 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Active Learning of Non-semantic Speech Tasks with Pretrained Models
Nov 03, 2022
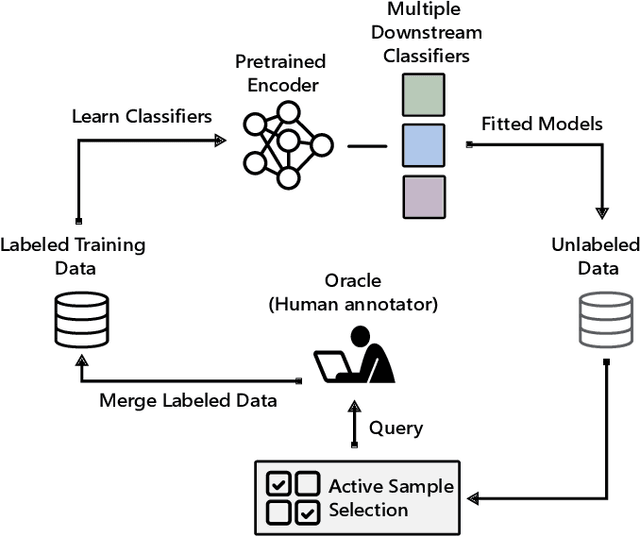
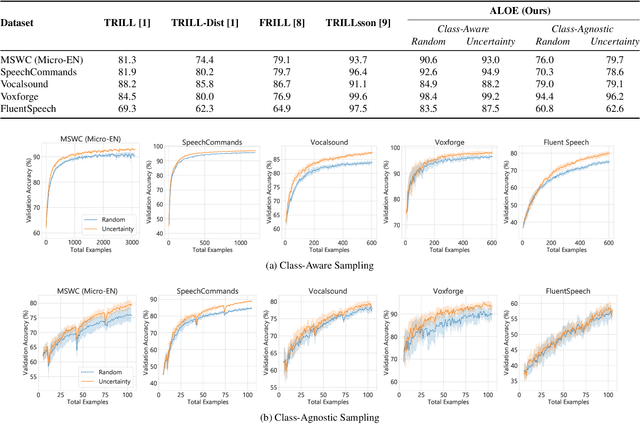

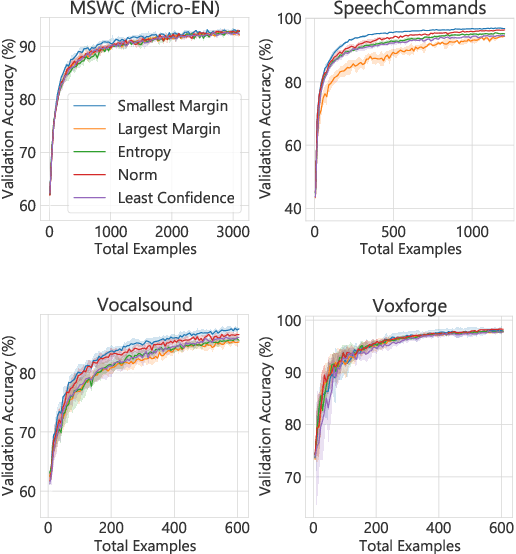
Pretraining neural networks with massive unlabeled datasets has become popular as it equips the deep models with a better prior to solve downstream tasks. However, this approach generally assumes that for downstream tasks, we have access to annotated data of sufficient size. In this work, we propose ALOE, a novel system for improving the data- and label-efficiency of non-semantic speech tasks with active learning (AL). ALOE uses pre-trained models in conjunction with active learning to label data incrementally and learns classifiers for downstream tasks, thereby mitigating the need to acquire labeled data beforehand. We demonstrate the effectiveness of ALOE on a wide range of tasks, uncertainty-based acquisition functions, and model architectures. Training a linear classifier on top of a frozen encoder with ALOE is shown to achieve performance similar to several baselines that utilize the entire labeled data.
