 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Improved disentangled speech representations using contrastive learning in factorized hierarchical variational autoencoder
Nov 15, 2022
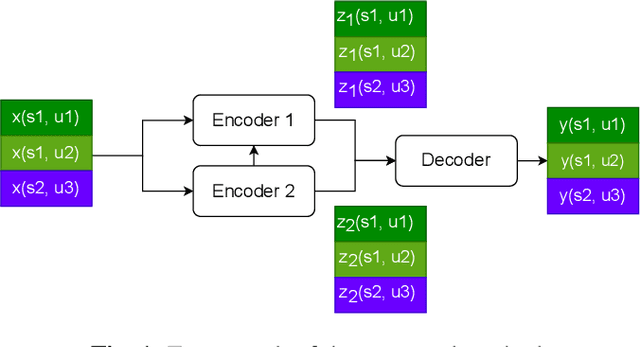
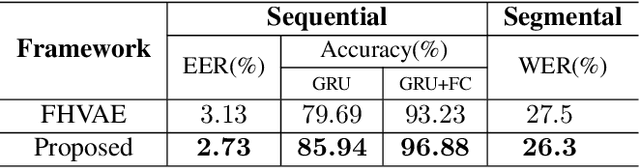
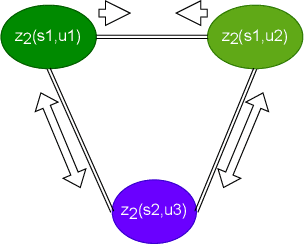
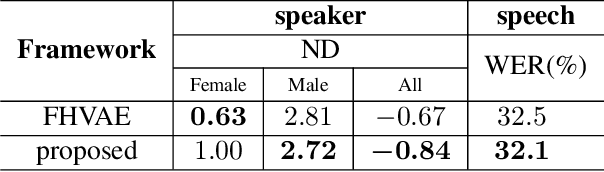
By utilizing the fact that speaker identity and content vary on different time scales, \acrlong{fhvae} (\acrshort{fhvae}) uses a sequential latent variable and a segmental latent variable to symbolize these two attributes. Disentanglement is carried out by assuming the latent variables representing speaker and content follow sequence-dependent and sequence-independent priors. For the sequence-dependent prior, \acrshort{fhvae} assumes a Gaussian distribution with an utterance-scale varying mean and a fixed small variance. The training process promotes sequential variables getting close to the mean of its prior with small variance. However, this constraint is relatively weak. Therefore, we introduce contrastive learning in the \acrshort{fhvae} framework. The proposed method aims to make the sequential variables clustering when representing the same speaker, while distancing themselves as far as possible from those of other speakers. The structure of the framework has not been changed in the proposed method but only the training process, thus no more cost is needed during test. Voice conversion has been chosen as the application in this paper. Latent variable evaluations include speakerincrease verification and identification for the sequential latent variable, and speech recognition for the segmental latent variable. Furthermore, assessments of voice conversion performance are on the grounds of speaker verification and speech recognition experiments. Experiment results show that the proposed method improves both sequential and segmental feature extraction compared with \acrshort{fhvae}, and moderately improved voice conversion performance.
