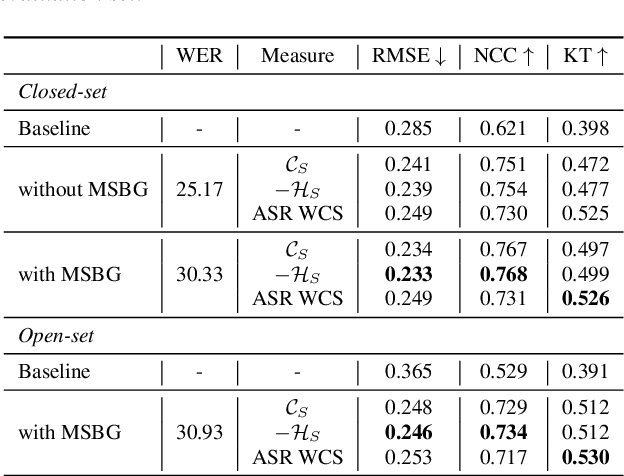
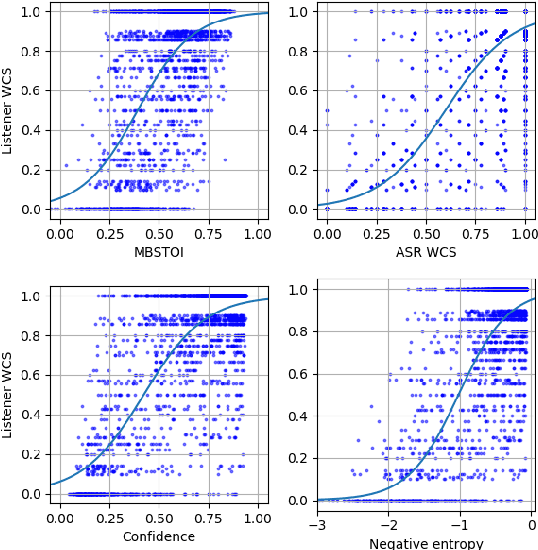
Non-intrusive intelligibility prediction is important for its application in realistic scenarios, where a clean reference signal is difficult to access. The construction of many non-intrusive predictors require either ground truth intelligibility labels or clean reference signals for supervised learning. In this work, we leverage an unsupervised uncertainty estimation method for predicting speech intelligibility, which does not require intelligibility labels or reference signals to train the predictor. Our experiments demonstrate that the uncertainty from state-of-the-art end-to-end automatic speech recognition (ASR) models is highly correlated with speech intelligibility. The proposed method is evaluated on two databases and the results show that the unsupervised uncertainty measures of ASR models are more correlated with speech intelligibility from listening results than the predictions made by widely used intrusive methods.
A Single Self-Supervised Model for Many Speech Modalities Enables Zero-Shot Modality Transfer
Jul 14, 2022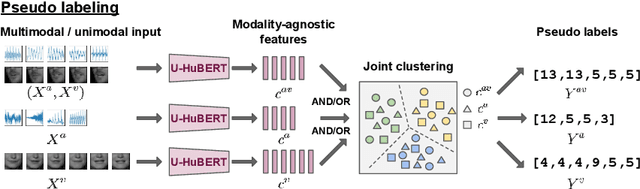
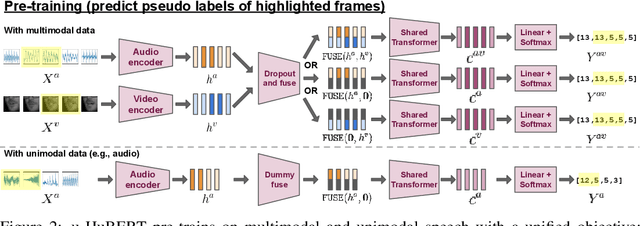
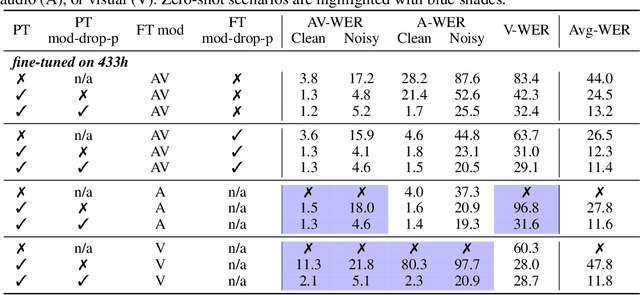
While audio-visual speech models can yield superior performance and robustness compared to audio-only models, their development and adoption are hindered by the lack of labeled and unlabeled audio-visual data and the cost to deploy one model per modality. In this paper, we present u-HuBERT, a self-supervised pre-training framework that can leverage both multimodal and unimodal speech with a unified masked cluster prediction objective. By utilizing modality dropout during pre-training, we demonstrate that a