 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Automated speech- and text-based classification of neuropsychiatric conditions in a multidiagnostic setting
Jan 13, 2023
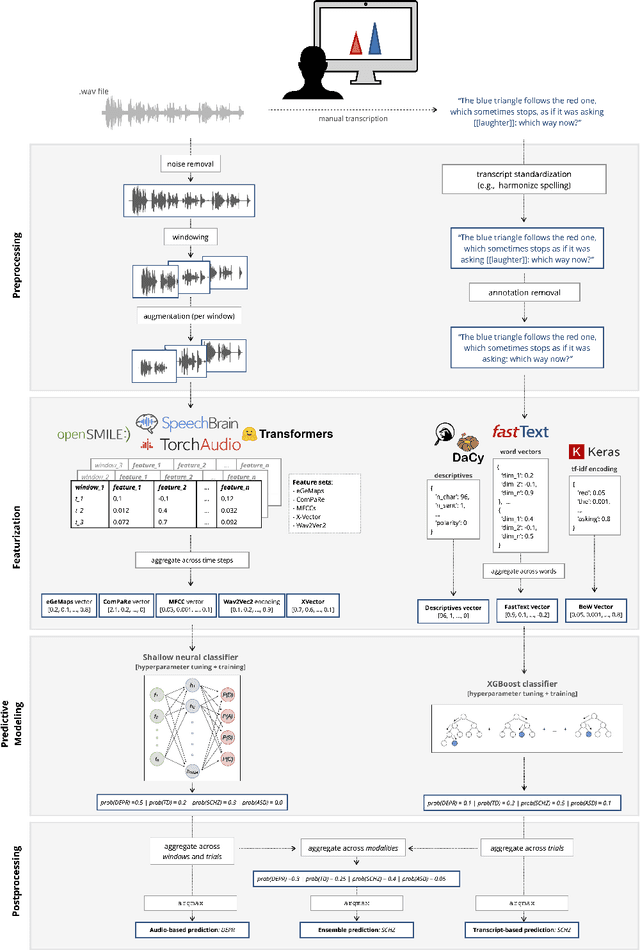
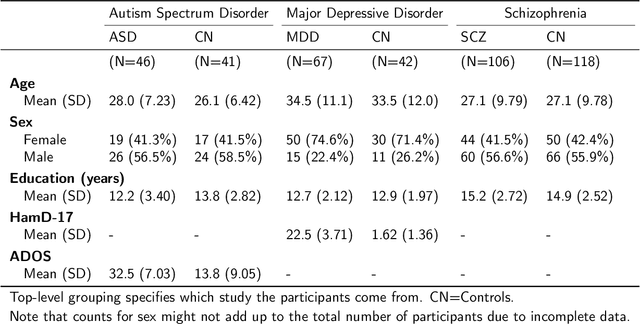
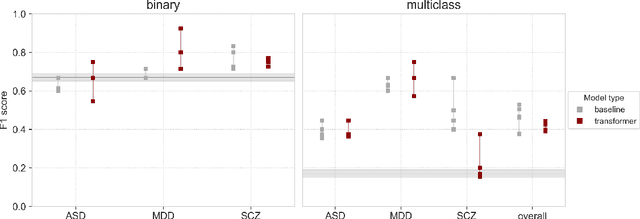
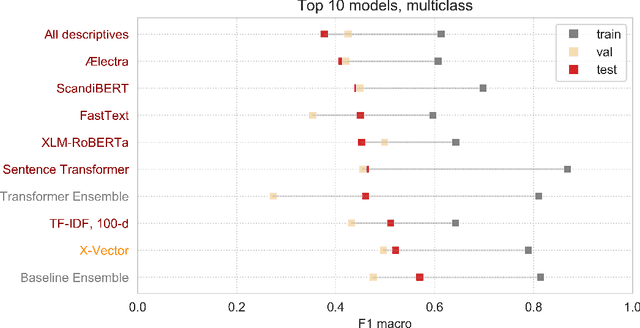
Speech patterns have been identified as potential diagnostic markers for neuropsychiatric conditions. However, most studies only compare a single clinical group to healthy controls, whereas clinical practice often requires differentiating between multiple potential diagnoses (multiclass settings). To address this, we assembled a dataset of repeated recordings from 420 participants (67 with major depressive disorder, 106 with schizophrenia and 46 with autism, as well as matched controls), and tested the performance of a range of conventional machine learning models and advanced Transformer models on both binary and multiclass classification, based on voice and text features. While binary models performed comparably to previous research (F1 scores between 0.54-0.75 for autism spectrum disorder, ASD; 0.67-0.92 for major depressive disorder, MDD; and 0.71-0.83 for schizophrenia); when differentiating between multiple diagnostic groups performance decreased markedly (F1 scores between 0.35-0.44 for ASD, 0.57-0.75 for MDD, 0.15-0.66 for schizophrenia, and 0.38-0.52 macro F1). Combining voice and text-based models yielded increased performance, suggesting that they capture complementary diagnostic information. Our results indicate that models trained on binary classification may learn to rely on markers of generic differences between clinical and non-clinical populations, or markers of clinical features that overlap across conditions, rather than identifying markers specific to individual conditions. We provide recommendations for future research in the field, suggesting increased focus on developing larger transdiagnostic datasets that include more fine-grained clinical features, and that can support the development of models that better capture the complexity of neuropsychiatric conditions and naturalistic diagnostic assessment.