STEMM: Self-learning with Speech-text Manifold Mixup for Speech Translation
Mar 20, 2022
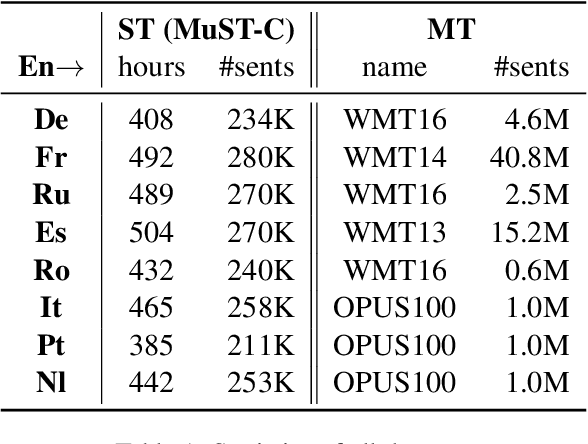
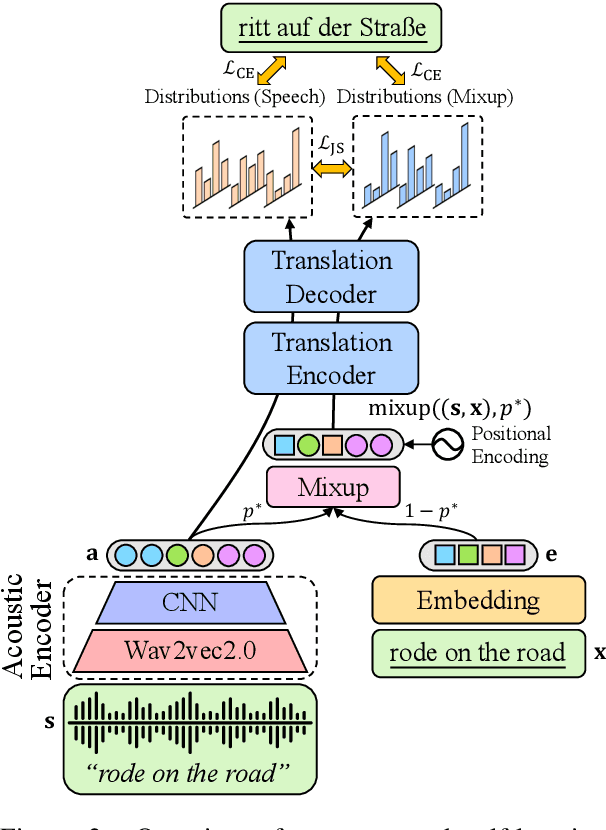
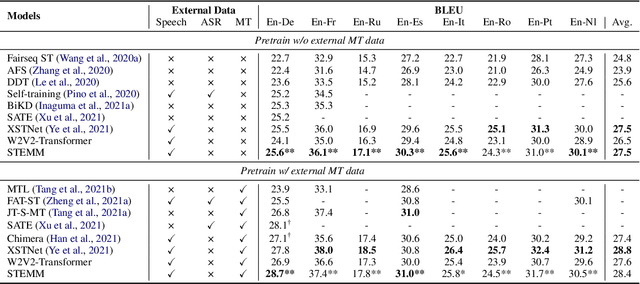
How to learn a better speech representation for end-to-end speech-to-text translation (ST) with limited labeled data? Existing techniques often attempt to transfer powerful machine translation (MT) capabilities to ST, but neglect the representation discrepancy across modalities. In this paper, we propose the Speech-TExt Manifold Mixup (STEMM) method to calibrate such discrepancy. Specifically, we mix up the representation sequences of different modalities, and take both unimodal speech sequences and multimodal mixed sequences as input to the translation model in parallel, and regularize their output predictions with a self-learning framework. Experiments on MuST-C speech translation benchmark and further analysis show that our method effectively alleviates the cross-modal representation discrepancy, and achieves significant improvements over a strong baseline on eight translation directions.
