 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Representation Learning Strategies to Model Pathological Speech: Effect of Multiple Spectral Resolutions
Sep 17, 2022
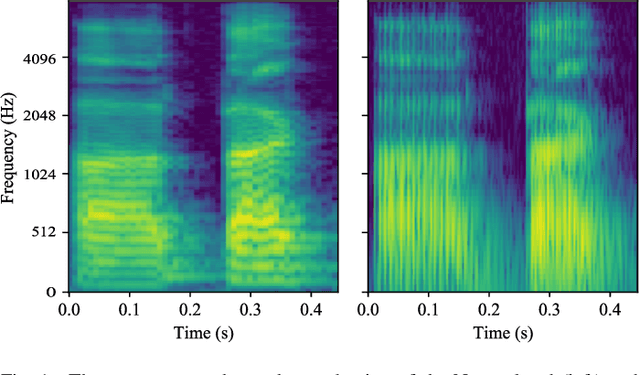
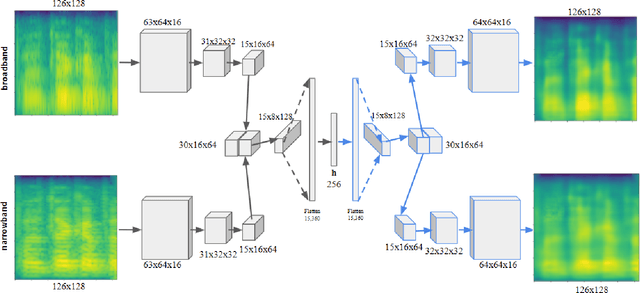
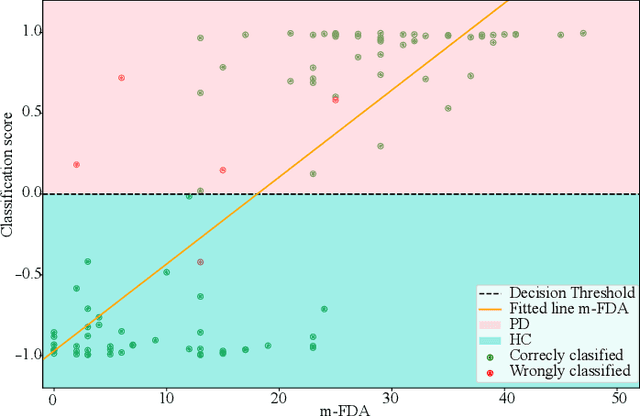
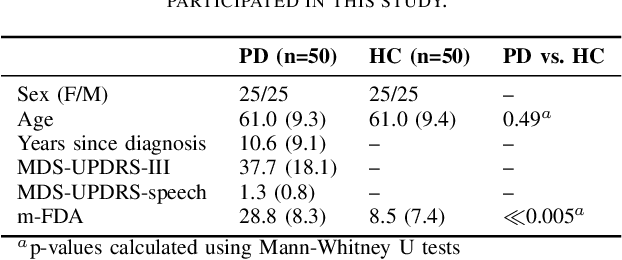
This paper considers a representation learning strategy to model speech signals from patients with Parkinson's disease and cleft lip and palate. In particular, it compares different parametrized representation types such as wideband and narrowband spectrograms, and wavelet-based scalograms, with the goal of quantifying the representation capacity of each. Methods for quantification include the ability of the proposed model to classify different pathologies and the associated disease severity. Additionally, this paper proposes a novel fusion strategy called multi-spectral fusion that combines wideband and narrowband spectral resolutions using a representation learning strategy based on autoencoders. The proposed models are able to classify the speech from Parkinson's disease patients with accuracy up to 95\%. The proposed models were also able to asses the dysarthria severity of Parkinson's disease patients with a Spearman correlation up to 0.75. These results outperform those observed in literature where the same problem was addressed with the same corpus.
