 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Speaker and Language Change Detection using Wav2vec2 and Whisper
Feb 18, 2023

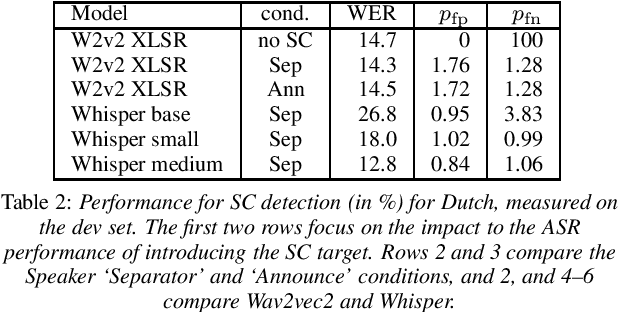
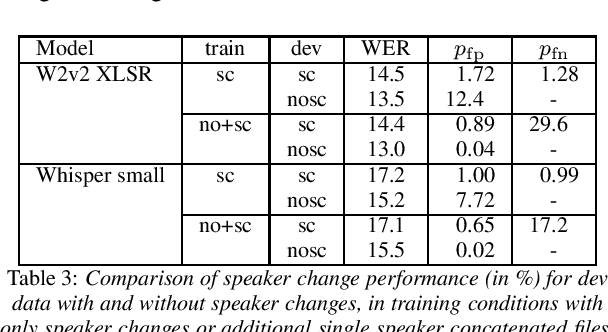
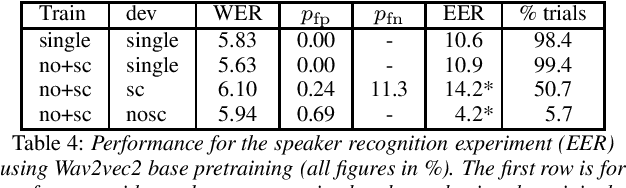
We investigate recent transformer networks pre-trained for automatic speech recognition for their ability to detect speaker and language changes in speech. We do this by simply adding speaker (change) or language targets to the labels. For Wav2vec2 pre-trained networks, we also investigate if the representation for the speaker change symbol can be conditioned to capture speaker identity characteristics. Using a number of constructed data sets we show that these capabilities are definitely there, with speaker recognition equal error rates of the order of 10% and language detection error rates of a few percent. We will publish the code for reproducibility.
Performance Disparities Between Accents in Automatic Speech Recognition
Aug 01, 2022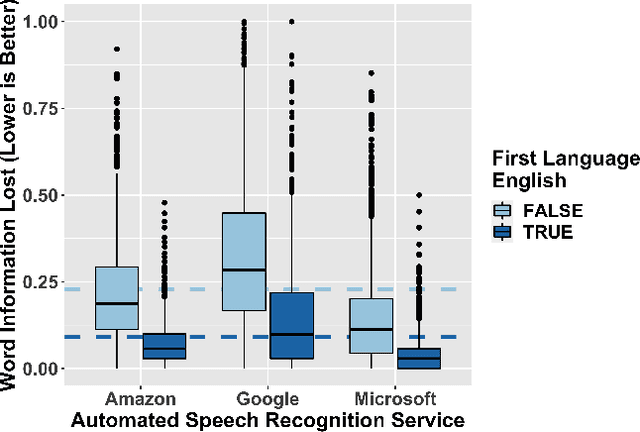
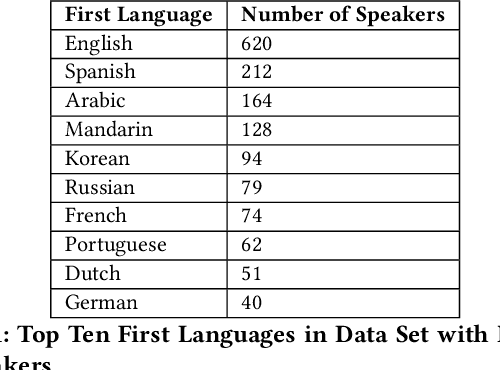
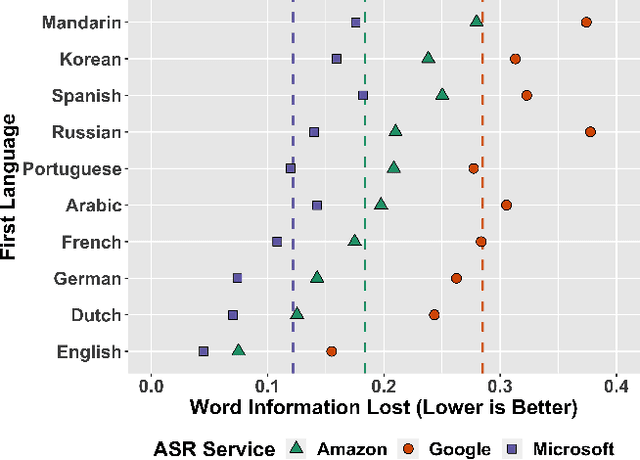
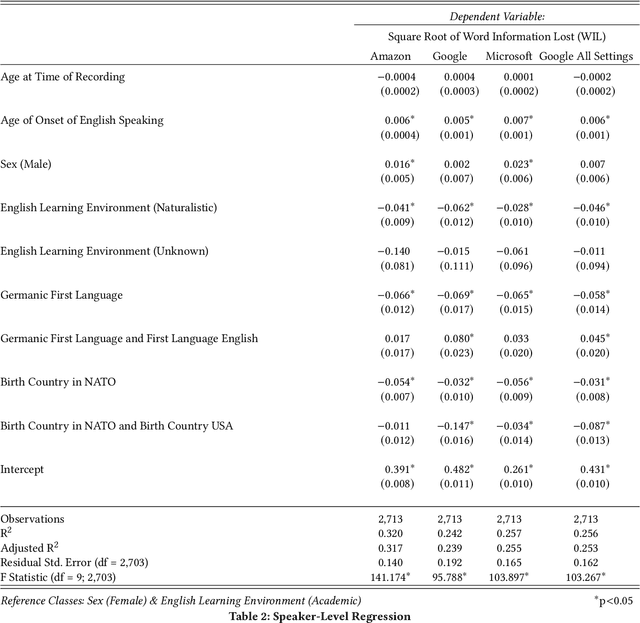
Automatic speech recognition (ASR) services are ubiquitous, transforming speech into text for systems like Amazon's Alexa, Google's Assistant, and Microsoft's Cortana. However, researchers have identified biases in ASR performance between particular English language accents by racial group and by nationality. In this paper, we expand this discussion both qualitatively by relating it to historical precedent and quantitatively through a large-scale audit. Standardization of language and the use of language to maintain global and political power have played an important role in history, which we explain to show the parallels in the ways in which ASR services act on English language speakers today. Then, using a large and global data set of speech from The Speech Accent Archive which includes over 2,700 speakers of English born in 171 different countries, we perform an international audit of some of the most popular English ASR services. We show that performance disparities exist as a function of whether or not a speaker's first language is English and, even when controlling for multiple linguistic covariates, that these disparities have a statistically significant relationship to the political alignment of the speaker's birth country with respect to the United States' geopolitical power.