single fine-tuned model can achieve performance on par or better than the state-of-the-art modality-specific models. Moreover, our model fine-tuned only on audio can perform well with audio-visual and visual speech input, achieving zero-shot modality generalization for speech recognition and speaker verification. In particular, our single model yields 1.2%/1.4%/27.2% speech recognition word error rate on LRS3 with audio-visual/audio/visual input.
VoiceFixer: A Unified Framework for High-Fidelity Speech Restoration
Apr 12, 2022
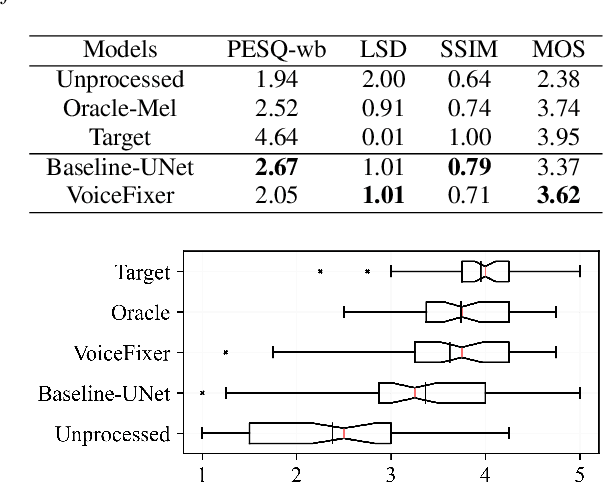
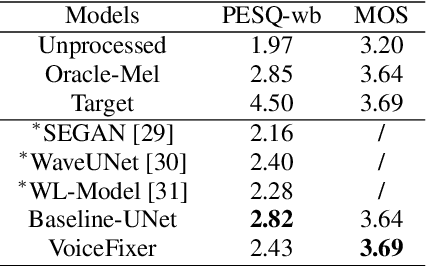
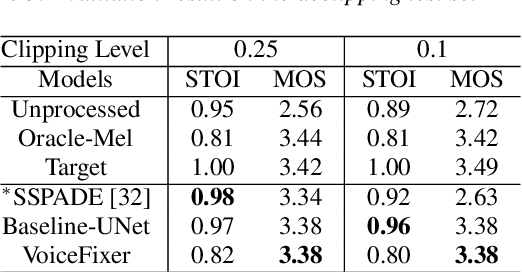
Speech restoration aims to remove distortions in speech signals. Prior methods mainly focus on a single type of distortion, such as speech denoising or dereverberation. However, speech signals can be degraded by several different distortions simultaneously in the real world. It is thus important to extend speech restoration models to deal with multiple distortions. In this paper, we introduce VoiceFixer, a unified framework for high-fidelity speech restoration. VoiceFixer restores speech from multiple distortions (e.g., noise, reverberation, and clipping) and can expand degraded speech (e.g., noisy speech) with a low bandwidth to 44.1 kHz full-bandwidth high-fidelity speech. We design VoiceFixer based on (1) an analysis stage that predicts intermediate-level features from the degraded speech, and (2) a synthesis stage that generates waveform using a neural vocoder. Both objective and subjective evaluations show that VoiceFixer is effective on severely degraded speech, such as real-world historical speech recordings. Samples of VoiceFixer are available at https://haoheliu.github.io/voicefixer.
