 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech": models, code, and papers
NLPre: a revised approach towards language-centric benchmarking of Natural Language Preprocessing systems
Mar 07, 2024
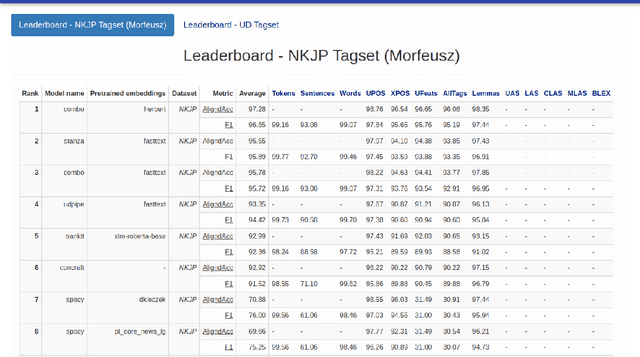
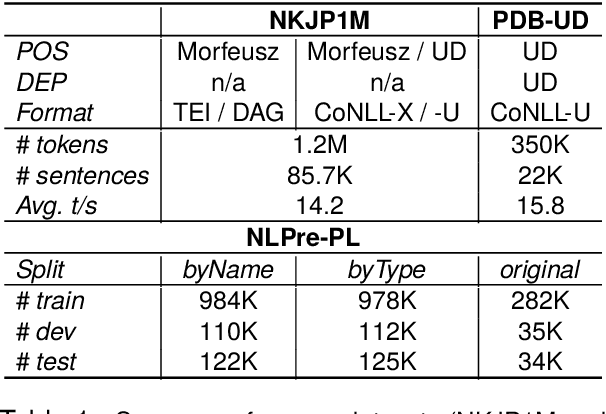
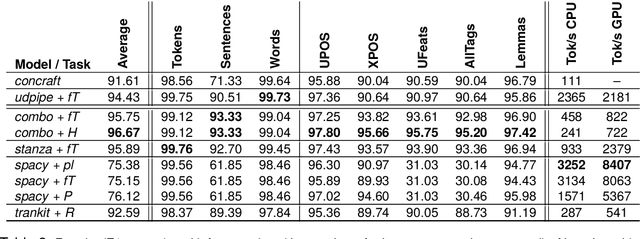
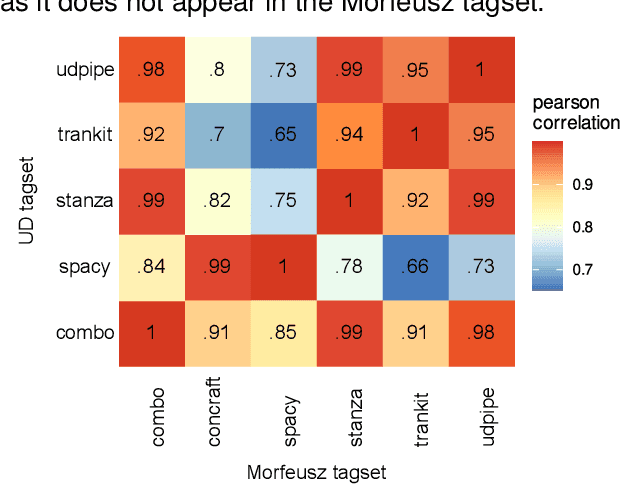
With the advancements of transformer-based architectures, we observe the rise of natural language preprocessing (NLPre) tools capable of solving preliminary NLP tasks (e.g. tokenisation, part-of-speech tagging, dependency parsing, or morphological analysis) without any external linguistic guidance. It is arduous to compare novel solutions to well-entrenched preprocessing toolkits, relying on rule-based morphological analysers or dictionaries. Aware of the shortcomings of existing NLPre evaluation approaches, we investigate a novel method of reliable and fair evaluation and performance reporting. Inspired by the GLUE benchmark, the proposed language-centric benchmarking system enables comprehensive ongoing evaluation of multiple NLPre tools, while credibly tracking their performance. The prototype application is configured for Polish and integrated with the thoroughly assembled NLPre-PL benchmark. Based on this benchmark, we conduct an extensive evaluation of a variety of Polish NLPre systems. To facilitate the construction of benchmarking environments for other languages, e.g. NLPre-GA for Irish or NLPre-ZH for Chinese, we ensure full customization of the publicly released source code of the benchmarking system. The links to all the resources (deployed platforms, source code, trained models, datasets etc.) can be found on the project website: https://sites.google.com/view/nlpre-benchmark.