Pac-HuBERT: Self-Supervised Music Source Separation via Primitive Auditory Clustering and Hidden-Unit BERT
Apr 04, 2023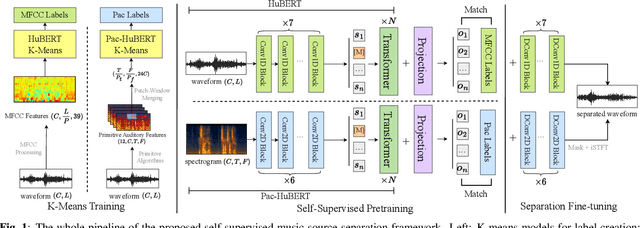

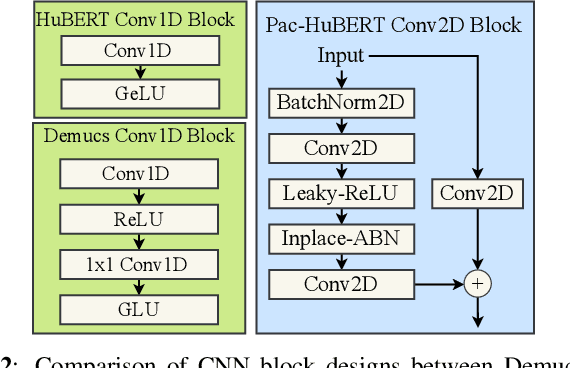
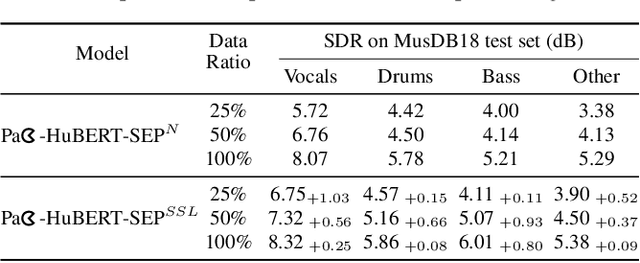
In spite of the progress in music source separation research, the small amount of publicly-available clean source data remains a constant limiting factor for performance. Thus, recent advances in self-supervised learning present a largely-unexplored opportunity for improving separation models by leveraging unlabelled music data. In this paper, we propose a self-supervised learning framework for music source separation inspired by the HuBERT speech representation model. We first investigate the potential impact of the original HuBERT model by inserting an adapted version of it into the well-known Demucs V2 time-domain separation model architecture. We then propose a time-frequency-domain self-supervised model, Pac-HuBERT (for primitive auditory clustering HuBERT), that we later use in combination with a Res-U-Net decoder for source separation. Pac-HuBERT uses primitive auditory features of music as unsupervised clustering labels to initialize the self-supervised pretraining process using the Free Music Archive (FMA) dataset. The resulting framework achieves better source-to-distortion ratio (SDR) performance on the MusDB18 test set than the original Demucs V2 and Res-U-Net models. We further demonstrate that it can boost performance with small amounts of supervised data. Ultimately, our proposed framework is an effective solution to the challenge of limited clean source data for music source separation.
GazeReader: Detecting Unknown Word Using Webcam for English as a Second Language (ESL) Learners
Mar 18, 2023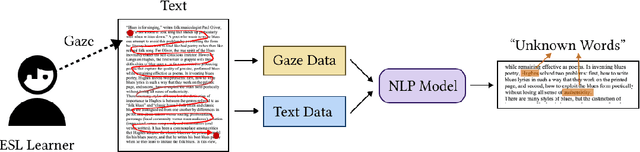
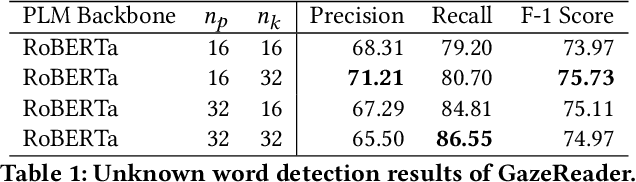
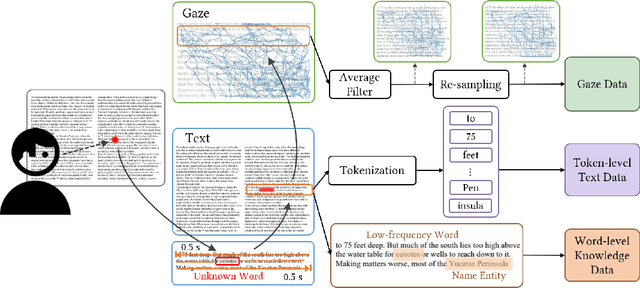

Automatic unknown word detection techniques can enable new applications for assisting English as a Second Language (ESL) learners, thus improving their reading experiences. However, most modern unknown word detection methods require dedicated eye-tracking devices with high precision that are not easily accessible to end-users. In this work, we propose GazeReader, an unknown word detection method only using a webcam. GazeReader tracks the learner's gaze and then applies a transformer-based machine learning model that encodes the text information to locate the unknown word. We applied knowledge enhancement including term frequency, part of speech, and named entity recognition to improve the performance. The user study indicates that the accuracy and F1-score of our method were 98.09% and 75.73%, respectively. Lastly, we explored the design scope for ESL reading and discussed the findings.
