 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
QuickVC: Many-to-any Voice Conversion Using Inverse Short-time Fourier Transform for Faster Conversion
Feb 17, 2023
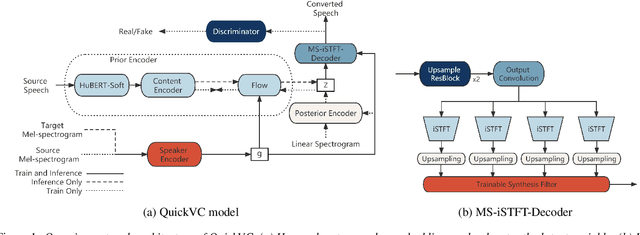
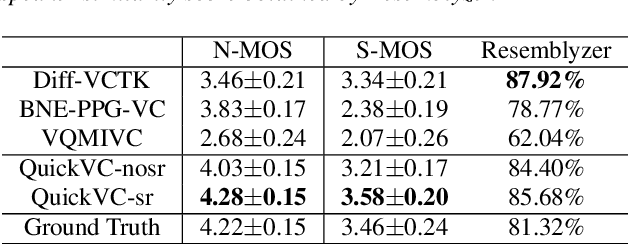

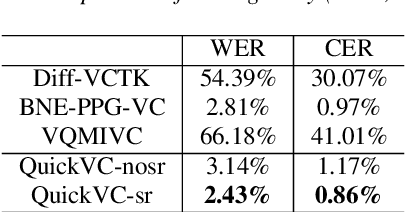
With the development of automatic speech recognition (ASR) and text-to-speech (TTS) technology, high-quality voice conversion (VC) can be achieved by extracting source content information and target speaker information to reconstruct waveforms. However, current methods still require improvement in terms of inference speed. In this study, we propose a lightweight VITS-based VC model that uses the HuBERT-Soft model to extract content information features without speaker information. Through subjective and objective experiments on synthesized speech, the proposed model demonstrates competitive results in terms of naturalness and similarity. Importantly, unlike the original VITS model, we use the inverse short-time Fourier transform (iSTFT) to replace the most computationally expensive part. Experimental results show that our model can generate samples at over 5000 kHz on the 3090 GPU and over 250 kHz on the i9-10900K CPU, achieving competitive speed for the same hardware configuration.
Dynamic Chuck Convolution For Unified Streaming And Non-streaming Conformer ASR
Apr 18, 2023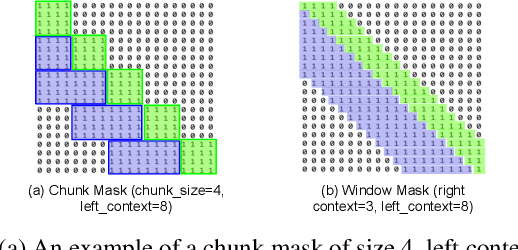
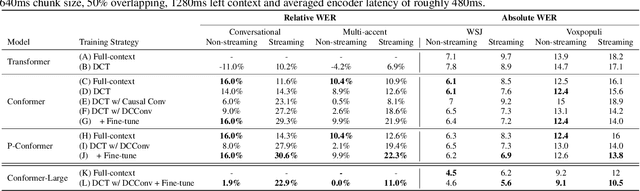
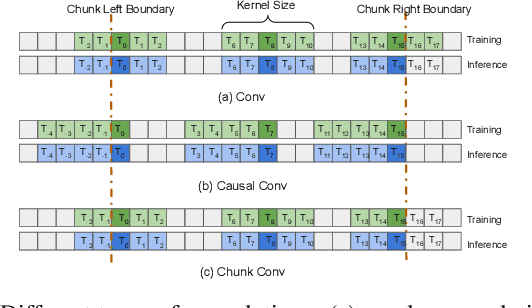
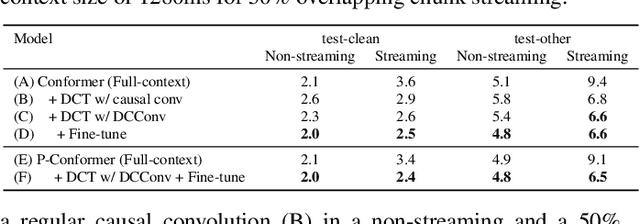
Recently, there has been an increasing interest in unifying streaming and non-streaming speech recognition models to reduce development, training and deployment cost. The best-known approaches rely on either window-based or dynamic chunk-based attention strategy and causal convolutions to minimize the degradation due to streaming. However, the performance gap still remains relatively large between non-streaming and a full-contextual model trained independently. To address this, we propose a dynamic chunk-based convolution replacing the causal convolution in a hybrid Connectionist Temporal Classification (CTC)-Attention Conformer architecture. Additionally, we demonstrate further improvements through initialization of weights from a full-contextual model and parallelization of the convolution and self-attention modules. We evaluate our models on the open-source Voxpopuli, LibriSpeech and in-house conversational datasets. Overall, our proposed model reduces the degradation of the streaming mode over the non-streaming full-contextual model from 41.7% and 45.7% to 16.7% and 26.2% on the LibriSpeech test-clean and test-other datasets respectively, while improving by a relative 15.5% WER over the previous state-of-the-art unified model.