AVI-Talking: Learning Audio-Visual Instructions for Expressive 3D Talking Face Generation
Feb 25, 2024While considerable progress has been made in achieving accurate lip synchronization for 3D speech-driven talking face generation, the task of incorporating expressive facial detail synthesis aligned with the speaker's speaking status remains challenging. Our goal is to directly leverage the inherent style information conveyed by human speech for generating an expressive talking face that aligns with the speaking status. In this paper, we propose AVI-Talking, an Audio-Visual Instruction system for expressive Talking face generation. This system harnesses the robust contextual reasoning and hallucination capability offered by Large Language Models (LLMs) to instruct the realistic synthesis of 3D talking faces. Instead of directly learning facial movements from human speech, our two-stage strategy involves the LLMs first comprehending audio information and generating instructions implying expressive facial details seamlessly corresponding to the speech. Subsequently, a diffusion-based generative network executes these instructions. This two-stage process, coupled with the incorporation of LLMs, enhances model interpretability and provides users with flexibility to comprehend instructions and specify desired operations or modifications. Extensive experiments showcase the effectiveness of our approach in producing vivid talking faces with expressive facial movements and consistent emotional status.
Brilla AI: AI Contestant for the National Science and Maths Quiz
Mar 04, 2024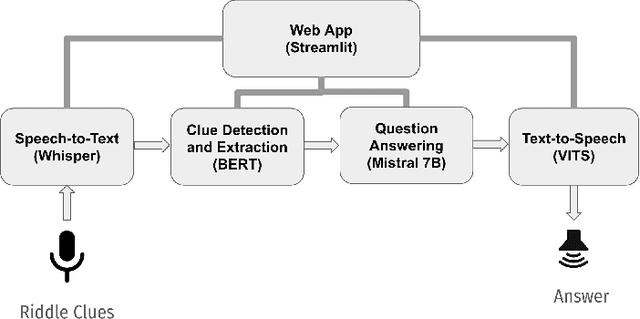
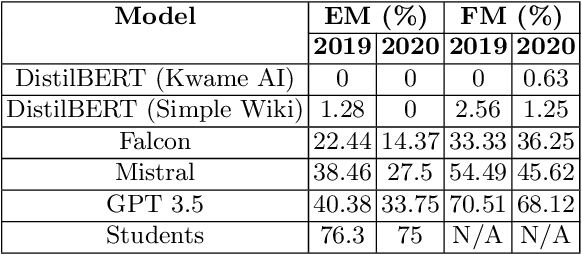
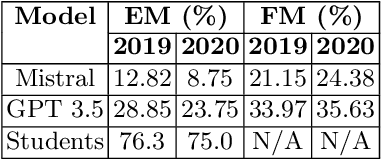

The African continent lacks enough qualified teachers which hampers the provision of adequate learning support. An AI could potentially augment the efforts of the limited number of teachers, leading to better learning outcomes. Towards that end, this work describes and evaluates the first key output for the NSMQ AI Grand Challenge, which proposes a robust, real-world benchmark for such an AI: "Build an AI to compete live in Ghana's National Science and Maths Quiz (NSMQ) competition and win - performing better than the best contestants in all rounds and stages of the competition". The NSMQ is an annual live science and mathematics competition for senior secondary school students in Ghana in which 3 teams of 2 students compete by answering questions across biology, chemistry, physics, and math in 5 rounds over 5 progressive stages until a winning team is crowned for that year. In this work, we built Brilla AI, an AI contestant that we deployed to unofficially compete remotely and live in the Riddles round of the 2023 NSMQ Grand Finale, the first of its kind in the 30-year history of the competition. Brilla AI is currently available as a web app that livestreams the Riddles round of the contest, and runs 4 machine learning systems: (1) speech to text (2) question extraction (3) question answering and (4) text to speech that work together in real-time to quickly and accurately provide an answer, and then say it with a Ghanaian accent. In its debut, our AI answered one of the 4 riddles ahead of the 3 human contesting teams, unofficially placing second (tied). Improvements and extensions of this AI could potentially be deployed to offer science tutoring to students and eventually enable millions across Africa to have one-on-one learning interactions, democratizing science education.
