 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Unsupervised Text-to-Speech Synthesis by Unsupervised Automatic Speech Recognition
Mar 29, 2022
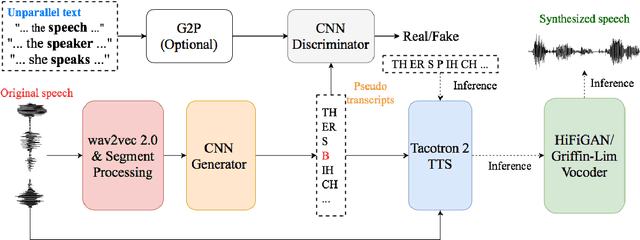

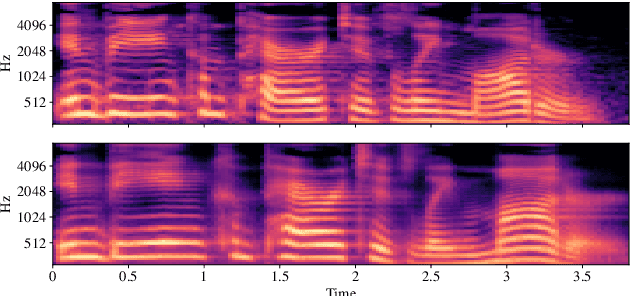
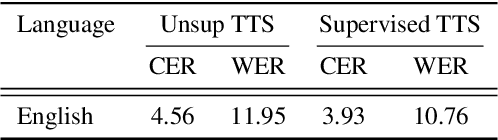
An unsupervised text-to-speech synthesis (TTS) system learns to generate the speech waveform corresponding to any written sentence in a language by observing: 1) a collection of untranscribed speech waveforms in that language; 2) a collection of texts written in that language without access to any transcribed speech. Developing such a system can significantly improve the availability of speech technology to languages without a large amount of parallel speech and text data. This paper proposes an unsupervised TTS system by leveraging recent advances in unsupervised automatic speech recognition (ASR). Our unsupervised system can achieve comparable performance to the supervised system in seven languages with about 10-20 hours of speech each. A careful study on the effect of text units and vocoders has also been conducted to better understand what factors may affect unsupervised TTS performance. The samples generated by our models can be found at https://cactuswiththoughts.github.io/UnsupTTS-Demo.
Automatic Speech recognition for Speech Assessment of Preschool Children
Mar 24, 2022

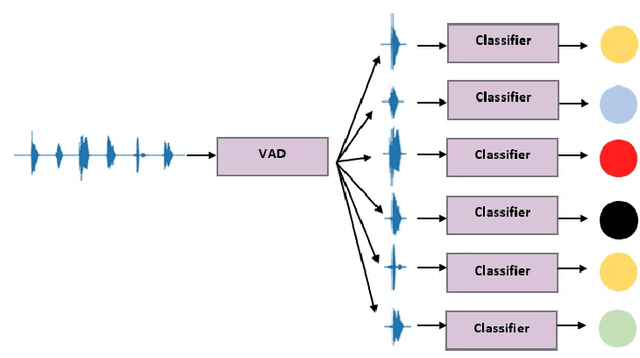
The acoustic and linguistic features of preschool speech are investigated in this study to design an automated speech recognition (ASR) system. Acoustic fluctuation has been highlighted as a significant barrier to developing high-performance ASR applications for youngsters. Because of the epidemic, preschool speech assessment should be conducted online. Accordingly, there is a need for an automatic speech recognition system. We were confronted with new challenges in our cognitive system, including converting meaningless words from speech to text and recognizing word sequence. After testing and experimenting with several models we obtained a 3.1\% phoneme error rate in Persian. Wav2Vec 2.0 is a paradigm that could be used to build a robust end-to-end speech recognition system.