Contextually-rich human affect perception using multimodal scene information
Mar 13, 2023
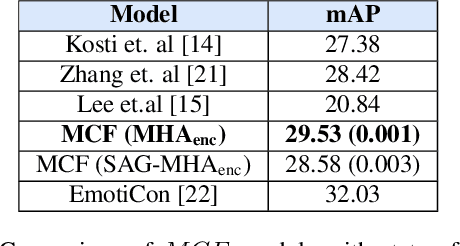
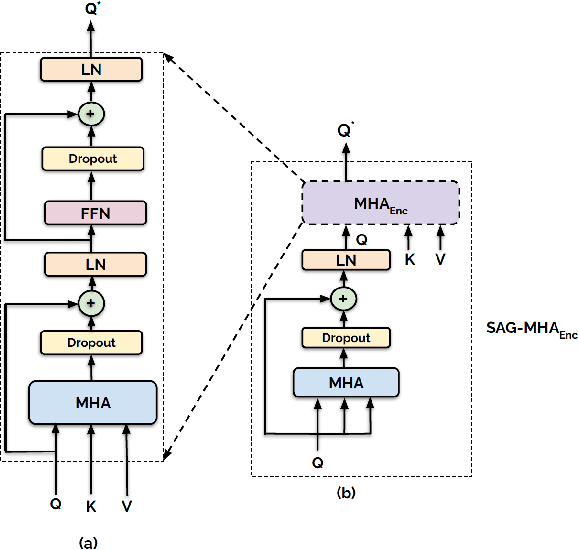
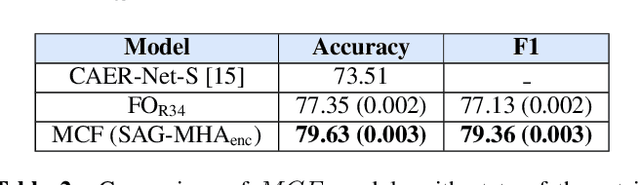
The process of human affect understanding involves the ability to infer person specific emotional states from various sources including images, speech, and language. Affect perception from images has predominantly focused on expressions extracted from salient face crops. However, emotions perceived by humans rely on multiple contextual cues including social settings, foreground interactions, and ambient visual scenes. In this work, we leverage pretrained vision-language (VLN) models to extract descriptions of foreground context from images. Further, we propose a multimodal context fusion (MCF) module to combine foreground cues with the visual scene and person-based contextual information for emotion prediction. We show the effectiveness of our proposed modular design on two datasets associated with natural scenes and TV shows.