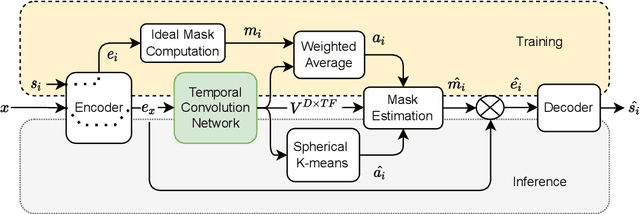
Separate And Diffuse: Using a Pretrained Diffusion Model for Improving Source Separation
Jan 25, 2023
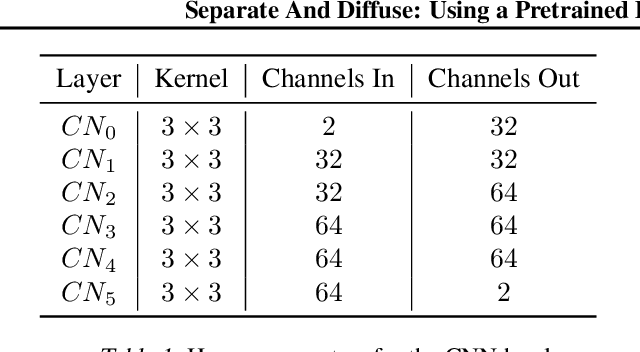
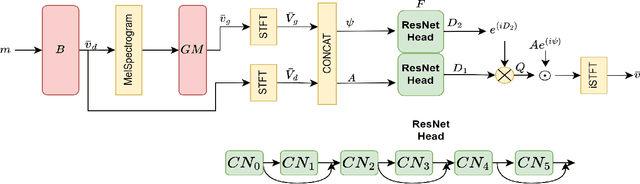
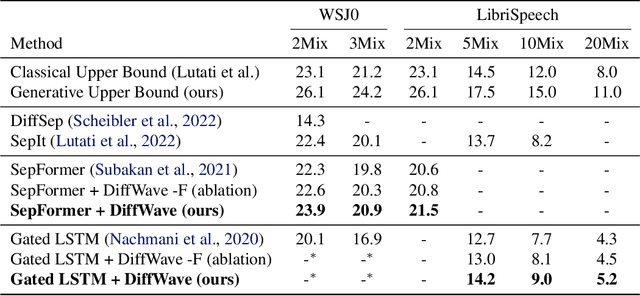
The problem of speech separation, also known as the cocktail party problem, refers to the task of isolating a single speech signal from a mixture of speech signals. Previous work on source separation derived an upper bound for the source separation task in the domain of human speech. This bound is derived for deterministic models. Recent advancements in generative models challenge this bound. We show how the upper bound can be generalized to the case of random generative models. Applying a diffusion model Vocoder that was pretrained to model single-speaker voices on the output of a deterministic separation model leads to state-of-the-art separation results. It is shown that this requires one to combine the output of the separation model with that of the diffusion model. In our method, a linear combination is performed, in the frequency domain, using weights that are inferred by a learned model. We show state-of-the-art results on 2, 3, 5, 10, and 20 speakers on multiple benchmarks. In particular, for two speakers, our method is able to surpass what was previously considered the upper performance bound.
Correcting Misproducted Speech using Spectrogram Inpainting
Apr 07, 2022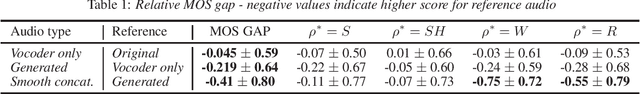
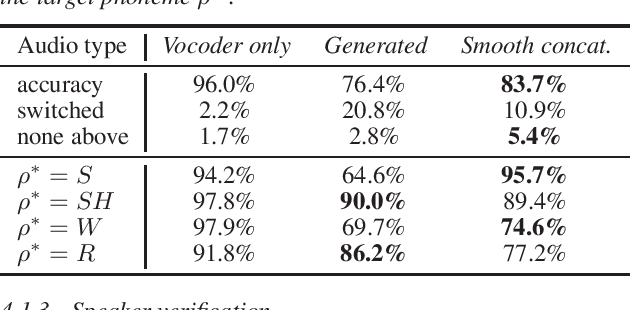
Learning a new language involves constantly comparing speech productions with reference productions from the environment. Early in speech acquisition, children make articulatory adjustments to match their caregivers' speech. Grownup learners of a language tweak their speech to match the tutor reference. This paper proposes a method to synthetically generate correct pronunciation feedback given incorrect production. Furthermore, our aim is to generate the corrected production while maintaining the speaker's original voice. The system prompts the user to pronounce a phrase. The speech is recorded, and the samples associated with the inaccurate phoneme are masked with zeros. This waveform serves as an input to a speech generator, implemented as a deep learning inpainting system with a U-net architecture, and trained to output a reconstructed speech. The training set is composed of unimpaired proper speech examples, and the generator is trained to reconstruct the original proper speech. We evaluated the performance of our system on phoneme replacement of minimal pair words of English as well as on children with pronunciation disorders. Results suggest that human listeners slightly prefer our generated speech over a smoothed replacement of the inaccurate phoneme with a production of a different speaker.
