 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Alternative Speech: Complementary Method to Counter-Narrative for Better Discourse
Jan 26, 2024
We introduce the concept of "Alternative Speech" as a new way to directly combat hate speech and complement the limitations of counter-narrative. An alternative speech provides practical alternatives to hate speech in real-world scenarios by offering speech-level corrections to speakers while considering the surrounding context and promoting speakers to reform. Further, an alternative speech can combat hate speech alongside counter-narratives, offering a useful tool to address social issues such as racial discrimination and gender inequality. We propose the new concept and provide detailed guidelines for constructing the necessary dataset. Through discussion, we demonstrate that combining alternative speech and counter-narrative can be a more effective strategy for combating hate speech by complementing specificity and guiding capacity of counter-narrative. This paper presents another perspective for dealing with hate speech, offering viable remedies to complement the constraints of current approaches to mitigating harmful bias.
SpeechGPT-Gen: Scaling Chain-of-Information Speech Generation
Jan 25, 2024Benefiting from effective speech modeling, current Speech Large Language Models (SLLMs) have demonstrated exceptional capabilities in in-context speech generation and efficient generalization to unseen speakers. However, the prevailing information modeling process is encumbered by certain redundancies, leading to inefficiencies in speech generation. We propose Chain-of-Information Generation (CoIG), a method for decoupling semantic and perceptual information in large-scale speech generation. Building on this, we develop SpeechGPT-Gen, an 8-billion-parameter SLLM efficient in semantic and perceptual information modeling. It comprises an autoregressive model based on LLM for semantic information modeling and a non-autoregressive model employing flow matching for perceptual information modeling. Additionally, we introduce the novel approach of infusing semantic information into the prior distribution to enhance the efficiency of flow matching. Extensive experimental results demonstrate that SpeechGPT-Gen markedly excels in zero-shot text-to-speech, zero-shot voice conversion, and speech-to-speech dialogue, underscoring CoIG's remarkable proficiency in capturing and modeling speech's semantic and perceptual dimensions. Code and models are available at https://github.com/0nutation/SpeechGPT.
Computation and Parameter Efficient Multi-Modal Fusion Transformer for Cued Speech Recognition
Feb 08, 2024Cued Speech (CS) is a pure visual coding method used by hearing-impaired people that combines lip reading with several specific hand shapes to make the spoken language visible. Automatic CS recognition (ACSR) seeks to transcribe visual cues of speech into text, which can help hearing-impaired people to communicate effectively. The visual information of CS contains lip reading and hand cueing, thus the fusion of them plays an important role in ACSR. However, most previous fusion methods struggle to capture the global dependency present in long sequence inputs of multi-modal CS data. As a result, these methods generally fail to learn the effective cross-modal relationships that contribute to the fusion. Recently, attention-based transformers have been a prevalent idea for capturing the global dependency over the long sequence in multi-modal fusion, but existing multi-modal fusion transformers suffer from both poor recognition accuracy and inefficient computation for the ACSR task. To address these problems, we develop a novel computation and parameter efficient multi-modal fusion transformer by proposing a novel Token-Importance-Aware Attention mechanism (TIAA), where a token utilization rate (TUR) is formulated to select the important tokens from the multi-modal streams. More precisely, TIAA firstly models the modality-specific fine-grained temporal dependencies over all tokens of each modality, and then learns the efficient cross-modal interaction for the modality-shared coarse-grained temporal dependencies over the important tokens of different modalities. Besides, a light-weight gated hidden projection is designed to control the feature flows of TIAA. The resulting model, named Economical Cued Speech Fusion Transformer (EcoCued), achieves state-of-the-art performance on all existing CS datasets, compared with existing transformer-based fusion methods and ACSR fusion methods.
Self-supervised speech representation and contextual text embedding for match-mismatch classification with EEG recording
Feb 01, 2024Relating speech to EEG holds considerable importance but is challenging. In this study, a deep convolutional network was employed to extract spatiotemporal features from EEG data. Self-supervised speech representation and contextual text embedding were used as speech features. Contrastive learning was used to relate EEG features to speech features. The experimental results demonstrate the benefits of using self-supervised speech representation and contextual text embedding. Through feature fusion and model ensemble, an accuracy of 60.29% was achieved, and the performance was ranked as No.2 in Task 1 of the Auditory EEG Challenge (ICASSP 2024). The code to implement our work is available on Github: https://github.com/bobwangPKU/EEG-Stimulus-Match-Mismatch.
