 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
SNIPER Training: Variable Sparsity Rate Training For Text-To-Speech
Nov 14, 2022
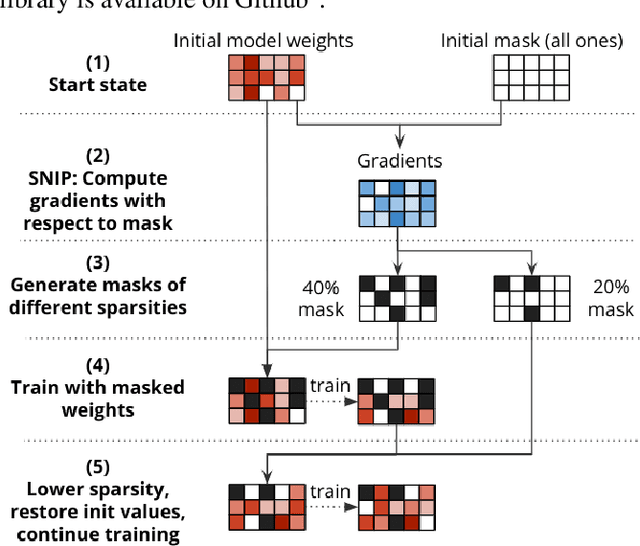
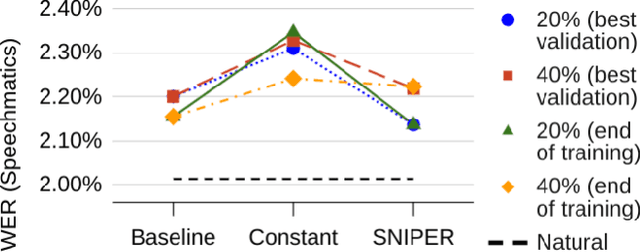
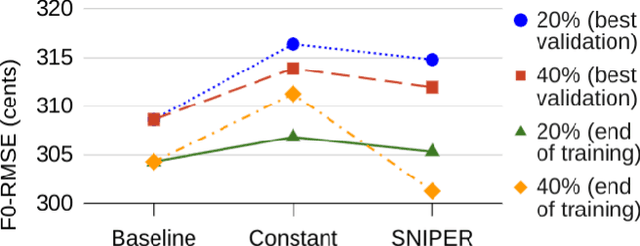
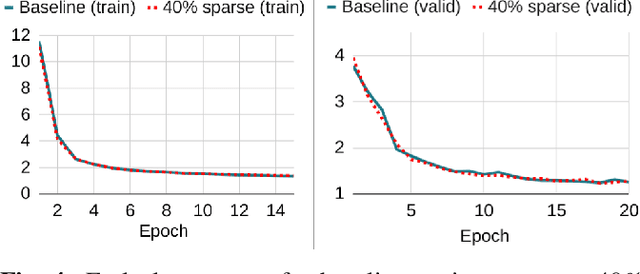
Text-to-speech (TTS) models have achieved remarkable naturalness in recent years, yet like most deep neural models, they have more parameters than necessary. Sparse TTS models can improve on dense models via pruning and extra retraining, or converge faster than dense models with some performance loss. Inspired by these results, we propose training TTS models using a decaying sparsity rate, i.e. a high initial sparsity to accelerate training first, followed by a progressive rate reduction to obtain better eventual performance. This decremental approach differs from current methods of incrementing sparsity to a desired target, which costs significantly more time than dense training. We call our method SNIPER training: Single-shot Initialization Pruning Evolving-Rate training. Our experiments on FastSpeech2 show that although we were only able to obtain better losses in the first few epochs before being overtaken by the baseline, the final SNIPER-trained models beat constant-sparsity models and pip dense models in performance.