LPCSE: Neural Speech Enhancement through Linear Predictive Coding
Jun 22, 2022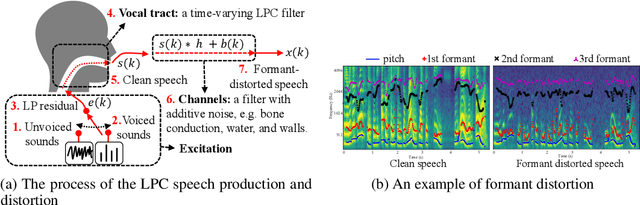
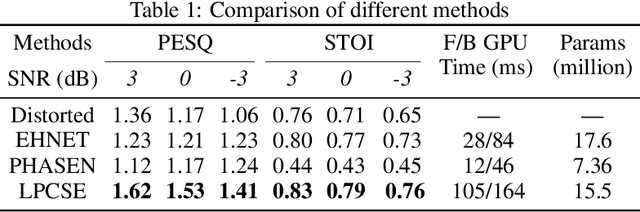
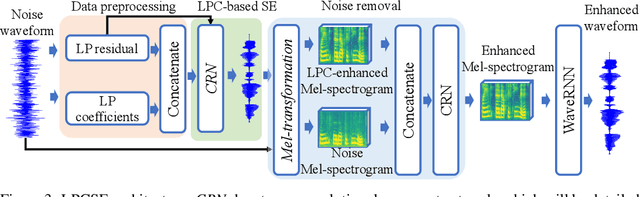
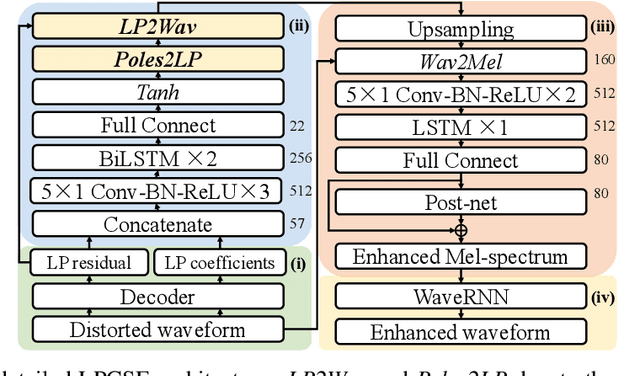
The increasingly stringent requirement on quality-of-experience in 5G/B5G communication systems has led to the emerging neural speech enhancement techniques, which however have been developed in isolation from the existing expert-rule based models of speech pronunciation and distortion, such as the classic Linear Predictive Coding (LPC) speech model because it is difficult to integrate the models with auto-differentiable machine learning frameworks. In this paper, to improve the efficiency of neural speech enhancement, we introduce an LPC-based speech enhancement (LPCSE) architecture, which leverages the strong inductive biases in the LPC speech model in conjunction with the expressive power of neural networks. Differentiable end-to-end learning is achieved in LPCSE via two novel blocks: a block that utilizes the expert rules to reduce the computational overhead when integrating the LPC speech model into neural networks, and a block that ensures the stability of the model and avoids exploding gradients in end-to-end training by mapping the Linear prediction coefficients to the filter poles. The experimental results show that LPCSE successfully restores the formants of the speeches distorted by transmission loss, and outperforms two existing neural speech enhancement methods of comparable neural network sizes in terms of the Perceptual evaluation of speech quality (PESQ) and Short-Time Objective Intelligibility (STOI) on the LJ Speech corpus.
