 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Self-Supervised Speech Representation Learning: A Review
May 21, 2022
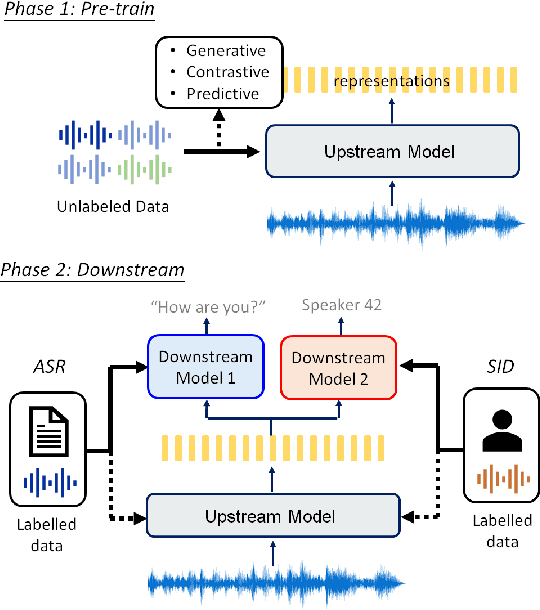
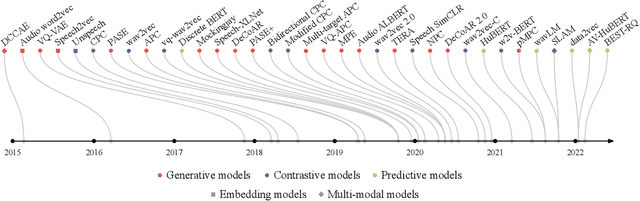
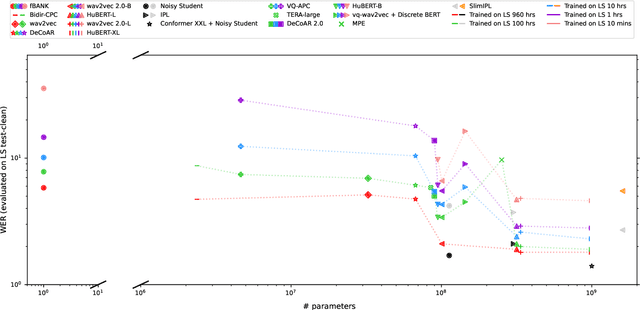
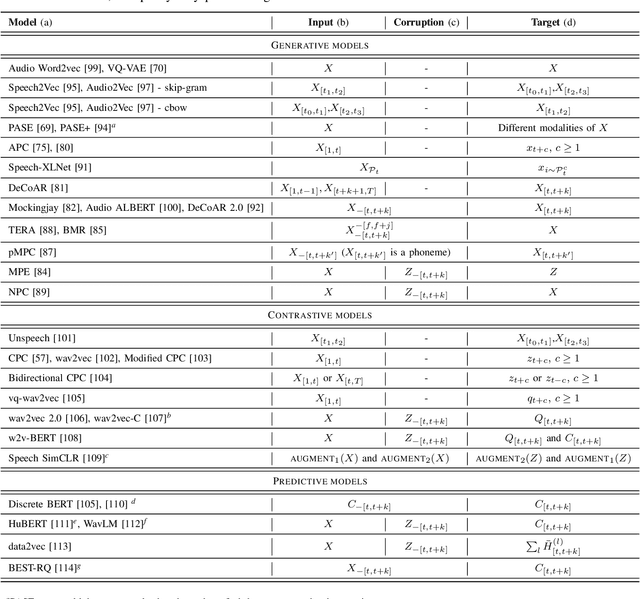
Although supervised deep learning has revolutionized speech and audio processing, it has necessitated the building of specialist models for individual tasks and application scenarios. It is likewise difficult to apply this to dialects and languages for which only limited labeled data is available. Self-supervised representation learning methods promise a single universal model that would benefit a wide variety of tasks and domains. Such methods have shown success in natural language processing and computer vision domains, achieving new levels of performance while reducing the number of labels required for many downstream scenarios. Speech representation learning is experiencing similar progress in three main categories: generative, contrastive, and predictive methods. Other approaches rely on multi-modal data for pre-training, mixing text or visual data streams with speech. Although self-supervised speech representation is still a nascent research area, it is closely related to acoustic word embedding and learning with zero lexical resources, both of which have seen active research for many years. This review presents approaches for self-supervised speech representation learning and their connection to other research areas. Since many current methods focus solely on automatic speech recognition as a downstream task, we review recent efforts on benchmarking learned representations to extend the application beyond speech recognition.
