 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Multi-class Detection of Pathological Speech with Latent Features: How does it perform on unseen data?
Oct 27, 2022
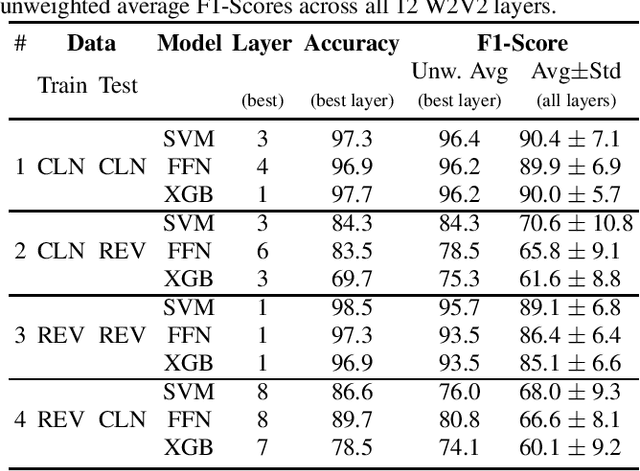
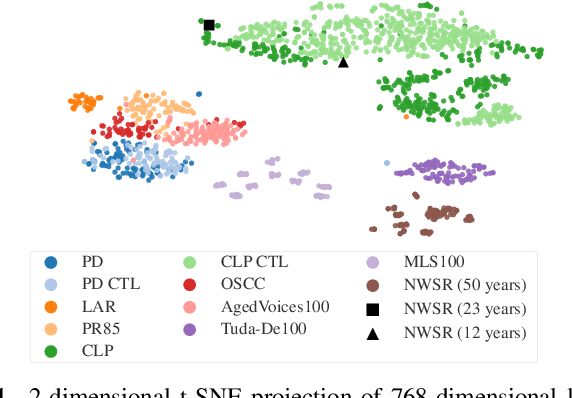
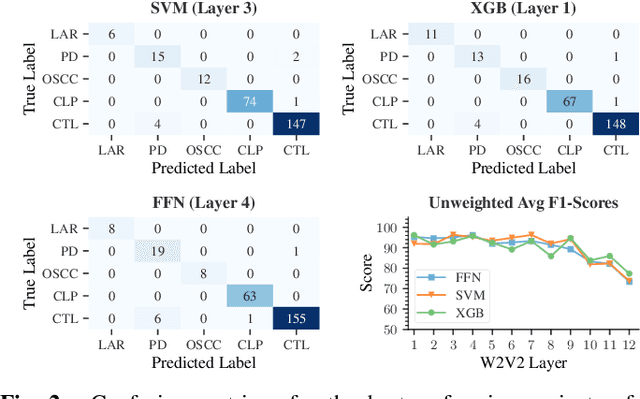
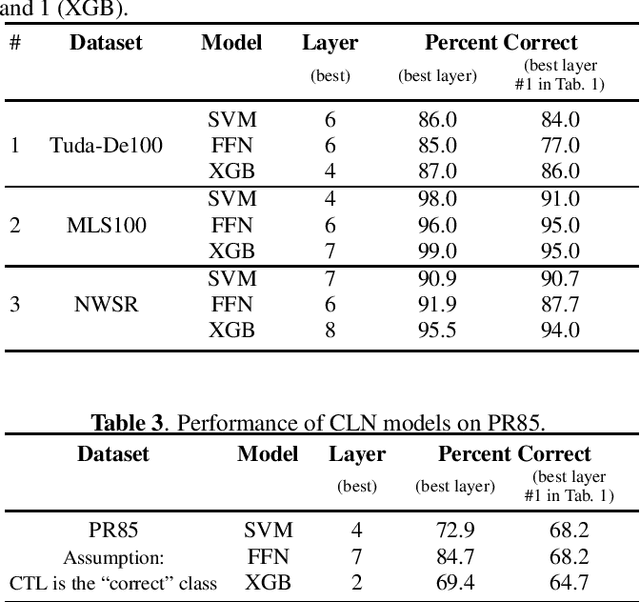
The detection of pathologies from speech features is usually defined as a binary classification task with one class representing a specific pathology and the other class representing healthy speech. In this work, we train neural networks, large margin classifiers, and tree boosting machines to distinguish between four different pathologies: Parkinson's disease, laryngeal cancer, cleft lip and palate, and oral squamous cell carcinoma. We demonstrate that latent representations extracted at different layers of a pre-trained wav2vec 2.0 system can be effectively used to classify these types of pathological voices. We evaluate the robustness of our classifiers by adding room impulse responses to the test data and by applying them to unseen speech corpora. Our approach achieves unweighted average F1-Scores between 74.1% and 96.4%, depending on the model and the noise conditions used. The systems generalize and perform well on unseen data of healthy speakers sampled from a variety of different sources.
