 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Modeling Speaker-Listener Interaction for Backchannel Prediction
Apr 10, 2023
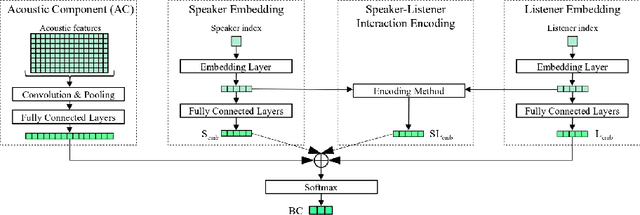
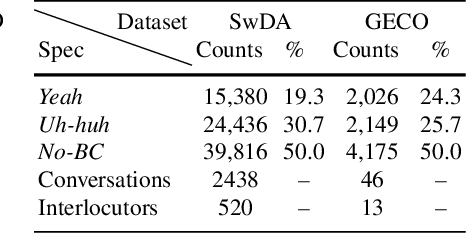
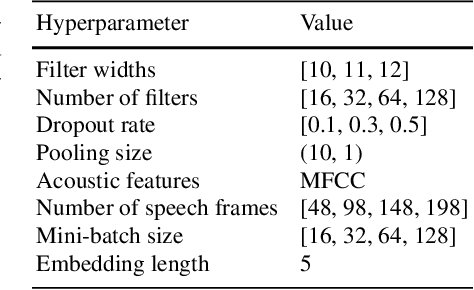
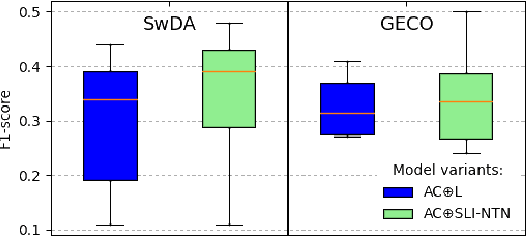
We present our latest findings on backchannel modeling novelly motivated by the canonical use of the minimal responses Yeah and Uh-huh in English and their correspondent tokens in German, and the effect of encoding the speaker-listener interaction. Backchanneling theories emphasize the active and continuous role of the listener in the course of the conversation, their effects on the speaker's subsequent talk, and the consequent dynamic speaker-listener interaction. Therefore, we propose a neural-based acoustic backchannel classifier on minimal responses by processing acoustic features from the speaker speech, capturing and imitating listeners' backchanneling behavior, and encoding speaker-listener interaction. Our experimental results on the Switchboard and GECO datasets reveal that in almost all tested scenarios the speaker or listener behavior embeddings help the model make more accurate backchannel predictions. More importantly, a proper interaction encoding strategy, i.e., combining the speaker and listener embeddings, leads to the best performance on both datasets in terms of F1-score.
Speaker and Language Change Detection using Wav2vec2 and Whisper
Feb 18, 2023
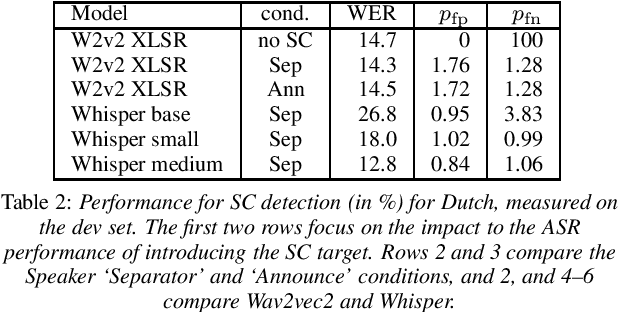
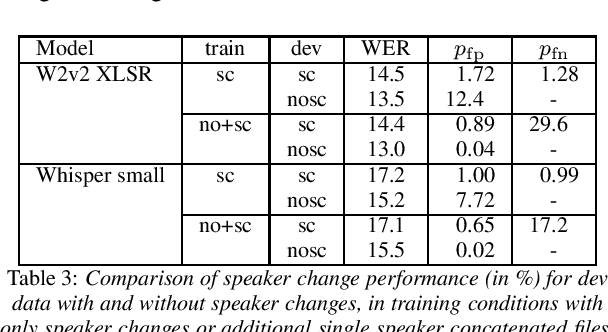
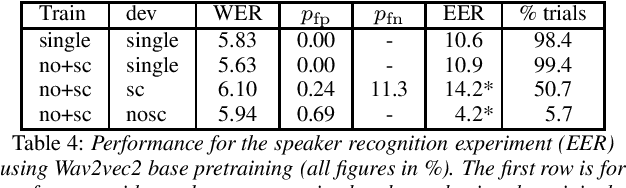
We investigate recent transformer networks pre-trained for automatic speech recognition for their ability to detect speaker and language changes in speech. We do this by simply adding speaker (change) or language targets to the labels. For Wav2vec2 pre-trained networks, we also investigate if the representation for the speaker change symbol can be conditioned to capture speaker identity characteristics. Using a number of constructed data sets we show that these capabilities are definitely there, with speaker recognition equal error rates of the order of 10% and language detection error rates of a few percent. We will publish the code for reproducibility.