End-to-End Integration of Speech Recognition, Speech Enhancement, and Self-Supervised Learning Representation
Apr 01, 2022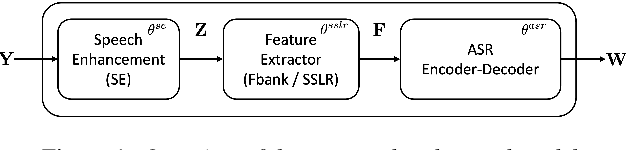
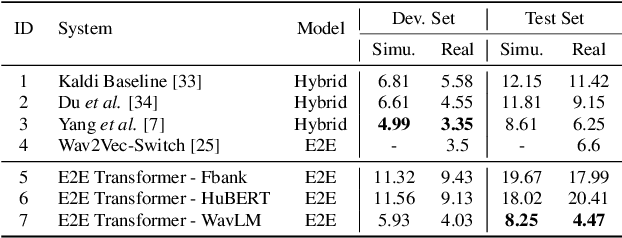
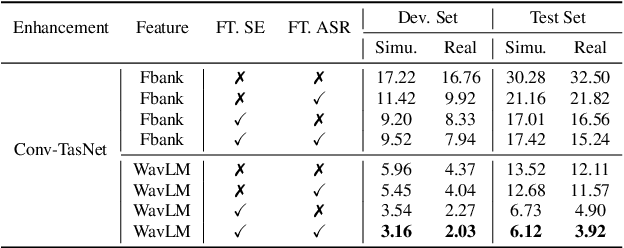
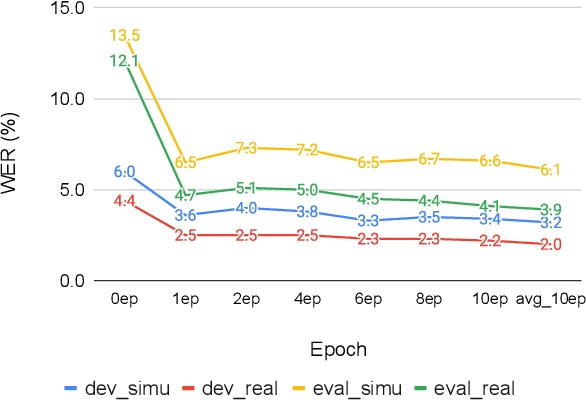
This work presents our end-to-end (E2E) automatic speech recognition (ASR) model targetting at robust speech recognition, called Integraded speech Recognition with enhanced speech Input for Self-supervised learning representation (IRIS). Compared with conventional E2E ASR models, the proposed E2E model integrates two important modules including a speech enhancement (SE) module and a self-supervised learning representation (SSLR) module. The SE module enhances the noisy speech. Then the SSLR module extracts features from enhanced speech to be used for speech recognition (ASR). To train the proposed model, we establish an efficient learning scheme. Evaluation results on the monaural CHiME-4 task show that the IRIS model achieves the best performance reported in the literature for the single-channel CHiME-4 benchmark (2.0% for the real development and 3.9% for the real test) thanks to the powerful pre-trained SSLR module and the fine-tuned SE module.