Modeling Speaker-Listener Interaction for Backchannel Prediction
Apr 10, 2023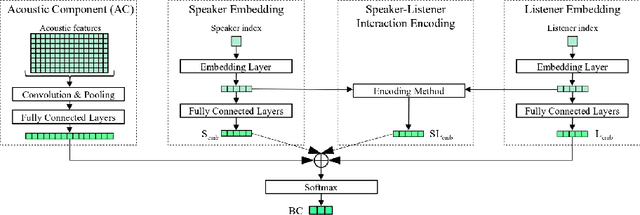
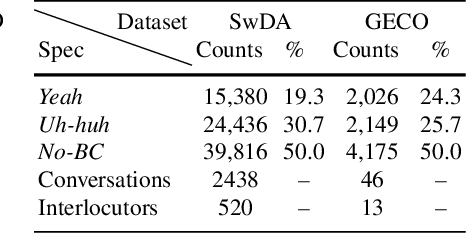
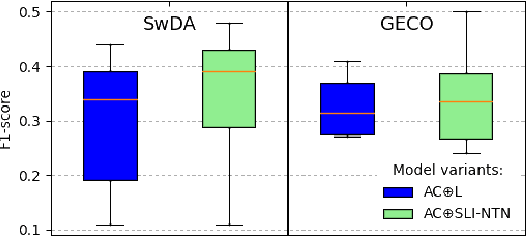
We present our latest findings on backchannel modeling novelly motivated by the canonical use of the minimal responses Yeah and Uh-huh in English and their correspondent tokens in German, and the effect of encoding the speaker-listener interaction. Backchanneling theories emphasize the active and continuous role of the listener in the course of the conversation, their effects on the speaker's subsequent talk, and the consequent dynamic speaker-listener interaction. Therefore, we propose a neural-based acoustic backchannel classifier on minimal responses by processing acoustic features from the speaker speech, capturing and imitating listeners' backchanneling behavior, and encoding speaker-listener interaction. Our experimental results on the Switchboard and GECO datasets reveal that in almost all tested scenarios the speaker or listener behavior embeddings help the model make more accurate backchannel predictions. More importantly, a proper interaction encoding strategy, i.e., combining the speaker and listener embeddings, leads to the best performance on both datasets in terms of F1-score.
LMEC: Learnable Multiplicative Absolute Position Embedding Based Conformer for Speech Recognition
Dec 05, 2022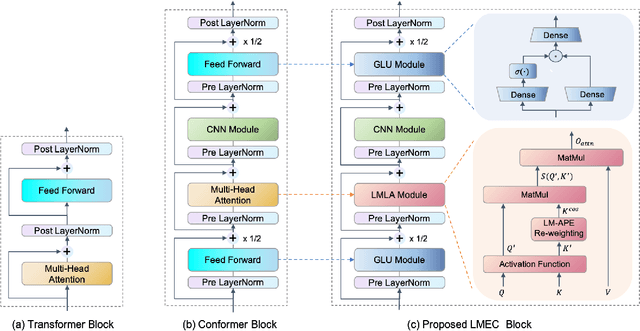
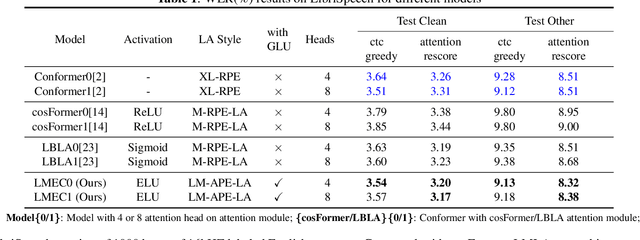
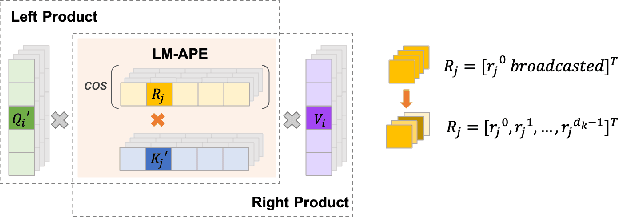
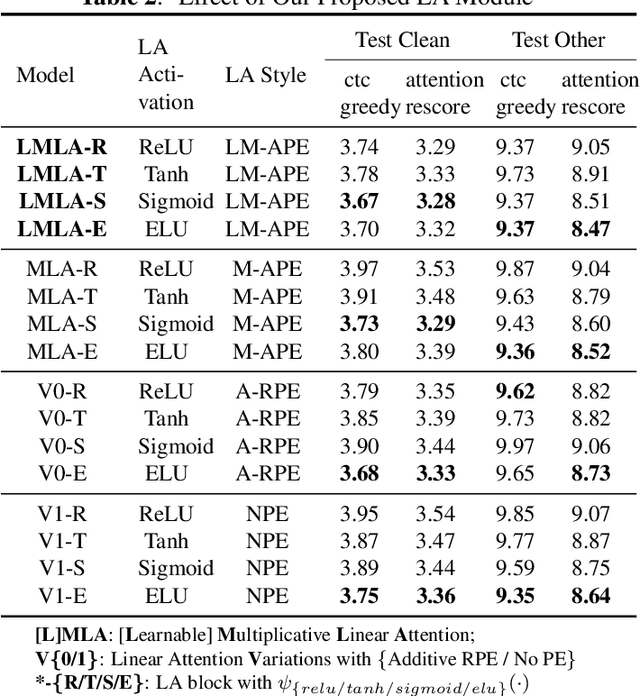