Non-Contrastive Self-Supervised Learning of Utterance-Level Speech Representations
Aug 10, 2022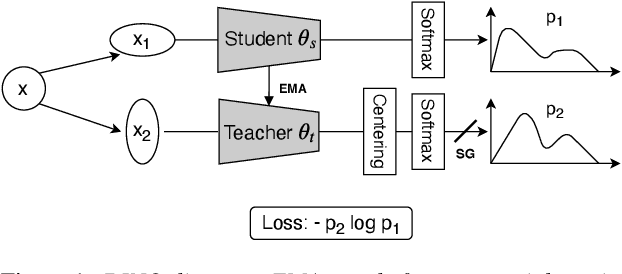
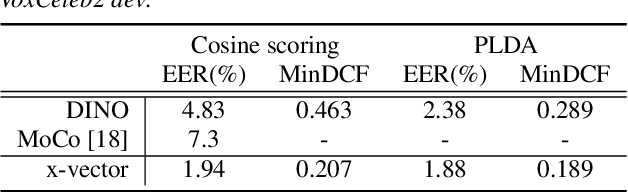
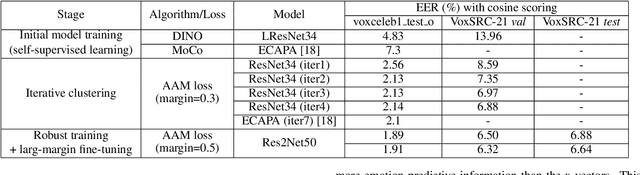
Considering the abundance of unlabeled speech data and the high labeling costs, unsupervised learning methods can be essential for better system development. One of the most successful methods is contrastive self-supervised methods, which require negative sampling: sampling alternative samples to contrast with the current sample (anchor). However, it is hard to ensure if all the negative samples belong to classes different from the anchor class without labels. This paper applies a non-contrastive self-supervised learning method on an unlabeled speech corpus to learn utterance-level embeddings. We used DIstillation with NO labels (DINO), proposed in computer vision, and adapted it to the speech domain. Unlike the contrastive methods, DINO does not require negative sampling. These embeddings were evaluated on speaker verification and emotion recognition. In speaker verification, the unsupervised DINO embedding with cosine scoring provided 4.38% EER on the VoxCeleb1 test trial. This outperforms the best contrastive self-supervised method by 40% relative in EER. An iterative pseudo-labeling training pipeline, not requiring speaker labels, further improved the EER to 1.89%. In emotion recognition, the DINO embedding performed 60.87, 79.21, and 56.98% in micro-f1 score on IEMOCAP, Crema-D, and MSP-Podcast, respectively. The results imply the generality of the DINO embedding to different speech applications.
VarArray Meets t-SOT: Advancing the State of the Art of Streaming Distant Conversational Speech Recognition
Sep 12, 2022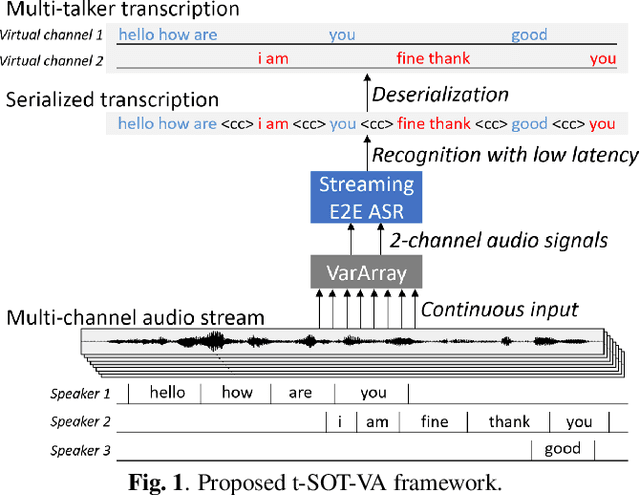
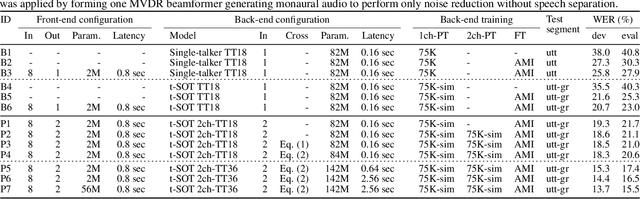
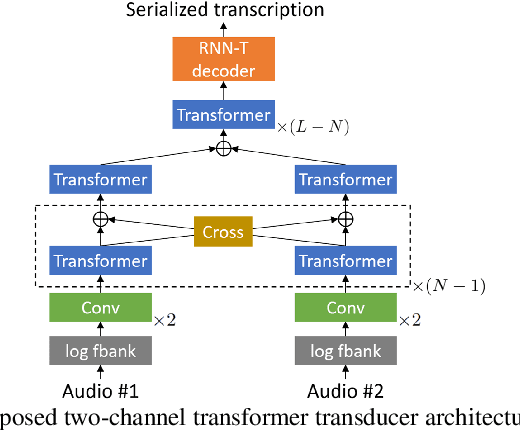

This paper presents a novel streaming automatic speech recognition (ASR) framework for multi-talker overlapping speech captured by a distant microphone array with an arbitrary geometry. Our framework, named t-SOT-VA, capitalizes on independently developed two recent technologies; array-geometry-agnostic continuous speech separation, or VarArray, and streaming multi-talker ASR based on token-level serialized output training (t-SOT). To combine the best of both technologies, we newly design a t-SOT-based ASR model that generates a serialized multi-talker transcription based on two separated speech signals from VarArray. We also propose a pre-training scheme for such an ASR model where we simulate VarArray's output signals based on monaural single-talker ASR training data. Conversation transcription experiments using the AMI meeting corpus show that the system based on the proposed framework significantly outperforms conventional ones. Our system achieves the state-of-the-art word error rates of 13.7% and 15.5% for the AMI development and evaluation sets, respectively, in the multiple-distant-microphone setting while retaining the streaming inference capability.