SATTS: Speaker Attractor Text to Speech, Learning to Speak by Learning to Separate
Jul 13, 2022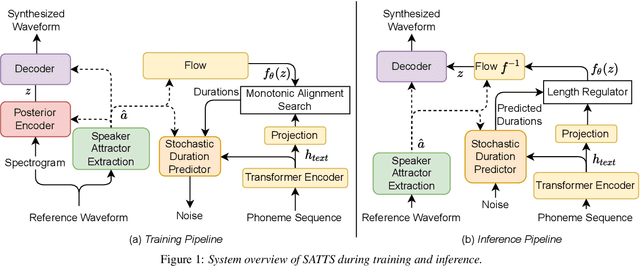
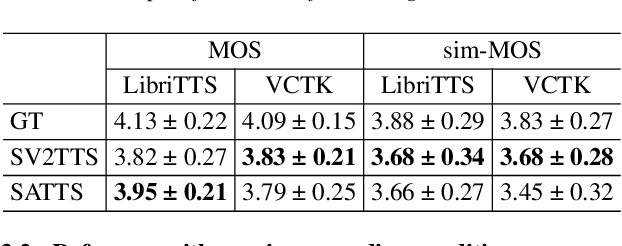

The mapping of text to speech (TTS) is non-deterministic, letters may be pronounced differently based on context, or phonemes can vary depending on various physiological and stylistic factors like gender, age, accent, emotions, etc. Neural speaker embeddings, trained to identify or verify speakers are typically used to represent and transfer such characteristics from reference speech to synthesized speech. Speech separation on the other hand is the challenging task of separating individual speakers from an overlapping mixed signal of various speakers. Speaker attractors are high-dimensional embedding vectors that pull the time-frequency bins of each speaker's speech towards themselves while repelling those belonging to other speakers. In this work, we explore the possibility of using these powerful speaker attractors for zero-shot speaker adaptation in multi-speaker TTS synthesis and propose speaker attractor text to speech (SATTS). Through various experiments, we show that SATTS can synthesize natural speech from text from an unseen target speaker's reference signal which might have less than ideal recording conditions, i.e. reverberations or mixed with other speakers.