Integrity and Junkiness Failure Handling for Embedding-based Retrieval: A Case Study in Social Network Search
Apr 18, 2023
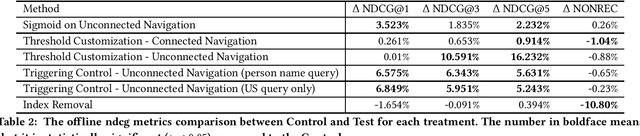

Embedding based retrieval has seen its usage in a variety of search applications like e-commerce, social networking search etc. While the approach has demonstrated its efficacy in tasks like semantic matching and contextual search, it is plagued by the problem of uncontrollable relevance. In this paper, we conduct an analysis of embedding-based retrieval launched in early 2021 on our social network search engine, and define two main categories of failures introduced by it, integrity and junkiness. The former refers to issues such as hate speech and offensive content that can severely harm user experience, while the latter includes irrelevant results like fuzzy text matching or language mismatches. Efficient methods during model inference are further proposed to resolve the issue, including indexing treatments and targeted user cohort treatments, etc. Though being simple, we show the methods have good offline NDCG and online A/B tests metrics gain in practice. We analyze the reasons for the improvements, pointing out that our methods are only preliminary attempts to this important but challenging problem. We put forward potential future directions to explore.
Deep Audio-Visual Singing Voice Transcription based on Self-Supervised Learning Models
Apr 24, 2023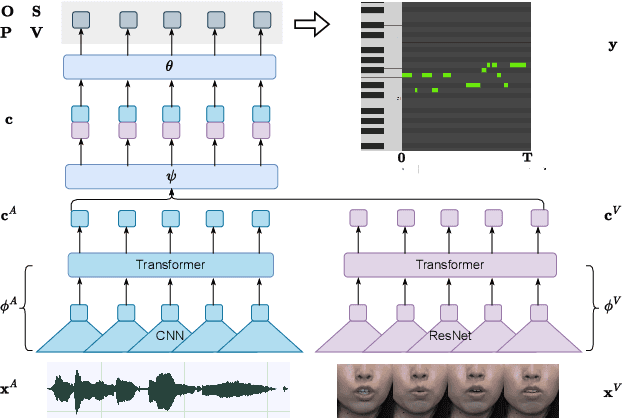
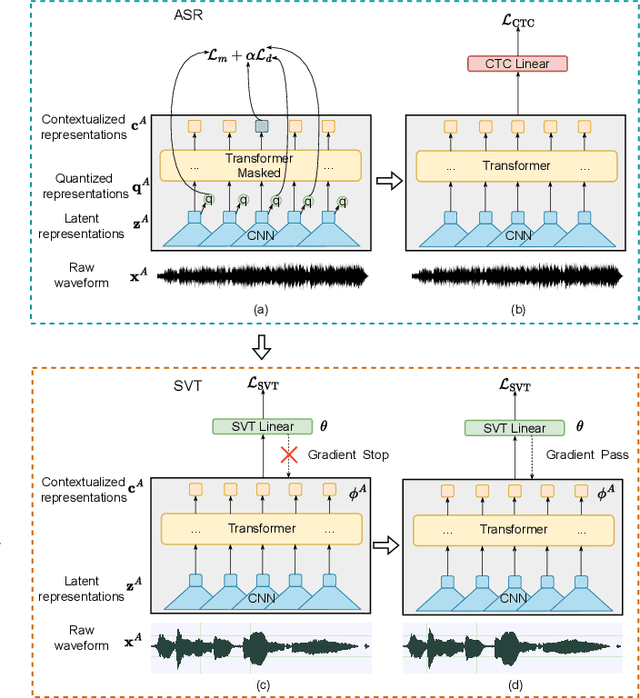
