 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
Security and Privacy Problems in Voice Assistant Applications: A Survey
Apr 19, 2023
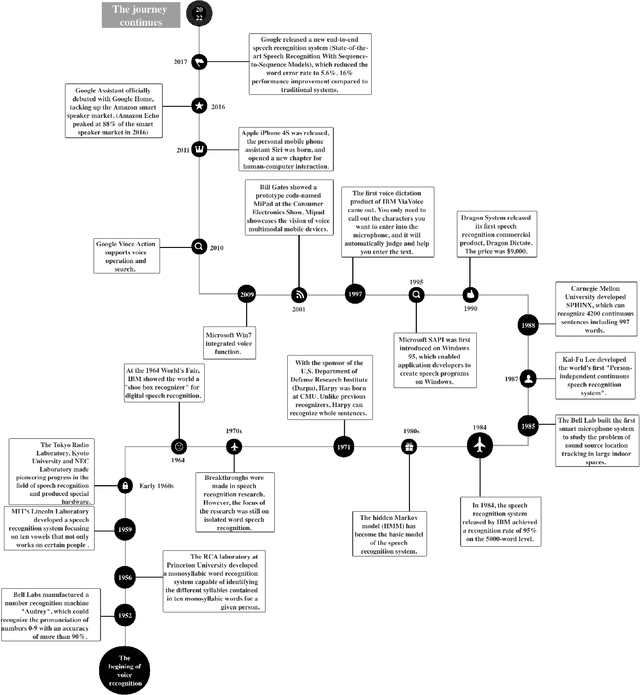
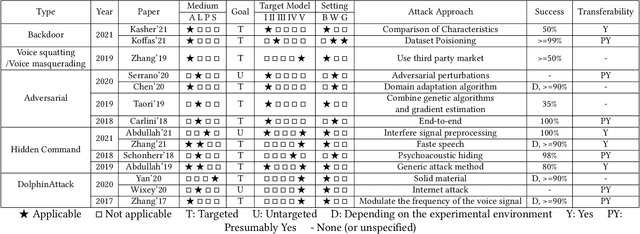
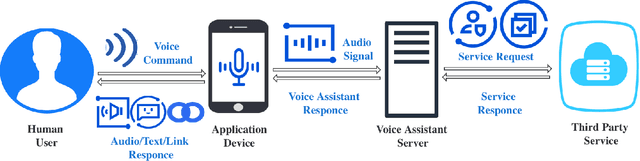
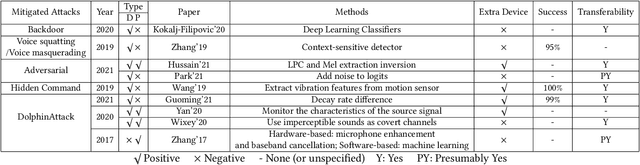
Voice assistant applications have become omniscient nowadays. Two models that provide the two most important functions for real-life applications (i.e., Google Home, Amazon Alexa, Siri, etc.) are Automatic Speech Recognition (ASR) models and Speaker Identification (SI) models. According to recent studies, security and privacy threats have also emerged with the rapid development of the Internet of Things (IoT). The security issues researched include attack techniques toward machine learning models and other hardware components widely used in voice assistant applications. The privacy issues include technical-wise information stealing and policy-wise privacy breaches. The voice assistant application takes a steadily growing market share every year, but their privacy and security issues never stopped causing huge economic losses and endangering users' personal sensitive information. Thus, it is important to have a comprehensive survey to outline the categorization of the current research regarding the security and privacy problems of voice assistant applications. This paper concludes and assesses five kinds of security attacks and three types of privacy threats in the papers published in the top-tier conferences of cyber security and voice domain.