Audio-Visual Speech Codecs: Rethinking Audio-Visual Speech Enhancement by Re-Synthesis
Mar 31, 2022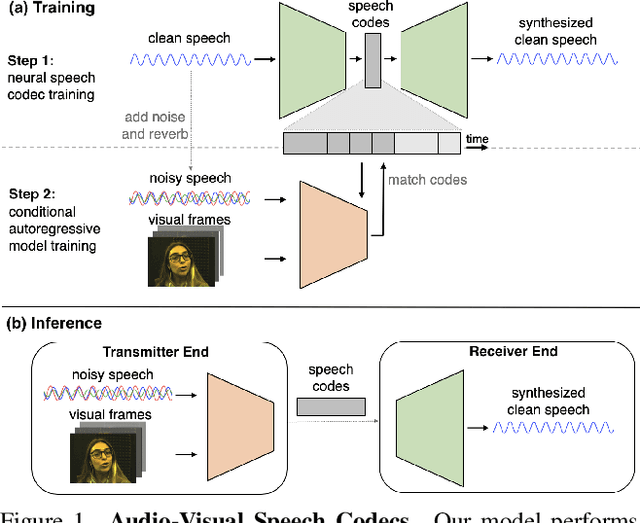
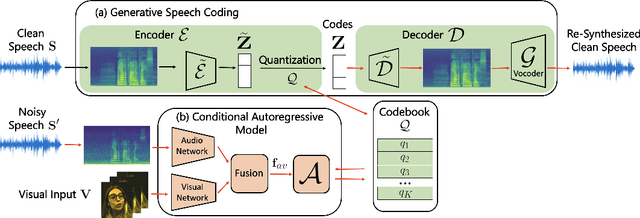

Since facial actions such as lip movements contain significant information about speech content, it is not surprising that audio-visual speech enhancement methods are more accurate than their audio-only counterparts. Yet, state-of-the-art approaches still struggle to generate clean, realistic speech without noise artifacts and unnatural distortions in challenging acoustic environments. In this paper, we propose a novel audio-visual speech enhancement framework for high-fidelity telecommunications in AR/VR. Our approach leverages audio-visual speech cues to generate the codes of a neural speech codec, enabling efficient synthesis of clean, realistic speech from noisy signals. Given the importance of speaker-specific cues in speech, we focus on developing personalized models that work well for individual speakers. We demonstrate the efficacy of our approach on a new audio-visual speech dataset collected in an unconstrained, large vocabulary setting, as well as existing audio-visual datasets, outperforming speech enhancement baselines on both quantitative metrics and human evaluation studies. Please see the supplemental video for qualitative results at https://github.com/facebookresearch/facestar/releases/download/paper_materials/video.mp4.
