 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
READIN: A Chinese Multi-Task Benchmark with Realistic and Diverse Input Noises
Feb 14, 2023


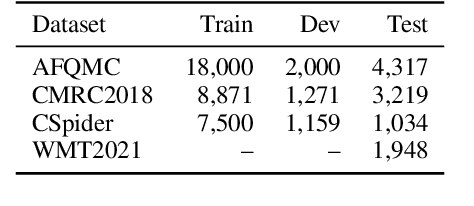
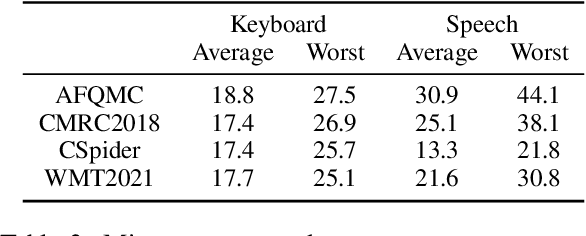
For many real-world applications, the user-generated inputs usually contain various noises due to speech recognition errors caused by linguistic variations1 or typographical errors (typos). Thus, it is crucial to test model performance on data with realistic input noises to ensure robustness and fairness. However, little study has been done to construct such benchmarks for Chinese, where various language-specific input noises happen in the real world. In order to fill this important gap, we construct READIN: a Chinese multi-task benchmark with REalistic And Diverse Input Noises. READIN contains four diverse tasks and requests annotators to re-enter the original test data with two commonly used Chinese input methods: Pinyin input and speech input. We designed our annotation pipeline to maximize diversity, for example by instructing the annotators to use diverse input method editors (IMEs) for keyboard noises and recruiting speakers from diverse dialectical groups for speech noises. We experiment with a series of strong pretrained language models as well as robust training methods, we find that these models often suffer significant performance drops on READIN even with robustness methods like data augmentation. As the first large-scale attempt in creating a benchmark with noises geared towards user-generated inputs, we believe that READIN serves as an important complement to existing Chinese NLP benchmarks. The source code and dataset can be obtained from https://github.com/thunlp/READIN.
Towards Parametric Speech Synthesis Using Gaussian-Markov Model of Spectral Envelope and Wavelet-Based Decomposition of F0
Aug 15, 2022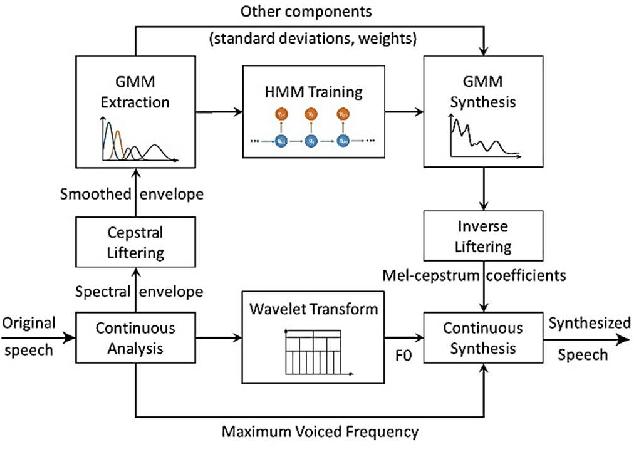
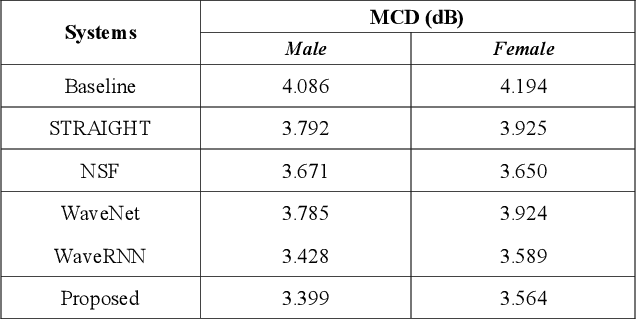
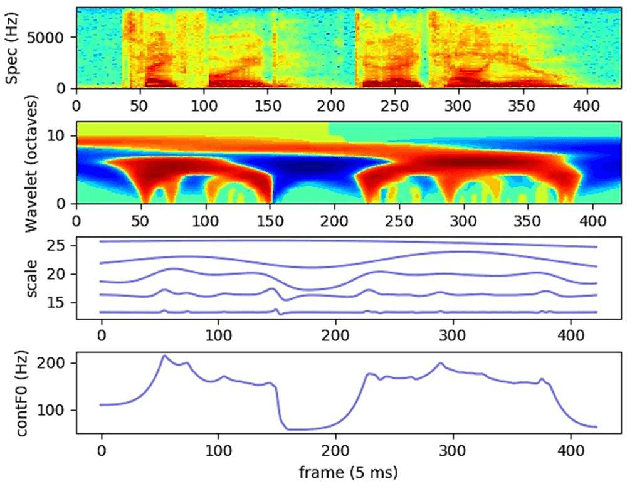
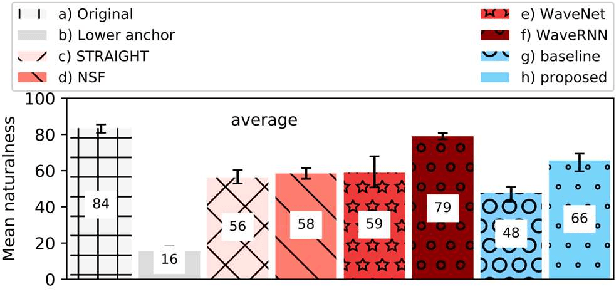
Neural network-based Text-to-Speech has significantly improved the quality of synthesized speech. Prominent methods (e.g., Tacotron2, FastSpeech, FastPitch) usually generate Mel-spectrogram from text and then synthesize speech using vocoder (e.g., WaveNet, WaveGlow, HiFiGAN). Compared with traditional parametric approaches (e.g., STRAIGHT and WORLD), neural vocoder based end-to-end models suffer from slow inference speed, and the synthesized speech is