Diffusion-based Generative Speech Source Separation
Nov 02, 2022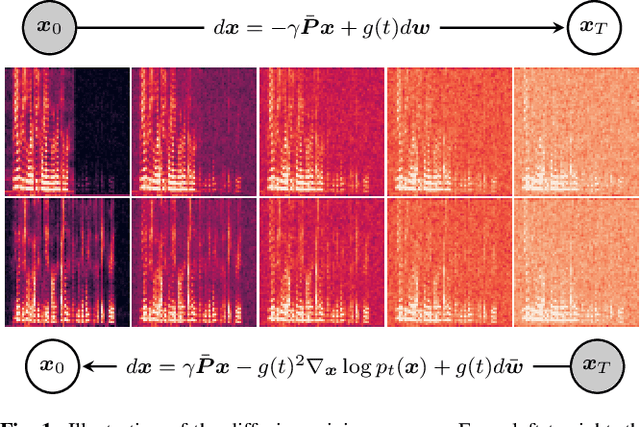
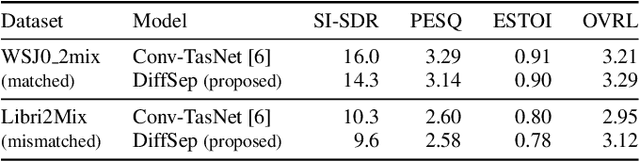
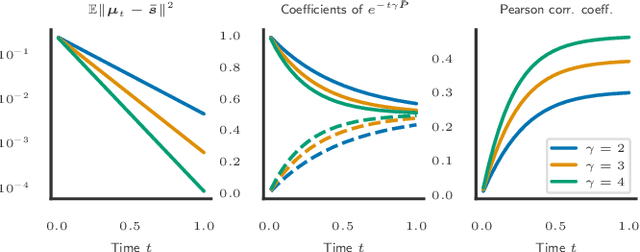
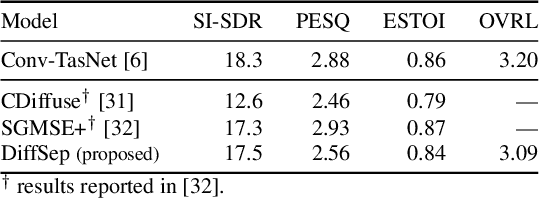
We propose DiffSep, a new single channel source separation method based on score-matching of a stochastic differential equation (SDE). We craft a tailored continuous time diffusion-mixing process starting from the separated sources and converging to a Gaussian distribution centered on their mixture. This formulation lets us apply the machinery of score-based generative modelling. First, we train a neural network to approximate the score function of the marginal probabilities or the diffusion-mixing process. Then, we use it to solve the reverse time SDE that progressively separates the sources starting from their mixture. We propose a modified training strategy to handle model mismatch and source permutation ambiguity. Experiments on the WSJ0 2mix dataset demonstrate the potential of the method. Furthermore, the method is also suitable for speech enhancement and shows performance competitive with prior work on the VoiceBank-DEMAND dataset.
