 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
ASVspoof 2021: Towards Spoofed and Deepfake Speech Detection in the Wild
Oct 05, 2022

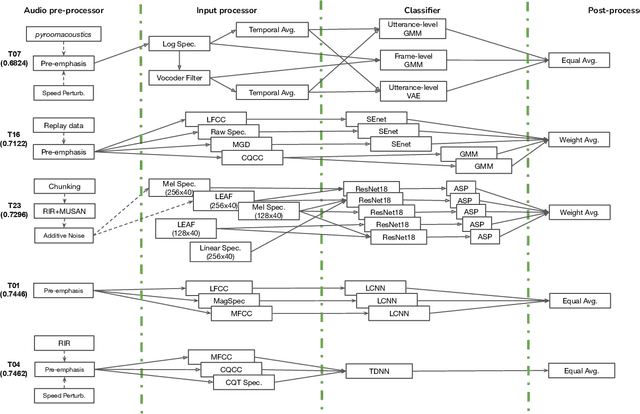
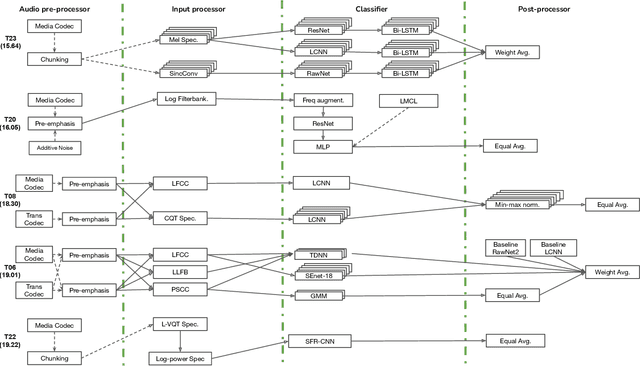
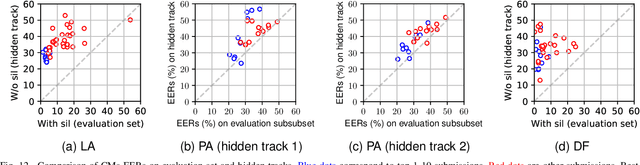
Benchmarking initiatives support the meaningful comparison of competing solutions to prominent problems in speech and language processing. Successive benchmarking evaluations typically reflect a progressive evolution from ideal lab conditions towards to those encountered in the wild. ASVspoof, the spoofing and deepfake detection initiative and challenge series, has followed the same trend. This article provides a summary of the ASVspoof 2021 challenge and the results of 37 participating teams. For the logical access task, results indicate that countermeasures solutions are robust to newly introduced encoding and transmission effects. Results for the physical access task indicate the potential to detect replay attacks in real, as opposed to simulated physical spaces, but a lack of robustness to variations between simulated and real acoustic environments. The DF task, new to the 2021 edition, targets solutions to the detection of manipulated, compressed speech data posted online. While detection solutions offer some resilience to compression effects, they lack generalization across different source datasets. In addition to a summary of the top-performing systems for each task, new analyses of influential data factors and results for hidden data subsets, the article includes a review of post-challenge results, an outline of the principal challenge limitations and a road-map for the future of ASVspoof. Link to the ASVspoof challenge and related resources: https://www.asvspoof.org/index2021.html
GazeReader: Detecting Unknown Word Using Webcam for English as a Second Language (ESL) Learners
Mar 18, 2023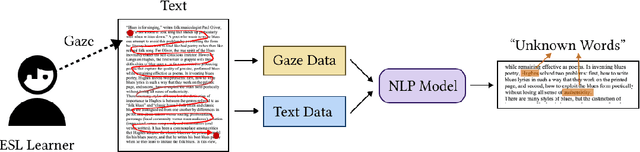
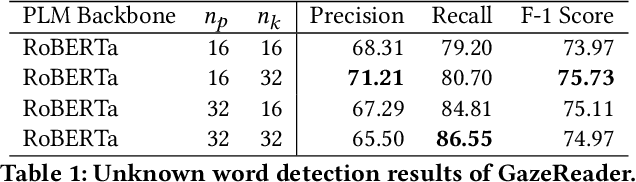
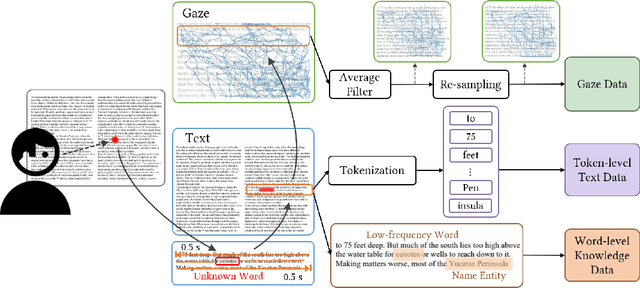

Automatic unknown word detection techniques can enable new applications for assisting English as a Second Language (ESL) learners, thus improving their reading experiences. However, most modern unknown word detection methods require dedicated eye-tracking devices with high precision that are not easily accessible to end-users. In this work, we propose GazeReader, an unknown word detection method only using a webcam. GazeReader tracks the learner's gaze and then applies a transformer-based machine learning model that encodes the text information to locate the unknown word. We applied knowledge enhancement including term frequency, part of speech, and named entity recognition to improve the performance. The user study indicates that the accuracy and F1-score of our method were 98.09% and 75.73%, respectively. Lastly, we explored the design scope for ESL reading and discussed the findings.