Optimizing Deep Learning Models For Raspberry Pi
Apr 25, 2023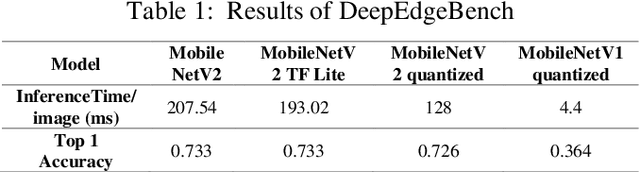
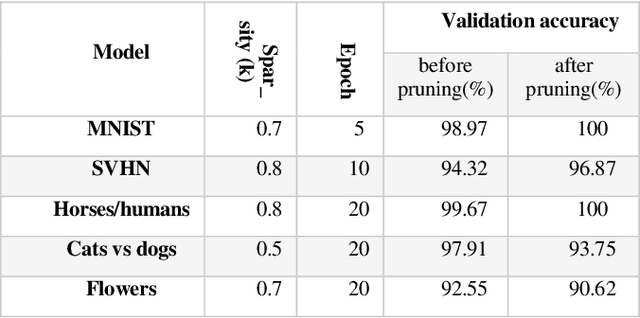
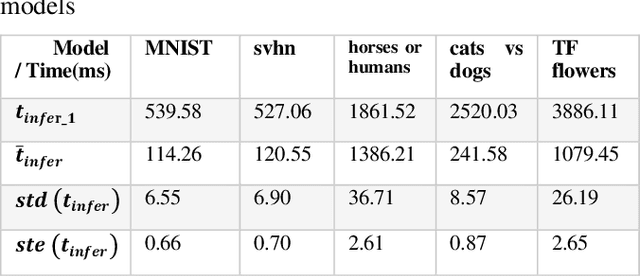
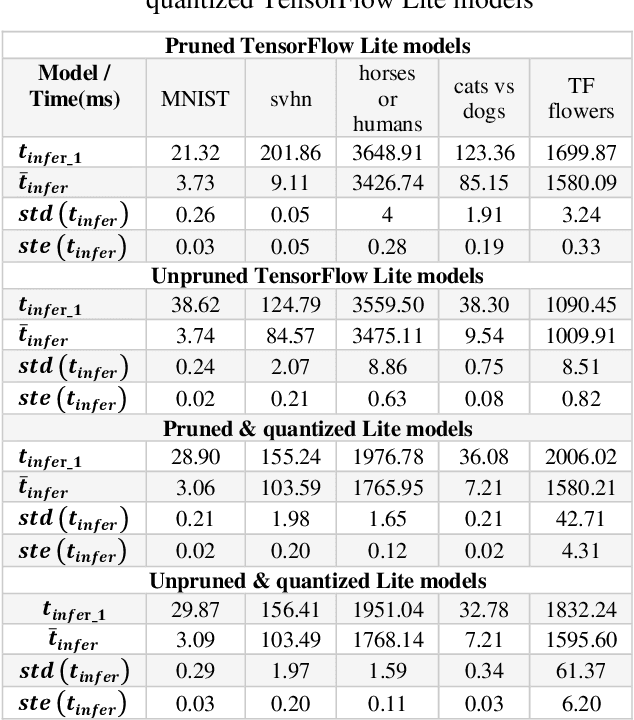
Deep learning models have become increasingly popular for a wide range of applications, including computer vision, natural language processing, and speech recognition. However, these models typically require large amounts of computational resources, making them challenging to run on low-power devices such as the Raspberry Pi. One approach to addressing this challenge is to use pruning techniques to reduce the size of the deep learning models. Pruning involves removing unimportant weights and connections from the model, resulting in a smaller and more efficient model. Pruning can be done during training or after the model has been trained. Another approach is to optimize the deep learning models specifically for the Raspberry Pi architecture. This can include optimizing the model's architecture and parameters to take advantage of the Raspberry Pi's hardware capabilities, such as its CPU and GPU. Additionally, the model can be optimized for energy efficiency by minimizing the amount of computation required. Pruning and optimizing deep learning models for the Raspberry Pi can help overcome the computational and energy constraints of low-power devices, making it possible to run deep learning models on a wider range of devices. In the following sections, we will explore these approaches in more detail and discuss their effectiveness for optimizing deep learning models for the Raspberry Pi.