Robust Data2vec: Noise-robust Speech Representation Learning for ASR by Combining Regression and Improved Contrastive Learning
Oct 27, 2022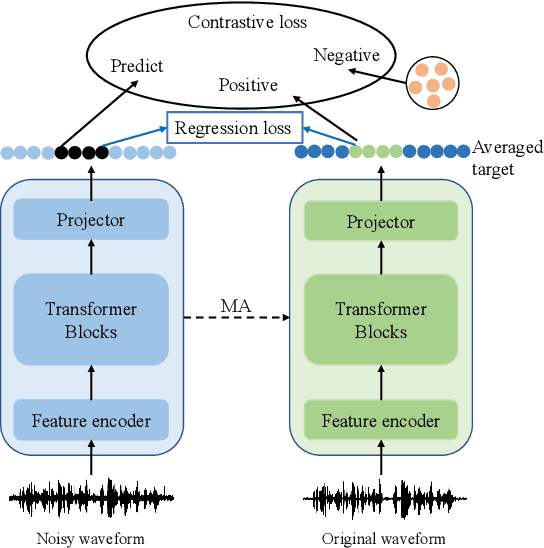
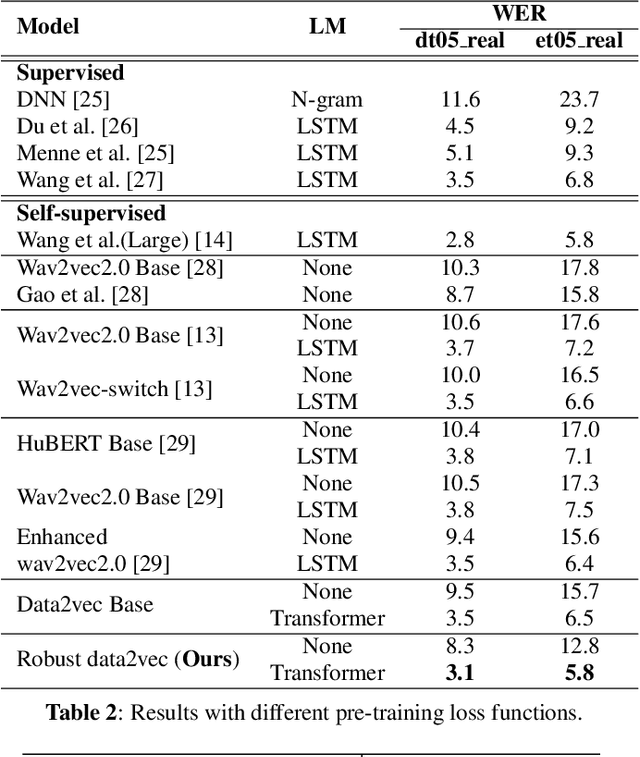

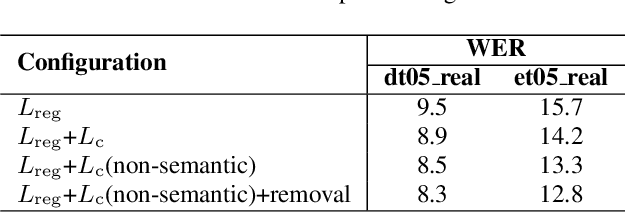
Self-supervised pre-training methods based on contrastive learning or regression tasks can utilize more unlabeled data to improve the performance of automatic speech recognition (ASR). However, the robustness impact of combining the two pre-training tasks and constructing different negative samples for contrastive learning still remains unclear. In this paper, we propose a noise-robust data2vec for self-supervised speech representation learning by jointly optimizing the contrastive learning and regression tasks in the pre-training stage. Furthermore, we present two improved methods to facilitate contrastive learning. More specifically, we first propose to construct patch-based non-semantic negative samples to boost the noise robustness of the pre-training model, which is achieved by dividing the features into patches at different sizes (i.e., so-called negative samples). Second, by analyzing the distribution of positive and negative samples, we propose to remove the easily distinguishable negative samples to improve the discriminative capacity for pre-training models. Experimental results on the CHiME-4 dataset show that our method is able to improve the performance of the pre-trained model in noisy scenarios. We find that joint training of the contrastive learning and regression tasks can avoid the model collapse to some extent compared to only training the regression task.