Context-Aware Selective Label Smoothing for Calibrating Sequence Recognition Model
Mar 13, 2023
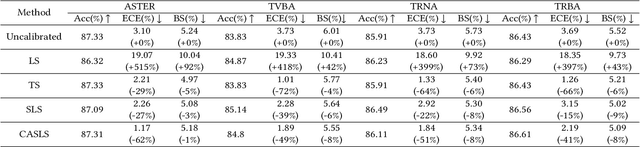
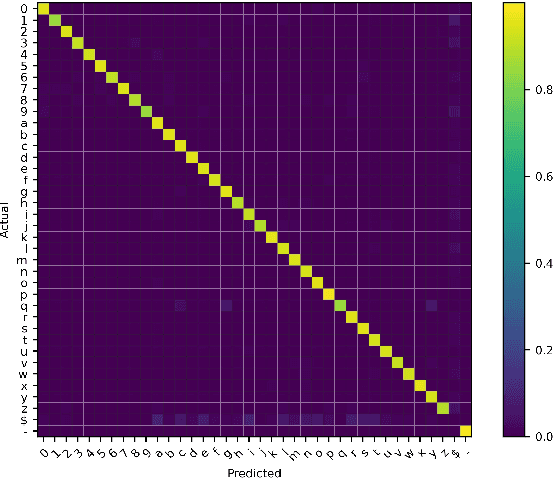
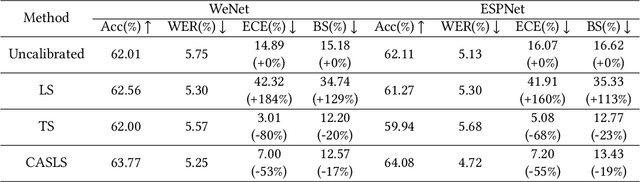
Despite the success of deep neural network (DNN) on sequential data (i.e., scene text and speech) recognition, it suffers from the over-confidence problem mainly due to overfitting in training with the cross-entropy loss, which may make the decision-making less reliable. Confidence calibration has been recently proposed as one effective solution to this problem. Nevertheless, the majority of existing confidence calibration methods aims at non-sequential data, which is limited if directly applied to sequential data since the intrinsic contextual dependency in sequences or the class-specific statistical prior is seldom exploited. To the end, we propose a Context-Aware Selective Label Smoothing (CASLS) method for calibrating sequential data. The proposed CASLS fully leverages the contextual dependency in sequences to construct confusion matrices of contextual prediction statistics over different classes. Class-specific error rates are then used to adjust the weights of smoothing strength in order to achieve adaptive calibration. Experimental results on sequence recognition tasks, including scene text recognition and speech recognition, demonstrate that our method can achieve the state-of-the-art performance.
Learning-based Robust Speaker Counting and Separation with the Aid of Spatial Coherence
Mar 13, 2023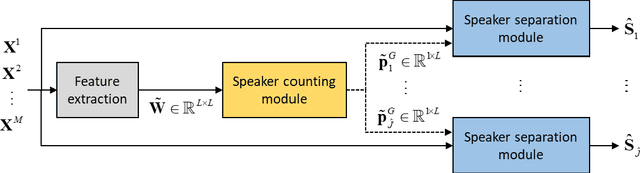
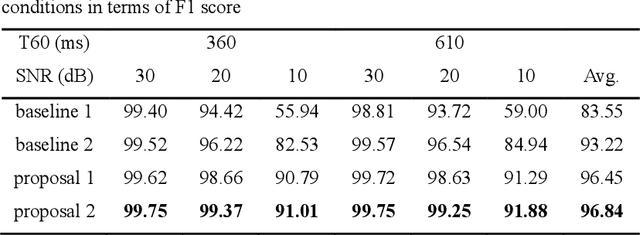
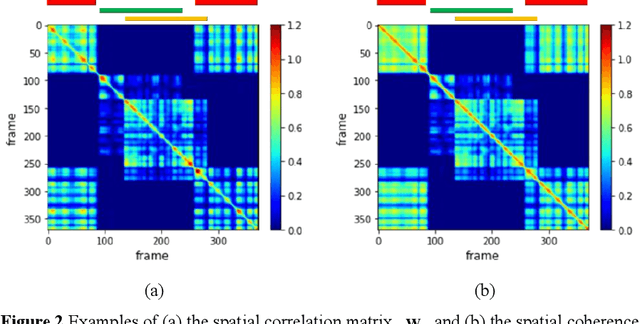
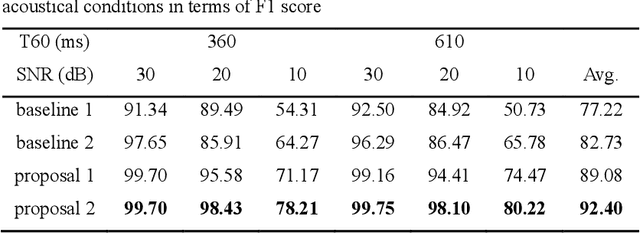
A two-stage approach is proposed for speaker counting and speech separation in noisy and reverberant environments. A spatial coherence matrix (SCM) is computed using whitened relative transfer functions (wRTFs) across time frames. The global activity functions of each speaker are estimated on the basis of a simplex constructed using the eigenvectors of the SCM, while the local coherence functions are computed from the coherence between the wRTFs of a time-frequency bin and the global activity function-weighted RTF of the target speaker. In speaker counting, we use the eigenvalues of the SCM and the maximum similarity of the interframe global activity distributions between two speakers as the input features to the speaker counting network (SCnet). In speaker separation, a global and local activity-driven network (GLADnet) is utilized to estimate a speaker mask, which is particularly useful for highly overlapping speech signals. Experimental results obtained from the real meeting recordings demonstrated the superior speaker counting and speaker separation performance achieved by the proposed learning-based system without prior knowledge of the array configurations.