SumREN: Summarizing Reported Speech about Events in News
Dec 02, 2022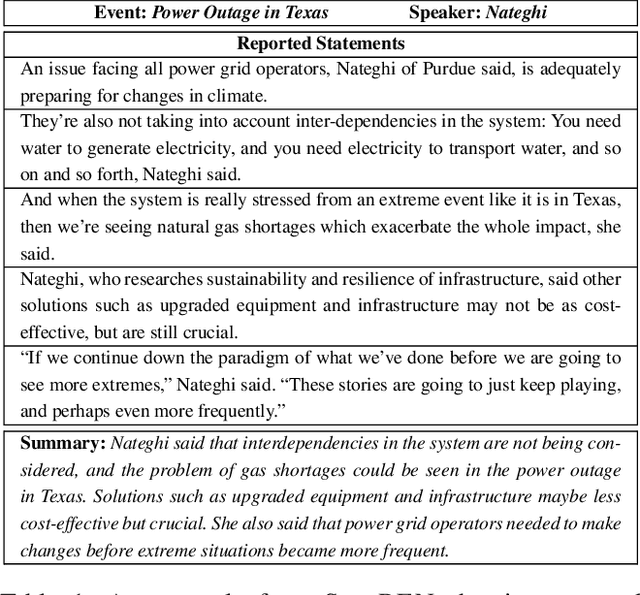
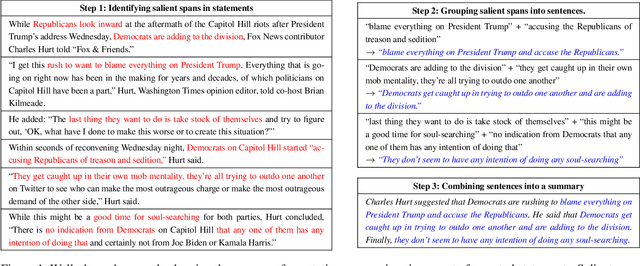

A primary objective of news articles is to establish the factual record for an event, frequently achieved by conveying both the details of the specified event (i.e., the 5 Ws; Who, What, Where, When and Why regarding the event) and how people reacted to it (i.e., reported statements). However, existing work on news summarization almost exclusively focuses on the event details. In this work, we propose the novel task of summarizing the reactions of different speakers, as expressed by their reported statements, to a given event. To this end, we create a new multi-document summarization benchmark, SUMREN, comprising 745 summaries of reported statements from various public figures obtained from 633 news articles discussing 132 events. We propose an automatic silver training data generation approach for our task, which helps smaller models like BART achieve GPT-3 level performance on this task. Finally, we introduce a pipeline-based framework for summarizing reported speech, which we empirically show to generate summaries that are more abstractive and factual than baseline query-focused summarization approaches.
Can ChatGPT Reproduce Human-Generated Labels? A Study of Social Computing Tasks
Apr 20, 2023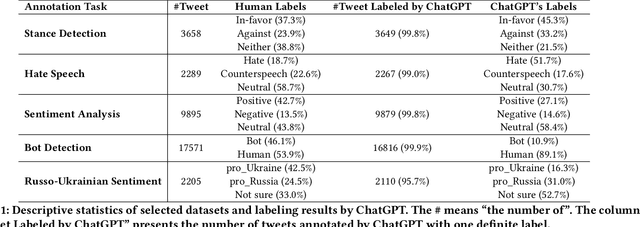
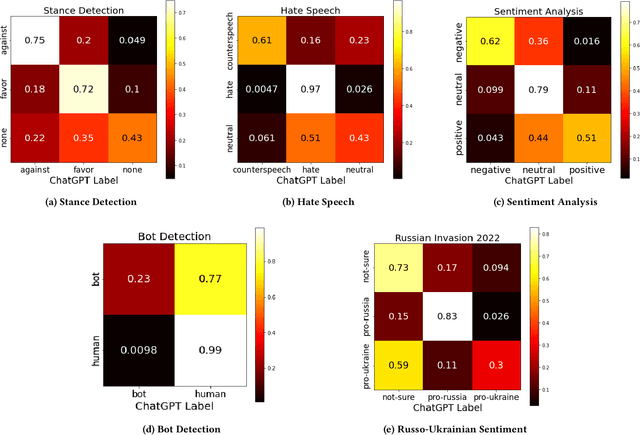

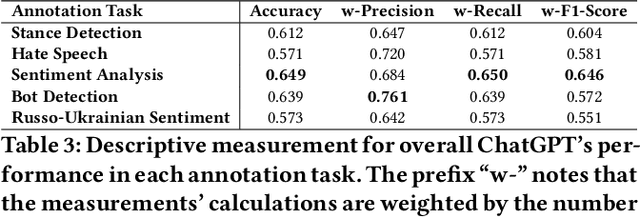
The release of ChatGPT has uncovered a range of possibilities whereby large language models (LLMs) can substitute human intelligence. In this paper, we seek to understand whether ChatGPT has the potential to reproduce human-generated label annotations in social computing tasks. Such an achievement could significantly reduce the cost and complexity of social computing research. As such, we use ChatGPT to re-label five seminal datasets covering stance detection (2x), sentiment analysis, hate speech, and bot detection. Our results highlight that ChatGPT does have the potential to handle these data annotation tasks, although a number of challenges remain. ChatGPT obtains an average precision 0.609. Performance is highest for the sentiment analysis dataset, with ChatGPT correctly annotating 64.9% of tweets. Yet, we show that performance varies substantially across individual labels. We believe this work can open up new lines of analysis and act as a basis for future research into the exploitation of ChatGPT for human annotation tasks.