Sejarah dan Perkembangan Teknik Natural Language Processing (NLP) Bahasa Indonesia: Tinjauan tentang sejarah, perkembangan teknologi, dan aplikasi NLP dalam bahasa Indonesia
Mar 28, 2023

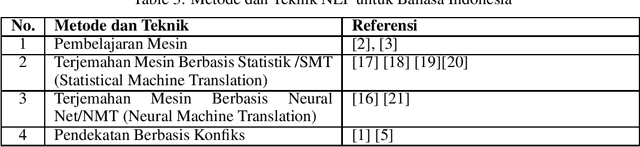
This study provides an overview of the history of the development of Natural Language Processing (NLP) in the context of the Indonesian language, with a focus on the basic technologies, methods, and practical applications that have been developed. This review covers developments in basic NLP technologies such as stemming, part-of-speech tagging, and related methods; practical applications in cross-language information retrieval systems, information extraction, and sentiment analysis; and methods and techniques used in Indonesian language NLP research, such as machine learning, statistics-based machine translation, and conflict-based approaches. This study also explores the application of NLP in Indonesian language industry and research and identifies challenges and opportunities in Indonesian language NLP research and development. Recommendations for future Indonesian language NLP research and development include developing more efficient methods and technologies, expanding NLP applications, increasing sustainability, further research into the potential of NLP, and promoting interdisciplinary collaboration. It is hoped that this review will help researchers, practitioners, and the government to understand the development of Indonesian language NLP and identify opportunities for further research and development.
QSpeech: Low-Qubit Quantum Speech Application Toolkit
May 26, 2022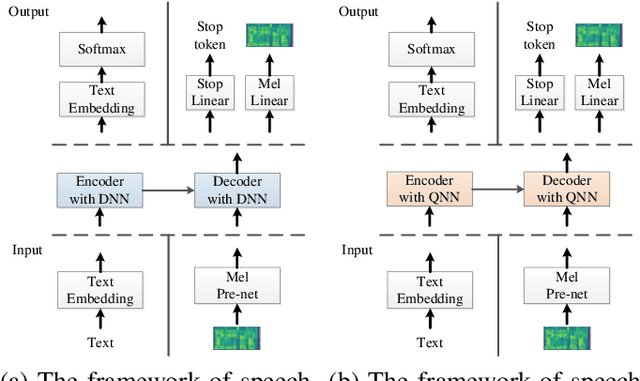
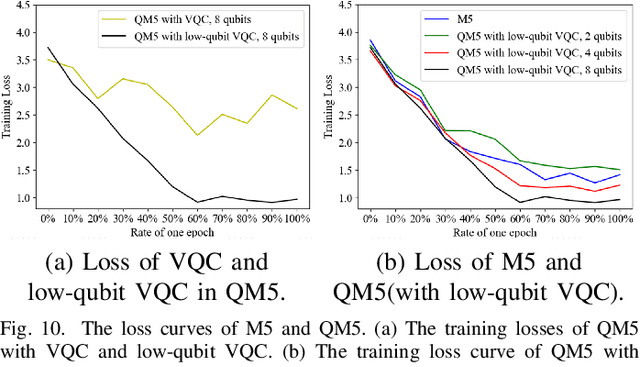
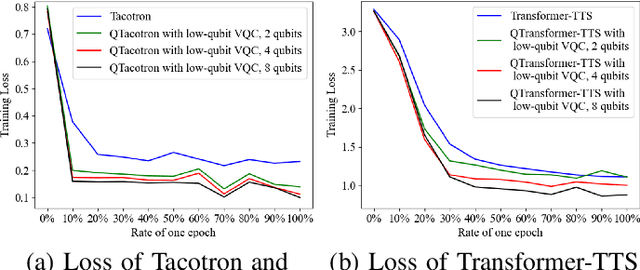
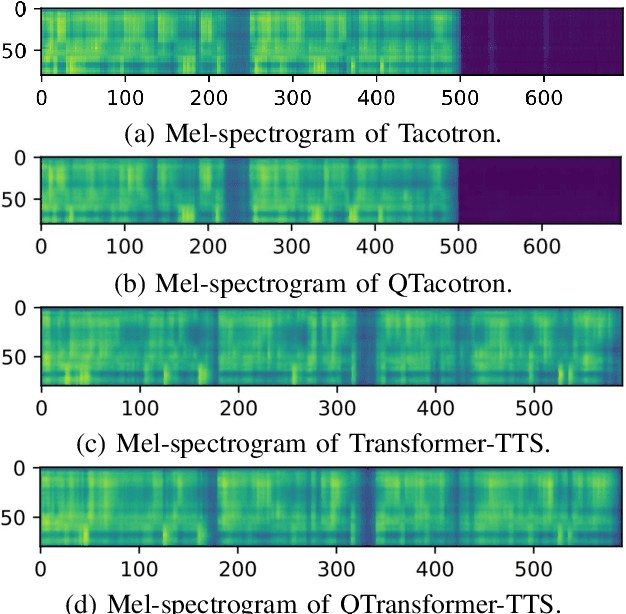
Quantum devices with low qubits are common in the Noisy Intermediate-Scale Quantum (NISQ) era. However, Quantum Neural Network (QNN) running on low-qubit quantum devices would be difficult since it is based on Variational Quantum Circuit (VQC), which requires many qubits. Therefore, it is critical to make QNN with VQC run on low-qubit quantum devices. In this study, we propose a novel VQC called the low-qubit