Learning Audio-Driven Viseme Dynamics for 3D Face Animation
Jan 15, 2023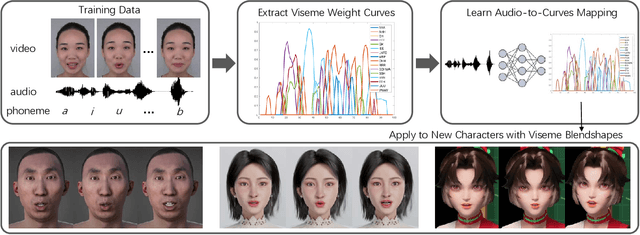

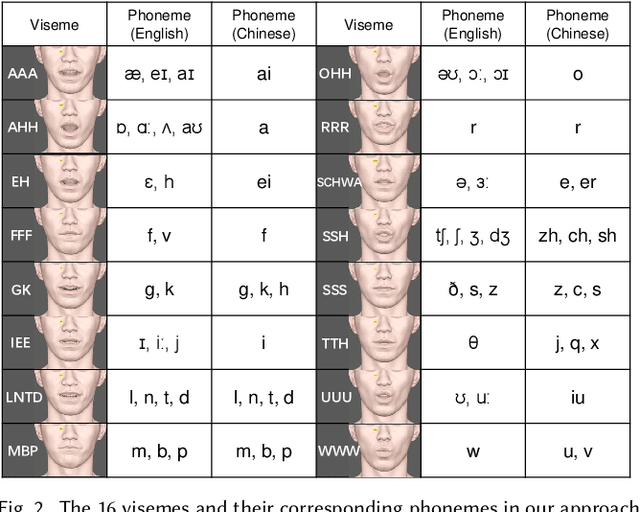
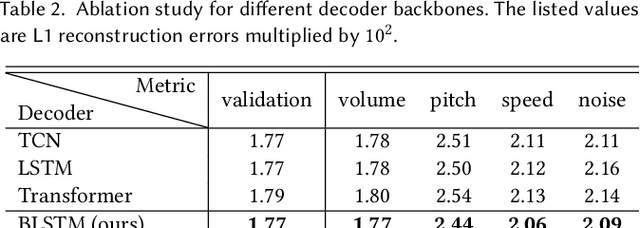
We present a novel audio-driven facial animation approach that can generate realistic lip-synchronized 3D facial animations from the input audio. Our approach learns viseme dynamics from speech videos, produces animator-friendly viseme curves, and supports multilingual speech inputs. The core of our approach is a novel parametric viseme fitting algorithm that utilizes phoneme priors to extract viseme parameters from speech videos. With the guidance of phonemes, the extracted viseme curves can better correlate with phonemes, thus more controllable and friendly to animators. To support multilingual speech inputs and generalizability to unseen voices, we take advantage of deep audio feature models pretrained on multiple languages to learn the mapping from audio to viseme curves. Our audio-to-curves mapping achieves state-of-the-art performance even when the input audio suffers from distortions of volume, pitch, speed, or noise. Lastly, a viseme scanning approach for acquiring high-fidelity viseme assets is presented for efficient speech animation production. We show that the predicted viseme curves can be applied to different viseme-rigged characters to yield various personalized animations with realistic and natural facial motions. Our approach is artist-friendly and can be easily integrated into typical animation production workflows including blendshape or bone based animation.
Learning Speaker-specific Lip-to-Speech Generation
Jun 04, 2022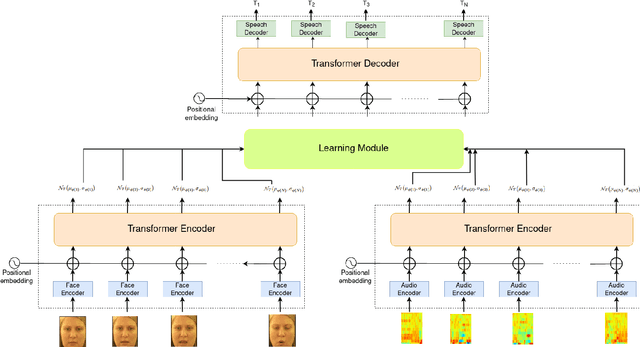
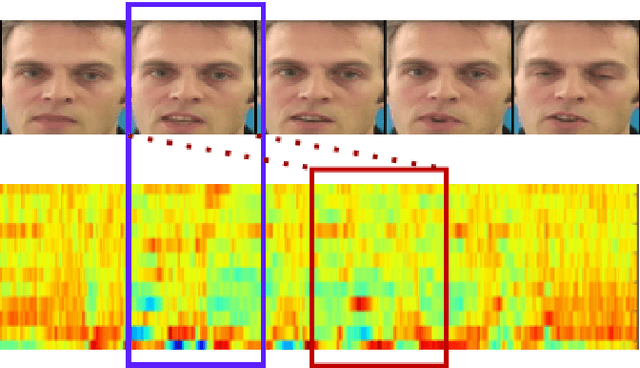
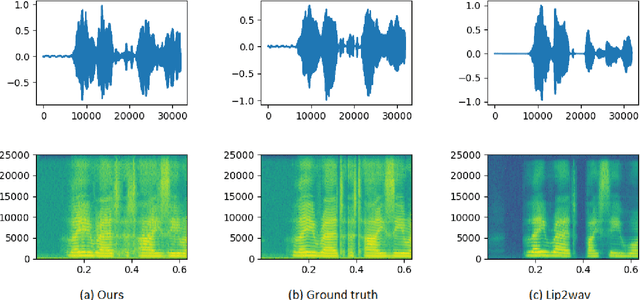
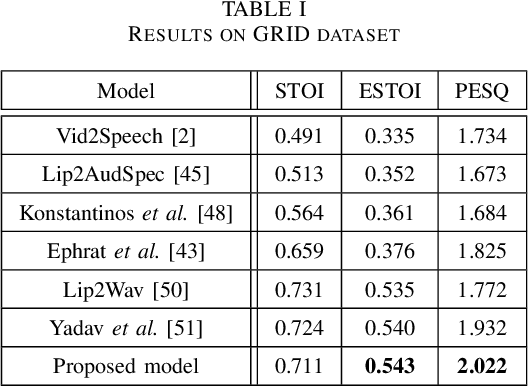