Human-Machine Collaboration Approaches to Build a Dialogue Dataset for Hate Speech Countering
Nov 07, 2022


Fighting online hate speech is a challenge that is usually addressed using Natural Language Processing via automatic detection and removal of hate content. Besides this approach, counter narratives have emerged as an effective tool employed by NGOs to respond to online hate on social media platforms. For this reason, Natural Language Generation is currently being studied as a way to automatize counter narrative writing. However, the existing resources necessary to train NLG models are limited to 2-turn interactions (a hate speech and a counter narrative as response), while in real life, interactions can consist of multiple turns. In this paper, we present a hybrid approach for dialogical data collection, which combines the intervention of human expert annotators over machine generated dialogues obtained using 19 different configurations. The result of this work is DIALOCONAN, the first dataset comprising over 3000 fictitious multi-turn dialogues between a hater and an NGO operator, covering 6 targets of hate.
Multi-blank Transducers for Speech Recognition
Nov 04, 2022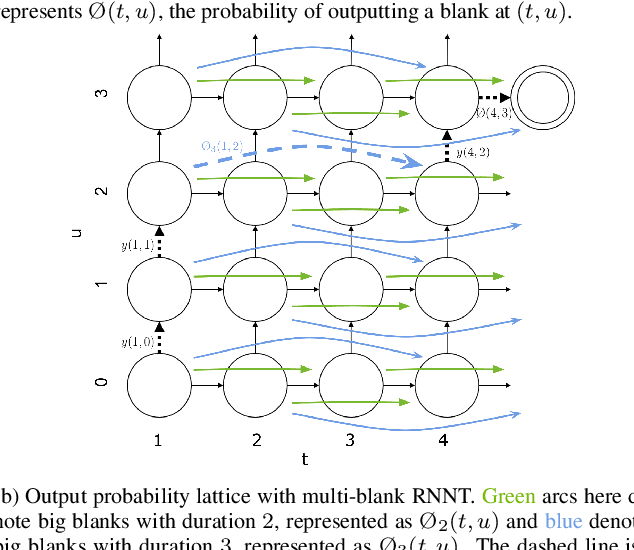
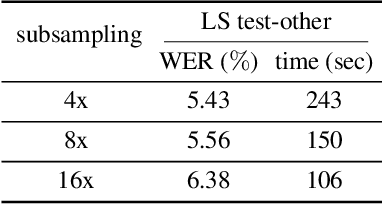
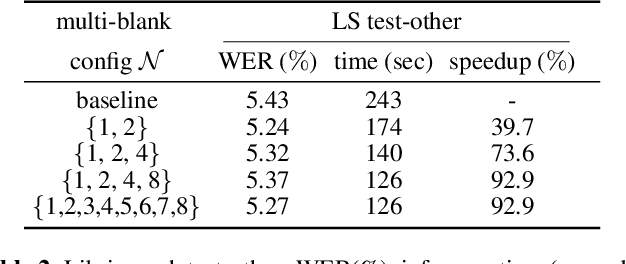
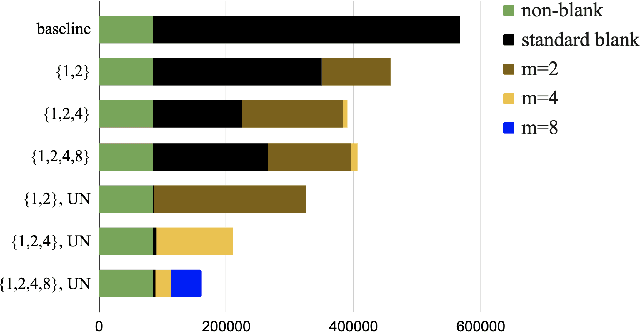
This paper proposes a modification to RNN-Transducer (RNN-T) models for automatic speech recognition (ASR). In standard RNN-T, the emission of a blank symbol consumes exactly one input frame; in our proposed method, we introduce additional blank symbols, which consume two or more input frames when emitted. We refer to the added symbols as big blanks, and the method multi-blank RNN-T. For training multi-blank RNN-Ts, we propose a novel logit under-normalization method in order to prioritize emissions of big blanks. With experiments on multiple languages and datasets, we show that multi-blank RNN-T methods could bring relative speedups of over +90%/+139% to model inference for English Librispeech and German Multilingual Librispeech datasets, respectively. The multi-blank RNN-T method also improves ASR accuracy consistently. We will release our implementation of the method in the NeMo (\url{https://github.com/NVIDIA/NeMo}) toolkit.