A Phoneme-Informed Neural Network Model for Note-Level Singing Transcription
Apr 12, 2023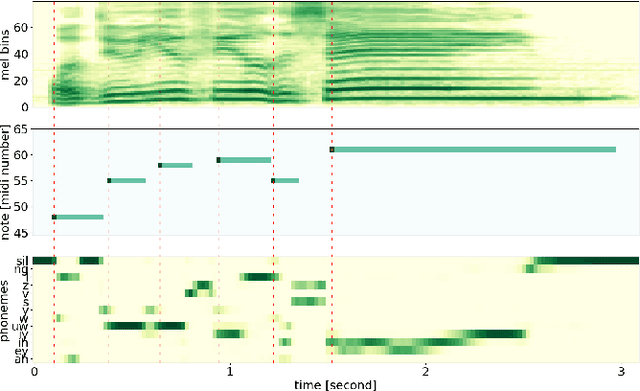
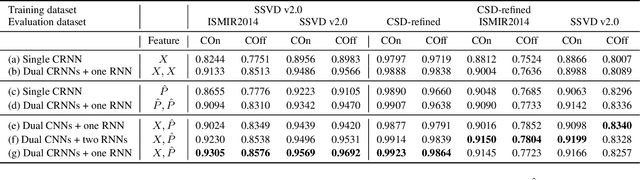
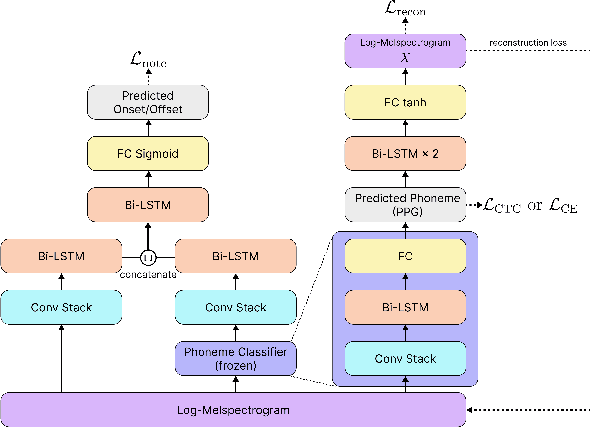

Note-level automatic music transcription is one of the most representative music information retrieval (MIR) tasks and has been studied for various instruments to understand music. However, due to the lack of high-quality labeled data, transcription of many instruments is still a challenging task. In particular, in the case of singing, it is difficult to find accurate notes due to its expressiveness in pitch, timbre, and dynamics. In this paper, we propose a method of finding note onsets of singing voice more accurately by leveraging the linguistic characteristics of singing, which are not seen in other instruments. The proposed model uses mel-scaled spectrogram and phonetic posteriorgram (PPG), a frame-wise likelihood of phoneme, as an input of the onset detection network while PPG is generated by the pre-trained network with singing and speech data. To verify how linguistic features affect onset detection, we compare the evaluation results through the dataset with different languages and divide onset types for detailed analysis. Our approach substantially improves the performance of singing transcription and therefore emphasizes the importance of linguistic features in singing analysis.
Controllable and Lossless Non-Autoregressive End-to-End Text-to-Speech
Jul 13, 2022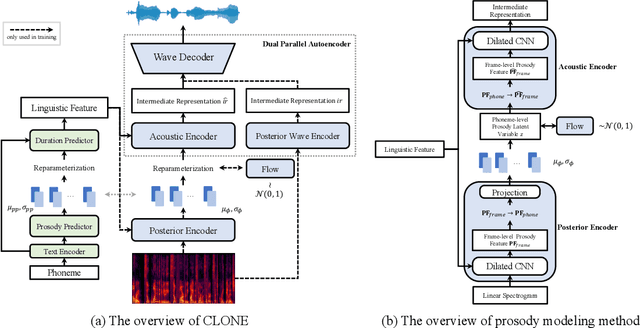
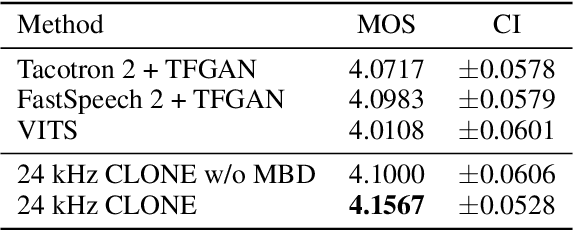
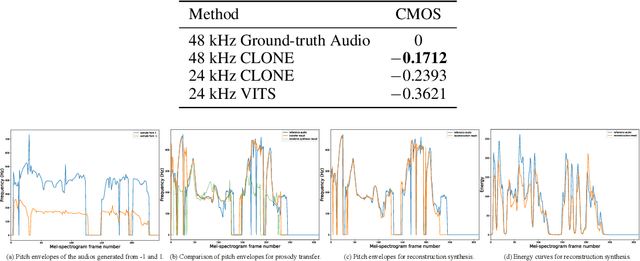

Some recent studies have demonstrated the feasibility of single-stage neural text-to-speech, which does not need to generate mel-spectrograms but generates the raw waveforms directly from the text. Single-stage text-to-speech often faces two problems: a) the one-to-many mapping problem due to multiple speech variations and b) insufficiency of high frequency reconstruction due to the lack of supervision of ground-truth acoustic features during training. To solve the a) problem and generate more expressive speech, we propose a novel phoneme-level prosody modeling method based on a variational autoencoder with normalizing flows to model underlying prosodic information in speech. We also use the prosody predictor to support end-to-end expressive speech synthesis. Furthermore, we propose the dual parallel autoencoder to introduce supervision of the ground-truth acoustic features during training to solve the b) problem enabling our model to generate high-quality speech. We compare the synthesis quality with state-of-the-art text-to-speech systems on an internal expressive English dataset. Both qualitative and quantitative evaluations demonstrate the superiority and robustness of our method for lossless speech generation while also showing a strong capability in prosody modeling.