Personalized Lightweight Text-to-Speech: Voice Cloning with Adaptive Structured Pruning
Mar 21, 2023
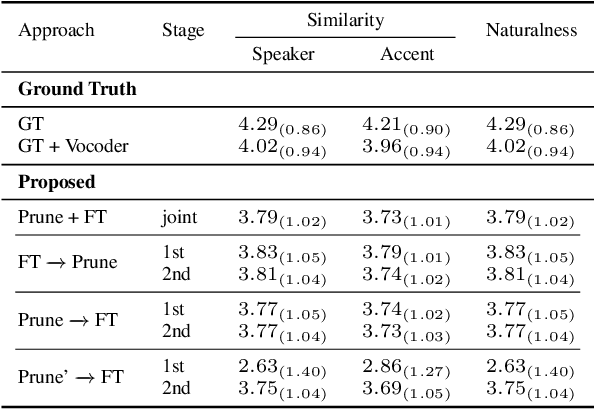
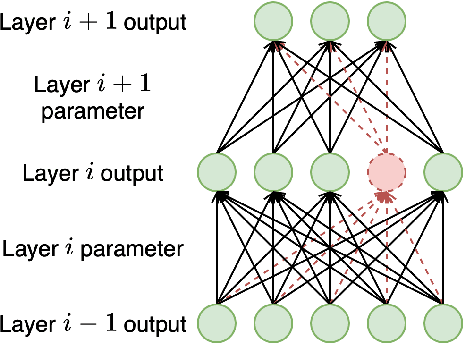
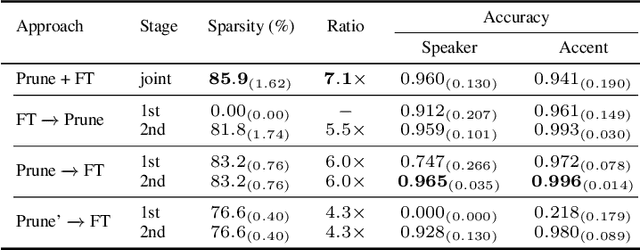
Personalized TTS is an exciting and highly desired application that allows users to train their TTS voice using only a few recordings. However, TTS training typically requires many hours of recording and a large model, making it unsuitable for deployment on mobile devices. To overcome this limitation, related works typically require fine-tuning a pre-trained TTS model to preserve its ability to generate high-quality audio samples while adapting to the target speaker's voice. This process is commonly referred to as ``voice cloning.'' Although related works have achieved significant success in changing the TTS model's voice, they are still required to fine-tune from a large pre-trained model, resulting in a significant size for the voice-cloned model. In this paper, we propose applying trainable structured pruning to voice cloning. By training the structured pruning masks with voice-cloning data, we can produce a unique pruned model for each target speaker. Our experiments demonstrate that using learnable structured pruning, we can compress the model size to 7 times smaller while achieving comparable voice-cloning performance.