Understanding the lip movement and inferring the speech from it is notoriously difficult for the common person. The task of accurate lip-reading gets help from various cues of the speaker and its contextual or environmental setting. Every speaker has a different accent and speaking style, which can be inferred from their visual and speech features. This work aims to understand the correlation/mapping between speech and the sequence of lip movement of individual speakers in an unconstrained and large vocabulary. We model the frame sequence as a prior to the transformer in an auto-encoder setting and learned a joint embedding that exploits temporal properties of both audio and video. We learn temporal synchronization using deep metric learning, which guides the decoder to generate speech in sync with input lip movements. The predictive posterior thus gives us the generated speech in speaker speaking style. We have trained our model on the Grid and Lip2Wav Chemistry lecture dataset to evaluate single speaker natural speech generation tasks from lip movement in an unconstrained natural setting. Extensive evaluation using various qualitative and quantitative metrics with human evaluation also shows that our method outperforms the Lip2Wav Chemistry dataset(large vocabulary in an unconstrained setting) by a good margin across almost all evaluation metrics and marginally outperforms the state-of-the-art on GRID dataset.
Contrastive Representation Learning for Acoustic Parameter Estimation
Mar 13, 2023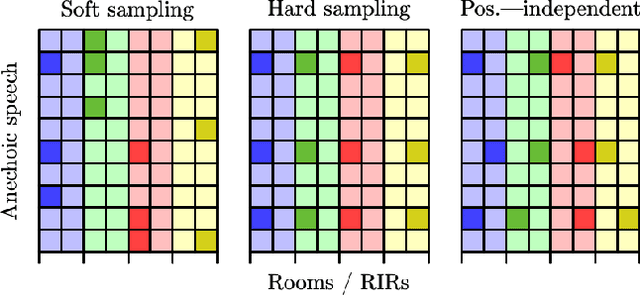


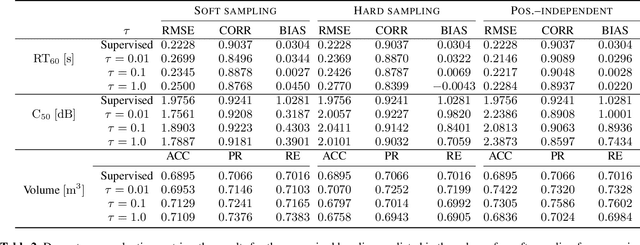
A study is presented in which a contrastive learning approach is used to extract low-dimensional representations of the acoustic environment from single-channel, reverberant speech signals. Convolution of room impulse responses (RIRs) with anechoic source signals is leveraged as a data augmentation technique that offers considerable flexibility in the design of the upstream task. We evaluate the embeddings across three different downstream tasks, which include the regression of acoustic parameters reverberation time RT60 and clarity index C50, and the classification into small and large rooms. We demonstrate that the learned representations generalize well to unseen data and perform similarly to a fully-supervised baseline.