usually not robust and lack of controllability. In this work, we propose a novel updated vocoder, which is a simple signal model to train and easy to generate waveforms. We use the Gaussian-Markov model toward robust learning of spectral envelope and wavelet-based statistical signal processing to characterize and decompose F0 features. It can retain the fine spectral envelope and achieve high controllability of natural speech. The experimental results demonstrate that our proposed vocoder achieves better naturalness of reconstructed speech than the conventional STRAIGHT vocoder, slightly better than WaveNet, and somewhat worse than the WaveRNN.
TimelyFL: Heterogeneity-aware Asynchronous Federated Learning with Adaptive Partial Training
Apr 14, 2023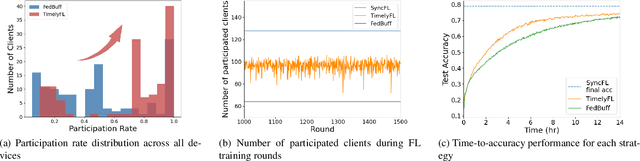
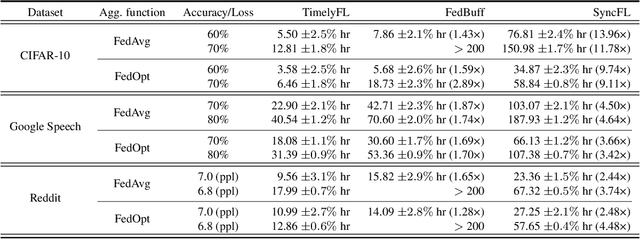
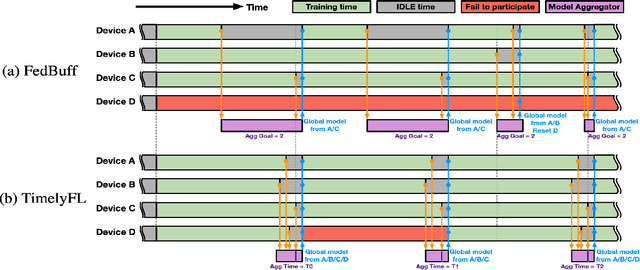

In cross-device Federated Learning (FL) environments, scaling synchronous FL methods is challenging as stragglers hinder the training process. Moreover, the availability of each client to join the training is highly variable over time due to system heterogeneities and intermittent connectivity. Recent asynchronous FL methods (e.g., FedBuff) have been proposed to overcome these issues by allowing slower users to continue their work on local training based on stale models and to contribute to aggregation when ready. However, we show empirically that this method can lead to a substantial drop in training accuracy as well as a slower convergence rate. The primary reason is that fast-speed devices contribute to many more rounds of aggregation while others join more intermittently or not at all, and with stale model updates. To overcome this barrier, we propose TimelyFL, a heterogeneity-aware asynchronous FL framework with adaptive partial training. During the training, TimelyFL adjusts the local training workload based on the real-time resource capabilities of each client, aiming to allow more available clients to join in the global update without staleness. We demonstrate the performance benefits of TimelyFL by conducting extensive experiments on various datasets (e.g., CIFAR-10, Google Speech, and Reddit) and models (e.g., ResNet20, VGG11, and ALBERT). In comparison with the state-of-the-art (i.e., FedBuff), our evaluations reveal that TimelyFL improves participation rate by 21.13%, harvests 1.28x - 2.89x more efficiency on convergence rate, and provides a 6.25% increment on test accuracy.