Universal Source Separation with Weakly Labelled Data
May 11, 2023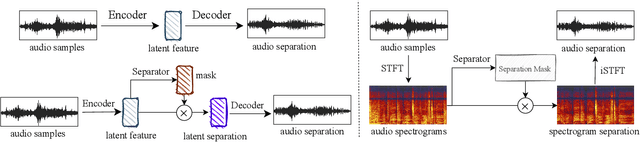
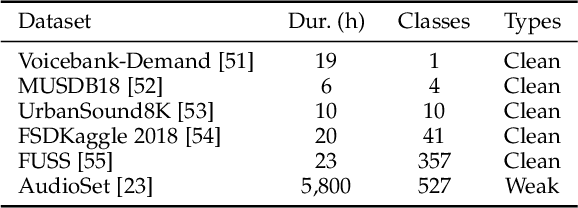
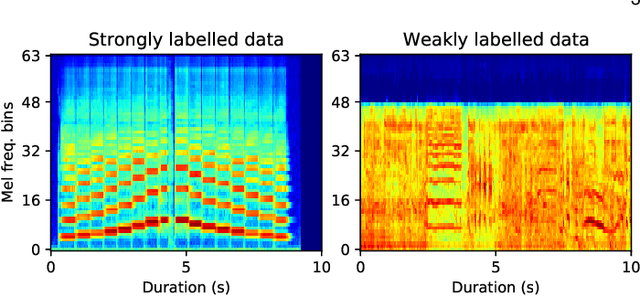

Universal source separation (USS) is a fundamental research task for computational auditory scene analysis, which aims to separate mono recordings into individual source tracks. There are three potential challenges awaiting the solution to the audio source separation task. First, previous audio source separation systems mainly focus on separating one or a limited number of specific sources. There is a lack of research on building a unified system that can separate arbitrary sources via a single model. Second, most previous systems require clean source data to train a separator, while clean source data are scarce. Third, there is a lack of USS system that can automatically detect and separate active sound classes in a hierarchical level. To use large-scale weakly labeled/unlabeled audio data for audio source separation, we propose a universal audio source separation framework containing: 1) an audio tagging model trained on weakly labeled data as a query net; and 2) a conditional source separation model that takes query net outputs as conditions to separate arbitrary sound sources. We investigate various query nets, source separation models, and training strategies and propose a hierarchical USS strategy to automatically detect and separate sound classes from the AudioSet ontology. By solely leveraging the weakly labelled AudioSet, our USS system is successful in separating a wide variety of sound classes, including sound event separation, music source separation, and speech enhancement. The USS system achieves an average signal-to-distortion ratio improvement (SDRi) of 5.57 dB over 527 sound classes of AudioSet; 10.57 dB on the DCASE 2018 Task 2 dataset; 8.12 dB on the MUSDB18 dataset; an SDRi of 7.28 dB on the Slakh2100 dataset; and an SSNR of 9.00 dB on the voicebank-demand dataset. We release the source code at https://github.com/bytedance/uss
