 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Neural Architecture Search with Multimodal Fusion Methods for Diagnosing Dementia
Feb 12, 2023
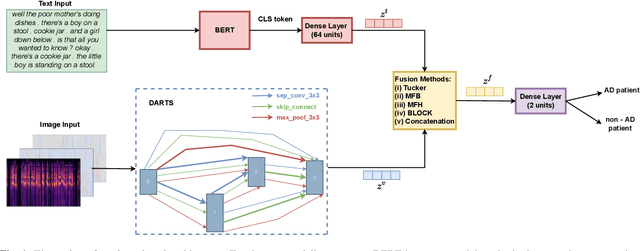
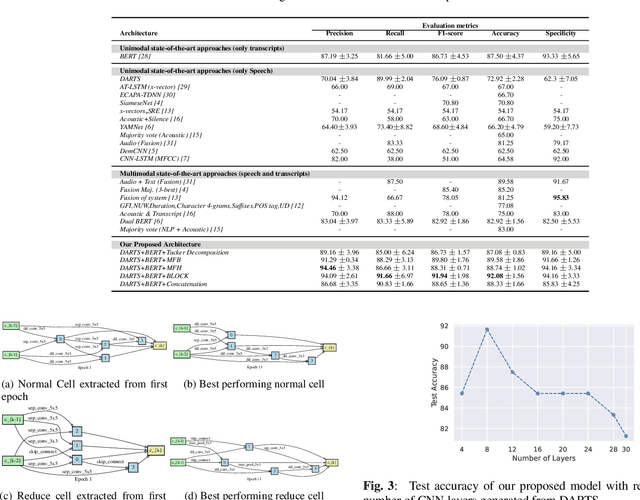
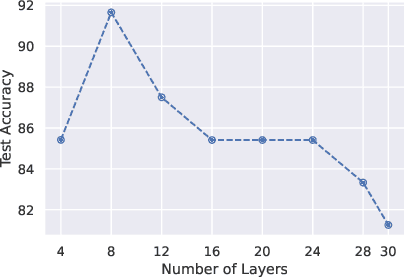
Alzheimer's dementia (AD) affects memory, thinking, and language, deteriorating person's life. An early diagnosis is very important as it enables the person to receive medical help and ensure quality of life. Therefore, leveraging spontaneous speech in conjunction with machine learning methods for recognizing AD patients has emerged into a hot topic. Most of the previous works employ Convolutional Neural Networks (CNNs), to process the input signal. However, finding a CNN architecture is a time-consuming process and requires domain expertise. Moreover, the researchers introduce early and late fusion approaches for fusing different modalities or concatenate the representations of the different modalities during training, thus the inter-modal interactions are not captured. To tackle these limitations, first we exploit a Neural Architecture Search (NAS) method to automatically find a high performing CNN architecture. Next, we exploit several fusion methods, including Multimodal Factorized Bilinear Pooling and Tucker Decomposition, to combine both speech and text modalities. To the best of our knowledge, there is no prior work exploiting a NAS approach and these fusion methods in the task of dementia detection from spontaneous speech. We perform extensive experiments on the ADReSS Challenge dataset and show the effectiveness of our approach over state-of-the-art methods.