This paper proposes a Learnable Multiplicative absolute position Embedding based Conformer (LMEC). It contains a kernelized linear attention (LA) module called LMLA to solve the time-consuming problem for long sequence speech recognition as well as an alternative to the FFN structure. First, the ELU function is adopted as the kernel function of our proposed LA module. Second, we propose a novel Learnable Multiplicative Absolute Position Embedding (LM-APE) based re-weighting mechanism that can reduce the well-known quadratic temporal-space complexity of softmax self-attention. Third, we use Gated Linear Units (GLU) to substitute the Feed Forward Network (FFN) for better performance. Extensive experiments have been conducted on the public LibriSpeech datasets. Compared to the Conformer model with cosFormer style linear attention, our proposed method can achieve up to 0.63% word-error-rate improvement on test-other and improve the inference speed by up to 13% (left product) and 33% (right product) on the LA module.
Unifying the Discrete and Continuous Emotion labels for Speech Emotion Recognition
Oct 29, 2022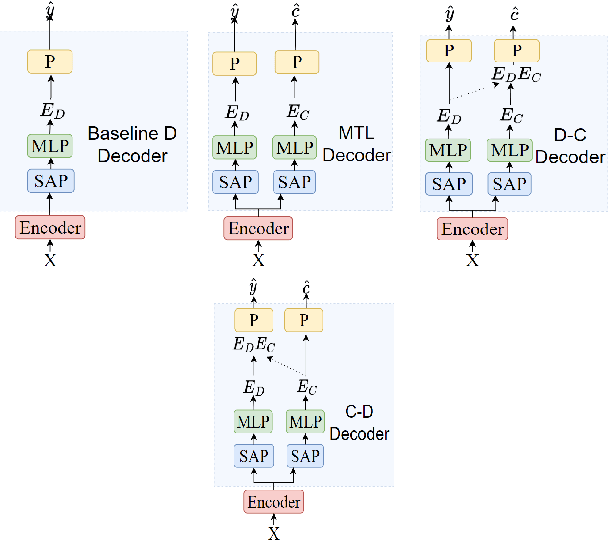
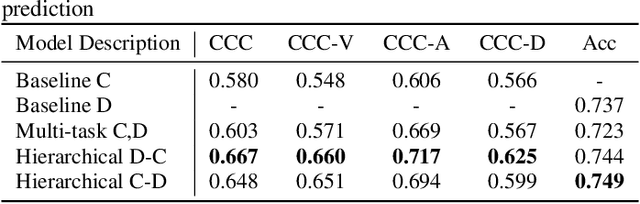
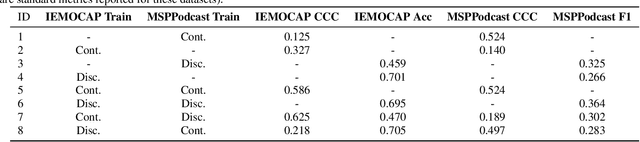
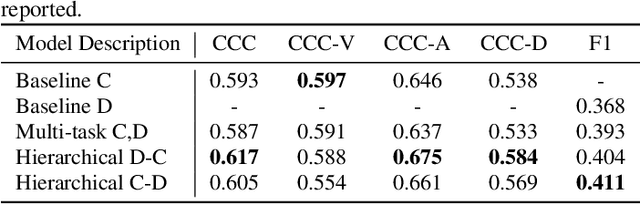
Traditionally, in paralinguistic analysis for emotion detection from speech, emotions have been identified with discrete or dimensional (continuous-valued) labels. Accordingly, models that have been proposed for emotion detection use one or the other of these label types. However, psychologists like Russell and Plutchik have proposed theories and models that unite these views, maintaining that these representations have shared and complementary information. This paper is an attempt to validate these viewpoints computationally. To this end, we propose a model to jointly predict continuous and discrete emotional attributes and show how the relationship between these can be utilized to improve the robustness and performance