Privacy against Real-Time Speech Emotion Detection via Acoustic Adversarial Evasion of Machine Learning
Nov 17, 2022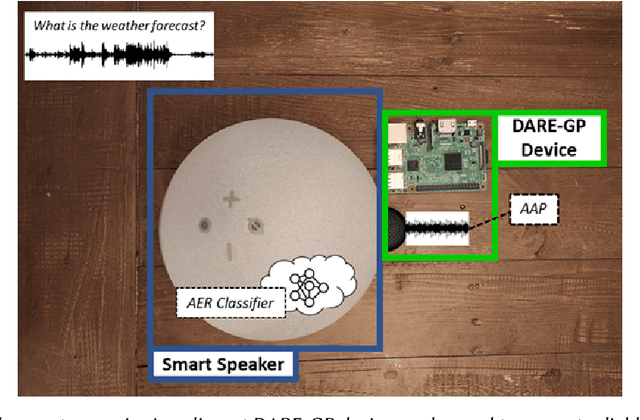
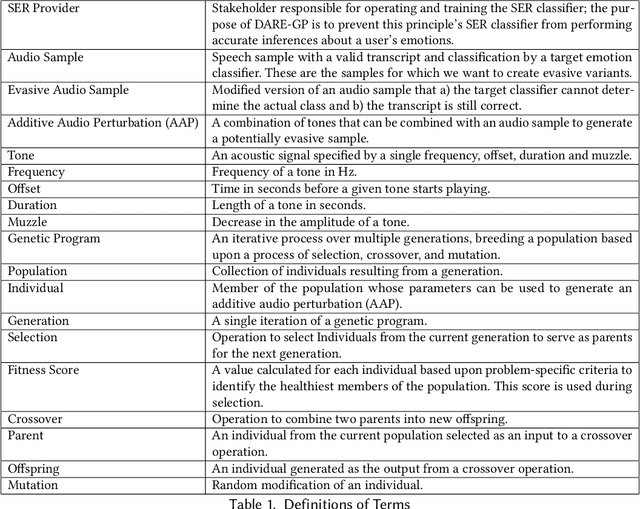
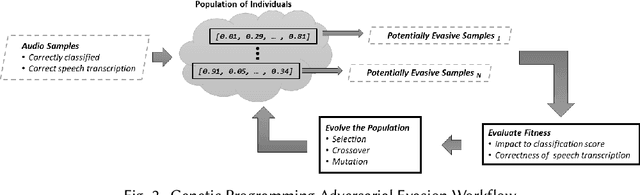

Emotional Surveillance is an emerging area with wide-reaching privacy concerns. These concerns are exacerbated by ubiquitous IoT devices with multiple sensors that can support these surveillance use cases. The work presented here considers one such use case: the use of a speech emotion recognition (SER) classifier tied to a smart speaker. This work demonstrates the ability to evade black-box SER classifiers tied to a smart speaker without compromising the utility of the smart speaker. This privacy concern is considered through the lens of adversarial evasion of machine learning. Our solution, Defeating Acoustic Recognition of Emotion via Genetic Programming (DARE-GP), uses genetic programming to generate non-invasive additive audio perturbations (AAPs). By constraining the evolution of these AAPs, transcription accuracy can be protected while simultaneously degrading SER classifier performance. The additive nature of these AAPs, along with an approach that generates these AAPs for a fixed set of users in an utterance and user location-independent manner, supports real-time, real-world evasion of SER classifiers. DARE-GP's use of spectral features, which underlay the emotional content of speech, allows the transferability of AAPs to previously unseen black-box SER classifiers. Further, DARE-GP outperforms state-of-the-art SER evasion techniques and is robust against defenses employed by a knowledgeable adversary. The evaluations in this work culminate with acoustic evaluations against two off-the-shelf commercial smart speakers, where a single AAP could evade a black box classifier over 70% of the time. The final evaluation deployed AAP playback on a small-form-factor system (raspberry pi) integrated with a wake-word system to evaluate the efficacy of a real-world, real-time deployment where DARE-GP is automatically invoked with the smart speaker's wake word.