Natural language guidance of high-fidelity text-to-speech with synthetic annotations
Feb 02, 2024Text-to-speech models trained on large-scale datasets have demonstrated impressive in-context learning capabilities and naturalness. However, control of speaker identity and style in these models typically requires conditioning on reference speech recordings, limiting creative applications. Alternatively, natural language prompting of speaker identity and style has demonstrated promising results and provides an intuitive method of control. However, reliance on human-labeled descriptions prevents scaling to large datasets. Our work bridges the gap between these two approaches. We propose a scalable method for labeling various aspects of speaker identity, style, and recording conditions. We then apply this method to a 45k hour dataset, which we use to train a speech language model. Furthermore, we propose simple methods for increasing audio fidelity, significantly outperforming recent work despite relying entirely on found data. Our results demonstrate high-fidelity speech generation in a diverse range of accents, prosodic styles, channel conditions, and acoustic conditions, all accomplished with a single model and intuitive natural language conditioning. Audio samples can be heard at https://text-description-to-speech.com/.
A Comprehensive Study of the Current State-of-the-Art in Nepali Automatic Speech Recognition Systems
Feb 05, 2024In this paper, we examine the research conducted in the field of Nepali Automatic Speech Recognition (ASR). The primary objective of this survey is to conduct a comprehensive review of the works on Nepali Automatic Speech Recognition Systems completed to date, explore the different datasets used, examine the technology utilized, and take account of the obstacles encountered in implementing the Nepali ASR system. In tandem with the global trends of ever-increasing research on speech recognition based research, the number of Nepalese ASR-related projects are also growing. Nevertheless, the investigation of language and acoustic models of the Nepali language has not received adequate attention compared to languages that possess ample resources. In this context, we provide a framework as well as directions for future investigations.
Objective and subjective evaluation of speech enhancement methods in the UDASE task of the 7th CHiME challenge
Feb 02, 2024Supervised models for speech enhancement are trained using artificially generated mixtures of clean speech and noise signals. However, the synthetic training conditions may not accurately reflect real-world conditions encountered during testing. This discrepancy can result in poor performance when the test domain significantly differs from the synthetic training domain. To tackle this issue, the UDASE task of the 7th CHiME challenge aimed to leverage real-world noisy speech recordings from the test domain for unsupervised domain adaptation of speech enhancement models. Specifically, this test domain corresponds to the CHiME-5 dataset, characterized by real multi-speaker and conversational speech recordings made in noisy and reverberant domestic environments, for which ground-truth clean speech signals are not available. In this paper, we present the objective and subjective evaluations of the systems that were submitted to the CHiME-7 UDASE task, and we provide an analysis of the results. This analysis reveals a limited correlation between subjective ratings and several supervised nonintrusive performance metrics recently proposed for speech enhancement. Conversely, the results suggest that more traditional intrusive objective metrics can be used for in-domain performance evaluation using the reverberant LibriCHiME-5 dataset developed for the challenge. The subjective evaluation indicates that all systems successfully reduced the background noise, but always at the expense of increased distortion. Out of the four speech enhancement methods evaluated subjectively, only one demonstrated an improvement in overall quality compared to the unprocessed noisy speech, highlighting the difficulty of the task. The tools and audio material created for the CHiME-7 UDASE task are shared with the community.