Conversion of Acoustic Signal (Speech) Into Text By Digital Filter using Natural Language Processing
Sep 09, 2022
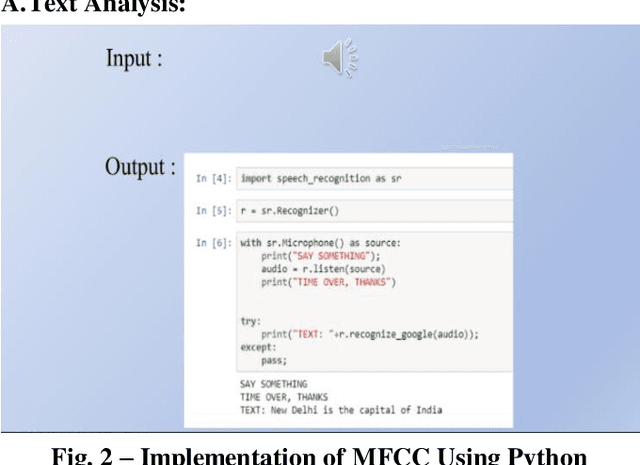
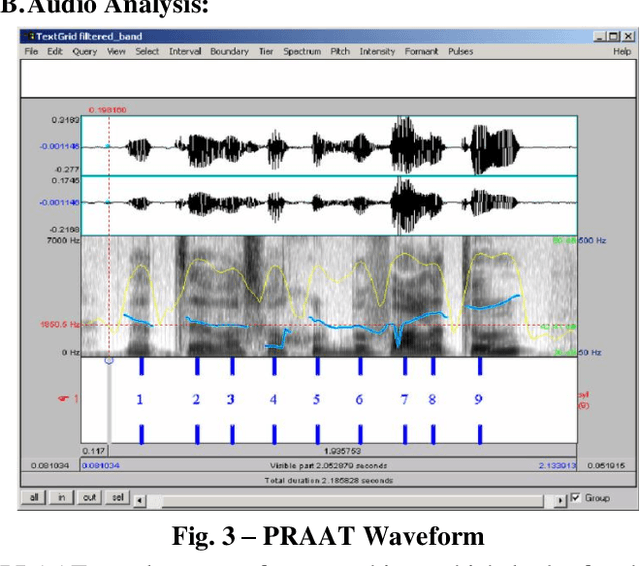
One of the most crucial aspects of communication in daily life is speech recognition. Speech recognition that is based on natural language processing is one of the essential elements in the conversion of one system to another. In this paper, we created an interface that transforms speech and other auditory inputs into text using a digital filter. Contrary to the many methods for this conversion, it is also possible for linguistic faults to appear occasionally, gender recognition, speech recognition that is unsuccessful (cannot recognize voice), and gender recognition to fail. Since technical problems are involved, we developed a program that acts as a mediator to prevent initiating software issues in order to eliminate even this little deviation. Its planned MFCC and HMM are in sync with its AI system. As a result, technical errors have been avoided.