Improving Noisy Student Training on Non-target Domain Data for Automatic Speech Recognition
Nov 09, 2022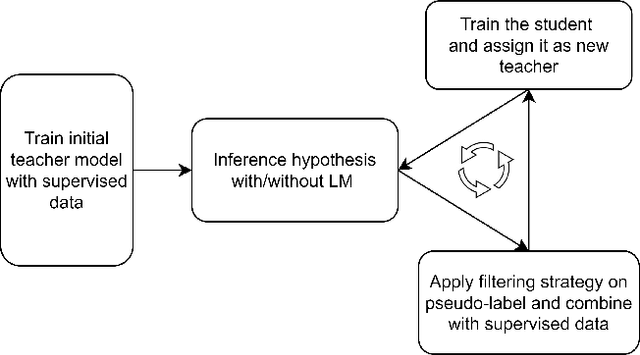


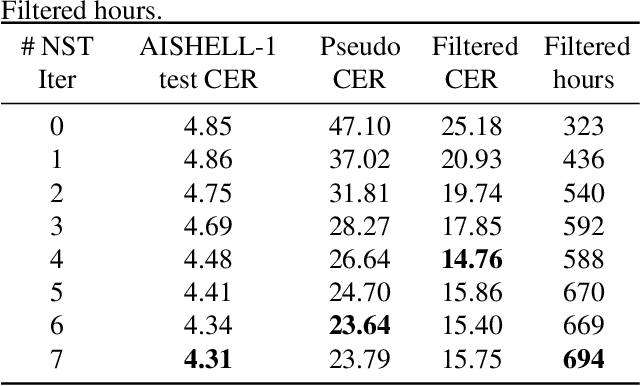
Noisy Student Training (NST) has recently demonstrated extremely strong performance in Automatic Speech Recognition (ASR). In this paper, we propose a data selection strategy named LM Filter to improve the performances of NST on non-target domain data in ASR tasks. Hypothesis with and without Language Model are generated and CER differences between them are utilized as a filter threshold. Results reveal that significant improvements of 10.4% compared with no data filtering baselines. We can achieve 3.31% CER in AISHELL-1 test set, which is best result from our knowledge without any other supervised data. We also perform evaluations on supervised 1000 hour AISHELL-2 dataset and competitive results of 4.72% CER can be achieved.
Deploying Enhanced Speech Feature Decreased Audio Complaints at SVT Play VOD Service
Aug 18, 2022At Public Service Broadcaster SVT in Sweden, background music and sounds in programs have for many years been one of the most common complaints from the viewers. The most sensitive group are people with hearing disabilities, but many others also find background sounds annoying. To address this problem SVT has added Enhanced Speech, a feature with lower background noise, to a number of TV programs in VOD service SVT Play. As a result, when the number of programs with the Enhanced Speech feature increased, the level of audio complaints to customer service decreased. The Enhanced Speech feature got the rating 8.3/10 in a survey with 86 participants. The rating for possible future usage was 9.0/10. In this article we describe this feature's design and development process, as well as its technical specification, limitations and future development opportunities.
StyleTTS-VC: One-Shot Voice Conversion by Knowledge Transfer from Style-Based TTS Models
Dec 29, 2022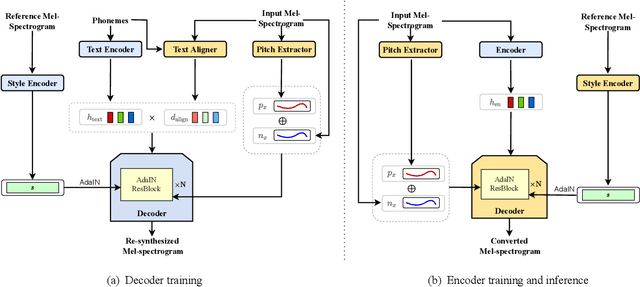
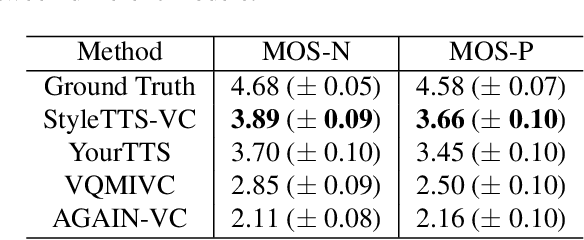
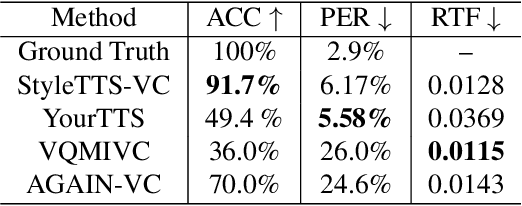

One-shot voice conversion (VC) aims to convert speech from any source speaker to an arbitrary target speaker with only a few seconds of reference speech from the target speaker. This relies heavily on disentangling the speaker's identity and speech content, a task that still remains challenging. Here, we propose a novel approach to learning disentangled speech representation by transfer learning from style-based text-to-speech (TTS) models. With cycle consistent and adversarial training, the style-based TTS models can perform transcription-guided one-shot VC with high fidelity and similarity. By learning an additional mel-spectrogram encoder through a teacher-student knowledge transfer and novel data augmentation scheme, our approach results in disentangled speech representation without needing the input text. The subjective evaluation shows that our approach can significantly outperform the previous state-of-the-art one-shot voice conversion models in both naturalness and similarity.