SA-SOT: Speaker-Aware Serialized Output Training for Multi-Talker ASR
Mar 04, 2024
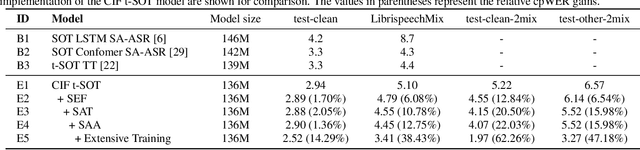
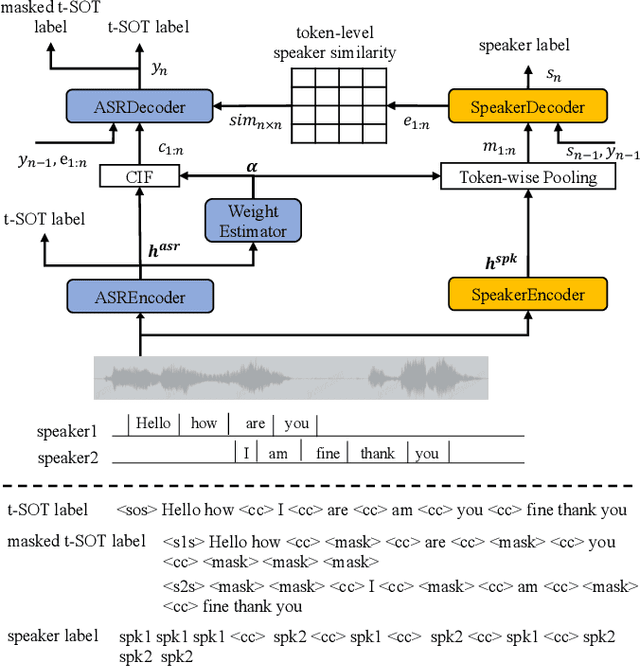
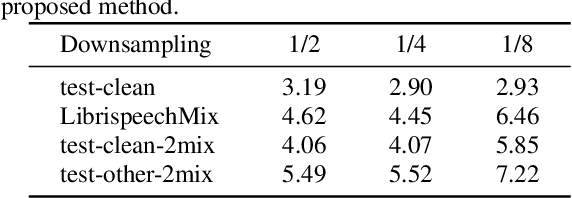
Multi-talker automatic speech recognition plays a crucial role in scenarios involving multi-party interactions, such as meetings and conversations. Due to its inherent complexity, this task has been receiving increasing attention. Notably, the serialized output training (SOT) stands out among various approaches because of its simplistic architecture and exceptional performance. However, the frequent speaker changes in token-level SOT (t-SOT) present challenges for the autoregressive decoder in effectively utilizing context to predict output sequences. To address this issue, we introduce a masked t-SOT label, which serves as the cornerstone of an auxiliary training loss. Additionally, we utilize a speaker similarity matrix to refine the self-attention mechanism of the decoder. This strategic adjustment enhances contextual relationships within the same speaker's tokens while minimizing interactions between different speakers' tokens. We denote our method as speaker-aware SOT (SA-SOT). Experiments on the Librispeech datasets demonstrate that our SA-SOT obtains a relative cpWER reduction ranging from 12.75% to 22.03% on the multi-talker test sets. Furthermore, with more extensive training, our method achieves an impressive cpWER of 3.41%, establishing a new state-of-the-art result on the LibrispeechMix dataset.
Automated Generation of Multiple-Choice Cloze Questions for Assessing English Vocabulary Using GPT-turbo 3.5
Mar 04, 2024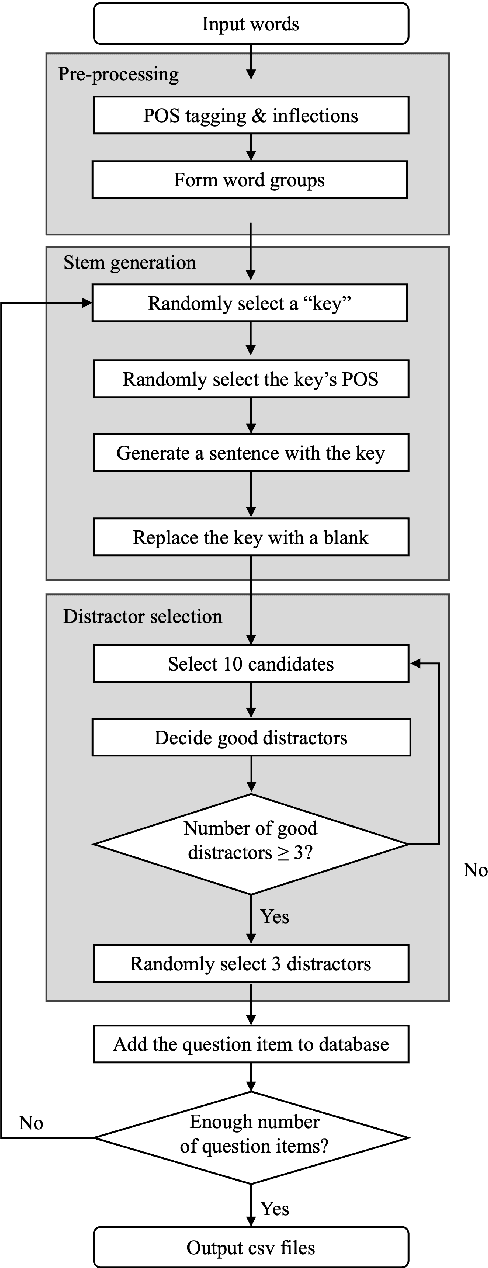
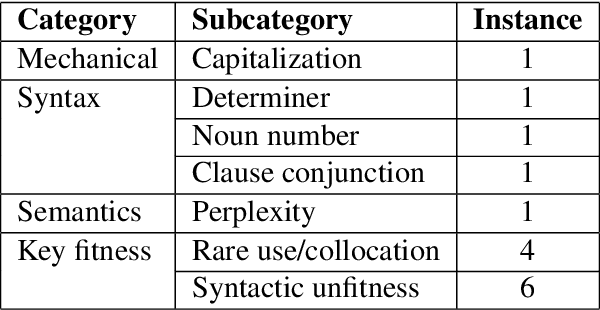
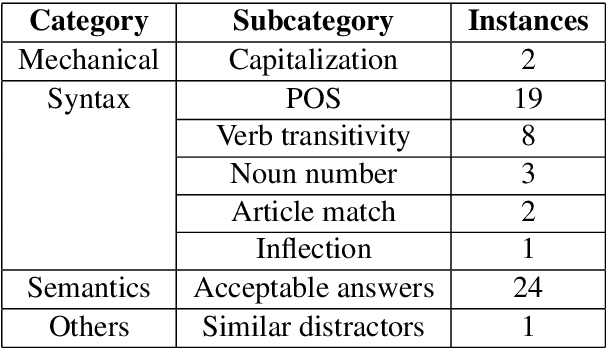
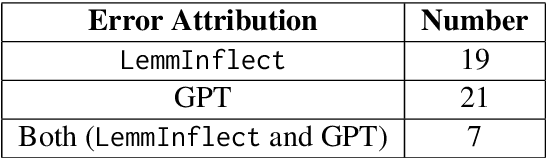