of emotion recognition tasks. Our approach comprises multi-task and hierarchical multi-task learning frameworks that jointly model the relationships between continuous-valued and discrete emotion labels. Experimental results on two widely used datasets (IEMOCAP and MSPPodcast) for speech-based emotion recognition show that our model results in statistically significant improvements in performance over strong baselines with non-unified approaches. We also demonstrate that using one type of label (discrete or continuous-valued) for training improves recognition performance in tasks that use the other type of label. Experimental results and reasoning for this approach (called the mismatched training approach) are also presented.
Conversion of Acoustic Signal (Speech) Into Text By Digital Filter using Natural Language Processing
Sep 09, 2022
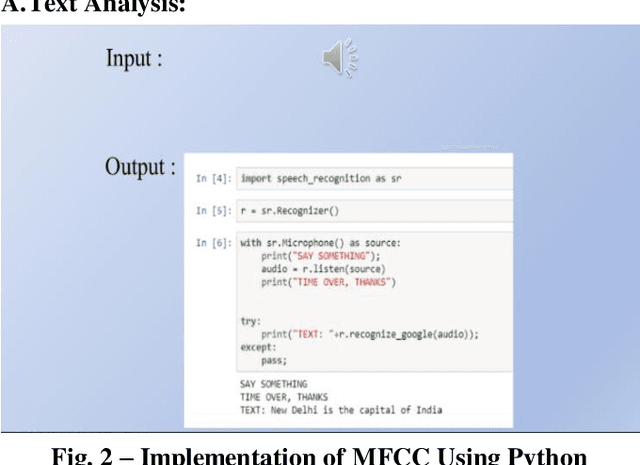
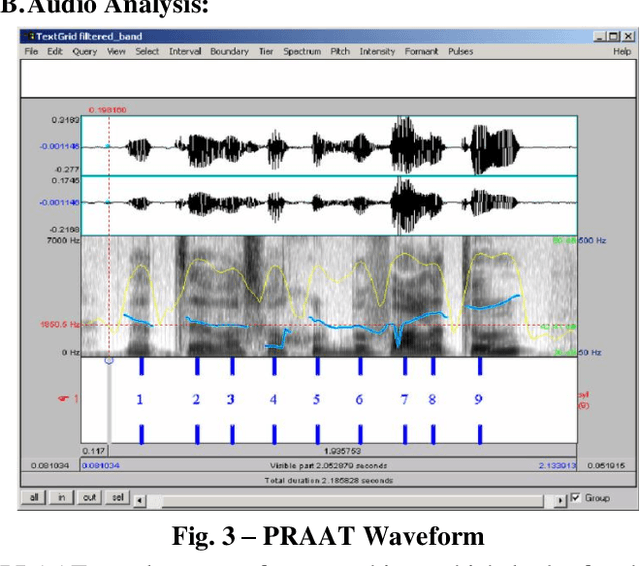
One of the most crucial aspects of communication in daily life is speech recognition. Speech recognition that is based on natural language processing is one of the essential elements in the conversion of one system to another. In this paper, we created an interface that transforms speech and other auditory inputs into text using a digital filter. Contrary to the many methods for this conversion, it is also possible for linguistic faults to appear occasionally, gender recognition, speech recognition that is unsuccessful (cannot recognize voice), and gender recognition to fail. Since technical problems are involved, we developed a program that acts as a mediator to prevent initiating software issues in order to eliminate even this little deviation. Its planned MFCC and HMM are in sync with its AI system. As a result, technical errors have been avoided.