TTS-Guided Training for Accent Conversion Without Parallel Data
Dec 20, 2022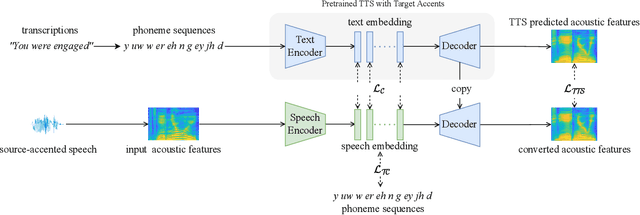
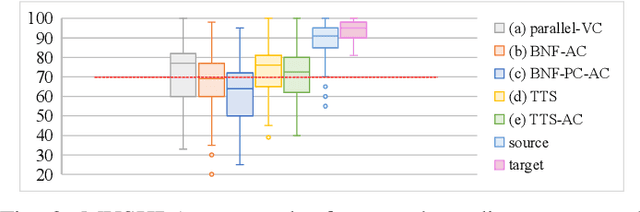
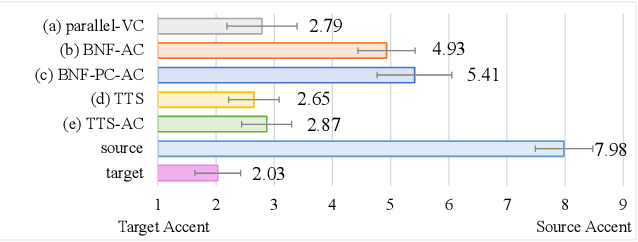
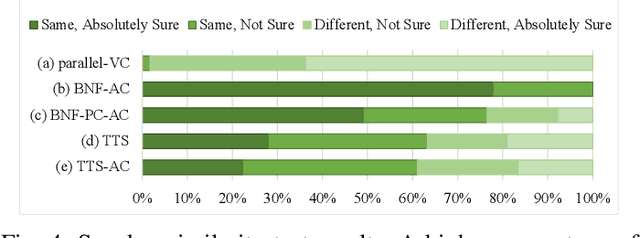
Accent Conversion (AC) seeks to change the accent of speech from one (source) to another (target) while preserving the speech content and speaker identity. However, many AC approaches rely on source-target parallel speech data. We propose a novel accent conversion framework without the need of parallel data. Specifically, a text-to-speech (TTS) system is first pretrained with target-accented speech data. This TTS model and its hidden representations are expected to be associated only with the target accent. Then, a speech encoder is trained to convert the accent of the speech under the supervision of the pretrained TTS model. In doing so, the source-accented speech and its corresponding transcription are forwarded to the speech encoder and the pretrained TTS, respectively. The output of the speech encoder is optimized to be the same as the text embedding in the TTS system. At run-time, the speech encoder is combined with the pretrained TTS decoder to convert the source-accented speech toward the target. In the experiments, we converted English with two source accents (Chinese and Indian) to the target accent (American/British/Canadian). Both objective metrics and subjective listening tests successfully validate that, without any parallel data, the proposed approach generates speech samples that are close to the target accent with high speech quality.
Semantic-preserved Communication System for Highly Efficient Speech Transmission
May 25, 2022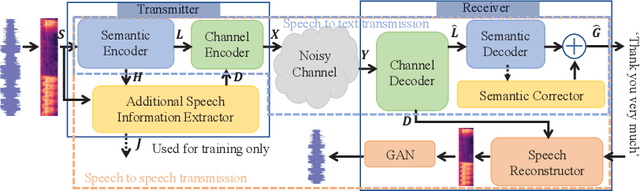
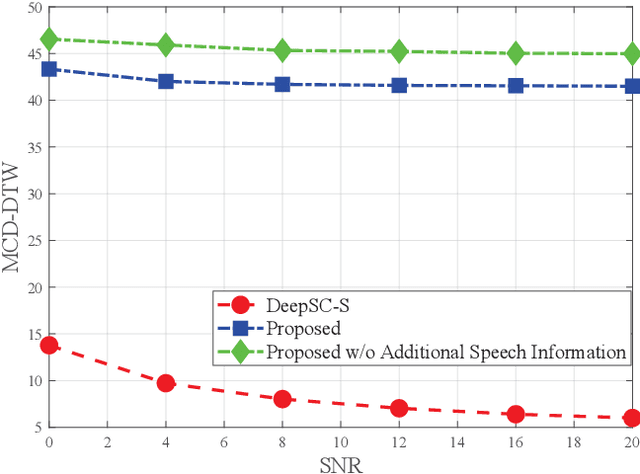
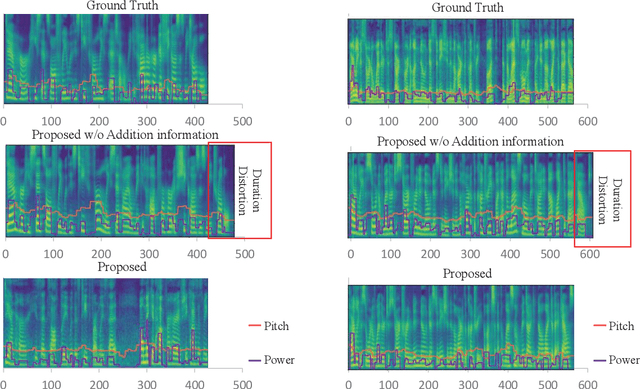
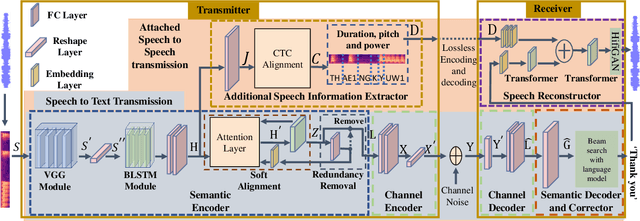
Deep learning (DL) based semantic communication methods have been explored for the efficient transmission of images, text, and speech in recent years. In contrast to traditional wireless communication methods that focus on the transmission of abstract symbols, semantic communication approaches attempt to achieve better transmission efficiency by only sending the semantic-related information of the source data. In this paper, we consider semantic-oriented speech transmission which transmits only the semantic-relevant information over the channel for the speech recognition