QuickVC: Many-to-any Voice Conversion Using Inverse Short-time Fourier Transform for Faster Conversion
Feb 20, 2023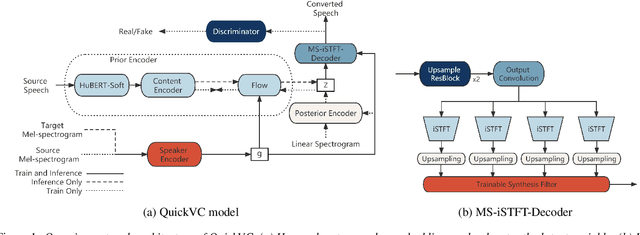
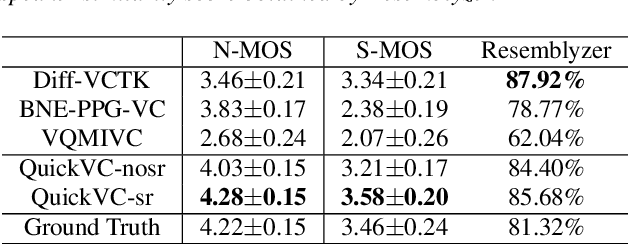

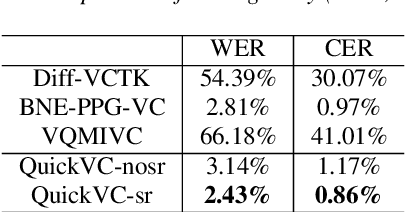
With the development of automatic speech recognition (ASR) and text-to-speech (TTS) technology, high-quality voice conversion (VC) can be achieved by extracting source content information and target speaker information to reconstruct waveforms. However, current methods still require improvement in terms of inference speed. In this study, we propose a lightweight VITS-based VC model that uses the HuBERT-Soft model to extract content information features without speaker information. Through subjective and objective experiments on synthesized speech, the proposed model demonstrates competitive results in terms of naturalness and similarity. Importantly, unlike the original VITS model, we use the inverse short-time Fourier transform (iSTFT) to replace the most computationally expensive part. Experimental results show that our model can generate samples at over 5000 kHz on the 3090 GPU and over 250 kHz on the i9-10900K CPU, achieving competitive speed for the same hardware configuration.
Real-Time Joint Personalized Speech Enhancement and Acoustic Echo Cancellation with E3Net
Nov 04, 2022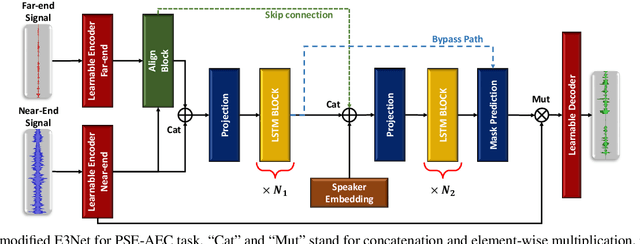
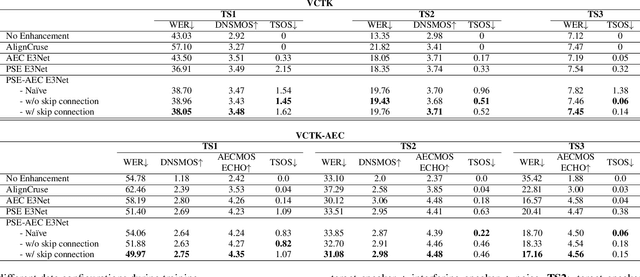
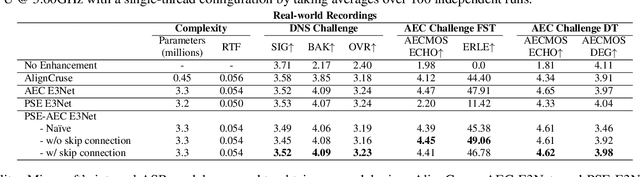
Personalized speech enhancement (PSE), a process of estimating a clean target speech signal in real time by leveraging a speaker embedding vector of the target talker, has garnered much attention from the research community due to the recent surge of online meetings across the globe. For practical full duplex communication, PSE models require an acoustic echo cancellation (AEC) capability. In this work, we employ a recently proposed causal end-to-end enhancement network (E3Net) and modify it to obtain a joint PSE-AEC model. We dedicate the early layers to the AEC task while encouraging later layers for personalization by adding a bypass connection from the early layers to the mask prediction layer. This allows us to employ a multi-task learning framework for joint PSE and AEC training. We provide extensive evaluation test scenarios with both simulated and real-world recordings. The results show that our joint model comes close to the expert models for each task and performs significantly better for the combined PSE-AEC scenario.