Diacritic Recognition Performance in Arabic ASR
Feb 27, 2023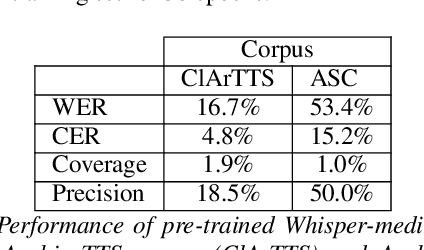
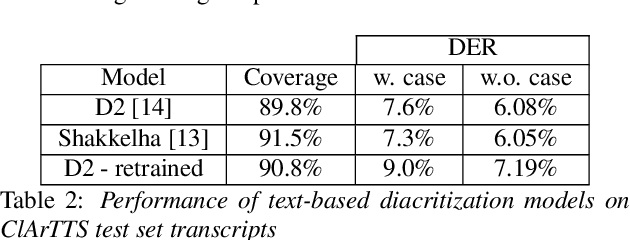
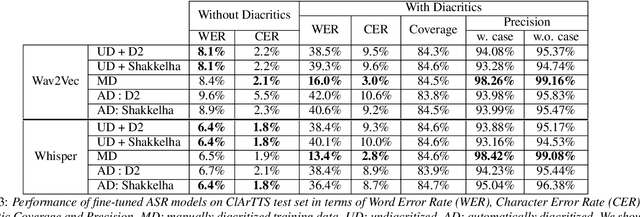
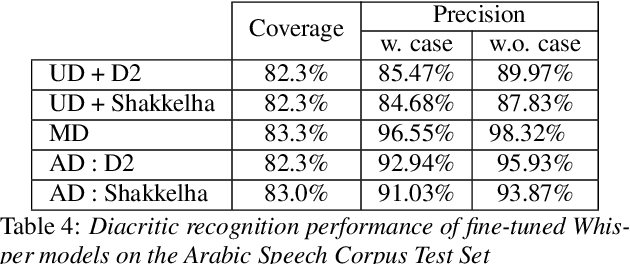
We present an analysis of diacritic recognition performance in Arabic Automatic Speech Recognition (ASR) systems. As most existing Arabic speech corpora do not contain all diacritical marks, which represent short vowels and other phonetic information in Arabic script, current state-of-the-art ASR models do not produce full diacritization in their output. Automatic text-based diacritization has previously been employed both as a pre-processing step to train diacritized ASR, or as a post-processing step to diacritize the resulting ASR hypotheses. It is generally believed that input diacritization degrades ASR performance, but no systematic evaluation of ASR diacritization performance, independent of ASR performance, has been conducted to date. In this paper, we attempt to experimentally clarify whether input diacritiztation indeed degrades ASR quality, and to compare the diacritic recognition performance against text-based diacritization as a post-processing step. We start with pre-trained Arabic ASR models and fine-tune them on transcribed speech data with different diacritization conditions: manual, automatic, and no diacritization. We isolate diacritic recognition performance from the overall ASR performance using coverage and precision metrics. We find that ASR diacritization significantly outperforms text-based diacritization in post-processing, particularly when the ASR model is fine-tuned with manually diacritized transcripts.