Non-Asymptotic Pointwise and Worst-Case Bounds for Classical Spectrum Estimators
Mar 21, 2023Spectrum estimation is a fundamental methodology in the analysis of time-series data, with applications including medicine, speech analysis, and control design. The asymptotic theory of spectrum estimation is well-understood, but the theory is limited when the number of samples is fixed and finite. This paper gives non-asymptotic error bounds for a broad class of spectral estimators, both pointwise (at specific frequencies) and in the worst case over all frequencies. The general method is used to derive error bounds for the classical Blackman-Tukey, Bartlett, and Welch estimators.
Speech Enhancement and Dereverberation with Diffusion-based Generative Models
Aug 11, 2022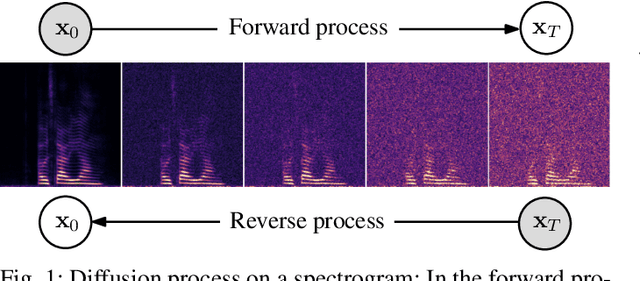
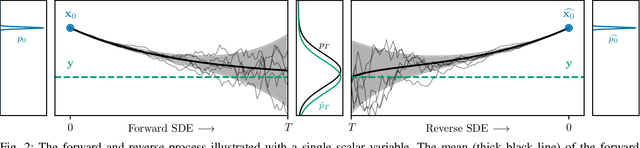
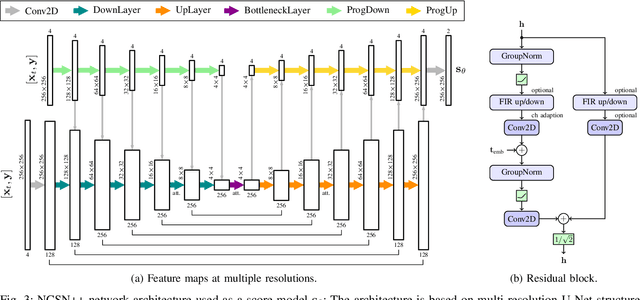
Recently, diffusion-based generative models have been introduced to the task of speech enhancement. The corruption of clean speech is modeled as a fixed forward process in which increasing amounts of noise are gradually added. By learning to reverse this process in an iterative fashion conditioned on the noisy input, clean speech is generated. We build upon our previous work and derive the training task within the formalism of stochastic differential equations. We present a detailed theoretical review of the underlying score matching objective and explore different sampler configurations for solving the reverse process at test time. By using a sophisticated network architecture from natural image generation literature, we significantly improve performance compared to our previous publication. We also show that we can