AHD ConvNet for Speech Emotion Classification
Jun 21, 2022
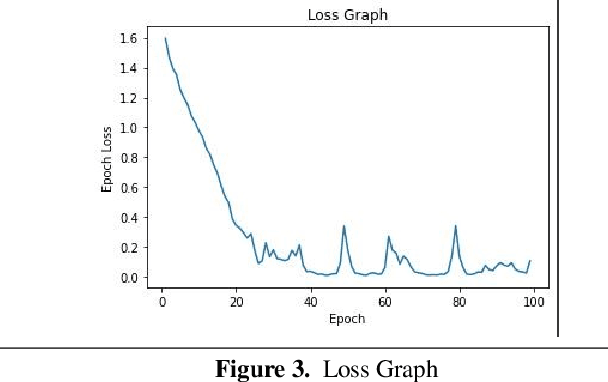
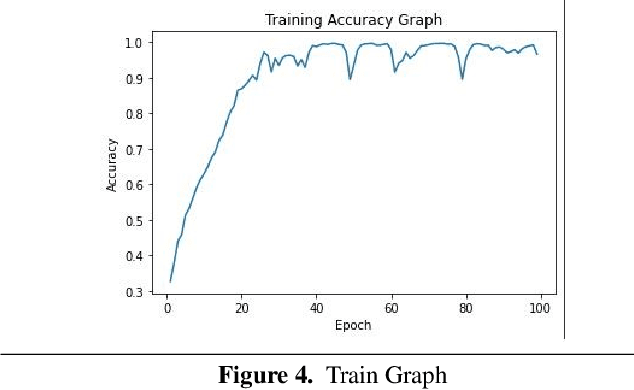
Accomplishments in the field of artificial intelligence are utilized in the advancement of computing and making of intelligent machines for facilitating mankind and improving user experience. Emotions are rudimentary for people, affecting thinking and ordinary exercises like correspondence, learning and direction. Speech emotion recognition is domain of interest in this regard and in this work, we propose a novel mel spectrogram learning approach in which our model uses the datapoints to learn emotions from the given wav form voice notes in the popular CREMA-D dataset. Our model uses log mel-spectrogram as feature with number of mels = 64. It took less training time compared to other approaches used to address the problem of emotion speech recognition.
Complex Recurrent Variational Autoencoder for Speech Enhancement
Apr 05, 2022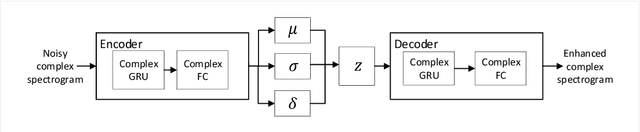
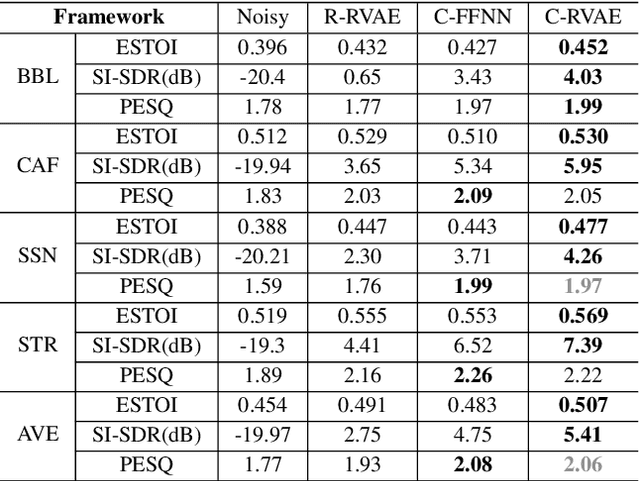
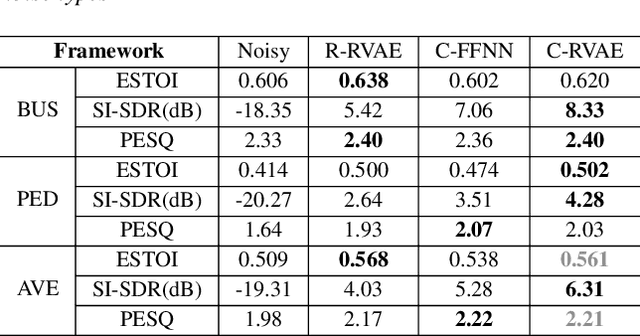
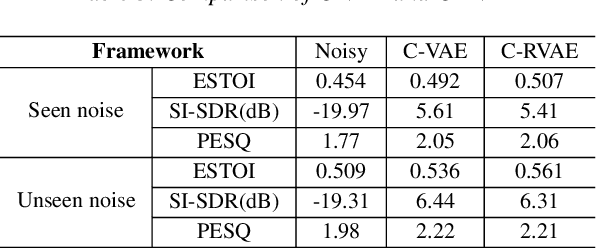
Commonly-used methods in speech enhancement are based on short-time fourier transform (STFT) representation, in particular on the magnitude of the STFT. This is because phase is naturally unstructured and intractable, and magnitude has shown more importance in speech enhancement. Nevertheless, phase has shown its significance in some research and cannot be ignored. Complex neural networks, with their inherent advantage, provide a solution for complex spectrogram processing. Complex variational autoencoder (VAE), as an extension of vanilla \acrshort{vae}, has shown positive