Domain Classification-based Source-specific Term Penalization for Domain Adaptation in Hate-speech Detection
Sep 18, 2022
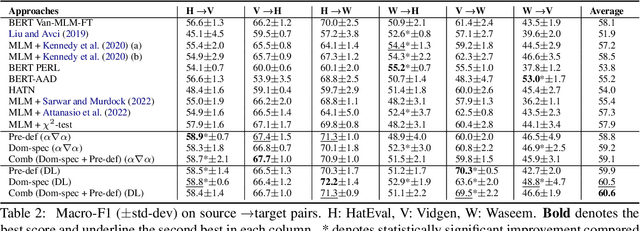


State-of-the-art approaches for hate-speech detection usually exhibit poor performance in out-of-domain settings. This occurs, typically, due to classifiers overemphasizing source-specific information that negatively impacts its domain invariance. Prior work has attempted to penalize terms related to hate-speech from manually curated lists using feature attribution methods, which quantify the importance assigned to input terms by the classifier when making a prediction. We, instead, propose a domain adaptation approach that automatically extracts and penalizes source-specific terms using a domain classifier, which learns to differentiate between domains, and feature-attribution scores for hate-speech classes, yielding consistent improvements in cross-domain evaluation.
End-to-end Speech-to-Punctuated-Text Recognition
Jul 07, 2022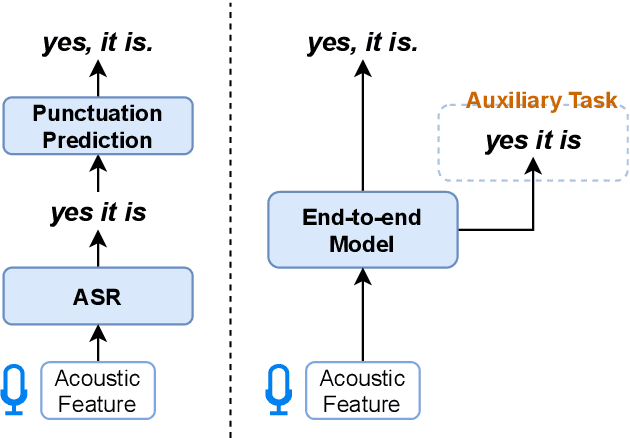
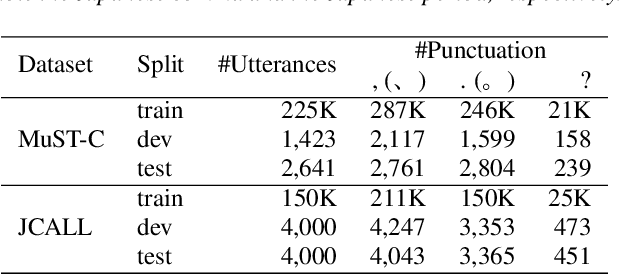

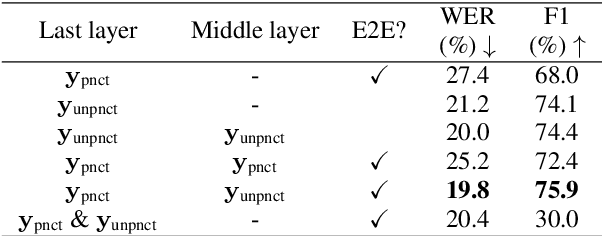
Conventional automatic speech recognition systems do not produce punctuation marks which are important for the readability of the speech recognition results. They are also needed for subsequent natural language processing tasks such as machine translation. There have been a lot of works on punctuation prediction models that insert punctuation marks into speech recognition results as post-processing. However, these studies do not utilize acoustic information for punctuation prediction and are directly affected by speech recognition errors. In this study, we propose an end-to-end model that takes speech as input and outputs punctuated texts. This model is expected to predict punctuation robustly against speech recognition errors while using acoustic information. We also propose to incorporate an auxiliary loss to train the model using the output of the intermediate layer and unpunctuated texts. Through experiments, we compare the performance of the proposed model to that of a cascaded system. The proposed model achieves higher punctuation prediction accuracy than the cascaded system without sacrificing the speech recognition error rate. It is also demonstrated that the multi-task learning using the intermediate output against the unpunctuated text is effective. Moreover, the proposed model has only about 1/7th of the parameters compared to the cascaded system.