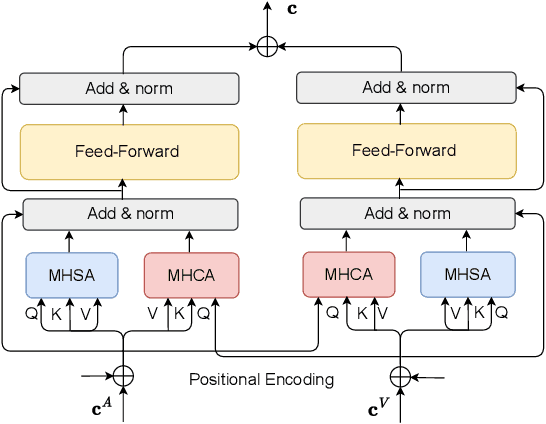
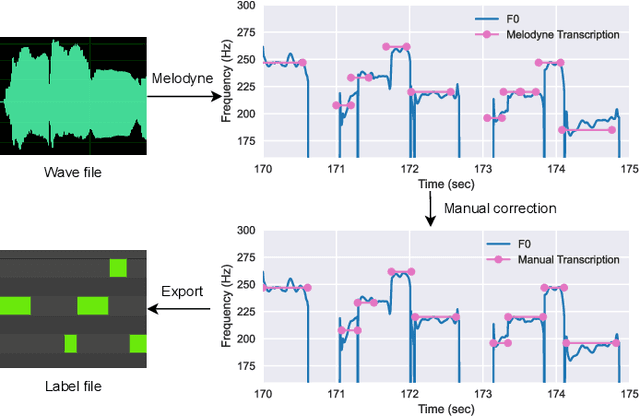
Singing voice transcription converts recorded singing audio to musical notation. Sound contamination (such as accompaniment) and lack of annotated data make singing voice transcription an extremely difficult task. We take two approaches to tackle the above challenges: 1) introducing multimodal learning for singing voice transcription together with a new multimodal singing dataset, N20EMv2, enhancing noise robustness by utilizing video information (lip movements to predict the onset/offset of notes), and 2) adapting self-supervised learning models from the speech domain to the singing voice transcription task, significantly reducing annotated data requirements while preserving pretrained features. We build a self-supervised learning based audio-only singing voice transcription system, which not only outperforms current state-of-the-art technologies as a strong baseline, but also generalizes well to out-of-domain singing data. We then develop a self-supervised learning based video-only singing voice transcription system that detects note onsets and offsets with an accuracy of about 80\%. Finally, based on the powerful acoustic and visual representations extracted by the above two systems as well as the feature fusion design, we create an audio-visual singing voice transcription system that improves the noise robustness significantly under different acoustic environments compared to the audio-only systems.