Right the docs: Characterising voice dataset documentation practices used in machine learning
Mar 19, 2023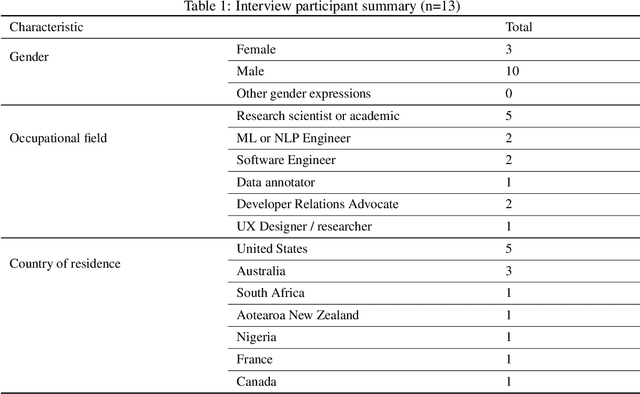
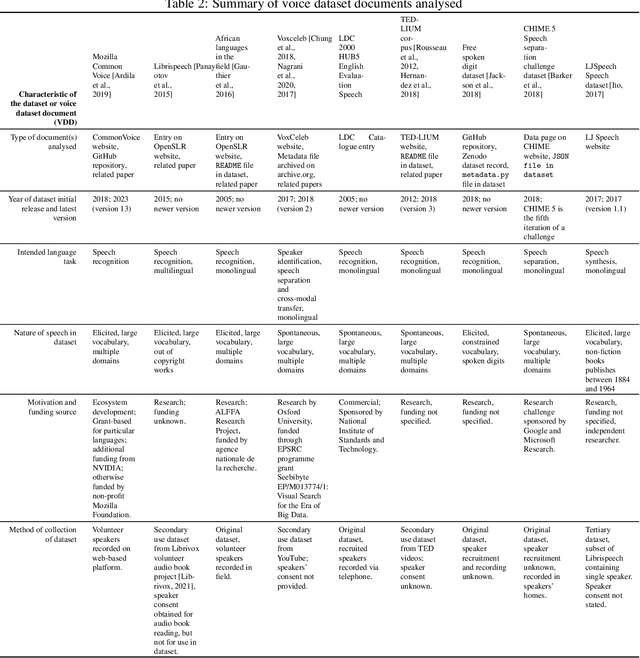
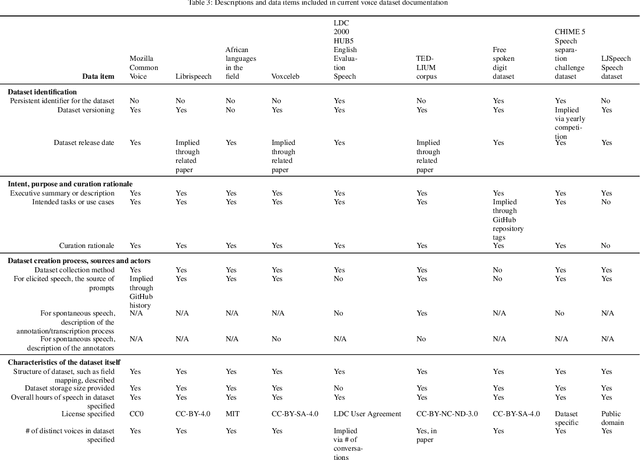
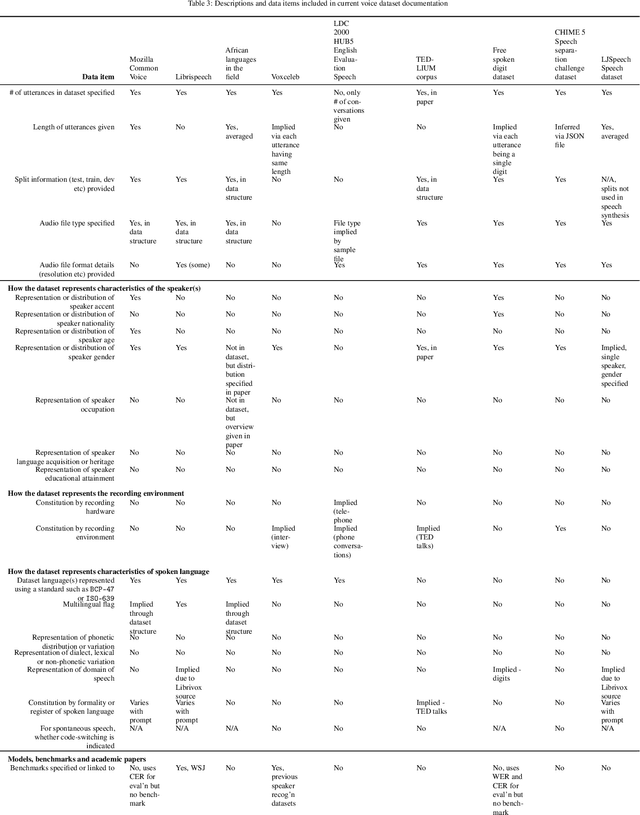
Voice-enabled technology is quickly becoming ubiquitous, and is constituted from machine learning (ML)-enabled components such as speech recognition and voice activity detection. However, these systems don't yet work well for everyone. They exhibit bias - the systematic and unfair discrimination against individuals or cohorts of individuals in favour of others (Friedman & Nissembaum, 1996) - across axes such as age, gender and accent. ML is reliant on large datasets for training. Dataset documentation is designed to give ML Practitioners (MLPs) a better understanding of a dataset's characteristics. However, there is a lack of empirical research on voice dataset documentation specifically. Additionally, while MLPs are frequent participants in fairness research, little work focuses on those who work with voice data. Our work makes an empirical contribution to this gap. Here, we combine two methods to form an exploratory study. First, we undertake 13 semi-structured interviews, exploring multiple perspectives of voice dataset documentation practice. Using open and axial coding methods, we explore MLPs' practices through the lenses of roles and tradeoffs. Drawing from this work, we then purposively sample voice dataset documents (VDDs) for 9 voice datasets. Our findings then triangulate these two methods, using the lenses of MLP roles and trade-offs. We find that current VDD practices are inchoate, inadequate and incommensurate. The characteristics of voice datasets are codified in fragmented, disjoint ways that often do not meet the needs of MLPs. Moreover, they cannot be readily compared, presenting a barrier to practitioners' bias reduction efforts. We then discuss the implications of these findings for bias practices in voice data and speech technologies. We conclude by setting out a program of future work to address these findings -- that is, how we may "right the docs".