task, and a compact additional set of semantic-irrelevant information for the speech reconstruction task. We propose a novel end-to-end DL-based transceiver which extracts and encodes the semantic information from the input speech spectrums at the transmitter and outputs the corresponding transcriptions from the decoded semantic information at the receiver. For the speech to speech transmission, we further include a CTC alignment module that extracts a small number of additional semantic-irrelevant but speech-related information for the better reconstruction of the original speech signals at the receiver. The simulation results confirm that our proposed method outperforms current methods in terms of the accuracy of the predicted text for the speech to text transmission and the quality of the recovered speech signals for the speech to speech transmission, and significantly improves transmission efficiency. More specifically, the proposed method only sends 16% of the amount of the transmitted symbols required by the existing methods while achieving about 10% reduction in WER for the speech to text transmission. For the speech to speech transmission, it results in an even more remarkable improvement in terms of transmission efficiency with only 0.2% of the amount of the transmitted symbols required by the existing method.
RealityTalk: Real-Time Speech-Driven Augmented Presentation for AR Live Storytelling
Aug 12, 2022
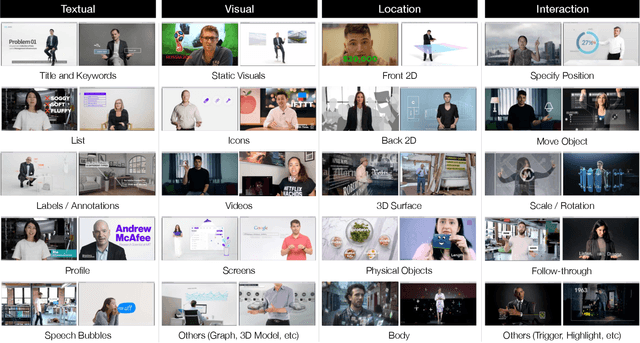
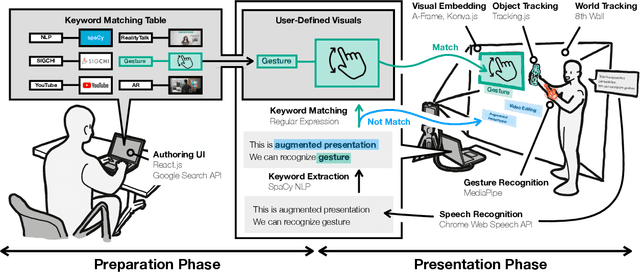

We present RealityTalk, a system that augments real-time live presentations with speech-driven interactive virtual elements. Augmented presentations leverage embedded visuals and animation for engaging and expressive storytelling. However, existing tools for live presentations often lack interactivity and improvisation, while creating such effects in video editing tools require significant time and expertise. RealityTalk enables users to create live augmented presentations with real-time speech-driven interactions. The user can interactively prompt, move, and manipulate graphical elements through real-time speech and supporting modalities. Based on our analysis of 177 existing video-edited augmented presentations, we propose a novel set of interaction techniques and then incorporated them into RealityTalk. We evaluate our tool from a presenter's perspective to demonstrate the effectiveness of our system.