"It's Not Just Hate'': A Multi-Dimensional Perspective on Detecting Harmful Speech Online
Oct 28, 2022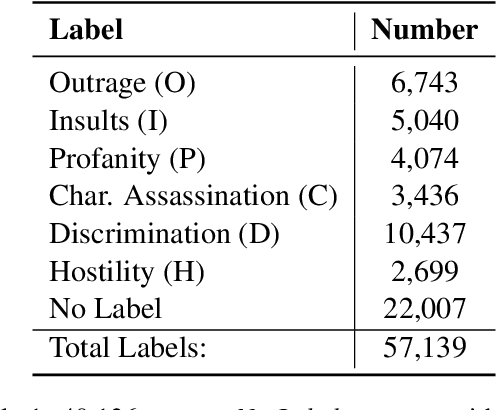
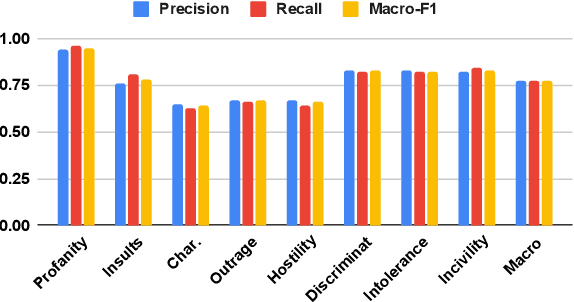

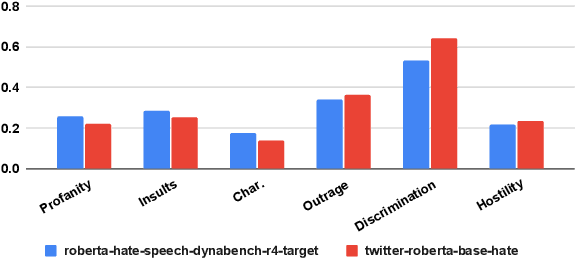
Well-annotated data is a prerequisite for good Natural Language Processing models. Too often, though, annotation decisions are governed by optimizing time or annotator agreement. We make a case for nuanced efforts in an interdisciplinary setting for annotating offensive online speech. Detecting offensive content is rapidly becoming one of the most important real-world NLP tasks. However, most datasets use a single binary label, e.g., for hate or incivility, even though each concept is multi-faceted. This modeling choice severely limits nuanced insights, but also performance. We show that a more fine-grained multi-label approach to predicting incivility and hateful or intolerant content addresses both conceptual and performance issues. We release a novel dataset of over 40,000 tweets about immigration from the US and UK, annotated with six labels for different aspects of incivility and intolerance. Our dataset not only allows for a more nuanced understanding of harmful speech online, models trained on it also outperform or match performance on benchmark datasets.
Cross-Attention is all you need: Real-Time Streaming Transformers for Personalised Speech Enhancement
Nov 08, 2022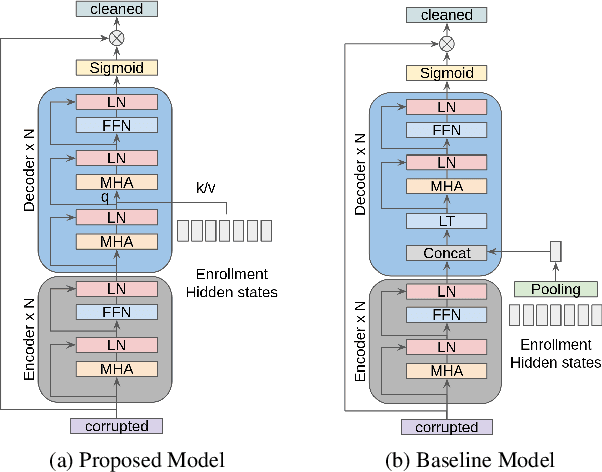
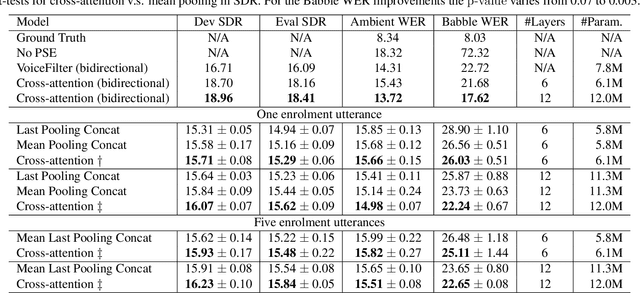
Personalised speech enhancement (PSE), which extracts only the speech of a target user and removes everything else from a recorded audio clip, can potentially improve users' experiences of audio AI modules deployed in the wild. To support a large variety of downstream audio tasks, such as real-time ASR and audio-call enhancement, a PSE solution should operate in a streaming mode, i.e., input audio cleaning should happen in real-time with a small latency and real-time factor. Personalisation is typically achieved by extracting a target speaker's voice profile from an enrolment audio, in the form of a static embedding vector, and then using it to condition the output of a PSE model. However, a fixed target speaker embedding may not be optimal under all conditions. In this work, we present a streaming Transformer-based PSE model and propose a novel cross-attention approach that gives adaptive target speaker representations. We present extensive experiments and show that our proposed cross-attention approach outperforms competitive baselines consistently, even when our model is only approximately half the size.