Turn-Taking Prediction for Natural Conversational Speech
Aug 29, 2022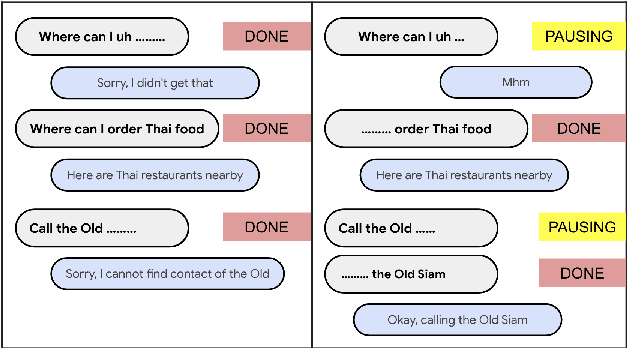
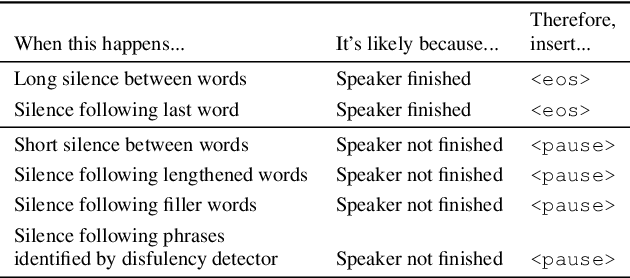
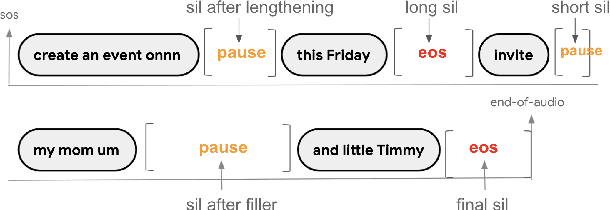
While a streaming voice assistant system has been used in many applications, this system typically focuses on unnatural, one-shot interactions assuming input from a single voice query without hesitation or disfluency. However, a common conversational utterance often involves multiple queries with turn-taking, in addition to disfluencies. These disfluencies include pausing to think, hesitations, word lengthening, filled pauses and repeated phrases. This makes doing speech recognition with conversational speech, including one with multiple queries, a challenging task. To better model the conversational interaction, it is critical to discriminate disfluencies and end of query in order to allow the user to hold the floor for disfluencies while having the system respond as quickly as possible when the user has finished speaking. In this paper, we present a turntaking predictor built on top of the end-to-end (E2E) speech recognizer. Our best system is obtained by jointly optimizing for ASR task and detecting when the user is paused to think or finished speaking. The proposed approach demonstrates over 97% recall rate and 85% precision rate on predicting true turn-taking with only 100 ms latency on a test set designed with 4 types of disfluencies inserted in conversational utterances.