Self-Supervised Speech Representations Preserve Speech Characteristics while Anonymizing Voices
Apr 04, 2022
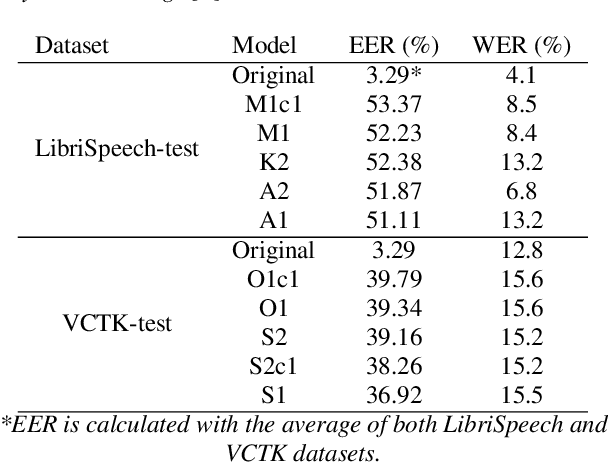

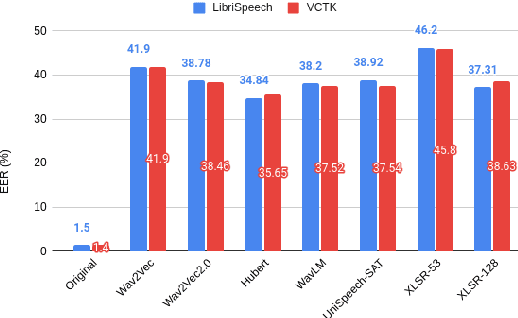
Collecting speech data is an important step in training speech recognition systems and other speech-based machine learning models. However, the issue of privacy protection is an increasing concern that must be addressed. The current study investigates the use of voice conversion as a method for anonymizing voices. In particular, we train several voice conversion models using self-supervised speech representations including Wav2Vec2.0, Hubert and UniSpeech. Converted voices retain a low word error rate within 1% of the original voice. Equal error rate increases from 1.52% to 46.24% on the LibriSpeech test set and from 3.75% to 45.84% on speakers from the VCTK corpus which signifies degraded performance on speaker verification. Lastly, we conduct experiments on dysarthric speech data to show that speech features relevant to articulation, prosody, phonation and phonology can be extracted from anonymized voices for discriminating between healthy and pathological speech.
GeneFace++: Generalized and Stable Real-Time Audio-Driven 3D Talking Face Generation
May 01, 2023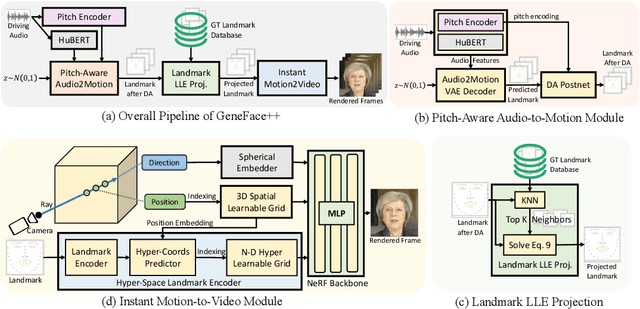
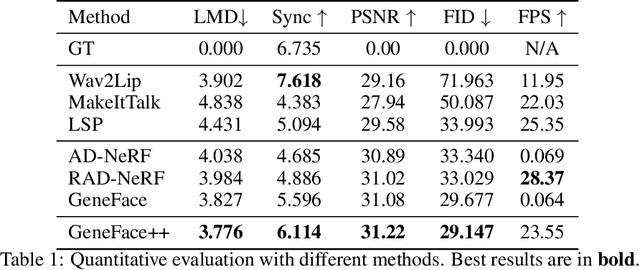
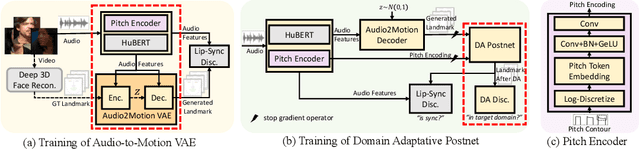

Generating talking person portraits with arbitrary speech audio is a crucial problem in the field of digital human and metaverse. A modern talking face generation method is expected to achieve the goals of generalized audio-lip synchronization, good video quality, and high system efficiency. Recently, neural radiance field (NeRF) has become a popular rendering technique in this field since it could achieve high-fidelity