Automated speech- and text-based classification of neuropsychiatric conditions in a multidiagnostic setting
Jan 13, 2023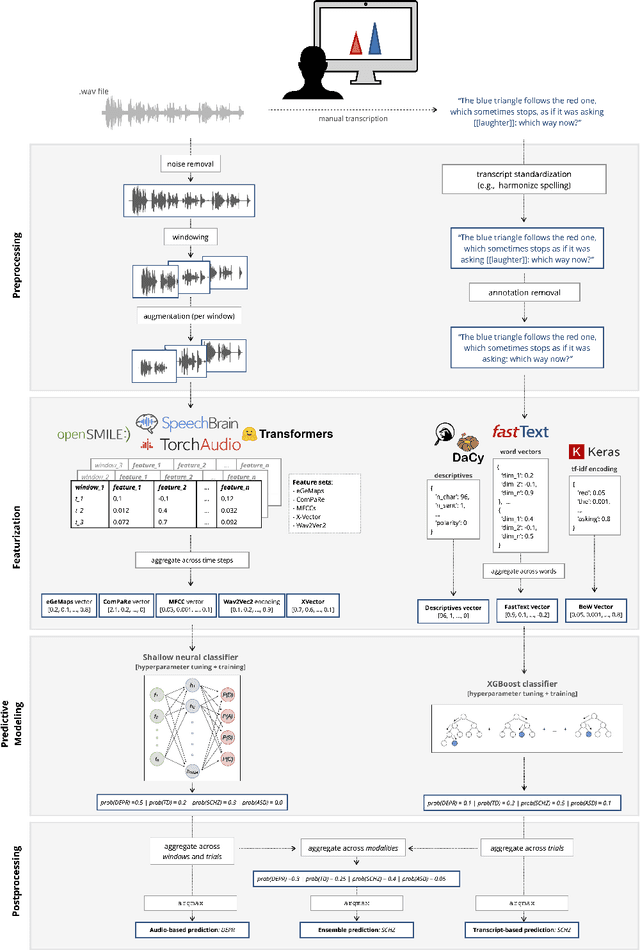
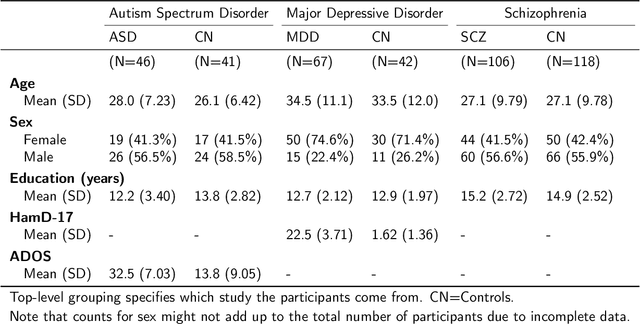
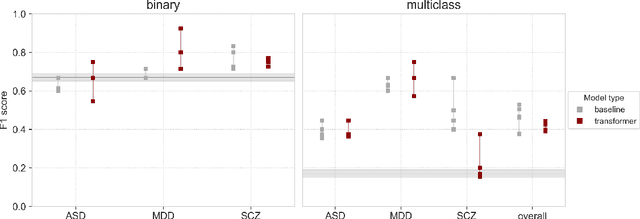
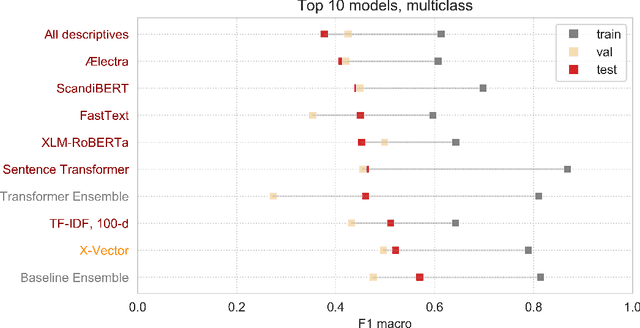
Speech patterns have been identified as potential diagnostic markers for neuropsychiatric conditions. However, most studies only compare a single clinical group to healthy controls, whereas clinical practice often requires differentiating between multiple potential diagnoses (multiclass settings). To address this, we assembled a dataset of repeated recordings from 420 participants (67 with major depressive disorder, 106 with schizophrenia and 46 with autism, as well as matched controls), and tested the performance of a range of conventional machine learning models and advanced Transformer models on both binary and multiclass classification, based on voice and text features. While binary models performed comparably to previous research (F1 scores between 0.54-0.75 for autism spectrum disorder, ASD; 0.67-0.92 for major depressive disorder, MDD; and 0.71-0.83 for schizophrenia); when differentiating between multiple diagnostic groups performance decreased markedly (F1 scores between 0.35-0.44 for ASD, 0.57-0.75 for MDD, 0.15-0.66 for schizophrenia, and 0.38-0.52 macro F1). Combining voice and text-based models yielded increased performance, suggesting that they capture complementary diagnostic information. Our results indicate that models trained on binary classification may learn to rely on markers of generic differences between clinical and non-clinical populations, or markers of clinical features that overlap across conditions, rather than identifying markers specific to individual conditions. We provide recommendations for future research in the field, suggesting increased focus on developing larger transdiagnostic datasets that include more fine-grained clinical features, and that can support the development of models that better capture the complexity of neuropsychiatric conditions and naturalistic diagnostic assessment.