Sejarah dan Perkembangan Teknik Natural Language Processing (NLP) Bahasa Indonesia: Tinjauan tentang sejarah, perkembangan teknologi, dan aplikasi NLP dalam bahasa Indonesia
Mar 28, 2023

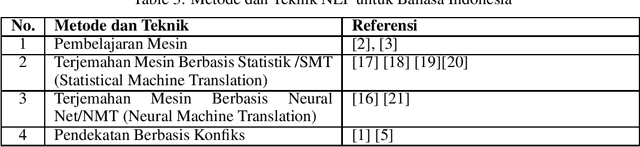
This study provides an overview of the history of the development of Natural Language Processing (NLP) in the context of the Indonesian language, with a focus on the basic technologies, methods, and practical applications that have been developed. This review covers developments in basic NLP technologies such as stemming, part-of-speech tagging, and related methods; practical applications in cross-language information retrieval systems, information extraction, and sentiment analysis; and methods and techniques used in Indonesian language NLP research, such as machine learning, statistics-based machine translation, and conflict-based approaches. This study also explores the application of NLP in Indonesian language industry and research and identifies challenges and opportunities in Indonesian language NLP research and development. Recommendations for future Indonesian language NLP research and development include developing more efficient methods and technologies, expanding NLP applications, increasing sustainability, further research into the potential of NLP, and promoting interdisciplinary collaboration. It is hoped that this review will help researchers, practitioners, and the government to understand the development of Indonesian language NLP and identify opportunities for further research and development.
Deep Spectro-temporal Artifacts for Detecting Synthesized Speech
Oct 11, 2022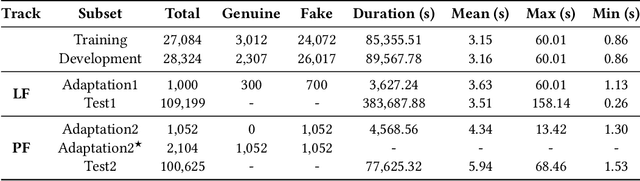
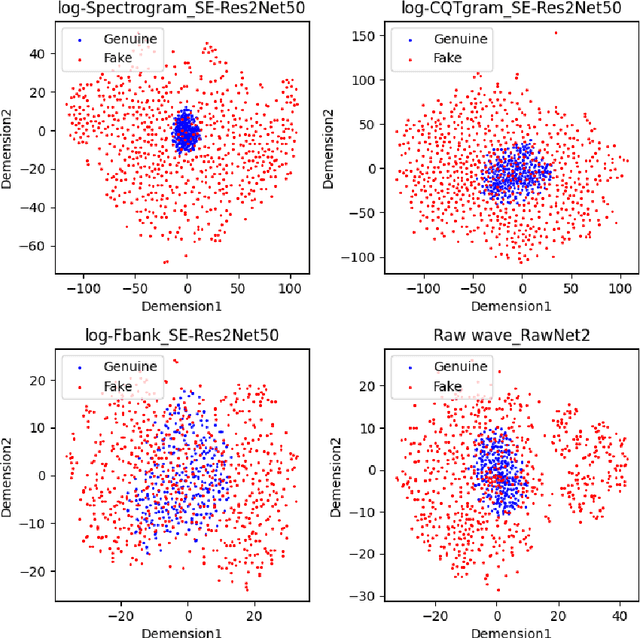
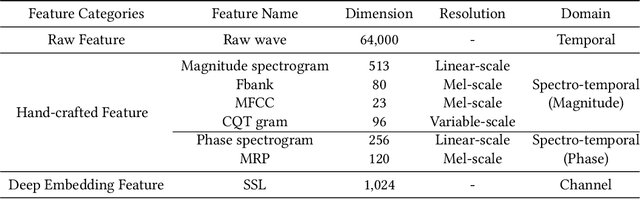

The Audio Deep Synthesis Detection (ADD) Challenge has been held to detect generated human-like speech. With our submitted system, this paper provides an overall assessment of track 1 (Low-quality Fake Audio Detection) and track 2 (Partially Fake Audio Detection). In this paper, spectro-temporal artifacts were detected using raw temporal signals, spectral features, as well as deep embedding features. To address track 1, low-quality data augmentation, domain adaptation via finetuning, and various complementary feature information fusion were aggregated in our system. Furthermore, we analyzed the clustering characteristics of subsystems with different features by visualization method and explained the effectiveness of our proposed greedy fusion strategy. As for track 2, frame transition and smoothing were detected using self-supervised learning structure to capture the manipulation of PF attacks in the time domain. We ranked 4th and 5th in track 1 and track 2, respectively.