results in complex spectrogram representation. However, the existing work on complex \acrshort{vae} only uses linear layers and merely applies the model on direct spectra representation. This paper extends the linear complex \acrshort{vae} to a non-linear one. Furthermore, on account of the temporal property of speech signals, a complex recurrent \acrshort{vae} is proposed. The proposed model has been applied on speech enhancement. As far as we know, it is the first time that a complex generative model is applied to speech enhancement. Experiments are based on the TIMIT dataset, while speech intelligibility and speech quality have been evaluated. The results show that, for speech enhancement, the proposed method has better performance on speech intelligibility and comparable performance on speech quality.
Synthesized Speech Detection Using Convolutional Transformer-Based Spectrogram Analysis
May 03, 2022
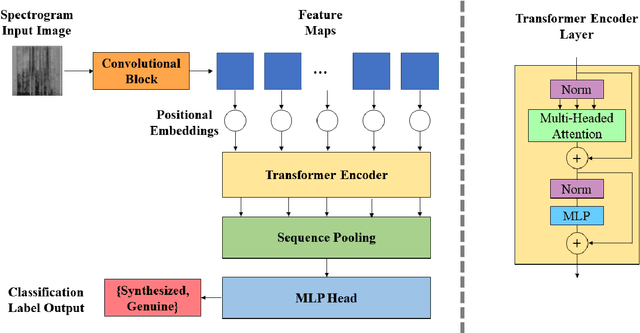
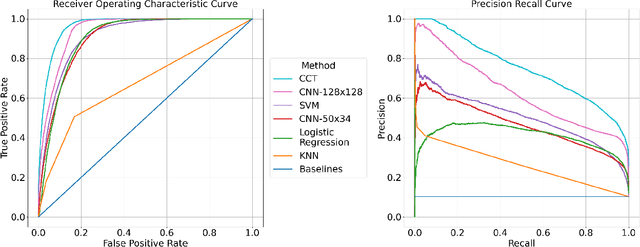
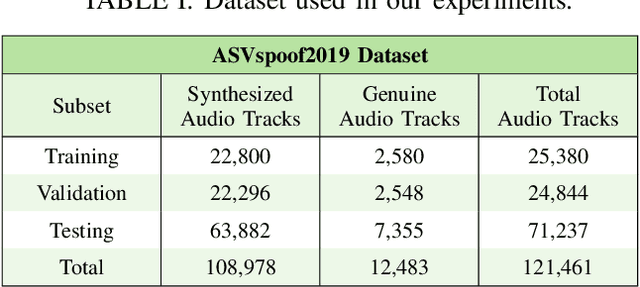
Synthesized speech is common today due to the prevalence of virtual assistants, easy-to-use tools for generating and modifying speech signals, and remote work practices. Synthesized speech can also be used for nefarious purposes, including creating a purported speech signal and attributing it to someone who did not speak the content of the signal. We need methods to detect if a speech signal is synthesized. In this paper, we analyze speech signals in the form of spectrograms with a Compact Convolutional Transformer (CCT) for synthesized speech detection. A CCT utilizes a convolutional layer that introduces inductive biases and shared weights into a network, allowing a transformer