VQC. VQC requires numerous qubits based on the input dimension; however, the low-qubit VQC with linear transformation can liberate this condition. Thus, it allows the QNN to run on low-qubit quantum devices for speech applications. Furthermore, as compared to the VQC, our proposed low-qubit VQC can stabilize the training process more. Based on the low-qubit VQC, we implement QSpeech, a library for quick prototyping of hybrid quantum-classical neural networks in the speech field. It has numerous quantum neural layers and QNN models for speech applications. Experiments on Speech Command Recognition and Text-to-Speech show that our proposed low-qubit VQC outperforms VQC and is more stable.
SAMU-XLSR: Semantically-Aligned Multimodal Utterance-level Cross-Lingual Speech Representation
May 17, 2022
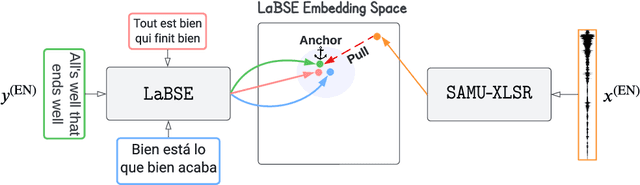
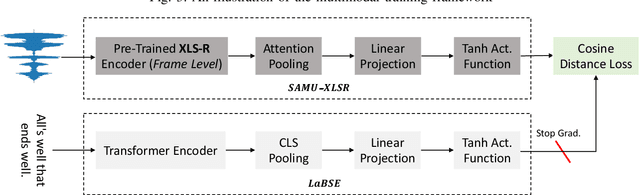
We propose the SAMU-XLSR: Semantically-Aligned Multimodal Utterance-level Cross-Lingual Speech Representation learning framework. Unlike previous works on speech representation learning, which learns multilingual contextual speech embedding at the resolution of an acoustic frame (10-20ms), this work focuses on learning multimodal (speech-text) multilingual speech embedding at the resolution of a sentence (5-10s) such that the embedding vector space is semantically aligned across different languages. We combine state-of-the-art multilingual acoustic frame-level speech representation learning model XLS-R with the Language Agnostic BERT Sentence Embedding (LaBSE) model to create an utterance-level multimodal multilingual speech encoder SAMU-XLSR. Although we train SAMU-XLSR with only multilingual transcribed speech data, cross-lingual speech-text and speech-speech associations emerge in its learned representation space. To substantiate our claims, we use SAMU-XLSR speech encoder in combination with a pre-trained LaBSE text sentence encoder for cross-lingual speech-to-text translation retrieval, and SAMU-XLSR alone for cross-lingual speech-to-speech translation retrieval. We highlight these applications by performing several cross-lingual text and speech translation retrieval tasks across several datasets.