compete with recent discriminative models and achieve better generalization when evaluating on a different corpus than used for training. We complement the evaluation results with a subjective listening test, in which our proposed method is rated best. Furthermore, we show that the proposed method achieves remarkable state-of-the-art performance in single-channel speech dereverberation. Our code and audio examples are available online, see https://uhh.de/inf-sp-sgmse
Monotonic segmental attention for automatic speech recognition
Oct 26, 2022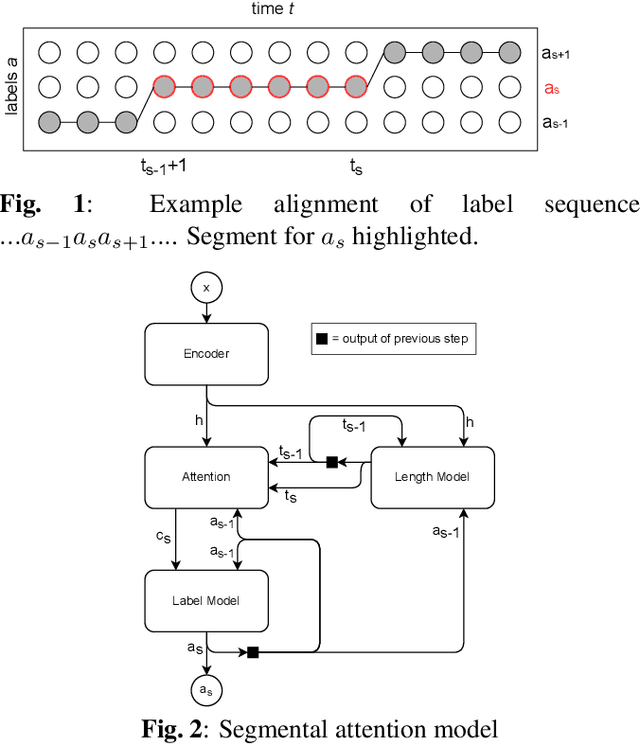
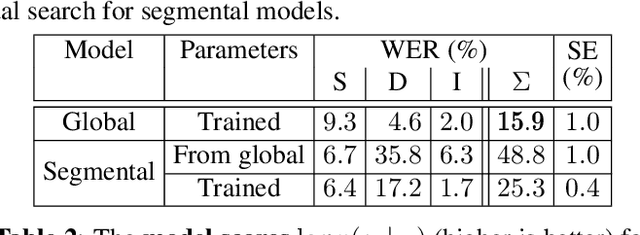
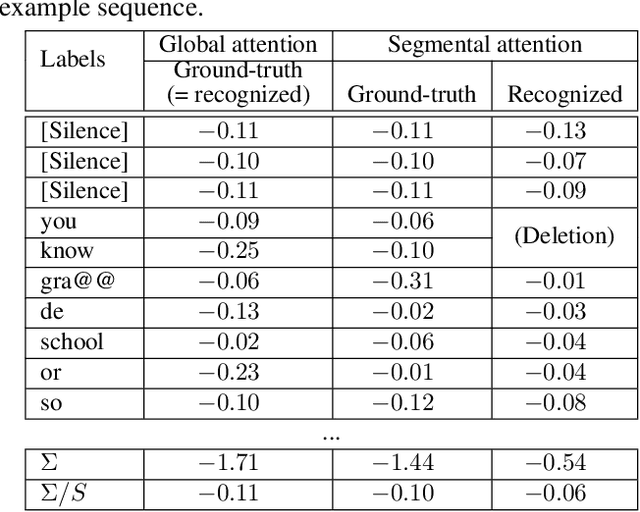
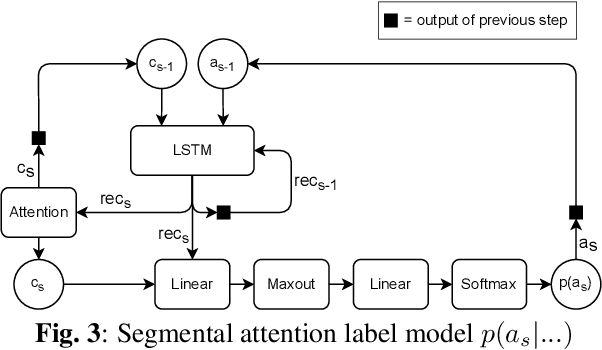
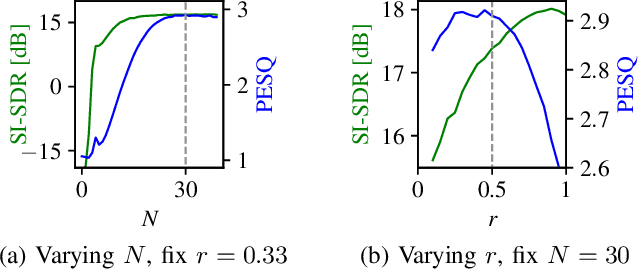
We introduce a novel segmental-attention model for automatic speech recognition. We restrict the decoder attention to segments to avoid quadratic runtime of global attention, better generalize to long sequences, and eventually enable streaming. We directly compare global-attention and different segmental-attention modeling variants. We develop and compare two separate time-synchronous decoders, one specifically taking the segmental nature into account, yielding further improvements. Using time-synchronous decoding for segmental models is novel and a step towards streaming applications. Our experiments show the importance of a length model to predict the segment boundaries. The final best segmental-attention model using segmental decoding performs better than global-attention, in contrast to other monotonic attention approaches in the literature. Further, we observe that the segmental model generalizes much better to long sequences of up to several minutes.