Speech-enhanced and Noise-aware Networks for Robust Speech Recognition
Mar 25, 2022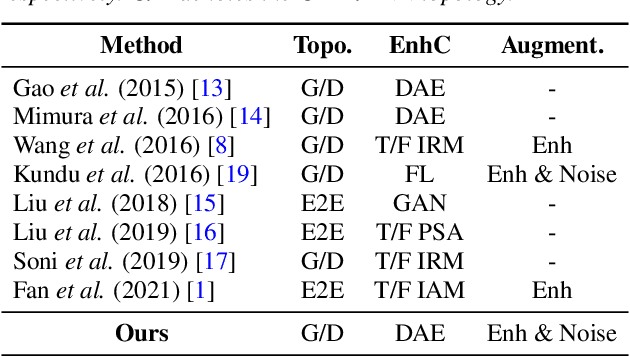
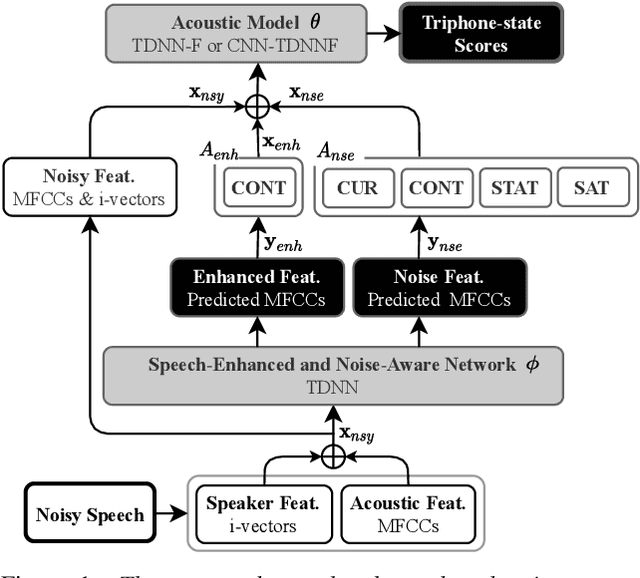
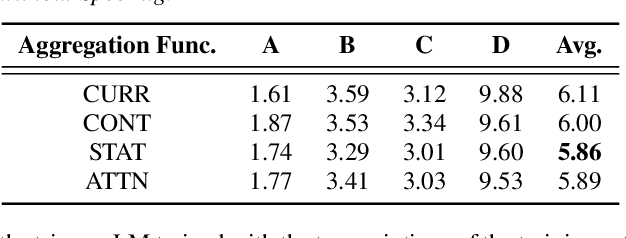
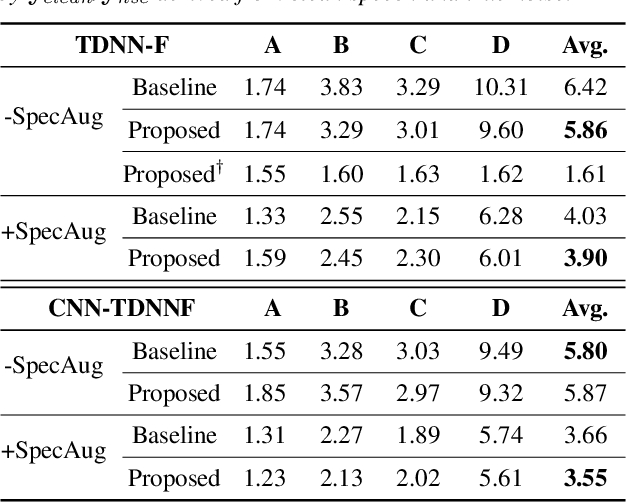
Compensation for channel mismatch and noise interference is essential for robust automatic speech recognition. Enhanced speech has been introduced into the multi-condition training of acoustic models to improve their generalization ability. In this paper, a noise-aware training framework based on two cascaded neural structures is proposed to jointly optimize speech enhancement and speech recognition. The feature enhancement module is composed of a multi-task autoencoder, where noisy speech is decomposed into clean speech and noise. By concatenating its enhanced, noise-aware, and noisy features for each frame, the acoustic-modeling module maps each feature-augmented frame into a triphone state by optimizing the lattice-free maximum mutual information and cross entropy between the predicted and actual state sequences. On top of the factorized time delay neural network (TDNN-F) and its convolutional variant (CNN-TDNNF), both with SpecAug, the two proposed systems achieve word error rate (WER) of 3.90% and 3.55%, respectively, on the Aurora-4 task. Compared with the best existing systems that use bigram and trigram language models for decoding, the proposed CNN-TDNNF-based system achieves a relative WER reduction of 15.20% and 33.53%, respectively. In addition, the proposed CNN-TDNNF-based system also outperforms the baseline CNN-TDNNF system on the AMI task.