Radio2Speech: High Quality Speech Recovery from Radio Frequency Signals
Jun 22, 2022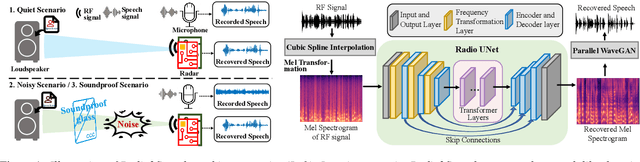
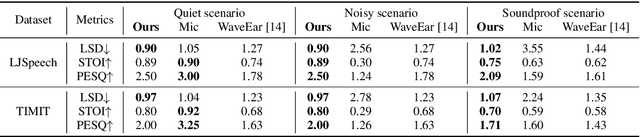

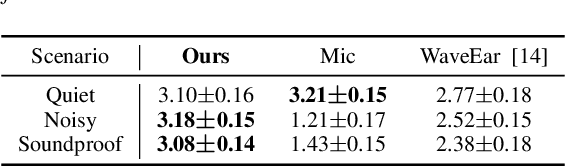
Considering the microphone is easily affected by noise and soundproof materials, the radio frequency (RF) signal is a promising candidate to recover audio as it is immune to noise and can traverse many soundproof objects. In this paper, we introduce Radio2Speech, a system that uses RF signals to recover high quality speech from the loudspeaker. Radio2Speech can recover speech comparable to the quality of the microphone, advancing from recovering only single tone music or incomprehensible speech in existing approaches. We use Radio UNet to accurately recover speech in time-frequency domain from RF signals with limited frequency band. Also, we incorporate the neural vocoder to synthesize the speech waveform from the estimated time-frequency representation without using the contaminated phase. Quantitative and qualitative evaluations show that in quiet, noisy and soundproof scenarios, Radio2Speech achieves state-of-the-art performance and is on par with the microphone that works in quiet scenarios.
Variable Attention Masking for Configurable Transformer Transducer Speech Recognition