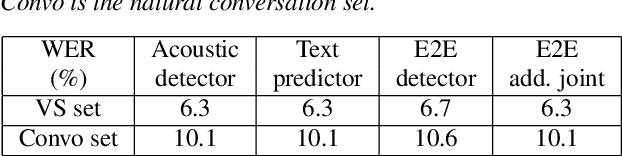
Speech Enhancement Using Self-Supervised Pre-Trained Model and Vector Quantization
Sep 28, 2022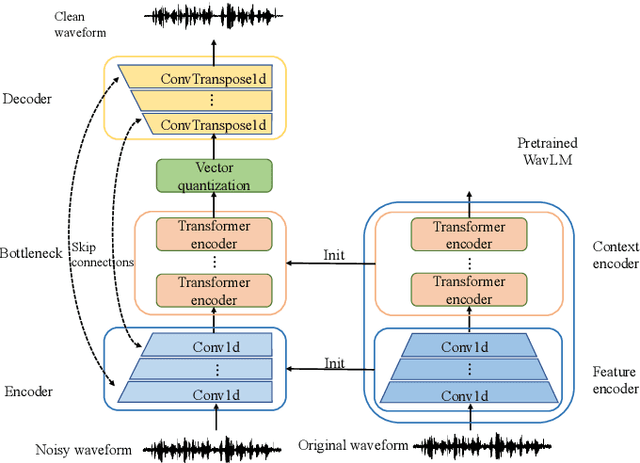
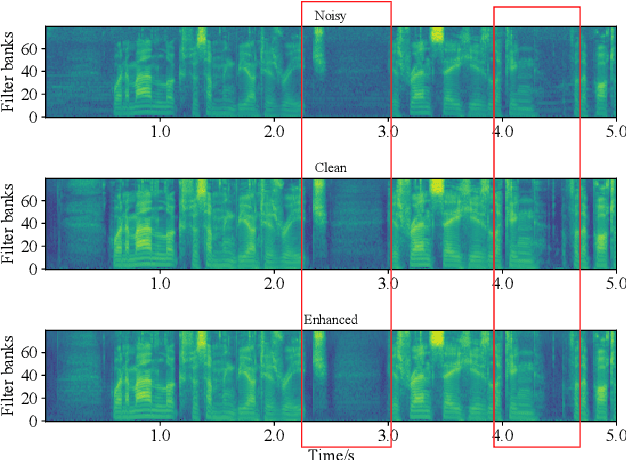
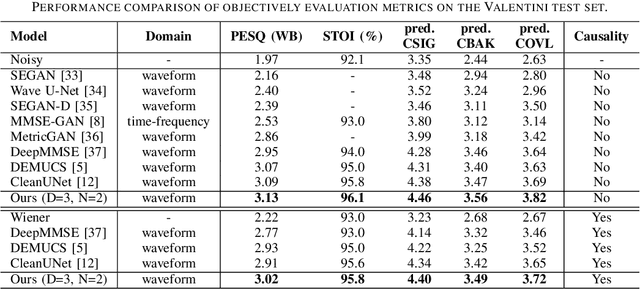
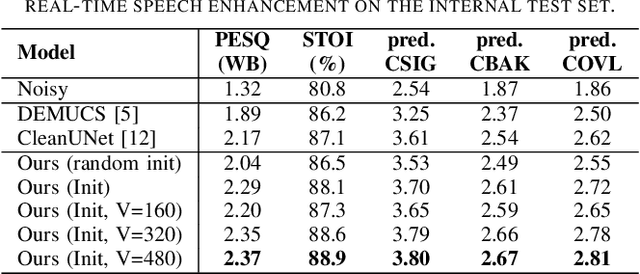
With the development of deep learning, neural network-based speech enhancement (SE) models have shown excellent performance. Meanwhile, it was shown that the development of self-supervised pre-trained models can be applied to various downstream tasks. In this paper, we will consider the application of the pre-trained model to the real-time SE problem. Specifically, the encoder and bottleneck layer of the DEMUCS model are initialized using the self-supervised pretrained WavLM model, the convolution in the encoder is replaced by causal convolution, and the transformer encoder in the bottleneck layer is based on causal attention mask. In addition, as discretizing the noisy speech representations is more beneficial for denoising, we utilize a quantization module to discretize the representation output from the bottleneck layer, which is then fed into the decoder to reconstruct the clean speech waveform. Experimental results on the Valentini dataset and an internal dataset show that the pre-trained model based initialization can improve the SE performance and the discretization operation suppresses the noise component in the representations to some extent, which can further improve the performance.