An Experimental Study on Private Aggregation of Teacher Ensemble Learning for End-to-End Speech Recognition
Oct 13, 2022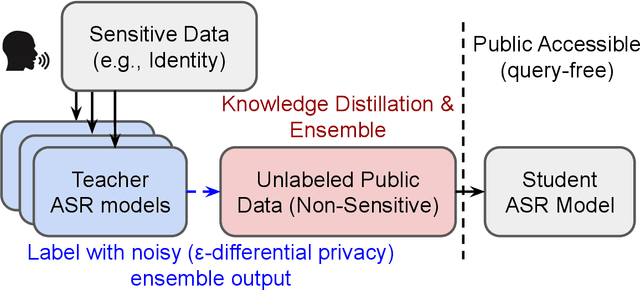
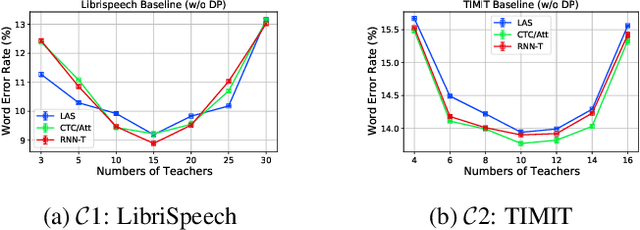
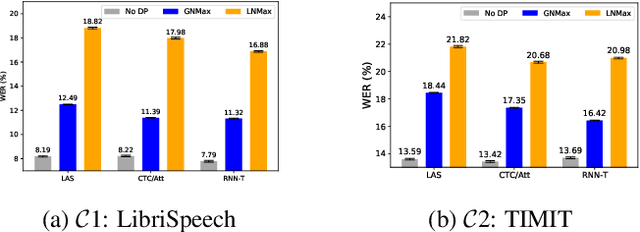
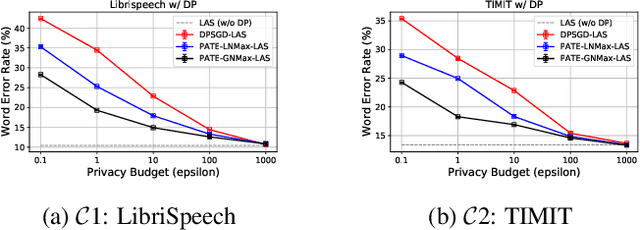
Differential privacy (DP) is one data protection avenue to safeguard user information used for training deep models by imposing noisy distortion on privacy data. Such a noise perturbation often results in a severe performance degradation in automatic speech recognition (ASR) in order to meet a privacy budget $\varepsilon$. Private aggregation of teacher ensemble (PATE) utilizes ensemble probabilities to improve ASR accuracy when dealing with the noise effects controlled by small values of $\varepsilon$. We extend PATE learning to work with dynamic patterns, namely speech utterances, and perform a first experimental demonstration that it prevents acoustic data leakage in ASR training. We evaluate three end-to-end deep models, including LAS, hybrid CTC/attention, and RNN transducer, on the open-source LibriSpeech and TIMIT corpora. PATE learning-enhanced ASR models outperform the benchmark DP-SGD mechanisms, especially under strict DP budgets, giving relative word error rate reductions between 26.2% and 27.5% for an RNN transducer model evaluated with LibriSpeech. We also introduce a DP-preserving ASR solution for pretraining on public speech corpora.
Inter-KD: Intermediate Knowledge Distillation for CTC-Based Automatic Speech Recognition
Nov 28, 2022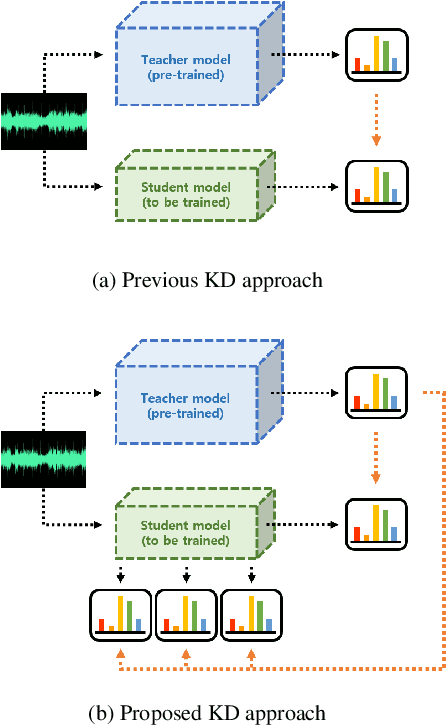
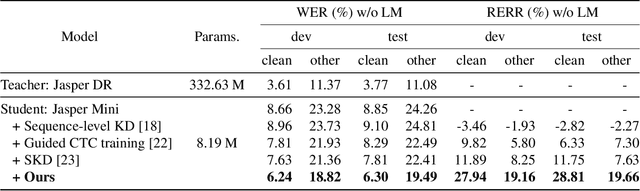
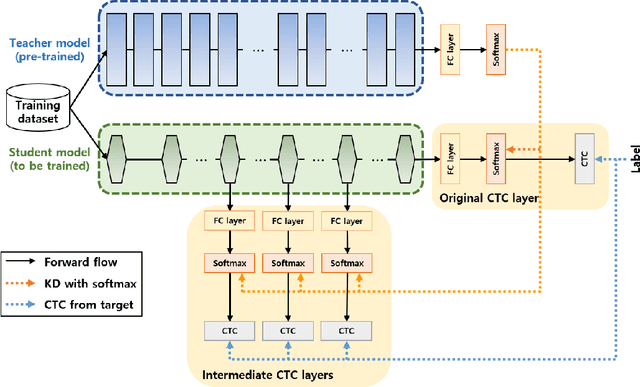
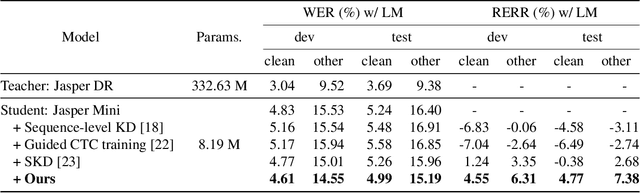
Recently, the advance in deep learning has brought a considerable improvement in the end-to-end speech recognition field, simplifying the traditional pipeline while producing promising results. Among the end-to-end models, the connectionist temporal classification (CTC)-based model has attracted research interest due to its non-autoregressive