Cross-Attention is all you need: Real-Time Streaming Transformers for Personalised Speech Enhancement
Nov 08, 2022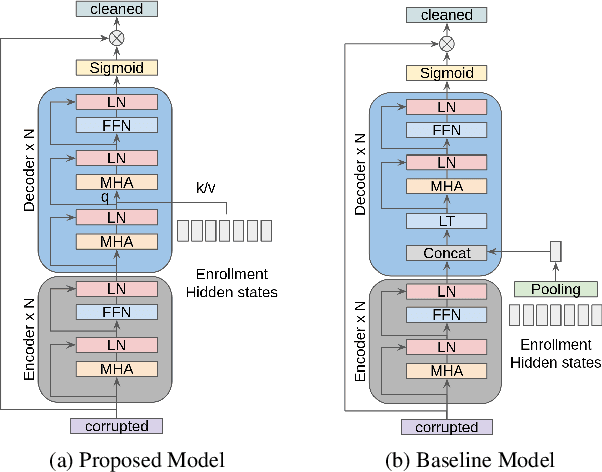
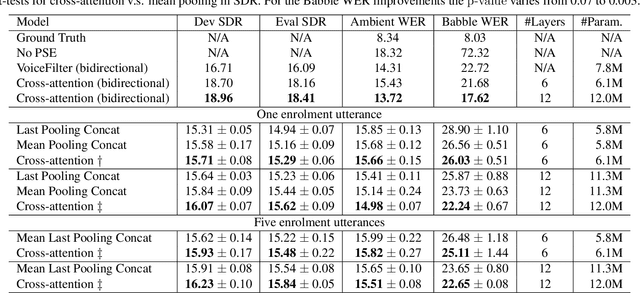
Personalised speech enhancement (PSE), which extracts only the speech of a target user and removes everything else from a recorded audio clip, can potentially improve users' experiences of audio AI modules deployed in the wild. To support a large variety of downstream audio tasks, such as real-time ASR and audio-call enhancement, a PSE solution should operate in a streaming mode, i.e., input audio cleaning should happen in real-time with a small latency and real-time factor. Personalisation is typically achieved by extracting a target speaker's voice profile from an enrolment audio, in the form of a static embedding vector, and then using it to condition the output of a PSE model. However, a fixed target speaker embedding may not be optimal under all conditions. In this work, we present a streaming Transformer-based PSE model and propose a novel cross-attention approach that gives adaptive target speaker representations. We present extensive experiments and show that our proposed cross-attention approach outperforms competitive baselines consistently, even when our model is only approximately half the size.