Open Challenges in Synthetic Speech Detection
Sep 15, 2022
In this paper the current status and open challenges of synthetic speech detection are addressed. The work comprises an initial analysis of available open datasets and of existing detection methods, a description of the requirements for new research datasets compliant with regulations and better representing real-case scenarios, and a discussion of the desired characteristics of future trustworthy detection methods in terms of both functional and non-functional requirements. Compared to other works, based on specific detection solutions or presenting single dataset of synthetic speeches, our paper is meant to orient future state-of-the-art research in the domain, to quickly lessen the current gap between synthesis and detection approaches.
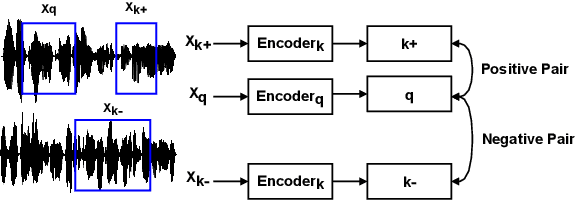
Residual Information in Deep Speaker Embedding Architectures
Feb 06, 2023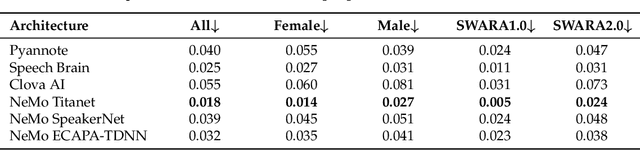
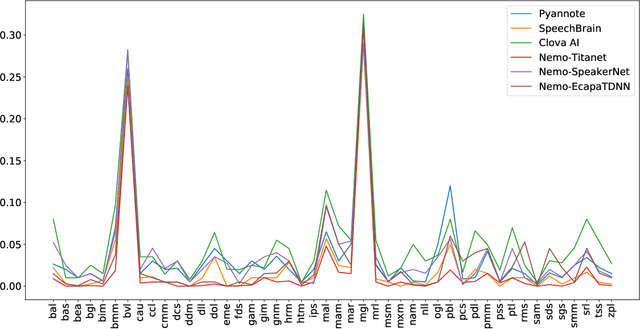
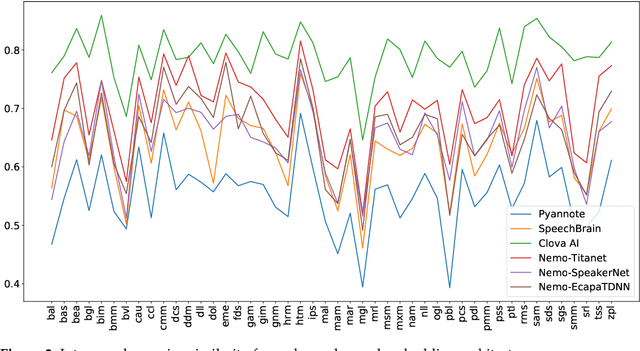
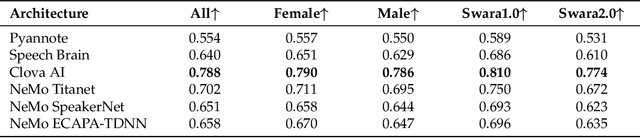
Speaker embeddings represent a means to extract representative vectorial representations from a speech signal such that the representation pertains to the speaker identity alone. The embeddings are commonly used to classify and discriminate between different speakers. However, there is no objective measure to evaluate the ability of a speaker embedding to disentangle the speaker identity from the other speech characteristics. This means that the embeddings are far from ideal, highly dependent on the training corpus and still include a degree of residual information pertaining to factors such as linguistic content, recording conditions or speaking style of the utterance. This paper introduces an analysis over six sets of speaker embeddings extracted with some of the most recent and high-performing DNN architectures, and in particular, the degree to which they are able to truly disentangle the speaker identity from the speech