Diacritic Recognition Performance in Arabic ASR
Feb 27, 2023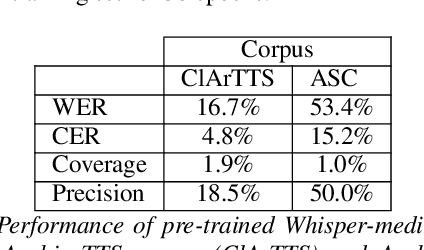
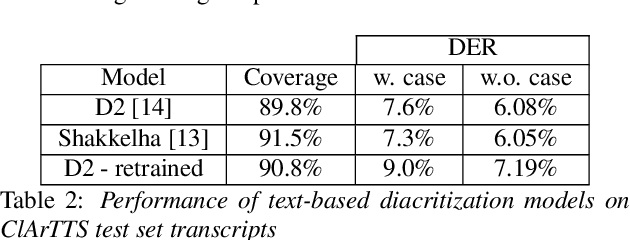
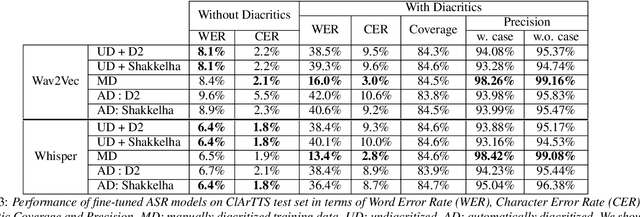
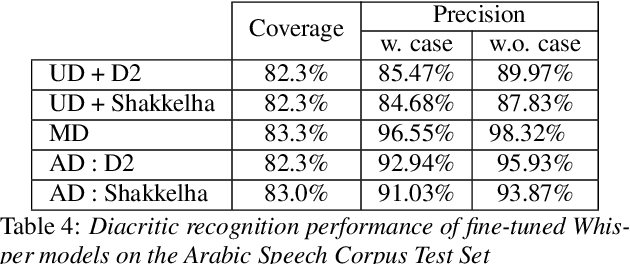
We present an analysis of diacritic recognition performance in Arabic Automatic Speech Recognition (ASR) systems. As most existing Arabic speech corpora do not contain all diacritical marks, which represent short vowels and other phonetic information in Arabic script, current state-of-the-art ASR models do not produce full diacritization in their output. Automatic text-based diacritization has previously been employed both as a pre-processing step to train diacritized ASR, or as a post-processing step to diacritize the resulting ASR hypotheses. It is generally believed that input diacritization degrades ASR performance, but no systematic evaluation of ASR diacritization performance, independent of ASR performance, has been conducted to date. In this paper, we attempt to experimentally clarify whether input diacritiztation indeed degrades ASR quality, and to compare the diacritic recognition performance against text-based diacritization as a post-processing step. We start with pre-trained Arabic ASR models and fine-tune them on transcribed speech data with different diacritization conditions: manual, automatic, and no diacritization. We isolate diacritic recognition performance from the overall ASR performance using coverage and precision metrics. We find that ASR diacritization significantly outperforms text-based diacritization in post-processing, particularly when the ASR model is fine-tuned with manually diacritized transcripts.
Can deepfakes be created by novice users?
Apr 28, 2023


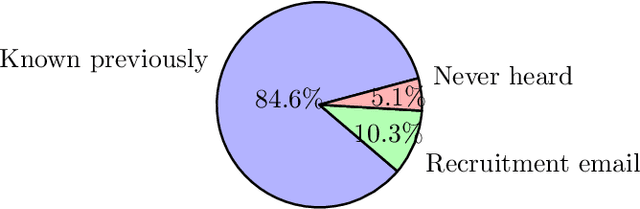
Recent advancements in machine learning and computer vision have led to the proliferation of Deepfakes. As technology democratizes over time, there is an increasing fear that novice users can create Deepfakes, to discredit others and undermine public discourse. In this paper, we conduct user studies to understand whether participants with advanced computer skills and varying levels of computer science expertise can create Deepfakes of a person saying a target statement using limited media files. We conduct two studies; in the first study (n = 39) participants try creating a target Deepfake in a constrained time frame using any tool they desire. In the second study (n = 29) participants use pre-specified deep learning-based tools to create the same Deepfake. We find that for the first study, 23.1% of the participants successfully created complete Deepfakes with audio and video, whereas, for the second user study, 58.6% of the participants were successful in stitching target speech to the target video. We further use Deepfake detection software tools as well as human examiner-based analysis, to classify the successfully generated Deepfake outputs as fake, suspicious, or real. The software detector classified 80% of the Deepfakes as fake, whereas the human examiners classified 100% of the videos as fake. We conclude that creating Deepfakes is a simple enough task for a novice user given adequate tools and time; however, the resulting Deepfakes are not sufficiently real-looking and are unable to completely fool detection software as well as human examiners