Improved disentangled speech representations using contrastive learning in factorized hierarchical variational autoencoder
Nov 15, 2022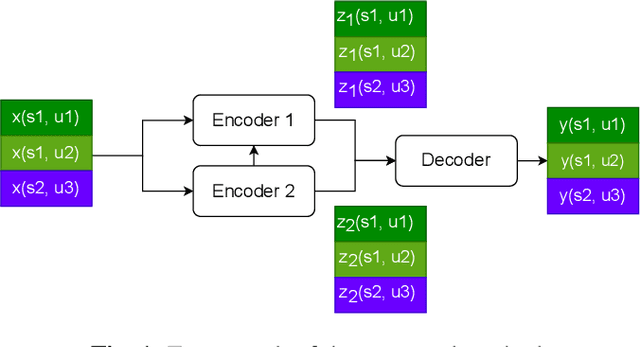
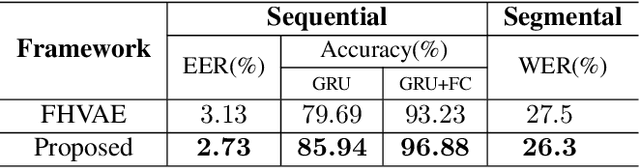
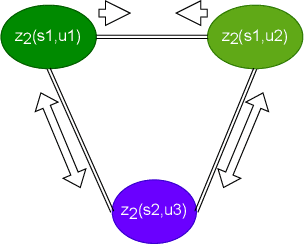
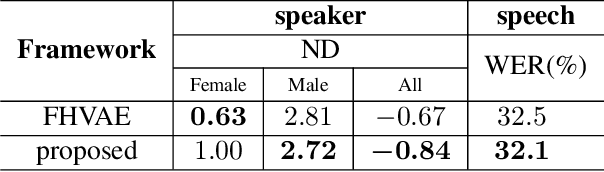
By utilizing the fact that speaker identity and content vary on different time scales, \acrlong{fhvae} (\acrshort{fhvae}) uses a sequential latent variable and a segmental latent variable to symbolize these two attributes. Disentanglement is carried out by assuming the latent variables representing speaker and content follow sequence-dependent and sequence-independent priors. For the sequence-dependent prior, \acrshort{fhvae} assumes a Gaussian distribution with an utterance-scale varying mean and a fixed small variance. The training process promotes sequential variables getting close to the mean of its prior with small variance. However, this constraint is relatively weak. Therefore, we introduce contrastive learning in the \acrshort{fhvae} framework. The proposed method aims to make the sequential variables clustering when representing the same speaker, while distancing themselves as far as possible from those of other speakers. The structure of the framework has not been changed in the proposed method but only the training process, thus no more cost is needed during test. Voice conversion has been chosen as the application in this paper. Latent variable evaluations include speakerincrease verification and identification for the sequential latent variable, and speech recognition for the segmental latent variable. Furthermore, assessments of voice conversion performance are on the grounds of speaker verification and speech recognition experiments. Experiment results show that the proposed method improves both sequential and segmental feature extraction compared with \acrshort{fhvae}, and moderately improved voice conversion performance.