Improving Massively Multilingual ASR With Auxiliary CTC Objectives
Feb 27, 2023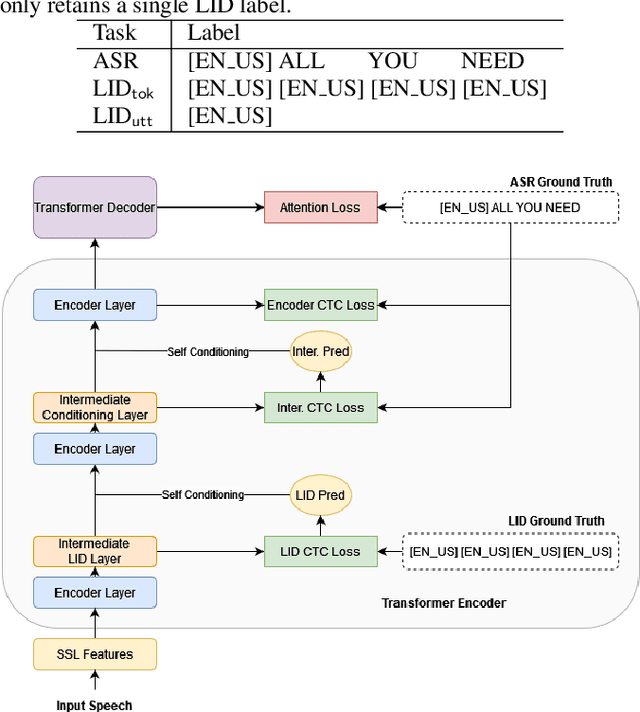
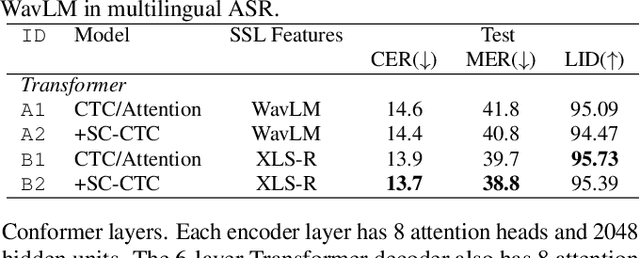
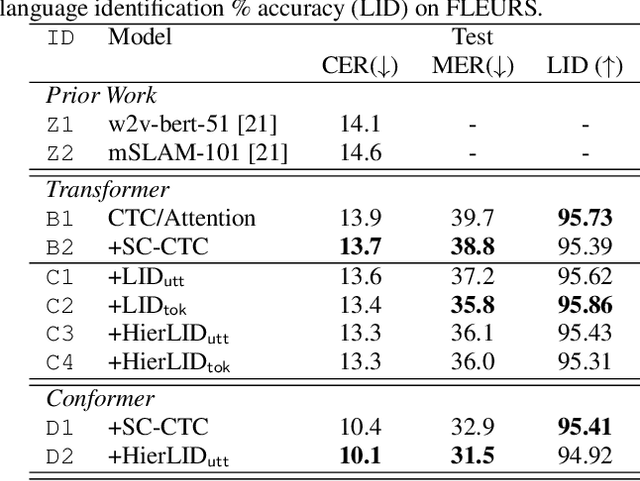
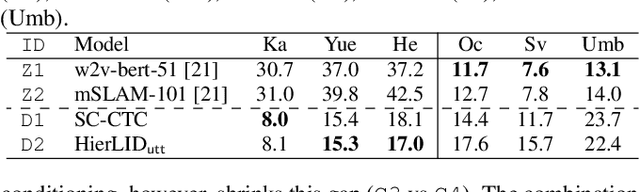
Multilingual Automatic Speech Recognition (ASR) models have extended the usability of speech technologies to a wide variety of languages. With how many languages these models have to handle, however, a key to understanding their imbalanced performance across different languages is to examine if the model actually knows which language it should transcribe. In this paper, we introduce our work on improving performance on FLEURS, a 102-language open ASR benchmark, by conditioning the entire model on language identity (LID). We investigate techniques inspired from recent Connectionist Temporal Classification (CTC) studies to help the model handle the large number of languages, conditioning on the LID predictions of auxiliary tasks. Our experimental results demonstrate the effectiveness of our technique over standard CTC/Attention-based hybrid models. Furthermore, our state-of-the-art systems using self-supervised models with the Conformer architecture improve over the results of prior work on FLEURS by a relative 28.4% CER. Trained models and reproducible recipes are available at https://github.com/espnet/espnet/tree/master/egs2/fleurs/asr1 .