architecture to perform well with fewer data samples used for training. The CCT uses an attention mechanism to incorporate information from all parts of a signal under analysis. Trained on both genuine human voice signals and synthesized human voice signals, we demonstrate that our CCT approach successfully differentiates between genuine and synthesized speech signals.
* Accepted to the 2021 IEEE Asilomar Conference on Signals, Systems, and Computers
Guided-TTS:Text-to-Speech with Untranscribed Speech
Dec 07, 2021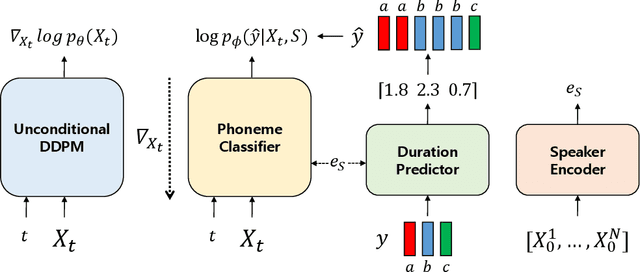

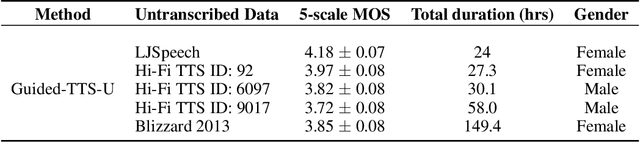
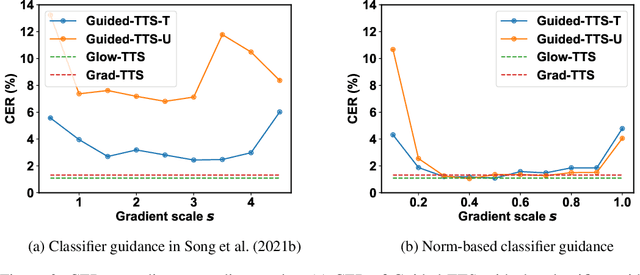
Most neural text-to-speech (TTS) models require <speech, transcript> paired data from the desired speaker for high-quality speech synthesis, which limits the usage of large amounts of untranscribed data for training. In this work, we present Guided-TTS, a high-quality TTS model that learns to generate speech from untranscribed speech data. Guided-TTS combines an unconditional diffusion probabilistic model with a separately trained phoneme classifier for text-to-speech. By modeling the unconditional distribution for speech, our model can utilize the untranscribed data for training. For text-to-speech synthesis, we guide the generative process of the unconditional DDPM via phoneme classification to produce mel-spectrograms from the conditional distribution given transcript. We show that Guided-TTS achieves comparable performance with the existing methods without any transcript for LJSpeech. Our results further show that a single speaker-dependent phoneme classifier trained on multispeaker large-scale data can guide unconditional DDPMs for various speakers to perform TTS.