nature. However, such CTC models require a heavy computational cost to achieve outstanding performance. To mitigate the computational burden, we propose a simple yet effective knowledge distillation (KD) for the CTC framework, namely Inter-KD, that additionally transfers the teacher's knowledge to the intermediate CTC layers of the student network. From the experimental results on the LibriSpeech, we verify that the Inter-KD shows better achievements compared to the conventional KD methods. Without using any language model (LM) and data augmentation, Inter-KD improves the word error rate (WER) performance from 8.85 % to 6.30 % on the test-clean.
An Ensemble Teacher-Student Learning Approach with Poisson Sub-sampling to Differential Privacy Preserving Speech Recognition
Oct 12, 2022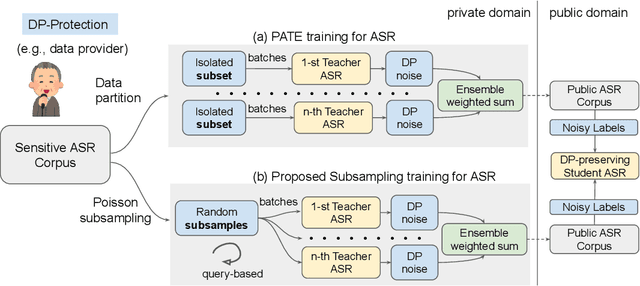


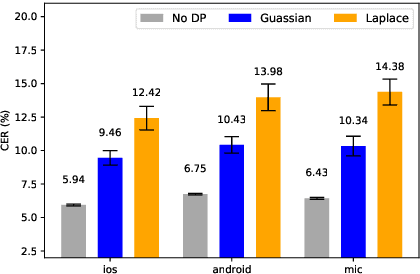
We propose an ensemble learning framework with Poisson sub-sampling to effectively train a collection of teacher models to issue some differential privacy (DP) guarantee for training data. Through boosting under DP, a student model derived from the training data suffers little model degradation from the models trained with no privacy protection. Our proposed solution leverages upon two mechanisms, namely: (i) a privacy budget amplification via Poisson sub-sampling to train a target prediction model that requires less noise to achieve a same level of privacy budget, and (ii) a combination of the sub-sampling technique and an ensemble teacher-student learning framework that introduces DP-preserving noise at the output of the teacher models and transfers DP-preserving properties via noisy labels. Privacy-preserving student models are then trained with the noisy labels to learn the knowledge with DP-protection from the teacher model ensemble. Experimental evidences on spoken command recognition and continuous speech recognition of Mandarin speech show that our proposed framework greatly outperforms existing DP-preserving algorithms in both speech processing tasks.