Nov 02, 2022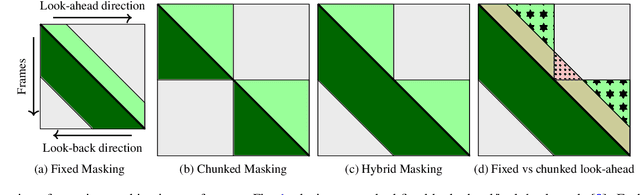
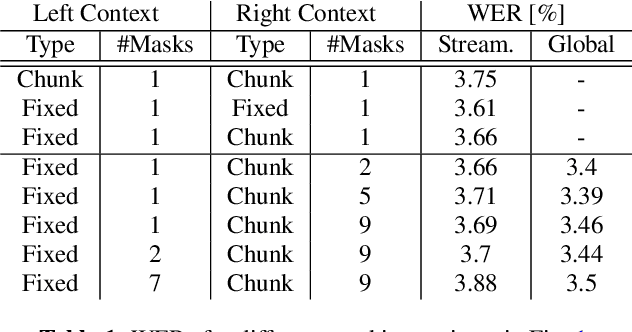
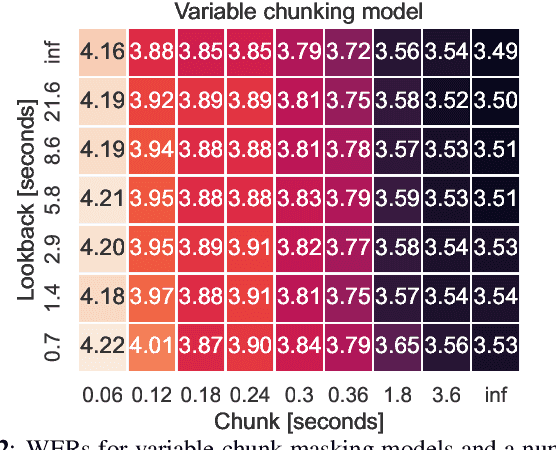
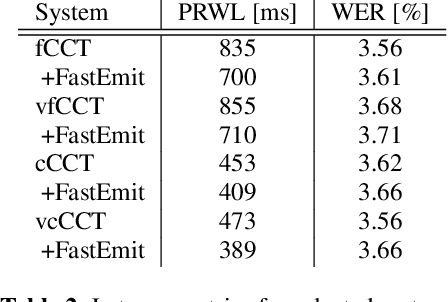
This work studies the use of attention masking in transformer transducer based speech recognition for building a single configurable model for different deployment scenarios. We present a comprehensive set of experiments comparing fixed masking, where the same attention mask is applied at every frame, with chunked masking, where the attention mask for each frame is determined by chunk boundaries, in terms of recognition accuracy and latency. We then explore the use of variable masking, where the attention masks are sampled from a target distribution at training time, to build models that can work in different configurations. Finally, we investigate how a single configurable model can be used to perform both first pass streaming recognition and second pass acoustic rescoring. Experiments show that chunked masking achieves a better accuracy vs latency trade-off compared to fixed masking, both with and without FastEmit. We also show that variable masking improves the accuracy by up to 8% relative in the acoustic re-scoring scenario.
Active Learning of Non-semantic Speech Tasks with Pretrained Models