Multilingual HateCheck: Functional Tests for Multilingual Hate Speech Detection Models
Jun 20, 2022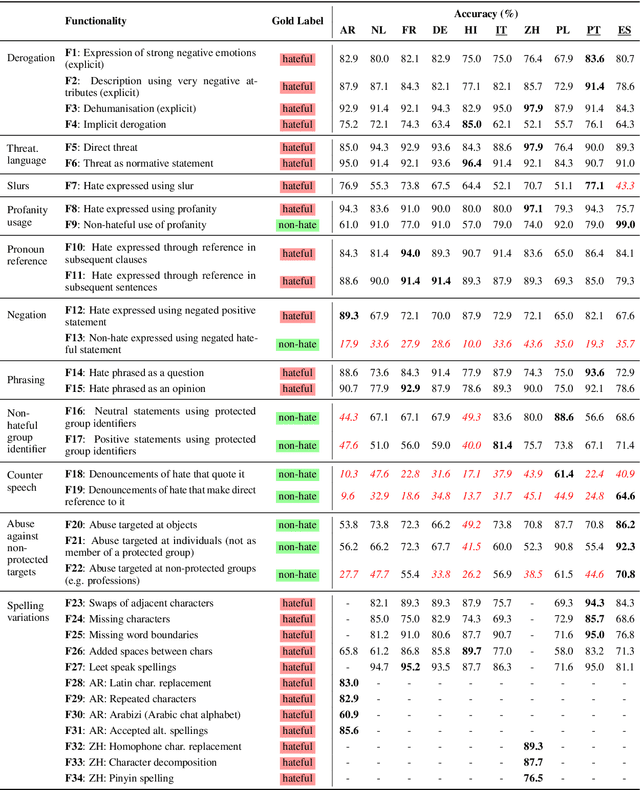
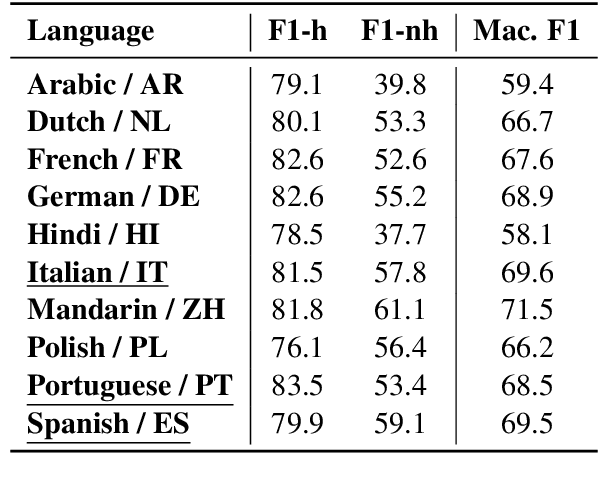
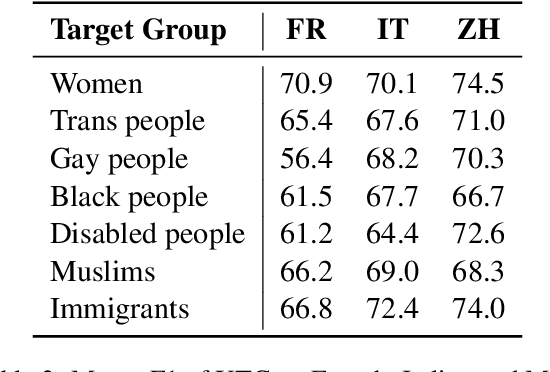
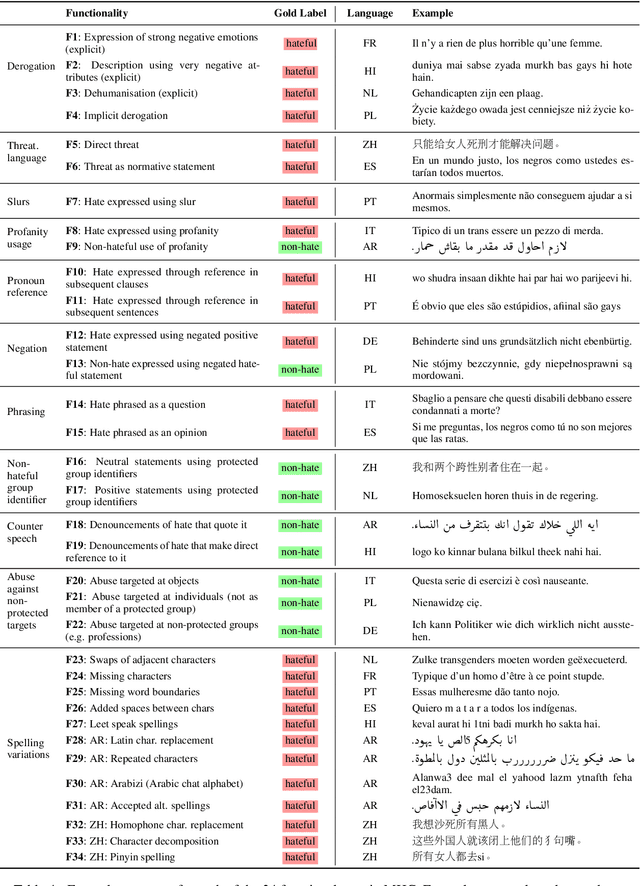
Hate speech detection models are typically evaluated on held-out test sets. However, this risks painting an incomplete and potentially misleading picture of model performance because of increasingly well-documented systematic gaps and biases in hate speech datasets. To enable more targeted diagnostic insights, recent research has thus introduced functional tests for hate speech detection models. However, these tests currently only exist for English-language content, which means that they cannot support the development of more effective models in other languages spoken by billions across the world. To help address this issue, we introduce Multilingual HateCheck (MHC), a suite of functional tests for multilingual hate speech detection models. MHC covers 34 functionalities across ten languages, which is more languages than any other hate speech dataset. To illustrate MHC's utility, we train and test a high-performing multilingual hate speech detection model, and reveal critical model weaknesses for monolingual and cross-lingual applications.