Probing Critical Learning Dynamics of PLMs for Hate Speech Detection
Feb 03, 2024Despite the widespread adoption, there is a lack of research into how various critical aspects of pretrained language models (PLMs) affect their performance in hate speech detection. Through five research questions, our findings and recommendations lay the groundwork for empirically investigating different aspects of PLMs' use in hate speech detection. We deep dive into comparing different pretrained models, evaluating their seed robustness, finetuning settings, and the impact of pretraining data collection time. Our analysis reveals early peaks for downstream tasks during pretraining, the limited benefit of employing a more recent pretraining corpus, and the significance of specific layers during finetuning. We further call into question the use of domain-specific models and highlight the need for dynamic datasets for benchmarking hate speech detection.
An Attention Long Short-Term Memory based system for automatic classification of speech intelligibility
Feb 05, 2024Speech intelligibility can be degraded due to multiple factors, such as noisy environments, technical difficulties or biological conditions. This work is focused on the development of an automatic non-intrusive system for predicting the speech intelligibility level in this latter case. The main contribution of our research on this topic is the use of Long Short-Term Memory (LSTM) networks with log-mel spectrograms as input features for this purpose. In addition, this LSTM-based system is further enhanced by the incorporation of a simple attention mechanism that is able to determine the more relevant frames to this task. The proposed models are evaluated with the UA-Speech database that contains dysarthric speech with different degrees of severity. Results show that the attention LSTM architecture outperforms both, a reference Support Vector Machine (SVM)-based system with hand-crafted features and a LSTM-based system with Mean-Pooling.
Online speaker diarization of meetings guided by speech separation
Jan 30, 2024Overlapped speech is notoriously problematic for speaker diarization systems. Consequently, the use of speech separation has recently been proposed to improve their performance. Although promising, speech separation models struggle with realistic data because they are trained on simulated mixtures with a fixed number of speakers. In this work, we introduce a new speech separation-guided diarization scheme suitable for the online speaker diarization of long meeting recordings with a variable number of speakers, as present in the AMI corpus. We envisage ConvTasNet and DPRNN as alternatives for the separation networks, with two or three output sources. To obtain the speaker diarization result, voice activity detection is applied on each estimated source. The final model is fine-tuned end-to-end, after first adapting the separation to real data using AMI. The system operates on short segments, and inference is performed by stitching the local predictions using speaker embeddings and incremental clustering. The results show that our system improves the state-of-the-art on the AMI headset mix, using no oracle information and under full evaluation (no collar and including overlapped speech). Finally, we show the strength of our system particularly on overlapped speech sections.
* Accepted at ICASSP 2024
RADIA -- Radio Advertisement Detection with Intelligent Analytics
Mar 06, 2024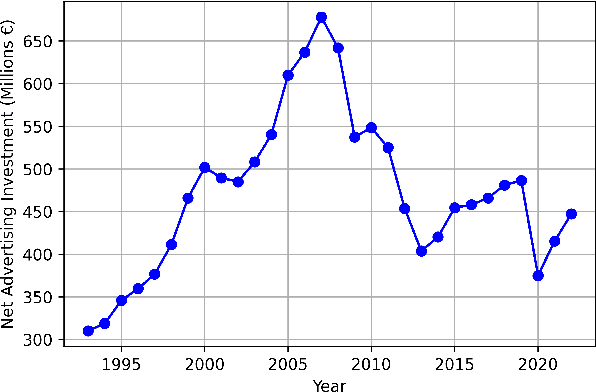
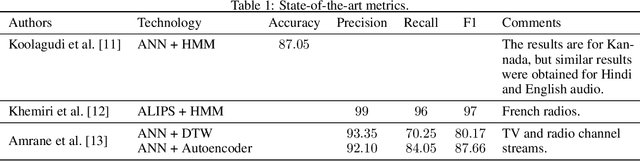
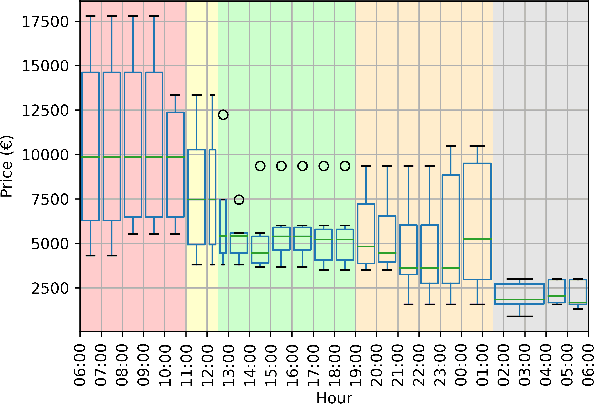
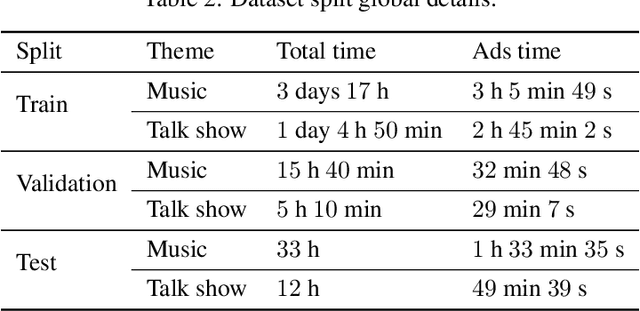