Computer-assisted Pronunciation Training -- Speech synthesis is almost all you need
Jul 02, 2022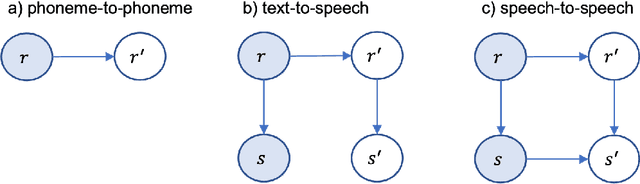
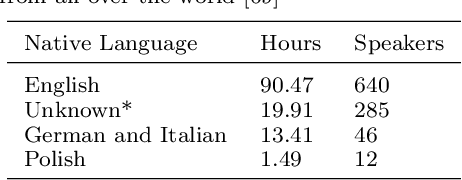

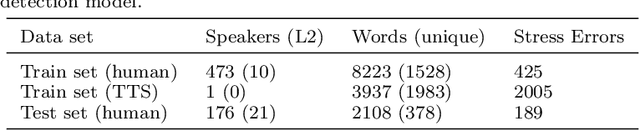
The research community has long studied computer-assisted pronunciation training (CAPT) methods in non-native speech. Researchers focused on studying various model architectures, such as Bayesian networks and deep learning methods, as well as on the analysis of different representations of the speech signal. Despite significant progress in recent years, existing CAPT methods are not able to detect pronunciation errors with high accuracy (only 60\% precision at 40\%-80\% recall). One of the key problems is the low availability of mispronounced speech that is needed for the reliable training of pronunciation error detection models. If we had a generative model that could mimic non-native speech and produce any amount of training data, then the task of detecting pronunciation errors would be much easier. We present three innovative techniques based on phoneme-to-phoneme (P2P), text-to-speech (T2S), and speech-to-speech (S2S) conversion to generate correctly pronounced and mispronounced synthetic speech. We show that these techniques not only improve the accuracy of three machine learning models for detecting pronunciation errors but also help establish a new state-of-the-art in the field. Earlier studies have used simple speech generation techniques such as P2P conversion, but only as an additional mechanism to improve the accuracy of pronunciation error detection. We, on the other hand, consider speech generation to be the first-class method of detecting pronunciation errors. The effectiveness of these techniques is assessed in the tasks of detecting pronunciation and lexical stress errors. Non-native English speech corpora of German, Italian, and Polish speakers are used in the evaluations. The best proposed S2S technique improves the accuracy of detecting pronunciation errors in AUC metric by 41\% from 0.528 to 0.749 compared to the state-of-the-art approach.
Reproducibility is Nothing without Correctness: The Importance of Testing Code in NLP
Mar 31, 2023


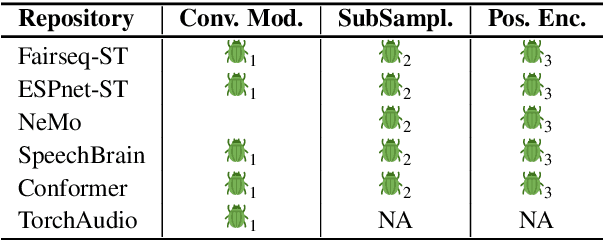
Despite its pivotal role in research experiments, code correctness is often presumed only on the basis of the perceived quality of the results. This comes with the risk of erroneous outcomes and potentially misleading findings. To address this issue, we posit that the current focus on result reproducibility should go hand in hand with the emphasis on coding best practices. We bolster our call to the NLP community by presenting a case study, in which we identify (and correct) three bugs in widely used open-source implementations of the state-of-the-art Conformer architecture. Through comparative experiments on automatic speech recognition and translation in various language settings, we demonstrate that the existence of bugs does not prevent the achievement of good and reproducible results and can lead to incorrect conclusions that potentially misguide future research. In response to this, this study is a call to action toward the adoption of coding best practices aimed at fostering correctness and improving the quality of the developed software.