The Secret Source : Incorporating Source Features to Improve Acoustic-to-Articulatory Speech Inversion
Oct 29, 2022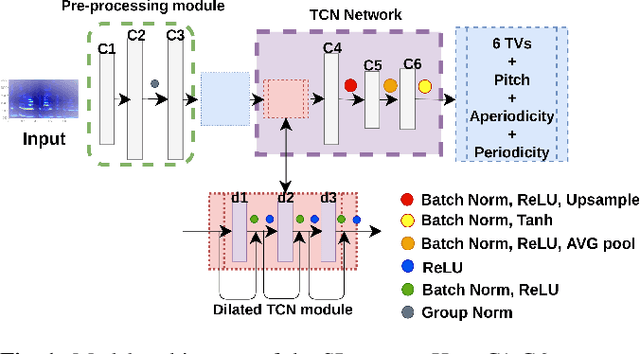
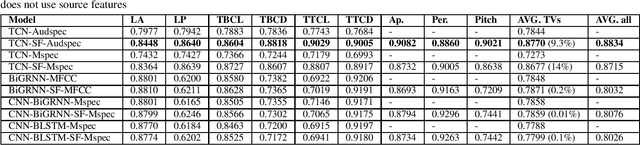
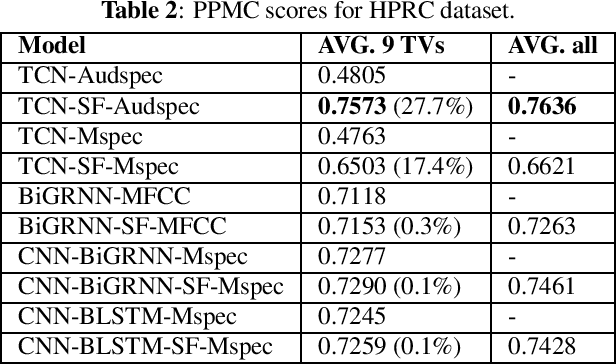
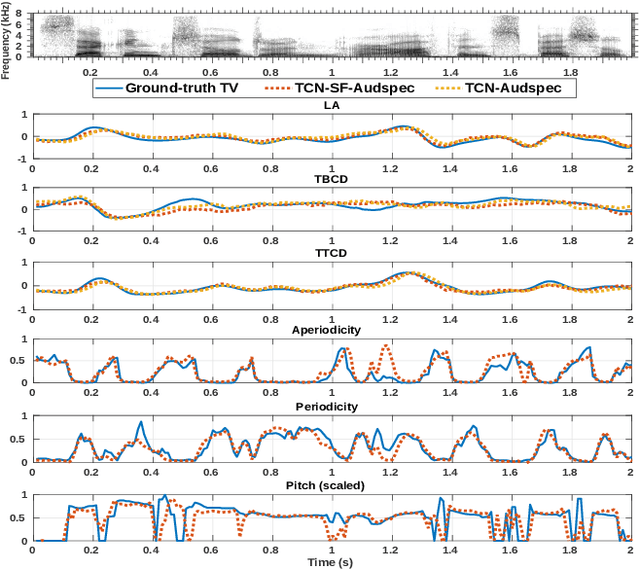
In this work, we incorporated acoustically derived source features, aperiodicity, periodicity and pitch as additional targets to an acoustic-to-articulatory speech inversion (SI) system. We also propose a Temporal Convolution based SI system, which uses auditory spectrograms as the input speech representation, to learn long-range dependencies and complex interactions between the source and vocal tract, to improve the SI task. The experiments are conducted with both the Wisconsin X-ray microbeam (XRMB) and Haskins Production Rate Comparison (HPRC) datasets, with comparisons done with respect to three baseline SI model architectures. The proposed SI system with the HPRC dataset gains an improvement of close to 28% when the source features are used as additional targets. The same SI system outperforms the current best performing SI models by around 9% on the XRMB dataset.
SkipConvGAN: Monaural Speech Dereverberation using Generative Adversarial Networks via Complex Time-Frequency Masking
Nov 22, 2022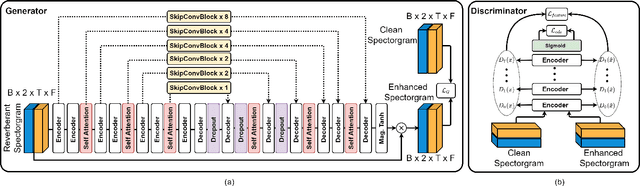
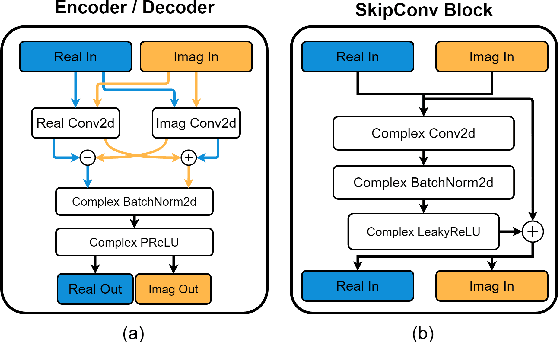
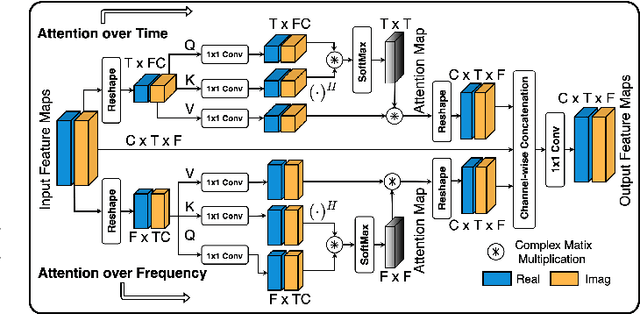
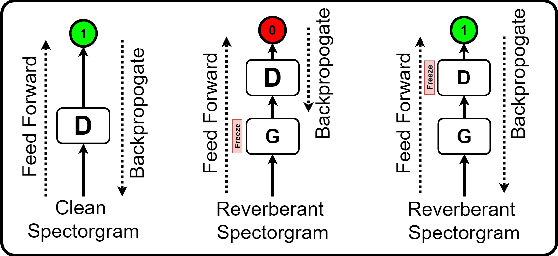
With the advancements in deep learning approaches, the performance of speech enhancing systems in the presence of background noise have shown significant improvements. However, improving the system's robustness against reverberation is still a work in progress, as reverberation tends to cause loss of formant structure due to smearing effects in time and frequency. A wide range of deep learning-based systems either enhance the magnitude response and reuse the distorted phase or enhance complex spectrogram using a complex time-frequency mask. Though these approaches have demonstrated