T5 for Hate Speech, Augmented Data and Ensemble
Oct 11, 2022
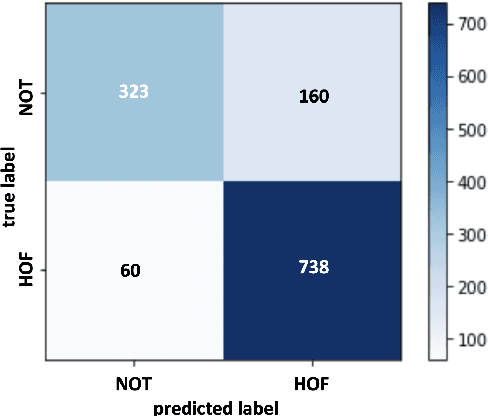
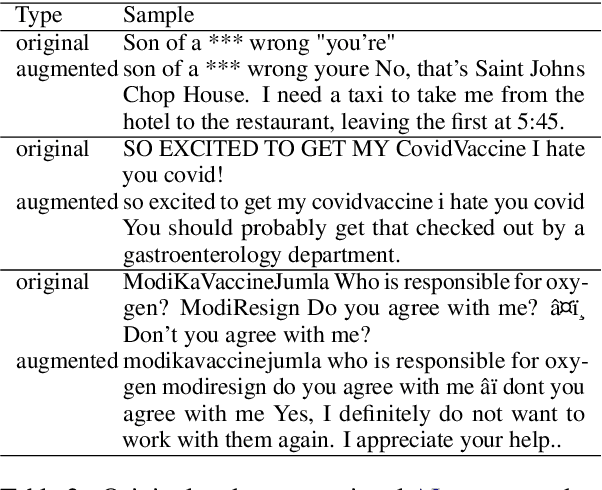
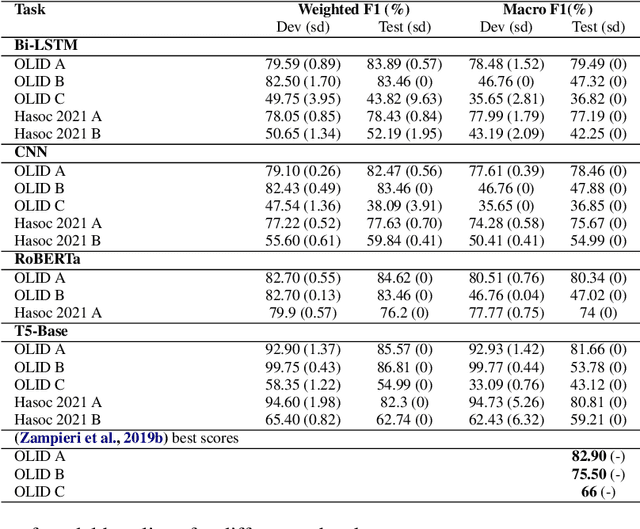
We conduct relatively extensive investigations of automatic hate speech (HS) detection using different state-of-the-art (SoTA) baselines over 11 subtasks of 6 different datasets. Our motivation is to determine which of the recent SoTA models is best for automatic hate speech detection and what advantage methods like data augmentation and ensemble may have on the best model, if any. We carry out 6 cross-task investigations. We achieve new SoTA on two subtasks - macro F1 scores of 91.73% and 53.21% for subtasks A and B of the HASOC 2020 dataset, where previous SoTA are 51.52% and 26.52%, respectively. We achieve near-SoTA on two others - macro F1 scores of 81.66% for subtask A of the OLID 2019 dataset and 82.54% for subtask A of the HASOC 2021 dataset, where SoTA are 82.9% and 83.05%, respectively. We perform error analysis and use two explainable artificial intelligence (XAI) algorithms (IG and SHAP) to reveal how two of the models (Bi-LSTM and T5) make the predictions they do by using examples. Other contributions of this work are 1) the introduction of a simple, novel mechanism for correcting out-of-class (OOC) predictions in T5, 2) a detailed description of the data augmentation methods, 3) the revelation of the poor data annotations in the HASOC 2021 dataset by using several examples and XAI (buttressing the need for better quality control), and 4) the public release of our model checkpoints and codes to foster transparency.