"It's Not Just Hate'': A Multi-Dimensional Perspective on Detecting Harmful Speech Online
Oct 28, 2022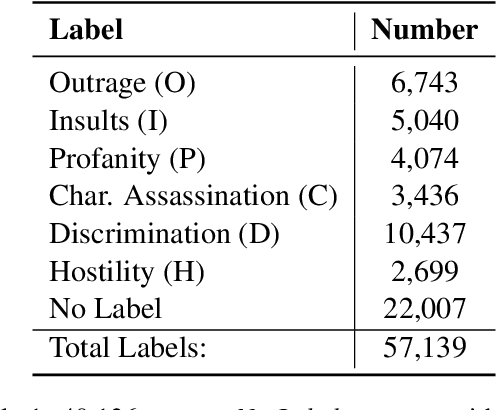
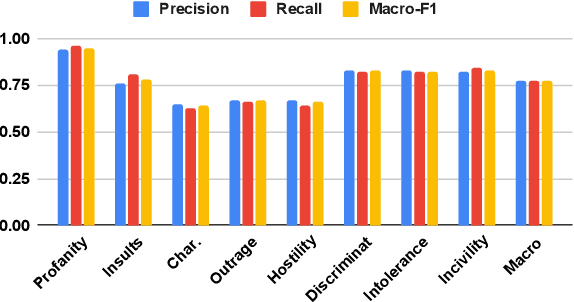

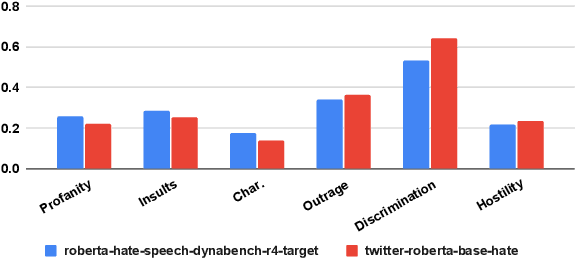
Well-annotated data is a prerequisite for good Natural Language Processing models. Too often, though, annotation decisions are governed by optimizing time or annotator agreement. We make a case for nuanced efforts in an interdisciplinary setting for annotating offensive online speech. Detecting offensive content is rapidly becoming one of the most important real-world NLP tasks. However, most datasets use a single binary label, e.g., for hate or incivility, even though each concept is multi-faceted. This modeling choice severely limits nuanced insights, but also performance. We show that a more fine-grained multi-label approach to predicting incivility and hateful or intolerant content addresses both conceptual and performance issues. We release a novel dataset of over 40,000 tweets about immigration from the US and UK, annotated with six labels for different aspects of incivility and intolerance. Our dataset not only allows for a more nuanced understanding of harmful speech online, models trained on it also outperform or match performance on benchmark datasets.
Unsupervised Text-to-Speech Synthesis by Unsupervised Automatic Speech Recognition
Mar 29, 2022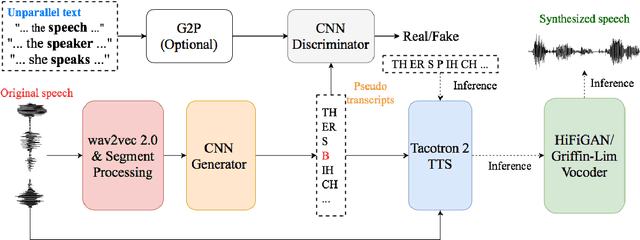

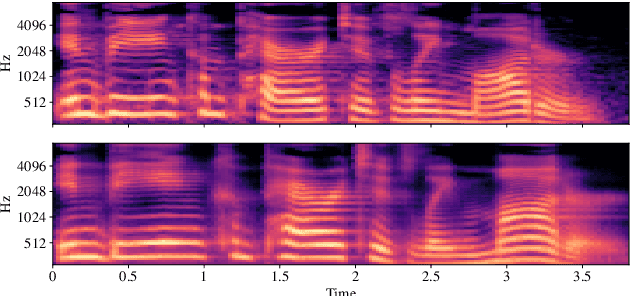
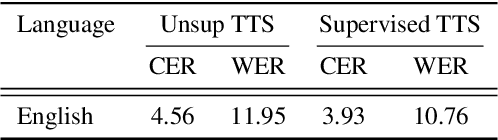
An unsupervised text-to-speech synthesis (TTS) system learns to generate the speech waveform corresponding to any written sentence in a language by observing: 1) a collection of untranscribed speech waveforms in that language; 2) a collection of texts written in that language without access to any transcribed speech. Developing such a system can significantly improve the availability of speech technology to languages without a large amount of parallel speech and text data. This paper proposes an unsupervised TTS system by leveraging recent advances in unsupervised automatic speech recognition (ASR). Our unsupervised system can achieve comparable performance to the supervised system in seven languages with about 10-20 hours of speech each. A careful study on the effect of text units and vocoders has also been conducted to better understand what factors may affect unsupervised TTS performance. The samples generated by our models can be found at https://cactuswiththoughts.github.io/UnsupTTS-Demo.