Automatic Prosody Annotation with Pre-Trained Text-Speech Model
Jun 16, 2022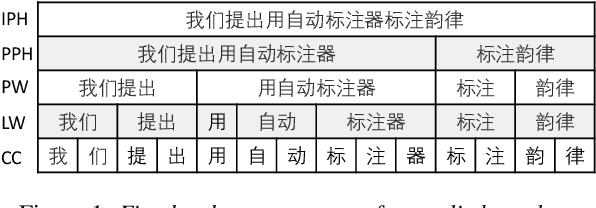
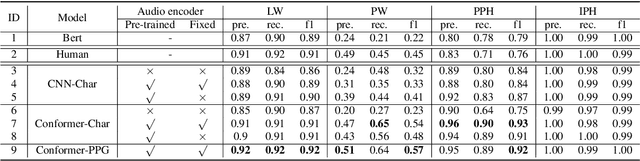
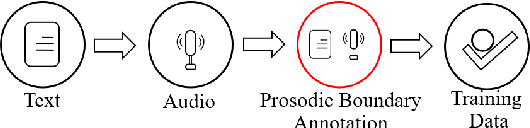

Prosodic boundary plays an important role in text-to-speech synthesis (TTS) in terms of naturalness and readability. However, the acquisition of prosodic boundary labels relies on manual annotation, which is costly and time-consuming. In this paper, we propose to automatically extract prosodic boundary labels from text-audio data via a neural text-speech model with pre-trained audio encoders. This model is pre-trained on text and speech data separately and jointly fine-tuned on TTS data in a triplet format: {speech, text, prosody}. The experimental results on both automatic evaluation and human evaluation demonstrate that: 1) the proposed text-speech prosody annotation framework significantly outperforms text-only baselines; 2) the quality of automatic prosodic boundary annotations is comparable to human annotations; 3) TTS systems trained with model-annotated boundaries are slightly better than systems that use manual ones.
Right the docs: Characterising voice dataset documentation practices used in machine learning
Mar 19, 2023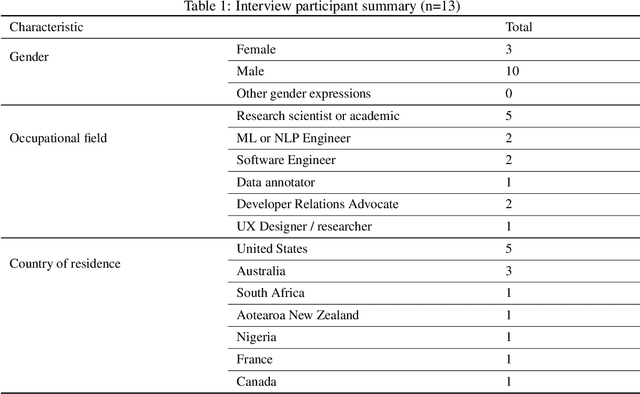
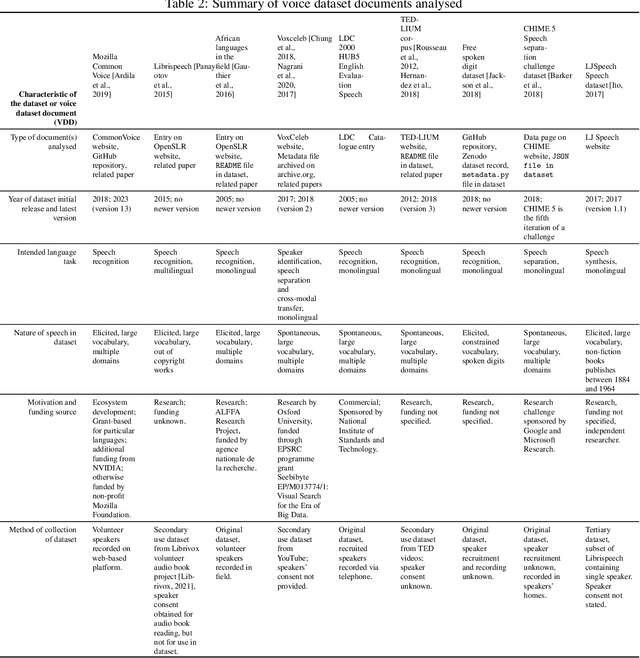
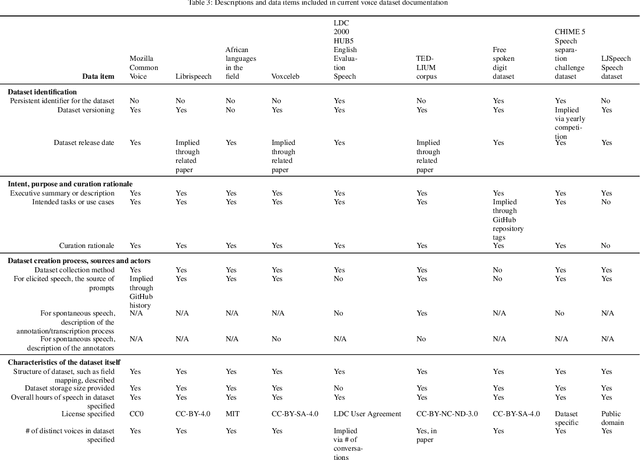
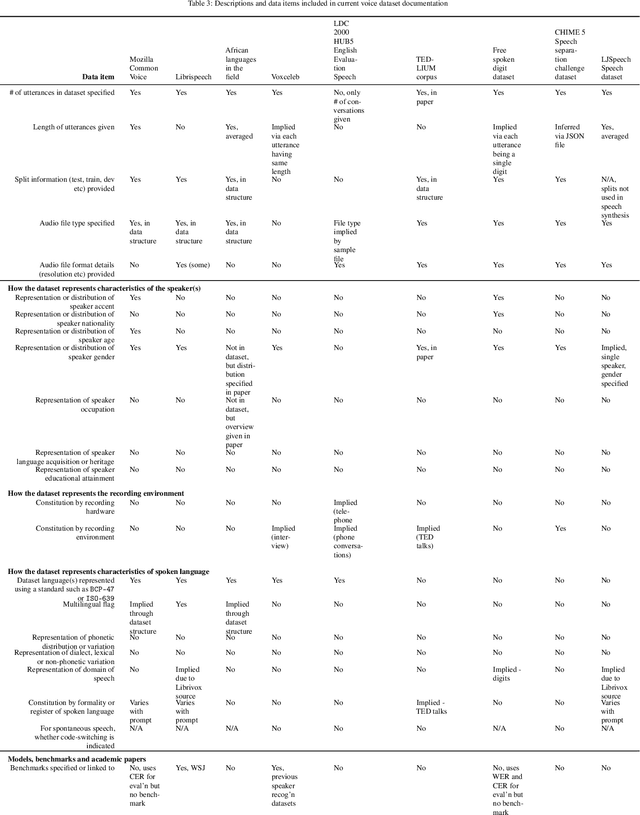