Differentiate ChatGPT-generated and Human-written Medical Texts
Apr 23, 2023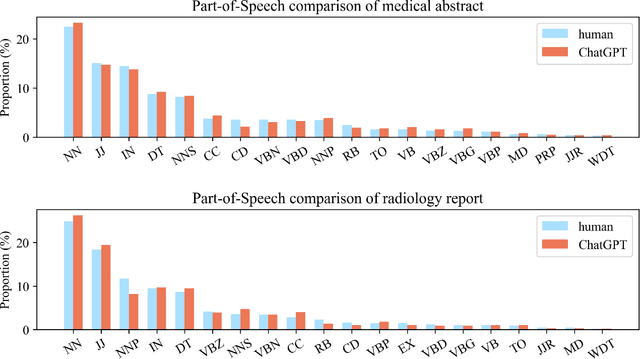

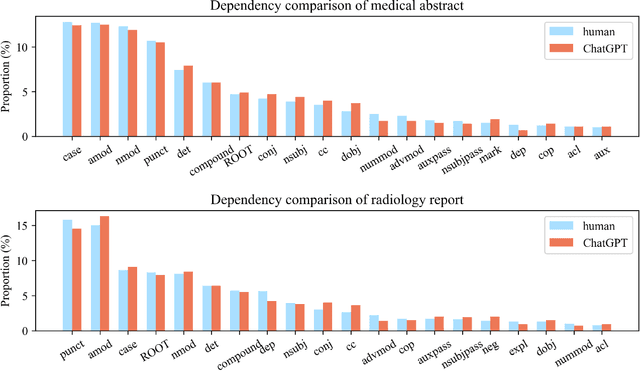
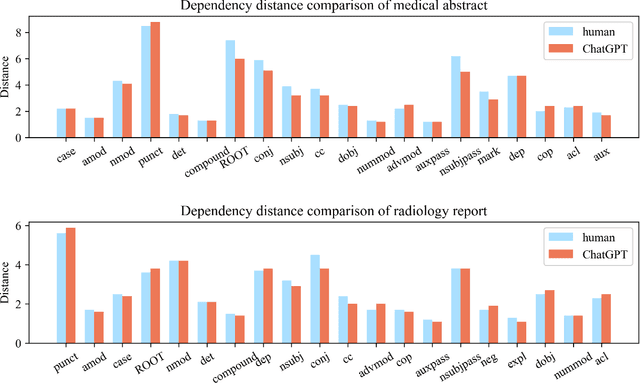
Background: Large language models such as ChatGPT are capable of generating grammatically perfect and human-like text content, and a large number of ChatGPT-generated texts have appeared on the Internet. However, medical texts such as clinical notes and diagnoses require rigorous validation, and erroneous medical content generated by ChatGPT could potentially lead to disinformation that poses significant harm to healthcare and the general public. Objective: This research is among the first studies on responsible and ethical AIGC (Artificial Intelligence Generated Content) in medicine. We focus on analyzing the differences between medical texts written by human experts and generated by ChatGPT, and designing machine learning workflows to effectively detect and differentiate medical texts generated by ChatGPT. Methods: We first construct a suite of datasets containing medical texts written by human experts and generated by ChatGPT. In the next step, we analyze the linguistic features of these two types of content and uncover differences in vocabulary, part-of-speech, dependency, sentiment, perplexity, etc. Finally, we design and implement machine learning methods to detect medical text generated by ChatGPT. Results: Medical texts written by humans are more concrete, more diverse, and typically contain more useful information, while medical texts generated by ChatGPT pay more attention to fluency and logic, and usually express general terminologies rather than effective information specific to the context of the problem. A BERT-based model can effectively detect medical texts generated by ChatGPT, and the F1 exceeds 95%.