signal. To correctly evaluate the architectures, a large multi-speaker parallel speech dataset is used. The dataset includes 46 speakers uttering the same set of prompts, recorded in either a professional studio or their home environments. The analysis looks into the intra- and inter-speaker similarity measures computed over the different embedding sets, as well as if simple classification and regression methods are able to extract several residual information factors from the speaker embeddings. The results show that the discriminative power of the analyzed embeddings is very high, yet across all the analyzed architectures, residual information is still present in the representations in the form of a high correlation to the recording conditions, linguistic contents and utterance duration.
Unsupervised Word Segmentation Using Temporal Gradient Pseudo-Labels
Mar 30, 2023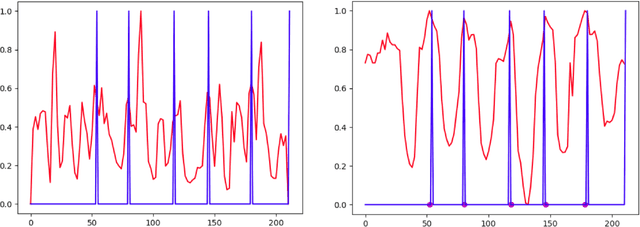
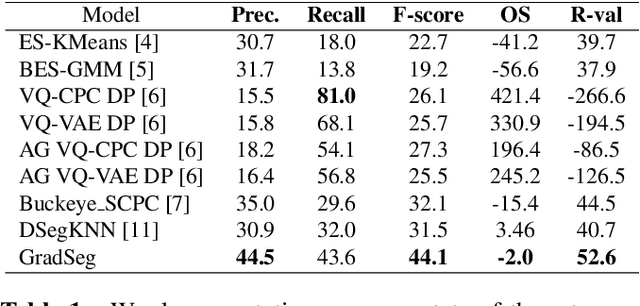

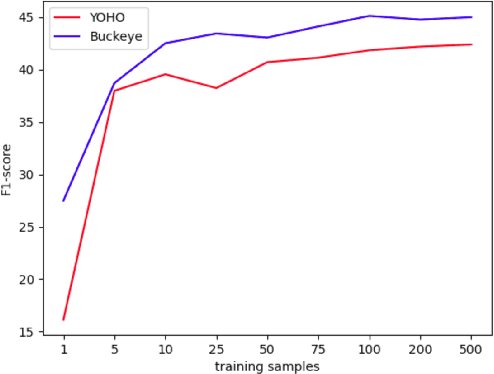
Unsupervised word segmentation in audio utterances is challenging as, in speech, there is typically no gap between words. In a preliminary experiment, we show that recent deep self-supervised features are very effective for word segmentation but require supervision for training the classification head. To extend their effectiveness to unsupervised word segmentation, we propose a pseudo-labeling strategy. Our approach relies on the observation that the temporal gradient magnitude of the embeddings (i.e. the distance between the embeddings of subsequent frames) is typically minimal far from the boundaries and higher nearer the boundaries. We use a thresholding function on the temporal gradient magnitude to define a psuedo-label for wordness. We train a linear classifier, mapping the embedding of a single frame to the pseudo-label. Finally, we use the classifier score to predict whether a frame is a word or a boundary. In an empirical investigation, our method, despite its simplicity and fast run time, is shown to significantly outperform all previous methods on two datasets.