Voice-enabled technology is quickly becoming ubiquitous, and is constituted from machine learning (ML)-enabled components such as speech recognition and voice activity detection. However, these systems don't yet work well for everyone. They exhibit bias - the systematic and unfair discrimination against individuals or cohorts of individuals in favour of others (Friedman & Nissembaum, 1996) - across axes such as age, gender and accent. ML is reliant on large datasets for training. Dataset documentation is designed to give ML Practitioners (MLPs) a better understanding of a dataset's characteristics. However, there is a lack of empirical research on voice dataset documentation specifically. Additionally, while MLPs are frequent participants in fairness research, little work focuses on those who work with voice data. Our work makes an empirical contribution to this gap. Here, we combine two methods to form an exploratory study. First, we undertake 13 semi-structured interviews, exploring multiple perspectives of voice dataset documentation practice. Using open and axial coding methods, we explore MLPs' practices through the lenses of roles and tradeoffs. Drawing from this work, we then purposively sample voice dataset documents (VDDs) for 9 voice datasets. Our findings then triangulate these two methods, using the lenses of MLP roles and trade-offs. We find that current VDD practices are inchoate, inadequate and incommensurate. The characteristics of voice datasets are codified in fragmented, disjoint ways that often do not meet the needs of MLPs. Moreover, they cannot be readily compared, presenting a barrier to practitioners' bias reduction efforts. We then discuss the implications of these findings for bias practices in voice data and speech technologies. We conclude by setting out a program of future work to address these findings -- that is, how we may "right the docs".