Implementation Of Tiny Machine Learning Models On Arduino 33 BLE For Gesture And Speech Recognition
Jul 23, 2022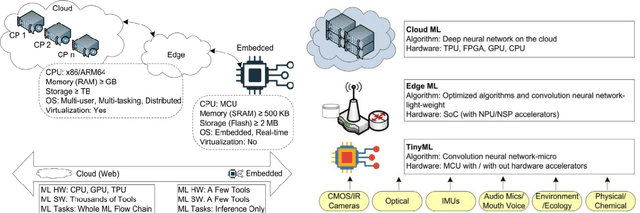
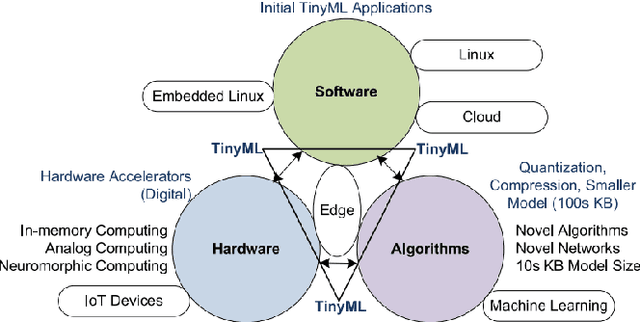
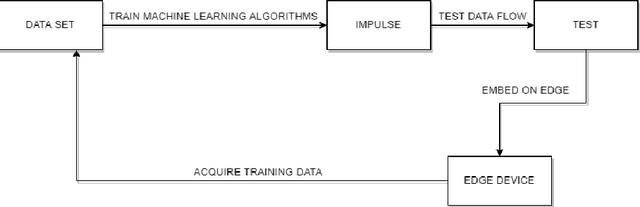
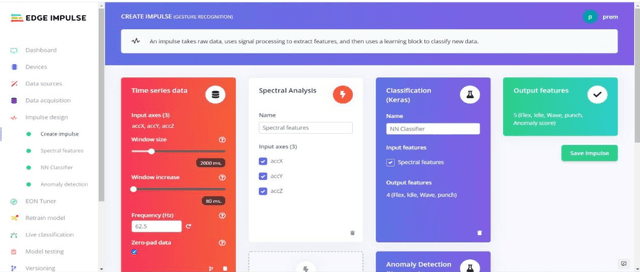
In this article gesture recognition and speech recognition applications are implemented on embedded systems with Tiny Machine Learning (TinyML). It features 3-axis accelerometer, 3-axis gyroscope and 3-axis magnetometer. The gesture recognition,provides an innovative approach nonverbal communication. It has wide applications in human-computer interaction and sign language. Here in the implementation of hand gesture recognition, TinyML model is trained and deployed from EdgeImpulse framework for hand gesture recognition and based on the hand movements, Arduino Nano 33 BLE device having 6-axis IMU can find out the direction of movement of hand. The Speech is a mode of communication. Speech recognition is a way by which the statements or commands of human speech is understood by the computer which reacts accordingly. The main aim of speech recognition is to achieve communication between man and machine. Here in the implementation of speech recognition, TinyML model is trained and deployed from EdgeImpulse framework for speech recognition and based on the keywords pronounced by human, Arduino Nano 33 BLE device having built-in microphone can make an RGB LED glow like red, green or blue based on keyword pronounced. The results of each application are obtained and listed in the results section and given the analysis upon the results.