Unifying the Discrete and Continuous Emotion labels for Speech Emotion Recognition
Oct 29, 2022
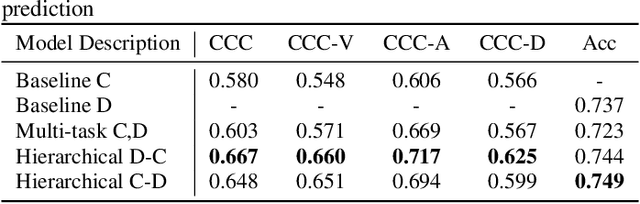
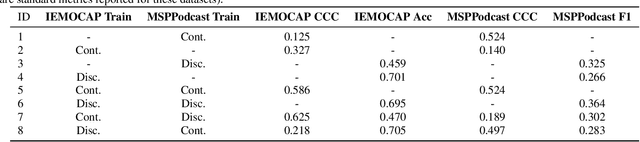
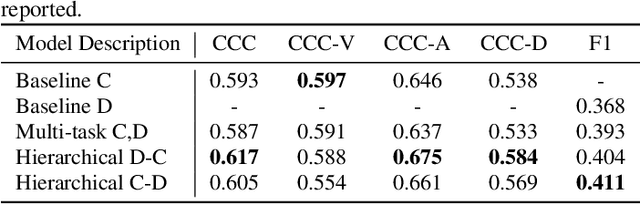
Traditionally, in paralinguistic analysis for emotion detection from speech, emotions have been identified with discrete or dimensional (continuous-valued) labels. Accordingly, models that have been proposed for emotion detection use one or the other of these label types. However, psychologists like Russell and Plutchik have proposed theories and models that unite these views, maintaining that these representations have shared and complementary information. This paper is an attempt to validate these viewpoints computationally. To this end, we propose a model to jointly predict continuous and discrete emotional attributes and show how the relationship between these can be utilized to improve the robustness and performance of emotion recognition tasks. Our approach comprises multi-task and hierarchical multi-task learning frameworks that jointly model the relationships between continuous-valued and discrete emotion labels. Experimental results on two widely used datasets (IEMOCAP and MSPPodcast) for speech-based emotion recognition show that our model results in statistically significant improvements in performance over strong baselines with non-unified approaches. We also demonstrate that using one type of label (discrete or continuous-valued) for training improves recognition performance in tasks that use the other type of label. Experimental results and reasoning for this approach (called the mismatched training approach) are also presented.
Efficient Self-supervised Learning with Contextualized Target Representations for Vision, Speech and Language
Dec 14, 2022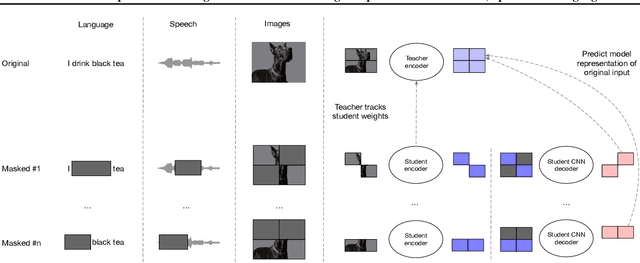
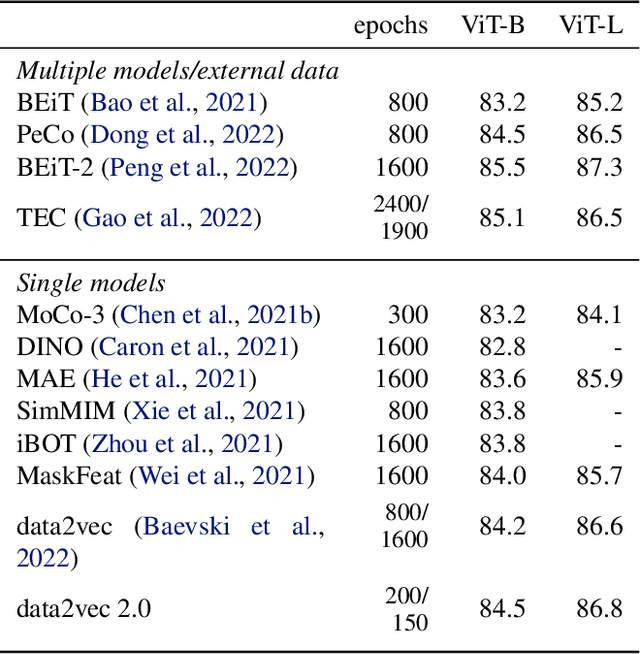
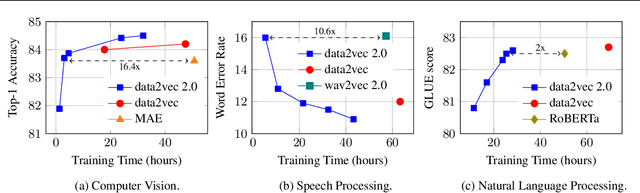

Current self-supervised learning algorithms are often modality-specific and require large amounts of computational resources. To address these issues, we increase the training efficiency of data2vec, a learning objective that generalizes across several modalities. We do not encode masked tokens, use a fast convolutional decoder and amortize the effort to build teacher representations. data2vec 2.0 benefits from the rich contextualized target representations introduced in data2vec which enable a fast self-supervised learner. Experiments on ImageNet-1K image classification show that data2vec 2.0 matches the accuracy of Masked Autoencoders in 16.4x lower pre-training time, on Librispeech speech recognition it performs as well as wav2vec 2.0 in 10.6x less time, and on GLUE natural language understanding it matches a retrained RoBERTa model in half the time. Trading some speed for accuracy results in ImageNet-1K top-1 accuracy of 86.8\% with a ViT-L model trained for 150 epochs.