Nov 03, 2022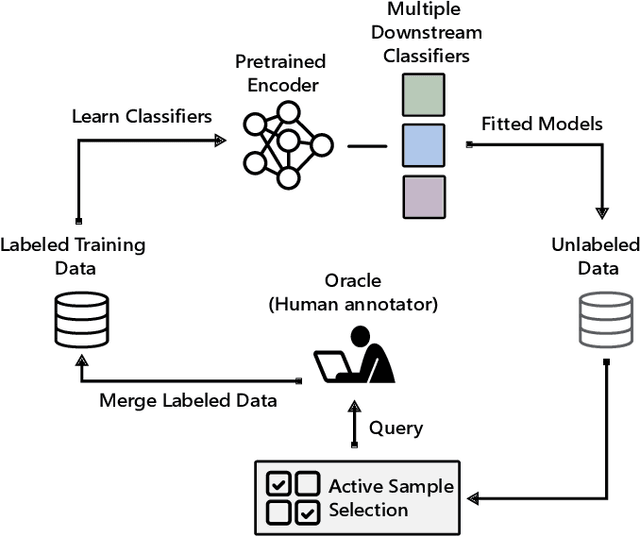
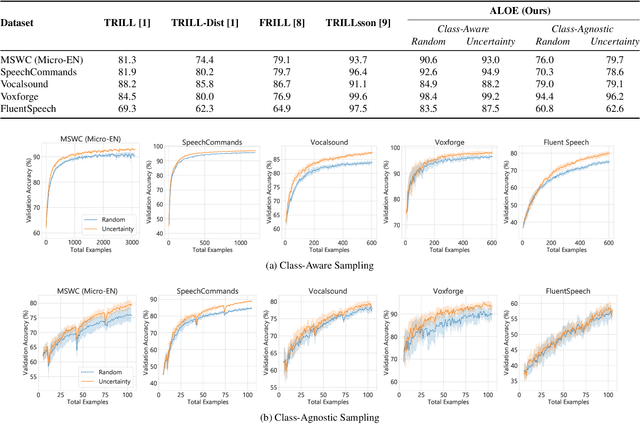

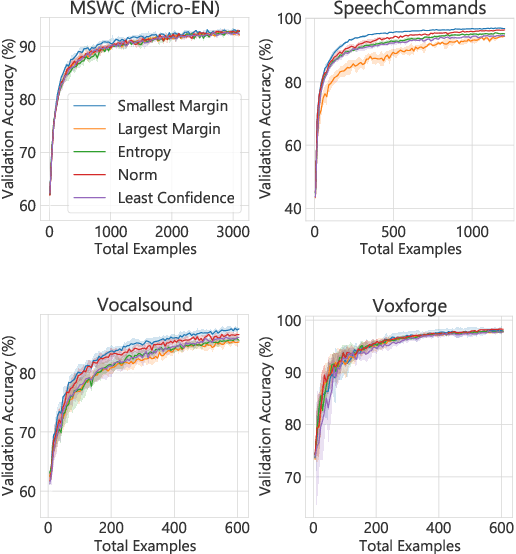
Pretraining neural networks with massive unlabeled datasets has become popular as it equips the deep models with a better prior to solve downstream tasks. However, this approach generally assumes that for downstream tasks, we have access to annotated data of sufficient size. In this work, we propose ALOE, a novel system for improving the data- and label-efficiency of non-semantic speech tasks with active learning (AL). ALOE uses pre-trained models in conjunction with active learning to label data incrementally and learns classifiers for downstream tasks, thereby mitigating the need to acquire labeled data beforehand. We demonstrate the effectiveness of ALOE on a wide range of tasks, uncertainty-based acquisition functions, and model architectures. Training a linear classifier on top of a frozen encoder with ALOE is shown to achieve performance similar to several baselines that utilize the entire labeled data.
UzbekTagger: The rule-based POS tagger for Uzbek language
Jan 30, 2023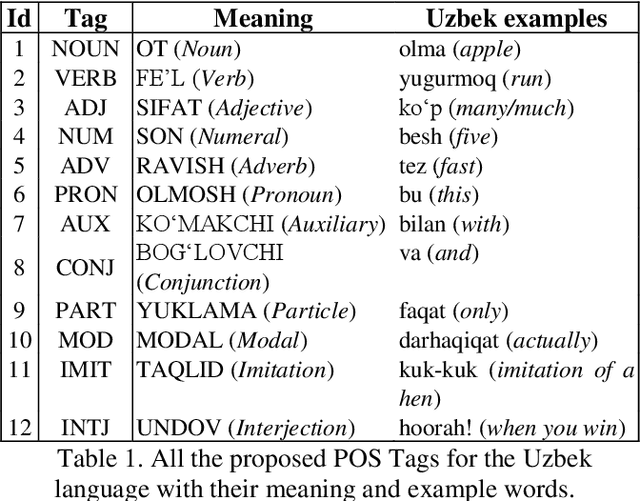
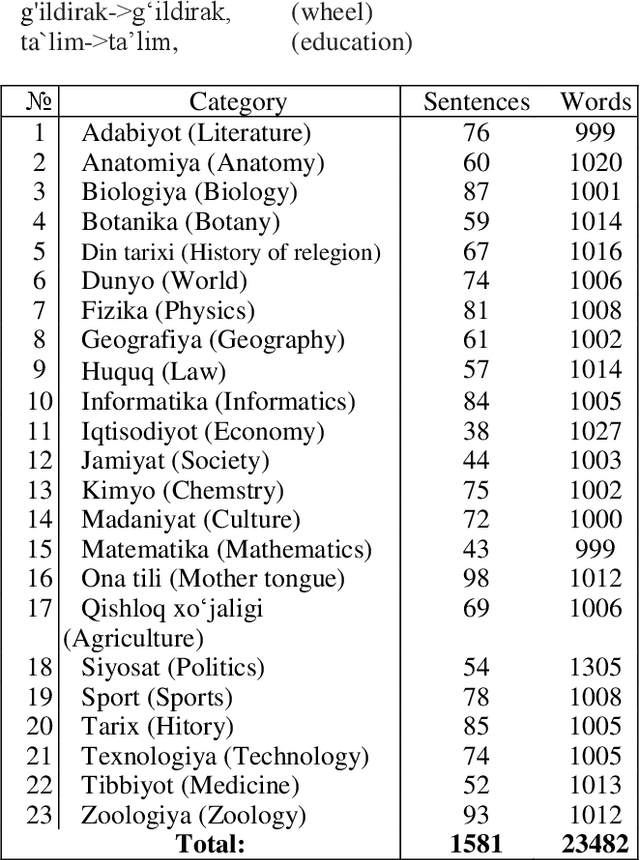
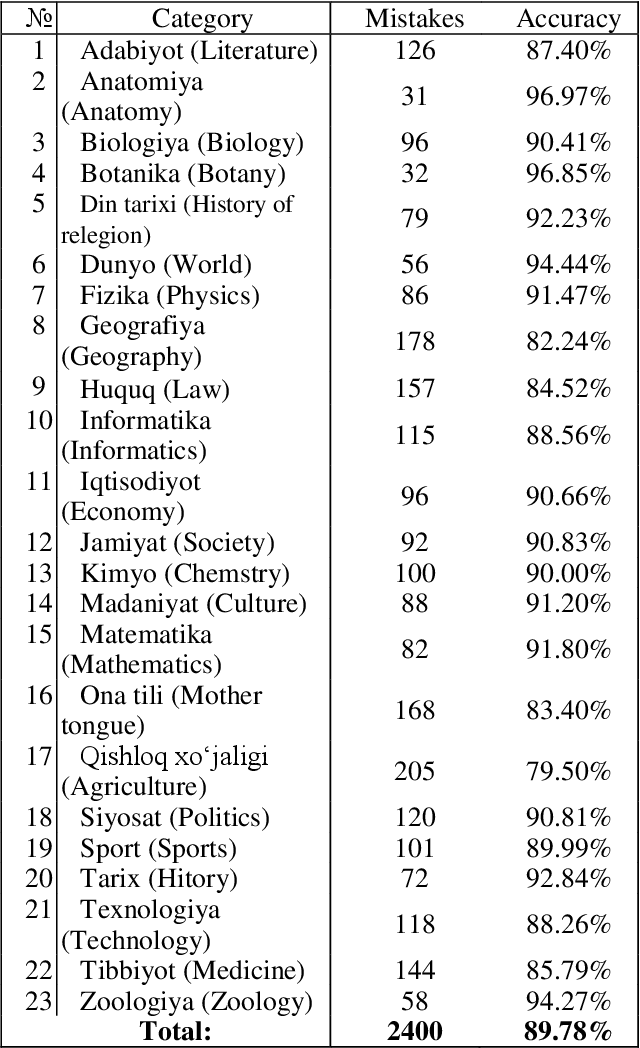
This research paper presents a part-of-speech (POS) annotated dataset and tagger tool for the low-resource Uzbek language. The dataset includes 12 tags, which were used to develop a rule-based POS-tagger tool. The corpus text used in the annotation process was made sure to be balanced over 20 different fields in order to ensure its representativeness. Uzbek being an agglutinative language so the most of the words in an Uzbek sentence are formed by adding suffixes. This nature of it makes the POS-tagging task difficult to find the stems of words and the right part-of-speech they belong to. The methodology proposed in this research is the stemming of the words with an affix/suffix stripping approach including database of the stem forms of the words in the Uzbek language. The tagger tool was tested on the annotated dataset and showed high accuracy in identifying and tagging parts of speech in Uzbek text. This newly presented dataset and tagger tool can be used for a variety of natural language processing tasks such as language modeling, machine translation, and text-to-speech synthesis. The presented dataset is the first of its kind to be made publicly available for Uzbek, and the POS-tagger tool created can also be used as a pivot to use as a base for other closely-related Turkic languages.