Speech Augmentation Based Unsupervised Learning for Keyword Spotting
May 28, 2022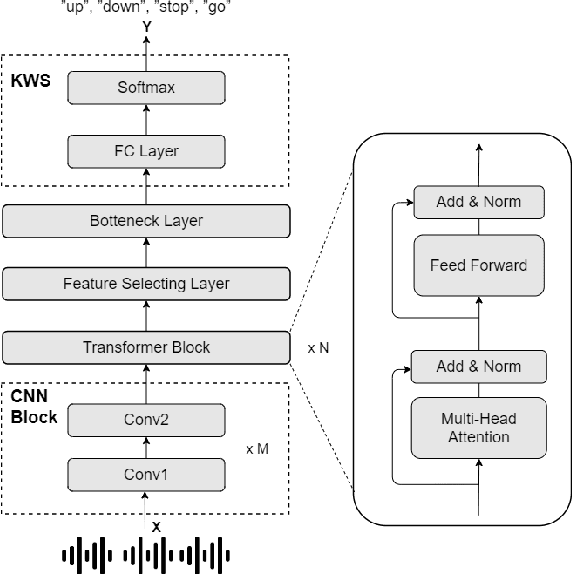
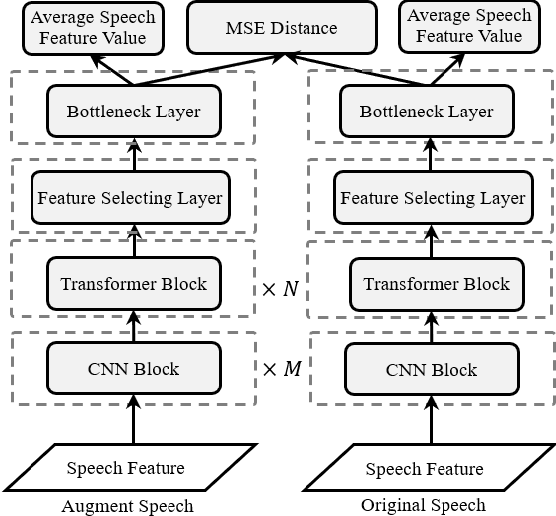

In this paper, we investigated a speech augmentation based unsupervised learning approach for keyword spotting (KWS) task. KWS is a useful speech application, yet also heavily depends on the labeled data. We designed a CNN-Attention architecture to conduct the KWS task. CNN layers focus on the local acoustic features, and attention layers model the long-time dependency. To improve the robustness of KWS model, we also proposed an unsupervised learning method. The unsupervised loss is based on the similarity between the original and augmented speech features, as well as the audio reconstructing information. Two speech augmentation methods are explored in the unsupervised learning: speed and intensity. The experiments on Google Speech Commands V2 Dataset demonstrated that our CNN-Attention model has competitive results. Moreover, the augmentation based unsupervised learning could further improve the classification accuracy of KWS task. In our experiments, with augmentation based unsupervised learning, our KWS model achieves better performance than other unsupervised methods, such as CPC, APC, and MPC.
Parallel Synthesis for Autoregressive Speech Generation
Apr 25, 2022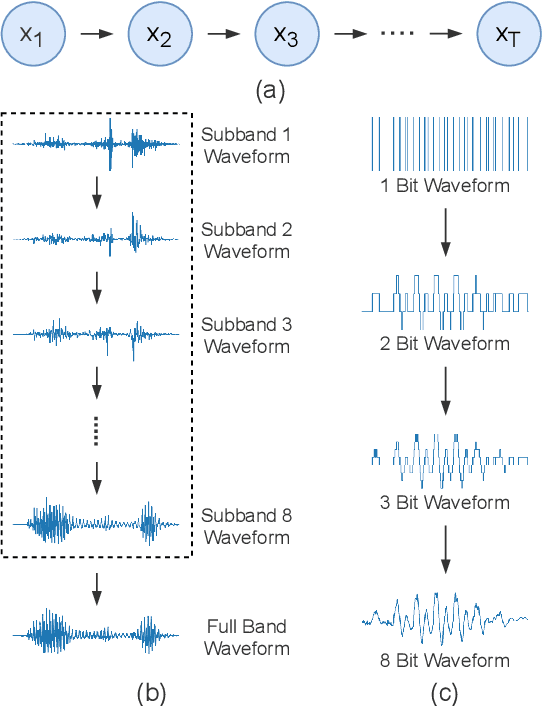
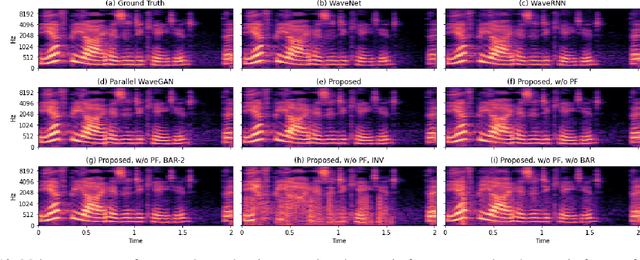
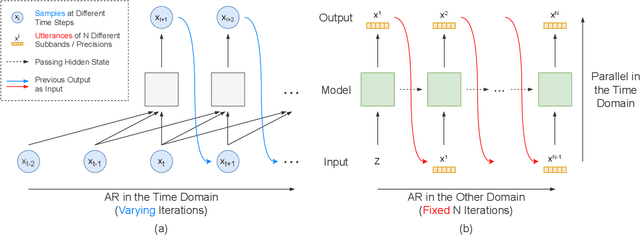
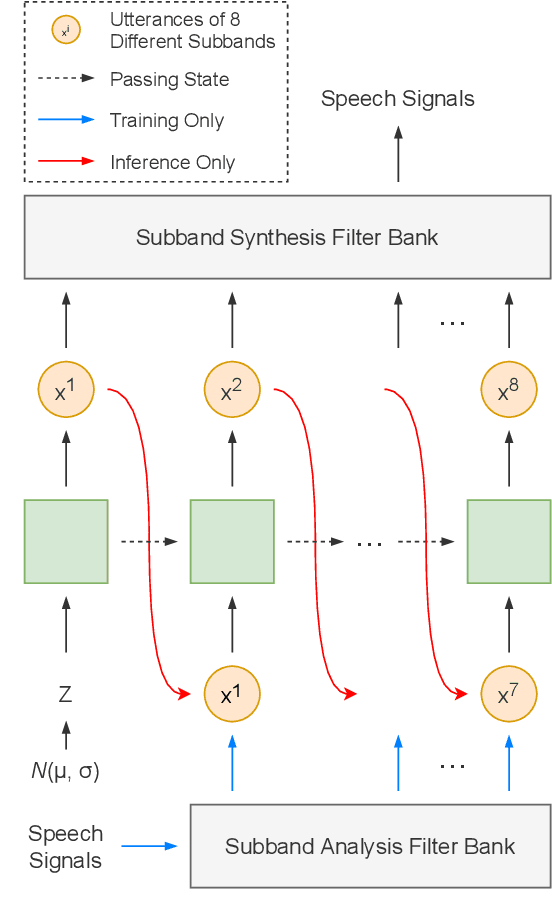