SATTS: Speaker Attractor Text to Speech, Learning to Speak by Learning to Separate
Jul 13, 2022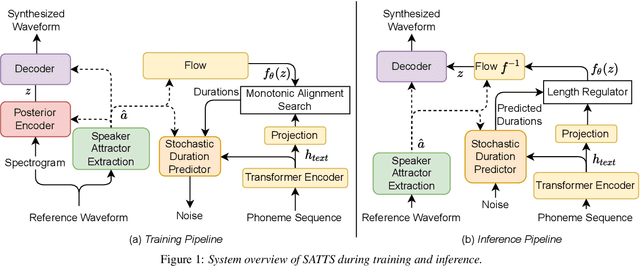
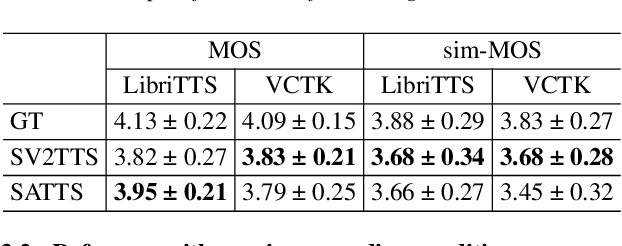
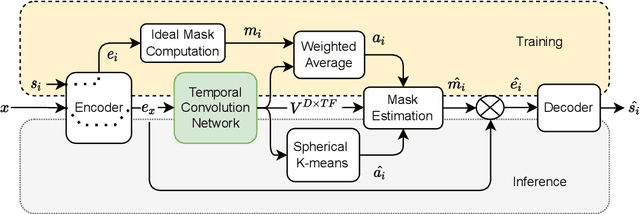

The mapping of text to speech (TTS) is non-deterministic, letters may be pronounced differently based on context, or phonemes can vary depending on various physiological and stylistic factors like gender, age, accent, emotions, etc. Neural speaker embeddings, trained to identify or verify speakers are typically used to represent and transfer such characteristics from reference speech to synthesized speech. Speech separation on the other hand is the challenging task of separating individual speakers from an overlapping mixed signal of various speakers. Speaker attractors are high-dimensional embedding vectors that pull the time-frequency bins of each speaker's speech towards themselves while repelling those belonging to other speakers. In this work, we explore the possibility of using these powerful speaker attractors for zero-shot speaker adaptation in multi-speaker TTS synthesis and propose speaker attractor text to speech (SATTS). Through various experiments, we show that SATTS can synthesize natural speech from text from an unseen target speaker's reference signal which might have less than ideal recording conditions, i.e. reverberations or mixed with other speakers.