and 3D-consistent talking face generation with a few-minute-long training video. However, there still exist several challenges for NeRF-based methods: 1) as for the lip synchronization, it is hard to generate a long facial motion sequence of high temporal consistency and audio-lip accuracy; 2) as for the video quality, due to the limited data used to train the renderer, it is vulnerable to out-of-domain input condition and produce bad rendering results occasionally; 3) as for the system efficiency, the slow training and inference speed of the vanilla NeRF severely obstruct its usage in real-world applications. In this paper, we propose GeneFace++ to handle these challenges by 1) utilizing the pitch contour as an auxiliary feature and introducing a temporal loss in the facial motion prediction process; 2) proposing a landmark locally linear embedding method to regulate the outliers in the predicted motion sequence to avoid robustness issues; 3) designing a computationally efficient NeRF-based motion-to-video renderer to achieves fast training and real-time inference. With these settings, GeneFace++ becomes the first NeRF-based method that achieves stable and real-time talking face generation with generalized audio-lip synchronization. Extensive experiments show that our method outperforms state-of-the-art baselines in terms of subjective and objective evaluation. Video samples are available at https://genefaceplusplus.github.io .
Self-Remixing: Unsupervised Speech Separation via Separation and Remixing
Nov 18, 2022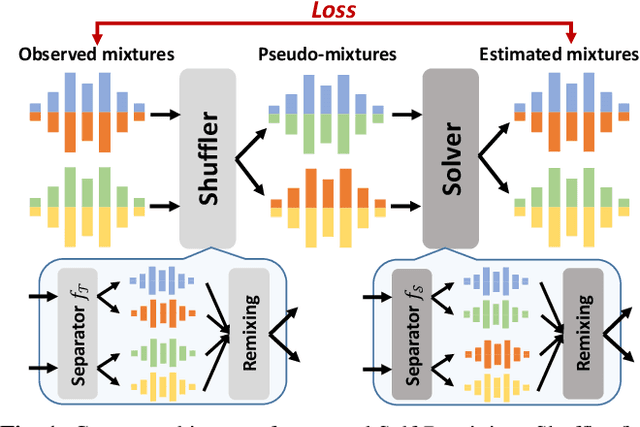
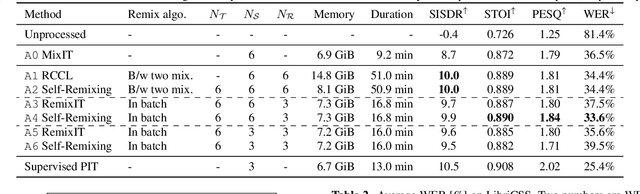
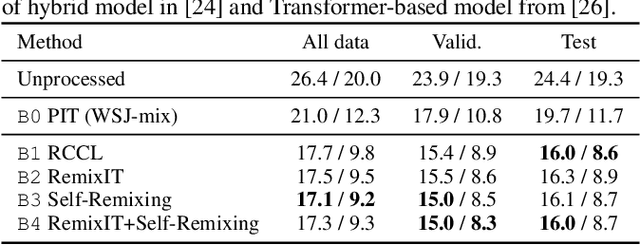
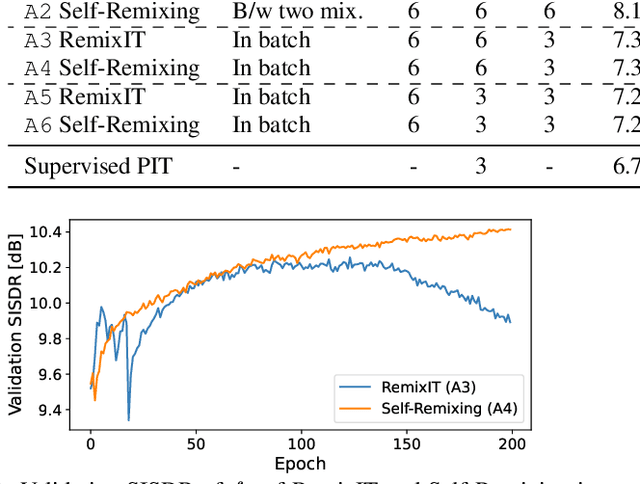