Improved disentangled speech representations using contrastive learning in factorized hierarchical variational autoencoder
Nov 15, 2022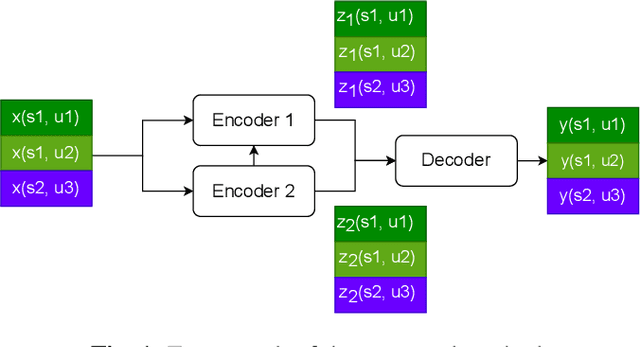
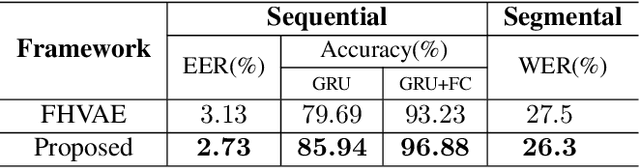
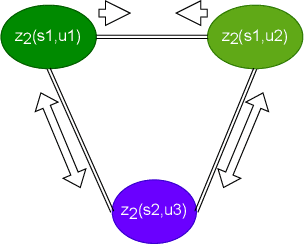
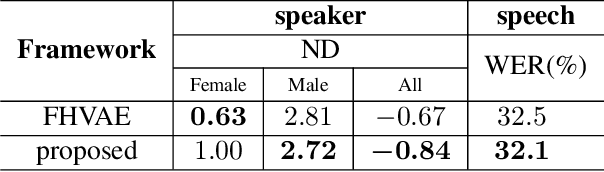
By utilizing the fact that speaker identity and content vary on different time scales, \acrlong{fhvae} (\acrshort{fhvae}) uses a sequential latent variable and a segmental latent variable to symbolize these two attributes. Disentanglement is carried out by assuming the latent variables representing speaker and content follow sequence-dependent and sequence-independent priors. For the sequence-dependent prior, \acrshort{fhvae} assumes a Gaussian distribution with an utterance-scale varying mean and a fixed small variance. The training process promotes sequential variables getting close to the mean of its prior with small variance. However, this constraint is relatively weak. Therefore, we introduce contrastive learning in the \acrshort{fhvae} framework. The proposed method aims to make the sequential variables clustering when representing the same speaker, while distancing themselves as far as possible from those of other speakers. The structure of the framework has not been changed in the proposed method but only the training process, thus no more cost is needed during test. Voice conversion has been chosen as the application in this paper. Latent variable evaluations include speakerincrease verification and identification for the sequential latent variable, and speech recognition for the segmental latent variable. Furthermore, assessments of voice conversion performance are on the grounds of speaker verification and speech recognition experiments. Experiment results show that the proposed method improves both sequential and segmental feature extraction compared with \acrshort{fhvae}, and moderately improved voice conversion performance.
Automatic Speech recognition for Speech Assessment of Preschool Children
Mar 24, 2022
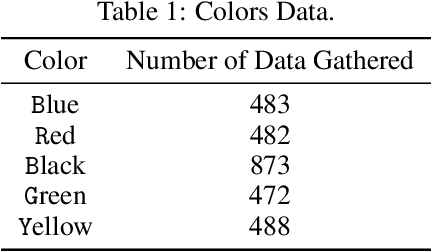

The acoustic and linguistic features of preschool speech are investigated in this study to design an automated speech recognition (ASR) system. Acoustic fluctuation has been highlighted as a significant barrier to developing high-performance ASR applications for youngsters. Because of the epidemic, preschool speech assessment should be conducted online. Accordingly, there is a need for an automatic speech recognition system. We were confronted with new challenges in our cognitive system, including converting meaningless words from speech to text and recognizing word sequence. After testing and experimenting with several models we obtained a 3.1\% phoneme error rate in Persian. Wav2Vec 2.0 is a paradigm that could be used to build a robust end-to-end speech recognition system.