Autoregressive models have achieved outstanding performance in neural speech synthesis tasks. Though they can generate highly natural human speech, the iterative generation inevitably makes the synthesis time proportional to the utterance's length, leading to low efficiency. Many works were dedicated to generating the whole speech time sequence in parallel and then proposed GAN-based, flow-based, and score-based models. This paper proposed a new thought for the autoregressive generation. Instead of iteratively predicting samples in a time sequence, the proposed model performs frequency-wise autoregressive generation (FAR) and bit-wise autoregressive generation (BAR) to synthesize speech. In FAR, a speech utterance is first split into different frequency subbands. The proposed model generates a subband conditioned on the previously generated one. A full band speech can then be reconstructed by using these generated subbands and a synthesis filter bank. Similarly, in BAR, an 8-bit quantized signal is generated iteratively from the first bit. By redesigning the autoregressive method to compute in domains other than the time domain, the number of iterations in the proposed model is no longer proportional to the utterance's length but the number of subbands/bits. The inference efficiency is hence significantly increased. Besides, a post-filter is employed to sample audio signals from output posteriors, and its training objective is designed based on the characteristics of the proposed autoregressive methods. The experimental results show that the proposed model is able to synthesize speech faster than real-time without GPU acceleration. Compared with the baseline autoregressive and non-autoregressive models, the proposed model achieves better MOS and shows its good generalization ability while synthesizing 44 kHz speech or utterances from unseen speakers.