Borrowing Human Senses: Comment-Aware Self-Training for Social Media Multimodal Classification
Mar 27, 2023
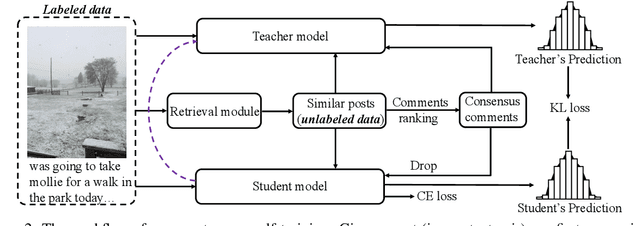
Social media is daily creating massive multimedia content with paired image and text, presenting the pressing need to automate the vision and language understanding for various multimodal classification tasks. Compared to the commonly researched visual-lingual data, social media posts tend to exhibit more implicit image-text relations. To better glue the cross-modal semantics therein, we capture hinting features from user comments, which are retrieved via jointly leveraging visual and lingual similarity. Afterwards, the classification tasks are explored via self-training in a teacher-student framework, motivated by the usually limited labeled data scales in existing benchmarks. Substantial experiments are conducted on four multimodal social media benchmarks for image text relation classification, sarcasm detection, sentiment classification, and hate speech detection. The results show that our method further advances the performance of previous state-of-the-art models, which do not employ comment modeling or self-training.
X-TIME: An in-memory engine for accelerating machine learning on tabular data with CAMs
Apr 05, 2023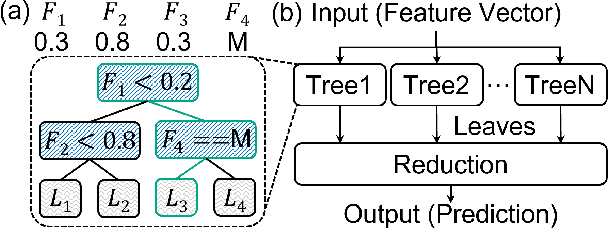
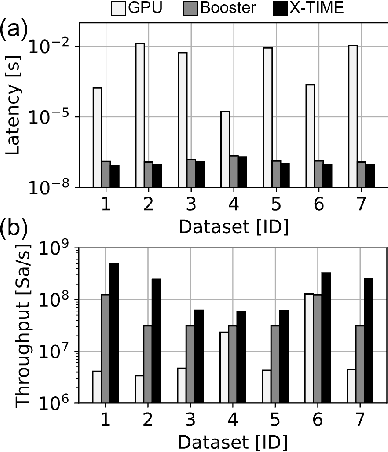
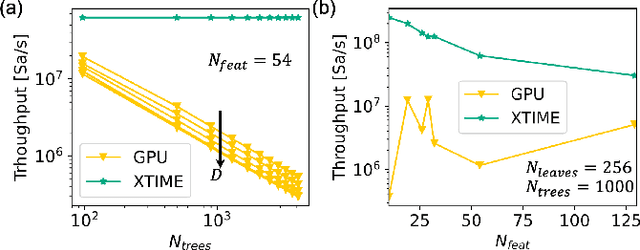
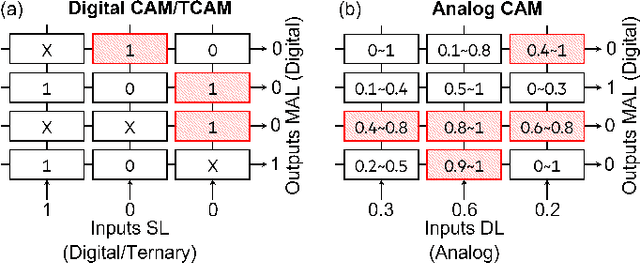
Structured, or tabular, data is the most common format in data science. While deep learning models have proven formidable in learning from unstructured data such as images or speech, they are less accurate than simpler approaches when learning from tabular data. In contrast, modern tree-based Machine Learning (ML) models shine in extracting relevant information from structured data. An essential requirement in data science is to reduce model inference latency in cases where, for example, models are used in a closed loop with simulation to accelerate scientific discovery. However, the hardware acceleration community has mostly focused on deep neural networks and largely ignored other forms of machine learning. Previous work has described the use of an analog content addressable memory (CAM) component for efficiently mapping random forests. In this work, we focus on an overall analog-digital architecture implementing a novel increased precision analog CAM and a programmable network on chip allowing the inference of state-of-the-art tree-based ML models, such as XGBoost and CatBoost. Results evaluated in a single chip at 16nm technology show 119x lower latency at 9740x higher throughput compared with a state-of-the-art GPU, with a 19W peak power consumption.