Improving Multimodal Speech Recognition by Data Augmentation and Speech Representations
Apr 27, 2022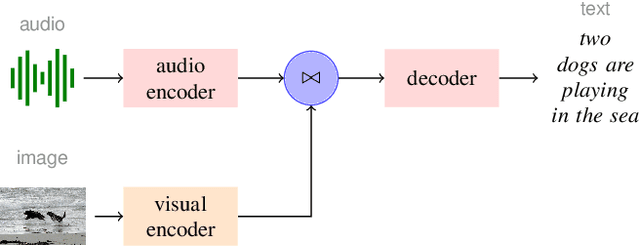
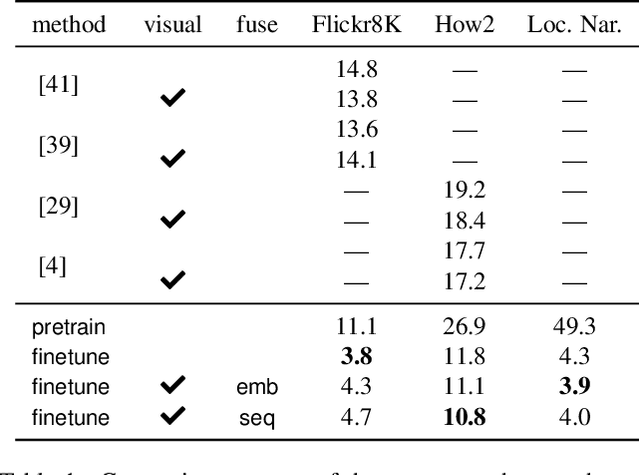
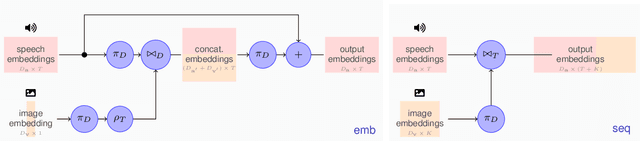
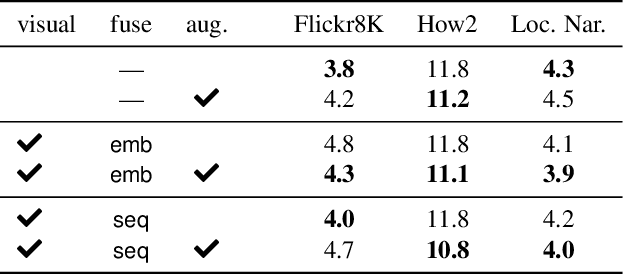
Multimodal speech recognition aims to improve the performance of automatic speech recognition (ASR) systems by leveraging additional visual information that is usually associated to the audio input. While previous approaches make crucial use of strong visual representations, e.g. by finetuning pretrained image recognition networks, significantly less attention has been paid to its counterpart: the speech component. In this work, we investigate ways of improving the base speech recognition system by following similar techniques to the ones used for the visual encoder, namely, transferring representations and data augmentation. First, we show that starting from a pretrained ASR significantly improves the state-of-the-art performance; remarkably, even when building upon a strong unimodal system, we still find gains by including the visual modality. Second, we employ speech data augmentation techniques to encourage the multimodal system to attend to the visual stimuli. This technique replaces previously used word masking and comes with the benefits of being conceptually simpler and yielding consistent improvements in the multimodal setting. We provide empirical results on three multimodal datasets, including the newly introduced Localized Narratives.