SIA-FTP: A Spoken Instruction Aware Flight Trajectory Prediction Framework
May 02, 2023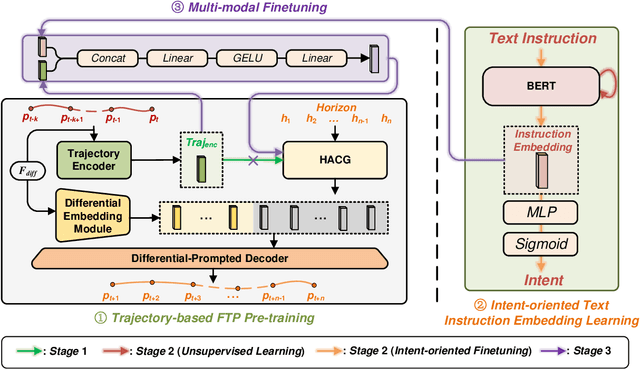

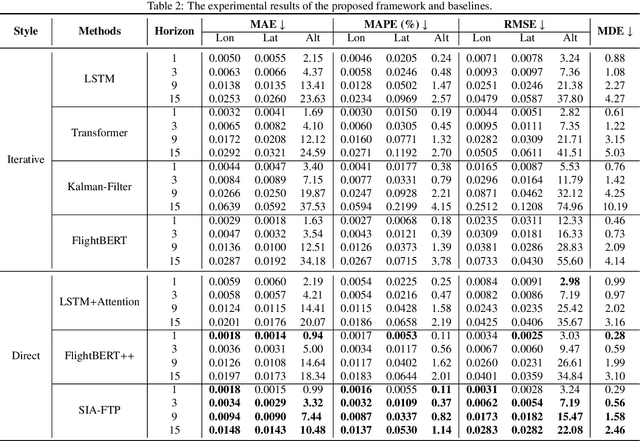
Ground-air negotiation via speech communication is a vital prerequisite for ensuring safety and efficiency in air traffic control (ATC) operations. However, with the increase in traffic flow, incorrect instructions caused by human factors bring a great threat to ATC safety. Existing flight trajectory prediction (FTP) approaches primarily rely on the flight status of historical trajectory, leading to significant delays in the prediction of real-time maneuvering instruction, which is not conducive to conflict detection. A major reason is that spoken instructions and flight trajectories are presented in different modalities in the current air traffic control (ATC) system, bringing great challenges to considering the maneuvering instruction in the FTP tasks. In this paper, a spoken instruction-aware FTP framework, called SIA-FTP, is innovatively proposed to support high-maneuvering FTP tasks by incorporating instant spoken instruction. To address the modality gap and minimize the data requirements, a 3-stage learning paradigm is proposed to implement the SIA-FTP framework in a progressive manner, including trajectory-based FTP pretraining, intent-oriented instruction embedding learning, and multi-modal finetuning. Specifically, the FTP model and the instruction embedding with maneuvering semantics are pre-trained using volumes of well-resourced trajectory and text data in the 1st and 2nd stages. In succession, a multi-modal fusion strategy is proposed to incorporate the pre-trained instruction embedding into the FTP model and integrate the two pre-trained networks into a joint model. Finally, the joint model is finetuned using the limited trajectory-instruction data to enhance the FTP performance within maneuvering instruction scenarios. The experimental results demonstrated that the proposed framework presents an impressive performance improvement in high-maneuvering scenarios.