Text with Knowledge Graph Augmented Transformer for Video Captioning
Mar 25, 2023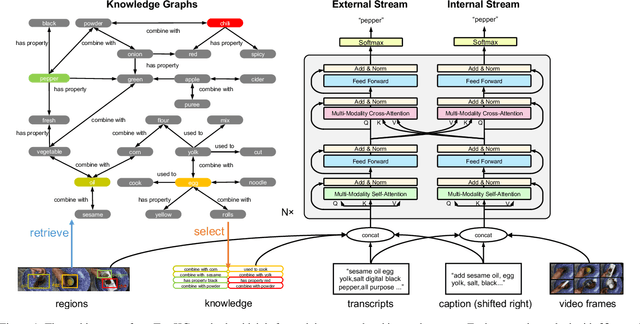
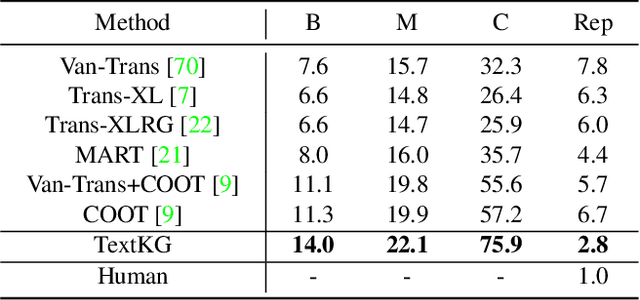
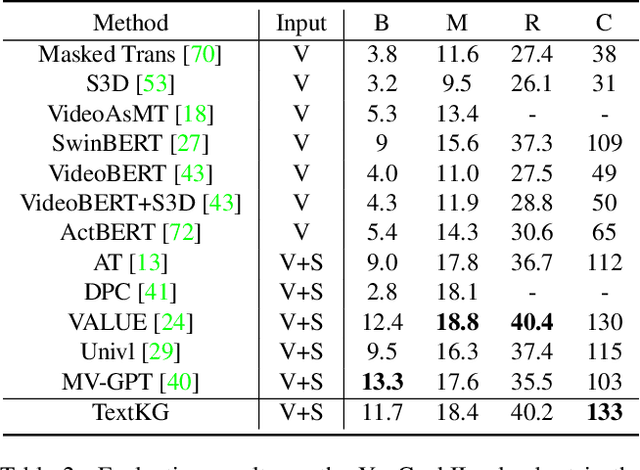
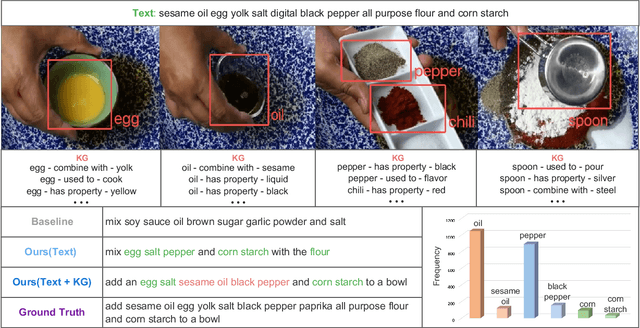
Video captioning aims to describe the content of videos using natural language. Although significant progress has been made, there is still much room to improve the performance for real-world applications, mainly due to the long-tail words challenge. In this paper, we propose a text with knowledge graph augmented transformer (TextKG) for video captioning. Notably, TextKG is a two-stream transformer, formed by the external stream and internal stream. The external stream is designed to absorb additional knowledge, which models the interactions between the additional knowledge, e.g., pre-built knowledge graph, and the built-in information of videos, e.g., the salient object regions, speech transcripts, and video captions, to mitigate the long-tail words challenge. Meanwhile, the internal stream is designed to exploit the multi-modality information in videos (e.g., the appearance of video frames, speech transcripts, and video captions) to ensure the quality of caption results. In addition, the cross attention mechanism is also used in between the two streams for sharing information. In this way, the two streams can help each other for more accurate results. Extensive experiments conducted on four challenging video captioning datasets, i.e., YouCookII, ActivityNet Captions, MSRVTT, and MSVD, demonstrate that the proposed method performs favorably against the state-of-the-art methods. Specifically, the proposed TextKG method outperforms the best published results by improving 18.7% absolute CIDEr scores on the YouCookII dataset.