A common way of assessing language learners' mastery of vocabulary is via multiple-choice cloze (i.e., fill-in-the-blank) questions. But the creation of test items can be laborious for individual teachers or in large-scale language programs. In this paper, we evaluate a new method for automatically generating these types of questions using large language models (LLM). The VocaTT (vocabulary teaching and training) engine is written in Python and comprises three basic steps: pre-processing target word lists, generating sentences and candidate word options using GPT, and finally selecting suitable word options. To test the efficiency of this system, 60 questions were generated targeting academic words. The generated items were reviewed by expert reviewers who judged the well-formedness of the sentences and word options, adding comments to items judged not well-formed. Results showed a 75% rate of well-formedness for sentences and 66.85% rate for suitable word options. This is a marked improvement over the generator used earlier in our research which did not take advantage of GPT's capabilities. Post-hoc qualitative analysis reveals several points for improvement in future work including cross-referencing part-of-speech tagging, better sentence validation, and improving GPT prompts.
KS-Net: Multi-band joint speech restoration and enhancement network for 2024 ICASSP SSI Challenge
Feb 02, 2024This paper presents the speech restoration and enhancement system created by the 1024K team for the ICASSP 2024 Speech Signal Improvement (SSI) Challenge. Our system consists of a generative adversarial network (GAN) in complex-domain for speech restoration and a fine-grained multi-band fusion module for speech enhancement. In the blind test set of SSI, the proposed system achieves an overall mean opinion score (MOS) of 3.49 based on ITU-T P.804 and a Word Accuracy Rate (WAcc) of 0.78 for the real-time track, as well as an overall P.804 MOS of 3.43 and a WAcc of 0.78 for the non-real-time track, ranking 1st in both tracks.