Contextually-rich human affect perception using multimodal scene information
Mar 13, 2023
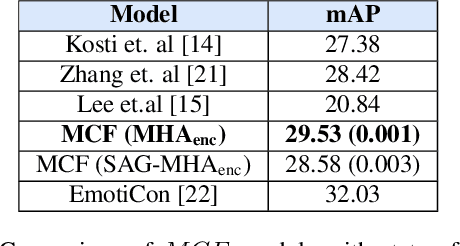
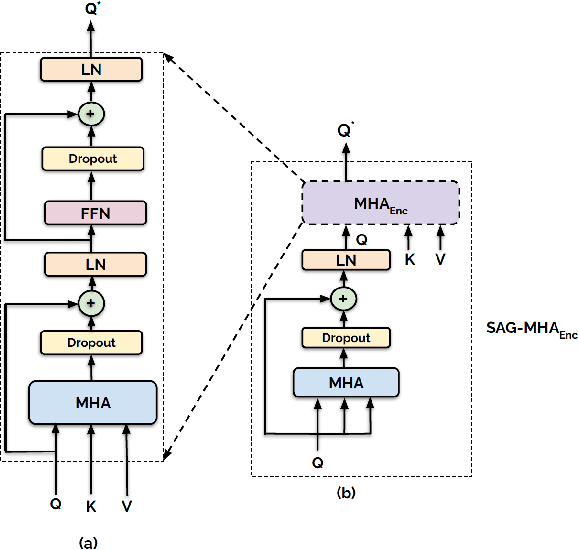
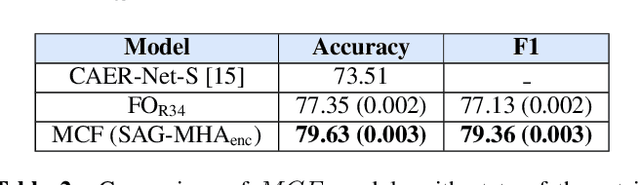
The process of human affect understanding involves the ability to infer person specific emotional states from various sources including images, speech, and language. Affect perception from images has predominantly focused on expressions extracted from salient face crops. However, emotions perceived by humans rely on multiple contextual cues including social settings, foreground interactions, and ambient visual scenes. In this work, we leverage pretrained vision-language (VLN) models to extract descriptions of foreground context from images. Further, we propose a multimodal context fusion (MCF) module to combine foreground cues with the visual scene and person-based contextual information for emotion prediction. We show the effectiveness of our proposed modular design on two datasets associated with natural scenes and TV shows.
Fast and accurate factorized neural transducer for text adaption of end-to-end speech recognition models
Dec 05, 2022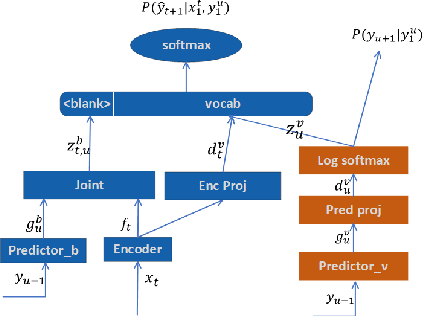
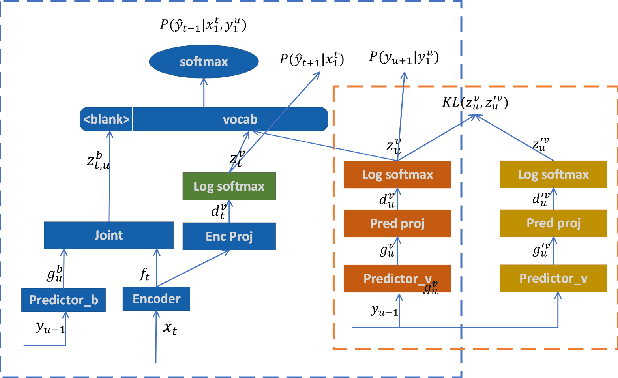

Neural transducer is now the most popular end-to-end model for speech recognition, due to its naturally streaming ability. However, it is challenging to adapt it with text-only data. Factorized neural transducer (FNT) model was proposed to mitigate this problem. The improved adaptation ability of FNT on text-only adaptation data came at the cost of lowered accuracy compared to the standard neural transducer model. We propose several methods to improve the performance of the FNT model. They are: adding CTC criterion during training, adding KL divergence loss during adaptation, using a pre-trained language model to seed the vocabulary predictor, and an efficient adaptation approach by interpolating the vocabulary predictor with the n-gram language model. A combination of these approaches results in a relative word-error-rate reduction of 9.48\% from the standard FNT model. Furthermore, n-gram interpolation with the vocabulary predictor improves the adaptation speed hugely with satisfactory adaptation performance.