LMEC: Learnable Multiplicative Absolute Position Embedding Based Conformer for Speech Recognition
Dec 05, 2022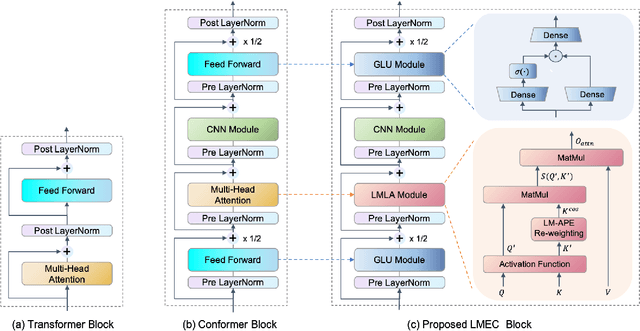
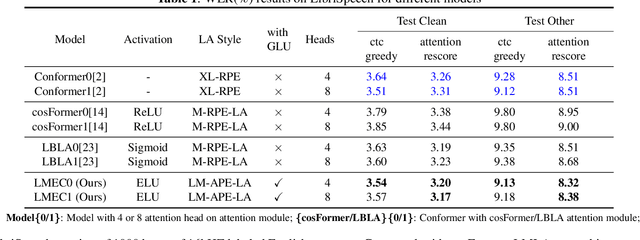
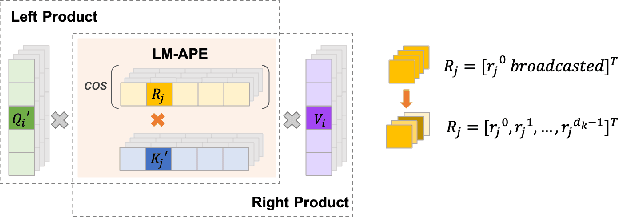
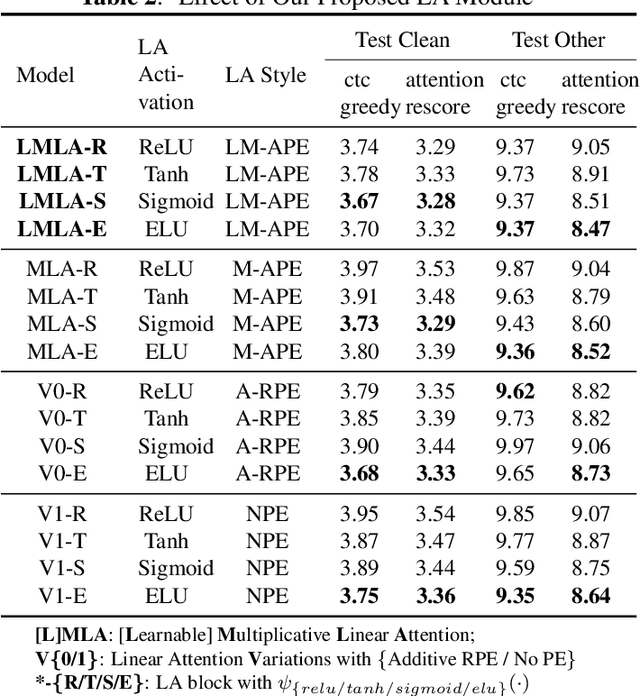
This paper proposes a Learnable Multiplicative absolute position Embedding based Conformer (LMEC). It contains a kernelized linear attention (LA) module called LMLA to solve the time-consuming problem for long sequence speech recognition as well as an alternative to the FFN structure. First, the ELU function is adopted as the kernel function of our proposed LA module. Second, we propose a novel Learnable Multiplicative Absolute Position Embedding (LM-APE) based re-weighting mechanism that can reduce the well-known quadratic temporal-space complexity of softmax self-attention. Third, we use Gated Linear Units (GLU) to substitute the Feed Forward Network (FFN) for better performance. Extensive experiments have been conducted on the public LibriSpeech datasets. Compared to the Conformer model with cosFormer style linear attention, our proposed method can achieve up to 0.63% word-error-rate improvement on test-other and improve the inference speed by up to 13% (left product) and 33% (right product) on the LA module.