GeneFace++: Generalized and Stable Real-Time Audio-Driven 3D Talking Face Generation
May 01, 2023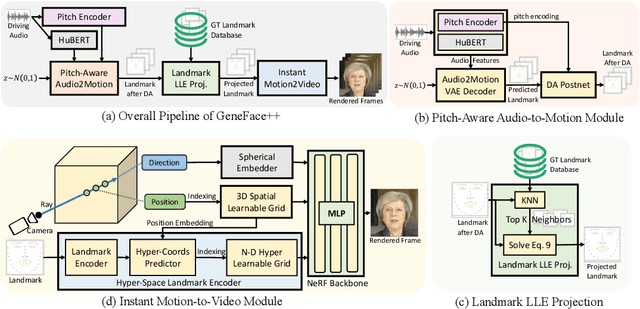
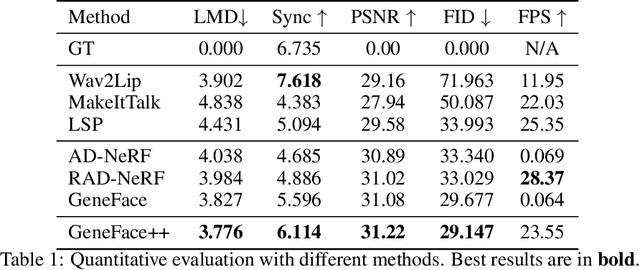
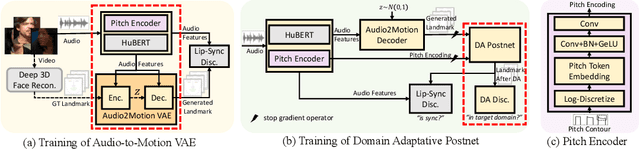

Generating talking person portraits with arbitrary speech audio is a crucial problem in the field of digital human and metaverse. A modern talking face generation method is expected to achieve the goals of generalized audio-lip synchronization, good video quality, and high system efficiency. Recently, neural radiance field (NeRF) has become a popular rendering technique in this field since it could achieve high-fidelity and 3D-consistent talking face generation with a few-minute-long training video. However, there still exist several challenges for NeRF-based methods: 1) as for the lip synchronization, it is hard to generate a long facial motion sequence of high temporal consistency and audio-lip accuracy; 2) as for the video quality, due to the limited data used to train the renderer, it is vulnerable to out-of-domain input condition and produce bad rendering results occasionally; 3) as for the system efficiency, the slow training and inference speed of the vanilla NeRF severely obstruct its usage in real-world applications. In this paper, we propose GeneFace++ to handle these challenges by 1) utilizing the pitch contour as an auxiliary feature and introducing a temporal loss in the facial motion prediction process; 2) proposing a landmark locally linear embedding method to regulate the outliers in the predicted motion sequence to avoid robustness issues; 3) designing a computationally efficient NeRF-based motion-to-video renderer to achieves fast training and real-time inference. With these settings, GeneFace++ becomes the first NeRF-based method that achieves stable and real-time talking face generation with generalized audio-lip synchronization. Extensive experiments show that our method outperforms state-of-the-art baselines in terms of subjective and objective evaluation. Video samples are available at https://genefaceplusplus.github.io .
Non-Asymptotic Pointwise and Worst-Case Bounds for Classical Spectrum Estimators
Mar 21, 2023Spectrum estimation is a fundamental methodology in the analysis of time-series data, with applications including medicine, speech analysis, and control design. The asymptotic theory of spectrum estimation is well-understood, but the theory is limited when the number of samples is fixed and finite. This paper gives non-asymptotic error bounds for a broad class of spectral estimators, both pointwise (at specific frequencies) and in the worst case over all frequencies. The general method is used to derive error bounds for the classical Blackman-Tukey, Bartlett, and Welch estimators.
Hate Speech Criteria: A Modular Approach to Task-Specific Hate Speech Definitions
Jun 30, 2022
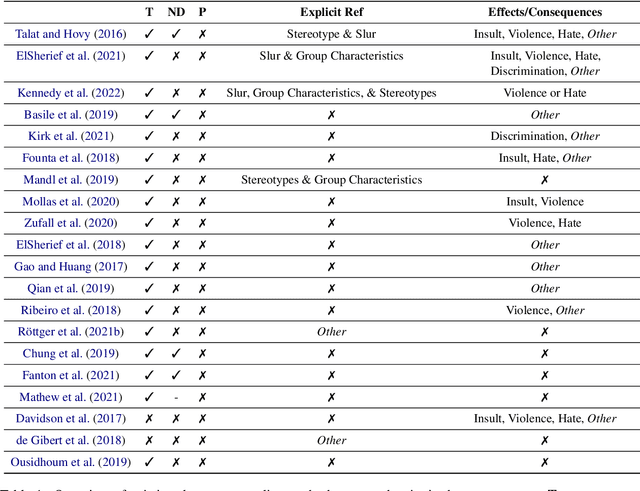
\textbf{Offensive Content Warning}: This paper contains offensive language only for providing examples that clarify this research and do not reflect the authors' opinions. Please be aware that these examples are offensive and may cause you distress. The subjectivity of recognizing \textit{hate speech} makes it a complex task. This is also reflected by different and incomplete definitions in NLP. We present \textit{hate speech} criteria, developed with perspectives from law and social science, with the aim of helping researchers create more precise definitions and annotation guidelines on five aspects: (1) target groups, (2) dominance, (3) perpetrator characteristics, (4) type of negative group reference, and the (5) type of potential consequences/effects. Definitions can be structured so that they cover a more broad or more narrow phenomenon. As such, conscious choices can be made on specifying criteria or leaving them open. We argue that the goal and exact task developers have in mind should determine how the scope of \textit{hate speech} is defined. We provide an overview of the properties of English datasets from \url{hatespeechdata.com} that may help select the most suitable dataset for a specific scenario.