Decoupled Pronunciation and Prosody Modeling in Meta-Learning-Based Multilingual Speech Synthesis
Sep 14, 2022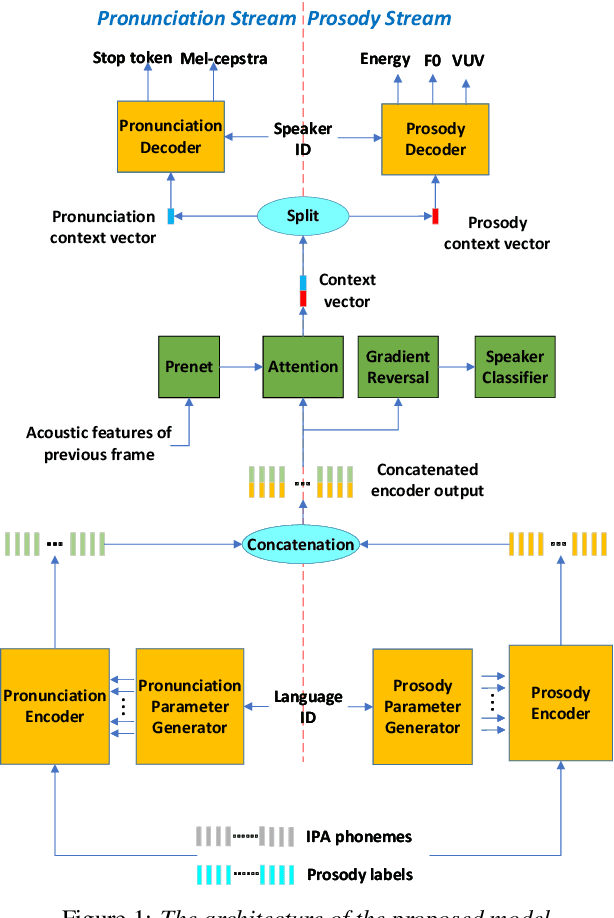

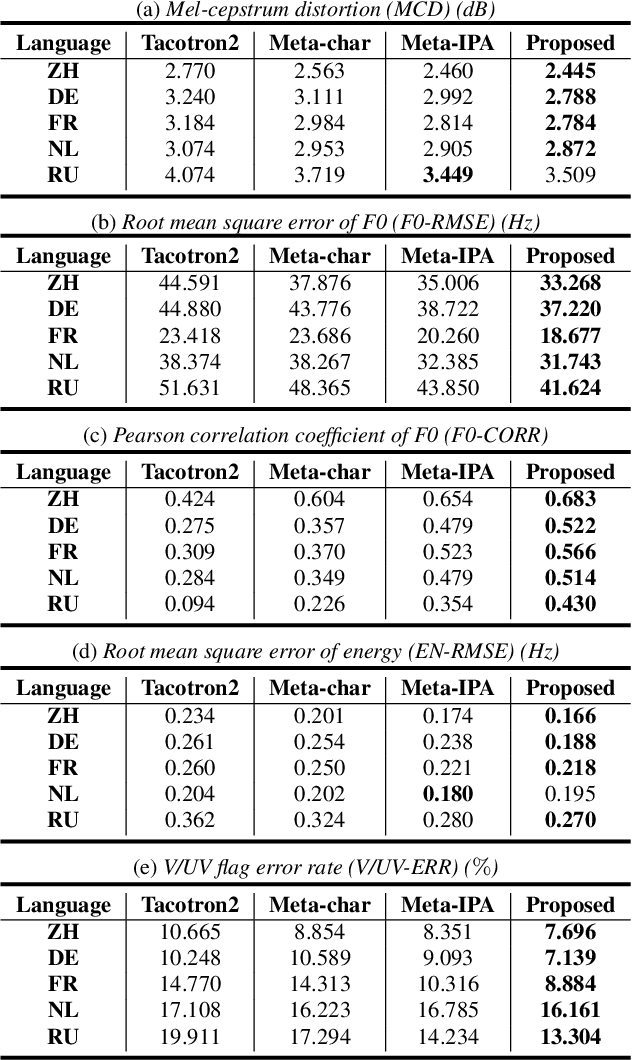
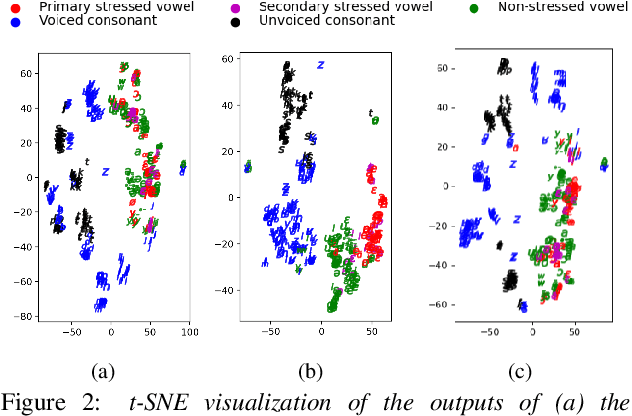
This paper presents a method of decoupled pronunciation and prosody modeling to improve the performance of meta-learning-based multilingual speech synthesis. The baseline meta-learning synthesis method adopts a single text encoder with a parameter generator conditioned on language embeddings and a single decoder to predict mel-spectrograms for all languages. In contrast, our proposed method designs a two-stream model structure that contains two encoders and two decoders for pronunciation and prosody modeling, respectively, considering that the pronunciation knowledge and the prosody knowledge should be shared in different ways among languages. In our experiments, our proposed method effectively improved the intelligibility and naturalness of multilingual speech synthesis comparing with the baseline meta-learning synthesis method.
NASTAR: Noise Adaptive Speech Enhancement with Target-Conditional Resampling
Jun 18, 2022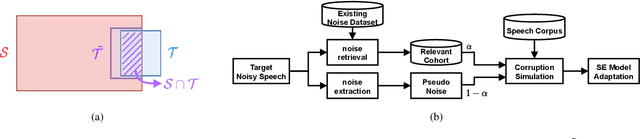
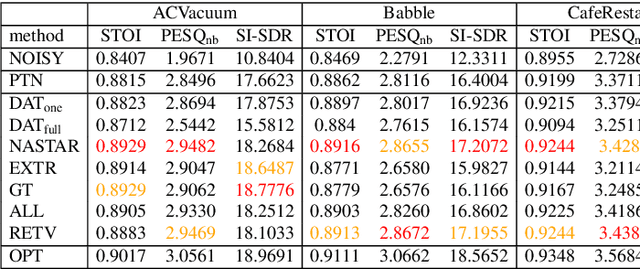
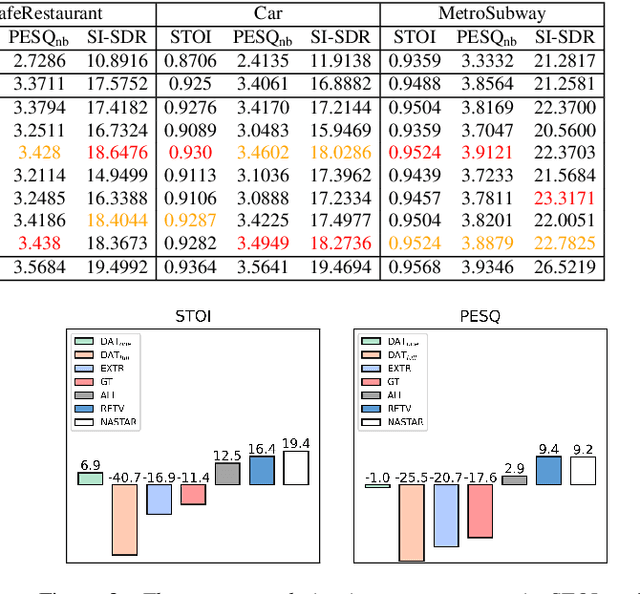
For deep learning-based speech enhancement (SE) systems, the training-test acoustic mismatch can cause notable performance degradation. To address the mismatch issue, numerous noise adaptation strategies have been derived. In this paper, we propose a novel method, called noise adaptive speech enhancement with target-conditional resampling (NASTAR), which reduces mismatches with only one sample (one-shot) of noisy speech in the target environment. NASTAR uses a feedback mechanism to simulate adaptive training data via a noise extractor and a retrieval model. The noise extractor estimates the target noise from the noisy speech, called pseudo-noise. The noise retrieval model retrieves relevant noise samples from a pool of noise signals according to the noisy speech, called relevant-cohort. The pseudo-noise and the relevant-cohort set are jointly sampled and mixed with the source speech corpus to prepare simulated training data for noise adaptation. Experimental results show that NASTAR can effectively use one noisy speech sample to adapt an SE model to a target condition. Moreover, both the noise extractor and the noise retrieval model contribute to model adaptation. To our best knowledge, NASTAR is the first work to perform one-shot noise adaptation through noise extraction and retrieval.