Feature Selection Enhancement and Feature Space Visualization for Speech-Based Emotion Recognition
Aug 19, 2022
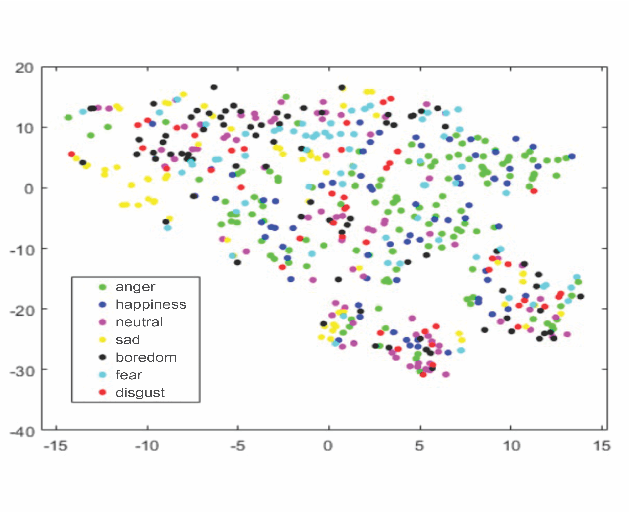
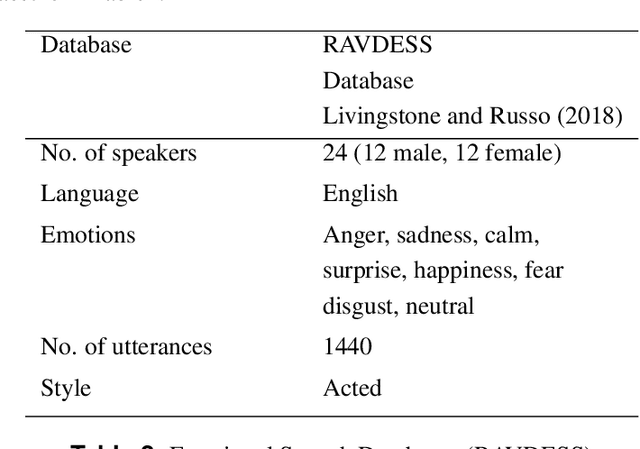
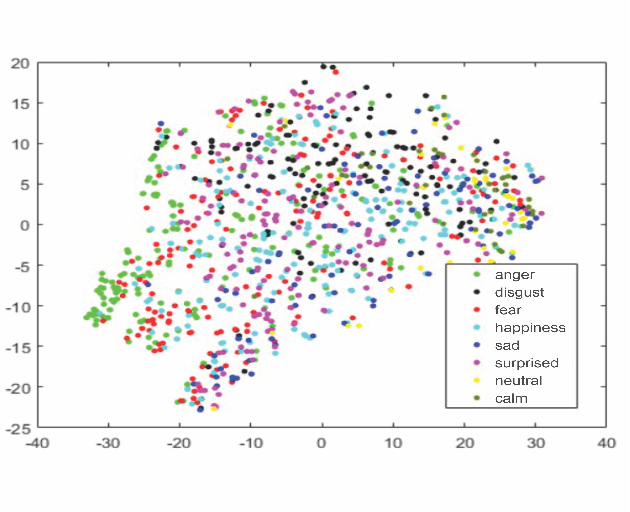
Robust speech emotion recognition relies on the quality of the speech features. We present speech features enhancement strategy that improves speech emotion recognition. We used the INTERSPEECH 2010 challenge feature-set. We identified subsets from the features set and applied Principle Component Analysis to the subsets. Finally, the features are fused horizontally. The resulting feature set is analyzed using t-distributed neighbour embeddings (t-SNE) before the application of features for emotion recognition. The method is compared with the state-of-the-art methods used in the literature. The empirical evidence is drawn using two well-known datasets: Emotional Speech Dataset (EMO-DB) and Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS) for two languages, German and English, respectively. Our method achieved an average recognition gain of 11.5\% for six out of seven emotions for the EMO-DB dataset, and 13.8\% for seven out of eight emotions for the RAVDESS dataset as compared to the baseline study.