Explanations for Automatic Speech Recognition
Feb 27, 2023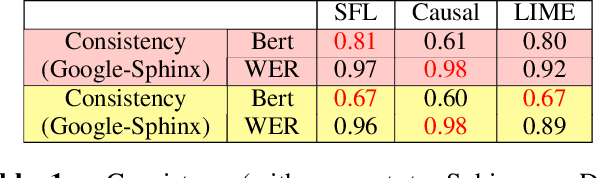
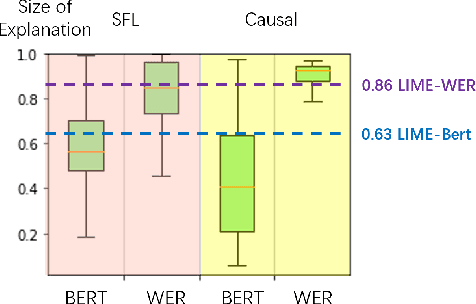
We address quality assessment for neural network based ASR by providing explanations that help increase our understanding of the system and ultimately help build trust in the system. Compared to simple classification labels, explaining transcriptions is more challenging as judging their correctness is not straightforward and transcriptions as a variable-length sequence is not handled by existing interpretable machine learning models. We provide an explanation for an ASR transcription as a subset of audio frames that is both a minimal and sufficient cause of the transcription. To do this, we adapt existing explainable AI (XAI) techniques from image classification-Statistical Fault Localisation(SFL) and Causal. Additionally, we use an adapted version of Local Interpretable Model-Agnostic Explanations (LIME) for ASR as a baseline in our experiments. We evaluate the quality of the explanations generated by the proposed techniques over three different ASR ,Google API, the baseline model of Sphinx, Deepspeech and 100 audio samples from the Commonvoice dataset.
Context-Aware Selective Label Smoothing for Calibrating Sequence Recognition Model
Mar 13, 2023
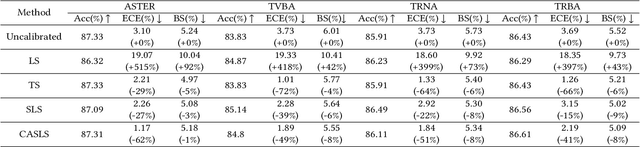
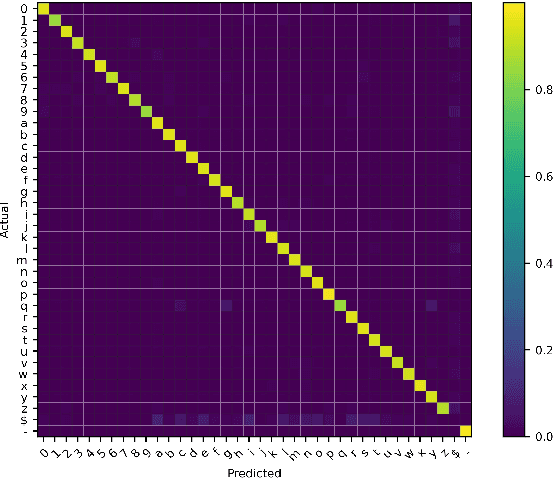
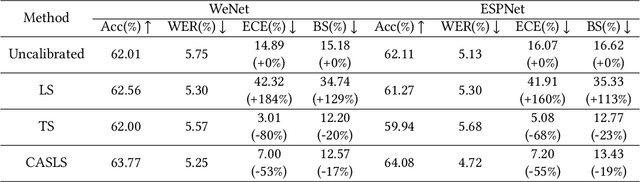
Despite the success of deep neural network (DNN) on sequential data (i.e., scene text and speech) recognition, it suffers from the over-confidence problem mainly due to overfitting in training with the cross-entropy loss, which may make the decision-making less reliable. Confidence calibration has been recently proposed as one effective solution to this problem. Nevertheless, the majority of existing confidence calibration methods aims at non-sequential data, which is limited if directly applied to sequential data since the intrinsic contextual dependency in sequences or the class-specific statistical prior is seldom exploited. To the end, we propose a Context-Aware Selective Label Smoothing (CASLS) method for calibrating sequential data. The proposed CASLS fully leverages the contextual dependency in sequences to construct confusion matrices of contextual prediction statistics over different classes. Class-specific error rates are then used to adjust the weights of smoothing strength in order to achieve adaptive calibration. Experimental results on sequence recognition tasks, including scene text recognition and speech recognition, demonstrate that our method can achieve the state-of-the-art performance.