TaylorAECNet: A Taylor Style Neural Network for Full-Band Echo Cancellation
Mar 11, 2023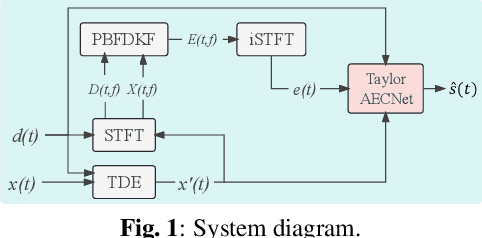
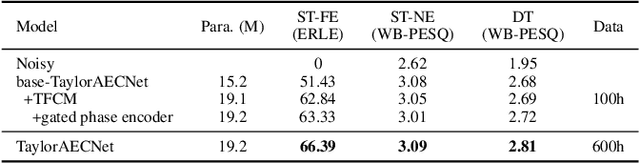
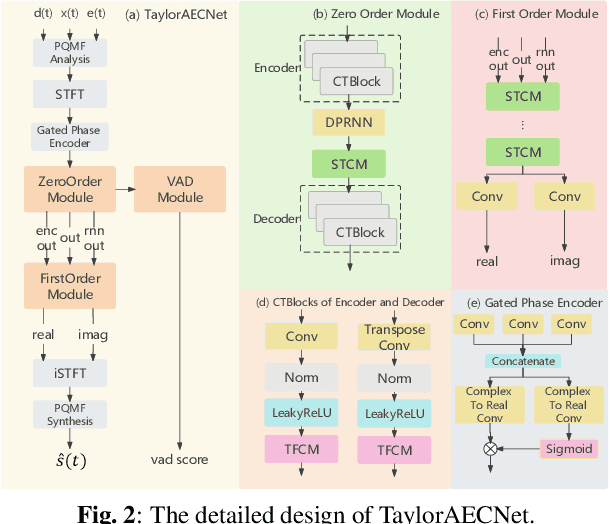

This paper describes aecX team's entry to the ICASSP 2023 acoustic echo cancellation (AEC) challenge. Our system consists of an adaptive filter and a proposed full-band Taylor-style acoustic echo cancellation neural network (TaylorAECNet) as a post-filter. Specifically, we leverage the recent advances in Taylor expansion based decoupling-style interpretable speech enhancement and explore its feasibility in the AEC task. Our TaylorAECNet based approach achieves an overall mean opinion score (MOS) of 4.241, a word accuracy (WAcc) ratio of 0.767, and ranks 5th in the non-personalized track (track 1).