YFACC: A Yorùbá speech-image dataset for cross-lingual keyword localisation through visual grounding
Oct 12, 2022

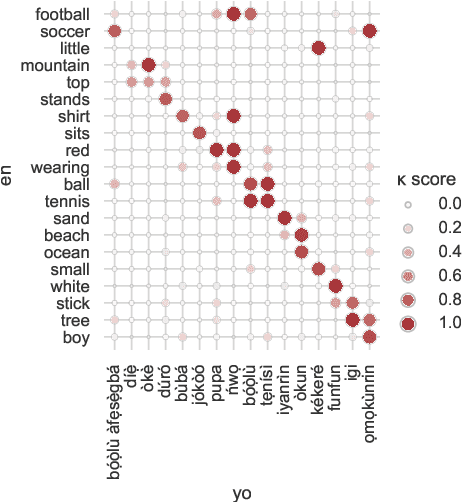

Visually grounded speech (VGS) models are trained on images paired with unlabelled spoken captions. Such models could be used to build speech systems in settings where it is impossible to get labelled data, e.g. for documenting unwritten languages. However, most VGS studies are in English or other high-resource languages. This paper attempts to address this shortcoming. We collect and release a new single-speaker dataset of audio captions for 6k Flickr images in Yor\`ub\'a -- a real low-resource language spoken in Nigeria. We train an attention-based VGS model where images are automatically tagged with English visual labels and paired with Yor\`ub\'a utterances. This enables cross-lingual keyword localisation: a written English query is detected and located in Yor\`ub\'a speech. To quantify the effect of the smaller dataset, we compare to English systems trained on similar and more data. We hope that this new dataset will stimulate research in the use of VGS models for real low-resource languages.
Integrity and Junkiness Failure Handling for Embedding-based Retrieval: A Case Study in Social Network Search
Apr 18, 2023
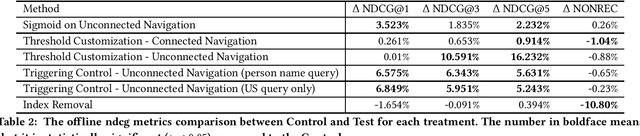

Embedding based retrieval has seen its usage in a variety of search applications like e-commerce, social networking search etc. While the approach has demonstrated its efficacy in tasks like semantic matching and contextual search, it is plagued by the problem of uncontrollable relevance. In this paper, we conduct an analysis of embedding-based retrieval launched in early 2021 on our social network search engine, and define two main categories of failures introduced by it, integrity and junkiness. The former refers to issues such as hate speech and offensive content that can severely harm user experience, while the latter includes irrelevant results like fuzzy text matching or language mismatches. Efficient methods during model inference are further proposed to resolve the issue, including indexing treatments and targeted user cohort treatments, etc. Though being simple, we show the methods have good offline NDCG and online A/B tests metrics gain in practice. We analyze the reasons for the improvements, pointing out that our methods are only preliminary attempts to this important but challenging problem. We put forward potential future directions to explore.