Radio advertising remains an integral part of modern marketing strategies, with its appeal and potential for targeted reach undeniably effective. However, the dynamic nature of radio airtime and the rising trend of multiple radio spots necessitates an efficient system for monitoring advertisement broadcasts. This study investigates a novel automated radio advertisement detection technique incorporating advanced speech recognition and text classification algorithms. RadIA's approach surpasses traditional methods by eliminating the need for prior knowledge of the broadcast content. This contribution allows for detecting impromptu and newly introduced advertisements, providing a comprehensive solution for advertisement detection in radio broadcasting. Experimental results show that the resulting model, trained on carefully segmented and tagged text data, achieves an F1-macro score of 87.76 against a theoretical maximum of 89.33. This paper provides insights into the choice of hyperparameters and their impact on the model's performance. This study demonstrates its potential to ensure compliance with advertising broadcast contracts and offer competitive surveillance. This groundbreaking research could fundamentally change how radio advertising is monitored and open new doors for marketing optimization.
"Define Your Terms" : Enhancing Efficient Offensive Speech Classification with Definition
Feb 05, 2024The propagation of offensive content through social media channels has garnered attention of the research community. Multiple works have proposed various semantically related yet subtle distinct categories of offensive speech. In this work, we explore meta-earning approaches to leverage the diversity of offensive speech corpora to enhance their reliable and efficient detection. We propose a joint embedding architecture that incorporates the input's label and definition for classification via Prototypical Network. Our model achieves at least 75% of the maximal F1-score while using less than 10% of the available training data across 4 datasets. Our experimental findings also provide a case study of training strategies valuable to combat resource scarcity.
SpeechBERTScore: Reference-Aware Automatic Evaluation of Speech Generation Leveraging NLP Evaluation Metrics
Jan 30, 2024While subjective assessments have been the gold standard for evaluating speech generation, there is a growing need for objective metrics that are highly correlated with human subjective judgments due to their cost efficiency. This paper proposes reference-aware automatic evaluation methods for speech generation inspired by evaluation metrics in natural language processing. The proposed SpeechBERTScore computes the BERTScore for self-supervised dense speech features of the generated and reference speech, which can have different sequential lengths. We also propose SpeechBLEU and SpeechTokenDistance, which are computed on speech discrete tokens. The evaluations on synthesized speech show that our method correlates better with human subjective ratings than mel cepstral distortion and a recent mean opinion score prediction model. Also, they are effective in noisy speech evaluation and have cross-lingual applicability.
Introduction to speech recognition
Feb 01, 2024This document contains lectures and practical experimentations using Matlab and implementing a system which is actually correctly classifying three words (one, two and three) with the help of a very small database. To achieve this performance, it uses speech modeling specificities, powerful computer algorithms (dynamic time warping and Dijktra's algorithm) and machine learning (nearest neighbor). This document introduces also some machine learning evaluation metrics.