Text-To-Speech Data Augmentation for Low Resource Speech Recognition
Apr 01, 2022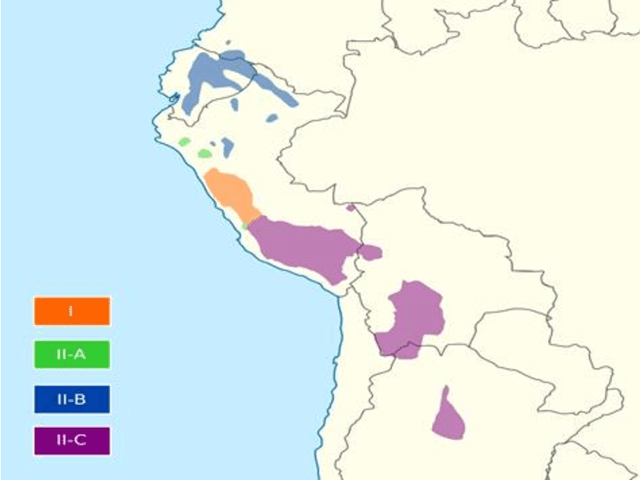
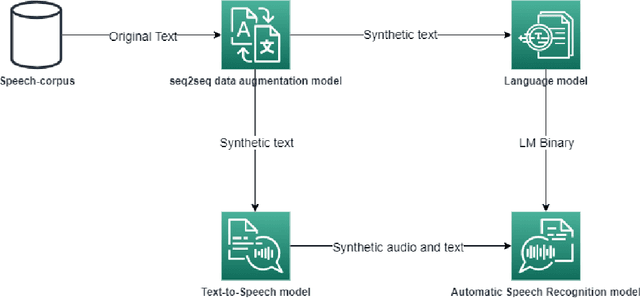
Nowadays, the main problem of deep learning techniques used in the development of automatic speech recognition (ASR) models is the lack of transcribed data. The goal of this research is to propose a new data augmentation method to improve ASR models for agglutinative and low-resource languages. This novel data augmentation method generates both synthetic text and synthetic audio. Some experiments were conducted using the corpus of the Quechua language, which is an agglutinative and low-resource language. In this study, a sequence-to-sequence (seq2seq) model was applied to generate synthetic text, in addition to generating synthetic speech using a text-to-speech (TTS) model for Quechua. The results show that the new data augmentation method works well to improve the ASR model for Quechua. In this research, an 8.73% improvement in the word-error-rate (WER) of the ASR model is obtained using a combination of synthetic text and synthetic speech.