BERT-based Ensemble Approaches for Hate Speech Detection
Sep 15, 2022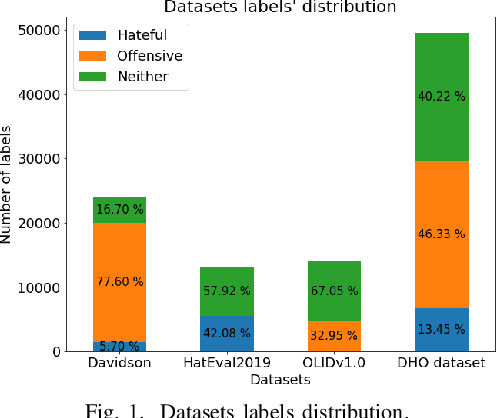
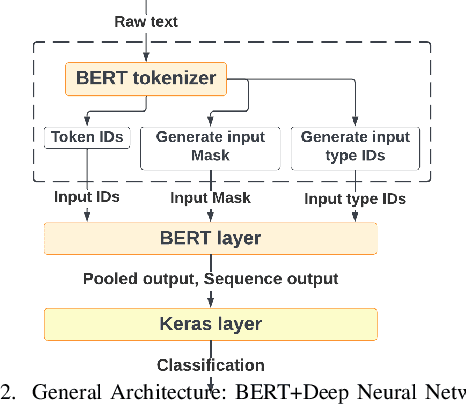
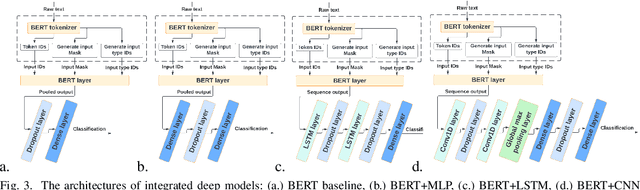
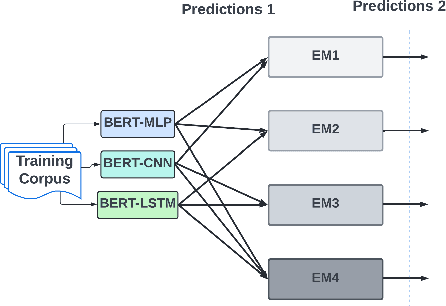
With the freedom of communication provided in online social media, hate speech has increasingly generated. This leads to cyber conflicts affecting social life at the individual and national levels. As a result, hateful content classification is becoming increasingly demanded for filtering hate content before being sent to the social networks. This paper focuses on classifying hate speech in social media using multiple deep models that are implemented by integrating recent transformer-based language models such as BERT, and neural networks. To improve the classification performances, we evaluated with several ensemble techniques, including soft voting, maximum value, hard voting and stacking. We used three publicly available Twitter datasets (Davidson, HatEval2019, OLID) that are generated to identify offensive languages. We fused all these datasets to generate a single dataset (DHO dataset), which is more balanced across different labels, to perform multi-label classification. Our experiments have been held on Davidson dataset and the DHO corpora. The later gave the best overall results, especially F1 macro score, even it required more resources (time execution and memory). The experiments have shown good results especially the ensemble models, where stacking gave F1 score of 97% on Davidson dataset and aggregating ensembles 77% on the DHO dataset.
Deep Speech Based End-to-End Automated Speech Recognition (ASR) for Indian-English Accents
Apr 03, 2022Automated Speech Recognition (ASR) is an interdisciplinary application of computer science and linguistics that enable us to derive the transcription from the uttered speech waveform. It finds several applications in Military like High-performance fighter aircraft, helicopters, air-traffic controller. Other than military speech recognition is used in healthcare, persons with disabilities and many more. ASR has been an active research area. Several models and algorithms for speech to text (STT) have been proposed. One of the most recent is Mozilla Deep Speech, it is based on the Deep Speech research paper by Baidu. Deep Speech is a state-of-art speech recognition system is developed using end-to-end deep learning, it is trained using well-optimized Recurrent Neural Network (RNN) training system utilizing multiple Graphical Processing Units (GPUs). This training is mostly done using American-English accent datasets, which results in poor generalizability to other English accents. India is a land of vast diversity. This can even be seen in the speech, there are several English accents which vary from state to state. In this work, we have used transfer learning approach using most recent Deep Speech model i.e., deepspeech-0.9.3 to develop an end-to-end speech recognition system for Indian-English accents. This work utilizes fine-tuning and data argumentation to further optimize and improve the Deep Speech ASR system. Indic TTS data of Indian-English accents is used for transfer learning and fine-tuning the pre-trained Deep Speech model. A general comparison is made among the untrained model, our trained model and other available speech recognition services for Indian-English Accents.