HMM vs. CTC for Automatic Speech Recognition: Comparison Based on Full-Sum Training from Scratch
Oct 18, 2022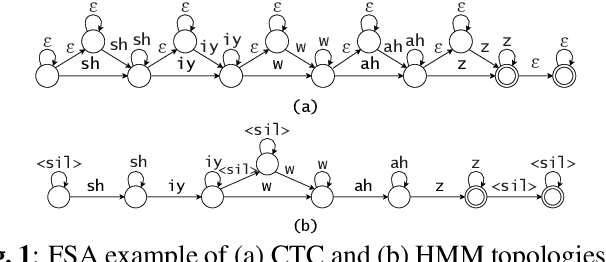
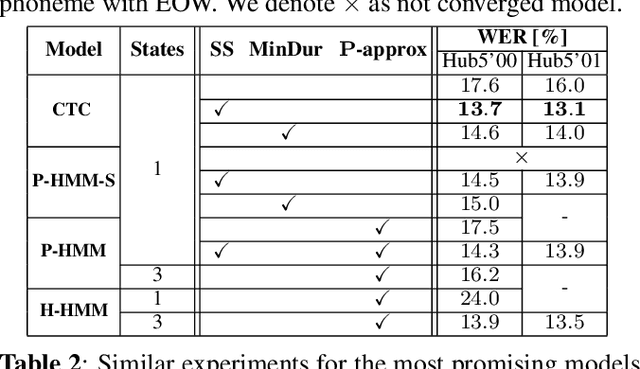
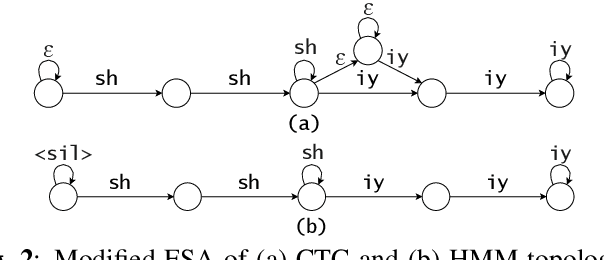
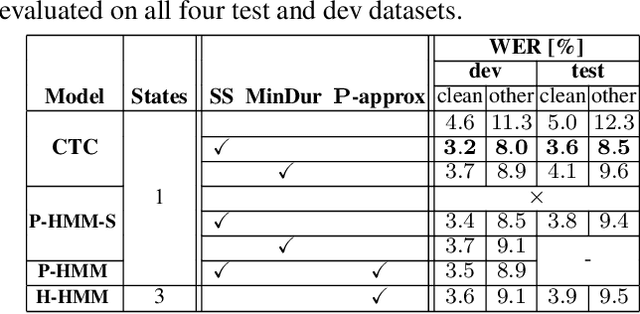
In this work, we compare from-scratch sequence-level cross-entropy (full-sum) training of Hidden Markov Model (HMM) and Connectionist Temporal Classification (CTC) topologies for automatic speech recognition (ASR). Besides accuracy, we further analyze their capability for generating high-quality time alignment between the speech signal and the transcription, which can be crucial for many subsequent applications. Moreover, we propose several methods to improve convergence of from-scratch full-sum training by addressing the alignment modeling issue. Systematic comparison is conducted on both Switchboard and LibriSpeech corpora across CTC, posterior HMM with and w/o transition probabilities, and standard hybrid HMM. We also provide a detailed analysis of both Viterbi forced-alignment and Baum-Welch full-sum occupation probabilities.