Talking Head from Speech Audio using a Pre-trained Image Generator
Sep 09, 2022
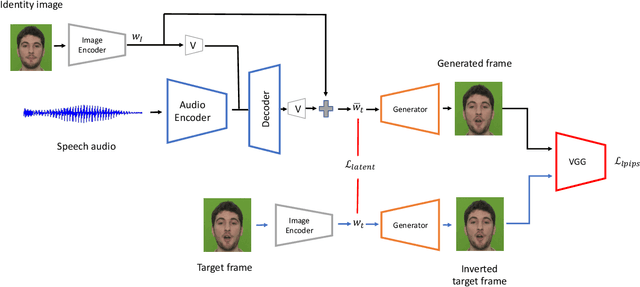
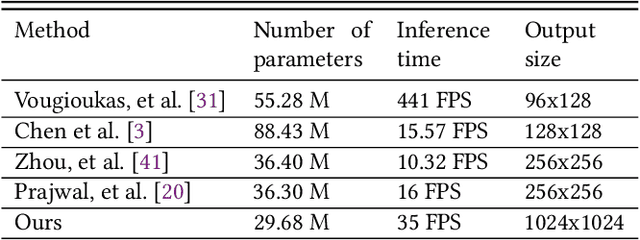

We propose a novel method for generating high-resolution videos of talking-heads from speech audio and a single 'identity' image. Our method is based on a convolutional neural network model that incorporates a pre-trained StyleGAN generator. We model each frame as a point in the latent space of StyleGAN so that a video corresponds to a trajectory through the latent space. Training the network is in two stages. The first stage is to model trajectories in the latent space conditioned on speech utterances. To do this, we use an existing encoder to invert the generator, mapping from each video frame into the latent space. We train a recurrent neural network to map from speech utterances to displacements in the latent space of the image generator. These displacements are relative to the back-projection into the latent space of an identity image chosen from the individuals depicted in the training dataset. In the second stage, we improve the visual quality of the generated videos by tuning the image generator on a single image or a short video of any chosen identity. We evaluate our model on standard measures (PSNR, SSIM, FID and LMD) and show that it significantly outperforms recent state-of-the-art methods on one of two commonly used datasets and gives comparable performance on the other. Finally, we report on ablation experiments that validate the components of the model. The code and videos from experiments can be found at https://mohammedalghamdi.github.io/talking-heads-acm-mm
Supervision-Guided Codebooks for Masked Prediction in Speech Pre-training
Jun 21, 2022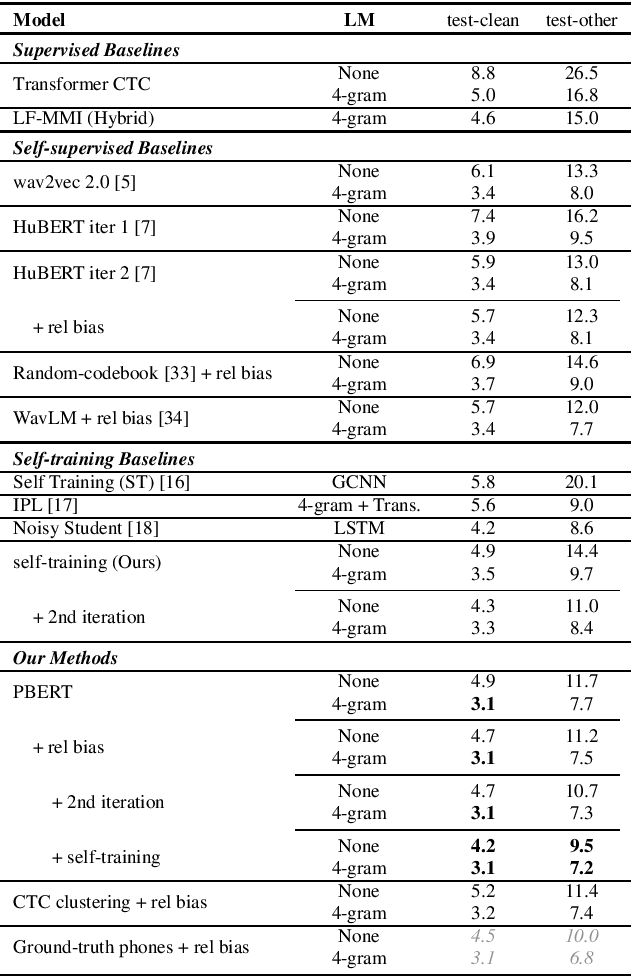
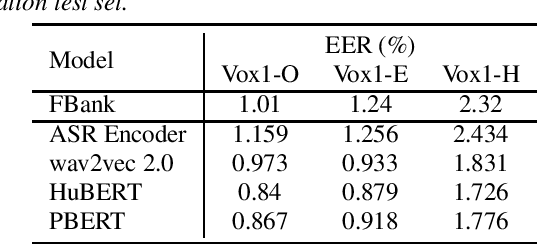
Recently, masked prediction pre-training has seen remarkable progress in self-supervised learning (SSL) for speech recognition. It usually requires a codebook obtained in an unsupervised way, making it less accurate and difficult to interpret. We propose two supervision-guided codebook generation approaches to improve automatic speech recognition (ASR) performance and also the pre-training efficiency, either through decoding with a hybrid ASR system to generate phoneme-level alignments (named PBERT), or performing clustering on the supervised speech features extracted from an end-to-end CTC model (named CTC clustering). Both the hybrid and CTC models are trained on the same small amount of labeled speech as used in fine-tuning. Experiments demonstrate significant superiority of our methods to various SSL and self-training baselines, with up to 17.0% relative WER reduction. Our pre-trained models also show good transferability in a non-ASR speech task.