We present Self-Remixing, a novel self-supervised speech separation method, which refines a pre-trained separation model in an unsupervised manner. The proposed method consists of a shuffler module and a solver module, and they grow together through separation and remixing processes. Specifically, the shuffler first separates observed mixtures and makes pseudo-mixtures by shuffling and remixing the separated signals. The solver then separates the pseudo-mixtures and remixes the separated signals back to the observed mixtures. The solver is trained using the observed mixtures as supervision, while the shuffler's weights are updated by taking the moving average with the solver's, generating the pseudo-mixtures with fewer distortions. Our experiments demonstrate that Self-Remixing gives better performance over existing remixing-based self-supervised methods with the same or less training costs under unsupervised setup. Self-Remixing also outperforms baselines in semi-supervised domain adaptation, showing effectiveness in multiple setups.
Speaker and Language Change Detection using Wav2vec2 and Whisper
Feb 18, 2023
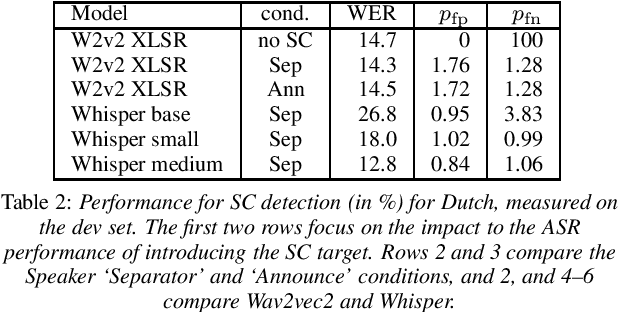
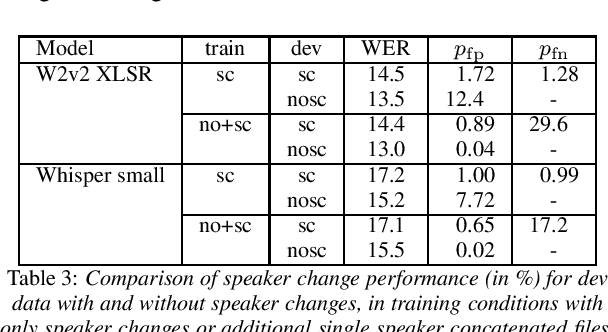
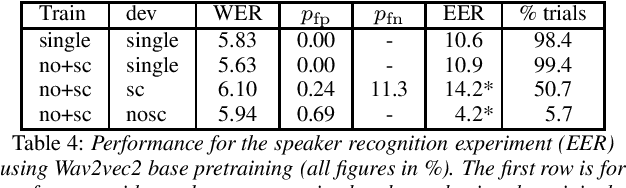
We investigate recent transformer networks pre-trained for automatic speech recognition for their ability to detect speaker and language changes in speech. We do this by simply adding speaker (change) or language targets to the labels. For Wav2vec2 pre-trained networks, we also investigate if the representation for the speaker change symbol can be conditioned to capture speaker identity characteristics. Using a number of constructed data sets we show that these capabilities are definitely there, with speaker recognition equal error rates of the order of 10% and language detection error rates of a few percent. We will publish the code for reproducibility.