satisfactory performance, they do not directly address the lost formant structure caused by reverberation. We believe that retrieving the formant structure can help improve the efficiency of existing systems. In this study, we propose SkipConvGAN - an extension of our prior work SkipConvNet. The proposed system's generator network tries to estimate an efficient complex time-frequency mask, while the discriminator network aids in driving the generator to restore the lost formant structure. We evaluate the performance of our proposed system on simulated and real recordings of reverberant speech from the single-channel task of the REVERB challenge corpus. The proposed system shows a consistent improvement across multiple room configurations over other deep learning-based generative adversarial frameworks.
QuickVC: Any-to-many Voice Conversion Using Inverse Short-time Fourier Transform for Faster Conversion
Feb 23, 2023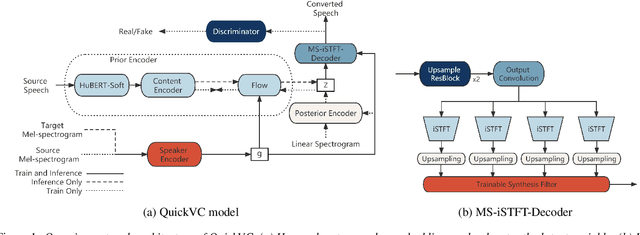
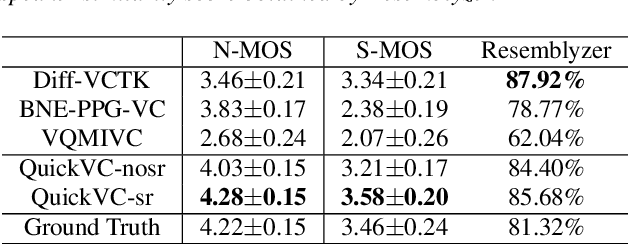

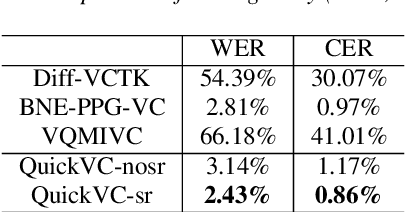
With the development of automatic speech recognition (ASR) and text-to-speech (TTS) technology, high-quality voice conversion (VC) can be achieved by extracting source content information and target speaker information to reconstruct waveforms. However, current methods still require improvement in terms of inference speed. In this study, we propose a lightweight VITS-based VC model that uses the HuBERT-Soft model to extract content information features without speaker information. Through subjective and objective experiments on synthesized speech, the proposed model demonstrates competitive results in terms of naturalness and similarity. Importantly, unlike the original VITS model, we use the inverse short-time Fourier transform (iSTFT) to replace the most computationally expensive part. Experimental results show that our model can generate samples at over 5000 kHz on the 3090 GPU and over 250 kHz on the i9-10900K CPU, achieving competitive speed for the same hardware configuration.