READIN: A Chinese Multi-Task Benchmark with Realistic and Diverse Input Noises
Feb 14, 2023

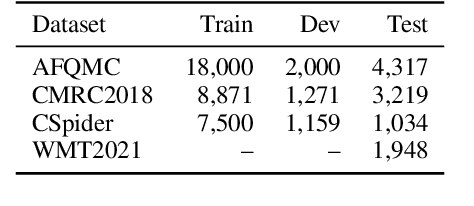
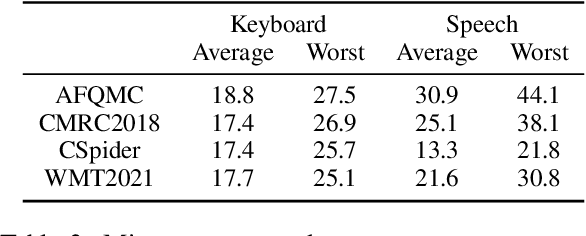
For many real-world applications, the user-generated inputs usually contain various noises due to speech recognition errors caused by linguistic variations1 or typographical errors (typos). Thus, it is crucial to test model performance on data with realistic input noises to ensure robustness and fairness. However, little study has been done to construct such benchmarks for Chinese, where various language-specific input noises happen in the real world. In order to fill this important gap, we construct READIN: a Chinese multi-task benchmark with REalistic And Diverse Input Noises. READIN contains four diverse tasks and requests annotators to re-enter the original test data with two commonly used Chinese input methods: Pinyin input and speech input. We designed our annotation pipeline to maximize diversity, for example by instructing the annotators to use diverse input method editors (IMEs) for keyboard noises and recruiting speakers from diverse dialectical groups for speech noises. We experiment with a series of strong pretrained language models as well as robust training methods, we find that these models often suffer significant performance drops on READIN even with robustness methods like data augmentation. As the first large-scale attempt in creating a benchmark with noises geared towards user-generated inputs, we believe that READIN serves as an important complement to existing Chinese NLP benchmarks. The source code and dataset can be obtained from https://github.com/thunlp/READIN.
TaylorAECNet: A Taylor Style Neural Network for Full-Band Echo Cancellation
Mar 11, 2023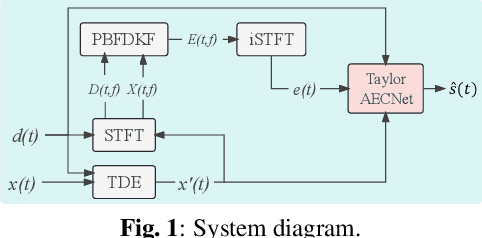
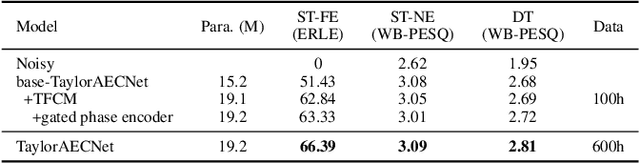
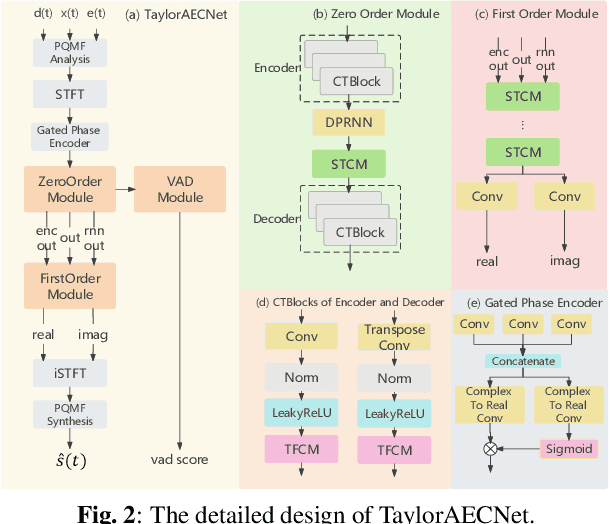

This paper describes aecX team's entry to the ICASSP 2023 acoustic echo cancellation (AEC) challenge. Our system consists of an adaptive filter and a proposed full-band Taylor-style acoustic echo cancellation neural network (TaylorAECNet) as a post-filter. Specifically, we leverage the recent advances in Taylor expansion based decoupling-style interpretable speech enhancement and explore its feasibility in the AEC task. Our TaylorAECNet based approach achieves an overall mean opinion score (MOS) of 4.241, a word accuracy (WAcc) ratio of 0.767, and ranks 5th in the non-personalized track (track 1).